LLaMA-Factory 快速入门(三): webui 名词全解析
本文详细记录了LLaMA-Factory用到的名词。
1. 引言
注意:本文部分内容根据AI生成,请注意甄别,仅供参考。
本文主要整理LLaMA-Factory 相关的名词,并进行解析。同学们可以根据目录导航去了解相关的知识点。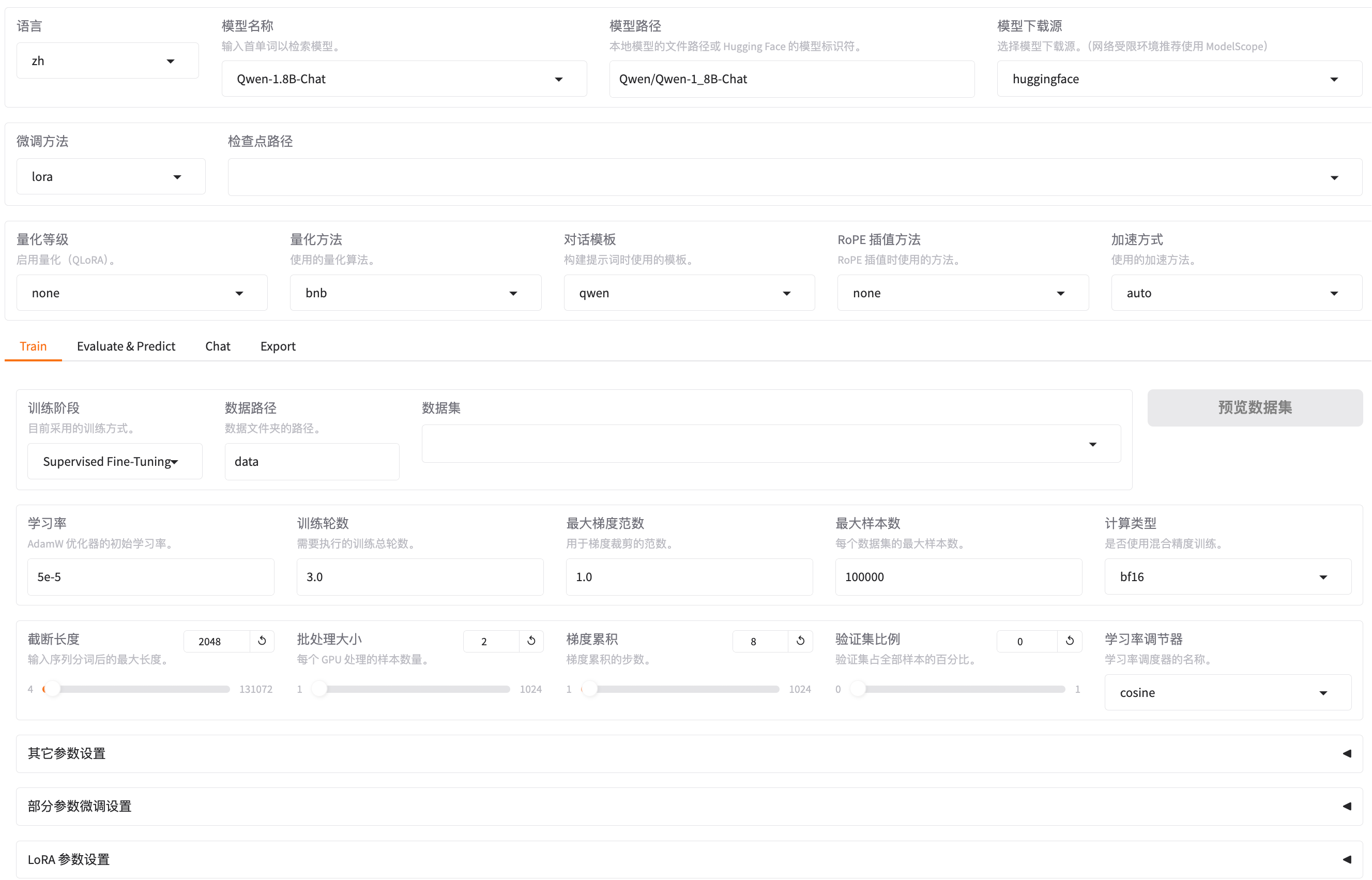
2. 基础名词
2.1 语言(Language)

LLaMA-Factory 支持的语言有如下:
en(英语)、ru(俄语)、zh(中文)、ka(格鲁吉亚语)、ja(日语)
选择语言之后,整个 WebUI 的菜单、按钮、提示信息等都会自动切换到对应语言。
2.2 模型

2.2.1 模型名称(Model name)
LLaMA-Factory 支持的模型如下:
| 模型名 | 参数量 | Template |
|---|---|---|
| Baichuan 2 | 7B/13B | baichuan2 |
| BLOOM/BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | - |
| ChatGLM3 | 6B | chatglm3 |
| Command R | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 7B/16B/67B/236B | deepseek |
| DeepSeek 2.5/3 | 236B/671B | deepseek3 |
| DeepSeek R1 (Distill) | 1.5B/7B/8B/14B/32B/70B/671B | deepseekr1 |
| Falcon | 7B/11B/40B/180B | falcon |
| Falcon-H1 | 0.5B/1.5B/3B/7B/34B | falcon_h1 |
| Gemma/Gemma 2/CodeGemma | 2B/7B/9B/27B | gemma/gemma2 |
| Gemma 3/Gemma 3n | 1B/4B/6B/8B/12B/27B | gemma3/gemma3n |
| GLM-4/GLM-4-0414/GLM-Z1 | 9B/32B | glm4/glmz1 |
| GLM-4.1V* | 9B | glm4v |
| GLM-4.5* | 106B/355B | glm4_moe |
| GPT-2 | 0.1B/0.4B/0.8B/1.5B | - |
| GPT-OSS | 20B/120B | gpt |
| Granite 3.0-3.3 | 1B/2B/3B/8B | granite3 |
| Granite 4 | 7B | granite4 |
| Hunyuan | 7B | hunyuan |
| Index | 1.9B | index |
| InternLM 2-3 | 7B/8B/20B | intern2 |
| InternVL 2.5-3 | 1B/2B/8B/14B/38B/78B | intern_vl |
| Kimi-VL | 16B | kimi_vl |
| Llama | 7B/13B/33B/65B | - |
| Llama 2 | 7B/13B/70B | llama2 |
| Llama 3-3.3 | 1B/3B/8B/70B | llama3 |
| Llama 4 | 109B/402B | llama4 |
| Llama 3.2 Vision | 11B/90B | mllama |
| LLaVA-1.5 | 7B/13B | llava |
| LLaVA-NeXT | 7B/8B/13B/34B/72B/110B | llava_next |
| LLaVA-NeXT-Video | 7B/34B | llava_next_video |
| MiMo | 7B | mimo |
| MiniCPM | 0.5B/1B/2B/4B/8B | cpm/cpm3/cpm4 |
| MiniCPM-o-2.6/MiniCPM-V-2.6 | 8B | minicpm_o/minicpm_v |
| Ministral/Mistral-Nemo | 8B/12B | ministral |
| Mistral/Mixtral | 7B/8x7B/8x22B | mistral |
| Mistral Small | 24B | mistral_small |
| OLMo | 1B/7B | - |
| PaliGemma/PaliGemma2 | 3B/10B/28B | paligemma |
| Phi-1.5/Phi-2 | 1.3B/2.7B | - |
| Phi-3/Phi-3.5 | 4B/14B | phi |
| Phi-3-small | 7B | phi_small |
| Phi-4 | 14B | phi4 |
| Pixtral | 12B | pixtral |
| Qwen (1-2.5) (Code/Math/MoE/QwQ) | 0.5B/1.5B/3B/7B/14B/32B/72B/110B | qwen |
| Qwen3 (MoE) | 0.6B/1.7B/4B/8B/14B/32B/235B | qwen3 |
| Qwen2-Audio | 7B | qwen2_audio |
| Qwen2.5-Omni | 3B/7B | qwen2_omni |
| Qwen2-VL/Qwen2.5-VL/QVQ | 2B/3B/7B/32B/72B | qwen2_vl |
| Seed Coder | 8B | seed_coder |
| Skywork o1 | 8B | skywork_o1 |
| StarCoder 2 | 3B/7B/15B | - |
| TeleChat2 | 3B/7B/35B/115B | telechat2 |
| XVERSE | 7B/13B/65B | xverse |
| Yi/Yi-1.5 (Code) | 1.5B/6B/9B/34B | yi |
| Yi-VL | 6B/34B | yi_vl |
| Yuan 2 | 2B/51B/102B | yuan |
2.2.2 模型路径(Model path)
模型路径是本地模型的文件路径或 Hugging Face 的模型标识符。
- 本地文件系统路径:指向你本机磁盘上已下载好、符合 Hugging Face 目录结构的模型文件夹(确保该目录中包含 config.json、tokenizer 配置以及权重文件),例如:
/data/models/chinese-llama-7b - Hugging Face Hub 标识符:在线仓库里的模型名称(含可选用户名/组织名与命名空间),例如:
meta-llama/Llama-2-7b-chat-hf
2.2.3 模型下载源(Hub name)
LaMa-Factory 首次(或缓存失效时)拉取模型权重、分词器及配置文件时,需要决定从哪个平台去下载,下拉框可三选一:
| 选项 | 全称 / 地址 | 适用场景 | 备注 |
|---|---|---|---|
| huggingface | Hugging Face Hub | 国际网络畅通 | 官方源,模型最全,速度取决于国际带宽 |
| modelscope | ModelScope 魔搭社区 | 国内网络、教育网 | 阿里达摩院运营,镜像同步快,网络受限环境推荐 |
| openmind | 魔乐社区 | 华为昇腾/Atlas 生态 | 华为主导,对 Ascend 芯片有专门优化 |
总结:“网络好就用 huggingface;国内或受限就用 modelscope;华为设备或魔乐专模就用 openmind”。
2.3 微调方法

2.3.1 微调方法(Finetuning method)
告诉 LaMa-Factory 在训练阶段只改哪些参数,从而决定显存占用、训练速度与最终效果之间的权衡,下拉框三选一:
| 选项 | 全称/含义 | 原理 | 显存 | 适用场景 |
|---|---|---|---|---|
| lora | Low-Rank Adaptation | 冻结原模型权重,插入少量可训练的低秩矩阵 | 最低 | 显存有限、快速实验、多卡并行 |
| full | Full-Parameter Fine-Tuning | 放开全部参数一起训练 | 最高 | 数据量大、算力充足、追求极限精度 |
| freeze | Freeze(部分冻结) | 冻结大部分层,只训练顶层/指定层 | 中等 | 想保留原模型知识、仅微调少量层 |
总结:“显存小选 lora,算力足选 full,想折中选 freeze”。
2.3.2 检查点路径(Checkpoint path)
告诉 LaMa-Factory 在 继续训练(resume)或 加载已微调好的权重 进行推理/评估时,去哪个目录里找完整的模型检查点。与「模型路径」不同,这里指向的通常是你自己上一次微调保存下来的结果(包含完整或 LoRA 权重、优化器状态、训练步数等信息)。
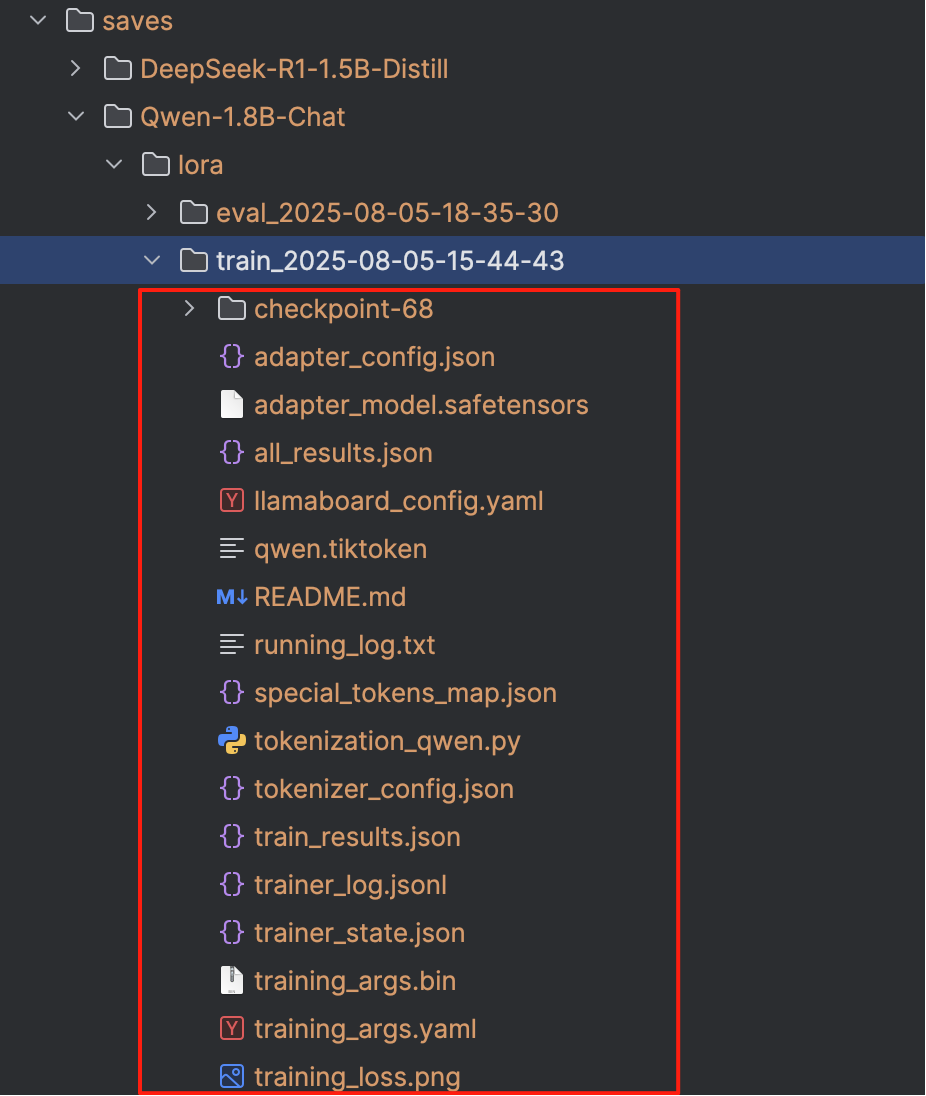
常见示例 :
# 继续上次的 LoRA 训练
./saves/llama2-7b-chat/lora/checkpoint-1200
# 加载已经微调完并合并权重的完整模型
./saves/baichuan-13b/full/best_model
# 评估或推理时,直接指向上次保存的最终目录
./output/exp_20240807
与「模型路径」的关系 :
- 如果 checkpoint_path 为空,LaMa-Factory 会完全从 model_name_or_path 初始化。
- 如果 checkpoint_path 不为空,则会覆盖 model_name_or_path 里的权重,用于继续训练或直接使用微调后的模型。
总结 :“检查点路径”就是告诉程序别用原来的预训练权重,用我上次训练出来的那一份。
2.4 量化

2.4.1 量化等级(Quantization bit)
在加载大模型前,先把权重压缩到 8-bit 或 4-bit 整数,从而显著降低显存占用和推理延迟,下拉框三选一:
| 选项 | 含义 | 显存节省 | 速度 | 适用场景 |
|---|---|---|---|---|
| none | 不做量化,保持原精度(FP16/BF16) | 0 % | 基准 | 显存充裕、追求最高精度 |
| 8 | 8-bit 整数量化(INT8) | ≈ 50 % | 轻微下降 | 中等显存、可接受少量误差 |
| 4 | 4-bit 整数量化(INT4/Q4_0、Q4_K、NF4 等) | ≈ 75 % | 明显下降 | 显存紧张、快速实验、本地部署 |
总结:“显存够选 none,想省一半选 8,想省四分之三选 4”
2.4.2 量化方法(Quantization method)
在“量化等级”里选了 8-bit 或 4-bit 后,再决定具体用哪一套算法去做低比特压缩,LaMa-Factory 的下拉框目前给出三种:
bnb(bitsandbytes)
• 最常见的动态量化库,社区支持最好。
• 支持 4-bit(NF4/fp4)和 8-bit(INT8)两种位宽。
• 与 LoRA/QLoRA 配合最成熟,微调阶段几乎零额外开发量。
• 显存节省约 50 %(8-bit)或 75 %(4-bit),对推理速度影响较小。
• 依赖:bitsandbytes CUDA 内核,安装简单,一条 pip install bitsandbytes 即可。
hqq(Half-Quadratic Quantization)
• 2024 年提出的“半二次”量化算法,无需校准数据即可后训练量化。
• 支持 2-8 bit 可配置位宽,官方推荐 3-4 bit 仍能保持较高精度。
• 在极低比特(2-3 bit)场景下,精度显著优于线性量化。
• 推理速度极快,适合边缘端部署;与 LoRA 同样兼容。
• 依赖:pip install hqq(或源码安装)。
eetq(Efficient and Effective Ternary Quantization)
• 三值/INT8 量化方案,目前 LaMa-Factory 固定 8-bit。
• 实现简单、延迟最低,对 GPU Tensor Core 友好;但仅 8-bit,压缩率低于前两者。
• 适合对延迟极度敏感、显存又不是极端紧张的场景。
• 依赖:pip install eetq(或指定 git 源码)。
总结 :“大众稳选 bnb,极限压缩选 hqq,只要快选 eetq”。
2.5 对话模版

在训练或推理时,把「用户输入」包装成符合目标模型 prompt 格式的「完整字符串」。不同模型家族(LLaMA-2-Chat、Baichuan-Chat、ChatGLM3、Qwen、Vicuna …)对 system / user / assistant / history 的拼接方式、特殊 token、换行符都有细微差异,模板就是用来 自动完成这种拼接 的。
LaMa-Factory 的下拉框里常见的内置模板示例 :
| 模板名 | 适用模型 | 处理后示例(简化) |
|---|---|---|
| llama2 | LLaMA-2-Chat | <s>[INST] <<SYS>>\nsystem\n<</SYS>>\nuser [/INST] assistant </s> |
| baichuan | Baichuan-Chat | <reserved_106>user<reserved_107>assistant |
| chatglm3 | ChatGLM3 | `[gMASK]sop< |
| qwen | Qwen-Chat | `< |
| vicuna | Vicuna-v1.5 | USER: user\nASSISTANT: assistant |
| raw / none | 基座模型 | 不做任何包装,直接把用户文本送进去 |
注意:
- 下拉框里直接挑与模型名字一致或官方推荐的模板。
- 若自定义模板,可把对应的
.jinja/.yaml文件放到templates/目录,下拉框会自动出现同名选项。 - 选错模板会导致模型输出乱码、胡言乱语,或者训练损失不降。
总结: “模型是谁,模板就选谁;模板选错,效果全毁。”
2.6 RoPE插值方法

