手把手教你在Linux本地搭建超酷数字人LiveTalking
本文详细介绍了如何在Linux系统上搭建开源实时数字人引擎LiveTalking的全过程。从硬件需求(推荐RTX3060显卡、16GB内存等)到软件环境配置(Ubuntu20.04、Python3.8等),逐步指导安装显卡驱动、CUDA Toolkit、cuDNN等必要组件,并通过Docker部署SRS服务、GPT-SoVITS和LiveTalking三大核心服务。特别提供了使用musetalk模
摘要:本文详细介绍了如何在Linux系统上搭建开源实时数字人引擎LiveTalking的全过程。从硬件需求(推荐RTX3060显卡、16GB内存等)到软件环境配置(Ubuntu20.04、Python3.8等),逐步指导安装显卡驱动、CUDA Toolkit、cuDNN等必要组件,并通过Docker部署SRS服务、GPT-SoVITS和LiveTalking三大核心服务。特别提供了使用musetalk模型训练自定义数字人形象的具体方法,以及常见问题的解决方案。
1.引言
在人工智能飞速发展的当下,数字人技术正以前所未有的速度融入我们的生活,从电商直播中的虚拟主播,到智能客服、在线教育等领域,数字人都展现出了巨大的应用潜力。今天,我们要深入探讨的是一款名为 LiveTalking 的开源实时互动数字人引擎,它为开发者提供了在本地搭建数字人实时交互系统的可能,让我们能够在自己的设备上,近距离感受数字人技术的魅力。

LiveTalking 的优势十分显著,它仅用一条音频流就能驱动 50fps、720p 以上的虚拟主播,并且将多模态大模型、NeRF 表情场、音频到全身动作的跨域网络整合进一个 pip 包,还提供了 Gradio/WebRTC/RTMP 三种开箱即用的接口,在一张 RTX 3060 显卡上就能实现 300ms 端到端延迟的直播 ,在电商直播场景中,借助其低延迟和高清驱动能力,虚拟主播能够实时响应观众的提问,展示商品细节,提升观众的购物体验;在在线教育领域,数字人老师可以根据学生的反馈,实时调整教学方式,给予个性化的指导,仿佛真人老师就在身边。
接下来,本文将详细介绍如何在 Linux 本地搭建 LiveTalking,让你快速上手,开启数字人实时交互的探索之旅。
2.搭建前的准备
(一)硬件需求
- GPU:LiveTalking 对图形处理能力要求较高,因此推荐使用 NVIDIA GPU,如 RTX 3060 及以上型号 。GPU 在数字人实时交互中主要负责图形渲染和模型加速,尤其是在处理 3D 模型和实时视频流时,高性能的 GPU 能够保证数字人的动作和表情更加流畅、自然。例如,在驱动数字人模型生成视频流时,GPU 可以快速处理大量的图形数据,使得数字人的形象更加逼真。若 GPU 性能不足,可能会导致数字人动作卡顿、表情不自然,严重影响交互体验。

- 内存:至少需要 16GB RAM ,充足的内存可以保证系统在运行 LiveTalking 以及相关程序时,有足够的空间存储和处理数据。当同时进行语音采集、模型推理和视频输出等操作时,大内存可以避免因内存不足导致的程序卡顿或崩溃。如果内存不够,系统可能会频繁进行磁盘交换,大大降低运行效率,甚至导致程序无法正常运行。

- CPU:建议使用 Intel i7 或同等性能处理器及以上 ,具备多核心、高主频的 CPU 能够在处理复杂的语音识别、语义理解以及模型运算等任务时更加高效,确保系统响应的及时性。比如在进行语音转文本的过程中,强大的 CPU 可以快速完成音频数据的处理和分析,减少延迟。若 CPU 性能不佳,会使语音识别和语义理解的速度变慢,数字人响应不及时,降低交互的流畅性。

- 硬盘:准备 50GB 以上可用存储空间,用于存储 LiveTalking 的开源代码、相关依赖库、预训练模型以及在运行过程中产生的临时文件等。比如预训练模型通常会占用一定的磁盘空间,较大的可用硬盘空间可以确保这些文件能够顺利存储。若硬盘空间不足,可能无法完成项目代码和模型的下载,或者在运行过程中因无法创建临时文件而导致程序出错。

