
DeepSeek-V3.2 突袭发布:推理逼近 GPT-5,Agent 能力登顶开源模型之巅!
DeepSeek-V3.2 的发布,标志着开源模型首次在 Agent 泛化能力上逼近甚至局部超越闭源顶级模型。它不再只是“参数竞赛”的产物,而是系统工程、算法创新、训练范式三位一体的结晶。DeepSeek-R2,你到底什么时候来?!
·
前几天,DeepSeek 毫无预兆 地放出两枚“核弹”:
| 模型 | 定位 | 关键能力 | 适用场景 |
|---|---|---|---|
| DeepSeek-V3.2 | 平衡实用型 | 推理≈GPT-5,首个“思考融入工具调用”的开源模型 | 日常问答、Agent任务、工程落地 |
| DeepSeek-V3.2-Speciale | 极致推理型 | 数学/编程/逻辑 → 媲美 Gemini-3.0-Pro | IMO/ICPC/IOI 级竞赛、科研证明 |
💡 划重点:
- V3.2 在 Agent 工具调用评测 中登顶开源模型榜首
- Speciale 模型斩获 IMO 2025、CMO 2025、ICPC World Finals 金牌(ICPC 人类第二,IOI 人类第十)
- 不针对测试集专项训练,全靠泛化能力硬刚!
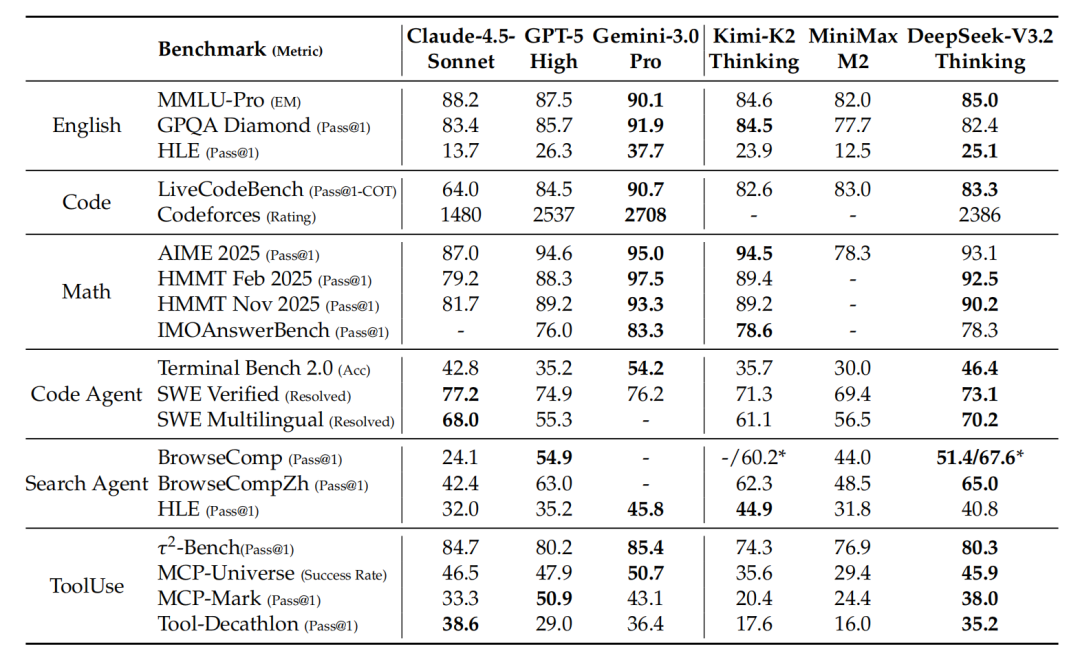
📊 一、性能实测:谁才是真正的开源之光?
