
大模型书籍丨《百面大模型》,一书打通大模型求职与实战
最近书单更新得有点勤,除了自己买的,还收到不少编辑社寄来的书。我挑了一些确实不错的(大概十分之一),推荐给大家!
最近书单更新得有点勤,除了自己买的,还收到不少编辑社寄来的书。我挑了一些确实不错的(大概十分之一),推荐给大家!
此外我给大家争取了福利,可以送这些书的PDF给到读者!!!
在大模型技术席卷产业的当下,相关岗位的招聘需求呈指数级增长:
招聘热岗示例:
-
• 模型工程师(如:字节·大模型平台组)
-
• 算法实习生(大模型方向,如:腾讯 AI Lab)
-
• AI 应用开发工程师(如:百度文心大模型团队)
-
• LLM 工程研发岗(如:MiniMax、Moonshot)
然而,由于技术栈更新迅速、工程挑战高度复杂、实战能力要求极高,求职者常常陷入以下困境:
常见求职痛点
-
• 面试题高度碎片化,缺乏系统学习路径
例:只刷 HuggingFace 教程或B站视频,却无法建立知识体系;碰到 “请你讲讲 KV Cache 的工作机制及优化方案” 就答不出来。
-
• 项目经验雷同,无法形成差异化竞争力
例:简历上都写 “构建了一个基于 LangChain 的问答系统”,但面试官追问“RAG 系统中的 Chunking 策略和召回机制”时无从应对。
-
• 理论与实战脱节,难以应对 Coding / 系统设计问题
例:知道 Attention 的公式,但做不出“实现简化版 Self-Attention 的伪代码”;也难以回答 “如何让大模型服务在 500ms 内响应用户请求?”
-
• 缺少对热点方向的深度理解与实操
例:只会使用开源模型部署 demo,面对 “请你优化一个多模型并发推理系统(多卡 + 多实例)” 或 “请设计一套 Agent 多角色协作调度机制” 时无从下手。
在这样的背景下,《百面大模型》应运而生,成为打通 LLM 求职与实战的关键工具书。
本书不是“背题集”,而是一部从知识体系、工程实战到项目落地全面覆盖的实战宝典,让你从“知道”到“能做”,再到“能讲清楚”。
这本《百面大模型》书已整理并打包好PDF了
放这里了↓↓↓↓

为什么你需要这本书?
通过对招聘平台、GitHub、知乎与面经社区的分析发现,大模型相关岗位的面试内容,主要集中在以下五大模块:
(1)LLM 基础与原理类问题
面试官常问:
-
• Transformer 的核心机制是什么?
-
• 为什么 Self-Attention 能捕捉长距离依赖?
-
• 微调 vs LoRA 的本质区别是什么?
这些问题考察的是你对 LLM 架构底层的理解,是所有岗位的基础门槛。
(2)工程与系统能力考察
重点考查以下技术栈:
-
• 推理加速:KV Cache 工作原理?LoRA 如何与主模型高效融合?
-
• 服务部署:vLLM、TGI 如何支持多租户?如何实现高并发推理?
-
• 分布式训练:DeepSpeed ZeRO 分层机制?FSDP 优于 DDP 的关键在哪?
这类题不仅考察技术掌握,还看你是否具备“系统工程”视角。
(3)实战项目设计题
经典高频问题:
-
• 如何构建一个 支持上下文记忆 的多轮对话系统?
-
• 从 0 到 1 设计一个 RAG 系统,你会如何选型和优化?
-
• 面向 C 端用户的智能体(Agent)系统,如何调度角色并防止 hallucination?
这类题最能拉开差距,项目理解深度决定你是否能胜任工程实践。
(4)评估与对齐类问题
包括但不限于:
-
• RLHF 的三阶段训练流程?
-
• 指令微调与 SFT 的区别?
-
• 如何设计 Prompt 来提升模型对齐性?
“对齐”问题正成为大模型落地的核心门槛,很多中高阶岗位必问。
(5)开源生态与工具库认知
常见要求:
-
• LLaMA、Mistral、Qwen 模型的差异与适用场景?
-
• Transformers、LangChain 的核心模块与使用技巧?
-
• 如何用 OpenChatKit 快速搭建一个 SFT 流水线?
工程岗与应用岗面试官普遍希望候选人能做到“调得动 +讲得清 +改得快”。
《百面大模型》为你解决什么?