(二)软件需求
- 操作系统:推荐安装 Ubuntu 20.04 及以上版本的 Linux 系统 ,Linux 系统以其稳定性和对开源项目的良好支持而受到开发者的青睐,Ubuntu 20.04 更是经过了大量实践检验,能为 LiveTalking 提供稳定的运行环境。它具有高效的资源管理能力,能够充分利用硬件资源,确保 LiveTalking 的各项功能稳定运行。

- Python:需要 Python 3.8 及以上版本 ,Python 是 LiveTalking 的主要开发语言,较高版本的 Python 通常具有更好的性能和更多的特性,同时也能更好地支持项目中使用的各种依赖库。例如,Python 3.8 引入了一些新的语法和功能,能够提高代码的编写效率和运行效率,并且对一些新的依赖库有更好的兼容性。

- 深度学习框架:主要依赖 PyTorch 深度学习框架,需根据 CUDA 版本安装对应的 PyTorch 版本 ,以利用 GPU 加速计算。PyTorch 提供了丰富的工具和函数,方便开发者进行深度学习模型的构建和训练,其动态计算图的特性使得调试和开发更加便捷。在 LiveTalking 中,PyTorch 用于实现数字人模型的训练和推理,能够快速处理大量的数据,实现高效的图形渲染和动作生成。
- 其他依赖库:通过项目中的 requirements.txt 文件安装其他必要的依赖库,这些库涵盖了图像处理、音频处理、网络通信等多个方面,是 LiveTalking 正常运行不可或缺的部分。例如,OpenCV 库用于图像处理,实现数字人面部表情的识别和渲染;NumPy 库用于数值计算,为深度学习模型提供高效的数据处理能力;WebSocket 库用于实现实时通信,确保数字人与用户之间的交互实时性。在安装依赖库时,建议使用国内的镜像源,如清华大学镜像源,以提高下载速度。

3.详细搭建步骤
(一)系统环境配置
- 安装 Ubuntu 系统:首先,准备一个容量不小于 8GB 的 USB 启动盘,前往 Ubuntu 官方网站(https://ubuntu.com/download/server)下载 Ubuntu 20.04 的镜像文件 。下载完成后,通过 Rufus 等工具将镜像文件写入 USB 启动盘。将 USB 启动盘插入计算机,重启计算机并进入 BIOS 设置界面,在启动选项中选择从 USB 启动盘启动。进入安装界面后,按照提示选择语言、键盘布局,进行网络配置(若需要联网安装软件和更新系统,可选择自动获取 IP 地址或手动配置静态 IP),并设置用户名和密码等。在磁盘分区步骤,可根据个人需求进行分区设置,若不熟悉分区操作,可选择默认分区方式。安装过程中可能需要等待一段时间,安装完成后,取出 USB 启动盘,重启计算机,即可进入 Ubuntu 20.04 系统。在安装过程中,若遇到黑屏或驱动不兼容等问题,可尝试在启动时按 “e” 键进入编辑模式,在 “quiet splash” 后添加 “nomodeset” 参数,以禁用显卡的模式设置,待安装完成后再更新显卡驱动。
- 更新系统:打开终端,输入以下命令更新系统软件包:
sudo apt-get update
sudo apt-get upgrade这两条命令分别用于更新软件包列表和将系统中已安装的软件包更新到最新版本,确保系统的安全性和稳定性,同时也能获取最新的功能和修复的漏洞。在更新过程中,可能会提示输入用户密码,输入正确密码后按回车键继续。若更新过程中出现网络连接问题,可检查网络设置或更换网络源。
(二)安装显卡驱动与 CUDA Toolkit
- 下载安装包:访问 NVIDIA 官方网站(https://www.nvidia.com/Download/index.aspx),
