
AI语音克隆神器来了!IndexTTS 2.0正式开源,离线可用,免费无广告!(附一键按照包)
在很多 TTS 系统里,情绪和音色是耦合的:改情绪往往也会改变音色。为了在强情绪表达下保证清晰度,模型还引入了 GPT 潜在表示(latent)辅助机制,并采用分阶段训练策略来稳定输出。这意味着你不需要采集大量语音,也无需专属模型,只要你有一段清晰的声音录音,就可以做“声音代入”。只要你的机器满足上述最低条件,再使用上述优化策略,就有可能在普通环境下跑通。这样,你可以用同一个人的音色做出不同情绪的
一、IndexTTS2 —— B 站开源的影视级 TTS 项目
在 2025 年 9 月,Index 团队宣布将其自主研发的 IndexTTS-2.0 全面开源,目标是打造一个具备工业级能力的 情感可控、自回归零样本 TTS 系统。
为什么这个项目值得关注?
- 它不是实验室原型,而是有望在实际内容创作、视频配音、动画、播客、数字人等场景中使用的工具。
- 它设计了可控机制,让用户既能保留说话人的音色,也能对情感、语速、时长进行精细控制。
- 因为是 B 站背书并开源发布,其权重、接口和部署方案都对公众开放。
- 社区反馈、整合包、演示视频、B 站视频教学都在陆续出现,普通机器用户也在尝试部署。
二、功能与技术核心解析
下面拆解 IndexTTS2 在语音合成方面的核心能力,以及它如何工作。
1. 零样本语音克隆
输入一段参考音频(几秒即可),模型能在 零训练 / 零微调 的情况下克隆这个人的音色特征,用于生成新的语音。
这意味着你不需要采集大量语音,也无需专属模型,只要你有一段清晰的声音录音,就可以做“声音代入”。
2. 精确时长控制(Duration Control)
传统自回归 TTS 模型在生成过程中通常无法精确控制音频输出的时长。这对于视频配音、口型同步、字幕对齐都是痛点。
IndexTTS2 的创新在于:它提供了两种生成方式:
- 显式控制 token 数:你可以在推理时指定生成多少 token,从而控制音频时长。
- 自由生成模式:如果不指定 token 数,模型仍能以自然节奏输出,同时尽量保留音频韵律特性。
这种设计让它既能在严格时长场景下使用,也能维持自然流畅的说话风格。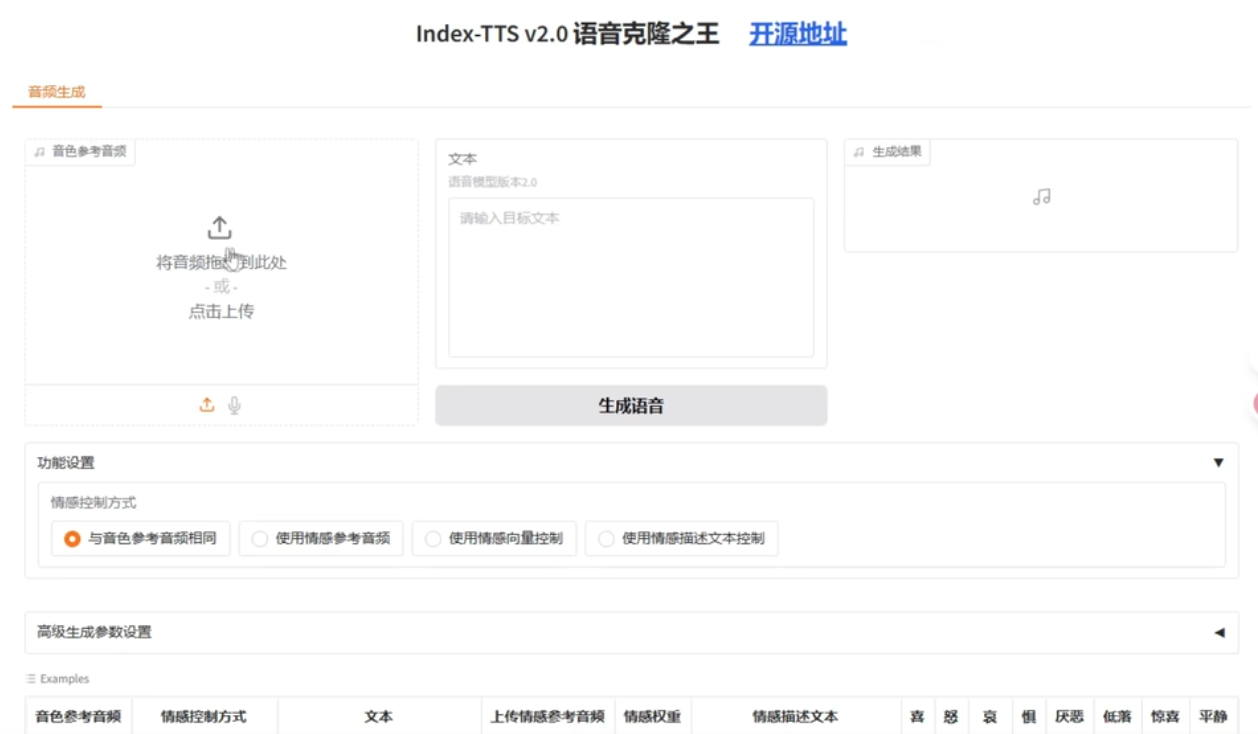
3. 情感与音色分离 / 可控情感表达
在很多 TTS 系统里,情绪和音色是耦合的:改情绪往往也会改变音色。IndexTTS2 引入了解耦设计,让音色和情绪两个维度可以分别控制。
控制方式包括:
- 使用 情感参考音频:让模型学习参考音频的情绪风格
- 使用 情感文本描述 / 软指令机制:可用一句情绪提示语(如 “今天很激动”)来引导情感强度
