33、LangGraph开发框架(二)-- LangGraph底层原理介绍
前面介绍了LangGraph基本概念,也使用create_react_agent做了简单的实验,如果说create_react_agent是一些图模板,那底层API就指的是允许用户手动去创建这些图的API。采用底层API构建智能体的话要求开发者掌握更加复杂的构建图的语法,但借助底层API,能够更加灵活的完成各类智能体的开发,而且在某些场景下,如实现人在闭环(Human in the loop)或者
前面介绍了LangGraph基本概念,也使用create_react_agent做了简单的实验,如果说create_react_agent是一些图模板,那底层API就指的是允许用户手动去创建这些图的API。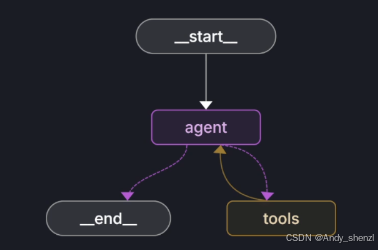
采用底层API构建智能体的话要求开发者掌握更加复杂的构建图的语法,但借助底层API,能够更加灵活的完成各类智能体的开发,而且在某些场景下,如实现人在闭环(Human in the loop)或者搭建多智能体(Multi Agent)系统时,必须要使用更加底层的图结构API才能够完成。因此这也使得掌握底层API是目前大模型开发人员进阶必备。
1. LangChain图结构概念说明
在以图构建的框架中,任何可执行的功能都可以作为对话、代理或程序的启动点。这个启动点可以是大模型的 API 接口、基于大模型构建的 AI Agent,通过 LangChain 或其他技术建立的线性序列等等,即下图中的 “Start” 圆圈所示。无论哪种形式,它都首先处理用户的输入,并决定接下来要做什么。下图展示了在 LangGraph 概念下,最基本的一种代理模型:👇
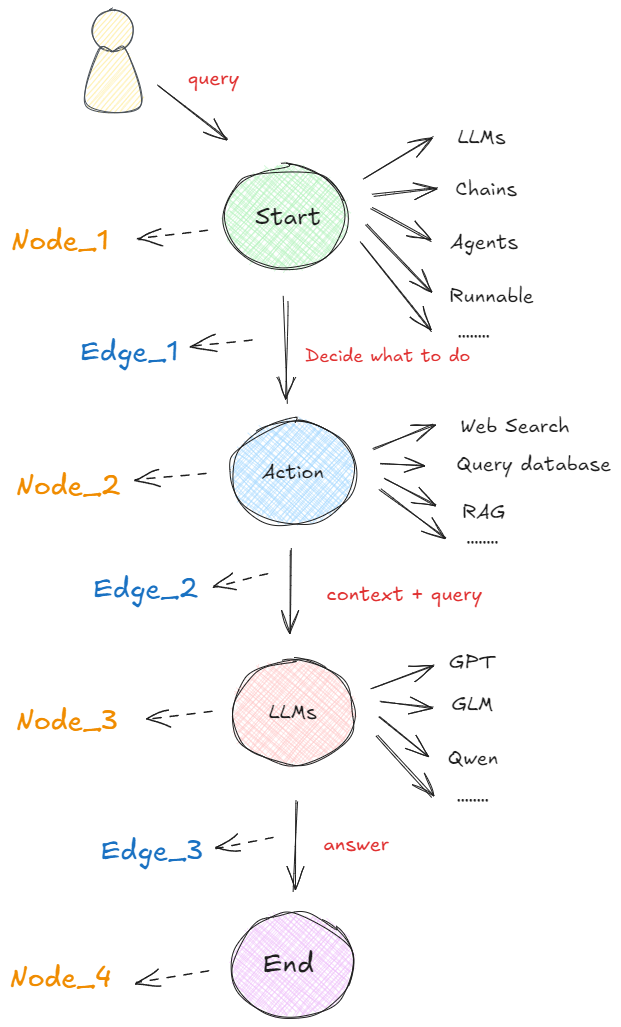
如上图所示,在这个系统中,不同的功能可以被当作“启动点”来执行。更通俗的说法是,系统中的每个操作都可以看作一个起点,可以触发一些具体的功能或任务,这些任务可以是与用户对话、操作代理程序或执行特定功能的程序。
具体来说,启动点(比如大模型的 API 接口或 AI 代理)首先接收到用户输入,然后决定下一步应该做什么。比如:
-
启动点:当用户发出请求时,启动点会处理这些输入,决定接下来要采取的行动。
-
检索信息:如果需要额外的信息(比如用户问了一个比较复杂的问题),系统会去搜索相关的内容,像用网络搜索(Web
Search)或者查询数据库(Query Database)来获取信息。 -
生成响应:接着,系统会利用一个大语言模型(LLM)对这些信息进行处理,并结合用户最初的查询来生成最终的回答。
-
最终响应:最后,这个回答会被传递到系统的终点节点,并展示给用户。
图中的“Start”表示功能的开始,“Action”是执行具体任务的过程,“LLMs”是生成最终响应的工具,而“End”则是整个过程的结束。所以,整个流程就像是从启动点开始,到最终给出一个答复的完整过程。
这个流程就是在LangGraph框架中一个非常简单的代理构成形式。非常关键且我们必须清楚的概念是:每个圆圈代表一个“节点”(Nodes),每个箭头表示一条“边”(Edges)。在 LangGraph 中,无论代理的构建是简单还是复杂,它最终都是由节点和边通过特定的组合形成的图。
这样的构建形式形成的工作流原理就是:当每个节点完成工作后,通过边告诉下一步该做什么,所以也就得出了:LangGraph的底层图算法就是在使用消息传递来定义通用程序。当节点完成其操作时,它会沿着一条或多条边向其他节点发送消息。然后,这些接收节点执行其功能,将结果消息传递给下一组节点,然后该过程继续。如此循环往复。
这就是LangGraph底层架构设计中图算法的根本思想。
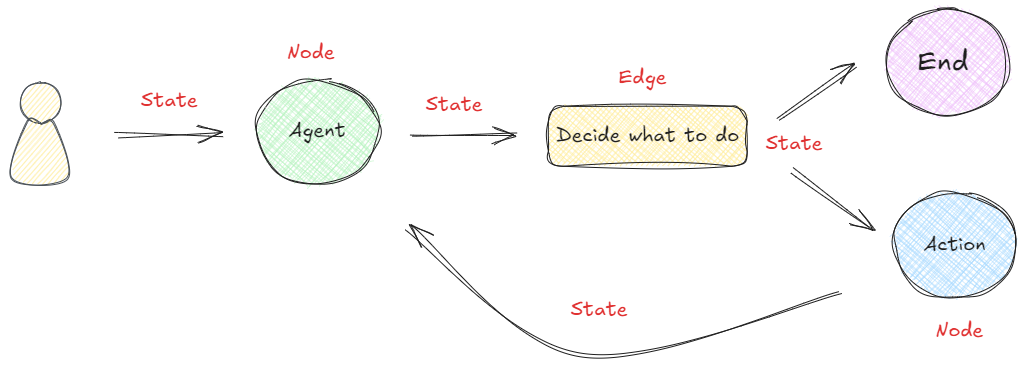
LangGraph框架是通过组合Nodes和Edges去创建复杂的循环工作流程,通过消息传递的方式串联所有的节点形成一个通路。那么维持消息能够及时的更新并向该去的地方传递,则依赖langGraph构建的State概念。 在LangGraph构建的流程中,每次执行都会启动一个状态,图中的节点在处理时会传递和修改该状态。这个状态不仅仅是一组静态数据,而是由每个节点的输出动态更新,然后影响循环内的后续操作。如下所示:👇
2.手动构建图流程
