开源项目介绍:Liger-Kernel 用于 LLM 训练的高效 Triton 内核
Liger Kernel 是专为 LLM 训练设计的 Triton 内核集合。它可以有效地提高 20% 的多 GPU 训练吞吐量,并减少 60% 的内存使用。我们已经实施了 Hugging Face 适配,以及更多即将推出的功能。该内核可与 Flash Attention、PyTorch FSDP 和 Microsoft DeepSpeed 配合使用,开箱即用。我们欢迎社区的贡献,以收集用于 LL
项目地址:https://github.com/linkedin/Liger-Kernel
项目依赖:torch、triton
环境要求:torch >= 2.1.2、triton >= 2.3.0
Liger Kernel 是专为 LLM 训练设计的 Triton 内核集合。它可以有效地提高 20% 的多 GPU 训练吞吐量,并减少 60% 的内存使用。我们已经实施了 Hugging Face 适配,以及更多即将推出的功能。该内核可与 Flash Attention、PyTorch FSDP 和 Microsoft DeepSpeed 配合使用,开箱即用。我们欢迎社区的贡献,以收集用于 LLM 训练的最佳内核。RMSNorm、RoPE、SwiGLU、CrossEntropy、FusedLinearCrossEntropy
我们还添加了优化的 Post-Training 内核,可为对齐和蒸馏任务节省高达 80% 的内存。我们支持 DPO、CPO、ORPO、SimPO、KTO、JSD 等损失。了解我们如何优化内存。
1、简介
如果是windows环境安装,确认torch符合、triton-windows安装后,可用以下命令安装(不要更改依赖库)
pip install liger-kernel --no-dependencies
如果使用以下命令,则会按照项目版本升级依赖库
pip install liger-kernel
主要特点
- 易用性:只需用一行代码修补你的 Hugging Face 模型,或者使用我们的 Liger Kernel 模块编写你自己的模型。