- 使用 情感向量输入:直接输入 8 维浮点向量控制各类情绪强度
这样,你可以用同一个人的音色做出不同情绪的语音,而不会音色跑偏。
为了在强情绪表达下保证清晰度,模型还引入了 GPT 潜在表示(latent)辅助机制,并采用分阶段训练策略来稳定输出。
4. 中文 / 拼音 / 多语言支持
在中文语境下,IndexTTS2 对多音字、长尾字的发音做了特殊处理:支持 字符 + 拼音混合输入,在必要时插入拼音提示以纠正发音。
模型以中英文为主要输出语种,输入参考音频可以是任意语言。
三、在普通机器上跑 —— 硬件条件与优化策略
很多人会问:“我的电脑 / 笔记本 / GPU 显存不太高能跑吗?”答案是:可以跑,但需要合理配置与折中。下面是部署建议和注意事项。
硬件条件参考(最低 / 推荐)
| 硬件组件 | 建议配置 / 最低要求 | 说明 |
|---|---|---|
| 显卡 / GPU | 最低:4–6 GB 显存(尝试 FP16);推荐:8 GB 及以上 | 有用户在 8 GB 显存环境下运行成功,B 站整合包里也有“8 GB 适用”说明 ([哔哩哔哩][2]) |
| 显卡类型 | NVIDIA 支持 CUDA 的显卡(如 RTX / GTX 系列) | 若非 NVIDIA GPU,推理可能无法加速或无法运行 |
| CPU | 四核起步 | CPU 也可跑推理,但速度可能非常慢 |
| 内存(RAM) | 16 GB 或以上 | 用于处理中间张量、音频缓存等 |
| 存储 / 硬盘 | 推荐 SSD(速度快) | 模型权重、缓存音频等都较大 |
| 系统 / 操作系统 | Linux / Windows 均可 | 避免目录路径中出现中文或空格,防止代码路径问题 |
实际上,有用户反馈在 8 GB 显存 的配置上可以跑得不错。
如果你显存更低,可以考虑以下优化方式:
- 使用 FP16 推理(半精度):可以显著降低显存占用。IndexTTS2 支持 FP16 模式。
- 减小 batch size / 并发量:只处理一个文本、一个语音参考时占用最少
- 关闭多余模块 / 优化插件:避免额外模块占 GPU
- 在 CPU 上运行(仅在 GPU 不可用时):可行但速度极慢
- 使用 CUDA kernel 优化 / DeepSpeed 加速:可选配置,视具体 GPU 驱动情况启用或关闭以观察效果差异
只要你的机器满足上述最低条件,再使用上述优化策略,就有可能在普通环境下跑通。
四、部署与使用流程 + 注意事项
下面是一个简化的实战流程,配合注意点。
1. 克隆与准备
git clone https://github.com/index-tts/index-tts.git
cd index-tts