在使用图计算框架(如LangGraph)构建图时,第一步是定义图的状态(State)。具体来说:
-
图的状态(State):
状态是图计算过程中持续更新和维护的上下文信息或记忆。每个步骤(节点)都依赖于图的状态,并且通过状态来“记住”前一步的计算结果。
图的每个节点通过访问当前的状态,了解之前的步骤发生了什么,从而做出动态的决策。这就保证了图能够根据前面的数据,做出与之相关的、适时的计算。 -
为什么需要状态(State):
在图计算中,每个步骤往往是依赖于前面步骤的结果的。如果没有一个统一的状态来存储这些信息,就无法在后续步骤中访问到先前节点的计算结果。
通过状态的管理,图的每个节点可以根据已经积累的状态信息,进行合适的处理。这种机制使得图计算变得灵活,可以应对复杂的逻辑和条件。 -
StateGraph类:
StateGraph是LangGraph框架中的核心类之一。它负责创建和管理图的状态,并确保各个节点能够通过这个状态进行交互。
StateGraph不仅保存状态,还允许节点基于状态来做出动态决策,构建复杂的图结构。
简而言之,图的状态(State)就是图计算的“记忆”或“上下文”,它帮助图中的每个节点“知道”前面的节点做了什么,从而保证每个步骤都能根据先前的信息做出正确的决策。StateGraph则是一个提供这种状态管理的工具,帮助我们创建和维护这样的状态图。
构建state的方法非常简答。我们可以将图的状态设计为一个字典,用于在不同节点间共享和修改数据,然后使用StateGraph类进行图的实例化。代码如下:
from langgraph.graph import StateGraph
# 使用 stategraph 接收一个字典
builder = StateGraph(dict)
builder
<langgraph.graph.state.StateGraph at 0x2a8b9d6deb0>
builder.schemas
{dict: {'__root__': <langgraph.channels.last_value.LastValue at 0x2a8b9d7a340>}}
示例:做一个简单的实例演示,输入英文单词,转换大小写
def to_uppercase(state):
print(f"[to_uppercase] Initial state: {state}")
return {"text": state["text"].upper()}
def to_lowercase(state):
print(f"[to_lowercase] Received state: {state}")
return {"text": state["text"].lower()}
- to_uppercase:实现英文字母大写
- to_lowercase:实现英文字母小写
def build_graph():
builder = StateGraph(dict)
# 添加节点
builder.add_node("to_uppercase", to_uppercase)
builder.add_node("to_lowercase", to_lowercase)
# 添加边
builder.add_edge(START, "to_uppercase") # 从起始节点到转大写节点
builder.add_edge("to_uppercase", "to_lowercase") # 从转大写到转小写节点
builder.add_edge("to_lowercase", END) # 从转小写到结束节点
# 编译图
return builder.compile()
- add_node 方法用于向图中添加 “节点”,每个节点对应一个具体的处理函数。第一个参数是节点名称(字符串标识,如 “to_uppercase”)。第二个参数是节点对应的处理函数(如 to_uppercase、to_lowercase)
- add_edge 方法用于添加 “边”,定义节点之间的执行顺序(流转关系)。START 和 END 是特殊节点,分别表示流程的起点和终点。
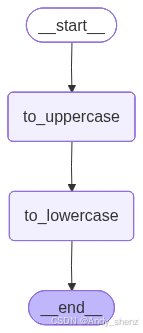
整个流程的执行顺序被定义为:START(开始)→ to_uppercase(转大写)→ to_lowercase(转小写)→ END(结束) - compile() 方法用于将定义的节点和边编译为可执行的状态图对象。