- 省时省内存:本着与 Flash-Attn 相同的精神,但适用于 RMSNorm、RoPE、SwiGLU 和 CrossEntropy!通过内核融合、就地替换和分块技术,将多 GPU 训练吞吐量提高 20%,并将内存使用量降低 60%。
- 精准:计算结果是严格等效的 - 没有近似值!前向和后向传递均通过严格的单元测试实现,并针对没有 Liger 内核的训练运行进行收敛测试,以确保准确性。
- 轻:Liger Kernel 的依赖项最少,只需要 Torch 和 Triton,不需要额外的库!告别依赖性头痛!
- 支持多 GPU:与多 GPU 设置(PyTorch FSDP、DeepSpeed、DDP 等)兼容。
- Trainer 框架集成:Axolotl、LLaMa-Factory、SFTTrainer、Hugging Face Trainer、SWIFT、oumi
2、使用效果
可以看到基于liger-kernel优化算子后,可以降低LLaMa 3-8B模型40%的内存占用,并加速20%左右。
按照官网的说法只需一行代码(替换模型加载方式),Liger Kernel 就可以将吞吐量提高 20% 以上,并将内存使用量降低 60%,从而实现更长的上下文长度、更大的批处理大小和海量词汇。
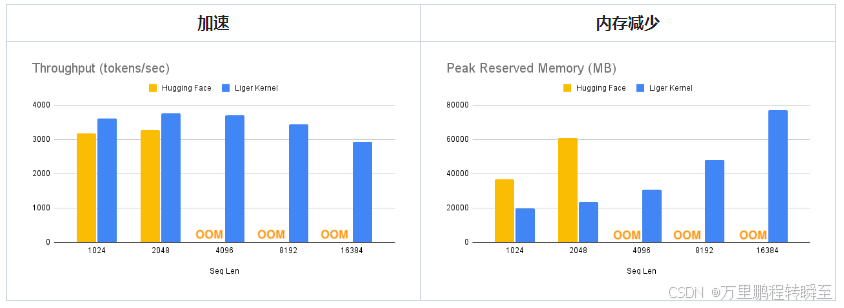 基准测试条件:
基准测试条件:LLaMA 3-8B,批量大小 = 8,数据类型 =bf16,优化器 = AdamW,梯度检查点 = True,分布式策略 = FSDP1 ,在 8 个 A100 上。
Hugging Face 模型在 4K 上下文长度处开始 OOM,而 Hugging Face + Liger Kernel 则可扩展到 16K。
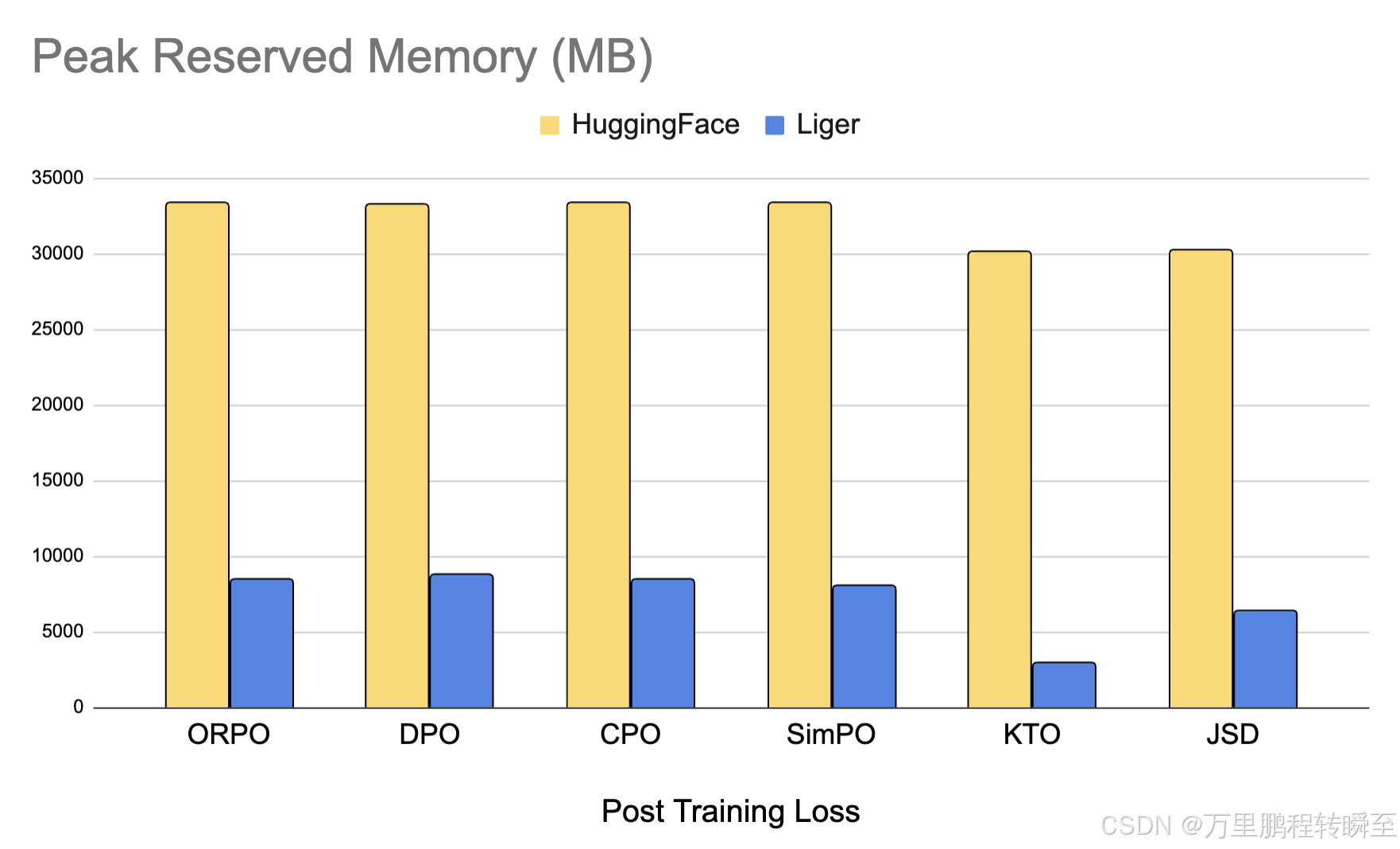
我们提供优化的后训练内核,如 DPO、ORPO、SimPO 等,可将内存使用量减少高达 80%。您可以轻松地将它们用作 python 模块。
from liger_kernel.chunked_loss import LigerFusedLinearORPOLoss
orpo_loss = LigerFusedLinearORPOLoss()
y = orpo_loss(lm_head.weight, x, target)
