DeepSeek-R1-Distill-Qwen-32B 不输出“<think>\n“解决方法
DeepSeek-R1-Distill-Qwen-32B 不输出"<think>\n"解决方法
使用LLaMA-Factory部署DeepSeek-R1-Distill-Qwen-32B时发现,模型的输出有时候并不会以<think>开头,但还是会输出<\think>。https://github.com/deepseek-ai/DeepSeek-R1/issues/352。
分析原因:
问题出在https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B/blob/main/tokenizer_config.json的chat_template里。下图是问题所在之处:

这里设置成这样是为了保证让模型的生成是以"<think>\n"开头的,然后开始思考过程,避免模型没有以"<think>\n"开头而不思考直接输出结果。
但在输出里却没看到<think>,是因为这个<think>已经是属于prompt部分了,不在输出部分里。
解决方法:
方法一:
直接在https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B/blob/main/tokenizer_config.json里的chat_template改,删掉"<think>\\n",但这样就可能导致模型跳过思考过程。
DeepSeek-R1官方仓库也说推荐设置"<think>\n"为开头。

方法二:
我使用的是LLaMA-Factory仓库,设置template为qwen(不会像现在的deepseek3模板一样把<think>加到前面),使用Vllm部署的。可以直接去里面改一下代码,在模型生成时,强行把第一个token设置成<think>。
将vllm_engine.py里的_generate函数改一下:
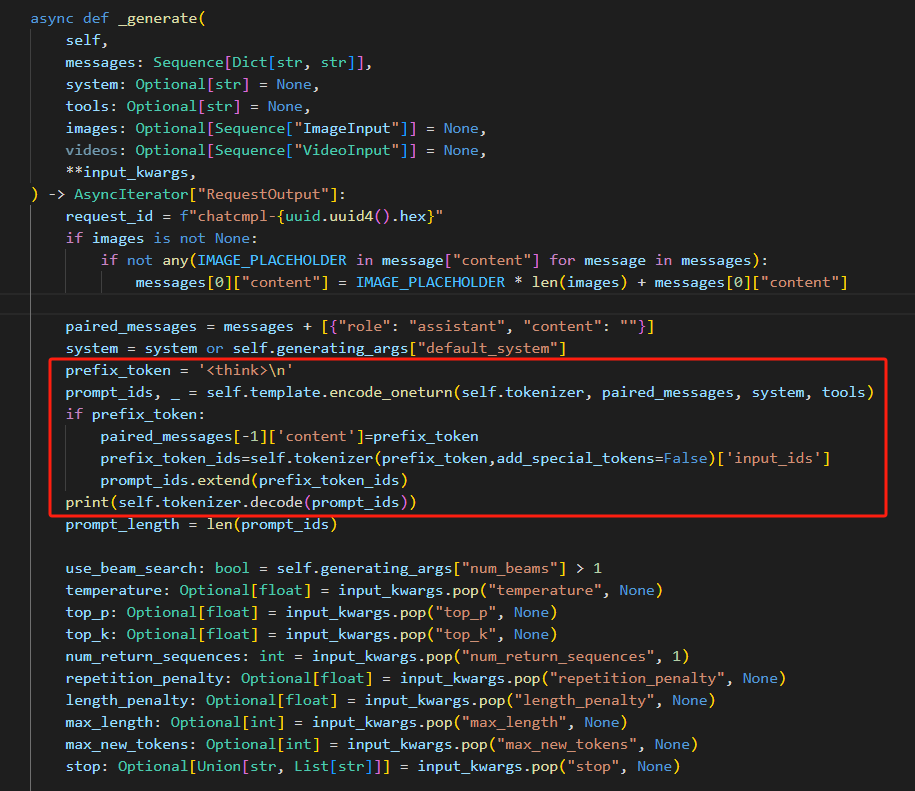
主要思路就是在把对话经过chat_template变成prompt_ids后,给prompt_ids后面加上"<think>\n"对应的词表id。然后再让Vllm去给prompt做续写。
改完后该函数代码如下:
async def _generate(
self,
messages: Sequence[Dict[str, str]],
system: Optional[str] = None,
tools: Optional[str] = None,
images: Optional[Sequence["ImageInput"]] = None,
videos: Optional[Sequence["VideoInput"]] = None,
**input_kwargs,
) -> AsyncIterator["RequestOutput"]:
request_id = f"chatcmpl-{uuid.uuid4().hex}"
if images is not None:
if not any(IMAGE_PLACEHOLDER in message["content"] for message in messages):
messages[0]["content"] = IMAGE_PLACEHOLDER * len(images) + messages[0]["content"]
paired_messages = messages + [{"role": "assistant", "content": ""}]
system = system or self.generating_args["default_system"]
prefix_token = '<think>\n'
prompt_ids, _ = self.template.encode_oneturn(self.tokenizer, paired_messages, system, tools)
if prefix_token:
paired_messages[-1]['content']=prefix_token
prefix_token_ids=self.tokenizer(prefix_token,add_special_tokens=False)['input_ids']
prompt_ids.extend(prefix_token_ids)
# print(self.tokenizer.decode(prompt_ids))
prompt_length = len(prompt_ids)
use_beam_search: bool = self.generating_args["num_beams"] > 1