- 函数最终返回这个编译好的状态图,供后续执行(例如传入初始数据,按定义的流程运行)。
from langgraph.graph import START, END
graph = build_graph()
graph.nodes
{'__start__': <langgraph.pregel._read.PregelNode at 0x2a8bb08b890>,
'to_uppercase': <langgraph.pregel._read.PregelNode at 0x2a8bb0884d0>,
'to_lowercase': <langgraph.pregel._read.PregelNode at 0x2a8bb088f20>}
# 定义一个初始化的状态
initial_state = {"text":"Hello Word"}
graph.invoke(initial_state)
[to_uppercase] Initial state: {'text': 'Hello Word'}
[to_lowercase] Received state: {'text': 'HELLO WORD'}
最后的结果
{'text': 'hello word'}
3. 借助Pydantic对象创建图
Pydantic 是一个用于创建数据模型的 Python 库,主要用于处理数据验证和解析。它使得数据结构更加严格,提供类型安全和自动校验,简化了数据的处理过程。
- 创建“数据模型”
- 数据模型是指定义数据结构的类,用于明确数据的格式和类型。例如,你可以使用数据模型来定义一个对象,它包含了若干个字段,每个字段有特定的类型(如整数、字符串等)。Pydantic通过定义这些数据模型来帮助你管理和验证数据。
- 使用Pydantic时,你会定义一个类,这个类继承自Pydantic的BaseModel。这个类描述了数据的结构和字段类型。比如,某个模型可以包含name(字符串类型)和age(整数类型)这两个字段。
- 自动校验数据类型
- 自动校验指的是Pydantic会自动检查你传入的数据是否符合你在模型中定义的类型。如果你传入的数据类型不匹配(例如传入一个字符串而模型要求的是一个整数),Pydantic会自动抛出错误。这种校验机制非常有助于避免程序中的类型错误,并保证数据的一致性。
- 例如,假设定义了一个User类,要求name字段是字符串,age字段是整数。如果传入了age是字符串类型的值,Pydantic会自动提示错误并拒绝处理。
- 将字典数据转换为结构化对象
字典转换指的是Pydantic能将一个字典(例如从API请求中获取的原始数据)转换为我们定义的结构化模型对象。例如,你可以把一个包含name和age的字典({“name”: “Alice”, “age”: 30})转换成User类的一个实例。
from pydantic import BaseModel
class User(BaseModel):
name: str
age: int
user_data = {"name": "Alice", "age": 30}
user = User(**user_data)
user
User(name='Alice', age=30)
结构化对象意味着通过数据模型定义的数据对象拥有明确的类型、字段和值,并可以通过属性访问。比如,你可以访问user.name来获取名字,user.age来获取年龄,而这些字段已经通过Pydantic自动验证了类型。
- 类型安全 + 自动验证
-
类型安全: Pydantic确保你定义的字段类型和你实际传入的数据类型一致。如果传入的数据类型不匹配,Pydantic会抛出ValidationError,告诉你哪里出错了。这种机制能够防止程序因类型不匹配而导致的错误。
-
自动验证: 每次创建模型实例时,Pydantic会自动验证所有字段的数据类型,确保字段的数据符合预期。比如,如果你定义了一个字段age是int类型,当你传入非整数的值时,Pydantic会自动报错。
-
简化数据处理
Pydantic简化了许多数据处理的繁琐过程,尤其是当你需要接收和验证外部输入数据时。它自动处理了很多工作,比如:-
类型转换(例如将字符串转换为整数)。
-
默认值和可选值。
-
字段校验。
-
复杂数据类型(如List、Dict)的支持。
-
示例:定义和使用Pydantic模型
