【解决】调用通义千问嵌入模型报错:batch size is invalid, it should not be larger than 10
摘要 在使用LangChain框架和Chroma数据库处理本地文件向量化时,遇到批量大小限制错误(batch size不能超过10)。解决方案是将文档分割成10个一批次处理,首批创建数据库,后续批次追加。通过分批次处理避免了嵌入模型的批量限制问题。
·
基本情况说明
应用功能:
读取本地文件,向量化后存储到本地文件数据库中。
开发框架:langchain
嵌入模型:text-embedding-v4
数据库chroma
报错全部信息:ValueError: status_code: 400 code: InvalidParameter message: <400> InternalError.Algo.InvalidParameter: Value error, batch size is invalid, it should not be larger than 10.: input.contents
报错情况说明
参考百炼控制台,最大行数有限制存在。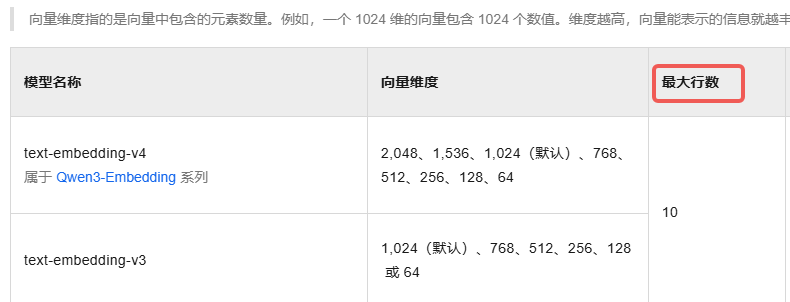
由于整个调用过程未显式传递batch_size参数,且整个调用过程由Chroma内部调用,导致问题不好定位。
解决方案:
将读取的文档内容进行分割,批量入库。
# 分批处理文档
batch_size = 10
for i in range(0, len(split_docs), batch_size):
batch_docs = split_docs[i:i+batch_size]
if i == 0:
# 第一批文档创建数据库
vectordb = Chroma.from_documents(
documents=batch_docs,
embedding=embedding,
persist_directory=persist_directory
)
else:
# 后续批次添加到数据库
vectordb.add_documents(batch_docs)
说到最后
以上。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)