git lfs pull
将模型权重(如 config.yaml、权重 .pth、拼音词表等)放在 checkpoints 目录。
2. 安装环境
建议使用 uv(项目自带包管理器):
uv sync --all-extras
或者使用 Python 虚拟环境 + pip install -r requirements.txt。注意 CUDA 版本、PyTorch 与 GPU 驱动兼容。
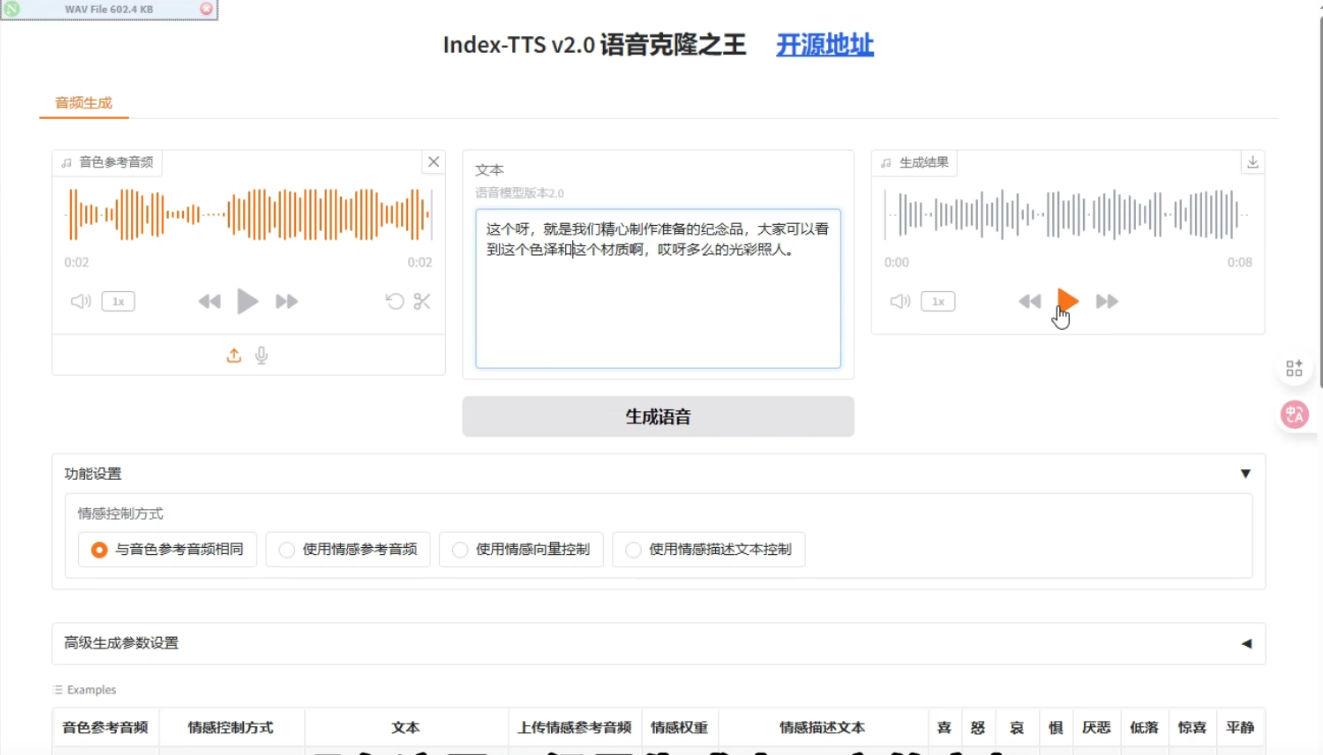
3. 启动 Web 界面(可视化演示)
uv run webui.py
浏览器访问 http://127.0.0.1:7860,可在界面上上传参考音频、输入文本、调节情感滑块、控制时长等。演示界面方便调试参数。
4. Python 脚本调用示例
from indextts.infer_v2 import IndexTTS2
tts = IndexTTS2(
cfg_path="checkpoints/config.yaml",
model_dir="checkpoints",
use_fp16=True, # 半精度推理,显存友好
use_cuda_kernel=False, # 根据硬件测试是否启用
use_deepspeed=False # 是否用 DeepSpeed 加速
)
tts.infer(
spk_audio_prompt="ref_voice.wav",
text="这是 IndexTTS2 的测试语句。",
output_path="output.wav",
emo_audio_prompt="emotion_ref.wav", # 可选
emo_alpha=0.8,
use_emo_text=True,
emo_text="带点激动"
)
5. 注意事项与调优建议
- 路径:项目目录、模型目录、音频路径避免使用中文、空格、特殊字符
- 显存:优先启用 FP16。如仍不够,可关闭其他模块 / 降低 batch
- 情感参考音频质量:情绪音频的质量、清晰度、语调风格应与目标场景尽量贴近,否则可能出现声音不稳定或失真
- 极端情绪:在表达强烈情绪(如大怒、哭泣)时,模型有可能出现咬字不清、音色波动,可适度降低情绪强度
- 拼音修正:若遇到多音字或发音不准的情况,可在文本中插入拼音提示
- 更新版本:GitHub 项目可能持续更新,注意拉取最新代码与模型权重,以匹配新的配置、接口变化
- 资源监控:运行时监控 GPU 显存、温度、IO 速度等,避免资源瓶颈导致卡死
最后备用下载
一键安装包
更多推荐



 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)