【大模型:知识图谱】--2.命名实体识别(NER)详解
命名实体识别(NER)是知识图谱构建中的关键步骤,旨在从文本中识别出具有特定意义的实体,如人名、地名、机构名等。中文NER相较于英文更具挑战性,主要由于中文缺乏明显的词边界标志,且存在中英文混用的情况。当前NER技术方法包括基于规则和词典的方法、基于统计的方法、混合方法以及基于神经网络的方法。其中,神经网络方法如BERT模型,通过预训练和微调,在NER任务中表现出色。实践环节展示了如何使用BERT
在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识图谱的每个步骤。今天介绍知识图谱里面的NER的环节。
命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。通常包括两部分:
(1)实体边界识别;
(2) 确定实体类别(人名、地名、机构名或其他)。
目录
1. NER--中文问题
中文的命名实体识别与英文的相比,挑战更大,目前未解决的难题更多。英语中的命名实体具有比较明显的形式标志,即实体中的每个词的第一个字母要大写,所以实体边界识别相对容易,任务的重点是确定实体的类别。和英语相比,汉语命名实体识别任务更加复杂,而且相对于实体类别标注子任务,实体边界的识别更加困难。
汉语命名实体识别的难点主要存在于:
- 汉语文本没有类似英文文本中空格之类的显式标示词的边界标示符,命名实体识别的第一步就是确定词的边界,即分词。
- 汉语分词和命名实体识别互相影响。
- 除了英语中定义的实体,外国人名译名和地名译名是存在于汉语中的两类特殊实体类型。
- 现代汉语文本,尤其是网络汉语文本,常出现中英文交替使用,这时汉语命名实体识别的任务还包括识别其中的英文命名实体。
- 不同的命名实体具有不同的内部特征,不可能用一个统一的模型来刻画所有的实体内部特征。
2. NER--方法总结
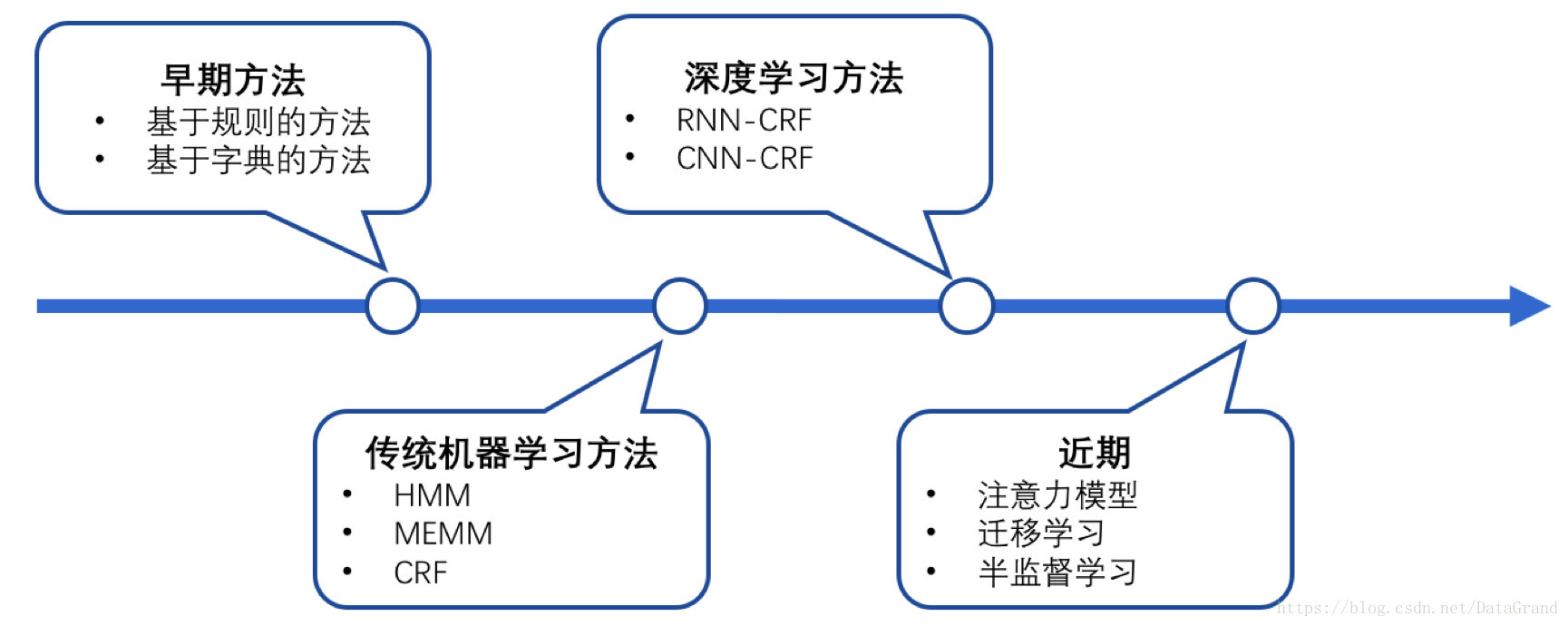
当前命名实体识别的主要技术方法分为:基于规则和词典的方法、基于统计的方法、二者混合的方法、神经网络的方法等。
2.1 基于规则和词典的方法
基于规则的方法多采用语言学专家手工构造规则模板,选用特征包括统计信息、标点符号、关键字、指示词和方向词、位置词(如尾字)、中心词等方法,以模式和字符串相匹配为主要手段,这类系统大多依赖于知识库和词典的建立。
- 缺点
- 这类系统大多依赖于知识库和词典的建立。
- 系统可移植性不好,对于不同的系统需要语言学专家重新书写规则。
- 代价太大,系统建设周期长。
2.2 基于统计的方法
基于统计机器学习的方法主要包括:隐马尔可夫模型(HiddenMarkovMode,HMM)、最大熵(MaxmiumEntropy)、支持向量机(Support VectorMachine,SVM)、条件随机场(ConditionalRandom Fields)。
- 特点
- 最大熵模型有较好的通用性,主要缺点是训练时间复杂性非常高。
- 条件随机场特征灵活、全局最优的标注框架,但同时存在收敛速度慢、训练时间长的问题。
- 隐马尔可夫模型在训练和识别时的速度要快一些,Viterbi算法求解命名实体类别序列的效率较高。
- 最大熵和支持向量机在正确率上要比隐马尔可夫模型高。
- 基于统计的方法对语料库的依赖也比较大
2.3 混合方法
自然语言处理并不完全是一个随机过程,单独使用基于统计的方法使状态搜索空间非常庞大,必须借助规则知识提前进行过滤修剪处理。目前几乎没有单纯使用统计模型而不使用规则知识的命名实体识别系统,在很多情况下是使用混合方法,主要包括:
- 统计学习方法之间或内部层叠融合。
- 规则、词典和机器学习方法之间的融合,其核心是融合方法技术。在基于统计的学习方法中引入部分规则,将机器学习和人工知识结合起来。
- 将各类模型、算法结合起来,将前一级模型的结果作为下一级的训练数据,并用这些训练数据对模型进行训练,得到下一级模型。
2.4 基于神经网络的方法
近年来,随着硬件能力的发展以及词的分布式表示(word embedding)的出现,神经网络成为可以有效处理许多NLP任务的模型。主要的模型有NN/CNN-CRF、RNN-CRF、LSTM-CRF。
神经网络可以分为以下几个步骤。
