2025年OCR大模型巅峰对决,实测对比谁更强
2025年10月,OCR技术迎来爆发期,百度、DeepSeek等团队密集开源旗舰模型,HuggingFace热榜前三均被OCR模型占据。评测显示: 性能对比 PaddleOCR-VL在文本、表格、公式、手写体等任务表现全面领先 DeepSeek-OCR在手写体、竖排文本等场景存在明显短板 技术架构 PaddleOCR-VL采用三阶段专业化架构(布局分析→内容识别→后处理),0.9B轻量参数实现SO
文章目录
- OCR的浪潮
- OCR的实测
-
- 文本
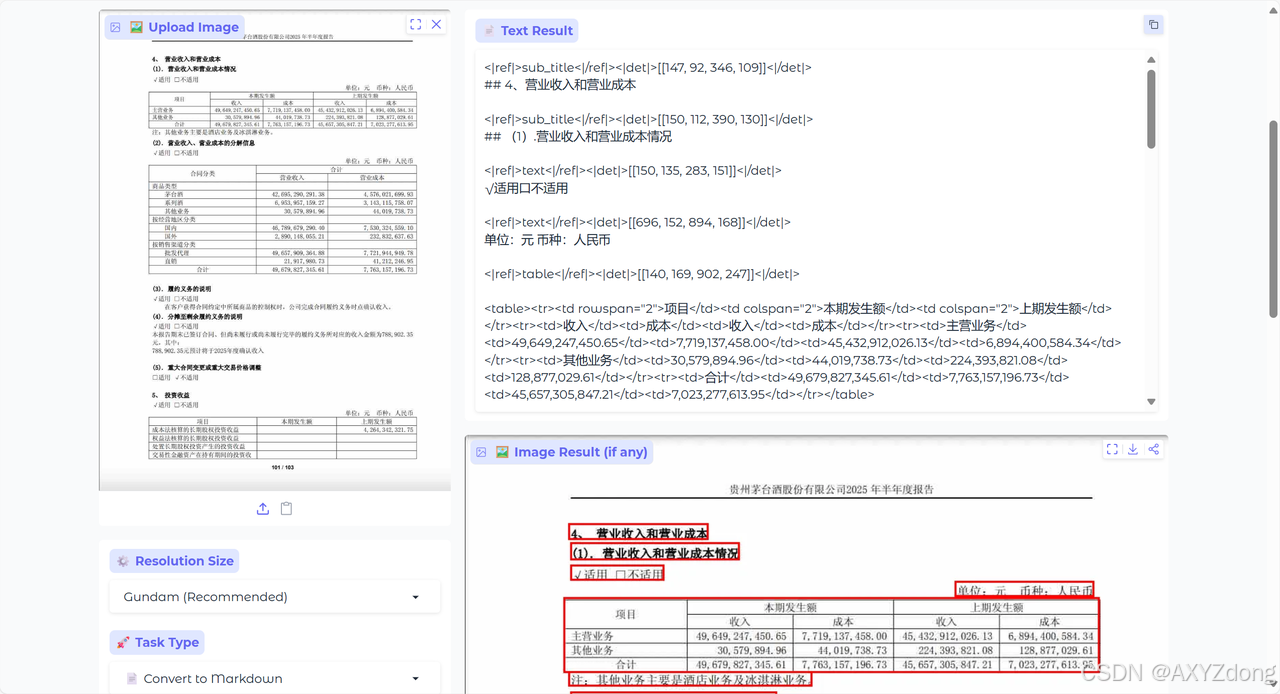
- 表格
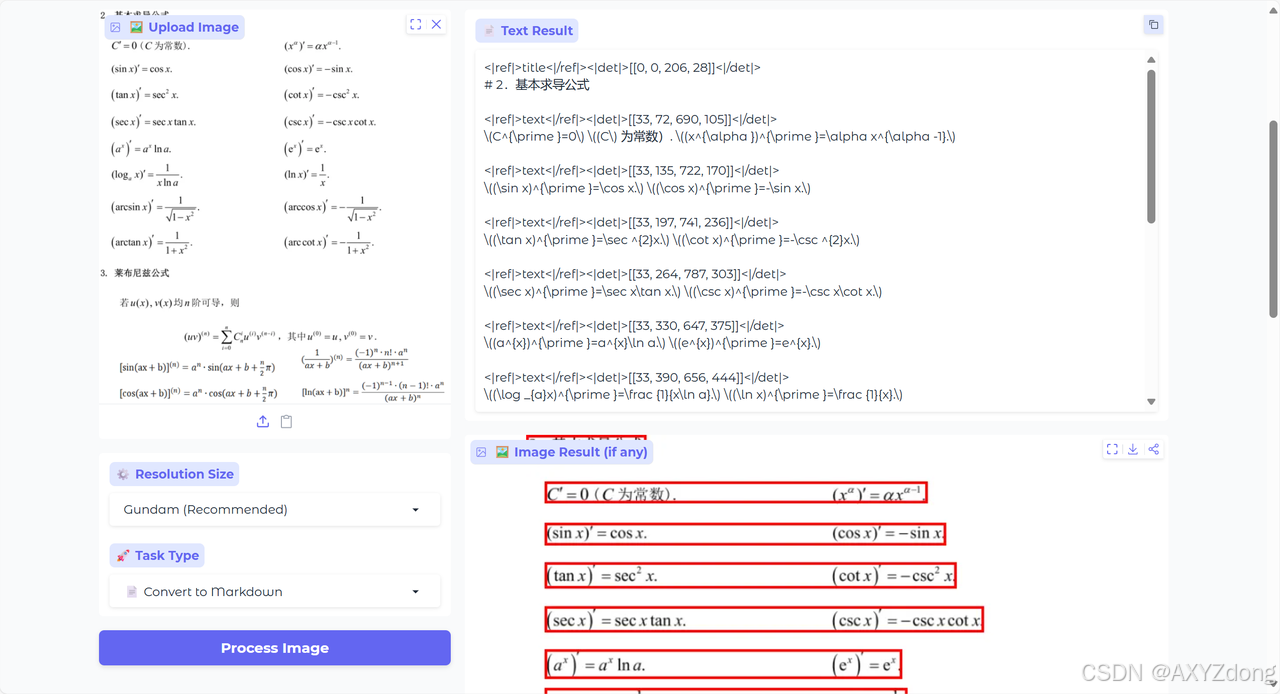
- 公式
- 手写体
- 竖版文字
- 混合排版
- 技术解读
-
- PaddleOCR-VL
- Deepseek-OCR
- Deepseek-OCR与PaddleOCR-VL性能对比
- 总结
OCR的浪潮
2025年10月,OCR领域风起云涌,一场围绕文档智能的开源竞赛骤然升温。在短短一个月内,DeepSeek、百度、上海AILab等顶尖团队密集发布并开源其旗舰级OCR模型,推动该技术进入新一轮发展浪潮。这场竞赛的热度直观地反映在全球顶级开源平台上。10月21日,HuggingFace全球模型趋势热榜前三名罕见地全部被OCR模型包揽,形成“三足鼎立”之势。榜单之首由百度飞桨团队于10月16日发布的PaddleOCR-VL占据,并已持续登顶5天;DeepSeek于20日开源的最新Deepseek-OCR模型紧随其后;第三名则为NanonetOCR。这一现象无疑向业界宣告:OCR技术正迎来一个关键的创新爆发期。各方技术路径展现出不同的侧重与远见:
