MCP 调用成本高到离谱?新机制让 token 成本降低 98%!
研究团队提出MCP-Zero框架,解决大语言模型工具调用痛点。传统方法需加载全部工具导致高token消耗和错误回复,而MCP-Zero通过主动工具请求、分层向量路由和迭代式调用,实现了按需工具检索和多轮闭环调用。实验表明,该系统在保持精度的同时降低98%的token开销,并构建了包含308个服务器、2797个工具的标准化数据集。该框架赋予大模型主动决策能力,支持跨领域工具组合和错误恢复,重新定义了
导读
大语言模型在处理复杂任务时,往往需要借助外部工具,而函数调用机制正是连接两者的关键通道。通过模型上下文协议(Model Context Protocol,MCP),LLM 能够轻松调用各类工具,实现更加灵活的问题求解。
不过,当前的 MCP 调用方式存在一个致命痛点:所有工具都会被一次性加载到系统提示中。这不仅带来巨大的 token 消耗,还容易导致模型产生错误回复。
为了解决这个问题,来自厦门大学与中科大的研究团队提出了两项关键改进方向:
-
• 一是引入按需调用机制,仅在必要时提供相关工具清单,降低 token 成本;
-
• 二是支持闭环式多轮调用流程,让模型能够阶段性调用不同工具,逐步完成子任务;同时在调用失败时,还能尝试其他备选方案或依靠自身知识储备重试。
基于这一思路,团队提出了全新框架 —— MCP-Zero[1]:一个主动式代理系统,支持 LLM 主动判断调用时机,自主检索所需工具,从零构建专用工具链。
MCP-Zero 的三大核心模块包括:
-
1. 主动工具请求机制:通过结构化
<tool_assistant>代码块,模型可清晰表达对特定服务器与任务的工具需求; -
2. 分层向量路由系统:结合语义匹配技术,先筛选候选服务器,再在服务器内对工具优先级排序,输出最优结果;
-
3. 迭代式调用流程:每轮只返回少量相关工具,降低上下文成本,支持多轮调用与跨领域工具组合;同时具备错误恢复能力,可自动调整请求并重新发起。
此外,研究者还整理并筛选了官方 MCP[2] 代码库中的所有 MCP servers,最终构建出包含 308 个服务器、2797 个工具 的 MCP-tools 数据集,并统一转换为 JSON 格式,方便检索调用。
在 APIbank[3] 测试中,MCP-Zero 在精度基本持平的情况下,将 token 开销降低了 98%,显著提升了调用效率与智能性。
一味塞工具,大模型只会越用越“笨”
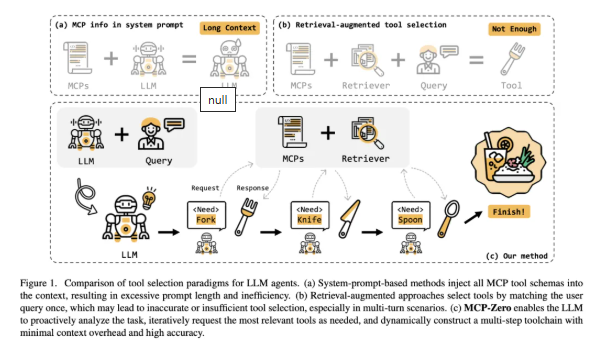
当前基于 MCP 的工具调用机制存在明显的瓶颈:它默认将全部工具信息嵌入到大模型的 system prompt 中,导致上下文负荷极高。
我们以 GitHub MCP Server[4] 为例,仅一个服务器就包含多达 26 种工具,单次调用就要消耗 超过 4600 个 tokens 的上下文资源。这种“工具全家桶式”的调用方式,不仅推高了使用成本,还严重影响了模型输出的稳定性 —— 尤其是在处理长上下文时,性能衰退的问题尤为明显。
为了减轻负担,部分工作尝试引入 基于检索的工具筛选策略,只选出少量最匹配的工具加入上下文。具体方法包括:
-
• 使用分类模型,对用户输入与工具描述进行比对;
-
• 或基于语义相似度,从工具库中挑选若干候选。
但这些方法也面临两大核心问题:
-
1. 泛化能力弱:依赖训练数据的分类器难以适应未见任务或新领域;
-
2. 语义错配风险高:用户表达和工具描述之间往往存在语言偏差,比如“查找某日数据”与“按日期检索”在表述上不同,容易造成匹配失败。
更严重的是,现有方案普遍依赖一次性、单轮匹配:即便匹配上了某个工具,也难以完成如“debug 某文件”这种复杂任务,因为它需要多个工具(修改代码、保存文件、执行命令等)协同完成。而一旦初次匹配出现错误,也几乎没有回旋余地。
本质上,这些方法都属于一种 “被动配置”式的调用逻辑。大模型只能依赖预设好的工具列表,无法主动发起工具请求,也缺乏基于任务需求动态切换工具的能力。
换句话说,当前机制并未真正发挥出大模型“理解上下文 + 动态决策”的潜力。而这正是 MCP-Zero 想要打破的局限 —— 让大模型从工具的被动接收者变成主动指挥官。
MCP-Zero 是如何破局的?