当输入文本长度超过模型预训练时的最大位置编码(例如 4k)时,通过 “插值” 把未见过的长位置索引映射回模型熟悉的区间,从而 无需重训 即可扩展上下文窗口。LaMa-Factory 下拉框给出了 5 种可选策略,按复杂度与效果递增:
| 选项 | 全称 / 原理 | 特点 | 适用场景 |
|---|---|---|---|
| none | 不插值 | 原样使用训练长度,超长直接外推,效果差 | 只处理短文本、或已专门重训 |
| linear | 线性插值 | 把位置索引整体等比例压缩,实现简单但易失真 | 快速实验;8k 以内扩展 |
| dynamic | 动态 NTK 插值 | 根据实时序列长度自动计算缩放系数,兼顾长短文本 | 开源模型零样本长文本首选,无需微调 |
| yarn | Yet another RoPE extensioN | 将不同频率维度分段处理:高频保留、低频线性插值、中频平滑过渡,支持 >200k token 超长输入;需少量长文本微调恢复精度 | 超长文档、代码仓库、书籍级任务 |
| llama3 | Llama-3 官方方案 | 先对 8k 长度继续预训练,再采用组合式 RoPE 缩放(含 yarn 思想),兼顾精度与效率;仅适合 Llama-3 系列 | 官方 8k+ 场景,直接开箱即用 |
总结: “短文本 none,8k 以内 linear,通用长文本 dynamic,极限超长 yarn,Llama-3 就用 llama3”。
2.7 加速方式

决定在训练或推理阶段,用哪一套 底层算子/系统级优化 来加速 Transformer 的注意力计算、显存调度或端到端流程。LaMa-Factory 的下拉框目前提供 4 个互斥选项:
| 选项 | 全称 / 实现 | 核心优化点 | 适用场景一句话 |
|---|---|---|---|
| auto | 自动检测 | 框架根据 GPU 架构、CUDA 版本、依赖是否安装,自动在 flashattn2、unsloth、xformers、pytorch-native 之间回退 |
不想折腾,让系统自己挑 |
| flashattn2 | FlashAttention-2 | 针对 Attention 的 IO-aware 精确加速:分块 (tiling) + Tensor Core,无精度损失;训练/推理都能用 | 长序列、大模型训练,A100/H100 等高端卡效果最佳 |
| unsloth | Unsloth 框架 | 训练阶段专用:重写反向传播 + 梯度检查点 + 动态量化,单卡可提速 2-10 倍,显存省 70 % | 单卡/多卡训练,显存紧张又想快 |
| liger_kernel | Liger Kernel | 推理阶段专用:算子融合、JIT 编译、静态内存预分配,面向端侧或 CPU/GPU 混合部署 | 边缘设备、推理服务、低延迟场景 |
如何选?
- 默认 auto:最省心,系统会优先尝试 flashattn2 → unsloth → 原生。
- 训练长序列或 GPU 支持 FA2 → 手动选 flashattn2。
- 本地 GPU 显存 < 24 GB,又想跑 7B/13B → 选 unsloth 并配合 4-bit 量化。
- 只是做端侧推理或需要极致低延迟 → 选 liger_kernel。
总结: “不想管就选 auto,训练又快又准 flashattn2,显存吃紧 unsloth,端侧推理 liger_kernel。”
2.8 设备显存

LaMa-Factory 在训练或推理阶段最多能占用多少显存,防止 OOM(Out-Of-Memory)或把整卡占爆。单位统一用 GiB(1 GiB = 1024 MiB)。
常见填写方式
| 场景 | 示例值 | 说明 |
|---|---|---|
| 单卡 24 GB,留 2 GB 给系统 | 22 | 实际最大占用 ≈ 22 GiB |
| 8×A100 80 GB,想让每张卡最多吃 70 GB | 70 | 多卡并行时每张卡都受 70 GiB 限制 |
| 笔记本 6 GB,测试小模型 | 5 | 留 1 GB 给 GUI/浏览器 |
注意事项
- 如果同时开启了 8/4-bit 量化、LoRA、unsloth 等优化,显存需求会大幅下降,可适当把
device_memory调低。 - 若出现 OOM,先减
per_device_train_batch_size或gradient_accumulation_steps,再下调device_memory。 - 在 CPU/多卡混合训练时,该参数仅限制 GPU 显存;CPU offload 部分不受此限制。
2.9 相关知识
2.9.1 显存
显存,全称是显卡内存(Video Memory,VRAM),是安装在显卡(GPU)上的一种高速存储器,用于存储和处理图像、视频和3D数据等与图形相关的信息。
显存、显卡、独立显卡、集成显卡、GPU、CPU等概念常常出现在电脑硬件、图形处理、人工智能等领域,看起来复杂,其实背后有清晰的关系。一张图先理清大局:
CPU(中央处理器)
│
├── 集成显卡(iGPU) → 使用共享内存
│
└── 主板插槽 ↘
↘
独立显卡(dGPU) → 包含 GPU + 显存(VRAM)
│
└─ NVIDIA/AMD(显卡厂商)
│
└─ CUDA(NVIDIA 的 GPU 编程平台)
如果使用的是 Mac (Apple Silicon 架构),这些概念会和传统的 PC(尤其是配 NVIDIA 显卡的 Windows/Linux)有些不同理解方式,下面是针对 Apple Silicon 架构的解释。
┌────────────────────────────────────────────────────┐
│ Apple 芯片(SoC) │
│─────────────────────────────────────────────────── │
│ │
│ ┌────────────┐ ┌────────────┐ ┌───────────────┐ │
│ │ CPU │ │ GPU │ │ Neural │ │
│ │(通用计算) │ │(图形处理) │ │ Engine神经引擎 │ │
│ └────────────┘ └────────────┘ └───────────────┘ │
│ │
│ 所有模块共享这块统一内存(Unified Memory) │
└────────────────────────────────────────────────────┘
▲
│
不再区分“显存 VRAM”和“系统内存 RAM”
│
┌─────────────────────────────────────────────────────┐
│ 无需独立显卡(NVIDIA/AMD) │
│ GPU 内置,Metal 接口调用图形能力 │
└─────────────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────────────┐
│ 编程接口支持(非 CUDA) │
│ - Metal(图形+计算) │
│ - Core ML(AI 推理) │
│ - PyTorch-MPS / TensorFlow-Metal(深度学习) │
└──────────────────────────────────────────────────────┘
| 概念 | 在 Mac 上的理解 |
|---|---|
| GPU | Apple 芯片中内置的图形处理器,性能很强 |
| 显卡 | 没有独立显卡,GPU 是芯片一部分 |
| 显存(VRAM) | 使用统一内存(Unified Memory) |
| CPU | M4 内部集成的高效能 + 高能效核心 |
| CUDA | NVIDIA 专有,Mac 不支持,使用 Metal 代替 |
| PyTorch/TensorFlow | 需要配置 MPS 或 Metal 后端才能在 Mac GPU 上运行 |
2.9.2 CPU/GPU/NPU/TPU
下面用一个清晰简洁的表格总结 CPU、GPU、NPU 和 TPU 的核心区别和特点:
| 项目 | CPU | GPU | NPU | TPU |
|---|---|---|---|---|
| 全称 | 中央处理器 | 图形处理器 | 神经网络处理器 | 张量处理器 |
| 主要用途 | 通用计算 | 并行计算,图形渲染 | AI推理加速 | AI训练和推理 |
| 计算特点 | 串行处理,灵活性高 | 大规模并行计算 | 针对神经网络矩阵运算优化 | 专门为机器学习设计的加速器 |
| 编程接口 | C/C++、Java 等 | CUDA、OpenCL、Metal 等 | Core ML(Apple)、NNAPI(Android) | TensorFlow、XLA |
| 能效比 | 较低 | 中等 | 高 | 极高 |
| 代表厂商 | Intel、AMD | NVIDIA、AMD | Apple(Neural Engine)、华为、三星 | |
| 是否支持训练 | 支持 | 支持 | 主要推理,不支持大规模训练 | 支持 |
| 典型应用 | 操作系统、应用程序逻辑 | 游戏、视频渲染、深度学习 | 手机、边缘设备的 AI推理(加速已经训练好的模型执行,比如图像识别、语音识别、自然语言处理等任务,通常在手机、边缘设备上实现快速响应和低功耗) 、 实时处理(例如实时人脸识别、摄像头画面增强、智能助手语音识别等需要快速低延迟的应用)、 低功耗设备(智能手机、IoT设备、智能摄像头等对功耗敏感的设备使用NPU做AI计算) |
云端大规模AI训练 |
这几种处理器虽然侧重点不同,但它们之间是互补且协同工作的关系。简单来说:
- CPU :是通用的大脑,负责整体控制、逻辑判断、调度任务。
- GPU :是擅长做大规模并行计算和图形渲染的“多线程工厂”,帮 CPU 加速大量重复计算。
- NPU :专门针对 AI 神经网络推理做硬件加速,比 GPU 更省电更高效,但灵活性略低。
- TPU :是谷歌为深度学习训练和推理设计的“超级加速器”,专门优化机器学习计算。
3. 训练相关名词(train)
3.1 基础设置
3.1.1 训练阶段

在 LaMa-Factory 里,「训练阶段」决定整个 pipeline 的 数据格式、损失函数、优化目标 以及 后续可用功能 。下拉框共有 6 个互斥选项,按典型流程从前到后排列:
| 选项 | 描述 | 输入数据长什么样 | 产出 |
|---|---|---|---|
| Pre-Training (继续预训练) |
让基座模型在大规模无监督文本上继续学通用知识 | 纯文本文件,每行一段 doc | 新的基座权重 |
| Supervised Fine-Tuning (SFT,监督微调) |
用「指令-回答」对把模型变成对话/任务助手 | JSONL:{“instruction”:“…”, “input”:“…”, “output”:“…”} | 指令微调模型 |
| Reward Modeling (RM,奖励模型训练) |
让模型学会给「回答」打分,为后续 RLHF 提供奖励信号 | JSONL:{“chosen”:“…”, “rejected”:“…”} | 奖励模型权重 |
| PPO | 用 RM 的打分做强化学习,进一步对齐人类偏好 | JSONL:{“prompt”:“…”}(无需答案) | 强化后对话模型 |
| DPO | 直接利用「chosen / rejected」对做偏好对齐,不需要显式奖励模型 | JSONL:{“prompt”:“…”, “chosen”:“…”, “rejected”:“…”} | 偏好对齐模型 |
| KTO | 类似 DPO,但使用「输赢」信号而非完整句子对,样本标注更轻 | JSONL:{“prompt”:“…”, “completion”:“…”, “label”:true/false} | 偏好对齐模型 |
总结:“先 Pre-Training 打底,再 SFT 教对话,RM 学打分,PPO/DPO/KTO 做对齐。”
3.1.2 数据集
简单来说,数据集就是一组经过组织和整理的数据集合,常用于训练、验证、测试机器学习和深度学习模型,也被广泛应用于统计分析、数据挖掘、人工智能、科研等领域。
3.1.2.1 数据集分类
注意:使用自定义数据集时,请更新
data/dataset_info.json文件。
LLaMA-Factory提供丰富的数据集,常见的内置数据集分类如下:
📘 预训练数据集(预训练阶段,Pre-training)
| 数据集名称 | 说明 | 语言/领域 |
|---|---|---|
| Wiki Demo (en) | 维基百科小规模演示数据 | 英文 |
| RefinedWeb (en) | 高质量网页文本 | 英文 |
| RedPajama V2 (en) | RedPajama 第二版网页和书籍语料 | 英文 |
| Wikipedia (en) | 英文维基百科全文 | 英文 |
| Wikipedia (zh) | 中文维基百科全文 | 中文 |
| Pile (en) | 多来源大型英文语料 | 英文 |
| SkyPile (zh) | Skywork 中文预训练语料 | 中文 |
| FineWeb (en) | 网页抓取后处理文本 | 英文 |
| FineWeb-Edu (en) | 教育领域网页文本 | 英文 |
| The Stack (en) | 开源代码语料库 | 多语言代码 |
| StarCoder (en) | StarCoder 代码语料 | 代码 |
🧾 指令微调数据集(指令微调阶段,SFT)
🧠 偏好数据集(偏好学习阶段, DPO / RLHF)
| 数据集名称 | 说明 | 语言/领域 |
|---|---|---|
| DPO mixed (en&zh) | 中英文偏好对齐数据 | 英文 & 中文 |
| UltraFeedback (en) | 大规模用户反馈数据 | 英文 |
| COIG-P (zh) | 中文偏好对比数据 | 中文 |
| RLHF-V (en) | 奖励模型训练数据 | 英文 |
| VLFeedback (en) | 多模态反馈数据 | 多模态 |
| RLAIF-V (en) | 强化学习带人类反馈数据 | 英文 |
| Orca DPO Pairs (en) | Orca 偏好对比数据 | 英文 |
| HH-RLHF (en) | Anthropic 人类反馈数据 | 英文 |
| Nectar (en) | 奖励模型训练数据 | 英文 |
| Orca DPO (de) | 德语 Orca 偏好对比数据 | 德语 |
| KTO mixed (en) | 英文混合偏好对齐数据 | 英文 |
3.1.2.2 构建数据集
可以使用如下工具构建用于微调的合成数据:
-
Easy Dataset:https://github.com/ConardLi/easy-dataset

-
DataFlow :https://github.com/OpenDCAI/DataFlow

3.1.3 学习率

AdamW 优化器在训练开始时使用的初始步长(step size),它决定了每次参数更新的幅度:
- 太大 → 损失震荡甚至发散;
- 太小 → 收敛极慢,浪费算力;
- 合适 → 快速且稳定地降低 loss。
默认值 5 × 10⁻⁵(即 0.00005),是 LLaMA / Baichuan / ChatGLM 等 7B~13B 模型做 SFT 时的社区常用起点。
调整技巧:
| 场景 | 推荐范围 | 调整思路 |
|---|---|---|
| 7B/13B 全参 SFT | 1e-5 ~ 5e-5 | 先用 5e-5,观察 loss 曲线再微调 |
| LoRA / QLoRA | 1e-4 ~ 2e-4 | 可训练参数少,学习率通常放大 2-10 倍 |
| 继续预训练(Pre-Training) | 2e-5 ~ 5e-5 | 数据量大,用较小 lr 防止灾难性遗忘 |
| Reward Modeling | 1e-5 ~ 3e-5 | 与 SFT 相近即可 |
| PPO / DPO / KTO | 1e-6 ~ 5e-6 | RLHF 阶段通常再降一个量级 |
总结:“默认 5e-5 先跑,LoRA 可放大到 1e-4,RLHF 再降 10 倍,看 loss 曲线随时改。”
3.1.4 训练轮数

设置 LaMa-Factory 完整地把整个数据集扫几遍 才结束训练,每完整扫一次数据集算 1 个 epoch(轮), 默认3 轮,适用于 7B-13B 模型在常见指令微调(SFT)数据集上的经验值。
设置技巧:
| 场景 | 推荐轮数 | 思路 |
|---|---|---|
| 小数据集(<1 万条) | 3-10 轮 | 样本少,多扫几遍防止欠拟合 |
| 中等数据集(1-10 万条) | 2-3 轮 | 默认 3 轮即可 |
| 大数据集(>50 万条) | 1-2 轮 | 扫 1 轮已足够,避免过拟合与耗时 |
| 继续预训练(Pre-Training) | 1 轮 | 数据量巨大,通常 1 轮即可 |
| PPO/DPO/KTO 强化学习 | 1-2 轮 | 强化阶段数据集小,且需防止过度优化 |
总结: “样本少多扫几轮,样本大扫 1 轮,默认 3 轮先跑,看 loss / eval 再减。”
3.1.5 最大梯度范数

最大梯度范数(max_grad_norm) 是一个用于 梯度裁剪(Gradient Clipping) 的超参数,当梯度的 L2 范数超过设定值时,自动将其缩放到该最大值以内,从而确保模型训练的稳定性。简单来说,它是一个“刹车机制”,避免模型在训练初期或数据波动较大时“失控”。
设置技巧(通常为 1.0,适用于大多数 Transformer 模型的训练场景):
| 场景 | 推荐值 | 思路 |
|---|---|---|
| 一般监督微调(SFT) | 1.0 | 默认即可,适用于大多数情况 |
| LoRA / QLoRA 微调 | 1.0 ~ 2.0 | 可训练参数少,梯度裁剪可以适当宽松 |
| 继续预训练(Pre-Training) | 1.0 | 数据量大,保持默认稳定训练 |
| PPO / DPO / KTO 强化学习 | 0.5 ~ 1.0 | 强化学习阶段梯度波动大,适当收紧 |
| 数据噪声大或模型复杂 | 0.5 | 若发现梯度爆炸,可尝试调小 |
总结:默认 1.0 就够用,LoRA 可放宽到 2.0,强化学习或噪声大就调到 0.5。
3.1.6 最大样本数

最大样本数指的是每一个数据集(dataset 列表中的每一项)设置 “最多只读取多少条样本”。
3.1.7 计算类型
决定在训练/推理时,把模型权重、激活值、梯度放在哪种浮点精度里计算。
- 精度越低 → 显存越小、速度越快;精度越高 → 数值越稳、误差越小。
LaMa-Factory 下拉框给出 4 个选项:
| 选项 | 全称 | 位数 | 显存节省 | 数值误差 | 何时用 |
|---|---|---|---|---|---|
| fp32 | 单精度 float32 | 32 bit | 0 % | 最小 | 研究/小模型,对精度要求极高 |
| fp16 | 半精度 float16 | 16 bit | ≈ 50 % | 中等 | 老显卡 (Pascal/Volta) 不支持 bf16 |
| bf16 | bfloat16 | 16 bit | ≈ 50 % | 低 | Ampere/A100/H100 等现代卡,默认推荐 |
| pure_bf16 | 纯 bf16(权重+优化器状态) | 16 bit | ≈ 75 % | 低 | 显存极紧时;需框架/优化器支持(AdamW-bf16) |
总结:老卡 fp16,新卡 bf16,显存爆炸 pure_bf16,极致稳妥 fp32。
3.1.8 截断长度

把每个样本 分词(tokenize)后的最大 token 数 限制在这条线上,超长部分直接截断或丢弃,防止 OOM,也统一批次尺寸, 默认值 2048(即 2K tokens),与大多数 7B-13B 基座模型的原始训练长度对齐。设置技巧如下:
| 场景 | 推荐值 | 思路 |
|---|---|---|
| 原始短对话(单轮 < 512 token) | 1024-2048 | 默认即可,浪费少 |
| 长文档/代码仓库 | 4096-8192 | 先确认 GPU 显存,再逐步上调 |
| 超长论文/书籍 | 16384-32768 | 需配合 RoPE 插值(如 dynamic、yarn)+ 量化,显存 ≥ 40 GB |
| 继续预训练 | 与基座模型一致 | 如 Llama-2 原始 4096,可直接设 4096 |
注意事项 :
- 截断策略:默认「右侧截断」,可用
truncation_side=left改变。 - 多轮对话:模板会把历史拼在一起,再整体截断;因此 cutoff_len 需 ≥ 最长完整对话长度。
- 若开启 packing(样本拼接),cutoff_len 仍是单条拼接后的最大长度,而非单条样本。
总结:“cutoff_len 就是‘一条样本最多吃多少个 token’,短文本 2K 够用,长文本先卡显存再往上加。”
3.1.9 批处理大小

