腾讯开源啦,源码地址+部署脚本,1B参数小身板扛起OCR界SOTA大旗
腾讯混元全新开源的HunyuanOCR模型横空出世,参数仅1B却直接拿下多项OCR应用榜单的SOTA。这种端到端设计、多场景适配、小语种支持等这些细节背后,是对开发者真实需求的深度洞察。
大家好,我是小悟。
腾讯混元全新开源的HunyuanOCR模型横空出世,参数仅1B却直接拿下多项OCR应用榜单的SOTA。
这波操作确实厉害,毕竟在动辄百亿参数的AI模型江湖里,1B的“轻量级选手”能打出如此漂亮的组合拳,确实让人眼前一亮。

传统OCR模型像流水线工人,文字检测、识别、结构化分析得一步步来,任何一个环节掉链子,最终结果都得翻车。
而HunyuanOCR直接“开挂”:原生分辨率视频编码器负责抓取图像细节,自适应视觉适配器像“翻译官”把视觉信号转成机器能懂的语言,轻量化混元语言模型再一锤定音输出结果。整个过程单次前向推理就能完成,效率比级联方案高出一大截。

举个例子,以前识别一张复杂票据,得先定位文字区域,再逐个字符识别,最后拼凑成结构化数据,整个流程下来像拆盲盒,你永远不知道哪一步会卡壳。
现在用HunyuanOCR,输入图片后模型直接输出JSON格式的字段,姓名、地址、金额一目了然,连公式表格都能自动转成LaTeX/HTML代码。

如果说效率是HunyuanOCR的“快”,那性能就是它的“狠”。在OmniDocBench复杂文档解析评测中,直接砍下94.1分,把谷歌Gemini3-pro等一众大佬甩在身后。
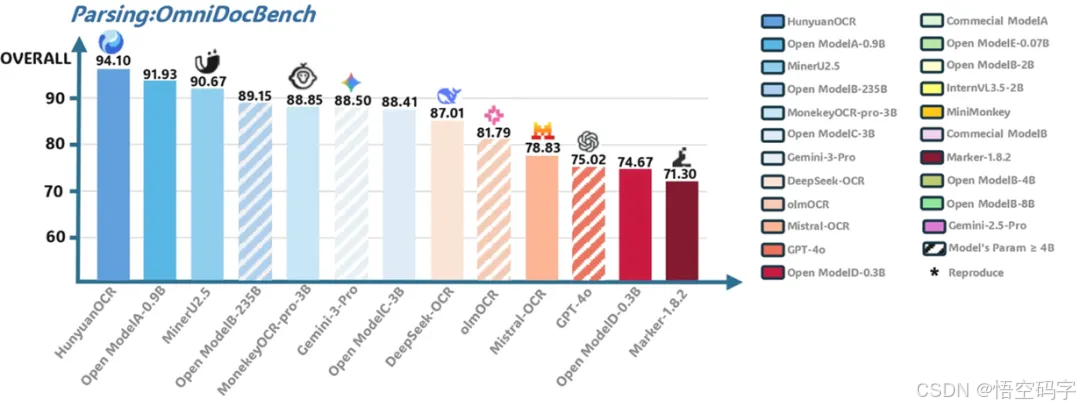
它自建的9大场景基准测试(文档、艺术字、街景、手写、广告、票据、截屏、游戏、视频)里,文字检测识别准确率像坐了火箭一样飙升,连商业OCR模型都得喊一声“前辈”。
看下测试数据:在OCRBench榜单上,HunyuanOCR以1B参数斩获总参数3B以下模型的SOTA,总分860分。

这什么概念?相当于用五菱宏光的油耗跑出了法拉利的速度,还顺便拿了节能奖。
更绝的是,它连小语种翻译都没放过,德语、西班牙语、阿拉伯语……这些让开发者头疼的“冷门语言”,现在都能一键翻译。

技术再牛,得落地才有价值。HunyuanOCR的实战表现也没让人失望,票据字段抽取能精准定位关键信息。

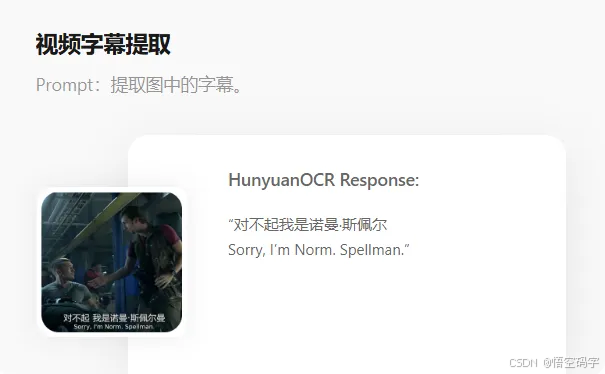
视频字幕识别支持中英双语自动生成,拍照翻译功能覆盖14种语言,连街景广告里的手写体都能准确识别。
1B参数这么小的模型,真能扛住复杂场景的考验?
通过规模化高质量数据训练+在线强化学习,小参数模型照样能玩出花。这种设计思路其实暗合了当前AI落地的核心需求:不是所有场景都需要“大力出奇迹”,很多时候我们更需要的是“小而美”的解决方案。
比如跨境电商的商品描述翻译、金融行业的票据自动化处理、教育领域的课件字幕生成……这些场景不需要百亿参数的“巨无霸”,但需要高效、稳定、易部署的轻量化模型。

作为技术圈的“吃瓜群众”,这种端到端设计、多场景适配、小语种支持……这些细节背后,是对开发者真实需求的深度洞察。
开源只是第一步,至少现在,它已经给轻量化OCR模型树立了一个标杆,原来1B参数也能这么“能打”。
本地安装与使用,源代码部署,更多详细步骤和用法,详见仓库文档:
1、安装
使用 pip:
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
使用 uv
uv pip install vllm --extra-index-url https://wheels.vllm.ai/nightly
2、模型推理
from vllm import LLM, SamplingParams
from PIL import Image
from transformers import AutoProcessor
def clean_repeated_substrings(text):
"""Clean repeated substrings in text"""
n = len(text)
if n<8000:
return text
for length in range(2, n // 10 + 1):
candidate = text[-length:]
count = 0
i = n - length
while i >= 0 and text[i:i + length] == candidate:
count += 1
i -= length
if count >= 10:
return text[:n - length * (count - 1)]
return text
model_path = "tencent/HunyuanOCR"
llm = LLM(model=model_path, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_path)
sampling_params = SamplingParams(temperature=0, max_tokens=16384)
img_path = "/path/to/image.jpg"
img = Image.open(img_path)
messages = [
{"role": "user", "content": [
{"type": "image", "image": img_path},
{"type": "text", "text": "检测并识别图片中的文字,将文本坐标格式化输出。"}
]}
]
prompt = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = {"prompt": prompt, "multi_modal_data": {"image": [img]}}
output = llm.generate([inputs], sampling_params)[0]
print(clean_repeated_substrings(output.outputs[0].text))
开源地址:


谢谢你看我的文章,既然看到这里了,如果觉得不错,随手点个赞、转发、在看三连吧,感谢感谢。那我们,下次再见。
您的一键三连,是我更新的最大动力,谢谢
山水有相逢,来日皆可期,谢谢阅读,我们再会
我手中的金箍棒,上能通天,下能探海

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)