✅ Agent 工具调用能力(开源模型 TOP 榜)
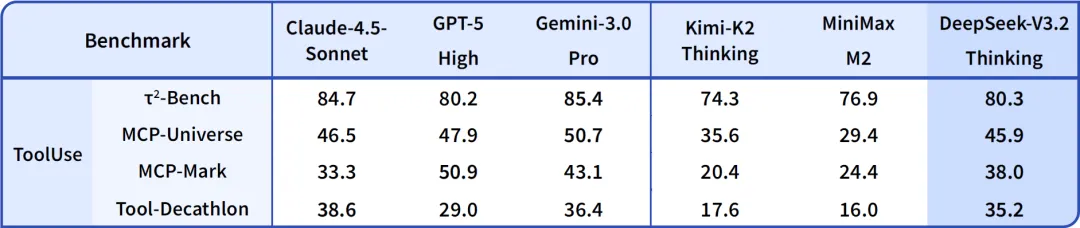
🔍 数据说明:
- 测试集:MCP-Universe / Tool-Decathlon / SWE-Bench Verified / Terminal Bench 2.0
- DeepSeek-V3.2 未针对任何工具做专项微调,纯靠泛化能力
- 相比 Kimi-K2-Thinking:输出长度缩短 60%+,响应更快
✅ 编程与数学竞赛表现
| 任务 | DeepSeek-V3.2-Speciale | 人类金牌线 | 达标情况 |
|---|---|---|---|
| ICPC 2025 | 9 题 AC | 8 题 | ✅ 超越人类金牌 |
| IOI 2025 | 338/600 分 | 320 分 | ✅ 排名全人类第 10 |
| IMO 2025 | 几何/数论全对 | 金牌线 29/42 | ✅ 金牌水平 |
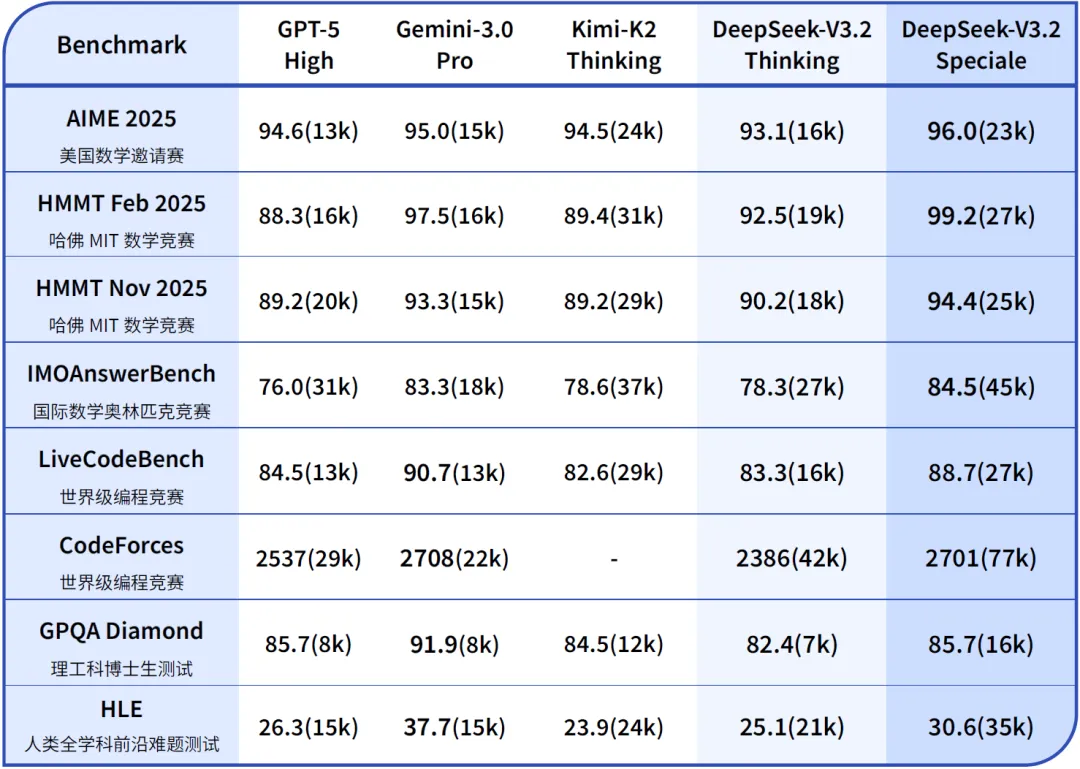
⚠️ 注意:Speciale 不支持工具调用,仅限研究/API调用,日常对话体验不如 V3.2。
⚙️ 二、核心技术突破:三大创新引擎驱动性能飞跃
1️⃣ 🧠 DSA 稀疏注意力机制 —— 长文本不再“烧钱”
传统注意力复杂度:O(L²) → DSA 降至 O(L·k)(k ≪ L)
🔬 DSA 双组件架构:
| 组件 | 作用 | 关键设计 |
|---|---|---|
| Lightning Indexer(闪电索引器) | 快速计算 query-token 相关性 | 使用 ReLU 提升吞吐,FP8 友好 |
| Fine-grained Token Selection | 动态选择 top-k 最相关 KV 对 | 每 query 仅保留 2048 个 token |
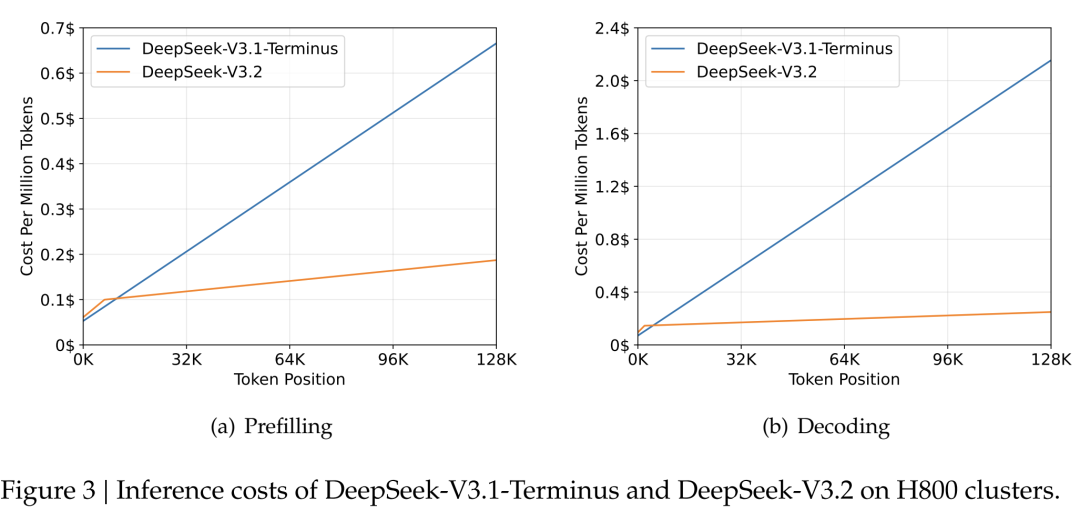
💰 成本实测(H800 集群,128K 上下文):
| 阶段 | V3.1-Terminus | V3.2 (DSA) | 降幅 |