批处理大小指的是每个GPU处理的样本数量。在 每张 GPU 上,每一次前向-反向传播 要喂多少条样本(注意是“样本条数”,不是 token 数),默认值为2(保守值,7B 模型单卡 24 GB 也能起步)。设置技巧如下:
- 先看显存:
batch_size ↑ → 显存 ↑ 近似线性。 - 再配梯度累积:
全局有效batch = per_device_train_batch_size × gradient_accumulation_steps × GPU数。 - 常见组合举例(7B 模型,fp16/bf16,cutoff_len=2048):
| GPU 显存 | per_device_train_batch_size | gradient_accumulation_steps | 全局有效 batch |
|---|---|---|---|
| 24 GB × 1 | 2 | 8 | 16 |
| 40 GB × 1 | 4 | 4 | 16 |
| 8×A100 80 GB | 8 | 1 | 64 |
- 出现 OOM 时:
先减 per_device_train_batch_size,再把 gradient_accumulation_steps 相应提高,保持全局 batch 不变。 - 推理/评估阶段:
对应的参数叫 per_device_eval_batch_size,可比训练再大 2-4 倍,因为无需保存梯度和优化器状态。
总结:“per_device_train_batch_size 是单卡一次吃几条;显存不够就改小它,靠梯度累积把总批量补回来。”
3.1.10 梯度累积

梯度累积指的是在显存有限、又想保持大全局批量的场景下,把一次完整梯度的计算拆成多步:
- 每步用较小的
per_device_train_batch_size正常前向+反向,算出的梯度先累加(不立即更新权重)。 - 累加到指定步数后,再一次性做权重更新 & 优化器步进。
- 因此「虚拟全局批量」=
per_device_train_batch_size × gradient_accumulation_steps × GPU 数。
默认值为8(官方脚本常用折中值,单卡 24 GB 也能跑 7B 模型)。
快速调参公式 :
期望全局批量 = 32
GPU 数 = 1
per_device_train_batch_size = 2 → gradient_accumulation_steps = 32 / (2 × 1) = 16
常见组合示例
| 场景 | batch_size | 梯度累积 | 全局批量 |
|---|---|---|---|
| 单卡 24 GB | 2 | 8 | 16 |
| 单卡 40 GB | 4 | 4 | 16 |
| 8×A100 | 8 | 1 | 64 |
总结:“显存不够就把梯度累积调大,用时间换空间,保证总批量不变。”
3.1.11 验证集比例

在启动训练时,把所有样本按给定比例随机切出一部分作为验证集(dev set),用于
- 每个 epoch 结束后计算验证损失 / 指标
- 早停(early stopping)
- 超参筛选(learning rate、LoRA rank 等)
填写技巧:
- 0 → 不保留验证集,全程只跑训练集(适合一次性训练或已单独准备了验证文件)。
- 0.05 → 5 % 数据做验证(常见做法:万条样本量级)。
- 0.1 → 10 % 数据做验证(千条样本量级)。
- 1 ~ 100 之间的整数会被自动当成百分比换算(写 5 与 0.05 效果相同)。
示例
| 总样本 | 验证集比例 | 验证集条数 | 说明 |
|---|---|---|---|
| 50 k | 0.05 | 2.5 k | 微调阶段常用,兼顾速度与评估 |
| 1 M | 0.01 | 10 k | 预训练时 1 % 已足够 |
| 500 | 0.2 | 100 | 数据极少时,可适当放大比例 |
注意事项
- 与
validation_split参数互斥:若已手动指定验证文件,请把 eval_ratio 设为 0,否则会二次切分。 - 随机种子固定后,切分结果可复现。
- 开启 streaming 时,eval_ratio 会先把总量截断再切分(不影响训练流式读取)。
总结: “验证集比例就是‘抽几成数据当考试卷’;不考试就填 0,想早停就填 0.05~0.1。”
3.1.12 学习率调节器

学习率调节器控制训练过程中学习率随步数(或 epoch)如何变化的“调度器”。不同任务、不同阶段的收敛速度差异很大,合理选调度器能显著缩短训练时间、提高最终指标。LaMa-Factory 下拉框给出 11 种常用策略:
| 选项 | 中文简称 | 典型曲线 | 适用场景一句话 |
|---|---|---|---|
| linear | 线性衰减 | 从初始值线性降到 0 | 通用默认,尤其 SFT |
| cosine | 余弦退火 | 先慢→快→慢,平滑降到 0 | 需要平滑收敛,视觉/NLP 都常用 |
| cosine_with_restart | 余弦+重启 | 余弦降到 0 后立刻回到初始值再循环 | 多轮重启,避免陷入局部极小 |
| polynomial | 多项式衰减 | 按 (1-当前步/总步)^power 下降 | 想自己控制下降曲率 |
| constant | 常数 | 全程不变 | 小数据快速调试或冻结层 |
| constant_with_warmup | 常数+预热 | 先线性升到初值,再保持常数 | 冷启动大 batch,防止震荡 |
| inverse_sqrt | 逆平方根 | ∝ 1/√step | Transformer 原始论文,适合预训练 |
| reduce_lr_on_plateau | plateau 自动降 | 监控验证指标,不提升就降 lr | 训练-验证同步调优 |
| cosine_with_min_lr | 余弦到最小值 | 余弦降到指定最小值而非 0 | 防止过度衰减 |
| warmup_stable_decay | 三段式 | 预热→恒定→指数衰减 | 大模型继续预训练常用 |
总结:“默认 linear 最稳;想更平滑用 cosine;大模型预训练先试 inverse_sqrt;验证早停 plateau。”
3.2 其它参数设置
3.2.1 日志间隔

控制在训练过程中,在终端/TensorBoard/WandB 等日志里输出一次损失、学习率、耗时等关键指标。默认值为5,表示每 5 个更新步打印一次日志。
设置技巧:
| 场景 | 推荐值 | 思路 |
|---|---|---|
| 小样本、调试阶段 | 1 ~ 5 | 日志密集,方便快速定位问题 |
| 中等规模训练 | 10 ~ 50 | 兼顾可读性与磁盘/网络 IO |
| 大规模多机训练 | 100 ~ 500 | 减少日志刷屏,提高训练效率 |
| 远程日志(WandB) | 50 ~ 100 | 避免频繁网络请求造成延迟 |
总结:“日志间隔就是‘隔几步报一次数’;调试写小一点,正式训练写大一点。”
3.2.2 保存间隔

训练过程中,每经过多少个「参数更新步」就把当前模型权重、优化器状态、学习率调度器状态等打包成一个**检查点(checkpoint)**保存到磁盘。
默认值:100(即每 100 个更新步存一次)。
设置技巧:
| 场景 | 推荐值 | 理由 |
|---|---|---|
| 单卡 7B 快速实验 | 50 ~ 100 | 训练时间短,磁盘占用可控 |
| 多机多卡大模型 | 200 ~ 500 | 减少 I/O 竞争,节省磁盘 |
| 长时间任务(>1 天) | 1000 | 防止因 I/O 频繁拖慢训练 |
| 云端训练(带宽计费) | 1000 ~ 2000 | 降低存储/流量费用 |
| 调试阶段 | 20 ~ 50 | 方便回滚定位问题 |
提示
- 与
save_total_limit连用可自动删除旧 checkpoint,只保留最近 N 个。 - 若同时开启
save_strategy=epoch,save_steps会被忽略,改为按 epoch 保存。 - 保存间隔 ≠ step 间隔;若
gradient_accumulation_steps=8,则每 100 个更新步 ≈ 800 个前向-反向小步。
总结:“save_steps 就是‘隔几步存一次盘’;调试写 50,久跑写 1000,别忘了配合自动清理旧 checkpoint。”
3.2.3 预热步数

在训练刚开始的若干步内,把学习率从一个极小值(或 0)线性增长到设定的初始学习率,避免因初始梯度爆炸导致训练不稳定。 默认值为0,表示 不预热,直接使用恒定学习率。
设置技巧:
| 场景 | 推荐预热步数 | 思路 |
|---|---|---|
| 全参数 SFT(7B/13B) | 0 ~ 100 | 数据集小或学习率≤5e-5 时可不开 |
| 大批量训练(global batch ≥ 512) | 100 ~ 500 | 大 batch 梯度方差大,预热稳 |
| 继续预训练(Pre-Training) | 总步数的 1 %~3 % | 例:100 k 步总步数 → 1 k~3 k 步 |
| LoRA / QLoRA | 50 ~ 200 | 可训练参数少,但学习率较大,预热更安全 |
| RLHF(PPO/DPO/KTO) | 100 ~ 300 | 强化阶段数据噪声高,预热可降低初期震荡 |
换算公式:
- 预热步数 ≈ 全局 batch_size × 1~3 epoch 的 1 %~5 %(经验值)。
- 若填
warmup_ratio=0.1,则自动按总训练步数 10 % 计算,无需手动换算。
总结: “预热步数就是‘先慢慢踩油门’;小任务写 0,大 batch 或预训练写几百到几千步。”
3.2.4 NEFTune 噪声参数

在训练阶段给**输入 token 的嵌入向量(embedding)**额外叠加一层均匀分布噪声,起到「数据增强」与「正则化」的效果,可轻微提升模型鲁棒性与泛化能力。
• 值为 0:完全关闭 NEFTune。
• 值 > 0:噪声强度 = neftune_noise_alpha,典型区间 5~15。数值越大,扰动越强。
如何设置
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 默认/首次实验 | 0 | 关闭,先复现基线 |
| 通用 SFT(7B/13B) | 5~10 | 小幅度增强即可 |
| 小数据集(<1 万条) | 10~15 | 数据不足时提高鲁棒性 |
| 继续预训练 | 0~5 | 大规模文本通常不需要额外噪声 |
| 实验对比 | 0 vs 5 vs 10 | 看验证集指标差异再拍板 |
总结: “NEFTune 噪声就是给 token embedding 撒点胡椒面;0 为关,5-10 增稳,15 以上可能糊味。”
3.2.5 额外参数

通过一段 JSON 字符串,把任何官方 Trainer / Accelerate / DeepSpeed 支持、但 WebUI 没有显式露出的小众超参数,一次性塞进训练器,避免改源码。 默认值:
{"optim": "adamw_torch"}
常见可填字段示例 :
| 场景 | 示例 JSON | 说明 |
|---|---|---|
| 换优化器 | {"optim": "adamw_8bit"} |
使用 bitsandbytes 的 8-bit AdamW,省显存 |
| 开 DeepSpeed ZeRO-3 | {"deepspeed": "./ds_config_zero3.json"} |
指定 DeepSpeed 配置文件路径 |
| 梯度裁剪阈值 | {"max_grad_norm": 1.0} |
若 WebUI 没暴露,可在此覆盖 |
| 关闭 tqdm 进度条 | {"disable_tqdm": true} |
日志更干净 |
| 多卡 NCCL 超时 | {"dataloader_timeout": 1800} |
避免慢节点导致训练挂起 |
| 混合精度开关 | {"fp16": false, "bf16": true} |
强制 bf16 而不用 fp16 |
使用规则
- 必须是合法 JSON,键值对用双引号。
- 与 WebUI 已提供的参数同名时,extra_args 优先级更高(覆盖)。
- 支持嵌套:
{
"optim": "adamw_torch",
"lr_scheduler_kwargs": {"num_cycles": 2},
"report_to": ["wandb", "tensorboard"]
}
- 若 JSON 格式非法,训练器会直接报错退出。
总结: “extra_args 就是给训练器开小灶:写合法 JSON,想塞啥就塞啥,优先级最高。”
3.2.6 序列打包

把多条 较短的样本 按顺序拼接成一条条「等长序列」,直到塞满 cutoff_len,从而
- 减少 Pad token,提高 GPU 利用率;
- 隐式地把「全局 batch 大小」放大,训练更快;
- 对显存占用几乎没有额外开销(因为是连续内存)。
开关方式:
- 勾选(true):启用打包,训练器会按
cutoff_len自动把样本粘成长条。 - 不勾选(false):传统做法——每条样本独立 pad 到
cutoff_len,会产生大量无效填充。
注意:
- 仅支持 无监督或 causal-LM 任务(Pre-Training、SFT 都可); 对于需要「样本边界」的任务(分类、NER 等)不要开启。
- 若样本本身很长(> cutoff_len),打包逻辑会自动跳过超长样本。
- 与
group_by_length互斥:后者按长度分组减少 pad,而 packing 直接拼接,两者只能二选一。 - 开启后日志里会显示
Packed samples: X → Y,可直观看到利用率提升。
总结:“序列打包就是‘把短句拼成长句’,省 pad 提速,因果 LM 全开,边界敏感任务别开。”
3.2.7 无污染打包

在启用序列打包(packing)的基础上,进一步优化打包逻辑,避免因打包导致的交叉注意力污染。 在传统的打包中,多条短样本拼接后,模型可能会对不同样本之间的内容产生不合理的注意力(例如,把前一条样本的结尾与后一条样本的开头错误关联)。 而「无污染打包」通过特殊的处理方式(例如在样本之间插入特殊的分隔符或调整注意力掩码),确保每个样本的注意力仅限于其原始内容,不会被其他样本干扰。
开关方式
- 勾选(true):启用无污染打包,训练器在打包时会自动处理交叉注意力问题。
- 不勾选(false):使用普通的打包逻辑,可能会有交叉注意力污染。
注意:
- 仅在启用 序列打包(packing) 时才生效。
- 适用于所有支持打包的任务(如 Pre-Training、SFT)。
- 会略微增加打包的计算开销,但通常对性能影响不大。
- 若样本本身很长(> cutoff_len),无污染打包依然会跳过超长样本。
总结: “无污染打包就是在拼长句时‘隔开不同样本’,避免交叉注意力,打包时必开。”
3.2.8 学习提示词

在监督微调(SFT)阶段,决定是否对提示词(prompt)部分计算损失。
- 不勾选(默认 false):
对整个序列(提示词 + 回答)都计算交叉熵损失,提示词也被迫“学习”如何复制自己,浪费算力并可能轻微降低回答质量。 - 勾选(true):
仅在 回答(response) 的 token 上计算损失;提示词部分被掩码(mask)掉,不参与梯度回传,训练更快、效果更聚焦。
使用条件
- 仅 SFT 阶段 生效,Pre-Training / RM / RLHF 等阶段无意义。
- 需要数据集字段结构清晰:至少包含
instruction/input/output(或prompt/response),框架才能自动区分提示词与回答。 - 与
packing/padding兼容:掩码会在打包或对齐后自动应用到对应 token。
总结: “SFT 时勾选 ‘学习提示词’=给 prompt 加遮罩,只让模型学回答,不学废话。”
3.2.8 不学习历史对话

在监督微调(SFT)阶段,仅对多轮对话中的最后一轮计算损失;前面所有历史轮次(包括用户和助手的对话)都被当成「纯 prompt」而被掩码,不贡献梯度。
- 勾选(true):只让模型“学习”如何生成最后一轮的回复,历史对话全部忽略。
- 不勾选(false,默认):对整个多轮序列都计算损失,历史轮也参与训练。
使用场景 :
| 场景 | 建议 | 原因 |
|---|---|---|
| 多轮 ShareGPT 类数据 | 可勾选 | 减少“自我模仿”带来的冗余训练,聚焦最新回复 |
| 单轮指令数据 | 无影响 | 数据本身只有一轮 |
| 需要保持对话一致性 | 不勾选 | 让模型学会维持上下文连贯 |
注意事项 :
- 仅在 SFT 阶段 生效,且需数据集含
conversations字段或history+output结构。 - 与
mask_prompt同时勾选时,先按only_last_turn截断,再对剩余 prompt 部分加掩码,双重节省计算。 - 若开启
packing,框架会在拼接后自动为每条样本定位最后一轮并加掩码,不会破坏边界。
总结: “不学习历史对话”就是告诉模型:前面的聊天都算背景,只练最后一句话。
3.2.9 更改词表大小

当需要扩充(或缩减)模型词表时,一次性把
-
- 分词器(tokenizer)的词汇表
-
- 模型嵌入层(lm_head + embedding)
调整为新的词表大小,并随机初始化新增/删除的 token 权重,确保训练能正常进行。
- 模型嵌入层(lm_head + embedding)
常见场景
- 新增中文/多语言 token:原 Llama 词表 32 k → 扩到 50 k 以提升中文压缩率。
- 添加特殊符号:如
<|im_start|>、<|plugin|>等 prompt 占位符。 - 删除冗余 token:缩减词表以减少显存/计算(极少用)。
如何操作
- WebUI 文本框直接填目标词表大小,例如
50000
- 需要先把扩展后的 tokenizer 文件(vocab.json / tokenizer.model / added_tokens.json 等)放到模型目录或指定路径;LaMa-Factory 会在启动时读取并校验。
- 训练脚本会自动调用
model.resize_token_embeddings(new_size)完成嵌入层尺寸调整;新增 token 的权重默认随机初始化,需在后续训练中继续学习。
注意事项
- 只能增大或减小,不能重复 resize 到同一尺寸。
- 扩词表后,embedding 参数量线性增加,显存占用也相应增加;可配合 LoRA 或量化抵消。
- 如果仅添加少量特殊 token,推荐用
add_tokens而非直接改词表大小;WebUI 另有「添加特殊 token」字段,优先级更高。
总结:“resize_vocab 就是一次性把字典和对应权重拉长或剪短;扩中文词表到 50 k 前,先把新 tokenizer 文件准备好。”
3.2.10 使用 LLaMA Pro

开启后,模型会把原始权重完全冻结,只让**“块扩展(block expansion)”**新增的那部分参数参与训练。
- 本质上是 “参数高效微调” 的另一种实现:
-
- 在现有 Transformer 每层之间插入若干全新的 FFN / Attention Block(通常 2–8 个)。
-
- 旧参数不动,新增参数量仅占总量的 5 %–20 %,显存占用接近 LoRA,但表达能力更强。
-
- 适用于:
-
- 大模型(30 B↑)全参数微调显存不够,又希望比 LoRA 获得更好的下游性能。
-
- 需要保留旧知识、同时注入新领域知识的场景(继续预训练或任务特化)。
-
如何启用
- 先准备好 LLaMA-Pro 结构配置文件(
config.json里含num_additional_blocks等字段)或官方提供的扩展权重。 - WebUI 勾选 “使用 LLaMA Pro”;框架会自动:
-
- 冻结原始层参数(requires_grad=False);
-
- 仅把新增 Block 的权重设为可训练;
-
- 学习率、优化器、调度器与 LoRA 相同即可。
-
注意事项 :
- 与
lora、freeze互斥:三者只能选其一。 - 扩展块默认随机初始化,需足够训练步数才能收敛。
- 若后续想合并回原模型,官方脚本会把新增 Block 权重与旧权重 concat,生成完整 checkpoint。
总结: “勾上 LLaMA Pro = 把模型原地加宽,只练新砖不动老墙,大模型高效微调的折中方案。”
3.2.11 启用思考模式
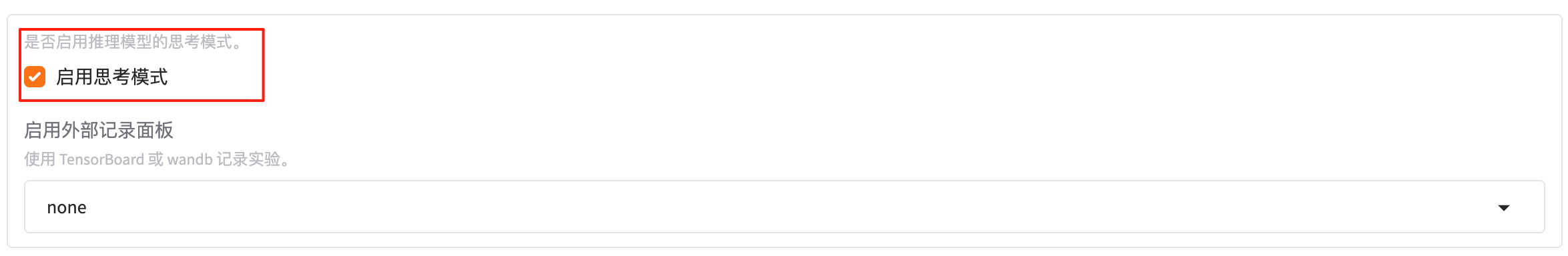
在 推理/对话阶段,让模型先输出一段「思考过程」(Chain-of-Thought),然后再给出正式回答。
- 勾选(true):
系统会在用户 prompt 后自动拼接“Let’s think step by step.”等触发语,并把模型生成的思考内容一并返回,前端可做隐藏/展开。 - 不勾选(false,默认):
直接输出最终答案,不暴露中间思考。
典型效果 :
- 勾选后,模型在数学推理、逻辑题、代码纠错等任务上准确率通常↑;
- 响应长度↑,首 token 延迟↑;
- 前端若支持折叠,可保持用户体验一致。
总结: “启用思考模式就是让模型先‘自言自语’再答问题,逻辑更稳,字也更多。”
3.2.12 启用外部记录面板