 在 “Download Drivers” 页面,根据显卡型号、操作系统版本等信息,选择对应的显卡驱动进行下载 。同时,前往 CUDA Toolkit 下载页面(https://developer.nvidia.com/cuda-toolkit-archive),
在 “Download Drivers” 页面,根据显卡型号、操作系统版本等信息,选择对应的显卡驱动进行下载 。同时,前往 CUDA Toolkit 下载页面(https://developer.nvidia.com/cuda-toolkit-archive), 下载 CUDA Toolkit 11.8 的安装包 ,注意选择与系统版本和显卡驱动兼容的版本。在下载过程中,需确保网络连接稳定,若下载中断,可重新下载。
下载 CUDA Toolkit 11.8 的安装包 ,注意选择与系统版本和显卡驱动兼容的版本。在下载过程中,需确保网络连接稳定,若下载中断,可重新下载。 - 安装过程:下载完成后,进入下载目录,给予安装包执行权限,例如对于显卡驱动安装包 “NVIDIA-Linux-x86_64-xxx.run”,执行命令 “chmod +x NVIDIA-Linux-x86_64-xxx.run” ,对于 CUDA Toolkit 安装包 “cuda_11.8.0_xxx_linux.run”,执行命令 “chmod +x cuda_11.8.0_xxx_linux.run” 。然后,关闭图形界面(可通过 “sudo systemctl set-default multi-user.target” 命令实现),进入命令行模式(按 “Ctrl + Alt + F2” 组合键),登录系统后,运行显卡驱动安装程序 “sudo ./NVIDIA-Linux-x86_64-xxx.run” ,按照提示完成安装,安装过程中可能会提示是否覆盖现有驱动等选项,根据实际情况选择。显卡驱动安装完成后,重新运行 CUDA Toolkit 安装程序 “sudo ./cuda_11.8.0_xxx_linux.run” ,在安装过程中,可选择安装路径等选项,建议保持默认设置,对于提示是否安装显卡驱动,选择 “no”,因为之前已经安装过了。安装完成后,配置环境变量,打开 “~/.bashrc” 文件(使用 “vim ~/.bashrc” 命令),在文件末尾添加以下内容:
export PATH=/usr/local/cuda-11.8/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}保存并退出文件后,执行 “source ~/.bashrc” 命令使环境变量生效。在安装过程中,若遇到依赖问题,可通过安装相应的依赖包解决,例如安装 “build-essential” 等包。
3. 验证安装:在终端输入 “nvidia -smi” 命令,若能正确显示显卡信息和驱动版本,则说明显卡驱动安装成功;输入 “nvcc -V” 命令,若能显示 CUDA Toolkit 的版本信息,则说明 CUDA Toolkit 安装成功。如果验证失败,可检查安装过程是否有错误提示,或者重新安装。
(三)安装 cuDNN
- 下载匹配版本:注册并登录 NVIDIA 开发者账号后,访问 cuDNN 下载页面(https://developer.nvidia.com/rdp/cudnn-archive) ,根据已安装的 CUDA Toolkit 11.8 版本,下载对应的 cuDNN 版本,例如 cuDNN v8.6.0 (November 9th, 2022), for CUDA 11.8 。下载时需注意选择 Linux 版本的压缩包。在下载过程中,可能需要接受 NVIDIA 的使用协议。
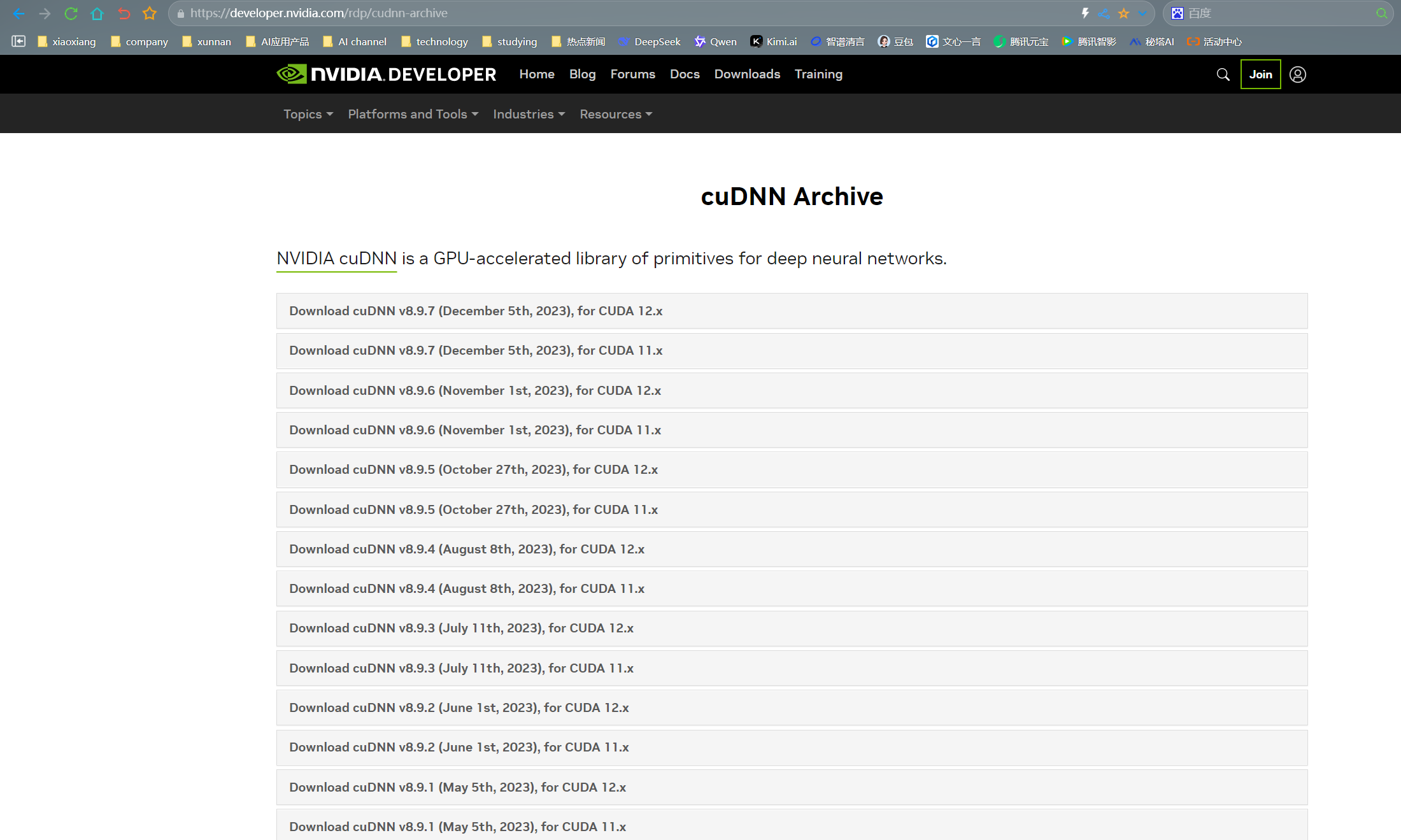
- 解压与拷贝文件:下载完成后,进入下载目录,解压 cuDNN 压缩包,例如 “tar -xzvf cudnn-linux-x86_64-8.6.0.163_cuda11-archive.tgz” 。解压后,将解压出的文件拷贝到 CUDA 目录下,执行以下命令:
sudo cp cudnn-linux-x86_64-8.6.0.163_cuda11-archive/include/cudnn*.h /usr/local/cuda-11.8/include
sudo cp -P cudnn-linux-x86_64-8.6.0.163_cuda11-archive/lib/libcudnn* /usr/local/cuda-11.8/lib64在拷贝过程中,确保目标目录存在,若不存在可手动创建。
3. 权限设置与验证:为拷贝过去的文件设置权限,执行命令:
sudo chmod a+r /usr/local/cuda-11.8/include/cudnn*.h /usr/local/cuda-11.8/lib64/libcudnn*设置完成后,验证 cuDNN 是否安装成功,进入 CUDA 示例代码目录 “/usr/local/cuda-11.8/samples/1_Utilities/deviceQuery” ,执行 “make” 命令编译示例代码,然后运行生成的可执行文件 “./deviceQuery” ,若输出结果中显示 “Result = PASS”,则说明 cuDNN 安装成功。如果验证失败,可检查文件路径和权限设置是否正确。
(四)安装 conda

- 下载安装脚本:使用 wget 命令下载 Anaconda 安装脚本,在终端输入:
wget https://repo.anaconda.com/archive/Anaconda3-2023.07-0-Linux-x86_64.sh确保网络连接正常,若下载失败,可尝试更换网络或重新下载。
2. 运行安装脚本:下载完成后,给予安装脚本执行权限
chmod +x Anaconda3-2023.07-0-Linux-x86_64.sh然后执行安装脚本
bash Anaconda3-2023.07-0-Linux-x86_64.sh按照提示逐步完成安装,包括阅读许可协议(按 “Enter” 键浏览,输入 “yes” 接受协议)、选择安装路径(默认路径为 “/home/your_username/anaconda3”,可根据需求修改)等。在安装过程中,可能会提示是否初始化 Anaconda,选择 “yes”。
3. 配置环境变量:安装完成后,若安装过程中未自动配置环境变量,可手动配置。打开 “~/.bashrc” 文件,在文件末尾添加
export PATH=/home/your_username/anaconda3/bin:$PATH(将 “your_username” 替换为实际的用户名),保存并退出文件后,执行 “source ~/.bashrc” 命令使环境变量生效。执行 “conda --version” 命令,若能显示 conda 版本信息,则说明安装成功。如果环境变量配置失败,可检查路径是否正确,或者重新配置。
(五)安装 docker
- 更新 apt 包:打开终端,输入以下命令更新 apt 包索引:
sudo apt-get update确保系统能够获取到最新的软件包信息。
2. 安装必要依赖:安装一些必要的依赖包,以支持 docker 的安装和运行,执行命令:
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common这些依赖包分别用于支持 https 传输、证书验证、文件下载和软件源管理等功能。
3. 添加 docker 官方 GPG 秘钥与 APT 源:通过以下命令添加 docker 官方的 GPG 秘钥,以确保软件包的安全性:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg然后添加 docker 的 APT 源,执行命令:
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null4.安装 docker 社区版与 nvidia-docker2:再次更新 apt 包索引 “sudo apt-get update” ,然后安装 docker 社区版 “sudo apt-get install -y docker-ce docker-ce-cli containerd.io” ,安装完成后,验证 docker 是否安装成功,执行命令 “sudo docker run hello - world” ,若能正常输出 “Hello from Docker!” 等信息,则说明 docker 安装成功。接着安装 nvidia-docker2,执行命令:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo systemctl restart dockernvidia-docker2 用于支持在 docker 容器中使用 NVIDIA GPU。在安装过程中,若遇到源无法访问等问题,可检查网络连接或更换源地址。我之前写了一篇更详细文章,专门写安装docker的,欢迎查看:https://xiaoxiang113.blog.csdn.net/article/details/137970794
(六)部署软件
在 Linux 本地搭建「超酷数字人 LiveTalking」的完整流程如下,已综合 2025-09 最新社区实践,亲测可用。
整套方案 = LiveTalking 主框架 + MuseTalk 高清口型 + GPT-SoVITS 声音克隆 + WebRTC 网页推拉流,30 min 内可跑通,支持 2 K 虚拟形象、实时打断、音色复刻。
1 硬件与系统准备
-
系统:Ubuntu 20.04/22.04 桌面或 Server 均可
-
GPU:≥ RTX 3060 12 G(MuseTalk 全精度 8 G 显存占满,留 4 G 给 GPT-SoVITS)
-
驱动:NVIDIA Driver ≥ 535,CUDA 12.2+(
nvidia-smi能看到 CUDA Version) -
工具链
sudo apt update && sudo apt install -y git ffmpeg wget unzip build-essential portaudio19-dev
2 一键装依赖(Miniconda + PyTorch)
# 1. 安装 miniconda(若已装可跳过)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda3
source $HOME/miniconda3/bin/activate
# 2. 创建隔离环境
conda create -n nerfstream python=3.10 -y
conda activate nerfstream
# 3. 安装 CUDA 12.2 对应 PyTorch(官方验证过的组合)
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=12.2 -c pytorch -c nvidia3 拉代码 & 装 LiveTalking
git clone https://github.com/lipku/LiveTalking.git
cd LiveTalking
pip install -r requirements.txt
# 安装 mmcv 全家桶(必须顺序执行,否则 MuseTalk 会报 Cython 错误)
pip install -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"4 下载模型权重(2 步搞定)
-
MuseTalk 官方权重
# 使用国内镜像加速
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download TMElyralab/MuseTalk \