temperature: Optional[float] = input_kwargs.pop("temperature", None)
top_p: Optional[float] = input_kwargs.pop("top_p", None)
top_k: Optional[float] = input_kwargs.pop("top_k", None)
num_return_sequences: int = input_kwargs.pop("num_return_sequences", 1)
repetition_penalty: Optional[float] = input_kwargs.pop("repetition_penalty", None)
length_penalty: Optional[float] = input_kwargs.pop("length_penalty", None)
max_length: Optional[int] = input_kwargs.pop("max_length", None)
max_new_tokens: Optional[int] = input_kwargs.pop("max_new_tokens", None)
stop: Optional[Union[str, List[str]]] = input_kwargs.pop("stop", None)
if "max_new_tokens" in self.generating_args:
max_tokens = self.generating_args["max_new_tokens"]
elif "max_length" in self.generating_args:
if self.generating_args["max_length"] > prompt_length:
max_tokens = self.generating_args["max_length"] - prompt_length
else:
max_tokens = 1
if max_length:
max_tokens = max_length - prompt_length if max_length > prompt_length else 1
if max_new_tokens:
max_tokens = max_new_tokens
sampling_params = SamplingParams(
n=num_return_sequences,
repetition_penalty=(
repetition_penalty if repetition_penalty is not None else self.generating_args["repetition_penalty"]
)
or 1.0, # repetition_penalty must > 0
temperature=temperature if temperature is not None else self.generating_args["temperature"],
top_p=(top_p if top_p is not None else self.generating_args["top_p"]) or 1.0, # top_p must > 0
top_k=top_k if top_k is not None else self.generating_args["top_k"],
use_beam_search=use_beam_search,
length_penalty=length_penalty if length_penalty is not None else self.generating_args["length_penalty"],
stop=stop,
stop_token_ids=[self.tokenizer.eos_token_id] + self.tokenizer.additional_special_tokens_ids,
max_tokens=max_tokens,
skip_special_tokens=True,
)
if images is not None: # add image features
image_data = []
for image in images:
if not isinstance(image, (str, ImageObject)):
raise ValueError(f"Expected image input is a path or PIL.Image, but got {type(image)}.")
if isinstance(image, str):