3、基本用法
3.1 AutoLigerKernelForCausalLM
基于AutoLigerKernelForCausalLM加载模型可以自动实现算子的替换
from liger_kernel.transformers import AutoLigerKernelForCausalLM
# This AutoModel wrapper class automatically monkey-patches the
# model with the optimized Liger kernels if the model is supported.
model = AutoLigerKernelForCausalLM.from_pretrained("path/to/some/model")
以上操作可能由于liger_kernel与transformers 的版本兼容关系,对部分模型加载可能会失败
3.2 apply_liger_kernel_to_llama
这里关于1b的步骤是可选的,主要是自行指定哪些算子需要进行转换
import transformers
from liger_kernel.transformers import apply_liger_kernel_to_llama
# 1a. Adding this line automatically monkey-patches the model with the optimized Liger kernels
apply_liger_kernel_to_llama()
# 1b. You could alternatively specify exactly which kernels are applied
apply_liger_kernel_to_llama(
rope=True,
swiglu=True,
cross_entropy=True,
fused_linear_cross_entropy=False,
rms_norm=False
)
# 2. Instantiate patched model
model = transformers.AutoModelForCausalLM("path/to/llama/model")
3.3 Linear层与CrossEntropyLoss合并
基于liger_kernel提供的算子合并层:LigerFusedLinearCrossEntropyLoss,可以将linear + cross entropy按照 chunk-by-chunk 的方式进行合并计算,从而实现内存占用降低。
from liger_kernel.transformers import LigerFusedLinearCrossEntropyLoss
import torch.nn as nn
import torch
model = nn.Linear(128, 256).cuda()
# fuses linear + cross entropy layers together and performs chunk-by-chunk computation to reduce memory
loss_fn = LigerFusedLinearCrossEntropyLoss()
input = torch.randn(4, 128, requires_grad=True, device="cuda")
target = torch.randint(256, (4, ), device="cuda")
loss = loss_fn(model.weight, input, target)
loss.backward()
4、API
4.1 High-level APIs
AutoModel
| AutoModel Variant | API |
|---|---|
| AutoModelForCausalLM | liger_kernel.transformers.AutoLigerKernelForCausalLM |
Patching
| Model | API | Supported Operations |
|---|---|---|
| LLaMA 2 & 3 | liger_kernel.transformers.apply_liger_kernel_to_llama |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| LLaMA 3.2-Vision | liger_kernel.transformers.apply_liger_kernel_to_mllama |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Mistral | liger_kernel.transformers.apply_liger_kernel_to_mistral |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Mixtral | liger_kernel.transformers.apply_liger_kernel_to_mixtral |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Gemma1 | liger_kernel.transformers.apply_liger_kernel_to_gemma |
RoPE, RMSNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Gemma2 | liger_kernel.transformers.apply_liger_kernel_to_gemma2 |
RoPE, RMSNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Paligemma, Paligemma2, & Paligemma2 Mix | liger_kernel.transformers.apply_liger_kernel_to_paligemma |
LayerNorm, RoPE, RMSNorm, GeGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Qwen2, Qwen2.5, & QwQ | liger_kernel.transformers.apply_liger_kernel_to_qwen2 |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Qwen2-VL, & QVQ | liger_kernel.transformers.apply_liger_kernel_to_qwen2_vl |
RMSNorm, LayerNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Qwen2.5-VL | liger_kernel.transformers.apply_liger_kernel_to_qwen2_5_vl |
RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Phi3 & Phi3.5 | liger_kernel.transformers.apply_liger_kernel_to_phi3 |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
| Granite 3.0 & 3.1 | liger_kernel.transformers.apply_liger_kernel_to_granite |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss |
| OLMo2 | liger_kernel.transformers.apply_liger_kernel_to_olmo2 |
RoPE, RMSNorm, SwiGLU, CrossEntropyLoss, FusedLinearCrossEntropy |
4.2 Low-level APIs
Fused Linearkernels combine linear layers with losses, reducing memory usage by up to 80% - ideal for HBM-constrained workloads.- Other kernels use fusion and in-place techniques for memory and performance optimization.