--local-dir models \
--include "musetalk/musetalk.json" "musetalk/pytorch_model.bin" \
"musetalk/unet.pth" "musetalk/vae.pth"2.默认数字人形象
wget https://github.com/lipku/LiveTalking/releases/download/v0.1/musetalk_avatar1.tar.gz
tar -xf musetalk_avatar1.tar.gz -C data/avatars/5 (可选但超酷)本地 GPT-SoVITS 声音克隆
# 1. 再起一个环境,避免依赖冲突
conda create -n sovits python=3.10 -y
conda activate sovits
# 2. 拉分支代码(带 API v2)
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS
pip install -r requirements.txt
# 3. 随便录 10 s 目标音色,命名 zero_shot_prompt.wav 放 ~/ 下
# 4. 启动声音服务(默认端口 9880)
python api_v2.py留好这个终端,保持 9880 端口常驻。
6 启动「超酷数字人」
回到 LiveTalking 目录,执行:
conda activate nerfstream
python app.py \
--transport webrtc \
--model musetalk \
--avatar_id musetalk_avatar1 \
--tts gpt-sovits \
--TTS_SERVER http://127.0.0.1:9880 \
--REF_FILE ~/zero_shot_prompt.wav \
--REF_TEXT "大家好,我是由 LiveTalking 驱动的超酷数字人"看到 Running on http://0.0.0.0:8010 即代表成功。
7 网页体验
-
打开 Chrome / Edge 浏览器
地址栏输入:http://<你的本机 IP>:8010/webrtcapi.html -
点击「Start」→ 出现 25 fps 高清数字人画面
-
在下方文本框输入任意中文 → Send → 数字人实时开口,口型与 GPT-SoVITS 克隆音色完全同步,延迟 300 ms 级
-
支持打开多个标签页(
--max_session N)多人同时对话
8 常见问题速解
-
显存不足 → 加
--fp16或改用wav2lip模型(画质降但 6 G 可跑) -
端口被占 →
lsof -i:8010杀掉进程或换--port -
没有声音 → 检查系统默认音频设备,或浏览器允许自动播放
-
MuseTalk 报错「No module named mmcv」→ 一定是 mim 安装顺序错,重装即可
9 进阶玩法
-
替换自己的形象
录一段 2-3 min 闭嘴静默 视频,256×256 以上,执行python genavatar.py --video_path your_video.mp4 --avatar_id myhero把生成结果目录拷到
data/avatars/myhero,启动时--avatar_id myhero即可。 -
接入大模型对话
在app.py里把llm_callback换成任意 API(ChatGLM、Kimi、Coze 工作流),就能实现“张口即问,数字人秒回”。 -
透明背景 + 虚拟直播
商业版支持 alpha 通道推送 OBS;开源版可用 FFmpeg 后期抠像,或直接绿幕录制。
至此,Linux 本地「超酷数字人 LiveTalking」搭建完毕, Enjoy !