指定把训练过程中的标量指标(loss、learning_rate、eval_accuracy…)和媒体(模型图、样本预测)实时上传到哪个外部可视化平台,方便远程监控、对比实验。LaMa-Factory 下拉框提供 6 个选项:
| 选项 | 平台名称 | 一句话特点 |
|---|---|---|
| none | 不启用 | 本地终端/日志文件即可,不连外网 |
| wandb | Weights & Biases | 社区最流行,支持曲线、表格、模型版本管理 |
| mlflow | MLflow | 与 Spark / sklearn 生态无缝,本地部署简单 |
| neptune | Neptune.ai | 大模型友好,支持海量实验并行展示 |
| tensorboard | TensorBoard | 无需注册,本地浏览器即可查看 |
| all | 全开 | 同时向已配置的所有平台推送 |
使用步骤
- 选好平台 → 安装对应库:
pip install wandb # 或 mlflow / neptune-client / tensorboard
- 首次使用按提示登录(wandb login / mlflow ui / neptune init)。
- 训练启动后,指标将自动上传;在 WebUI 的「Run Name」里可自定义实验名。
- 若想关闭,可随时把下拉框切回 none 并重启训练。
总结:“想让实验曲线飞云端,选 wandb;想本地看图,选 tensorboard;都不想就连 none。”
2.2 部分参数微调设置

2.2.1 可训练层数

在 Freeze 微调 模式下,只放开模型最末端或最前端的若干层进行训练,其余权重全部冻结。
- 正数
+N:从最后一层往前数,解冻 N 层(默认+2即最后 2 层)。 - 负数
-N:从第一层往后数,解冻 N 层(-2即最前 2 层)。 0:完全冻结,仅用于推理或特征提取。
典型用法
| 场景 | 设置示例 | 说明 |
|---|---|---|
| 想轻量微调大模型 | +2 |
仅训练最后 2 层,显存占用接近 LoRA |
| 研究早期特征 | -3 |
只训练最前 3 层,观察低层表征变化 |
| 全冻结做评估 | 0 |
不更新任何权重,纯粹跑验证 |
总结:“正数从末尾解冻,负数从开头解冻;填 0 全冻,填 2 只练最后两层。”
2.2.2 可训练模块

在「Freeze」或「LoRA」微调模式下,进一步 精确指定 哪些模块(由网络层名称匹配) 参与训练,其余权重全部冻结。
- 填写内容是 PyTorch 模块名 或 正则表达式,多个名称用英文逗号隔开。
- 匹配到的层及其内部全部参数都会被设为可训练,未匹配到的全部冻结。
常见填写示例
| 场景 | 示例填写 | 解释 |
|---|---|---|
| 只训练 Llama 的 MLP 部分 | mlp |
匹配所有含 mlp 的层(如 model.layers.*.mlp) |
| LoRA 仅训练 Attention 与 MLP | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
典型 7B Llama LoRA 层 |
| ChatGLM 只训练 query_key_value | query_key_value,dense |
匹配对应模块 |
| 正则同时匹配多层 | .*\.attention\.dense,.*\.mlp\.up_proj |
用正则一次匹配多条 |
使用步骤:
- 先用
python -c "from transformers import AutoModel; m=AutoModel.from_pretrained('xxx'); [print(n) for n, _ in m.named_modules()]"打印模型结构,找到想要解冻的模块名。 - 把名称或正则抄进 WebUI 输入框,逗号分隔即可。
- 若与
trainable_layers同时给出,以trainable_modules为准(更细粒度)。
总结:“trainable_modules 就是‘点名’:只让名字匹配的层当学生,其它层全部挂科。”
2.2.3 额外模块

在 trainable_layers 与 trainable_modules 之外,再补充一批“零散但重要”的权重,使它们也参与训练。
- 典型目标:LayerNorm、embed_tokens、lm_head、位置编码、bias 项、router 等不属于 Transformer 隐藏层的模块。
- 填写格式:用英文逗号分隔模块名称或正则表达式,与前面两项规则一致。
- 可空:不填时等价于“无额外模块”。
常见示例 :
| 目的 | 填写示例 | 解释 |
|---|---|---|
| 解冻词嵌入 | embed_tokens |
让 tokenizer 新增 token 的权重可训练 |
| 解冻输出头 | lm_head |
配合词表扩展或 LoRA 输出层 |
| 解冻 LayerNorm | norm,layer_norm |
恢复分布偏移,微调更稳 |
| 解冻全部 bias | .*bias |
极小参数量,可与 LoRA 并用 |
| MoE 模型解冻 router | gate |
让专家路由权重参与更新 |
总结:“额外模块就是给隐藏层以外的‘小零件’开绿灯;不填没事,想动 embedding、lm_head 或 bias 就写进来。”
2.3 LoRA 参数设置
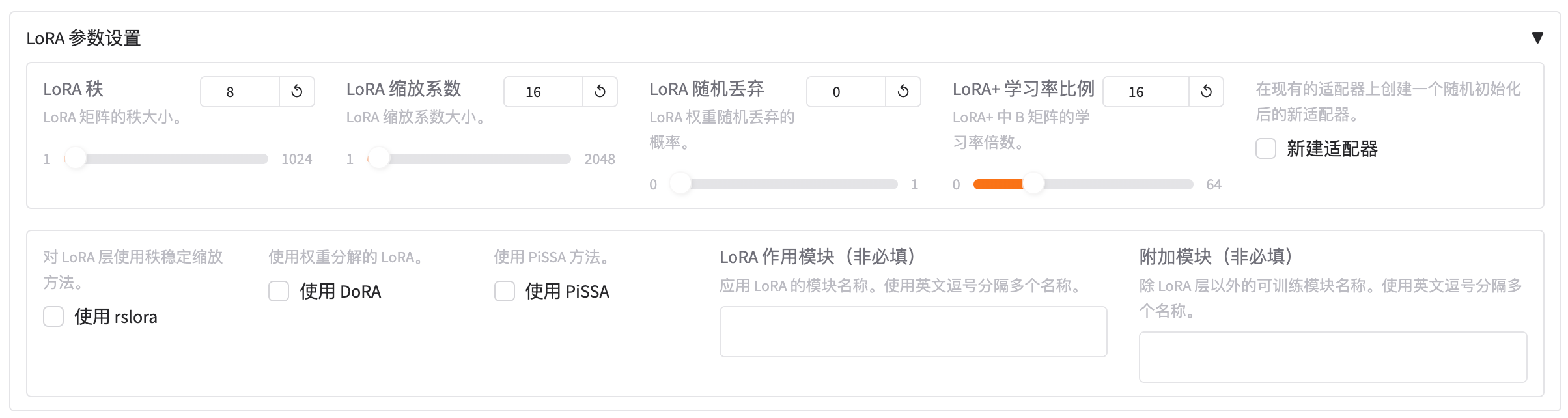
2.3.1 LoRA秩

决定 LoRA 低秩分解中两个矩阵(A、B)的“中间维度”。
- rank↑:表达力↑,但参数量与显存↑,训练速度↓。
- rank↓:更轻量,可能欠拟合。
默认值:8(7B/13B 模型做通用 SFT 的社区常用起点)。
| 场景 | 推荐 rank | 备注 |
|---|---|---|
| 7B/13B 通用 SFT | 8–16 | 默认 8 先跑,效果不够再加大 |
| 30B/70B 大模型 | 32–64 | 大模型容量大,rank 太小易欠拟合 |
| 中文领域特化 | 16–32 | 需要更多自由度学新词、新句式 |
| 极小显存(6 GB) | 4–8 | 先保收敛,再考虑提升 rank |
| 继续预训练 | 64–128 | 任务复杂,需更大表达空间 |
总结:“LoRA 秩就是低秩矩阵的‘宽度’:8 通用,16 提效,32 大模型,64 以上继续预训练。”
2.3.2 LoRA 缩放系数
 控制 LoRA 低秩适配器输出在加回原权重前的“放大倍数”。
控制 LoRA 低秩适配器输出在加回原权重前的“放大倍数”。
公式:ΔW = (lora_alpha / lora_rank) ⋅ BA
- 值越大,LoRA 的影响越强;
- 值越小,LoRA 的影响越弱。
默认值:16(与 rank=8 配合时实际放大 2 倍)。
经验值速查:
| lora_rank | 常用 lora_alpha | 实际放大倍数 | 说明 |
|---|---|---|---|
| 4 | 16 | 4× | 小 rank 需高 alpha 补强度 |
| 8 | 16 | 2× | 默认组合,平衡 |
| 16 | 16 | 1× | 线性缩放,稳定 |
| 32 | 32 | 1× | 大 rank 同步放大 |
| 64 | 64 | 1× | 继续预训练常用 |
总结:“alpha 与 rank 同量级最稳;显存紧就降 rank、保持 alpha 不变或略降,防止过拟合。”
2.3.3 LoRA 随机丢弃

在 LoRA 微调阶段,对低秩矩阵 A 和 B 的乘积结果应用 Dropout,防止过拟合。
- 值为 0:不丢弃(默认)。
- 值 > 0:按给定概率随机将 LoRA 增量置零,仅影响训练,不影响推理。
经验值
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 数据量小 / 易过拟合 | 0.05 – 0.1 | 轻微正则化 |
| 数据量中等 | 0.0 – 0.05 | 默认 0 即可 |
| 数据量极大 | 0.0 | 无需额外正则 |
总结:“LoRA dropout 就是给低秩增量随机‘失忆’,防过拟合;默认 0,数据少可调到 0.1。”
2.3.4 LoRA+ 学习率比例

在 LoRA+ 微调时,为矩阵 B 额外乘上一个学习率放大倍数,使得
lr(B) = lr(A) × loraplus_lr_ratio
从而让 B 用更高学习率更新,而 A 保持原学习率。
- 根据 LoRA+ 论文 ,这种非对称更新可带来 最多 2× 收敛加速 与 1–2 % 计算增益。
默认值:16(社区实践常用起点 )。
设置建议
| 场景 | 推荐比例 | 说明 |
|---|---|---|
| 首次尝试 | 16 | 论文与社区经验值 |
| 保守调参 | 4–8 | 稳定性优先,效果略慢但风险低 |
| 激进大模型 | 32 | 70 B+ 模型可再放大,需监控 loss 爆炸 |
| 搭配其他优化器 | 0 | 使用 D-Adaptation、Prodigy 等自适应优化器时需设为 0(互斥) |
总结:“LoRA+ 比例就是给矩阵 B 的学习率加‘油门’,默认 16,想稳就 4–8,大模型可 32。”
2.3.5 新建适配器
 在已有 LoRA 适配器(checkpoint)之上,再叠加一个全新、随机初始化的 LoRA 适配器,实现“适配器套娃”或“任务增量”:
在已有 LoRA 适配器(checkpoint)之上,再叠加一个全新、随机初始化的 LoRA 适配器,实现“适配器套娃”或“任务增量”:
- 旧适配器权重保持冻结,继续为新任务训练新适配器;
- 避免覆盖原任务知识,适合多任务/多领域持续学习;
- 推理时可通过切换 adapter_name 快速在不同适配器间热插拔。
使用方式
| 步骤 | 说明 |
|---|---|
| 1 | 在 WebUI 勾选「新建适配器」。 |
| 2 | 在「适配器路径」里填写旧适配器目录(含 adapter_config.json / adapter_model.bin)。 |
| 3 | 框架自动把旧 adapter 设为只读,并新建同名目录下带 _new 后缀的新 adapter,内部随机初始化。 |
| 4 | 训练结束后,通过 --adapter_name_or_path old_adapter,new_adapter 可在推理时组合或单独调用。 |
总结:“勾上新建适配器,就是在老 LoRA 上再盖一层‘新被子’,旧的不动,只练新的。”
2.3.6 使用 rslora

勾选后,框架会采用 秩稳定 LoRA(rsLoRA) 的缩放策略,把传统 LoRA 的
ΔW = (lora_alpha / lora_rank) · B·A
改为
ΔW = (lora_alpha / sqrt(lora_rank)) · B·A
优势 :
- 当
lora_rank较大时,梯度不再因分母过大而消失,训练更稳定; - 允许使用更高的 rank(32、64 甚至 128)而不崩溃,实验显示在 rank ≥ 16 时仍能带来额外性能提升 。
使用方式 :
- WebUI 勾选 “使用 rslora”;
- 无需改代码,框架自动替换缩放因子;
- 建议同步把
lora_alpha设得与lora_rank同量级(例如 rank=32 ⇒ alpha=32),再按需要微调学习率即可 。
总结:“勾上 rslora,就能把缩放因子从 ‘除 rank’ 换成 ‘除 √rank’,高秩也稳!”
2.3.7 使用 DoRA

勾选后,LoRA 不再直接学习「ΔW」,而是把原始权重矩阵 W 先分解为 幅度向量 m 与 方向矩阵 V,再对方向部分加 LoRA 低秩扰动:
W = m ⊙ V
ΔW = ΔV (LoRA)
优势:
- 训练稳定性更高,尤其在大 rank、长序列或强化学习任务中。
- 推理阶段可把幅度向量与方向矩阵融合回原始权重,零额外延迟。
- 与量化、梯度累积、DeepSpeed ZeRO 完全兼容。
使用方式 :
- WebUI 勾选 “使用 DoRA”;
- 保持原有
lora_rank/lora_alpha即可,无需额外超参; - 若想关闭,只需取消勾选,权重即回退到普通 LoRA。
总结:“DoRA 把权重拆成‘方向+大小’,只练方向,更稳更快,勾上即用,无推理成本。”
2.3.8 使用 PiSSA

把预训练权重矩阵 W 做奇异值分解(SVD),只保留前 r 个主奇异值/向量作为 初始化 的 LoRA A、B 矩阵,其余信息冻结。
效果:
- 相比随机初始化的 LoRA,收敛更快(步数↓30 %–50 %)
- 同样秩下,下游指标↑0.5–2 %(尤其 rank ≤ 16)
代价: 首次启动需额外一次 SVD 计算(可在 CPU 上完成,耗时几分钟~十几分钟)。
使用方式 :
- WebUI 勾选 “使用 PiSSA”
- 保持
lora_rank不变即可;框架自动:- 对指定层做 SVD → 取前 r 奇异值 → 初始化 A、B
- 冻结剩余奇异向量
- 后续训练与普通 LoRA 完全一致;推理时可合并权重。
总结:“PiSSA = 把预训练权重的主成分直接拿来当 LoRA 初值,起跑更快,效果更稳,勾上即可。”
2.3.9 LoRA 作用模块

告诉框架“把 LoRA 插到哪些层里”,只有匹配到的模块才会被替换成 LoRA 形式;其余权重保持冻结或原始形式。
填写格式:
- 模块的 注册名 或 正则表达式,多个名称用英文逗号隔开,不含空格。
- 留空表示使用当前模型的默认列表(不同模型默认不同)。
常见模型的默认/推荐填写
| 模型系列 | 推荐填写示例 | 说明 |
|---|---|---|
| Llama-2 / CodeLlama | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
覆盖全部 Attention & MLP |
| Baichuan-2 | W_pack,o_proj,gate_proj,up_proj,down_proj |
Baichuan 把 qkv 打包成 W_pack |
| ChatGLM-3 | query_key_value,dense,dense_h_to_4h,dense_4h_to_h |
GLM 的命名风格 |
| Qwen-7B | c_attn,c_proj,w1,w2 |
Qwen 内部命名 |
| Bloom | query_key_value,dense,dense_h_to_4h,dense_4h_to_h |
与 GLM 类似 |
| 只想做 qkv 实验 | q_proj,v_proj,k_proj |
最小集合,显存最省 |
如何查看自己模型的可用名
from transformers import AutoModel
model = AutoModel.from_pretrained("your-model")
for name, _ in model.named_modules():
print(name)
把想要加 LoRA 的层名复制进来即可。
总结:“LoRA 作用模块就是‘点名’:把要插低秩 Adapter 的层名写进来,逗号隔开,不写就按模型默认。”
2.3.10 附加模块

在已经指定了 LoRA 作用模块(lora_target)之外,再额外放开一些层或组件参与训练,它们将不采用 LoRA 低秩分解,而是全参数更新。
- 填写的仍是模块名称或正则表达式,多个用英文逗号分隔。
- 这些模块与 LoRA 层同时生效:前者全量可训,后者保持低秩,可看作“LoRA + 少量全参”的混合微调。
常见填写示例:
| 目的 | 示例填写 | 解释 |
|---|---|---|
| 让 LayerNorm 也一起更新 | norm,layer_norm |
低秩之外顺带调分布 |
| 让输出头(lm_head)全参 | lm_head |
词表扩充后一起训练 |
| 让嵌入层全参 | embed_tokens |
新 token 直接更新,不经过 LoRA |
| 让 bias 全部可训 | .*bias |
几乎不占显存,又能微调细节 |
| MoE 模型更新 router | gate |
专家路由不插 LoRA,直接全参 |
总结:“附加模块就是给 LoRA 之外的少数关键层开‘全参绿灯’,写名字即可,与低秩层井水不犯河水。”
2.4 RLHF 参数设置