- DeepSeek-OCR 创新性地提出“上下文光学压缩”理念,试图从视觉模态破解大语言模型处理长文档的效率瓶颈,展现了对未来文档智能的前瞻性思考。
- PaddleOCR-VL 则以其实用性与综合性能的极致追求引发关注。它以仅0.9B的轻量级参数,在权威的OmniBenchDoc V1.5榜单中斩获综合性能全球第一,在文档解析的四大核心能力上全面达到SOTA水平,被誉为刷新了OCR-VL模型的性能天花板。
在此背景下,本次评测旨在对站在浪潮之巅的这些顶尖模型进行一次全面的“巅峰对决”。本文将通过多场景横评,客观对比它们在常规文本、表格、公式识别乃至手写体、竖排文字等高难度任务上的实际表现。这不仅是一次性能的检验,更是一场“理论创新”与“实用最强” 的对话,旨在为开发者与行业用户提供一份清晰的选型参考。
OCR的实测
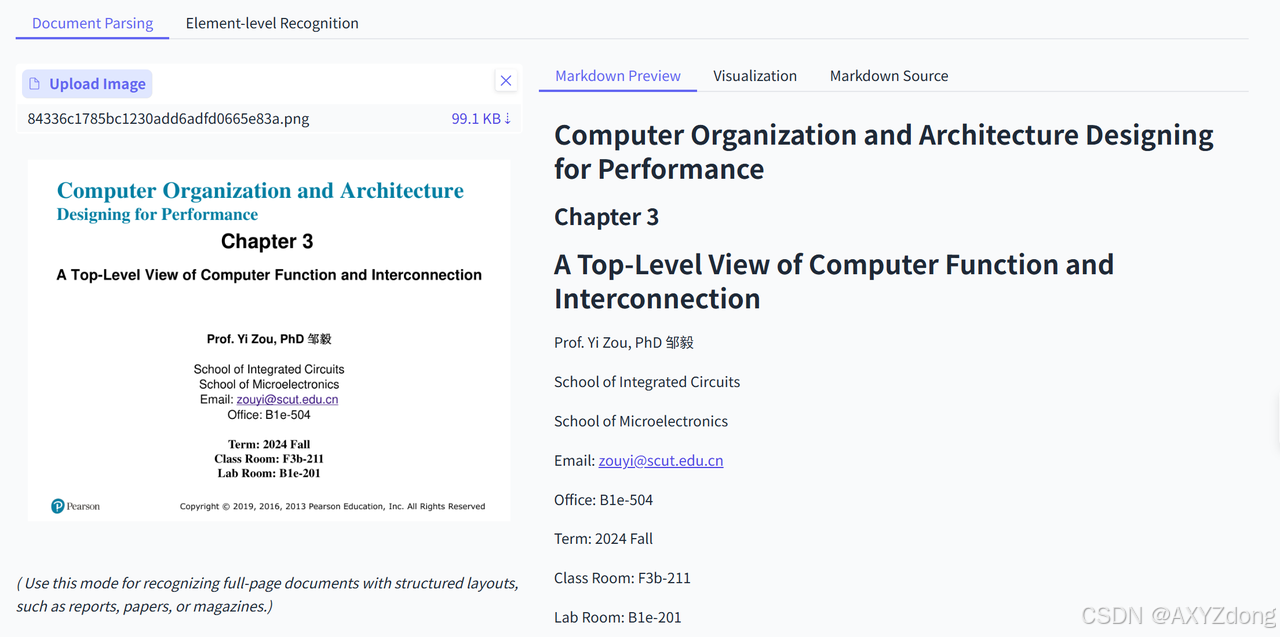
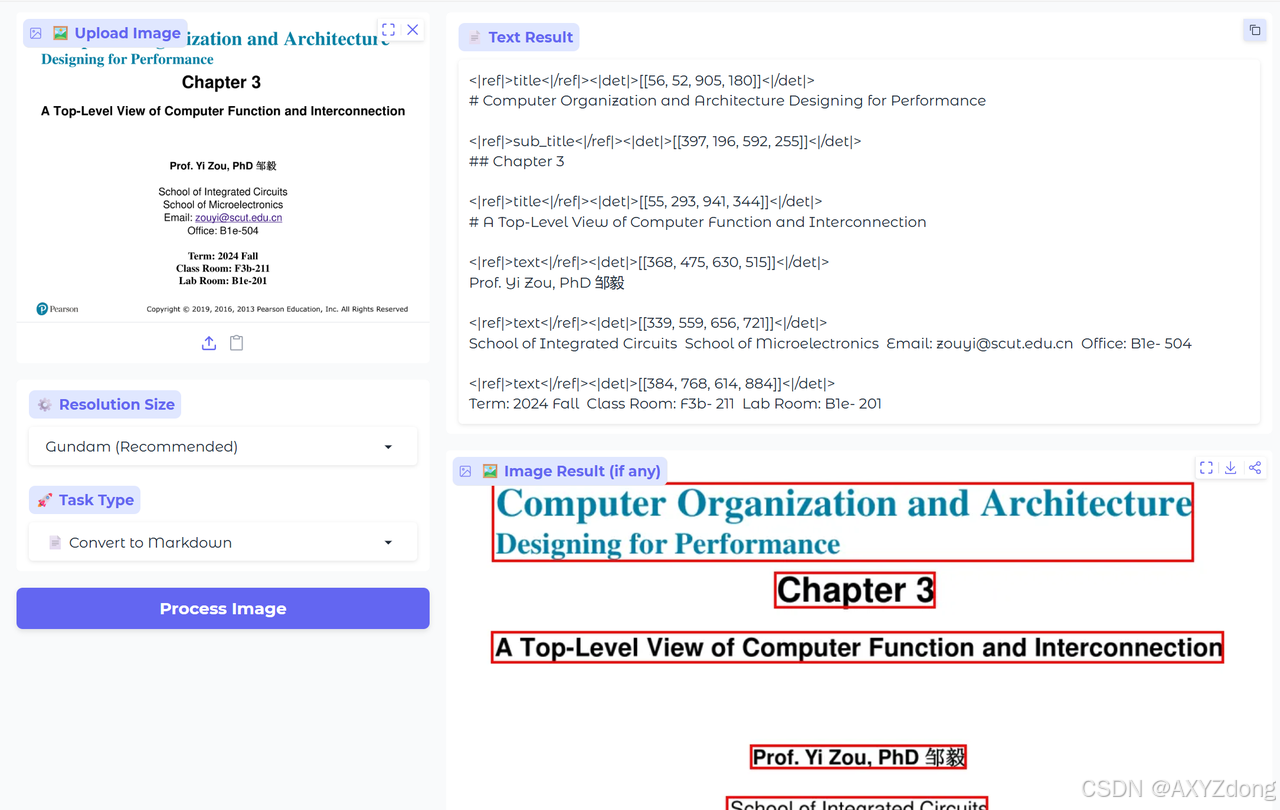
文本
- PaddleOCR-VL
- DeepSeek-OCR
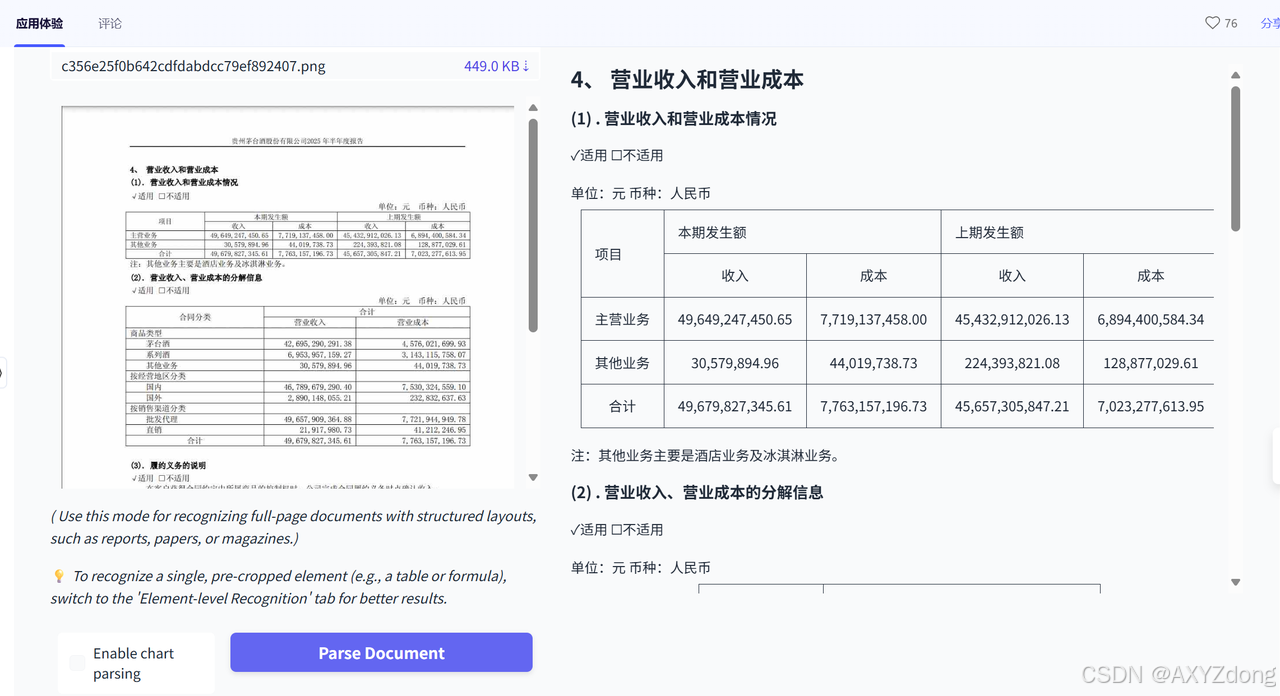
表格
- PaddleOCR-VL
- DeepSeek-OCR
公式
- PaddleOCR-VL

- DeepSeek-OCR
手写体
- PaddleOCR-VL

- DeepSeek-OCR

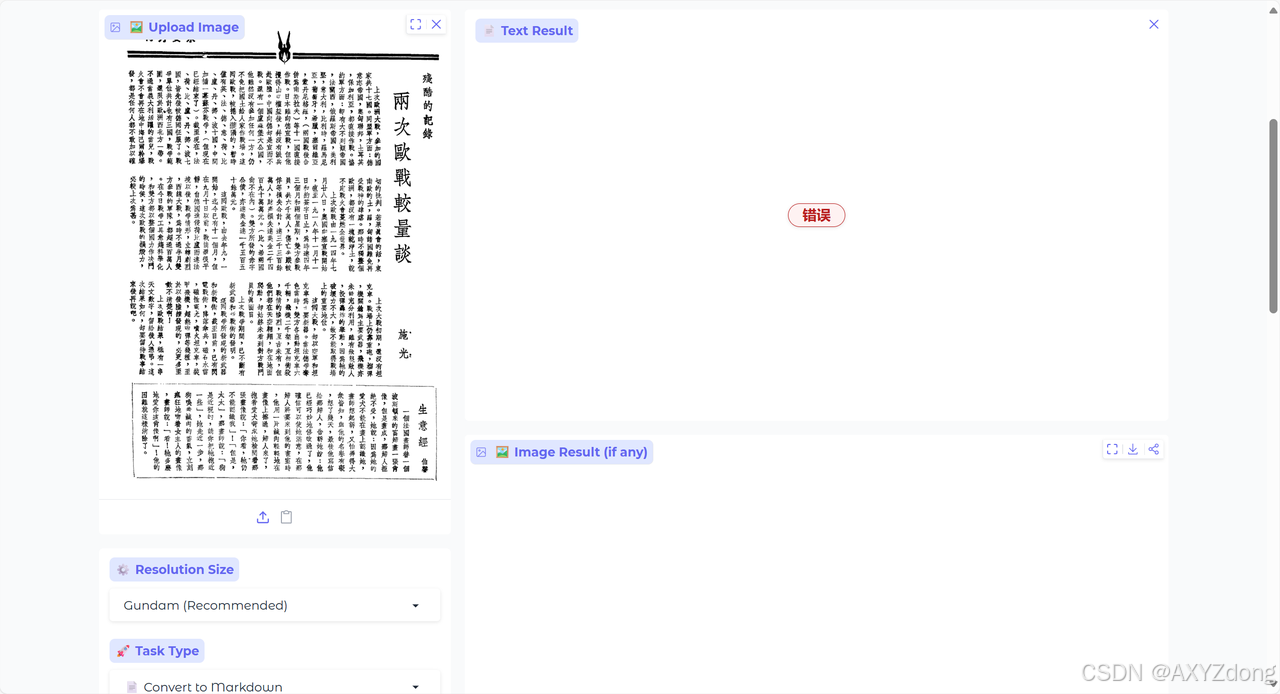
竖版文字
- PaddleOCR-VL

- DeepSeek-OCR
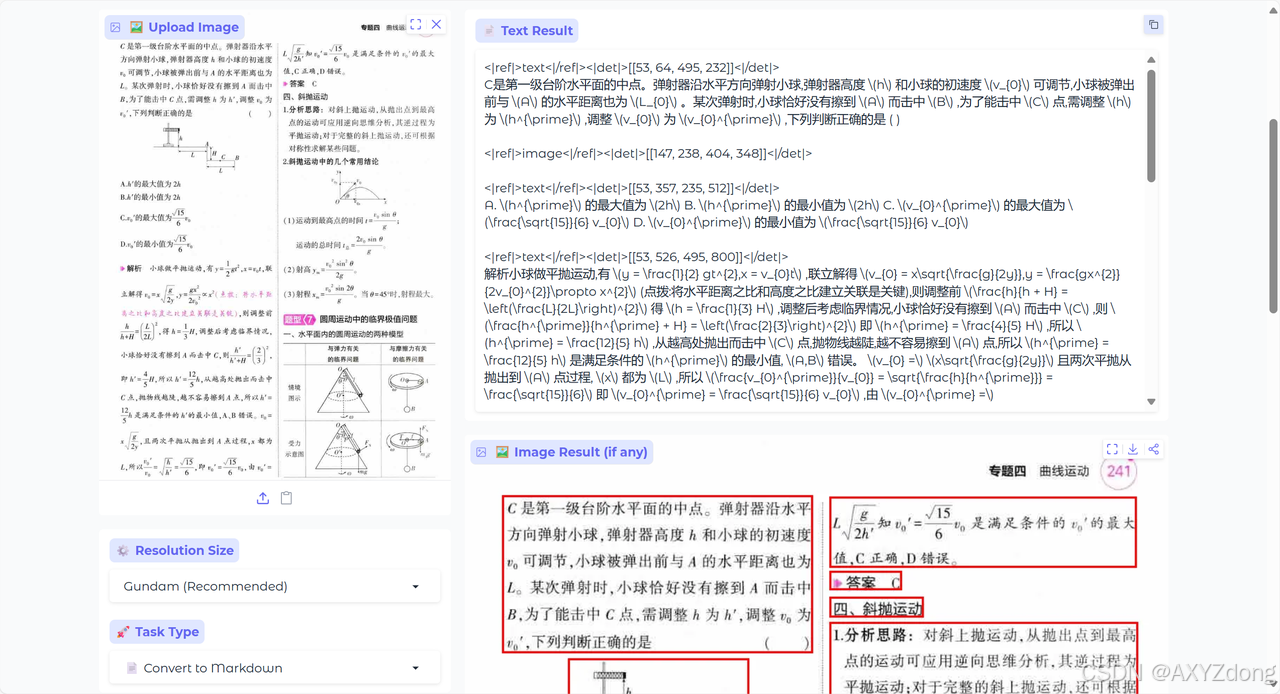
混合排版
- PaddleOCR-VL

- DeepSeek-OCR