MCP-Zero 致力于释放大模型的"自主"潜能,而非将其局限于人工预设的功能边界内。
基于这一目标,研究人员从如下维度进行探索:
-
• 主动工具发现:大模型转变为"主动识别并提出所需工具"的模式,而非传统的"从既定工具库中被动选取"。
-
• 主动多轮执行:大模型能够采用分阶段调用策略,每个阶段专注解决特定子任务,这种方式更贴近实际工具应用的场景需求。同时,当工具调用或响应出现异常时,大模型具备及时识别问题的能力,并能够启动新的尝试流程。
具体地,本文方法主要分为以下五个环节:
1. 主动工具请求
首先,我们可以定义一个新的格式块,当大模型需要调用工具时输出如下一段内容:
<tool assistant>
server: ... # Platform/permission domain
tool: ... # Operation type + target
</tool assistant>在这个结构体里面,大模型分别输出对 server 和 tool 的需求描述。
与直接匹配用户请求的方式不同,大模型生成的语言表达更具规范性和精确性,与 API 文档的表述风格更为接近。这种特性使得匹配过程能够达到更高的精准度。
通过实验数据对比可以发现,这种方法的匹配准确度相较于基于用户请求的传统方式有着显著的改善(准确率从72%提升至96%)。
2. 分层向量匹配
本文采用 OpenAI text-embedding-3-large[5] 模型对文本内容进行编码处理,以提取其语义特征向量。接下来执行匹配:MCP 框架提供了服务器描述和工具描述等信息,这为我们实施分层匹配策略创造了条件。
匹配过程分为两个层次:首先是服务器层面的匹配,利用服务器的描述信息来识别相应的平台、领域和服务类型等要素。值得注意的是,MCP 框架中定义的服务器描述往往较为简洁。
为了解决这一问题,本文引入 Qwen2.5-72b-Instruct[6] 模型,对各个服务器的原始资料(主要是 ReadMe 文档)进行归纳整理,重点关注其功能特性、特色功能、使用模式等方面的信息,从而生成了服务器的概要信息,这些概要作为相对完整且详尽的描述文本参与匹配过程。在计算匹配度时,选择两种描述方式中得分较高的一种作为最终评分。
接下来进行具体工具层面的匹配,并计算工具间的相似度分数。最终评分的计算采用以下公式: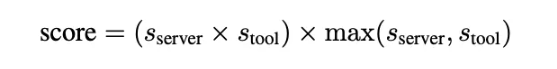
3. 主动多轮调用
大语言模型能够在执行任务的各个环节中,多次生成此类请求结构,从而完成多轮次的工具调用流程。下图展现了一个具体的调用案例:
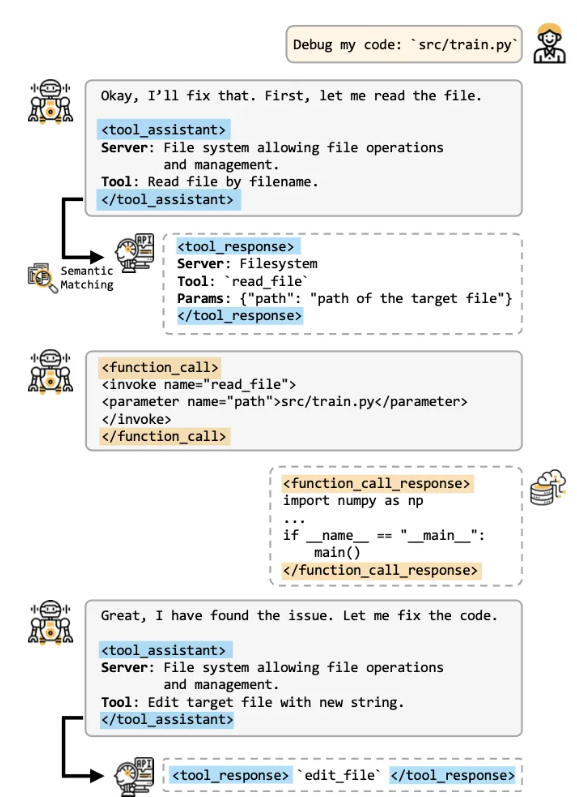
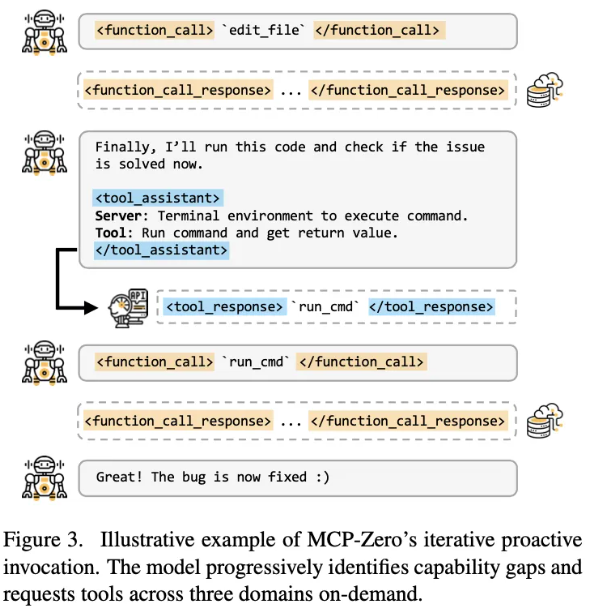
在问题求解的进程中,大语言模型依据上下文信息及当前推进状况,具备选取适当工具并执行调用的能力。若返回的工具存在不精确的情况,大语言模型根据具体的反馈结果,可以尝试调整自身的表述内容,进而重新调用工具,具有一定的容错性。
4. 理论分析验证
通过理论分析,本文验证了分层匹配方法相较于传统直接检索方式具备更优的计算复杂度。
此外,大语言模型生成的语义表示与文档描述呈现更高的相似性,具有较低的信息熵。详细的理论推导过程可参考完整论文内容。
5. 数据集的构建过程
当前缺乏专门面向 MCP 服务器和工具检索任务的标准数据集。基于这一现状,团队采集了官方 MCP servers 代码仓库中的全部现有服务器及工具相关信息。通过对各项目的 ReadMe 文档进行系统性的结构化处理,我们建立了以下统一的标准化格式:
{
"server_name": string,
"server_description": string,
"server_summary": string,
"tools":[
{
"name": string,
"description": string,
"parameter":{
"param1":"(type) description1",
"param2":"(Optional, type) description2"
}
}
]
}如上文所述,作者为 server 额外生成了 server_summary 字段,包含更详细的描述文本,以用于更好的语义匹配。【注:目前该数据集已经开源,欢迎下载】
实验结果
研究人员率先进行了"大海捞针"式的压力测试实验。该测试是检验检索性能的经典方法,具体做法是在模型的上下文环境中按照 MCP 标准格式嵌入工具,然后要求模型准确定位并找出指定位置的目标工具。
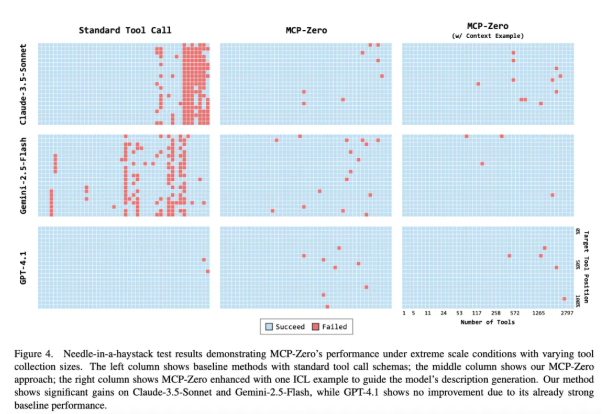
测试结果表明,广泛使用的 Claude-3.5 和 Gemini-2.5 模型在标准配置下表现不佳,频繁出现错误识别。
然而,当引入 MCP-Zero 后,这些模型的检索精确度有了显著改善。值得注意的是,GPT-4.1 模型并未从该方法中获得进一步提升,我们分析认为这可能是因为 GPT 系列模型已经针对工具调用情境下的长上下文处理进行了特别的优化调整。
