第2.1讲、《The Annotated Transformer》论文解读
《The Annotated Transformer》是哈佛大学 NLP 团队对经典论文《Attention is All You Need》的逐行讲解式实现,旨在帮助开发者深入理解 Transformer 模型的内部机制与实现细节。文章通过 PyTorch 代码详细解析了 Transformer 的核心模块,包括编码器、解码器、多头注意力机制、位置编码、前馈神经网络等。项目目标是通过简洁、逐行注
📘 前言
《The Annotated Transformer》是哈佛大学 NLP 团队对经典论文《Attention is All You Need》的逐行讲解式实现,
使用 PyTorch 编写,目的是帮助开发者深入理解 Transformer 模型的内部机制与实现细节。本文将对这篇文章进行系统性的解读
适合对深度学习与自然语言处理(NLP)感兴趣的技术人员与研究者阅读。
🧠 一、项目背景与目标
Transformer 是一种完全基于注意力机制的神经网络架构,由 Google 于 2017 年提出。它彻底摆脱了 RNN 和 CNN 对序列处理的限制,
实现了高效并行和优秀的长期依赖建模能力。
《The Annotated Transformer》的目标是:
- 用简洁、明了、逐行注释的 PyTorch 代码复现 Transformer
- 帮助读者理解 Transformer 的关键模块和实现原理
- 作为学习、研究和二次开发的良好起点
🧱 二、Transformer 模型结构概览
Transformer 的整体结构分为:
- 编码器(Encoder)
- 解码器(Decoder)
- 多头注意力机制(Multi-Head Attention)
- 位置编码(Positional Encoding)
- 前馈神经网络(Feed-Forward Network)
- 残差连接 + 层归一化(Residual Connection + LayerNorm)

🔍 三、核心模块解析与代码说明
1️⃣ 模块克隆工具 clones
该函数用于生成多个重复子层结构(例如 6 层编码器):
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
2️⃣ 位置编码(Positional Encoding)