综合实测结果,可以发现,DeepSeek-OCR在图片、手写字体、竖版文本等方面提取能力较差,而PaddleOCR-VL在文本、表格、公式、手写体、竖版文字等方面输出完整,有较好的OCR能力。
技术解读
PaddleOCR-VL
模型架构
PaddleOCR-VL 采用分阶段专用化架构,将文档解析流程系统性地分解为三个核心环节,有效解决了端到端模型在复杂布局下的稳定性与效率问题。系统首先通过专门设计的 PP-DocLayoutV2 模型进行布局分析。该模型采用双网络串联架构:第一个网络基于 RT-DETR 检测框架,负责对文档图像中的各种版面元素进行精确的定位和分类;第二个网络是一个轻量级的指针网络,包含六层 Transformer 编码器,并引入了来自 Relation-DETR 的几何偏置机制。该指针网络将检测到的元素边界框和类别信息转化为嵌入表示,通过计算元素间的双线性相似度生成一个表示两两顺序关系的矩阵,最后使用确定的赢家累积解码算法恢复出全局拓扑一致的阅读顺序。这种设计将布局分析与内容识别解耦,避免了端到端视觉语言模型在处理多列或混合布局时常见的幻觉问题和高延迟。
完成布局分析后,系统进入元素识别阶段。PaddleOCR-VL-0.9B 模型负责对前一阶段定位出的各个区域进行细粒度内容解析。该模型采用视觉-语言对齐架构,其核心是一个支持原生动态分辨率的视觉编码器,该编码器基于 NaViT 技术,能够无需扭曲地处理任意尺寸的高清文档图像,显著提升了密集文本的识别精度。视觉特征通过一个随机初始化的两层 MLP 投影器映射到语言模型的嵌入空间。语言模型采用参数量为 0.3B 的 ERNIE 模型,并集成了增强的 3D-RoPE 位置编码来更好地理解文档中的空间关系。该模型经过多任务指令微调,能够精准识别文本、表格、公式和图表四种元素,并分别输出相应的结构化格式。