2.4.1 Beta 参数

在 DPO(Direct Preference Optimization) 或 KTO(Kahneman-Tversky Optimization) 等偏好对齐损失函数中,控制对「偏好差异」的惩罚强度。
- 数值越大:模型对“chosen vs rejected”差异越敏感,训练更保守,但可能过拟合;
- 数值越小:差异惩罚更宽松,训练更激进,可能生成更多样但风险更高的回答。
默认值
- DPO:0.1
- KTO:0.1
经验区间:
| 任务 | 推荐 β | 说明 |
|---|---|---|
| 通用对话 DPO | 0.1–0.5 | 默认 0.1 已足够 |
| 安全对齐 | 0.5–1.0 | 更强惩罚,减少有害输出 |
| 创意写作 | 0.01–0.1 | 允许更大差异,鼓励多样性 |
| KTO | 0.1–0.2 | 与 DPO 类似,视正负样本比例微调 |
总结:“β 就是 DPO/KTO 的‘紧箍咒’:0.1 通用,想更保守就 0.5,要放开就 0.01。”
2.4.2 Ftx gamma

在 RLHF(PPO、DPO、KTO 等) 或某些混合损失函数里,给 SFT(监督微调)损失 项分配一个权重系数,用于平衡「偏好对齐」与「原始指令遵循」这两股信号。
- 公式示例(DPO 混合损失):
Loss = β · DPO_loss + γ · SFT_loss
其中 γ 即 Ftx gamma。 - 值越大,模型更偏向保持原有指令遵循能力;值越小,侧重偏好对齐。
默认值 0(即不额外引入 SFT 损失,仅用偏好损失)。
经验值 :
| 场景 | 推荐 γ | 说明 |
|---|---|---|
| 纯 DPO / KTO | 0 | 默认即可 |
| 混合损失(避免对齐后指令能力下降) | 0.1–1.0 | 逐步增大,监控指令评测集指标 |
| 强化学习阶段继续 SFT | 0.5–2.0 | 在 reward 信号噪声大时,用 SFT 损失做正则 |
| 继续预训练 + RLHF | 1.0–5.0 | 防止大规模偏好数据淹没通用知识 |
总结:“Ftx gamma 就是给 SFT 损失‘加秤’:0 只对齐,1 左右保指令,5 以上防灾难遗忘。”
2.4.3 损失类型

指定在 DPO / KTO / ORPO / SimPO 等偏好对齐阶段 实际采用的 损失函数公式,直接影响模型如何比较「chosen」与「rejected」样本的优劣。
| 选项 | 全称 / 核心思想 | 场景一句话 |
|---|---|---|
| sigmoid | DPO-sigmoid(标准) | 最常用,默认即可 |
| hinge | DPO-hinge(合页损失) | 想更严格地拉开 chosen-rejected 差距 |
| ipo | IPO(Identity-Preserved Optimization) | 防止过拟合,收敛更稳 |
| kto_pair | KTO-pair(Kahneman-Tversky) | 正负样本成对出现时用 |
| orpo | Odds-Ratio Preference Optimization | 无需参考模型,单模型即可对齐 |
| simpo | SimPO(Simple Preference Optimization) | 简化的无参考模型损失,训练更快 |
使用提示
- 只有训练阶段为 DPO / KTO / ORPO / SimPO 时该参数才生效。
- 选错损失类型通常不会报错,但可能导致指标下降或训练不收敛。
- 若不确定,优先 sigmoid;想实验无参考模型可试 orpo 或 simpo。
总结:“损失类型就是‘比较优劣的尺子’:DPO 用 sigmoid,无参考模型用 orpo/simpo,想稳一点用 ipo。”
2.4.4 奖励模型

在 PPO 强化学习阶段,告诉训练器去 哪里加载为当前任务专门训练好的奖励模型。
- 它必须是一个 LoRA 适配器目录(含
adapter_config.json和adapter_model.bin),而不是完整权重。 - 路径可以是
– 本地绝对/相对路径:
– Hugging Face Hub 上的 adapter 仓库:./saves/qwen-7b-rm-loratrl-lib/llama-7b-hh-rm-adapter
使用注意
- 奖励模型必须与 策略模型(Actor)同架构(同 tokenizer、同隐藏层尺寸)。
- 若路径留空,PPO 训练会报错或退回到虚拟奖励(仅用于冒烟测试)。
- 如果奖励模型是 完整权重(非 LoRA),需先用
peft.get_peft_model再保存为 adapter 后才能填在此处。
总结:“奖励模型就是填 LoRA 奖励适配器的地址,本地或 Hub 都行,PPO 用它来打分。”
2.4.5 归一化分数

在 PPO 的每一次 rollout 后,把奖励模型给出的原始奖励分数做 均值-方差标准化(减去 batch 均值再除以 batch 标准差),使奖励分布近似 N(0,1)。
- 勾选(true)
- 奖励尺度统一,避免不同 batch 间量级差异导致策略更新震荡;
- 默认推荐,尤其当奖励模型输出范围不稳定时。
- 不勾选(false)
- 使用原始奖励数值,要求奖励模型已校准到合理范围;
- 若奖励绝对值过大/过小,可能导致梯度爆炸或训练无进展。
总结:“归一化分数就是给奖励打 z-score,true 保稳,false 省事但要求奖励模型已校准。”
2.4.6 白化奖励

在 PPO 训练中,把奖励模型给出的原始奖励进一步做 白化处理(Whiten):
- 先减去当前 batch 的均值;
- 再除以 batch 标准差;
- 可选地加入极小 ε 防止除零。
结果使奖励分布近似 N(0,1),消除不同 prompt 或 batch 间尺度差异,提升梯度稳定性。
开关方式:
- 勾选(true):启用白化,推荐在奖励幅度差异大或 prompt 长度分布广的场景。
- 不勾选(false):保留原始奖励尺度,适合已校准的奖励模型或与
normalize_reward二选一。
总结:“白化奖励就是‘标准化 z-score’,开 true 让奖励更稳,关 false 用原始尺度。”
2.5 多模态参数设置
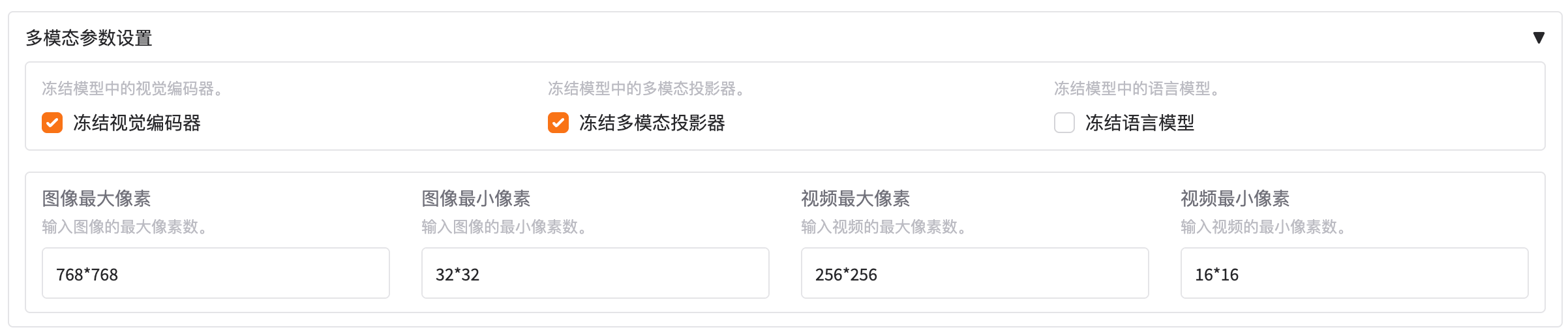
2.5.1 冻结视觉编码器
 在多模态模型(如 LLaVA、Qwen-VL、MiniGPT-4 等)里,锁定视觉编码器(Vision Encoder / CLIP-ViT)的全部权重,使其在训练过程中不接收梯度、不更新参数。
在多模态模型(如 LLaVA、Qwen-VL、MiniGPT-4 等)里,锁定视觉编码器(Vision Encoder / CLIP-ViT)的全部权重,使其在训练过程中不接收梯度、不更新参数。
- 勾选(true):
‑ 视觉编码器完全冻结,仅训练语言模型或新增的投影层/LoRA,大幅节省显存与计算。
‑ 适用于 图文对齐已充分、只需微调语言侧的场景。 - 不勾选(false,默认):
‑ 视觉编码器随语言模型一起训练,可学习更细粒度的图文特征,但显存与耗时显著增加。
总结:“冻结视觉编码器就是把图像侧‘锁死’,只让文本侧继续上课,省显存、提速度。”
2.5.2 冻结多模态投影器
 在多模态模型(如 LLaVA、Qwen-VL 等)里,锁定“视觉 → 语言”映射层(通常是一个或若干线性/MLP 投影器)的参数,使其在训练过程中 不更新。
在多模态模型(如 LLaVA、Qwen-VL 等)里,锁定“视觉 → 语言”映射层(通常是一个或若干线性/MLP 投影器)的参数,使其在训练过程中 不更新。
- 勾选(true):
– 投影器保持预训练权重,只训练语言模型或 LoRA,显存占用更小;
– 适合 图文对齐已较好、仅需调整语言侧的场景。 - 不勾选(false,默认):
– 投影器随语言模型一起训练,可进一步优化视觉特征与文本空间的匹配,代价是显存和时间增加。
总结: “冻结投影器就是把‘图像转文字’的桥梁锁死,只让文本端继续微调,省显存、提速度。”
2.5.3 冻结语言模型

在多模态模型(如 LLaVA、Qwen-VL 等)中,锁定语言模型(LLM 主干)的全部权重,使其在训练过程中不接收梯度、不更新参数。
- 勾选(true):
– 仅训练视觉编码器、投影器或新增适配器,用于视觉端微调或图文对齐校准;
– 显存需求大幅下降,训练速度极快。 - 不勾选(false,默认):
– 语言模型继续参与训练,可学习更细粒度的图文融合特征,但显存与耗时显著增加。
总结: “冻结语言模型就是把文本主干‘锁死’,只让图像端或投影器继续上课,省显存、提速度。”
2.5.4 图像最大像素

限制单张输入图像的 总像素数(宽 × 高)。
• 超出限定的图像会被等比例缩放到该像素以下,防止显存爆炸。
• 单位为 像素(pixels),不是 MB 或 token 数。
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 短视频帧 / 小图 | 50 000–100 000 | 默认即可 |
| 高分辨率文档 OCR | 200 000–400 000 | 需显卡 ≥ 24 GB |
| 4K 图 | 800 000+ | 需显卡 ≥ 40 GB + 梯度累积 |
| 显存紧张 | ≤ 50 000 | 先跑通流程 |
总结:“图像最大像素就是‘一张图最多多少点’,显存够就调大,不够就缩小。”
2.5.5 图像最小像素

过滤掉总像素(宽 × 高)小于该阈值的图像,防止模型在训练/推理阶段处理过小的低质量图片而浪费显存或引入噪声。
• 单位为 像素(pixels)。
• 低于阈值的样本会被自动丢弃,不参与后续处理。
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 通用微调 | 0 或留空 | 不丢弃任何图像 |
| 高质量数据集 | 10 000(≈100×100) | 剔除缩略图、图标 |
| 文档 OCR | 50 000(≈224×224) | 保证文字清晰 |
| 极端过滤 | 100 000(≈320×320) | 仅保留高分辨率图 |
总结:“图像最小像素就是‘低于多少点的图直接扔掉’;默认 0 不扔,想筛低清图就调大。”
2.5.6 视频最大像素

限制 单段输入视频 在任意一帧中的最大像素数(宽 × 高)。
- 超过此阈值的帧会被 等比例缩放 至该像素以下,防止显存爆炸。
- 单位为 像素(pixels),与图像的
max_image_pixels逻辑一致。 - 仅对 逐帧采样 的视频输入生效;若模型采用时空池化或其他降采样策略,仍需先满足该上限。
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 短视频/低清 | 100 000–200 000 | 默认够用 |
| 高清 1080p | 400 000–500 000 | 需单卡 ≥ 24 GB |
| 4K 视频 | 800 000+ | 需多卡或帧间降采样 |
| 显存紧张 | ≤ 100 000 | 先跑通流程再放大 |
总结:“视频最大像素就是‘每帧最多多少点’,显存够就调大,不够就压小。”
2.5.7 视频最小像素

过滤掉任何一帧像素数(宽 × 高)小于该阈值的视频片段,避免模型在训练或推理阶段处理分辨率过低、质量过差的视频帧而浪费显存或引入噪声。
- 单位为 像素(pixels)。
- 低于阈值的视频会被整段丢弃,不进行后续处理。
总结:“视频最小像素就是‘每帧低于多少点直接整段扔掉’;默认 0 不扔,想过滤低清视频就调大。”
2.6 GaLore 参数设置

2.6.1 使用 GaLore

勾选后,LaMa-Factory 会把 GaLore 优化器(Gradient Low-Rank Projection,梯度低秩投影)注入训练流程,实现全参数微调级别的性能却只消耗 LoRA 级显存。
- 核心思想:在 优化器状态 层面做 梯度低秩投影,而不是像 LoRA 那样改模型权重。
- 适配器无关:可同时搭配 LoRA、DoRA、PiSSA 等,也可单独使用。
- 支持 AdamW、8-bit AdamW、Adafactor 等常用优化器,只需在额外参数里指定
galore_optim。 - 官方测试:7B 模型在 24 GB 单卡即可全参训练,显存节省 ≈ 50 %–70 %。
如何启用:
- WebUI 勾选「使用 GaLore」。
- 在「额外参数」填:
{
"optim": "galore_adamw",
"galore_rank": 1024,
"galore_scale": 0.25,
"update_proj_gap": 200
}
• galore_rank:投影秩大小,常用 512–1024;
• galore_scale:缩放系数,0.25 为经验值;
• update_proj_gap:每多少步更新一次投影矩阵。
总结: “勾上 GaLore,就能在 24 GB 单卡‘全参’训练 7B,显存省一半,效果不打折。”
2.6.2 GaLore 秩

作用:指定 GaLore 优化器在做梯度低秩投影时的秩大小。
- 数值越大 → 梯度近似越精确,训练更稳,但显存节省幅度减小。
- 数值越小 → 显存压缩更明显,可能损失精度。
总结:“GaLore 秩就是压缩梯度的‘宽度’:7B 用 1024,大模型再放大,省显存但别太省。”
2.6.3 更新间隔

在 GaLore 优化器里,每隔多少步重新计算一次梯度低秩投影矩阵(U、V)。
- 步数越小 → 投影矩阵更新越频繁,近似更精确,但额外计算开销增高;
- 步数越大 → 计算量减少,显存更省,但长时间不更新可能积累误差。
经验区间
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 7B/13B 通用微调 | 200–500 | 稳定且高效 |
| 大模型 30B+ | 500–1000 | 计算开销敏感 |
| 超大规模继续预训练 | 1000–2000 | 重计算代价高 |
| 快速实验/调试 | 50–100 | 验证收敛即可 |
总结:“更新间隔就是‘多少步重算一次投影’,默认 200,大模型可 1000,调试可 50。”
2.6.4 GaLore 缩放系数

控制 GaLore 优化器在每次更新时对低秩梯度投影结果的 整体放大/缩小倍数,相当于对梯度更新量进行 全局缩放。
- 值越大 → 每次更新步长越大,收敛可能更快,但也更容易震荡。
- 值越小 → 更新更保守,训练更稳,但可能收敛变慢。
总结:“GaLore 缩放系数就是给梯度更新量‘加音量’:默认 0.25,稳;想快可 0.5,怕震就 0.1。”
2.6.5 GaLore 作用模块

指定 哪些网络模块 的梯度需要被 GaLore 低秩投影 处理;其余模块仍按常规全梯度更新。
• 填写方式:模块的 注册名 或 正则表达式,多个用英文逗号分隔,留空则使用框架默认列表。
• 仅对 GaLore 优化器 生效;与普通 LoRA 的 lora_target_modules 独立。
常见填写示例
| 模型系列 | 推荐填写 | 说明 |
|---|---|---|
| Llama-2/3 | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
对 Attention & MLP 全做低秩梯度投影 |
| Baichuan-2 | W_pack,o_proj,gate_proj,up_proj,down_proj |
Baichuan 把 qkv 打包成 W_pack |
| ChatGLM-3 | query_key_value,dense,dense_h_to_4h,dense_4h_to_h |
对应 GLM 命名 |
| 仅投影 FFN | gate_proj,up_proj,down_proj |
显存再省一点 |
| 正则写法 | .*\.attention.*,.*\.mlp.* |
一次匹配所有 Attention 和 MLP |
总结:“GaLore 作用模块就是‘点名’:告诉 GaLore 该把低秩投影插到哪些层里,逗号隔开即可。”
2.7 APOLLO参数设置

2.7.1 使用APPOLO
使用APPOLO:使用 APOLLO 优化器,https://github.com/zhuhanqing/APOLLO
在 LLaMA-Factory 中勾选后,框架会把 APOLLO 优化器(Approximated Gradient Scaling for Memory-Efficient LLM Optimization)注入训练流程,实现 SGD 级别的显存占用 却保持 AdamW 级别的收敛效果,适用于 全参数预训练 / 微调。
关键超参(在「额外参数」中以 JSON 填写)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| optim | string | "apollo_adamw" |
优化器名称(已集成到 HF Trainer) |
| apollo_rank | int | 256(APOLLO) / 1(APOLLO-Mini) | 梯度低秩子空间秩大小 |
| apollo_scale_type | string | "channel" |
channel(APOLLO) 或 tensor(APOLLO-Mini) |
| apollo_scale | int | 1(channel) / 128(tensor) | 缩放因子,补偿低秩近似误差 |
| update_proj_gap | int | 200 | 重新计算投影矩阵的步数间隔 |
| scale_front | bool | false | 是否在缩放前应用 Norm-Growth Limiter |
典型用法(7B 单卡 24 GB 微调示例)
{
"optim": "apollo_adamw",
"apollo_rank": 1024,
"apollo_scale_type": "channel",
"apollo_scale": 1,
"update_proj_gap": 200,
"scale_front": false
}
总结:“勾上‘使用 APOLLO’,再配 4 个超参,就能在 24 GB 单卡全参训 7B:显存省到 SGD 级,效果仍是 AdamW 级。”
2.7.2 APOLLO 秩
APOLLO 秩:APOLLO 梯度的秩大小。
指定 APOLLO 优化器在做“梯度低秩投影”时所使用的 秩大小(rank of the auxiliary sub-space)。
• 数值越大 → 近似精度越高,收敛更稳,但显存节省幅度减小。
• 数值越小 → 显存压缩更极致,可能带来精度损失。
官方默认值
- APOLLO(channel-wise):256
- APOLLO-Mini(tensor-wise):1
经验值速查
| 模型规模 | 推荐秩 | 说明 |
|---|---|---|
| 60 M–1 B | 64–128 | 小模型秩可低 |
| 7 B | 256–1024 | 单卡 24 GB 常用 1024 |
| 13 B | 512–2048 | 秩过小易失真 |
| 30 B+ | 1024–4096 | 大模型需更高秩保精度 |
总结:“APOLLO 秩就是梯度投影的‘宽度’:7B 常用 1024,越大越稳,越小越省。”
2.7.3 更新间隔
更新间隔:相邻两次投影更新的步数。
在 APOLLO 优化器中,每隔多少步重新计算一次梯度低秩投影矩阵(即更新辅助子空间)。
- 间隔越小 → 投影矩阵紧跟梯度变化,近似更准确,但计算开销增大;
- 间隔越大 → 计算量减少,显存更省,但长时间不更新可能累积误差。
默认值 :200 步(官方脚本与社区实践的折中值)。
经验区间
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 7B/13B 通用微调 | 200–500 | 稳定且高效 |
| 大模型 30B+ | 500–1000 | 减少额外计算 |
| 超长序列/高分辨率 | 100–200 | 梯度变化快,频繁更新更稳 |
| 快速调试 | 50–100 | 验证收敛即可 |
总结:“更新间隔就是隔多少步重算一次投影:默认 200,大模型可 1000,调试可 50。”
2.7.4 APOLLO 缩放系数
APOLLO 缩放系数:APOLLO 缩放系数大小。
在 APOLLO 优化器内部,用于 补偿低秩近似带来的梯度幅度误差。
- 数值越大 → 梯度更新步子更大,收敛更快,但过大可能震荡;
- 数值越小 → 步子更稳,但收敛变慢。
官方默认值
- APOLLO(channel-wise) apollo_scale = 1.0
- APOLLO-Mini(tensor-wise) apollo_scale = 128.0
经验设置
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 7B 模型微调 | 1.0–2.0 | 与官方脚本一致 |
| 13B 模型 | 1.0–4.0 | 略放大补偿 |
| APOLLO-Mini | 128.0–256.0 | 默认 128,可线性放大 |
| 长序列/高分辨率 | 1–4(channel)/ 128–512(tensor) | 视显存与梯度幅度再调 |
总结:“APOLLO 缩放系数就是给梯度‘音量旋钮’:channel 模式默认 1,tensor 模式默认 128,显存紧就下调,震荡就上调。”
2.7.5 APOLLO 作用模块
APOLLO 作用模块:应用 APOLLO 的模块名称。使用英文逗号分隔多个名称。
告诉 APOLLO 优化器 “对哪些网络层/模块做梯度低秩投影”。
- 填写方式:模块的 注册名 或 正则表达式,多个名称用英文逗号隔开。
- 未列出的模块将保持常规全梯度更新;留空则使用官方默认列表(通常覆盖 Attention 与 MLP)。
常见填写示例
| 模型 | 推荐填写 | 说明 |
|---|---|---|
| Llama-2/3 | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
对全部 Attention & MLP 使用 APOLLO |
| Baichuan-2 | W_pack,o_proj,gate_proj,up_proj,down_proj |
Baichuan qkv 打包为 W_pack |
| ChatGLM-3 | query_key_value,dense,dense_h_to_4h,dense_4h_to_h |
GLM 命名风格 |
| 只投影 FFN | gate_proj,up_proj,down_proj |
显存再省一点 |
| 正则写法 | .*\.attention.*,.*\.mlp.* |
一次性匹配所有 Attention 和 MLP |
总结:“APOLLO 作用模块就是‘点名’:告诉优化器该对哪些层做梯度低秩投影,逗号隔开即可。”
2.8 BAdam 参数设置

