通义千问凭借“门控注意力”斩获 NeurIPS 最佳论文奖!详解Gated Attention原理
此外团队还进一步发现了门控机制能消除注意力池(Attention Sink)和巨量激活(Massive Activation)等现象,提高了模型的训练稳定性,极大程度减少了训练过程中的损失波动(loss spike)。得益于门控机制对注意力的精细控制,模型在长度外推上相比基线得到了显著的提升。本文的成果耗费大量工作,只有利用工业规模的计算资源才能完成,而论文团队直接分享了他们的研究成果,这将增进社
来源:通义千问Qwen
刚刚,人工智能领域顶级会议 NeurIPS 2025公布了论文奖,我们关于 Gated Attention 的成果论文从全球5524篇论文中脱颖而出,斩获最佳论文奖!
“本文的主要发现易于实现,并且论文提供了大量证据支持对 LLM 架构的这种改进,我们预计这一想法将被广泛采用。本文的成果耗费大量工作,只有利用工业规模的计算资源才能完成,而论文团队直接分享了他们的研究成果,这将增进社区对大型语言模型中注意力机制的理解,尤其是在LLM领域科学成果开放共享逐渐减少的背景下,这种做法非常值得称赞。”
——NeurIPS 2025评委会

NeurIPS 获奖链接
https://blog.neurips.cc/2025/11/26/announcing-the-neurips-2025-best-paper-awards/
正文
在大语言模型持续向更大规模、更长上下文演进的过程中,训练稳定性与注意力行为的可控性日益成为关键瓶颈。门控机制的有效性已经被广泛证实,但其在注意力机制中的有效性及扩展(scaling up)的能力并未被充分讨论。在通义千问团队的论文《Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free》中,研究团队系统性地分析了门控机制对大语言模型的有效性,并通过一系列控制实验证明了门控机制的有效性来源于增强了注意力机制中的非线性与提供输入相关的稀疏性。此外团队还进一步发现了门控机制能消除注意力池(Attention Sink)和巨量激活(Massive Activation)等现象,提高了模型的训练稳定性,极大程度减少了训练过程中的损失波动(loss spike)。得益于门控机制对注意力的精细控制,模型在长度外推上相比基线得到了显著的提升。团队在各个尺寸、架构、训练数据规模上验证了方法的有效性,并最终成功运用到了 Qwen3-Next 模型中。
论文链接:
https://openreview.net/forum?id=1b7whO4SfY
代码链接:
https://github.com/qiuzh20/gated_attention
门控并非新概念
但在注意力中被低估影响
门控并非新概念。从 LSTM 中的遗忘门,到现代 FFN 中的 SwiGLU,再到 Mamba 等状态空间模型,门控始终扮演着调节信息流、增强非线性表达的角色。近年来,研究者也尝试将门控引入注意力机制——AlphaFold2、Forgetting Transformer 等工作都在 Softmax 注意力输出端加入了门控。然而,这些尝试大多将其作为整体架构的一部分,缺乏对门控本身作用的系统解耦。
千问团队通过在 1.7B 密集模型与 15B 混合专家模型(MoE)上训练超过 3.5 万亿 token,并对比 30 余组控制实验,首次清晰回答了三个关键问题:如何在注意力中使用门控形式最有效?它为何有效?如何能在大模型中更好使用该机制?