最后,一个轻量级的后处理模块负责整合布局结构和识别内容。它根据 PP-DocLayoutV2 提供的阅读顺序和区域类别,将 PaddleOCR-VL-0.9B 识别出的文本、表格、公式和图表内容有序地组织起来,最终生成同时包含视觉层次和语义信息的结构化 Markdown 和 JSON 文档,完成了从图像到结构化数据的完整解析流程。
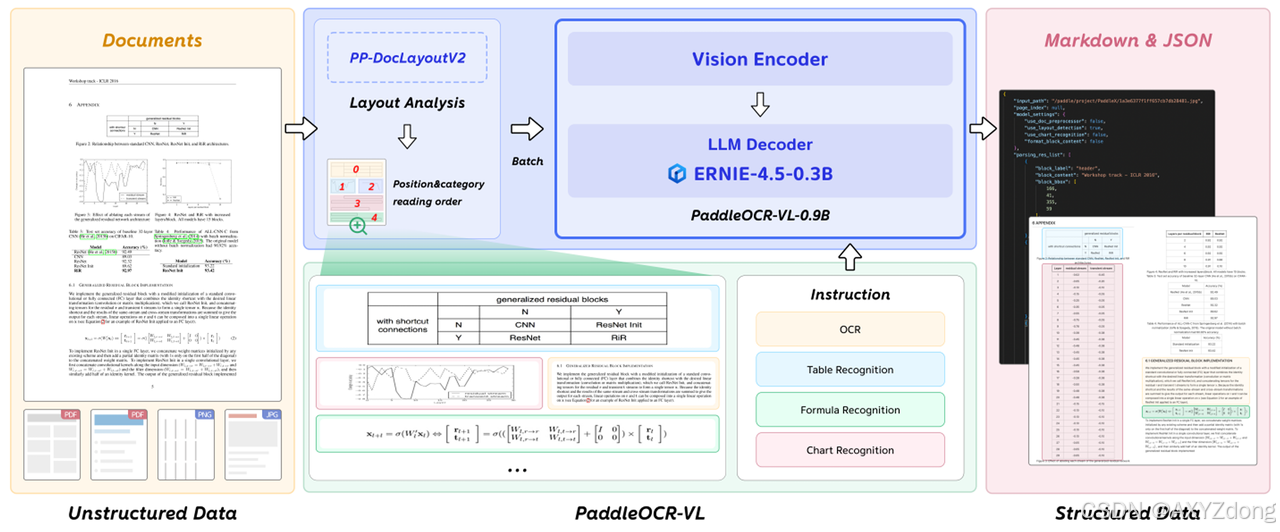
PP-DocLayoutV2
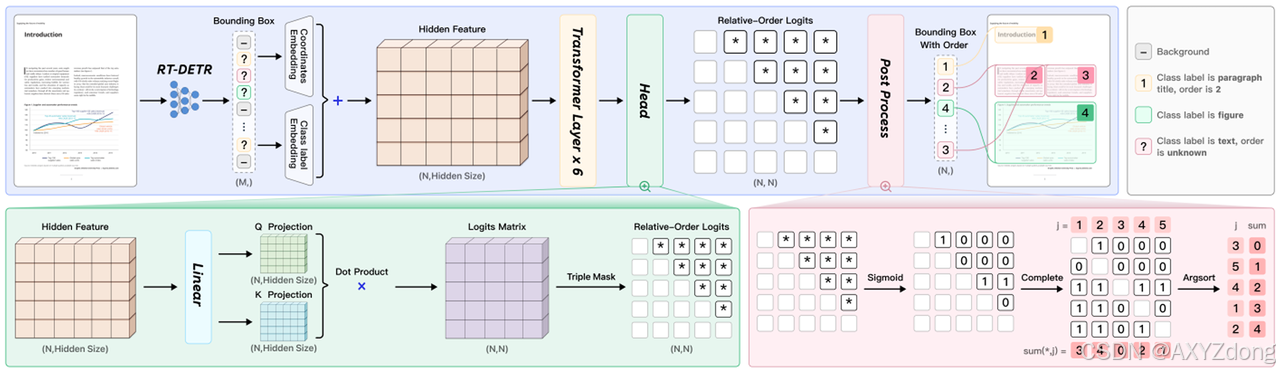
- 模型架构 :PP-DocLayoutV2基于RT-DETR扩展,增加了专门用于预测阅读顺序的指针网络。
- 训练策略:两阶段法
第一阶段:检测与分类训练首先训练核心RT-DETR模型进行版面元素定位和分类。模型采用PP-DocLayout_Plus-L的预训练权重初始化,并在包含超过20,000个高质量样本的自建数据集上训练100个epoch。
第二阶段:阅读顺序预测训练冻结第一阶段训练好的检测模型参数,独立训练指针网络。该网络输出表示元素间两两排序关系的矩阵,并使用广义交叉熵损失进行优化以增强对标注噪声的鲁棒性。训练采用恒定学习率2e-4和AdamW优化器,共进行200个epoch。
PaddleOCR-VL-0.9B
- 模型架构 :包含视觉编码器、投影器和语言模型三个模块,视觉模型初始化自Keye-VL权重,语言模型初始化自ERNIE-4.5-0.3B权重。
- 训练策略:两阶段法
第一阶段:预训练对齐目标是对齐视觉与文本特征空间。使用2900万高质量图文对训练1个epoch,最大分辨率1280×28×28,序列长度16384,批大小128,启用数据增强。学习率从5×10⁻⁵衰减至5×10⁻⁶。此阶段让模型建立视觉输入与语义文本的连贯理解。