2.8.1 使用 BAdam
使用 BAdam:使用 BAdam 优化器,https://github.com/Ledzy/BAdam
勾选后,LaMa-Factory 会把 BAdam 优化器(Block-coordinate Adam)接入训练流程,实现 “逐块 Adam” 更新:
- 每次只对 一个 Transformer 层(或自定义块) 做完整 Adam 更新,其余参数冻结;
- 循环遍历所有块,内存峰值 ≈ 2 GB + 16 GB / D(Llama-7B 约 22 GB);
- 单卡 24 GB 即可全参微调 7B/8B,且效果优于 LoRA。
如何启用
- WebUI 勾选「使用 BAdam」。
- 在「额外参数」填写:
{
"optim": "badam",
"switch_block_every": 100,
"switch_mode": "random"
}
• switch_block_every:每训练多少步后切换到下一块(默认 100)。
• switch_mode:切换顺序,random / ascending / descending。
总结:“勾上 BAdam,再设
switch_block_every,就能 24 GB 单卡全参训 7B:一块一块地跑 Adam,省显存还比 LoRA 好用。”
2.8.2 BAdam 模式
BAdam 模式:使用 layer-wise 或 ratio-wise BAdam 优化器。(layer、ratio)
决定 BAdam 优化器把模型切成“层块(layer-wise)”还是“比例块(ratio-wise)”来逐块训练。
- layer(默认)
按 Transformer 层划分,每层为一个块;块数 = 层数,更新顺序清晰,BP 时间最省。 - ratio
每层只取固定 比例参数 组成跨层混合块(例如 10 % 参数/块),块数更多,显存再降,但 BP 开销略高。
总结:“选 layer 按层切块,简单高效;选 ratio 按比例跨层切,更省显存但稍慢。”
2.8.3 切换策略
切换策略:Layer-wise BAdam 优化器的块切换策略(ascending、descending、random、fixed)。
2.8.4 切换频率
切换频率:Layer-wise BAdam 优化器的块切换频率。
决定 Layer-wise BAdam 在逐层更新时,按什么顺序依次切换各层(块)。
- ascending 从输入层 → 输出层(第 0 层 → 最后一层)顺序更新。
- descending 从输出层 → 输入层逆向更新。
- random (默认)每次随机打乱层序,打散相关性,收敛更稳。
- fixed 按预设固定顺序循环,通常用于调试或复现实验。
总结:“顺序升 ascending,逆序 descending,随机 random(推荐),固定 fixed 调试用。”
2.8.5 Block 更新比例
Block 更新比例:Ratio-wise BAdam 优化器的更新比例
仅在 BAdam 模式 = ratio 时生效。
指定“每一次活跃块”占 每层参数总量的百分比(0–1 之间的小数)。
• 值越大 → 每块包含的参数越多,显存需求↑,但训练步数↓;
• 值越小 → 每块更稀疏,显存峰值↓,训练步数↑。
经验值
| 场景 | 推荐比例 | 说明 |
|---|---|---|
| 单卡 24 GB 微调 7B | 0.1–0.2 | 显存与速度平衡 |
| 显存极度紧张 | 0.05–0.1 | 再省显存,但需更多步 |
| 多卡大 batch | 0.2–0.4 | 充分利用并行带宽 |
总结:“Block 更新比例就是‘每块抠多少参数’:显存紧写 0.1,宽裕写 0.2,越小越省越大越快。”
2.9 SwanLab 参数设置

2.9.1 使用 SwanLab
使用 SwanLab:启用 SwanLab 进行实验跟踪和可视化,https://swanlab.cn/
2.9.2 SwanLab 项目名
SwanLab 项目名:
一键把 LLaMA-Factory 的训练日志、超参、指标、硬件信息实时同步到 SwanLab 云端,提供 可视化仪表盘、实验对比、多人协作 与 离线缓存 功能。
如何启用
- WebUI 勾选「使用 SwanLab」。
- 首次运行会提示输入 API Key:
swanlab login
或在「额外参数」里直接写:
{
"report_to": "swanlab",
"swanlab_project": "llama-factory-exp",
"swanlab_experiment_name": "sft-7b-lora"
}
- 训练启动后,终端会给出实验链接,点击即可在浏览器查看实时曲线、GPU 使用率、生成样本等。
总结:“勾上 SwanLab,扫码登录,训练指标实时上云,链接一甩,同事直接看结果。”
2.9.3 SwanLab 实验名
SwanLab 实验名(非必填):
为本次训练在 SwanLab 云端创建一条独立的实验记录,方便后续在仪表盘里快速定位、对比或分享。
- 留空 → 系统自动生成一串时间戳 + 随机字符(可读性差)。
- 填写 → 支持中英文、数字、下划线、连字符,如
llama2-7b-lora-sft-v1。
示例
qwen3-8b-dpo-beta0.1
baichuan-13b-pretrain-stage1
总结:“想给 SwanLab 里的实验起个好听的名字,就填;不填系统自动乱码。”
2.9.4 SwanLab 工作区
SwanLab 工作区(非必填):SwanLab 的工作区,默认在个人工作区下。
指定本次实验在 SwanLab 云端归属的 工作区 / 组织空间。
- 留空(默认)→ 实验落在 个人工作区。
- 填写组织名(如
nlp-lab、company-ai)→ 实验自动归入对应组织,方便 团队共享、权限管理与统一计费。 - 组织名需先在 SwanLab 后台创建,且当前账号具备写入权限。
示例
nlp-lab
company-ai
总结:“想把自己跑的实验放进团队公共目录,就把组织名填进来;不填就留在个人空间。”
2.9.5 SwanLab API 密钥
SwanLab API 密钥(非必填):用于在编程环境登录 SwanLab,已登录则无需填写。
2.9.6 SwanLab 模式
SwanLab 模式:使用云端版或离线版 SwanLab。(分为 cloud和local)
在非浏览器环境(如远程服务器、离线脚本、CI/CD)登录 SwanLab 时,用这把密钥完成身份验证,实现自动上传日志与指标。
- 已在本机执行过
swanlab login或已配置环境变量SWANLAB_API_KEY→ 可留空。 - 未登录 → 需填写 32 位字符串密钥,可从 SwanLab 控制台「个人设置 → API Key」复制。
填写示例 :
sl_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
总结:“服务器上跑实验时,把 SwanLab 的 API Key 粘进来,就能免浏览器一键上传。”
2.10 其它
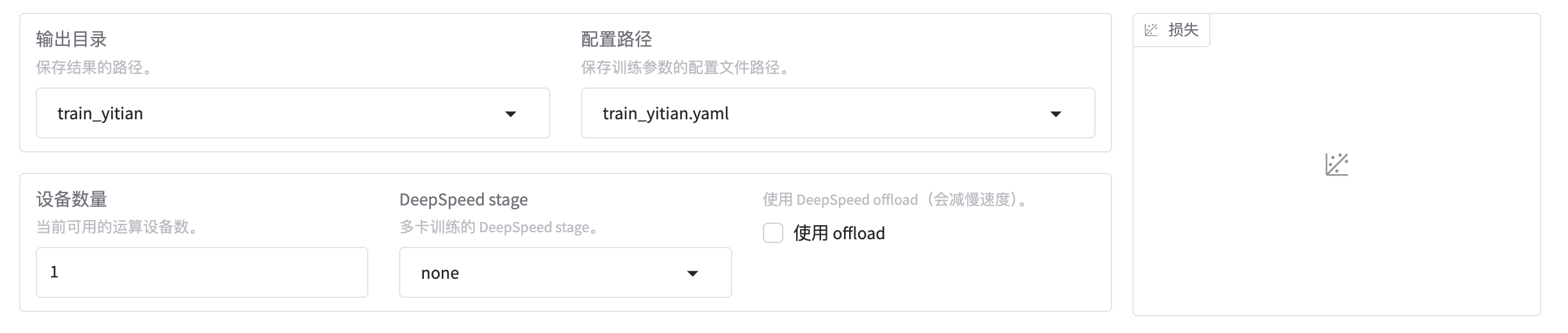
2.10.1 输出目录
输出目录:保存结果的路径。
指定训练或推理完成后,所有结果文件(模型权重、配置、日志、检查点、可视化图表等)的保存根目录。
- 支持绝对路径或相对路径;若目录不存在,框架会自动创建。
- 留空时,默认使用
./outputs/<timestamp>,防止覆盖旧实验。
常见示例
| 场景 | 示例路径 | 说明 |
|---|---|---|
| 本地快速实验 | ./runs/exp-07-13 |
相对路径,易备份 |
| 多实验并行 | ./outputs/llama2-7b-lora-sft-001 |
按实验命名 |
| 云端挂载盘 | /mnt/data/models/baichuan-13b-dpo |
绝对路径,持久化 |
| 团队共享 | /shared/llama-factory/outputs/qwen3-8b-pretrain |
统一目录,方便协作 |
总结:“输出目录就是‘所有训练成果打包放哪’,写清路径,方便下次找模型。”
2.10.2 配置路径
配置路径:保存训练参数的配置文件路径。
告诉 LaMa-Factory 去哪里读取一份完整的 YAML 或 JSON 训练配置,把 WebUI 里没展示或难以一次性填写的超参数一次性加载进来。
- 文件可以是本地绝对/相对路径,也可以是 Hugging Face Hub 上的配置文件。
- 如果同时填写了 WebUI 字段,文件里的值优先级更高,可用来快速复现实验或在集群脚本中调用。
常见示例
# 本地文件
./configs/llama2-7b-lora-sft.yaml
# 相对路径
configs/qwen3-8b-dpo.json
# Hub 上的公共配置
hza/llama-factory-configs/llama3-8b-pretrain.yaml
总结:“配置路径就是‘一键导入超参’:把写好的 YAML/JSON 指给它,WebUI 没填的也能生效。”
2.10.3 设备数量
设备数量:当前可用的运算设备数。
告诉 LaMa-Factory 当前可用于训练/推理的 GPU(或 NPU/CPU)总数。
- 自动检测:通常为
torch.cuda.device_count()的结果;在 WebUI 留空或填auto即可让框架自动识别。 - 手动指定:当使用 CPU 训练、容器限额、或手工切分 时,可强制写成具体数字(如
4)。 - 影响逻辑:决定 DataParallel / DeepSpeed ZeRO / FSDP 的并行规模;若与真实卡数不符会报错或 OOM。
总结:“设备数量就是‘手上有几张卡’;默认 auto,让系统自己数,特殊环境再手写。”
2.10.4 DeepSpeed stage
DeepSpeed stage:多卡训练的 DeepSpeed stage。
指定 多卡训练 时 DeepSpeed 的并行策略(ZeRO stage),决定 模型、梯度、优化器状态 在 GPU 之间的切分粒度。
- 数字越大 → 显存越省,通信量越高;需与 device_count、batch_size、显存容量 匹配。
可选值
| stage | 全称 | 切分内容 | 显存节省 | 适用场景 |
|---|---|---|---|---|
| 0 | ZeRO-0 | 不切分,普通 DDP | 0 % | 小模型/调试 |
| 1 | ZeRO-1 | 仅优化器状态切分 | 中等 | 中等模型 |
| 2 | ZeRO-2 | 优化器 + 梯度切分 | 高 | 7B–13B 常见 |
| 3 | ZeRO-3 | 模型 + 梯度 + 优化器 | 最高 | 30B+ / 长序列 |
总结:“DeepSpeed stage 就是‘显存救命档位’:7B 用 2,30B 用 3,调试用 0。”
2.10.5 使用 offload
使用 offload:使用 DeepSpeed offload(会减慢速度)。
把 优化器状态 和/或 模型参数 从显存 卸载到 CPU 内存或 NVMe,进一步降低 GPU 显存需求。
- 勾选(true)
– 显存可再省 30 %–70 %,单卡即可跑超大模型/超长序列;
– 训练速度会明显下降(CPU ↔ GPU 拷贝)。 - 不勾选(false,默认)
– 所有状态保留在显存,速度最快,但需足够显存。
总结:“显存爆了就开 offload:参数搬 CPU,省显存但慢;速度优先就关掉。”
3. 评估与预测(Evaluate&Predict)
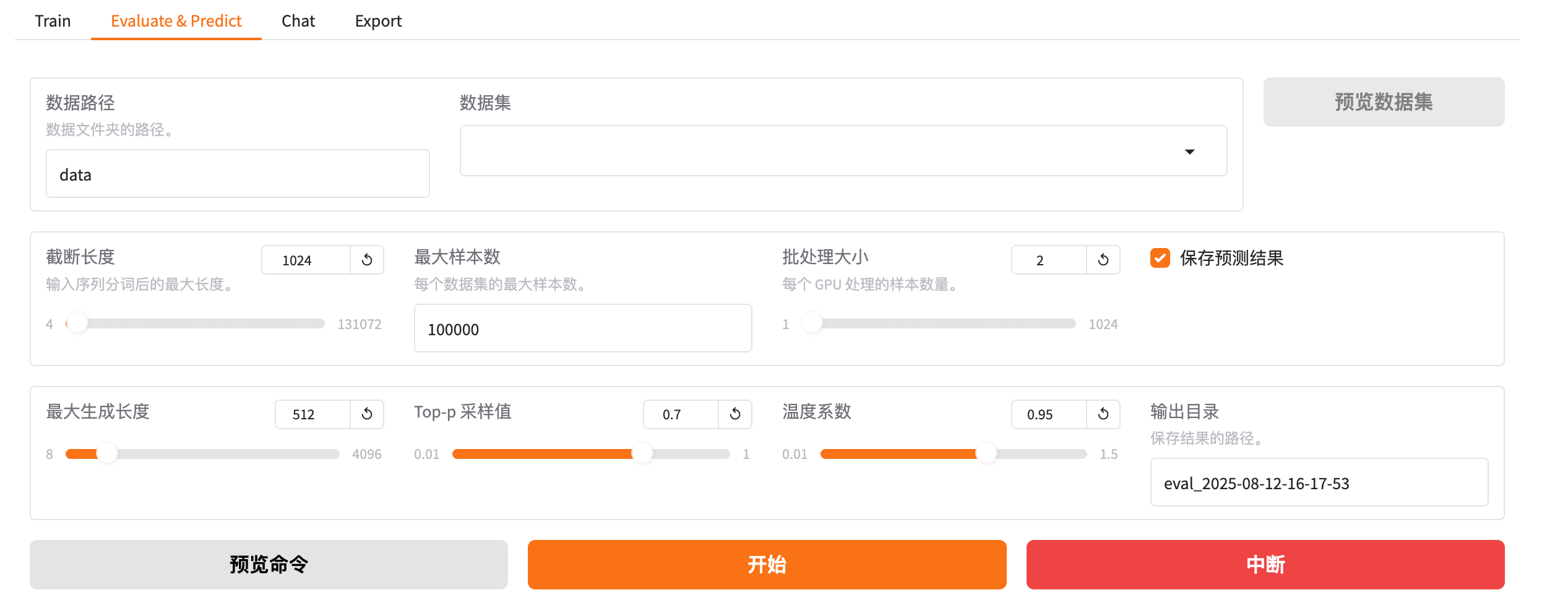
3.1 数据路径

告诉 LaMa-Factory 去哪个本地或云端目录读取用于 评估(evaluate)或预测(predict) 的样本文件。
- 支持绝对路径、相对路径或 Hugging Face Hub 数据集标识符。
- 目录内需包含符合模板的数据文件(如
jsonl / txt / csv)以及可选的dataset_info.yaml描述字段映射。
示例
./data/eval/alpaca_eval
./data/benchmarks/mmlu
/ceph/user/eval_sets/safety_zh
总结:“评估与预测数据路径就是‘放测试题的地方’;指到目录,模型才知道去哪拿题打分。”
3.2 数据集