from pydantic import BaseModel, ValidationError
# 定义一个数据模型
class User(BaseModel):
name: str
age: int
email: str = None # 可选字段
# 使用字典数据初始化
user_data = {"name": "Alice", "age": 30}
user = User(**user_data)
print(user)
# 输出:name='Alice' age=30 email=None
# 处理数据校验
try:
invalid_user = User(name="Bob", age="not-a-number") # 这里age字段传入了一个错误的类型
except ValidationError as e:
print(e)
1 validation error for User
age
Input should be a valid integer, unable to parse string as an integer [type=int_parsing, input_value='not-a-number', input_type=str]
For further information visit https://errors.pydantic.dev/2.11/v/int_parsing
修改前面的代码
from langgraph.graph import StateGraph, START, END
from pydantic import BaseModel
# 定义结构化状态
class TextState(BaseModel):
text: str
# 定义节点处理逻辑,接受并返回 TextState
def to_uppercase(state: TextState) -> TextState:
print(f"[to_uppercase] Initial state: {state}")
return TextState(text=state.text.upper())
def to_lowercase(state: TextState) -> TextState:
print(f"[to_lowercase] Received state: {state}")
return TextState(text=state.text.lower())
# 构建图
def build_graph():
builder = StateGraph(TextState) # 使用 Pydantic 模型作为状态对象
# 添加节点
builder.add_node("to_uppercase", to_uppercase)
builder.add_node("to_lowercase", to_lowercase)
# 添加边
builder.add_edge(START, "to_uppercase") # 从起始节点到转大写节点
builder.add_edge("to_uppercase", "to_lowercase") # 从转大写到转小写节点
builder.add_edge("to_lowercase", END) # 从转小写到结束节点
# 编译图
return builder.compile()
# 执行图
def execute_graph(initial_state: TextState):
graph = build_graph()
final_state = graph.invoke(initial_state)
print("\n[Final State] ->", final_state)
# 测试执行
initial_state = TextState(text="Hello, World!")
execute_graph(initial_state)
[to_uppercase] Initial state: text='Hello, World!'
[to_lowercase] Received state: text='HELLO, WORLD!'
[Final State] -> {'text': 'hello, world!'}

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)