第二阶段: 指令微调专注于适应下游任务。使用270万精心策划的样本训练2个epoch,最大分辨率提升至2048×28×28,采用更精细的学习率(5×10⁻⁶→5×10⁻⁷)。针对四大任务进行优化:OCR文字识别、表格解析(输出OTSL格式)、公式识别(转换LaTeX格式)和图表信息提取(输出Markdown表格)。
该方案通过分阶段训练策略有效平衡通用能力与专项性能。阅读顺序预测机制与多任务指令微调设计显著提升了复杂文档的结构理解和内容识别精度。
Deepseek-OCR
DeepSeek-OCR是一个端到端的多模态文档解析模型。
如下图,DeepSeek-OCR的架构由编码器(DeepEncoder)和解码器(DeepSeek3B-MoE-A570M)组成。
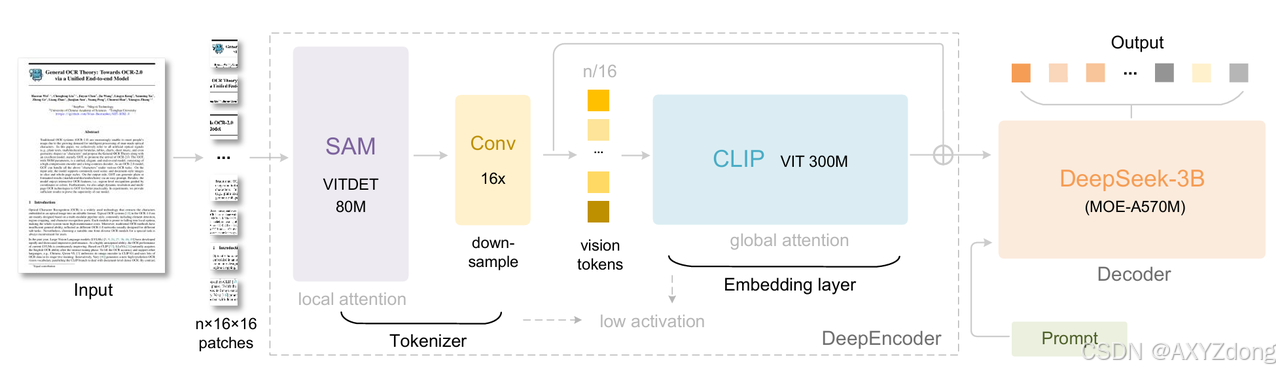
DeepEncoder编码器:DeepEncoder作为DeepSeek-OCR的核心组件,是一个专为高分辨率图像设计的轻量级视觉压缩器,旨在解决现有VLM视觉编码器(如Vary、InternVL2.0)在高分辨率输入下产生的Token过多、激活内存巨大及难以支持多分辨率等核心痛点。其设计包含三个关键阶段:首先,视觉感知模块以基于80M参数的SAM模型为骨干,通过窗口注意力机制高效捕捉图像局部细节(如文本位置),规避了全局注意力的高内存消耗;随后,16倍卷积压缩器通过一个紧凑的两层卷积网络,将视觉Token数量进行16倍下采样(例如从4096个压缩至256个),极大减轻了后续计算负担;最后,视觉知识模块基于300M参数的CLIP模型(移除了其初始的patch嵌入层),对压缩后的Token施加全局注意力,以抽取出图像的整体语义与文档结构逻辑,从而为解码器提供高质量的结构化视觉知识。这个版本将三个模块的信息整合进一个连贯的段落中,通过“首先”、“随后”、“最后”等连接词清晰地展示了数据流和处理阶段,同时保持了所有的技术细节和专业性。