Model Kernels
| Kernel | API |
|---|---|
| RMSNorm | liger_kernel.transformers.LigerRMSNorm |
| LayerNorm | liger_kernel.transformers.LigerLayerNorm |
| RoPE | liger_kernel.transformers.liger_rotary_pos_emb |
| SwiGLU | liger_kernel.transformers.LigerSwiGLUMLP |
| GeGLU | liger_kernel.transformers.LigerGEGLUMLP |
| CrossEntropy | liger_kernel.transformers.LigerCrossEntropyLoss |
| Fused Linear CrossEntropy | liger_kernel.transformers.LigerFusedLinearCrossEntropyLoss |
Alignment Kernels
| Kernel | API |
|---|---|
| Fused Linear CPO Loss | liger_kernel.chunked_loss.LigerFusedLinearCPOLoss |
| Fused Linear DPO Loss | liger_kernel.chunked_loss.LigerFusedLinearDPOLoss |
| Fused Linear ORPO Loss | liger_kernel.chunked_loss.LigerFusedLinearORPOLoss |
| Fused Linear SimPO Loss | liger_kernel.chunked_loss.LigerFusedLinearSimPOLoss |
| Fused Linear KTO Loss | liger_kernel.chunked_loss.LigerFusedLinearKTOLoss |
Distillation Kernels
| Kernel | API |
|---|---|
| KLDivergence | liger_kernel.transformers.LigerKLDIVLoss |
| JSD | liger_kernel.transformers.LigerJSD |
| Fused Linear JSD | liger_kernel.transformers.LigerFusedLinearJSD |
| TVD | liger_kernel.transformers.LigerTVDLoss |
Experimental Kernels
| Kernel | API |
|---|---|
| Embedding | liger_kernel.transformers.experimental.LigerEmbedding |
| Matmul int2xint8 | liger_kernel.transformers.experimental.matmul |
5、使用案例
5.1 模型加载测试
原始模型
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
model_dir=r"F:\DMT\.cache_dir\qwen\Qwen2-VL-2B-Instruct"
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype="auto",
attn_implementation="flash_attention_2",
device_map="auto",
)

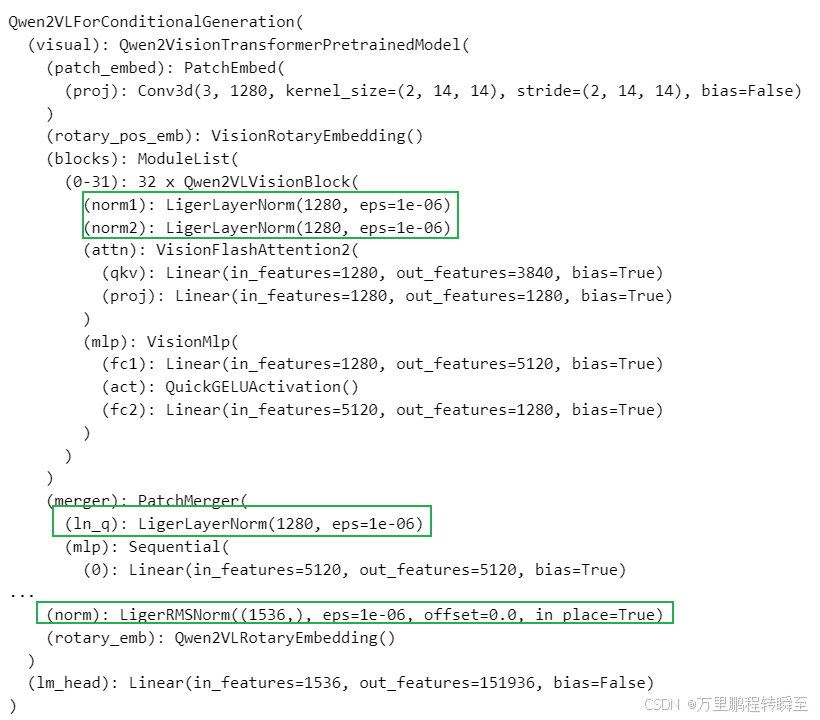
基于liger_kernel加载模型,可以发现有不少算子已经被替换为liger_kernel实现了。
from liger_kernel.transformers import apply_liger_kernel_to_qwen2_vl
# 1a. Adding this line automatically monkey-patches the model with the optimized Liger kernels
apply_liger_kernel_to_qwen2_vl()
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
model_dir=r"F:\DMT\.cache_dir\qwen\Qwen2-VL-2B-Instruct"
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype="auto",
attn_implementation="flash_attention_2",
device_map="auto",
)
5.2 ms-swift训练
在ms-swift中已经嵌入了Liger-Kernel的支持
在原来的训练命令中加入 --use_liger参数即可使用Liger-Kernel

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)