使用cherry studio 构建知识库,解析模型、调用工具和参数
使用工具,搭建知识库,需要进行模型Api 和 知识库相关参数的设置,本无对调用模型和调整参数进行解析。
·
使用cherry studio构建知识库,解析模型、调用工具和参数
使用 cherry-studio 工具,搭建知识库,需要进行模型Api 和 知识库相关参数的设置,本无对调用模型和调整参数进行解析
调用模型和工具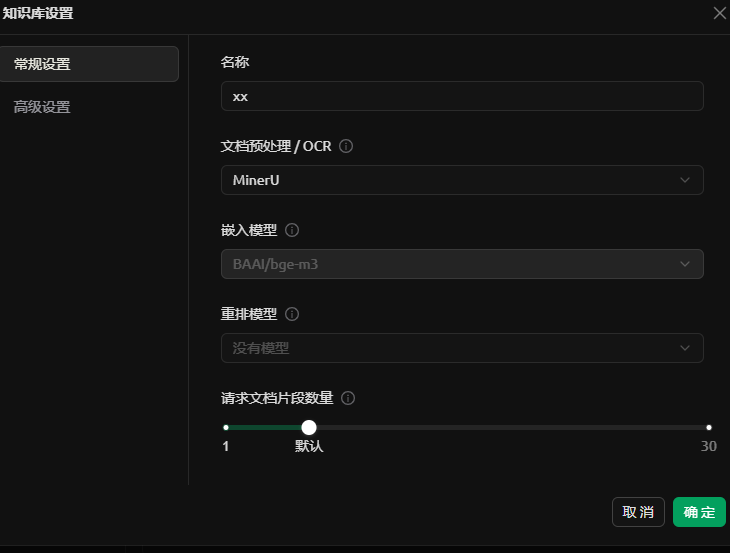
设置参数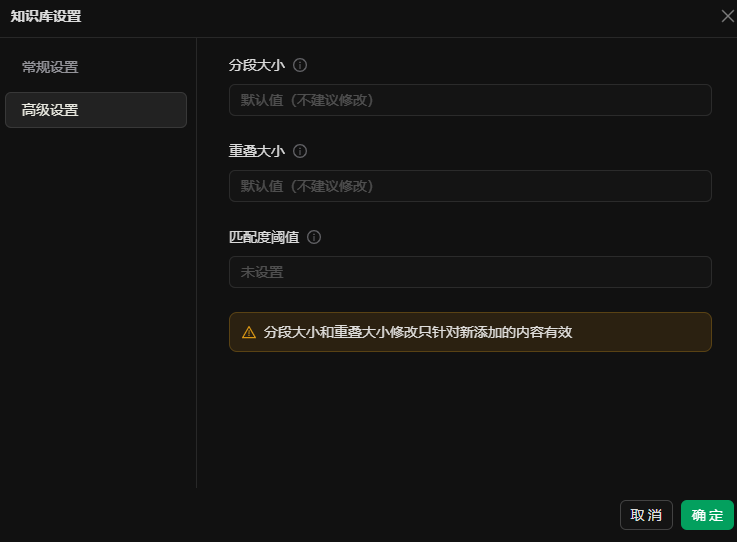
一、文档预处理
- 光学字符识别(OCR):将扫描版文档、图像中的文字转换为机器可读文本,解决非结构化数据(如PDF图片、手写稿)的文本提取问题
- 解析(MinerU,限时申请free api-key):将PDF/PPT/DOC等文档转换为结构化的文本数据(Markdown/JSON),保持多模态元素的布局
嵌入模型(Embedding Model)
作用:将文本映射为稠密向量,用于相似性计算与检索优化。
价值:精准排序 / 业务融合
使用方式:cherry studio + API云服务
重排模型(Reranker Model)
作用:对初步检索结果重新排序,优化上下文相关性与多样性
价值:语义捕捉 / 检索优化
使用方式:cherry studio + API云服务
二、分块策略参数
控制文档切片方式,影响检索精度与计算效率。
1. 请求文档片数量(Top-K Chunks)
含义:检索时返回的候选片段数量,输入重排模型前的粗筛步骤。
过高:增加重排计算负担,延迟上升。
过低:可能遗漏相关片段。
建议范围:50–200(根据检索系统吞吐量调整)
2. 分段大小(Chunk Size)
定义:单一片段的最大长度(按字符或token计)。
建议值:自然段落转换成token的数量(考虑多模态模型中的特殊数据token量,比如图像)
3. 重叠大小(Overlap Size)
作用:避免切片时割裂关键信息(如跨段落的术语)。
经验值:分段大小的10–20%(如512 tokens分段,重叠64–128 tokens)。
三 、匹配度阈值(Similarity Threshold)
作用:过滤低相关性片段,仅保留分数高于阈值的候选集进入重排阶段。
经验值:动态调整(通常0.6–0.8)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)