DeepSeek3B-MoE解码器:解码器使用的是DeepSeek3B-MoE,由3B参数的MoE模型,包含64个routed experts和2个shared experts。推理时仅激活6个routed experts+2个shared experts,实际激活参数约570M(仅为3B模型的19%)。这样做既保留3B模型的文本生成能力,又将推理速度提升至“500M小模型”级别,适合大规模部署。
Deepseek-OCR与PaddleOCR-VL性能对比
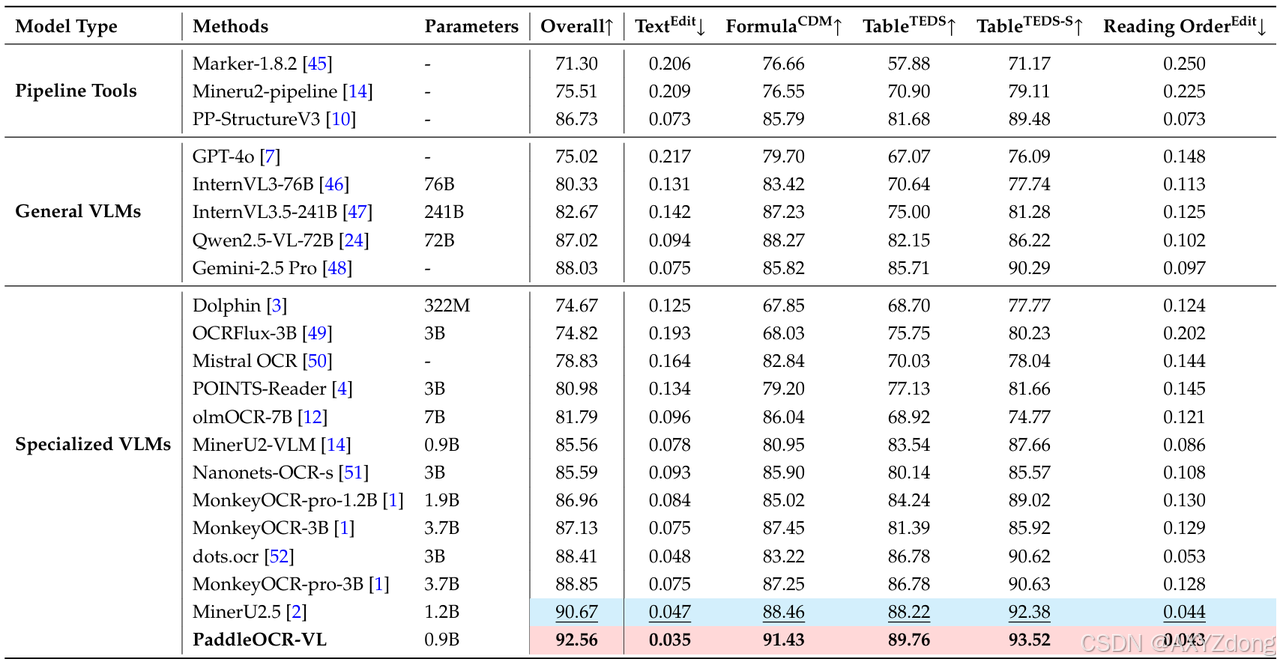
- 最新 OmniBenchDoc V1.5 权威榜单中,PaddleOCR-VL 以仅 0.9B参数 实现 92.56综合得分,超越 DeepSeek-OCR-Gundam-M(3B参数)约6分,继续位居全球第一。
- 在OCR核心四项任务上(文本、公式、表格、结构理解),PaddleOCR-VL均全面超越DeepSeek-OCR,为当前SOTA方案。
![[图片]](https://i-blog.csdnimg.cn/direct/dd26627b1e00420b89604df1430eb597.png)
- 整体性能:综合得分 92.56 vs 86.46,领先 6.1 分,整体文档解析能力全球最强。
- 公式识别:公式 CDM 得分 89.76 vs 89.45,PaddleOCR-VL 在数学表达与符号识别上更稳定。
- 表格结构理解:Table TEDS 得分 93.52 vs 78.02,领先 15.5 分,结构化还原与单元格识别精准度显著提升。