由于 Transformer 不具备序列结构,需要人为加入位置感知:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
PyTorch 实现:
class PositionalEncoding(nn.Module):
def forward(self, x):
x = x + self.pe[:x.size(0)]
return self.dropout(x)
3️⃣ 注意力机制(Scaled Dot-Product Attention)
计算 Query 与 Key 的点积、归一化、Softmax 后加权 Value:
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
p_attn = F.softmax(scores, dim=-1)
return torch.matmul(p_attn, value), p_attn
4️⃣ 多头注意力机制(Multi-Head Attention)
多头注意力将注意力过程并行化:
class MultiHeadedAttention(nn.Module):
def forward(self, query, key, value, mask=None):
# 分头,注意力计算,拼接输出
5️⃣ 子层连接(残差 + 层归一化)
这是 Transformer 稳定训练的关键技巧之一。
class SublayerConnection(nn.Module):
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
这种方式被称为 Post-Norm(先归一化再残差连接)。
6️⃣ 编码器与解码器层结构
编码器层 EncoderLayer:
class EncoderLayer(nn.Module):
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
解码器层 DecoderLayer:
class DecoderLayer(nn.Module):
def forward(self, x, memory, src_mask, tgt_mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, memory, memory, src_mask))
return self.sublayer[2](x, self.feed_forward)