|---|---|---|---|
| Prefill(每百万 token) | $0.70 | $0.20 | 71% ↓ |
| Decode(每百万 token) | $2.40 | $0.80 | 67% ↓ |
✅ 两阶段训练策略:
- Dense Warm-up(1000 step):仅训练 Indexer 对齐主注意力
- Sparse Finetune(15,000 step):引入稀疏,总 tokens:943.7B
2️⃣ 🚀 RL 训练算力超预训练 10% —— 开源界首次“重后训”
📌 论文原话:
“开源模型 post-training 算力投入严重不足,是其难以攻克高难任务的主因。”
🔧 GRPO 算法三大改进:
| 问题 | 改进方案 | 效果 |
|---|---|---|
| KL 估计偏差 | 无偏 KL 估计器(修正 K3 估计) | 消除梯度爆炸 |
| Off-policy 偏移 | 离线序列掩码(KL > 阈值则屏蔽) | 提升更新稳定性 |
| MoE 路由抖动 | Keep Routing(冻结推理时专家路径) | 训练/推理一致性↑ |
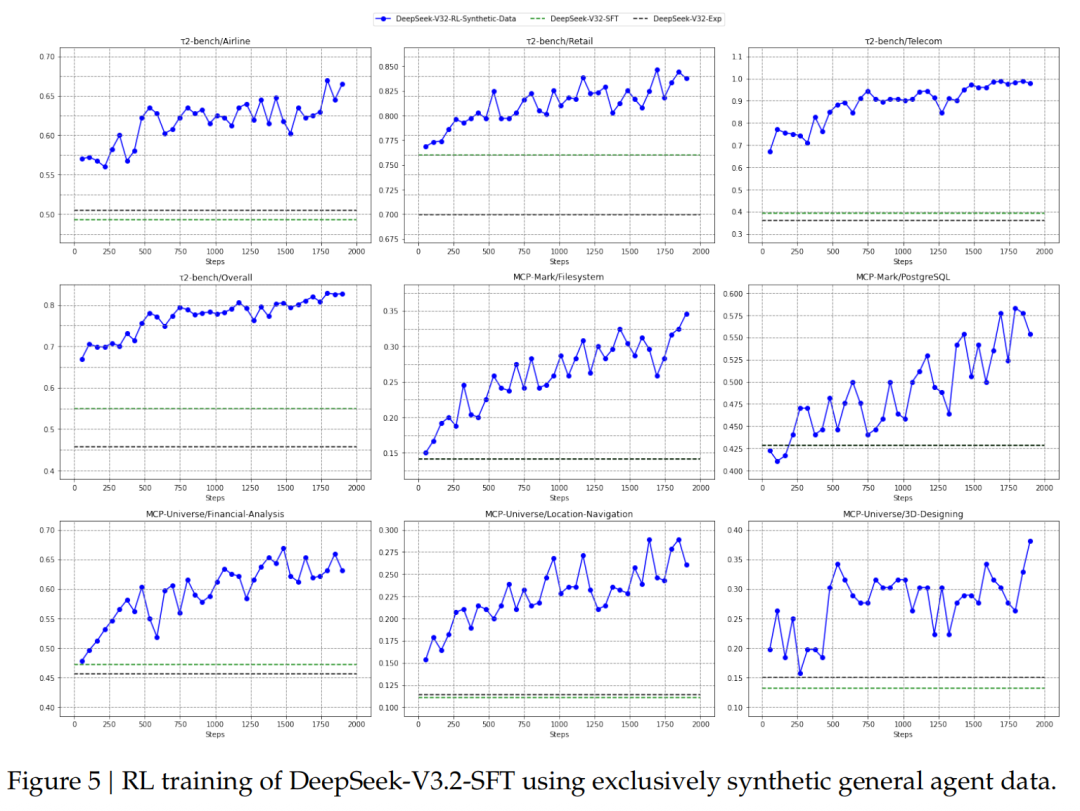
🧪 专家蒸馏训练管线:
3️⃣ 🤖 Agent 能力三大突破 —— 真·思考型工具调用
✅ ① 思考-工具融合设计(DeepSeek首创!)
- 支持 思考模式 / 非思考模式 双工具调用
- 系统 prompt 引导模型:
“先推理 → 再决定是否调工具 → 工具结果反哺推理”
✅ ② 上下文冷启动优化
| 策略 | 旧模型(如 R1) | V3.2 |
|---|---|---|
| 新用户消息到来 | 丢弃全部历史(含推理) | ✅ 仅丢推理,保留工具调用历史 |
| 工具返回结果 | 重新生成完整推理链 | ✅ 增量推理,复用已有思维 |
✅ ③ 自动环境合成 Pipeline
- 生成 1,827 个任务环境 + 85,000+ 复杂指令
- 示例:3 天旅行规划 Agent
- 约束:城市不重复、酒店≤¥500、餐厅预算动态联动景点等级