SDPA 输出门控
最优实践

实验发现,在 Scaled Dot-Product Attention(SDPA)输出后(即加权 Value 之后、输出映射之前)添加一个头专属、逐元素、Sigmoid、乘性门控,是提升模型性能最有效的方式。
该门控的数学形式为:
其中
是 SDPA 的输出(即
),
是当前 token 的经过注意力层 pre-norm 后的隐藏状态(用于生成门控分数),
是可学习参数,
为 Sigmoid 激活函数,
表示逐元素相乘。这一设计使门控分数依赖于当前查询 token(query-dependent),从而实现动态信息过滤。
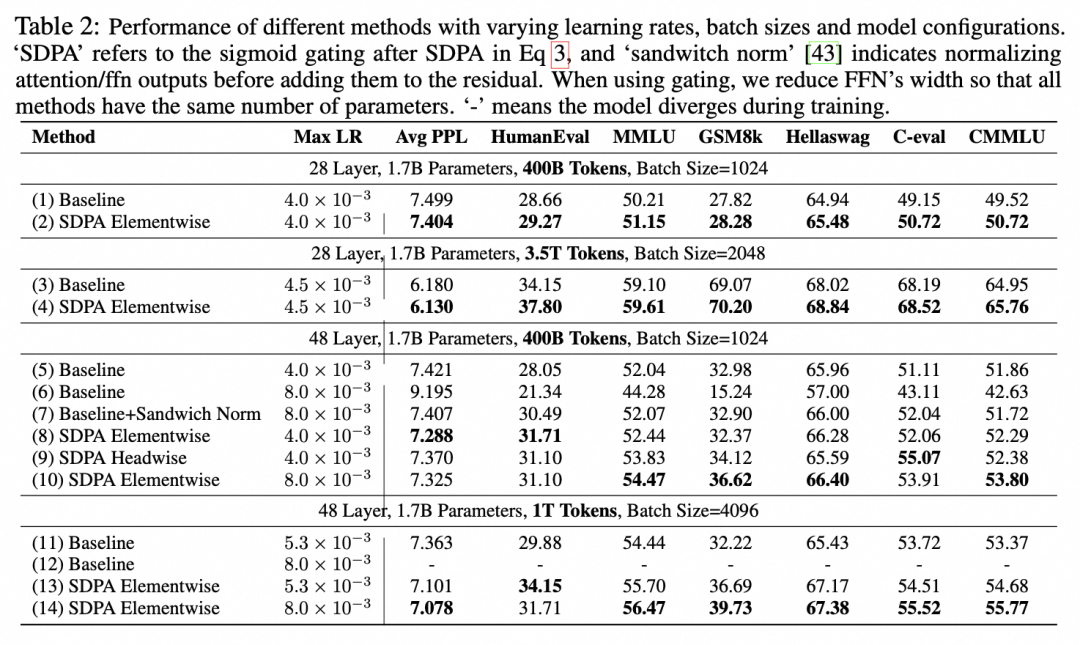
该改动仅引入额外1%参数,却能稳定带来 0.2 以上的困惑度下降和 1–2 个点的 MMLU/Hellaswag 等评测提升。更重要的是,它显著增强了训练稳定性:在 1.7B 模型上使用 8e-3 的学习率时,基线模型严重发散,而门控模型仍能收敛且性能更优。
这表明门控不仅提升性能,还为更大规模训练打开了超参空间。引入非线性
突破注意力的低秩瓶颈
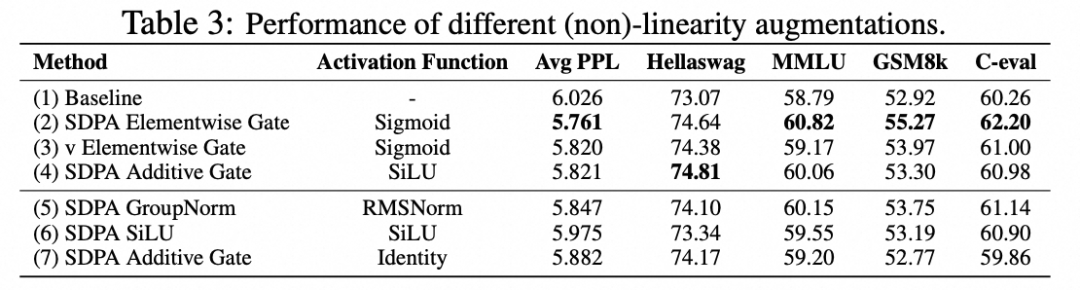
在标准多头注意力中,Value 投影 与输出投影 构成连续两层线性变换。对于第 个注意力头,第 个 token 查询第 tokens 的输出可表示为:
其中
是注意力分数,
是第
个 token 的输入。由于头维度
,
本质上是一个低秩线性映射,严重限制了模型的表达能力。
门控机制在 与 之间引入了非线性函数,等价于:
-
G2(Value 输出门控):
-
G1(SDPA 输出门控):
我们还发现在 G1 和 G2 位置添加 Layernorm 等方法同样能带来相对基线的提升,这进一步证明了我们的猜想。然而,虽然在 G1 和 G2 位置使用门控均能提升表达能力,但 G1 效果更优——这引出了第二个关键机制。
输入相关的稀疏性
动态过滤无关上下文

