
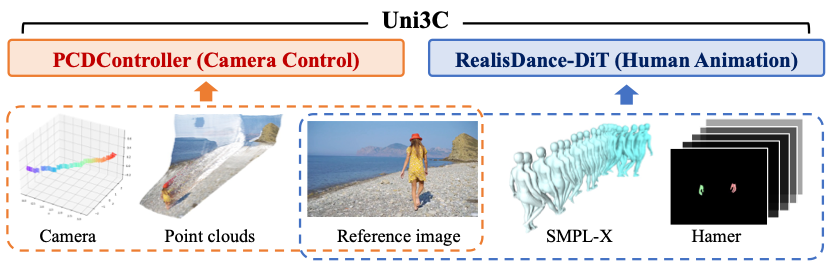
CVPR 2025 Highlight | 可控视频生成新范式Uni3C:无需联合标注数据,一套框架统一相机与人体控制
为此,我们提出Uni3C(Unified 3D-enhanced Camera and Human Motion Control),基于3D引导的相机轨迹与人体运动统一控制的视频生成框架,在实现高精度相机轨迹控制的同时,支持复杂视角下人物与环境互动的物理空间合理性。AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
个人信息
作者:曹辰捷,达摩院算法工程师
项目简介
当前视频生成技术发展迅猛,对于视频内容的可控生成需求也与日俱增。然而现在的技术对相机轨迹和人体运动的控制往往分开处理,依赖高质量标注数据且难以协同。
为此,我们提出Uni3C(Unified 3D-enhanced Camera and Human Motion Control),基于3D引导的相机轨迹与人体运动统一控制的视频生成框架,在实现高精度相机轨迹控制的同时,支持复杂视角下人物与环境互动的物理空间合理性。Uni3C在相机轨迹精度和人体运动质量上均显著优于现有方法,并在360°环绕拍摄、运动迁移等极限场景中展现强鲁棒性。