- 表格语义理解:Table TEDS-S 得分 91.43 vs 81.55,领先 9.9 分,表格逻辑与语义关联恢复更完整。
- 阅读顺序识别:Reading Order Edit 误差 0.043 vs 0.093,降低 约 54%,文档阅读顺序更符合人类逻辑。
注:DeepSeek-OCR论文中用的是OmniBenchDoc V1.0,在该榜单上,PaddleOCR-VL指标为SOTA;上述测试为权威榜单OmniBenchDocV1.5最新测试结果。
关于 OmniBenchDoc V1.5
OmniBenchDoc V1.5 是当前国际上最系统、最具代表性的文档视觉语言理解(Document Vision-Language Understanding)基准之一,由 OpenDataLab 联合清华大学、阿里达摩院、上海人工智能实验室等多家机构共同建设,并在 CVPR 2025 论文《OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations》 中正式发布。
该基准覆盖 九大类真实文档场景(教材、学术论文、财报、报纸、合约、手写笔记等),在布局、语言、版式上高度多样化,提供 超十万级页面、百万级标注样本,并建立了端到端与模块化双层评测体系,涵盖文本识别、公式解析、表格重建、阅读顺序、逻辑结构等核心维度。
凭借公开数据、可复现评测工具与多机构共同维护机制,OmniBenchDoc V1.5 已成为学界和产业界公认的权威基准,被 GPT-4o、Gemini-2.5 Pro、Qwen2.5-VL、InternVL 1.5、MonkeyOCR Pro 等主流模型采用,用于系统验证多模态文档理解性能。
关于PaddleOCR-VL模型
1)全球性能第一
- 在权威评测 OmniDoc Bench V1.5 中,PaddleOCR-VL 以 92.6分刷新综合性能记录。