image = Image.open(image).convert("RGB")
image_data.append(image)
multi_modal_data = {"image": image_data}
else:
multi_modal_data = None
result_generator = self.model.generate(
inputs={"prompt_token_ids": prompt_ids, "multi_modal_data": multi_modal_data},
sampling_params=sampling_params,
request_id=request_id,
lora_request=self.lora_request,
)
return result_generator现在问"1+1=?"时,把vllm的输入print出来,发现已经有了<think>。
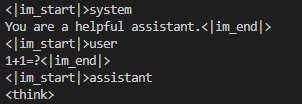
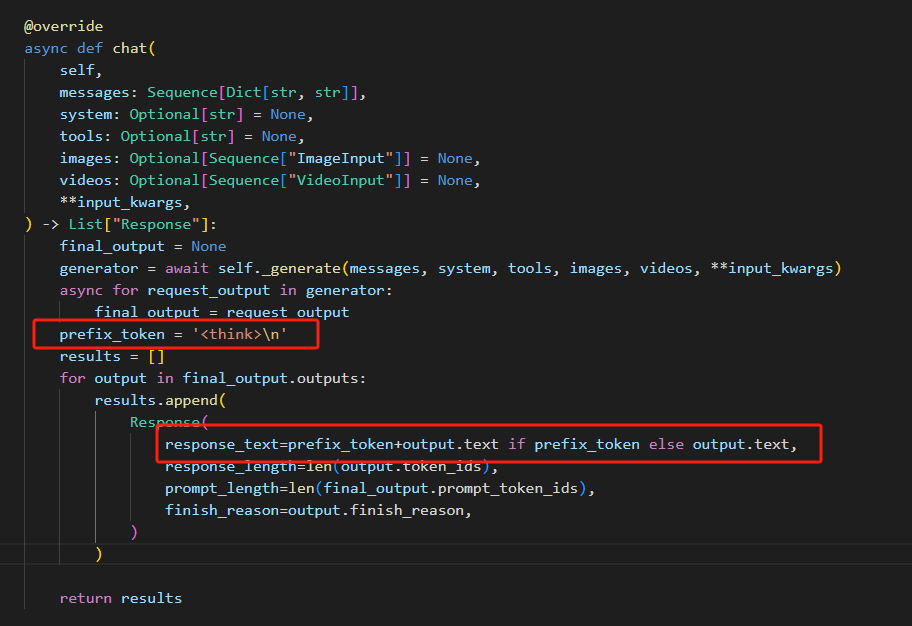
同时,记得在构造API输出时,把"<think>\n"加上,不然输出里不会显示。
非流式输出:
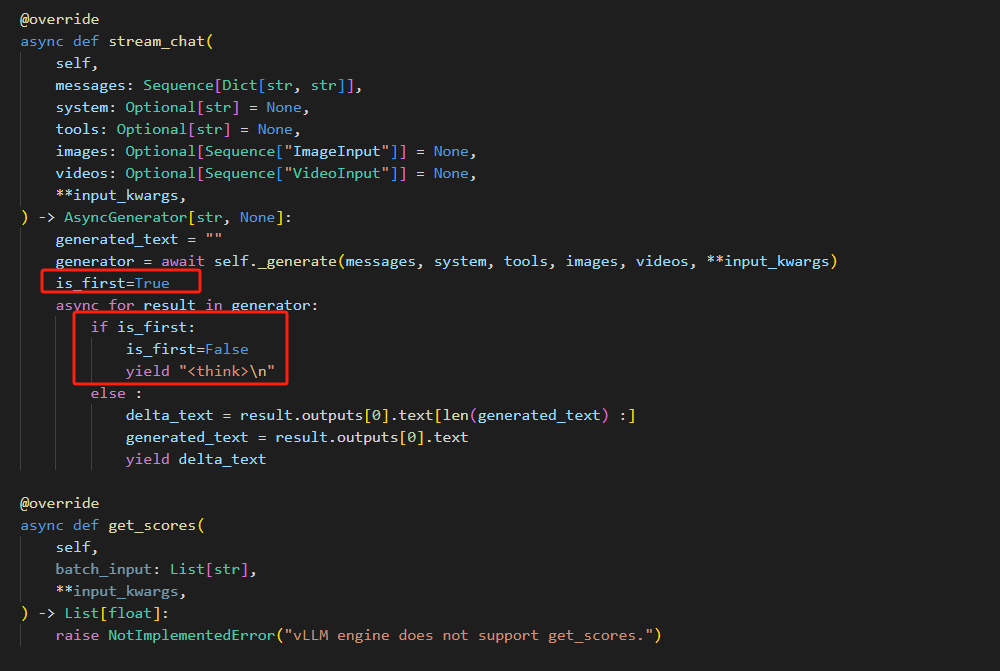
流式输出:
改完代码后重新部署。
再测试一下API:
import requests
import json
if __name__ == "__main__":
api_url = "http://xxxx/v1/chat/completions" # deepseek蒸馏qwen32b
data = {
"model": "test",
"messages": [
{
#"role": "user", "content": "树上原本有4只鸟,开枪打死一只,还剩几只?"
"role": "user", "content": "1+1=?"
},
],
"tools": [],
"do_sample": True,
"temperature": 0.6,
"top_p": 0,
"n": 1,
"max_tokens": 512,
"stream": False,
}
response = requests.post(url=api_url, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["content"])发现输出有deepseek那味儿了。
<think>
Okay, so I have this problem here: 1 + 1 equals what? Hmm, let's see. I remember from when I was a kid, my teacher showed us how to add numbers. So, if I have one apple and then I get another apple, how many apples do I have in total? That makes sense. It should be two apples, right? So, 1 plus 1 should be 2. But wait, is there a different way to look at this? Maybe in some other context, like in computer science or something? Oh, right, in binary, 1 + 1 equals 10. But I think the question is asking for basic arithmetic, not binary. So, sticking with the simple addition, 1 plus 1 is 2. Yeah, that seems right. I don't think I'm missing anything here. It's pretty straightforward.
</think>
1 + 1 equals 2.注:最新版LLaMA-Factory已经支持了DeepSeek-R1-Distill-Qwen-32B模板,需设置模板为deepseek3,但不支持强制思考。

使用最新版LLaMA-Factory测试结果如下:
每次一定会输出<think>和<\think>,但里面内容可能是空的,也就是其实没思考,只是通过自己写的模板把<think>和<\think>补上去。
<think>
</think>
1 + 1 equals 2.
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)