本文也将平均每一次正确检索的 token开销整理成下图:
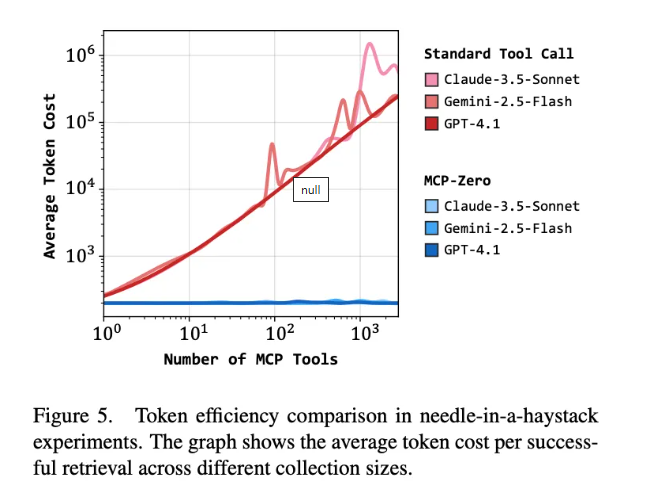
观察可知,传统方案由于要从上下文内的全部工具中筛选出适配的工具,所以其平均检索消耗与工具总量呈现线性增长关系。工具达到1k规模时,单次工具检索的消耗约为100k tokens。若模型性能不够稳定,检索成本还将进一步攀升。然而,MCP-Zero方案的检索成本为常数,不会因工具数量增加而产生token消耗的增长。因此,面对全数据集约3k工具的应用场景,仍能实现精确检索,且无需消耗大量上下文token。
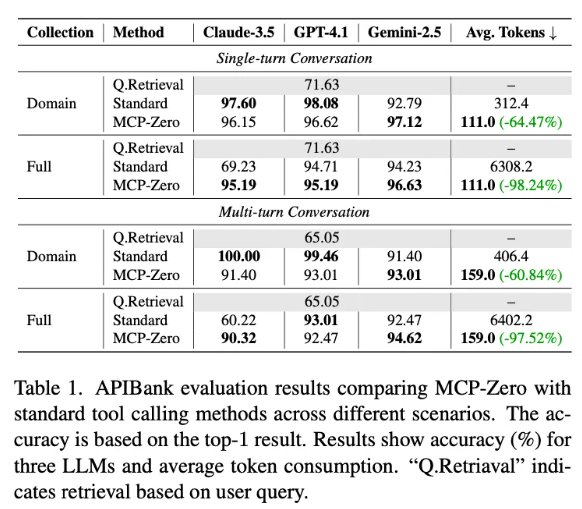
接下来,基于 APIBank 数据集进行了验证。测试结果表明,结合提出的方案,在开源APIBank数据集上同样表现出色。
可见,MCP-Zero 能够在保持检索精确度的前提下,显著降低上下文消耗,特别是在工具数量较多(表格中Full Collection相关数据)的情况下,效果提升更为显著。
总结
本文围绕 MCP 工具调用机制的核心瓶颈,提出了一个颠覆性的解决思路 —— MCP-Zero 框架,实现了从“被动工具接收”到“大模型主动驱动”的范式转变。
研究团队构建了标准化的 MCP 工具数据集,并提出了完整的调用流程,核心操作包括三步:
-
1. 引导模型主动发起请求,通过结构化格式精确描述其调用需求;
-
2. 搭建 MCP-tools 数据子集,提供多样化但可控的工具来源;
-
3. 执行分层语义匹配流程,高效完成工具的筛选与调用组合。
此外,实验还发现:仅提供一个上下文示例,就能显著提升模型构建请求体的准确性。这表明,当前大模型对结构化表达的掌握仍有边界,但一旦给予微小提示,其学习能力可被迅速激活。
整体来看,MCP-Zero 展现出三大关键能力:
-
• 强鲁棒性:即使面对数千工具,依旧能稳定调用、低成本匹配;
-
• 高灵活性:可多轮调整请求体,支持任务分解与跨域组合;
-
• 良好迁移性:无需微调,仅凭提示与数据结构即可迁移至新场景。
从“堆叠工具”到“自主检索、动态指挥”—— MCP-Zero 不仅优化了 token 成本,更重新定义了大模型在复杂任务中的角色边界。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 32
32 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)