🔁 四、训练流程与优化器
损失函数:交叉熵 + 标签平滑
class LabelSmoothing(nn.Module):
def forward(self, x, target):
... # 使用平滑标签而非 one-hot
学习率调度器(NoamOpt)
Transformer 使用了论文中自定义的优化器调度器:
class NoamOpt:
def step(self):
lrate = factor * d_model ** (-0.5) * min(step ** (-0.5), step * warmup ** (-1.5))
🧪 五、推理与可视化
推理过程(Greedy Decode)
def greedy_decode(model, src, src_mask, max_len, start_symbol):
... # 每步生成一个词直到终止符
可视化注意力权重
项目支持使用 matplotlib 绘制每一层每个头的注意力热力图,帮助观察模型是如何捕捉输入中不同词之间关系的。
🛠 六、简单使用案例(简化)
# 输入句子:I am a student
src = torch.LongTensor([[0, 5, 8, 14, 2]]) # 模拟词表索引
model.eval()
output = greedy_decode(model, src, src_mask, max_len=10, start_symbol=1)
print("模型输出:", output)
🛠 七、注意力可视化(Attention Visualization )
tgt_sent = trans.split()
def draw(data, x, y, ax):
seaborn.heatmap(data,
xticklabels=x, square=True, yticklabels=y, vmin=0.0, vmax=1.0,
cbar=False, ax=ax)
for layer in range(1, 6, 2):
fig, axs = plt.subplots(1,4, figsize=(20, 10))
print("Encoder Layer", layer+1)
for h in range(4):
draw(model.encoder.layers[layer].self_attn.attn[0, h].data,