指定在 评估(evaluate)或预测(predict)阶段 使用的 数据集名称,框架会自动从 数据路径 下的 dataset_info.yaml 文件里读取对应数据集的字段映射与格式。
- 可以是本地定义的自定义数据集,也可以是 Hugging Face Hub 上的公共数据集。
- 若数据集路径下有多个数据集,需明确指定其中一个。
示例
alpaca_eval
mmlu
safety_zh
总结:“评估与预测数据集就是‘告诉程序用哪套题’;路径是放题的地方,数据集是题的名称。”
3.3 截断长度
截断长度:输入序列分词后的最大长度。
在 评估(evaluate)或预测(predict)阶段,把每个输入样本分词后的最大 token 数限制在这个值以下。
- 若样本超长,会从尾部截断多余部分,防止 OOM(显存溢出)。
- 若样本不足该长度,会正常填充(pad)到该长度。
- 默认值通常与训练阶段的
cutoff_len一致,但可根据评估数据调整。
总结:“截断长度就是‘评估时每条样本最多吃多少 token’;超长截尾,不足补零。”
3.4 最大样本数
最大样本数:每个数据集的最大样本数。
在 评估(evaluate)或预测(predict)阶段,对每个指定的数据集设置“最多只处理多少条样本”。
- 填 0 或留空 → 处理全部样本。
- 填正整数 N → 只随机/顺序截取前 N 条,用于快速实验、调试或消融。
总结:“最大样本数就是‘每个评估集最多测几条’;填 0 全测,填 1000 就测 1000 条。”
3.5 批处理大小
批处理大小:每个 GPU 处理的样本数量。
在 评估(evaluate)或预测(predict)阶段,指定 每张 GPU 上,每一次前向传播 要喂多少条样本。
- 与训练阶段的
per_device_train_batch_size类似,但通常可以更大(因为无需反向传播)。 - 显存允许的情况下,增大该值可以加速评估过程。
总结:“评估时的批处理大小就是‘每张卡一次喂几条’;显存够就放大,加速测指标。”
3.6 最大生成长度
最大生成长度:
在 推理(predict)阶段,限制模型生成的新 token 数量,从而控制输出文本的最大长度。
- 填写正整数 N → 模型在已有输入基础上最多再生成 N 个 token;
- 若输入长度为 L,最终输出长度 = L + N。
- 默认值通常为 200 左右,但可根据任务调整。
总结:“最大生成长度就是‘模型最多再写几个字’;填 200 就是最多再写 200 个 token。”
3.7 Top-p 采样值
Top-p 采样值:
在 推理(predict)阶段,控制生成文本时的 随机性与多样性。
- 值越小(如 0.1)→ 生成越保守,倾向于高频词汇,重复率高;
- 值越大(如 0.9)→ 生成越多样,包含更多低频词汇,可能更离谱;
- 默认值 0.95 是社区通用平衡点。
总结:“Top-p 采样值就是‘生成时冒点险的概率’:0.1 很保守,0.95 比较大胆。”
3.8 温度系数

