Telegram 中文群/频道搜索部署指南(含 TG号 & 协议号 & Python 代码)
《中文Telegram群组搜索导航系统搭建指南》摘要:本教程提供从零搭建中文TG群组/频道搜索导航的全流程方案,涵盖协议号申请、Python采集脚本开发(基于Telethon与@letstgbot交互)、SQLite数据存储、Flask搜索界面实现,以及Docker与systemd部署方案。重点包括:通过API自动抓取群组链接并去重入库、关键词定时扫描机制、轻量级Web搜索界面开发,同时强调安全规
面向:想要自建“中文群/频道搜索导航”的个人/团队。 覆盖:TG 账号准备、协议号(API ID/API HASH)申请、Python 采集脚本、入库、Web 搜索展示、Docker 与 systemd 部署、排错与安全建议。
目录
概念速览
本地开发环境准备
采集:与 @letstgbot 交互并抓取群/频道链接(Python)
入库:SQLite 结构与存取代码
Web 展示:Flask 搜索页面
定时任务:apscheduler/cron 扫描关键词清单
Docker 化部署(Dockerfile & docker-compose.yml)
systemd 方式部署(可选)
安全、合规与最佳实践
常见报错与排查
1) 概念速览
协议号:社区常称的“协议号”,本质是 Telegram 开发接口的 API ID 与 API HASH。
Telethon/Pyrogram:常用 Python 客户端库,用于调用 Telegram API、收发消息、监听机器人。本文以 Telethon 为例(附 Pyrogram 替代片段)。
@letstgbot:面向中文群/频道检索的搜索机器人。我们通过代码向它发送关键词并抓取返回的
t.me/xxx链接。
2) 准备 TG 账号 & 申请协议号(API ID / API HASH)
在手机上注册并登录 Telegram(建议开启两步验证)。
浏览器打开
https://my.telegram.org→ 使用 同一账号 登录。进入 API Development Tools → 新建应用。
记下生成的 API ID 与 API HASH(即“协议号”)。
安全建议:
不要泄露 API HASH;
建议结合
.env文件或环境变量管理敏感信息;开启 Telegram 账户两步验证。
3) 本地开发环境准备
在项目根目录创建.env:API_ID=你的API_ID
API_HASH=你的API_HASH
PHONE_NUMBER=+886你的手机号或+86你的手机号
# 可选:使用 Telethon StringSession\ n# TG_SESSION=你的StringSession
提示:首次运行会在终端输入短信/应用验证码完成授权;之后生成本地 session 文件,避免重复登录。
4) 采集:与 @letstgbot 交互并抓取群/频道链接(Python)
创建
collector.py:
#!/usr/bin/env python3 full = "https://" + full links.append(full) # 去重保序 seen, out = set(), [] for l in links: if l not in seen: seen.add(l) out.append(l) return out async def ensure_login(client: TelegramClient): await client.connect() if not await client.is_user_authorized(): phone = PHONE or input("请输入手机号(含国家码,如 +886..., +86...): ") await client.send_code_request(phone) code = input("输入验证码: ") await client.sign_in(phone=phone, code=code) async def search_keyword(keyword: str, timeout: float = 8.0) -> Tuple[List[str], List[str]]: if TG_SESSION: client = TelegramClient(StringSession(TG_SESSION), API_ID, API_HASH) else: client = TelegramClient("letstg", API_ID, API_HASH) messages, links = [], [] async with client: await ensure_login(client) bot = await client.get_entity(BOT_USERNAME) # 预热机器人 try: await client.send_message(bot, "/start") await asyncio.sleep(0.8) except Exception: pass @client.on(events.NewMessage(from_users=bot)) async def handler(event): txt = (event.message.message or "").strip() if txt: messages.append(txt) links.extend(extract_links(txt)) client.add_event_handler(handler) try: await client.send_message(bot, keyword) start = time.time() while time.time() - start < timeout: await asyncio.sleep(0.3) finally: client.remove_event_handler(handler) # 去重 dedup = [] seen = set() for l in links: if l not in seen: seen.add(l) dedup.append(l) return messages, dedup if __name__ == "__main__": kw = input("输入搜索关键词:") msgs, links = asyncio.run(search_keyword(kw, timeout=10)) print("\n=== 结果链接(去重后) ===") for i, l in enumerate(links, 1): print(f"{i:>2}. {l}")
5) 入库:SQLite 结构与存取代码
创建
store.py:
# -*- coding: utf-8 -*- import sqlite3 from typing import Iterable SCHEMA = """ CREATE TABLE IF NOT EXISTS tg_groups ( id INTEGER PRIMARY KEY AUTOINCREMENT, keyword TEXT, link TEXT UNIQUE, title TEXT, last_seen TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); CREATE INDEX IF NOT EXISTS idx_tg_groups_kw ON tg_groups(keyword); """ class Store: def __init__(self, path="data.db"): self.conn = sqlite3.connect(path, check_same_thread=False) self.conn.execute("PRAGMA journal_mode=WAL;") self.conn.executescript(SCHEMA) def upsert_links(self, keyword: str, links: Iterable[str]): cur = self.conn.cursor() for l in links: try: cur.execute( """ INSERT INTO tg_groups(keyword, link, title) VALUES(?, ?, NULL) ON CONFLICT(link) DO UPDATE SET keyword=excluded.keyword, last_seen=CURRENT_TIMESTAMP """, (keyword, l), ) except Exception: pass self.conn.commit() def search(self, q: str, limit=50): cur = self.conn.cursor() q_like = f"%{q}%" rows = cur.execute( "SELECT link, keyword, last_seen FROM tg_groups WHERE link LIKE ? OR keyword LIKE ? ORDER BY last_seen DESC LIMIT ?", (q_like, q_like, limit), ).fetchall() return rows整合采集 + 入库,创建
crawl_and_store.py:
# -*- coding: utf-8 -*- import asyncio from store import Store from collector import search_keyword KEYWORDS = ["学习", "科技", "影视", "AI", "留学", "区块链"] async def run_once(): db = Store("data.db") for kw in KEYWORDS: print(f"==> 抓取 {kw}") msgs, links = await search_keyword(kw, timeout=10) db.upsert_links(kw, links) print(f" 收到 {len(links)} 条链接") if __name__ == "__main__": asyncio.run(run_once())
6) Web 展示:Flask 搜索页面
创建
app.py:
# -*- coding: utf-8 -*- from flask import Flask, request, render_template_string from store import Store TEMPLATE = """ <!doctype html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>中文群/频道搜索导航</title> <style> body { font-family: -apple-system, BlinkMacSystemFont, Segoe UI, Roboto, PingFang SC, Noto Sans SC, Helvetica, Arial, sans-serif; margin: 24px; } input[type=text]{ width: 280px; padding: 8px; } button{ padding: 8px 12px; } .card{ border: 1px solid #eee; padding: 12px; border-radius: 10px; margin: 12px 0; } .muted{ color:#666; font-size: 12px; } </style> </head> <body> <h1>中文群/频道搜索导航</h1> <form method="get"> <input type="text" name="q" value="{{q}}" placeholder="输入关键词,如 学习 / 科技" /> <button type="submit">搜索</button> </form> <div> {% for link, kw, ts in rows %} <div class="card"> <div><a href="{{link}}" target="_blank" rel="noopener">{{link}}</a></div> <div class="muted">关键词:{{kw}} | 最近收录:{{ts}}</div> </div> {% else %} {% if q %}<p>未找到相关结果,换个词试试~</p>{% endif %} {% endfor %} </div> </body> </html> """ app = Flask(__name__) store = Store("data.db") @app.route("/") def home(): q = request.args.get("q", "").strip() rows = store.search(q) if q else [] return render_template_string(TEMPLATE, q=q, rows=rows) if __name__ == "__main__": app.run(host="0.0.0.0", port=8000)
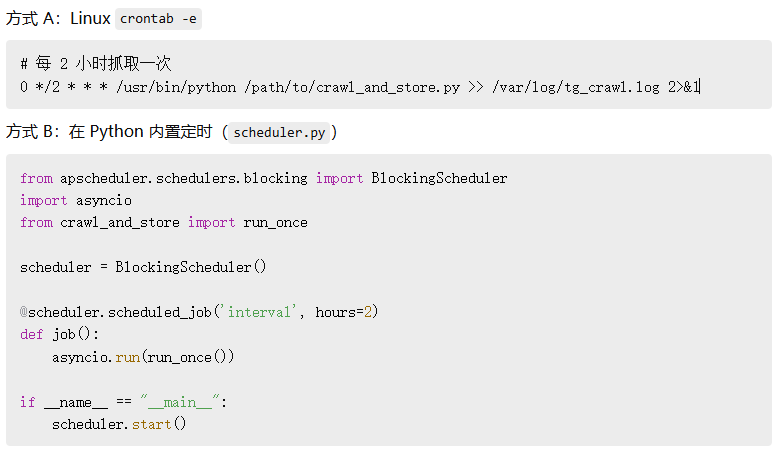
7) 定时任务:apscheduler/cron 扫描关键词清单
8) Docker 化部署
Dockerfile
FROM python:3.11-slim WORKDIR /app ENV PYTHONDONTWRITEBYTECODE=1 \ PYTHONUNBUFFERED=1 COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . EXPOSE 8000 CMD ["python", "app.py"]
10) 安全、合规与最佳实践
隐私与合规:遵守 Telegram 与当地法律法规;不分发违规内容链接;应提供下架/投诉渠道。
速率与礼貌:控制请求频率,避免对机器人造成压力;关键词批次化、间隔执行。
内容质量:可加入黑名单/白名单、活跃度标签(按最近消息频率)与“失效链接扫描”。
备份:定期备份
data.db与 session 文件;生产使用建议迁移到 PostgreSQL。观测:为 Flask 加入简单访问日志、Prometheus 指标或 Sentry 监控。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 41
41 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)