分析显示,SDPA 输出门控的平均门控值仅为 0.116,且分布高度集中在 0 附近,表明其具有强稀疏性。更重要的是,该门控于当前查询 token 的隐藏状态计算,因此是查询依赖的(query-dependent)——模型能动态判断“哪些历史上下文对当前 token 无关”,并主动抑制其贡献。
相比之下,Value 层门控(G2)基于历史 token 的状态计算,无法感知当前查询意图,其门控值更高(0.221),稀疏性更弱,性能也相应较差。若强制使用非稀疏门控(如将 Sigmoid 输出限制在 [0.5, 1.0] 区间),或采用输入无关的可学习常数门控,性能增益将大幅减弱,退化到仅有增强非线性带来的提升。这进一步证明:有效的门控必须是稀疏且由当前 token 驱动的。

消除“注意力池”与“巨量激活”
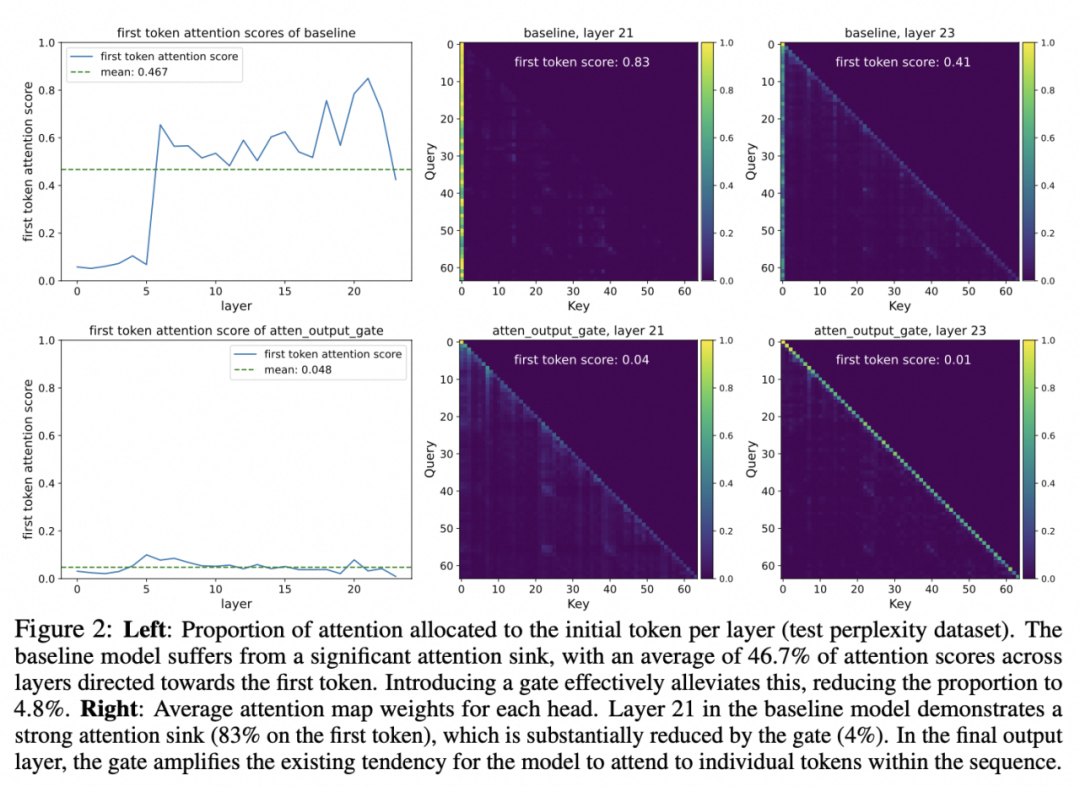
我们进一步分析模型内部的状态发现,SDPA 输出门控还解决了两个长期存在的问题:
-
注意力池(Attention Sink):在标准 LLM 中,首 token 平均占据 46.7% 的注意力分数,并对应着巨大的 logits 数值,容易导致训练不稳定;
-
巨量激活(Massive Activation):早期 FFN 层输出的隐藏状态数值常超过 1000,很容易在 BF16 等低精度训练中引发数值误差,影响训练稳定与低精度部署。
门控注意力将首 token 的注意力占比降至 4.8%,同时将最大激活值从 1053 降至 94。值得注意的是,Value 层门控虽能抑制巨量激活,却无法消除注意力池,说明巨量激活并不是注意力池的充分要条件。只有通过查询相关的稀疏门控,才能同时根除这两个现象。
其背后的直觉是:注意力池本质上是一种“被动稀释”机制——通过将大量注意力分配给首 token,来压低其他无关 token 的分数;而门控则是一种“主动过滤”机制——直接将无关上下文的贡献置零,因此无需依赖固定的 sink token。
长上下文泛化
无需重训 性能跃升