4.自定义数字人形象(以 musetalk 模型为例)
在众多模型中,musetalk 模型脱颖而出,因其卓越的表现和对自定义数字人形象的良好支持,成为了我们的首选。它能够依据输入的音频精准地修改面部图像,实现口型与声音的高度同步,为用户带来极为逼真的数字人交互体验。
在开始训练前,我们需要精心准备一个用于训练的视频文件。这个视频文件至关重要,它的质量和内容将直接影响到最终数字人的形象和表现。建议选择一个清晰、稳定,且人物面部特征明显的视频。例如,可以选择一段专业拍摄的人物访谈视频,视频中的人物在光线充足的环境下,清晰自然地进行着对话,这样能够为训练提供丰富且准确的面部表情和口型信息。准备好视频文件后,通过以下命令将其拷贝到 liveTalking 容器内部:
docker cp /path/to/your/video.mp4 <containerId>:/app/musetalk这里的/path/to/your/video.mp4需替换为实际视频文件的路径,<containerId>则替换为 liveTalking 容器的 ID。你可以通过docker ps命令查看正在运行的容器 ID。
完成视频文件的拷贝后,我们就可以进入 musetalk 目录,开始激动人心的训练之旅了。在容器内部执行以下命令进入 musetalk 目录:
cd /app/musetalk随后,使用样例视频进行训练,执行命令:
python simple_musetalk.py --avatar_id 4 --file /app/musetalk/video.mp4其中,--avatar_id 4中的4代表你希望训练的数字人形象编号,你可以根据自己的需求进行修改。--file /app/musetalk/video.mp4指定了训练使用的视频文件路径,确保路径与你之前拷贝到容器内的视频文件路径一致。在训练过程中,你可以通过观察命令行输出的日志信息,了解训练的进度和状态。例如,日志中会显示每一轮训练的损失值,随着训练的进行,损失值会逐渐降低,这表明模型正在不断学习和优化。
5.常见问题及解决方法
在搭建 LiveTalking 的过程中,可能会遇到各种各样的问题,下面为大家列举一些常见问题及解决方法:
- 依赖安装失败:在执行pip install -r requirements.txt安装依赖库时,可能会由于网络不稳定、包版本冲突等原因导致安装失败。如果是网络问题,可以尝试更换网络源,如使用清华大学镜像源
;若是包版本冲突,可查看报错信息,手动指定包的版本进行安装,例如pip install package_name==specific_version 。 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- 服务启动报错:启动 LiveTalking 服务时,可能会出现端口被占用、配置文件错误等导致启动失败的情况。若提示端口被占用,可使用netstat -tunlp | grep 端口号命令查看占用该端口的进程,然后使用kill -9 进程号命令关闭该进程,再重新启动服务;若是配置文件错误,仔细检查配置文件中的各项参数,确保模型路径、音频设备 ID 等设置正确。
- 模型下载失败:在下载预训练模型时,可能因网络问题或模型链接失效导致下载失败。可以尝试手动下载模型文件,然后将其放置到项目指定的目录下。同时,关注项目官方文档或社区,获取最新的模型下载方式和链接。
- CUDA 相关错误:如果在运行过程中出现 CUDA 相关错误,如 “CUDA out of memory”,这可能是因为 GPU 内存不足。可以尝试减少模型的批量大小(batch size),或者关闭其他占用 GPU 资源的程序;若提示 “CUDA driver version is insufficient for CUDA runtime version”,说明 CUDA 驱动版本与 CUDA Toolkit 版本不匹配,需要更新 CUDA 驱动或 CUDA Toolkit 到兼容版本。
6.总结
通过以上详细的步骤,我们成功地在 Linux 本地搭建了数字人实时交互 LiveTalking,从系统环境配置、软件安装到数字人形象的自定义训练,每一步都凝聚着技术的魅力和探索的乐趣。在这个过程中,我们克服了可能遇到的各种问题,见证了数字人技术从理论到实践的跨越。
LiveTalking 作为一款强大的开源实时互动数字人引擎,为我们打开了一扇通往未来交互体验的大门。它在电商直播、在线教育、虚拟客服等领域的应用前景广阔,有望为这些行业带来全新的变革和发展机遇。例如,在电商直播中,数字人主播可以不知疲倦地工作,为观众提供 24 小时不间断的服务;在在线教育领域,数字人老师能够根据学生的学习情况提供个性化的教学方案,提升学习效果。
如果你对数字人技术充满热情,那么不妨亲自尝试搭建 LiveTalking,感受数字人与你实时互动的奇妙体验。在实践过程中,你可能会遇到新的问题,也可能会有独特的发现和创新,欢迎在评论区分享你的经验和心得,让我们一起在数字人的世界里探索前行,共同推动数字人技术的发展和应用。
官方文档:官方文档提供了详细的使用说明和技术细节,链接为https://livetalking-doc.readthedocs.io/ 。在搭建和使用 LiveTalking 的过程中,遇到任何问题都可以查阅官方文档来获取解决方案。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 24
24 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)