在 推理(predict)阶段,控制生成文本的 随机性强度。
- 数值越小(如 0.1)→ 生成越确定,倾向于选择最高概率的 token,重复率高;
- 数值越大(如 1.5)→ 生成越随机,包含更多低概率词汇,可能更离谱;
- 默认值 1.0 表示按照原始概率分布采样。
总结:“温度系数就是‘生成时的随机强度’:0.1 很稳定,1.5 很随机。”
3.9 输出目录
输出目录:保存结果的路径
在 评估(evaluate)或预测(predict)阶段,指定将结果文件(如评估指标、生成的文本、日志等)保存到本地或云端的哪个路径。
- 支持绝对路径、相对路径或云存储路径。
- 若目录不存在,LaMa-Factory 会自动创建。
常见示例
| 场景 | 示例路径 | 说明 |
|---|---|---|
| 本地快速保存 | ./results/eval-07-13 |
相对路径,方便本地查看 |
| 云端持久化 | /mnt/ceph/results/predict-llama2-7b |
绝对路径,适合团队共享 |
| 按任务分类 | ./outputs/eval-llama2-7b-lora-sft |
按模型/任务命名,便于区分 |
总结: “输出目录就是‘把评估或预测结果存哪’;写清路径,方便后续找文件。”
4. 对话(Chat)
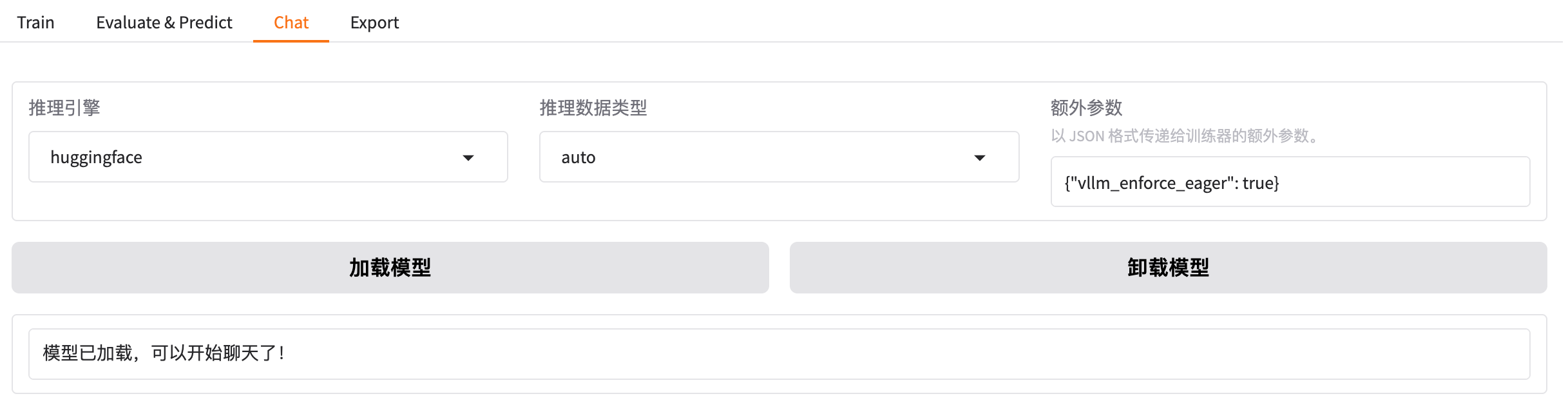
4.1 推理引擎
推理引擎:huggingface、vLLM、sglang
在 LaMa-Factory 的对话推理场景中,可以选择以下三种推理引擎:
HuggingFace 推理引擎:
-
特点:
- 提供统一接口调用各类模型,支持 HuggingFace Hub 上的所有模型(如 BERT、T5、GPT2、ChatGLM、LLaMA 等)。
- 适合教育科研、原型开发、多任务处理。
- 推理速度相对较慢,显存占用较高,但支持多平台(CPU/GPU)。
-
适用场景:
- 教育科研、小规模推理、多任务处理。
2. vLLM 推理引擎
-
特点:
- 基于 PagedAttention 机制,显著优化 KV Cache 的内存利用率,显存占用低,吞吐量高。
- 支持动态批处理、多 GPU 并行推理、量化(INT8、AWQ 等)、流式输出。
- 推理速度比 HuggingFace 快 2–4 倍,适合高并发、低延迟需求。
-
适用场景:
- 高并发对话系统、在线客服、内容生成、API 服务。
3. SGLang 推理引擎
-
特点:
- 支持结构化输出(如 JSON、XML),适合复杂逻辑的 AI 助理和 Agent 场景。
- 采用 Radix Tree 缓存,吞吐性能高,适合多轮对话。
- 支持 GPU/CPU,社区活跃度较高。
-
适用场景:
- 高并发多轮对话、搜索引擎、金融领域。
总结:如果需要 快速原型开发和 多任务处理,且对推理速度要求不高,可以选择 HuggingFace 推理引擎。 如果需要 高并发处理和低延迟响应,且主要使用 LLaMA、GPT 等模型,推荐 vLLM 推理引擎。 如果需要 复杂逻辑处理 和 结构化输出,适合选择 SGLang 推理引擎。
4.2 推理数据类型
推理数据类型:auto、float16、bflot16、float32
指定在 推理(predict)阶段,模型权重、输入数据和计算过程使用的浮点精度。
不同的精度类型会影响推理速度、显存占用和计算精度。
可选值及特点
| 选项 | 全称 | 位数 | 显存节省 | 推理速度 | 适用场景 |
|---|---|---|---|---|---|
| auto | 自动检测 | - | - | - | 让框架自动选择最优精度(通常为 float16 或 bfloat16)。 |
| float16 | 半精度浮点 | 16 bit | ≈ 50 % | 快 | 现代 GPU(如 A100、H100)支持,适合推理速度优先场景。 |
| bfloat16 | 脑浮点 | 16 bit | ≈ 50 % | 快 | 现代 GPU(如 A100、H100)支持,精度略高于 float16。 |
| float32 | 单精度浮点 | 32 bit | 0 % | 慢 | 适用于对精度要求极高、显存充足场景。 |
总结:“推理数据类型选 float16 最快,bfloat16 稍稳,float32 最准,auto 让系统自己挑。”
4.3 额外参数
额外参数:以json格式传递给训练器的额外参数
在 LaMa-Factory 的 训练(train) 或 推理(predict) 阶段,通过一段 JSON 字符串,把任何官方 Trainer / Accelerate / DeepSpeed 支持、但 WebUI 没有显式露出的小众超参数,一次性塞进训练器或推理器,避免改源码。
总结:“extra_args 就是给训练器或推理器开小灶:写合法 JSON,想塞啥就塞啥,优先级最高。”
4.4 角色
角色:user、oberservation
在对话系统或推理任务中,角色(role)通常用来定义不同参与者的身份和行为模式。在 LaMa-Factory 的上下文中,角色可能用于指定对话中的不同实体,例如用户(user)和观察者(observation)。以下是对这两个角色的详细解释:
1. 用户(user)
- 用户 是与系统直接交互的主体,通常是人类用户。
- 在对话系统中,用户提出问题或发起对话,系统根据用户的输入生成回答。
示例
{
"role": "user",
"content": "你好,我想了解一下今天的天气。"
}
2. 观察者(observation)
- 观察者 是一个特殊的角色,通常用于记录或分析对话过程中的某些信息。
- 在某些场景中,观察者可以记录对话的上下文、用户的反馈、系统的回答等,用于后续的分析或优化。
- 观察者也可以用于多轮对话中的中间状态记录,帮助系统更好地理解对话的进展。
示例
{
"role": "observation",
"content": "用户询问了今天的天气,系统已生成回答。"
}
在单轮对话中,通常只有用户和系统之间的交互:
[
{
"role": "user",
"content": "你好,我想了解一下今天的天气。"
},
{
"role": "system",
"content": "今天天气晴朗,最高温度 30 度。"
}
]
在多轮对话中,观察者可以记录每轮对话的状态:
[
{
"role": "user",
"content": "你好,我想了解一下今天的天气。"
},
{
"role": "system",
"content": "今天天气晴朗,最高温度 30 度。"
},
{
"role": "observation",
"content": "用户询问了今天的天气,系统已生成回答。"
},
{
"role": "user",
"content": "明天呢?"
},
{
"role": "system",
"content": "明天多云,最高温度 28 度。"
},
{
"role": "observation",
"content": "用户询问了明天的天气,系统已生成回答。"
}
]
总结: 用户(user)与系统直接交互,提出问题或发起对话。 观察者(observation)记录对话过程中的信息,用于分析或优化。
4.5 系统提示词
在对话系统中,系统提示词 是一段预设的文本,用于为模型提供上下文信息或引导模型的生成方向。它通常在对话开始时插入到用户输入之前,帮助模型更好地理解任务目标、风格或约束条件。
作用与重要性:
- 提供上下文:帮助模型理解对话的背景或主题。
- 引导生成:指定生成文本的风格、格式或内容范围。
- 约束输出:限制模型的生成,避免生成无关或不适当的内容。
示例 1. 提供上下文
{
"role": "system",
"content": "你是一位专业的天气预报员,擅长提供准确的天气信息。"
}
用户输入:
{
"role": "user",
"content": "今天天气怎么样?"
}
模型生成:
{
"role": "system",
"content": "今天天气晴朗,最高温度 30 度,适合户外活动。"
}
示例2. 引导生成
{
"role": "system",
"content": "请用简洁的语言回答用户的问题。"
}
用户输入:
{
"role": "user",
"content": "今天天气怎么样?"
}
模型生成:
{
"role": "system",
"content": "今天晴,30 度。"
}
示例3. 约束输出
{
"role": "system",
"content": "请避免生成任何敏感或不适当的内容。"
}
用户输入:
{
"role": "user",
"content": "告诉我一个笑话。"
}
模型生成:
{
"role": "system",
"content": "为什么电脑生病了?因为它得了病毒!"
}
使用场景:
- 多轮对话:在多轮对话中,系统提示词可以持续引导模型的生成方向。
- 特定任务:在特定任务(如写作、翻译、问答)中,系统提示词可以明确任务要求。
- 风格控制:通过系统提示词指定生成文本的风格(如正式、幽默、简洁)。
总结:“系统提示词就是‘给模型的悄悄话’:告诉它怎么回答、什么风格、什么不能说。”
4.6 工具列表
在对话系统或推理任务中,工具列表 是一个数组,用于定义模型在回答问题时可以调用的外部工具或 API。这些工具可以帮助模型获取额外信息、执行复杂计算或调用第三方服务,从而生成更准确、更有用的回答。
作用与重要性:
- 扩展能力:让模型能够调用外部资源,提升回答的准确性和实用性。
- 动态交互:根据用户需求动态调用工具,增强系统的灵活性。
- 多模态支持:支持调用图像识别、语音识别等工具,实现多模态交互。
假设你正在构建一个智能助手,用户可以询问天气、新闻或进行数学计算。工具列表可以定义如下:
[
{
"name": "weather_api",
"description": "获取指定城市的天气信息",
"parameters": {
"city": "string"
}
},
{
"name": "news_api",
"description": "获取最新新闻",
"parameters": {
"category": "string"
}
},
{
"name": "calculator",
"description": "执行数学计算",
"parameters": {
"expression": "string"
}
}
]
使用场景 1:查询天气
用户输入:
{
"role": "user",
"content": "今天北京的天气怎么样?"
}
模型调用工具:
{
"role": "system",
"content": "调用 weather_api,参数:{ 'city': '北京' }"
}
工具返回:
{
"role": "tool",
"content": "今天北京天气晴朗,最高温度 30 度。"
}
模型生成:
{
"role": "system",
"content": "今天北京天气晴朗,最高温度 30 度。"
}
使用场景 2:查询新闻
用户输入:
{
"role": "user",
"content": "给我看看今天的科技新闻。"
}
模型调用工具:
{
"role": "system",
"content": "调用 news_api,参数:{ 'category': '科技' }"
}
工具返回:
{
"role": "tool",
"content": "今天科技新闻:苹果公司发布新款 iPhone。"
}
模型生成:
{
"role": "system",
"content": "今天科技新闻:苹果公司发布新款 iPhone。"
}
使用场景 3:数学计算
用户输入:
{
"role": "user",
"content": "计算 2 + 3 * 4"
}
模型调用工具:
{
"role": "system",
"content": "调用 calculator,参数:{ 'expression': '2 + 3 * 4' }"
}
工具返回:
{
"role": "tool",
"content": "计算结果是 14"
}
模型生成:
{
"role": "system",
"content": "2 + 3 * 4 的结果是 14。"
}
总结:“工具列表就是‘模型的外挂清单’:告诉它能用哪些工具,按需调用,让回答更强大。”
4.7 最大生成长度
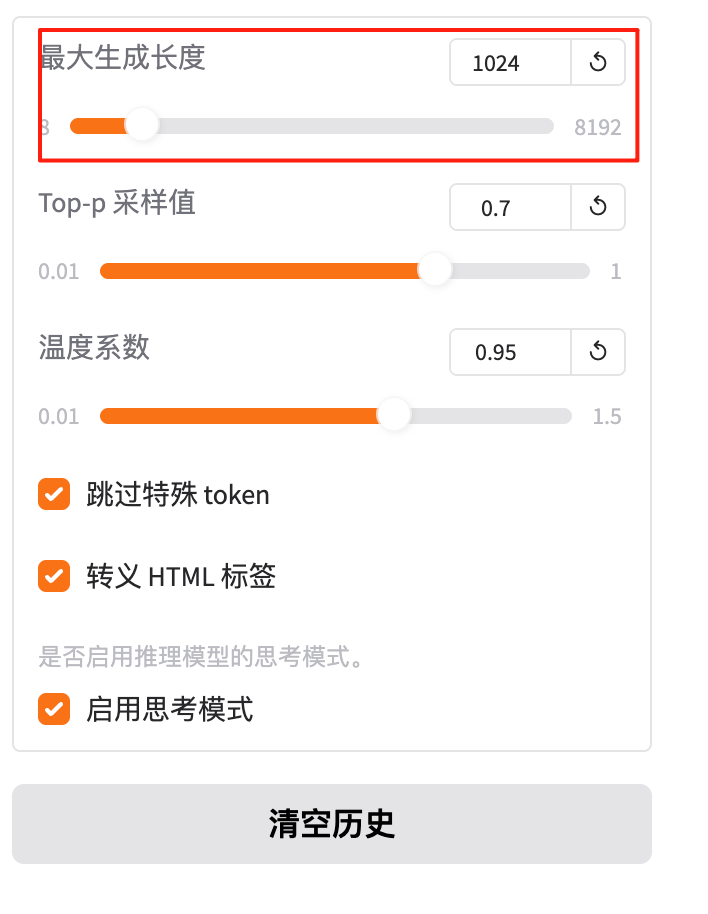
在 推理(predict)阶段,限制模型生成的新 token 数量,从而控制输出文本的最大长度。
- 若输入长度为 L,最终输出长度 = L + max_new_tokens。
- 该参数用于避免模型生成过长的文本,节省计算资源并提高响应速度。
假设输入文本为:
"今天天气真好,"
分词后长度为 5(L = 5)。 若设置 max_new_tokens = 10,模型最多再生成 10 个 token,最终输出长度为 15。
使用场景 :
- 短文本生成:如生成标题、摘要,可设置较小值(如 50)。
- 长文本生成:如生成故事、文章,可设置较大值(如 500)。
- 实时交互:如聊天机器人,需快速响应,可设置较小值(如 100)。
总结:“最大生成长度就是‘模型最多再写几个字’;填 200 就是最多再写 200 个 token。”
4.8 Top-P采样值
Top-P采样值: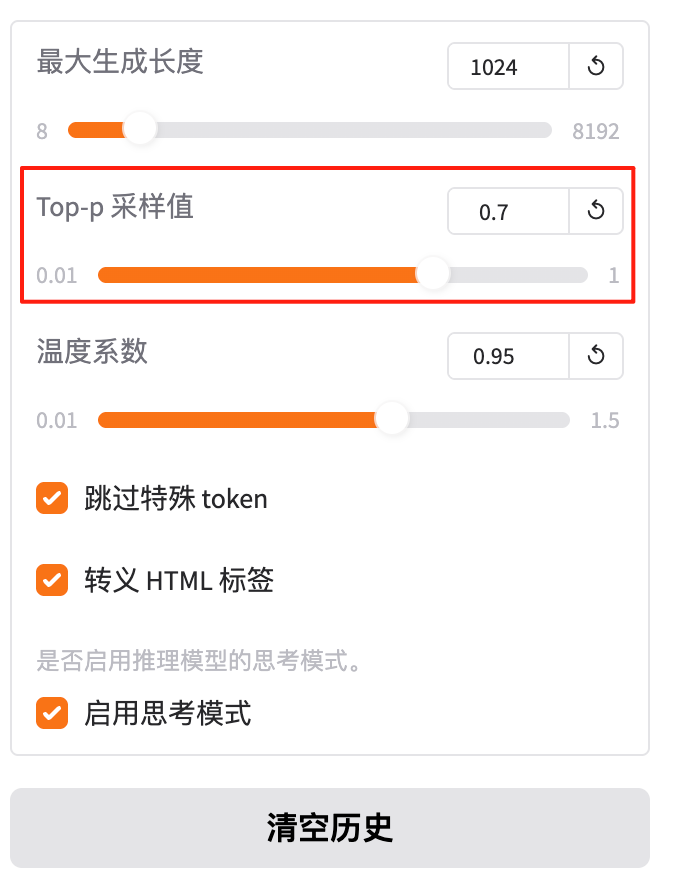
在 推理(predict)阶段,控制生成文本时的 随机性与多样性。
- Top-P 采样 是一种基于概率的采样方法,模型会从所有可能的下一个 token 中选择累积概率达到指定阈值(top_p)的那些 token。
- 值越小 → 生成越保守,倾向于高频词汇,重复率高;
- 值越大 → 生成越多样,包含更多低频词汇,可能更离谱;
- 默认值 0.95 是社区通用平衡点。
假设模型预测下一个 token 的概率分布如下:
token1: 0.4
token2: 0.3
token3: 0.2
token4: 0.1
若设置 top_p = 0.7,模型会从累积概率达到 0.7 的 token 中采样,即从 token1 和 token2 中选择。
使用场景:
- 保守生成:如写作辅助、知识问答,希望生成稳定、准确的内容,可设置较小值(如 0.1–0.5)。
- 创意生成:如故事创作、诗歌生成,希望生成多样、新颖的内容,可设置较大值(如 0.9–1.0)。
- 调试阶段:可尝试不同值,观察生成效果,找到最优平衡点。
总结:“Top-P 采样值就是‘生成时冒点险的概率’:0.1 很保守,0.95 比较大胆。”
4.9 温度系数
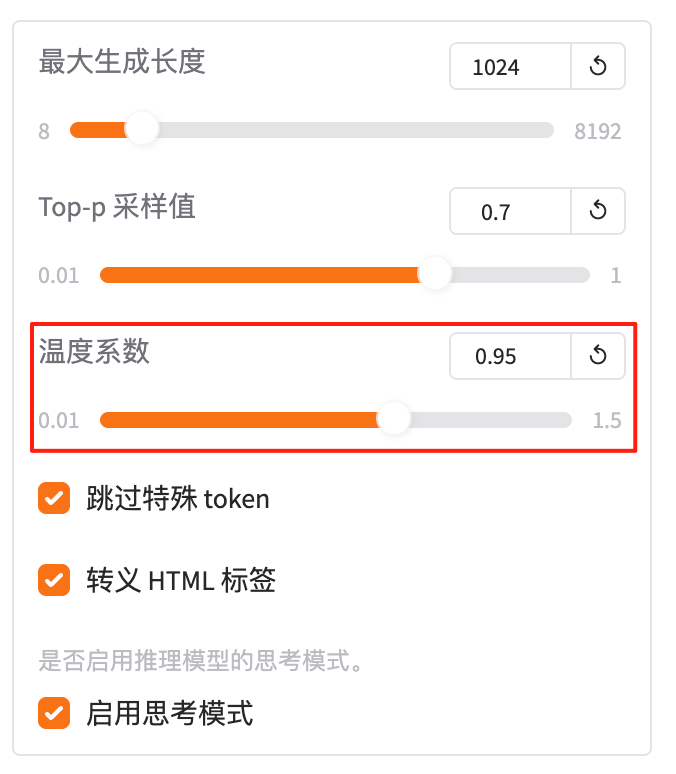
在 推理(predict)阶段,控制生成文本的 随机性强度。
- 温度系数 是一个控制生成多样性的参数,它会影响模型选择下一个 token 的概率分布。
- 数值越小(如 0.1)→ 生成越确定,倾向于选择最高概率的 token,重复率高;
- 数值越大(如 1.5)→ 生成越随机,包含更多低概率词汇,可能更离谱;
- 默认值 1.0 表示按照原始概率分布采样。
假设模型预测下一个 token 的概率分布如下:
token1: 0.4
token2: 0.3
token3: 0.2
token4: 0.1
若设置 temperature = 0.5,模型会将概率分布调整为:
token1: 0.5
token2: 0.3
token3: 0.15
token4: 0.05
生成结果会更倾向于高频词汇。
若设置 temperature = 1.5,模型会将概率分布调整为:
token1: 0.3
token2: 0.25
token3: 0.2
token4: 0.25
生成结果会更随机。
使用场景:
- 确定性生成:如知识问答、翻译,希望生成稳定、准确的内容,可设置较小值(如 0.1–0.5)。
- 创意生成:如故事创作、诗歌生成,希望生成多样、新颖的内容,可设置较大值(如 1.5–2.0)。
- 调试阶段:可尝试不同值,观察生成效果,找到最优平衡点。
总结:“温度系数就是‘生成时的随机强度’:0.1 很稳定,1.5 很随机。”
4.10 跳过特殊token
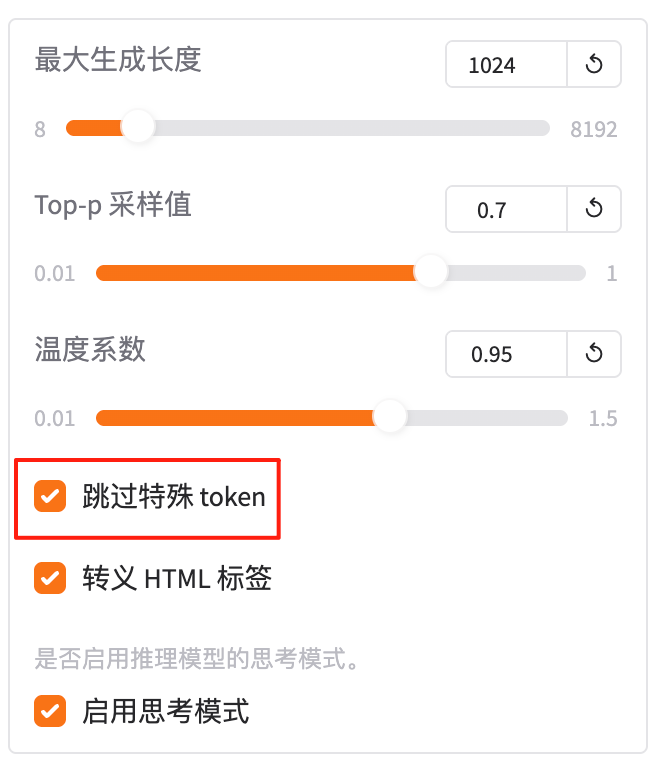
在 推理(predict)阶段,决定是否在生成的文本中跳过特殊 token。
特殊 token 通常是指模型用于内部处理的标记,如 [CLS]、[SEP]、<s>、</s> 等,这些 token 在生成文本时通常没有实际意义,甚至可能干扰最终输出。
假设模型生成的 token 序列如下:
<s> 今天天气真好 </s> [CLS] [SEP]
- 跳过特殊 token(true):最终输出的文本会去掉这些特殊 token,只保留实际内容:
今天天气真好
- 不跳过特殊 token(false):最终输出的文本会包含所有 token,包括特殊 token:
<s> 今天天气真好 </s> [CLS] [SEP]
默认值
通常默认值为 true,即跳过特殊 token,以生成更干净的文本。
使用场景:
- 文本生成:如写作辅助、对话系统,通常希望生成的文本干净、无干扰,建议设置为
true。 - 调试模型:在调试阶段,可能希望保留特殊 token 以观察模型的内部行为,可设置为
false。
总结:“跳过特殊 token 就是‘去掉没意义的标记’:默认 true,生成干净文本;false 保留所有标记。”
4.11 转义HTML标签
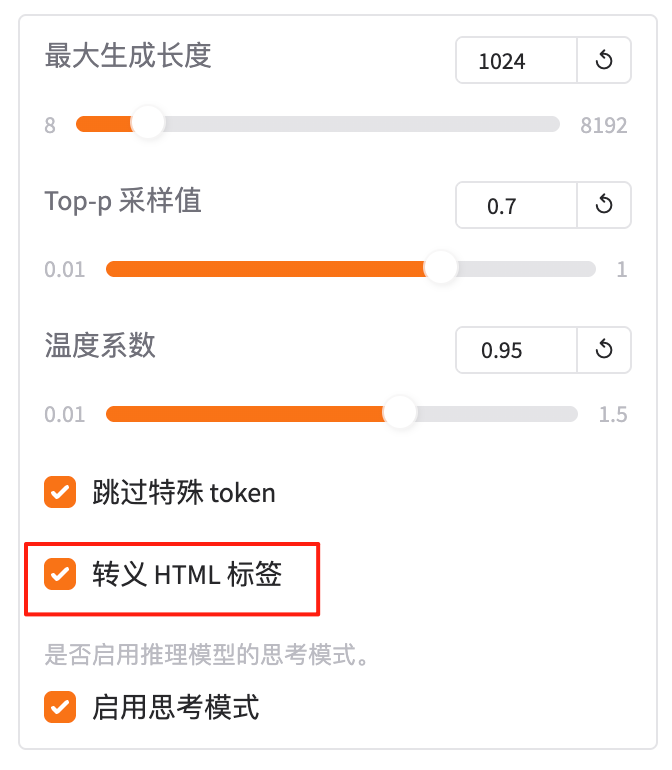
在 推理(predict)阶段,决定是否将生成的文本中的 HTML 标签进行转义处理。
HTML 标签(如 <div>、<p>、<a> 等)在某些场景下可能会被浏览器解析为格式化指令,而不是普通文本。转义处理可以将这些标签转换为纯文本形式,避免被浏览器错误解析。
假设模型生成的文本如下:
<p>今天天气真好</p>
<a href="http://example.com">点击这里</a>
- 转义 HTML 标签(true):最终输出的文本会将 HTML 标签转换为纯文本形式:
<p>今天天气真好</p>
<a href="http://example.com">点击这里</a>
- 不转义 HTML 标签(false):最终输出的文本会保留原始 HTML 标签:
<p>今天天气真好</p>
<a href="http://example.com">点击这里</a>
使用场景:
- 网页内容生成:如果生成的内容将直接插入到 HTML 页面中,且希望保留 HTML 格式,应设置为
false。 - 纯文本输出:如果生成的内容将用于非 HTML 环境(如日志、纯文本文件),建议设置为
true,以避免 HTML 标签干扰。
总结:“转义 HTML 标签就是‘把尖括号换成纯文本’:true 避免浏览器解析,false 保留原始格式。”
4.12 启用思考模式
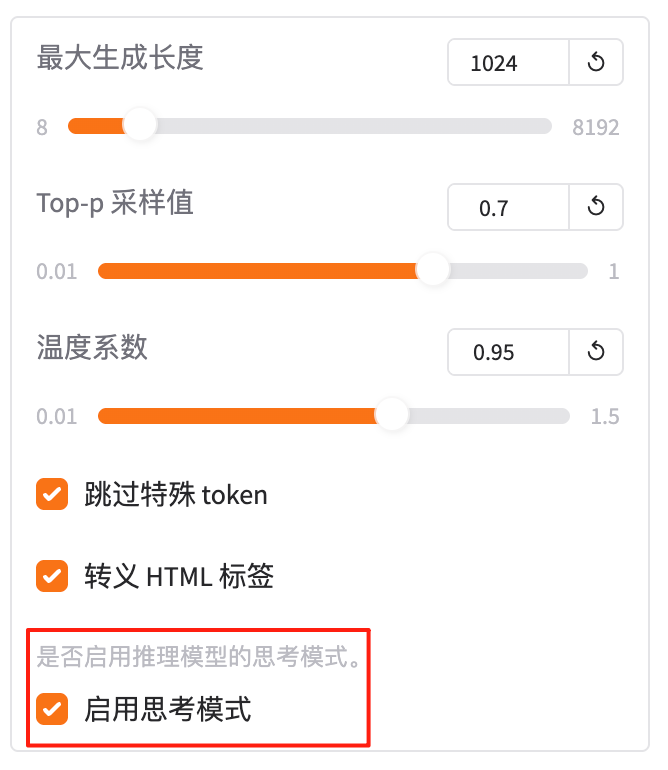
在 推理(predict)阶段,让模型在生成最终回答之前,先输出一段思考过程(Chain-of-Thought)。
- 思考过程 是模型在生成回答时的中间步骤,通常包含逻辑推理、计算过程或决策路径。
- 启用思考模式可以帮助用户更好地理解模型的决策过程,提高透明度和可解释性。
假设用户输入:
"今天天气怎么样?"
启用思考模式后,模型可能会输出:
思考:查询今天的天气信息,需要调用天气 API,获取当前城市的天气数据。
回答:今天天气晴朗,最高温度 30 度。
使用场景:
- 教育用途:帮助学生理解模型的推理过程,提高学习效果。
- 复杂任务:如数学计算、逻辑推理,思考模式可以展示中间步骤,便于用户验证。
- 调试阶段:在开发或优化模型时,启用思考模式可以帮助开发者理解模型的行为。
总结:“启用思考模式就是让模型‘先说说怎么想的’,再给出答案,提高透明度。”
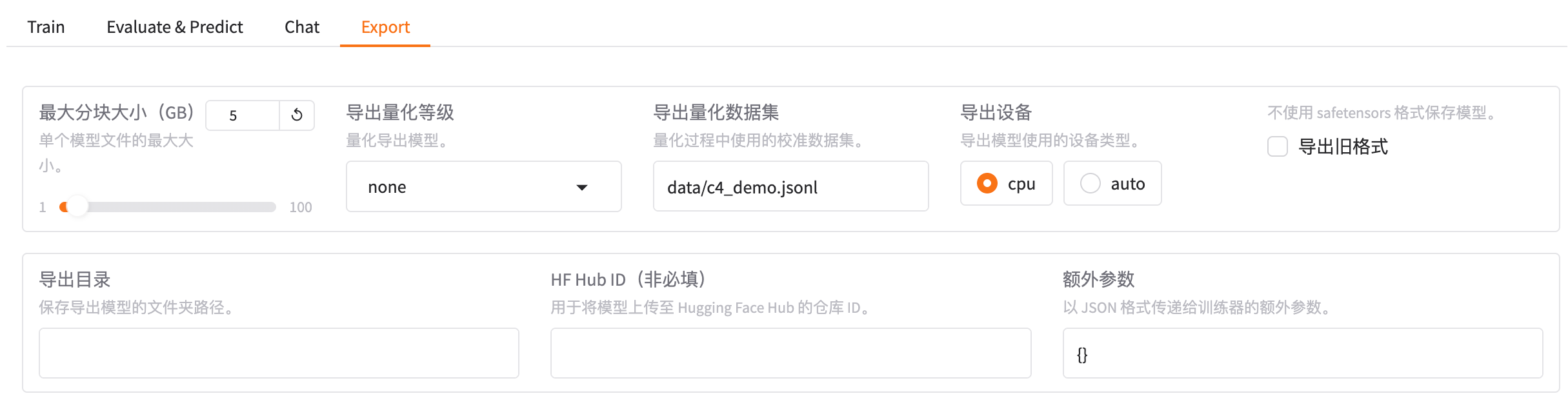
5. 导出(Export)
5.1 最大分块大小
最大分块大小:单个模型文件的最大大小
最大分块大小(Max Chunk Size):指定导出模型时,每个分块文件的最大大小。
- 如果模型过大,可通过分块方式导出,防止单个文件过大导致加载或存储问题。
- 单位通常为 MB 或 GB。
使用场景:
- 大模型导出:避免单个文件过大而无法上传或加载。
- 分布式加载:不同设备可并行加载不同分块,提高效率。
总结:“控制模型导出文件大小,解决大模型存储和加载问题。”
5.2 导出量化等级
导出量化等级:量化导出模型(none、2、3、4、8)
导出量化等级(Quantization Level):模型导出时使用的量化精度,可选值如 none、2、3、4、8。
- none:不量化,保持原始精度。
- 2/3/4/8:降低模型权重精度,减少存储空间和推理计算量,但可能略有精度损失。
使用场景:
- 推理部署:量化可减少内存占用和计算成本。
- 原始训练权重保存:不量化保留精度,便于继续训练。
总结:“选择量化等级,是在模型精度和存储效率之间做权衡。”
5.3 导出量化数据集
导出量化数据集:量化过程中使用的校准数据集
导出量化数据集(Quantization Dataset):量化时使用的校准数据集,用于计算权重缩放和偏置。
- 量化结果依赖于校准数据集的分布。
- 可指定特定数据集进行量化,以保证推理精度。
使用场景:
- 量化训练:提高量化模型的准确性。
- 自定义校准:使用和目标推理任务分布一致的数据集。
总结:“量化数据集决定了量化模型的精度表现。”
5.4 导出设备
导出设备:导出模型使用的设备类型(cpu、auto)
导出设备(Export Device):指定导出模型使用的硬件设备类型,如 cpu 或 auto。
- cpu:在 CPU 上执行导出。
- auto:根据环境自动选择 GPU 或 CPU。
使用场景:
- 资源限制:在无 GPU 环境下可选择 CPU 导出。
- 加速导出:有 GPU 时可自动使用,提升导出速度。
总结:“选择导出设备,是为了兼顾导出速度和硬件资源。”
5.5 导出旧格式
导出旧格式:不适用safetensors格式保存模型
导出旧格式(Export Legacy Format):是否使用非 safetensors 格式保存模型。
- 开启:使用传统格式(如
.pt或.bin),兼容老版本工具。 - 关闭:使用
safetensors,安全且防止权重被篡改。
使用场景:
- 兼容旧工具:老版本推理或训练工具可能不支持 safetensors。
- 安全性需求:推荐使用 safetensors 防止模型被修改。
总结:“决定保存模型的文件格式,是兼容性和安全性的权衡。”
5.6 导出目录
导出目录:保存导出模型的文件夹路径
导出目录(Export Directory):保存导出模型的文件夹路径。
- 可以指定绝对路径或相对路径。
- 文件夹中会生成模型权重、配置文件及可选分块文件。
使用场景:
- 集中管理:统一存放导出模型便于部署和备份。
- 多版本管理:为不同版本或量化等级指定不同目录。
总结:“导出目录就是模型文件最终落脚的位置。”
5.7 HF Hub ID
HF Hub ID(非必填):用于将模型上传至Hugging Face Hub的仓库ID
HF Hub ID(Hugging Face Hub Repository ID,可选):将模型上传至 Hugging Face Hub 时使用的仓库 ID。
- 如果填写,则导出后可直接上传至指定仓库。
- 不填写则仅在本地保存。
使用场景:
- 模型共享:上传 Hugging Face Hub 便于团队或社区使用。
- 版本控制:通过 Hub 管理模型版本和更新。
总结:“HF Hub ID 是模型上传到 Hugging Face 仓库的唯一标识。”
5.8 额外参数

额外参数(Extra Parameters):以 JSON 格式传递给训练器的额外参数,用于控制导出行为。
- 可设置一些高级选项,如自定义权重处理、特殊优化等。
- 格式示例:
{
"use_fp16": true,
"optimize_for_inference": true
}
使用场景:
- 高级自定义:满足特殊导出需求。
- 调试与优化:控制导出过程中模型的行为或格式。
总结:“额外参数让导出更灵活,支持个性化需求。”

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)