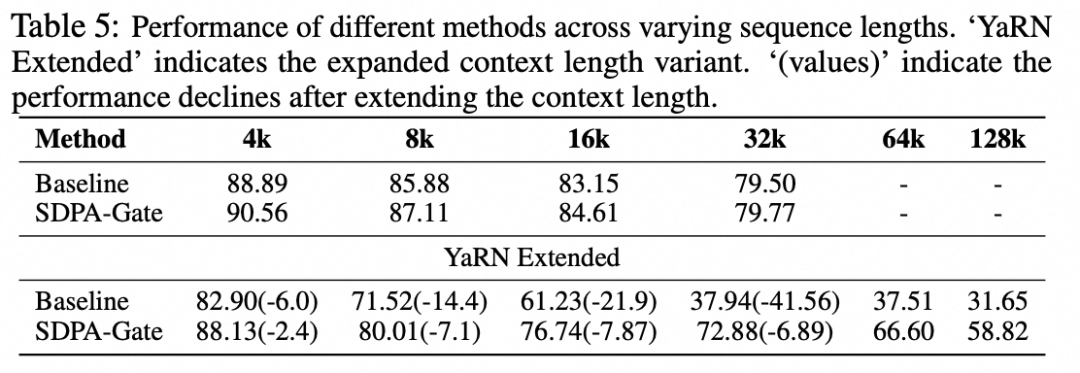
得益于“无注意力池”的特性,门控模型在长度外推任务中表现卓越。在使用 YaRN 将上下文从 32K 扩展至 128K 的实验中,基线模型在 128K 长度下的 RULER 得分仅为 31.7,而门控模型达到 58.8,领先近 27 个点。一种可能的解释是,基线模型依赖固定的注意力池来调节 Softmax 分母,当上下文长度变化时,这种静态机制难以适应;而门控模型通过动态门控分数调节信息流,具备更强的泛化能力,无需重训即可稳健处理超长序列。
工程建议与落地实践
为最大化收益,我们推荐以下配置:
-
位置:SDPA 输出后、输出映射前;
-
形式:每个注意力头独立、逐元素、Sigmoid激活函数、乘性门控;
-
训练:可适度提高学习率,以充分利用其带来的稳定性增益;
-
兼容性:适用于 Dense、MoE、GQA 等各种架构。
该方案已在 Qwen3-Next 系列模型中落地,并成为其性能与鲁棒性的关键技术支撑。我们建议在预训练阶段即引入该机制,因其对训练动态的影响在继续训练(continue pretraining)中难以体现。

为促进社区研究,团队已开源相关代码 (https://github.com/qiuzh20/gated_attention)、实验性的“无注意力池”模型 (https://huggingface.co/QwQZh/gated_attention) 与产品级的模型 Qwen3-Next (https://qwen.ai/blog?id=qwen3-next)。我们相信,对门控机制、模型机制等的深入理解,不仅为 LLM 架构设计提供了新思路,也为构建更稳定、更高效、更可控的大模型奠定了基础。
 ·················END·················
·················END·················
分享
收藏
点赞
在看

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)