- 四大核心能力(文本、表格、公式、阅读顺序)全线 SOTA,超越 GPT-4o、Gemini-2.5 Pro、Qwen2.5-VL-72B 及主流OCR专业模型。
2)轻量高效,参数仅0.9B
在极低计算开销下即可实现高精度识别文本、手写汉字、表格、公式、图表等复杂元素。
3)支持 109 种语言
覆盖中文、英语、法语、日语、俄语、阿拉伯语、西班牙语等。
![[图片]](https://i-blog.csdnimg.cn/direct/672a5ea01bf9484d8ca06ced384e11a4.png)
总结
本文从当前OCR技术发展的背景出发,概述了近期OCR模型在行业内的最新动态。基于HuggingFace Trending中排名前列的OCR模型,我们选取了DeepSeek-OCR与PaddleOCR-VL进行实际测试与比较分析。
测试结果显示,PaddleOCR-VL近期在多个平台的热度表现突出,连续多日位居HuggingFace、ModelScope等相关榜单前列,反映出其在社区中的广泛关注度。文章进一步从技术架构、应用适配性、实际场景表现等方面对两个模型展开解析。综合来看,PaddleOCR-VL在多项评测与应用中展现出较强的综合能力,具备优秀的实用性能。
欢迎各位读者朋友结合自身业务场景进行实测验证,探索不同OCR模型在实际应用中的表现差异。毕竟,模型是否真正“领先”,最终还是取决于是否能够高效、稳定地服务于具体业务需求。
如果以上内容有任何错误或者不准确的地方,欢迎在下面 👇 留言。或者你有更好的想法,欢迎一起交流学习~~~
更多精彩内容请前往 AXYZdong的博客

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)