图表 1 给定单张图片(真实图片或动漫图片)Uni3C能在任意复杂相机轨迹下实现人物姿态控制或动作迁移
论文地址:
https://arxiv.org/abs/2504.14899
项目主页:
https://alibaba-damo-academy.github.io/Uni3C/
视频可控生成的现存问题与挑战
近年来,基于视频扩散模型(Video Diffusion Models, VDMs)的动态内容生成取得了突破性进展,但视频生成的可控性仍是核心挑战,尤其在相机轨迹与人体运动协同控制方面存在三大关键问题:
-
泛化性困境:现有方法通过改造VDMs固有结构(如注入Plücker射线、点云条件)实现相机控制,或依赖姿势/SMPL模型驱动人体动画,但这类强干预会破坏基础模型的泛化能力,难以处理分布外场景;
-
数据依赖性:相机与人体运动的联合控制需高质量多视角人体视频标注,此类数据稀缺且标注成本极高,导致现有方法多局限于单一控制维度;
-
3D一致性缺失:相机(点云)与人体(SMPL)控制信号分属独立3D空间,缺乏统一的世界坐标系对齐机制,导致人物与环境交互失真(如穿模、悬浮等现象)。
这三大问题严重制约了可控视频生成在影视制作、VR等场景的实用化进程。为此,本文提出Uni3C框架,通过轻量化点云控制模块(PCDController)与全局3D空间对齐机制,实现无需联合标注数据,且无需联合训练的跨域协同控制,为3D感知视频生成提供新范式。
Uni3C:视频生成中相机与人体运动的统一3D增强控制
1、方法总览
图表 2 Uni3C整体总览,运镜控制(PCDController)和人物驱动(RealisDance-DiT)分别接收不同模态的 3D 引导输入
Uni3C是基于开源视频扩散模型Wan2.1构建的统一控制框架,旨在实现相机轨迹与人体运动的协同控制。其核心流程分为三步:
-
输入处理:给定单视角参考图像、相机轨迹和动作序列(可来自动捕、生成或者数据库预存动作),结合文本描述生成目标视频。
-
控制模块协作:通过PCDController实现精准相机控制(基于3D点云),结合RealisDance-DiT驱动人体动画(基于SMPL-X模型)。
-
3D空间对齐:全局3D世界引导将场景点云与人体模型对齐至统一坐标系,确保物理合理性。
2、PCDController:轻量化点云相机控制器
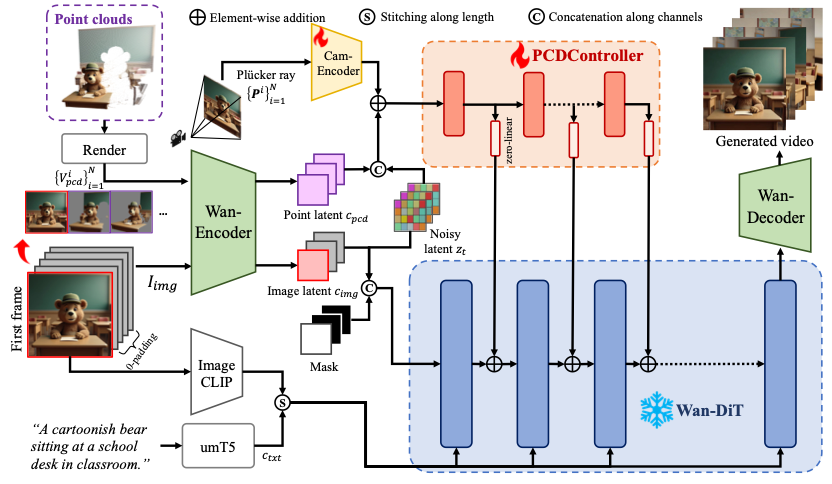
图表 3 PCDController的模型架构图
我们基于ControlNet和Wan2.1-I2V的主干网络,提出了运镜控制模型PCDController。其中,我们实现了一系列轻量化设计来确保其泛化性:
-
采用简化DiT结构,仅训练0.95B参数(远小于Wan2.1-I2V的14B),完全固定Wan2.1-I2V,避免主干模型微调。
-
仅在前20层注入控制信号,保留模型泛化性;移除基于文本的cross-attention模块以消除文本干扰。
为了弥补模型简化带来的损失,我们引入3D几何先验来实现准确的运镜控制:
-
点云重建:通过单目深度估计(Depth-Pro)反投影生成度量点云
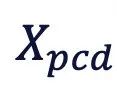 ,渲染多视角图像
,渲染多视角图像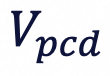 作为注入条件。
作为注入条件。 -
混合条件:结合Plücker射线编码P(处理大视角变化)与点云特征,建模分布
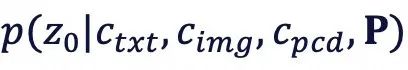 。
。 -
鲁棒性:即使点云存在误差(如单目深度噪声),仍能通过VDM固有能力进行补偿,保持稳定生成(如下图所示)。

图表 4 加入点云控制后模型收敛速度大幅度加快

图表 5 PCDController有极强的泛化性
数据来源:CVPR 2025 MVGenMaster
PCDController的训练需要多样性充分的多视角数据以及点云,其数据来源则是同样出自达摩院的CVPR2025工作:MVGenMaster: Scaling Multi-View Generation from Any Image via 3D Priors Enhanced Diffusion Model。
MVGenMaster提出了一种多视角生成基础模型,能够灵活根据任意张条件图片生成目标图片序列:

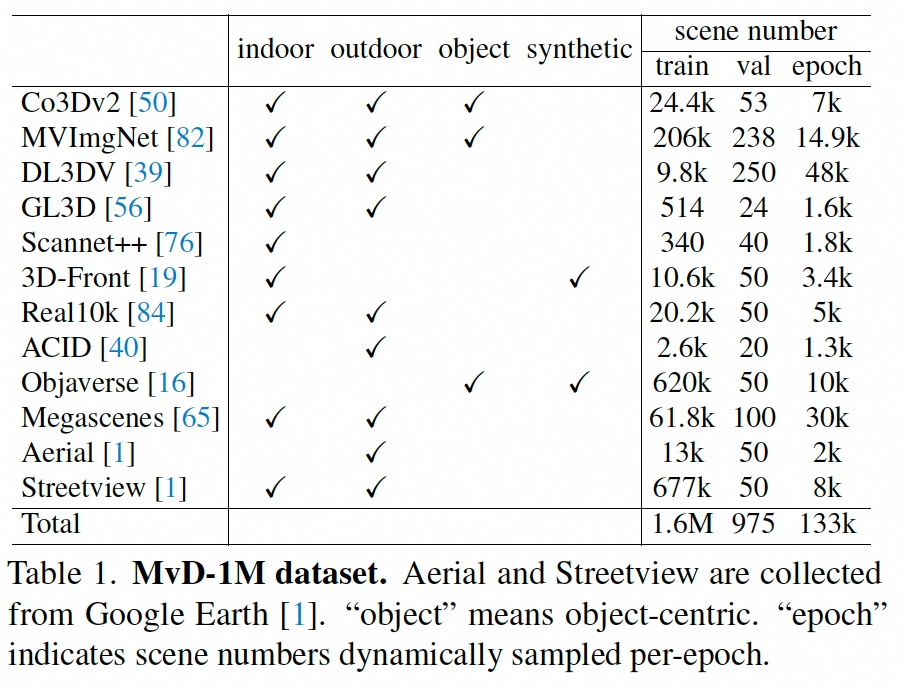
此外,MVGenMaster还提出了带有矫正后depth的多视角数据MvD-1M,包含了1.6M的场景数据集。该数据集也作为PCDController的训练集:
3、RealisDance-DiT:泛化的人体姿态控制
Uni3C能够适应到任意基于Wan2.1框架的网络,同时支持I2V(图生视频)和T2V(文生视频)模式,展现其强大的泛化性。在Uni3C的工作中,我们选择同为阿里巴巴达摩院近期开发的RealisDance-DiT作为人体驱动的模型。RealisDance-DiT以SMPL-X人体参数和手部模型Hamer为控制信号,支持运动迁移与多样化动作生成。
此外,RealisDance-DiT能够随机选择参考帧,放宽SMPL-X与首帧的严格对齐要求。在与Uni3C中世界坐标系对齐策略结合后,RealisDance-DiT能够轻松实现各类动作迁移任务。

上图为RealisDance-DiT生成效果以及对应的网络架构
RealisDance-DiT论文地址:
https://arxiv.org/abs/2504.14977
RealisDance-DiT项目主页:
https://thefoxofsky.github.io/project_pages/RealisDance-DiT/index
4、全局3D世界引导:多模态空间对齐
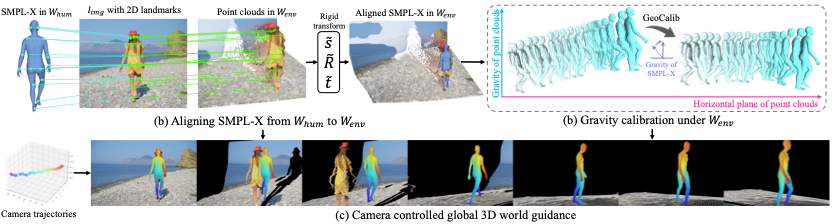
图表6 全局3D世界引导的构建方式。我们将场景点云和人体模型联合对齐在一个空间内形成联合控制
不同3D条件用于视频控制的核心问题在于场景点云 与人体模型
与人体模型 分属独立3D空间,需统一坐标系。因此,在Uni3C中我们提出了一种对齐策略:
分属独立3D空间,需统一坐标系。因此,在Uni3C中我们提出了一种对齐策略:
1)2D关键点桥接:通过ViTPose++提取参考图像2D关键点,反投影至 生成3D关键点
生成3D关键点 。
。
2)刚性变换:基于最小二乘法优化缩放 、旋转
、旋转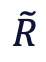 和平移
和平移 ,将SMPL-X的3D关键点
,将SMPL-X的3D关键点 对齐至
对齐至 。
。
3) 重力校准:利用GeoCalib估计场景重力方向,校正SMPL-X姿态,避免运动轨迹失真(如悬空或穿模)。
4) 手部处理:通过共享顶点将Hamer手部模型与SMPL-X对齐,动态掩膜处理遮挡问题。