面对这些挑战,《百面大模型》从实际面试需求出发,采用:
面试题 × 技术点 × 项目实战 的三位一体结构
帮助你构建从 知识扫盲 → 工程落地 → 面试通关 的完整成长路径。
-
• 不只是告诉你“答案”,而是系统拆解“原理 + 实现 + 实战”
-
• 每一类问题背后都有 真实岗位能力需求作为支撑
-
• 每一章都配有“代码实战 + 工程图解”强化理解
内容结构一览
《百面大模型》围绕 100 道核心面试题 精心编排,覆盖大模型学习与就业所需的全链路能力,内容共分为 五大部分:
第一部分:大模型的基础知识(第1章 - 第3章)
-
• 第1章 语义表达:从稀疏词向量到BERT嵌入类型,详解语义建模的基础与演进。
-
• 第2章 大模型的数据:涵盖训练数据集、预处理、数据扩展法则与灾难性遗忘问题。
-
• 第3章 大模型的预训练:梳理预训练方法与流程、显存优化、通信开销和训练效率提升策略。
第二部分:对齐与微调机制(第4章 - 第5章)
-
• 第4章 大模型的对齐:系统解析对齐数据、PPO与DPO等强化学习方法,以及训练稳定性问题。
-
• 第5章 大模型的垂类微调:聚焦于监督微调、词表扩展、外推能力、知识注入和定制化损失函数。
第三部分:大模型组件与架构(第6章 - 第8章)
-
• 第6章 大模型的组件:全面介绍Transformer架构、注意力机制、RoPE/ALiBi、归一化、Dropout与初始化等关键模块。
-
• 第7章 大模型的评估:分析评测榜单、生成式评估指标、自动化与对抗性测试及备案流程。
-
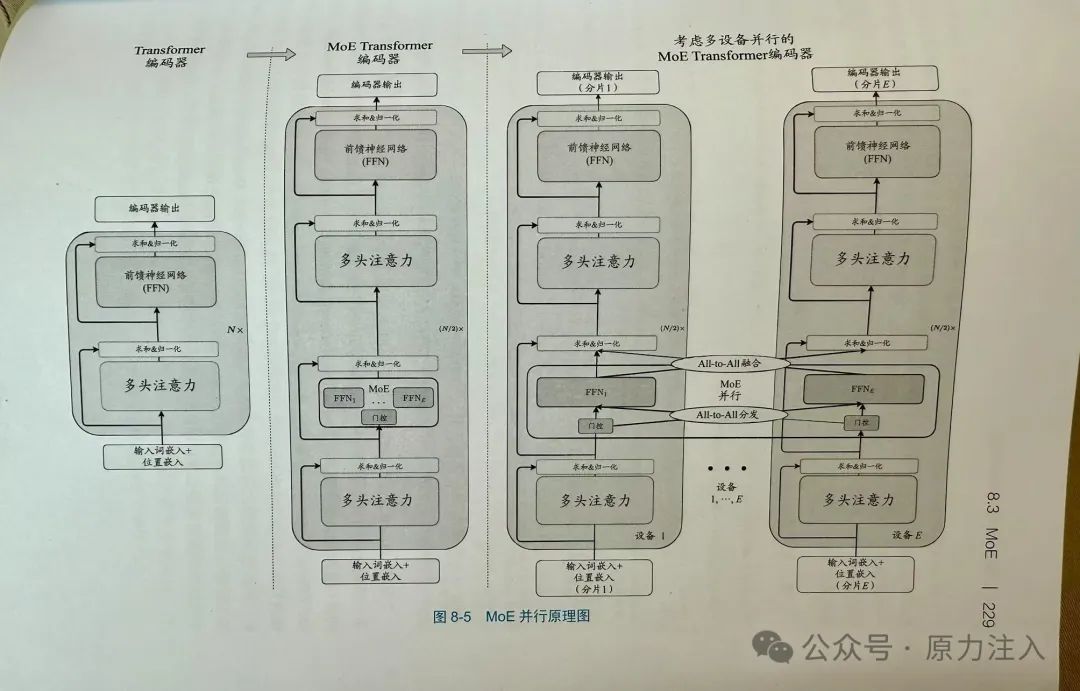
• 第8章 大模型的架构:讨论因果解码器主流架构、融合机制与稀疏专家模型(MoE)。
以下是 MoE 的图解,可以很好帮助我们理解:
第四部分:大模型关键应用实践(第9章 - 第11章)
-
• 第9章 检索增强生成:系统阐述RAG组成、召回与重排策略、以及工程化实现挑战。
-
• 第10章 大模型智能体:探讨智能体组成、规划、记忆、工具调用与主流框架如XAgent、AutoGen。
-
• 第11章 大模型PEFT:讲解LoRA、各类参数高效微调方法及其与全参数微调的差异。
第五部分:训练优化与代表性大模型解析(第12章 - 第13章)
-
• 第12章 大模型的训练与推理:深入FlashAttention、PagedAttention、专家并行、量化、并行训练策略等加速与优化技术。
-
• 第13章 DeepSeek:剖析DeepSeek模型的创新架构(如MLA与多词元预测)及其训练流程,提供典型国产大模型参考样本。
适合读者
如果你属于以下几类人群,这本书就是为你量身打造:
-
• 算法工程师 / 后端开发者:希望顺利转型 LLM 岗位,构建系统知识图谱
-
• 在校学生 / 研究生:准备大模型方向实习、校招,系统扫盲 + 精准刷题
-
• 已入职 LLM 团队成员:补齐从原理到部署的工程知识盲区
-
• AI 应用工程师 / 创业者:希望从 0 到 1 搭建 LLM 应用系统,落地 RAG / Agent 项目
总结:不只是“背题”,而是“破题+解法+实战”
《百面大模型》不是一本简单的面试题集,而是一本融合原理讲解 × 工程实践 × 面试突破的实战型技术参考书:
-
• 用真实面试题引导学习路径,建立大模型知识框架
-
• 用项目实战拆解技术细节,提升开发与部署能力
-
• 用大厂真题沉淀方法论,帮助你从“会答题”走向“能解题”
求职通关,只是起点;构建系统技术力,才是你的长期核心竞争力。
这本《百面大模型》书已整理并打包好PDF了
放这里了↓↓↓↓
更多推荐


 26
26 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)