- 对于序列标注任务(如CWS、POS、NER)的处理方式是类似的,将token从离散one-hot表示映射到低维空间中成为稠密的embedding。
- 将句子的embedding序列输入到RNN中,用神经网络自动提取特征。
- Softmax来预测每个token的标签。
- 优点
- 神经网络模型的训练成为一个端到端的整体过程,而非传统的pipeline。
- 不依赖特征工程,是一种数据驱动的方法。
- 缺点
 3.NER--主流模型
3.NER--主流模型
| 类别 | 模型/方法 | 核心思想 | 优点 |
|---|---|---|---|
| 传统机器学习 | CRF | 建模标签序列依赖关系,结合手工特征(词性、词形等) | 小数据表现好,标签逻辑性强 |
| HMM | 基于概率的生成模型,假设观测值由隐藏状态生成 | 简单易实现 | |
| 深度学习 | BiLSTM-CRF | 双向LSTM捕捉上下文 + CRF约束标签逻辑 | 自动学习特征,中等数据表现优秀 |
| IDCNN | 膨胀卷积网络捕捉长距离依赖 | 并行计算效率高 | |
| 预训练语言模型 | BERT | Transformer编码上下文,微调后直接预测实体标签 | 强大泛化能力,支持多任务 |
| RoBERTa | 优化BERT训练策略(更大批次、更多数据) | 性能优于BERT | |
| BioBERT/SciBERT | 在生物医学/科学文本上继续预训练BERT | 领域适配性强 | |
| ELECTRA | 用生成器-判别器架构替代MLM,提升训练效率 | 效率高,小模型表现好 | |
| 少样本/零样本学习 | Prompt-Tuning + BERT | 将NER任务重构为文本生成(如填空式提示) | 适应少量标注数据 |
| 原型网络 | 基于样本学习实体类别的原型表示 | 无需大量标注 | |
| 大模型应用 | GPT-3/4 | 通过上下文学习(in-context learning)生成实体 | 无需微调,灵活性强 |
4.NER--代码实践
BERT(Bidirectional Encoder Representations from Transformers)是一个预训练的深度学习模型,在多种 NLP 任务中取得了优异的性能。通过微调(Fine-tuning)BERT,我们可以非常有效地完成 NER 任务。
from transformers import BertTokenizer, BertForTokenClassification
from transformers import pipeline
# 加载预训练的 BERT 模型和分词器
tokenizer = BertTokenizer.from_pretrained('dbmdz/bert-large-cased-finetuned-conll03-english')
model = BertForTokenClassification.from_pretrained('dbmdz/bert-large-cased-finetuned-conll03-english')
# 创建 NER pipeline
nlp_ner = pipeline("ner", model=model, tokenizer=tokenizer)
# 示例文本
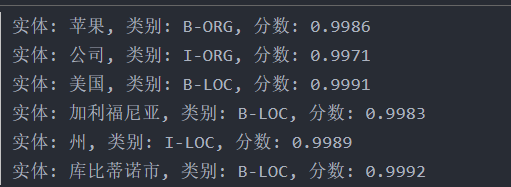
text = "苹果公司总部位于美国加利福尼亚州的库比蒂诺市。"
# 进行命名实体识别
ner_results = nlp_ner(text)
# 输出识别结果
for entity in ner_results:
print(f"实体: {entity['word']}, 类别: {entity['entity']}, 分数: {entity['score']:.4f}")
如果https://huggingface.co/models连不上,可以直接下载模型:
dbmdz/bert-large-cased-finetuned-conll03-english at main

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)