图表7 重力矫正的重要性,防止悬空倾斜等问题
在统一将渲染点云、SMPL-X和Hamer条件对齐至 后,Uni3C利用该协同控制能力实现了视频模型在任意相机轨迹下的物理空间合理生成。
后,Uni3C利用该协同控制能力实现了视频模型在任意相机轨迹下的物理空间合理生成。
实验结果
1、相机控制:在包含动画、真实场景的128例out-of-distribution测试集上,PCDController的绝对轨迹误差(ATE)仅0.102,较同为点云控制的ViewCrafter降低51%。且VBench++得分达到了88.27,超过其他SOTA运镜方法(ViewCrafter 85.39,SEVA 87.39)。
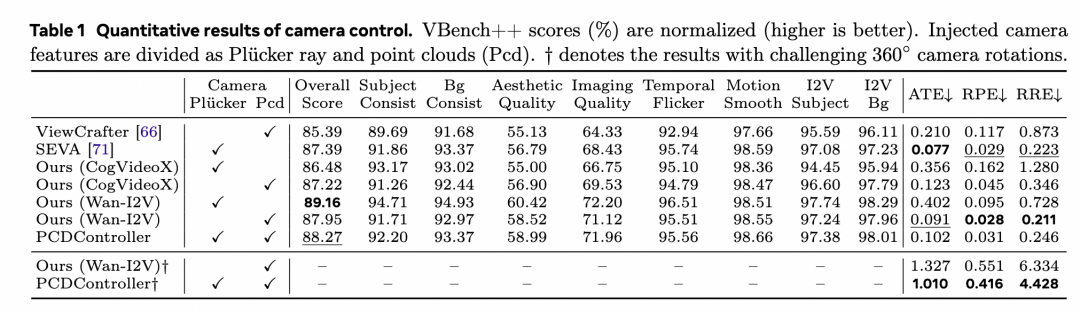
2、相机运镜可视化结果:所提算法能够兼容极端场景,达到360°环绕拍摄时细节无畸变。
3、联合控制:在人体运动数据集中,Uni3C支持复杂动作(如翻滚,芭蕾,骑车等)与自由视角同步控制,相关相机度量指标达SOTA。
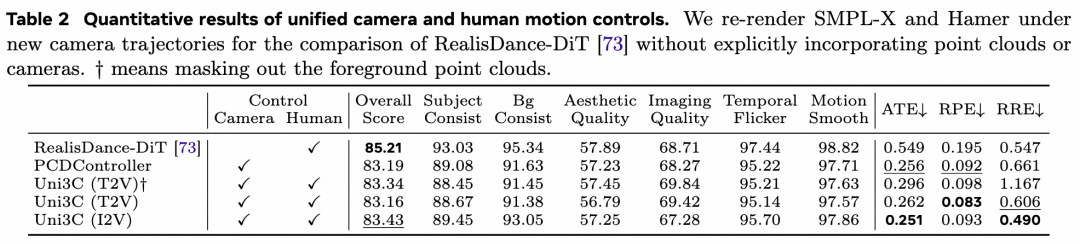
并且能够兼容text-to-motion或从动作库中检索的动作模版进行生成。
未来工作方向
如果动作序列和场景发生冲突,例如运动轨迹遇到障碍物、墙壁等情况,生成结果会出现不符合物理碰撞逻辑的情况。未来工作可能会聚焦于如何生成符合环境规律的动作序列,以及如何处理多人场景控制等方面。
近期精彩活动

ICML 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)