- 验证:方案易验、生成难 → 完美适配 RL 训练

✅ 代码 & 搜索 Agent 训练数据构建
| 类型 | 数据来源 | 环境规模 |
|---|---|---|
| Code Agent | GitHub Issue-PR 对 | 数万可执行环境(Py/Java/JS) |
| Search Agent | Web 长尾实体 + 多 Agent 生成 | 自动构建 QA 对 + 验证 |
📈 开源模型 SOTA 表现:
| Benchmark | DeepSeek-V3.2 | 当前开源 SOTA |
|---|---|---|
| SWE-Bench Verified | 73.1% | 58.2% |
| Terminal Bench 2.0 | 46.4% | 32.1% |
| MCP-Universe | 81.7 | 72.3 |
🚧 三、当前局限 & 未来方向
| 问题 | 现状 | 改进计划 |
|---|---|---|
| 世界知识广度 | FLOPs 总量少于闭源模型 | V3.3 增加预训练 tokens |
| Token 效率 | 输出轨迹较长 → 成本高 | 优化推理压缩 + 提示剪枝 |
| 多模态缺失 | 纯文本模型 | 多模态版本已在规划中 |
🎯 DeepSeek 团队坦承:
“这些是明确的技术 debt,将在后续版本中系统性解决。”
🌐 四、如何体验?
| 模型 | 访问方式 | 状态 |
|---|---|---|
| DeepSeek-V3.2 | Web / App(已全量上线) | ✅ 正式版 |
| DeepSeek-V3.2-Speciale | 临时 API(需申请) | 🔬 研究专用 |
💬 结语:开源模型的新里程碑
DeepSeek-V3.2 的发布,标志着 开源模型首次在 Agent 泛化能力上逼近甚至局部超越闭源顶级模型。
它不再只是“参数竞赛”的产物,而是系统工程、算法创新、训练范式三位一体的结晶。
📣 最后灵魂拷问:
DeepSeek-R2,你到底什么时候来?!
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)