sent, sent if h ==0 else [], ax=axs[h])
plt.show()
for layer in range(1, 6, 2):
fig, axs = plt.subplots(1,4, figsize=(20, 10))
print("Decoder Self Layer", layer+1)
for h in range(4):
draw(model.decoder.layers[layer].self_attn.attn[0, h].data[:len(tgt_sent), :len(tgt_sent)],
tgt_sent, tgt_sent if h ==0 else [], ax=axs[h])
plt.show()
print("Decoder Src Layer", layer+1)
fig, axs = plt.subplots(1,4, figsize=(20, 10))
for h in range(4):
draw(model.decoder.layers[layer].self_attn.attn[0, h].data[:len(tgt_sent), :len(sent)],
sent, tgt_sent if h ==0 else [], ax=axs[h])
plt.show()
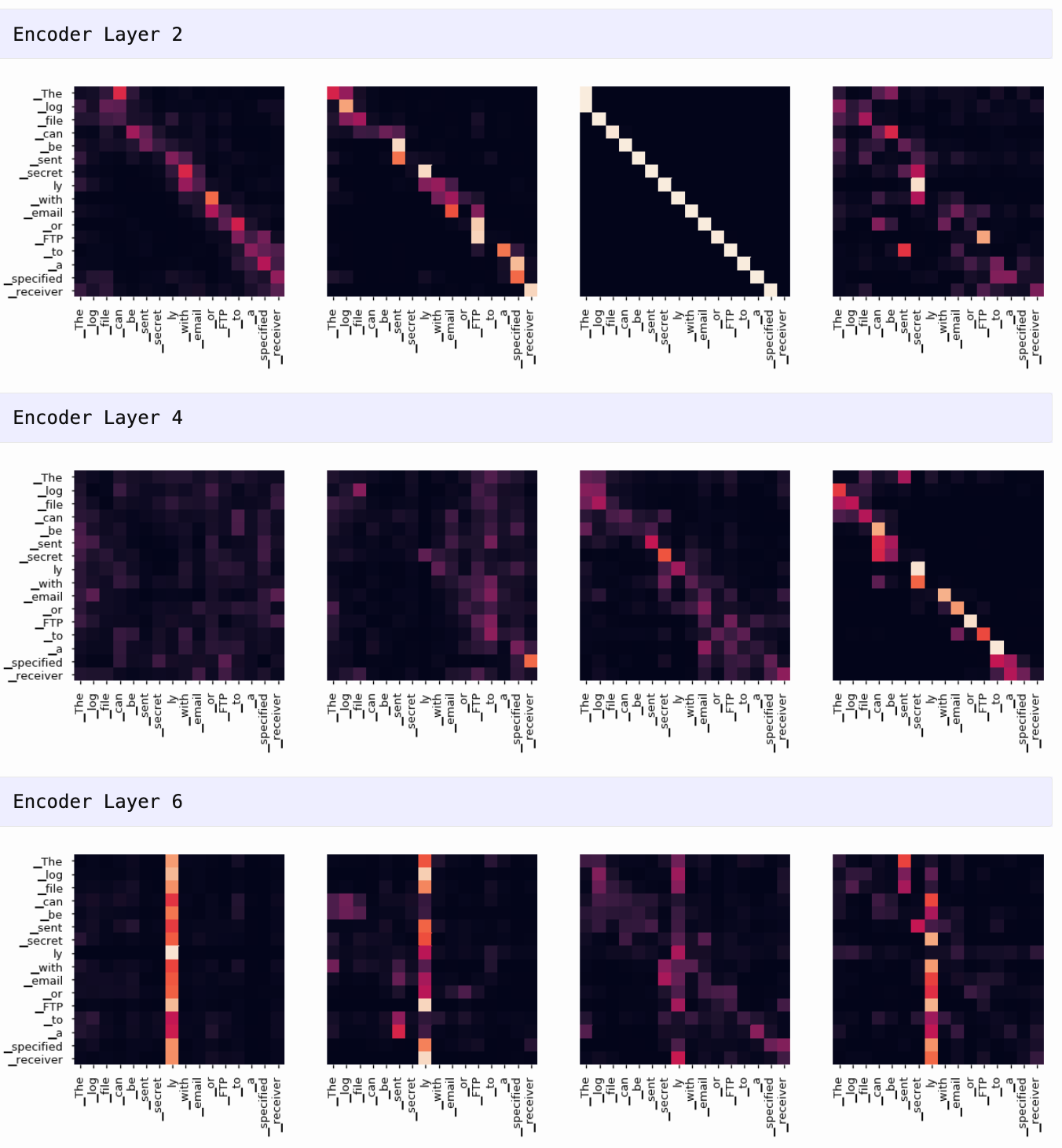
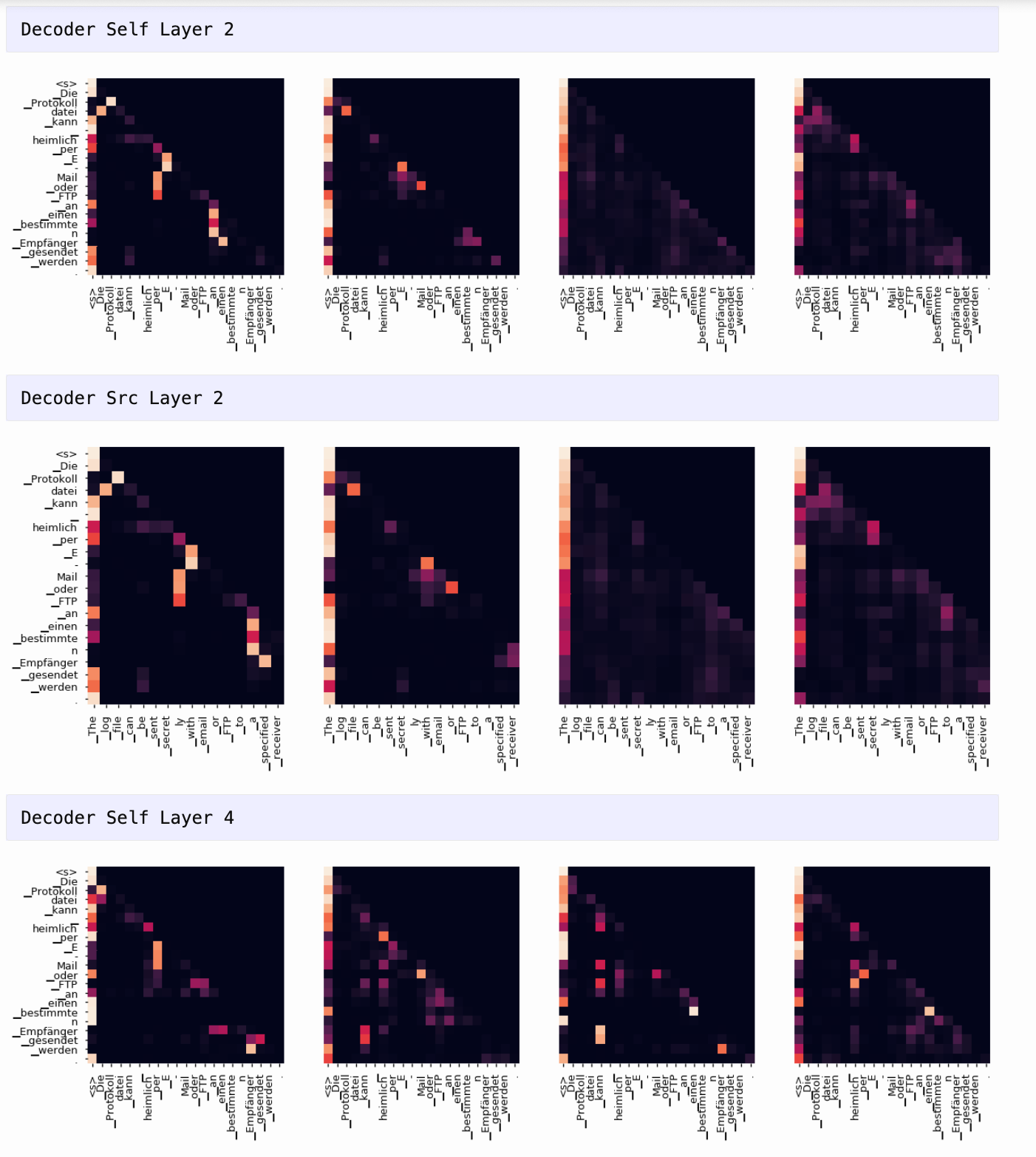
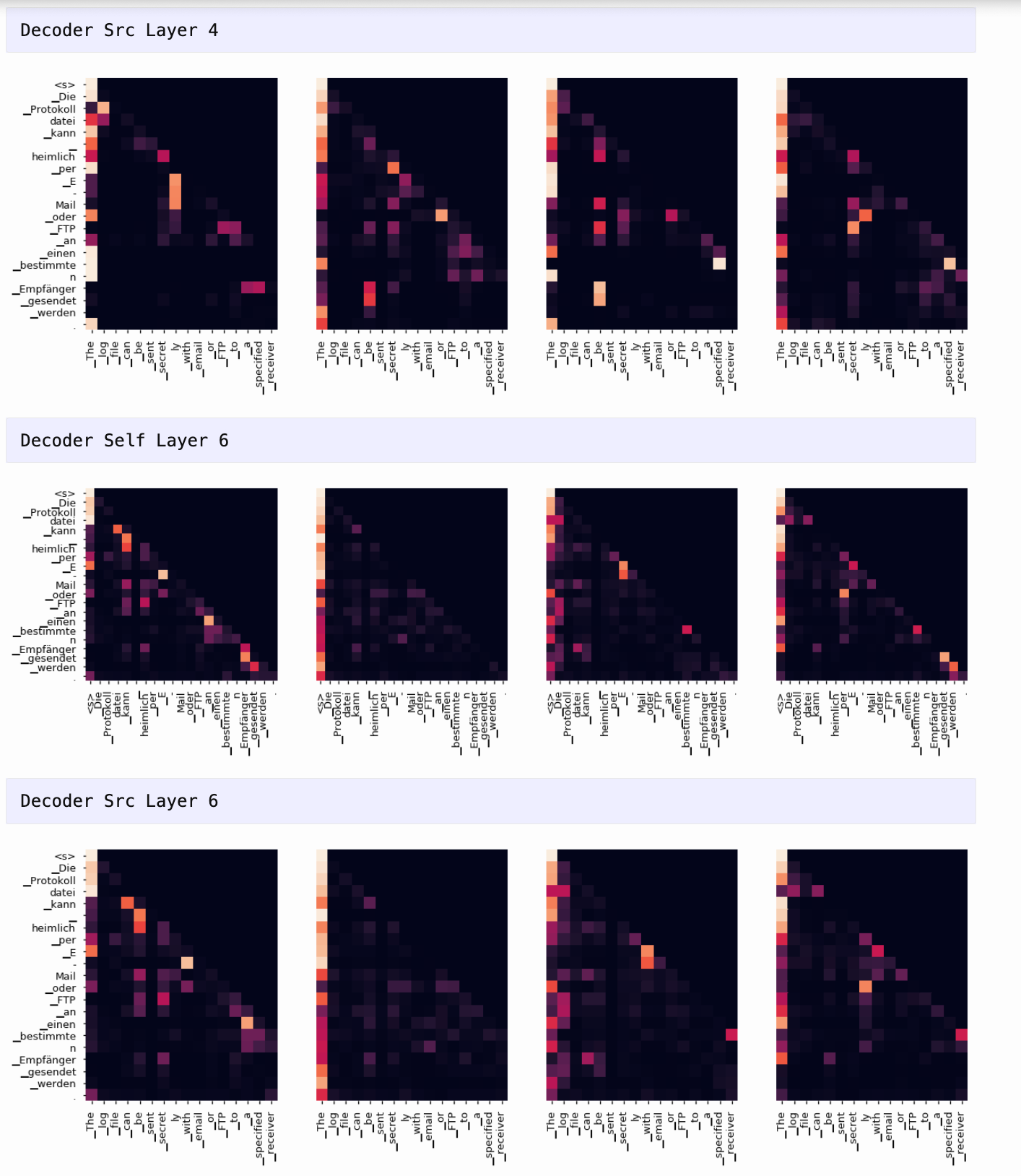
📝 八、总结与启示
| 模块 | 作用 | 特点 |
|---|---|---|
| 编码器 | 提取输入特征 | 多头注意力 + 前馈网络 |
| 解码器 | 逐步生成输出 | Masked Attention + 编码器联动 |
| 注意力机制 | 聚焦关键信息 | Query-Key-Value 模型 |
| 残差连接 | 防梯度消失 | 提高深层网络稳定性 |
| 位置编码 | 加入顺序信息 | sin/cos 周期函数 |
理解 Transformer 的三个关键:
- 一切皆注意力(All Attention)
- 模块化、组合式设计
- 高度并行训练能力
🔗 项目资源与延伸阅读

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)