零代码打造高效车型Lora打标流水线:n8n+图像识别大模型批量图片标签自动生成
在AI训练领域,尤其是LORA 图像等细分模型的训练,对高质量、结构化的图片标签数据有极高要求。车型 LORA 的打标标签,有独立的要求:每一个图片的标签结果需要有一个与图片名称一致的 txt 文档。
在AI训练领域,尤其是LORA 图像等细分模型的训练,对高质量、结构化的图片标签数据有极高要求。
车型 LORA 的打标标签,有独立的要求:每一个图片的标签结果需要有一个与图片名称一致的 txt 文档。
前排提示,文末有大模型AGI-CSDN独家资料包哦!

传统的人工打标方式需要一张一张点开图片,人工打标后,独立保存 txt 文件。
不仅耗时耗力,还容易出错,难以满足大规模数据集的高效处理需求。
有没有一种方法,能让我们像搭积木一样,自动完成图片批量打标、标签txt文件自动生成,并且灵活适配国内主流大模型API?
这几天用 n8n(一个可视化自动化流程平台),结合国内大模型(如豆包图像理解API),实现了“批量读取本地图片→自动生成标签→标签文件自动写出”的全流程自动化。
整个流程无需写一行后端代码,极大降低了AI训练数据准备的门槛。

实现的效果是这样的。
准备好需要标注的图片文件:
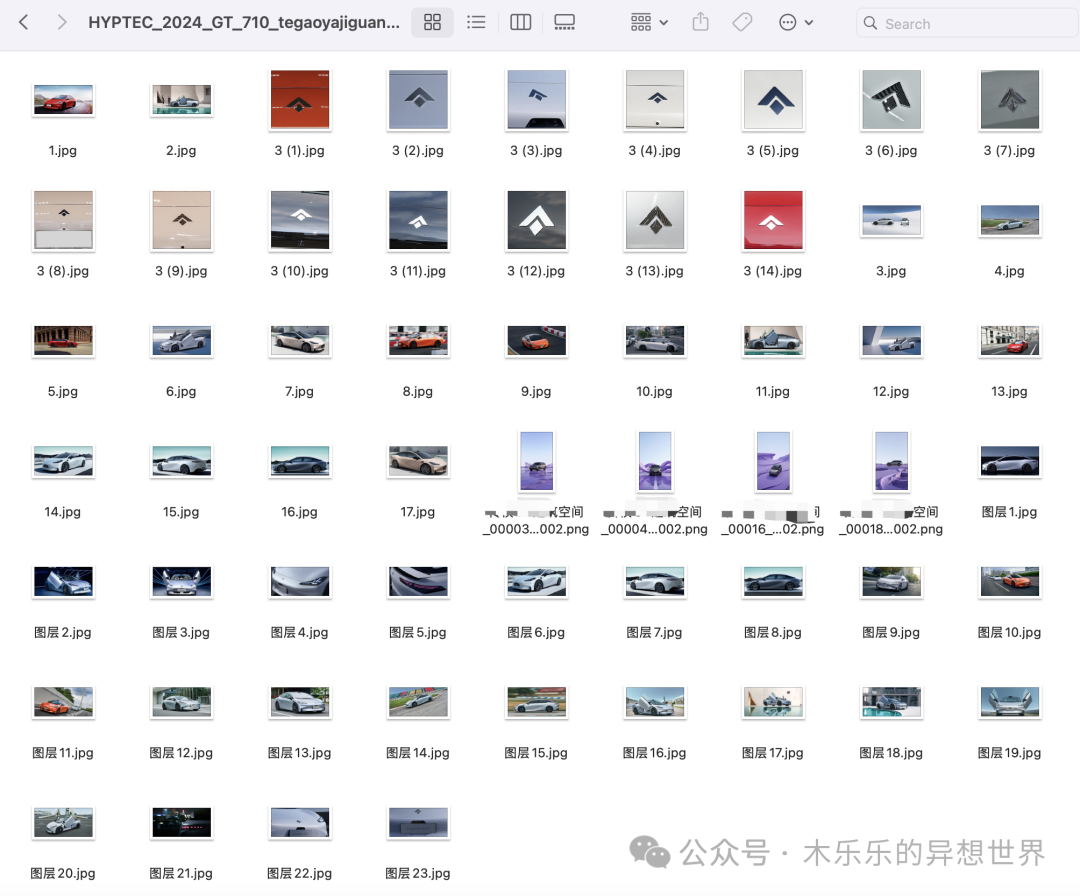
另外,图片提示词文件:
每一次任务启动的时候,配置启动词和豆包图像识别 ApiKey。
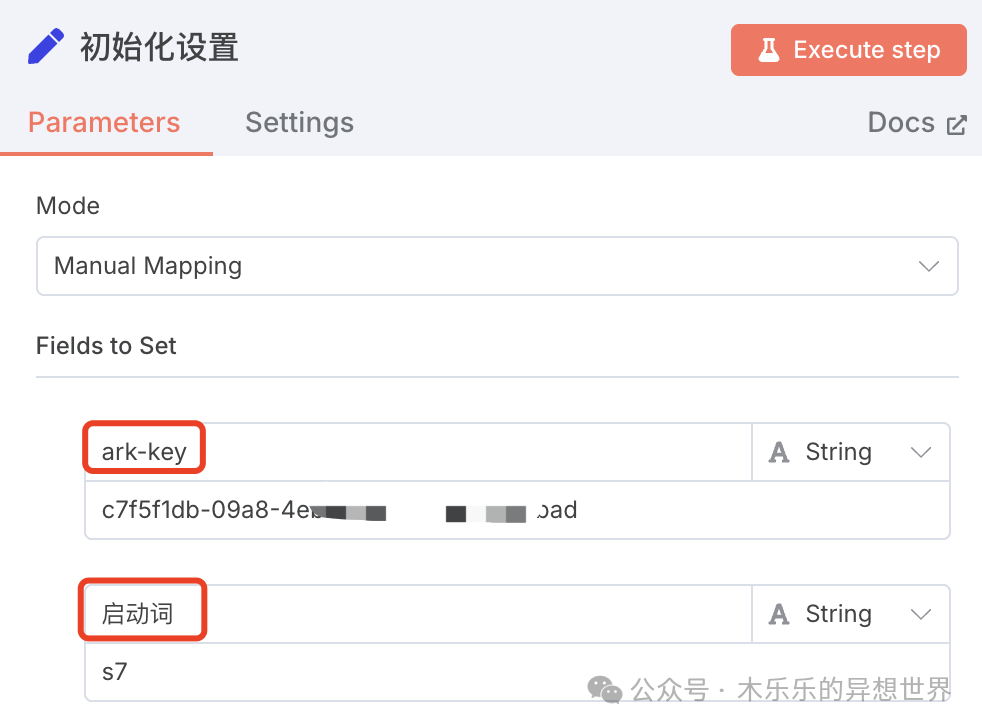
点击运行,就可以得到这样的批量打标结果:

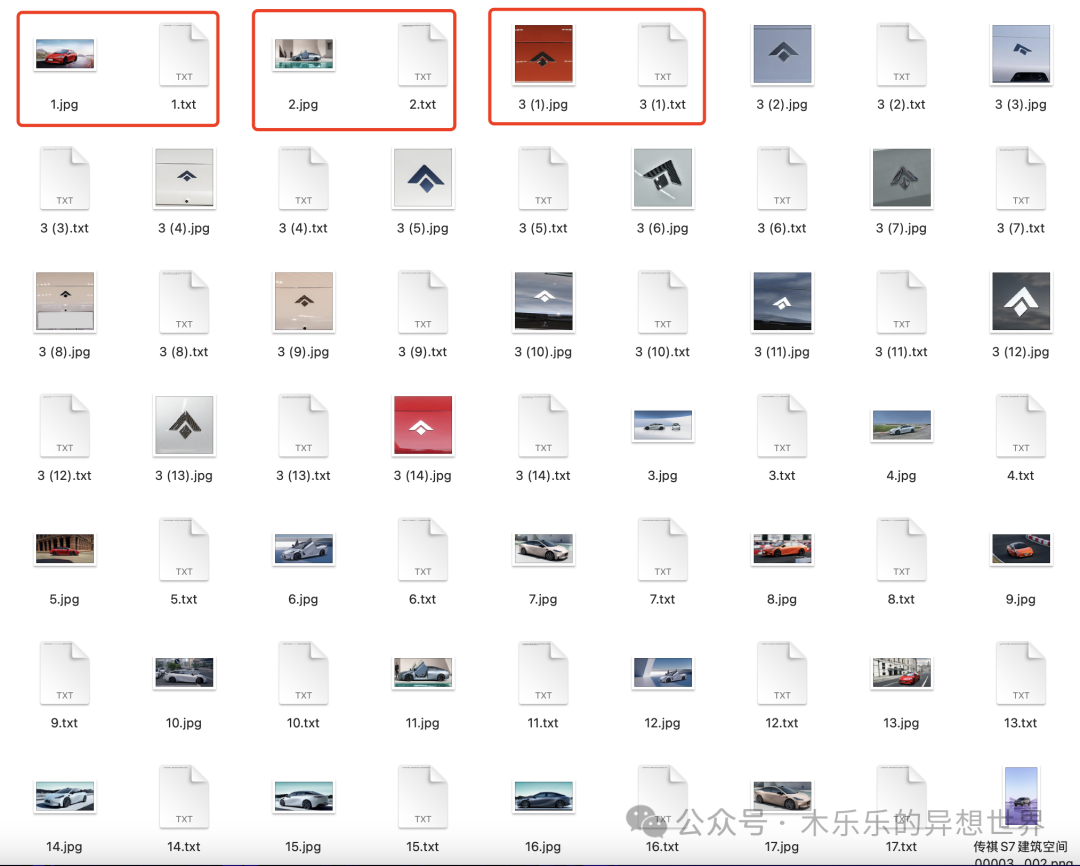
工作流中的难点与亮点逐一说明一下
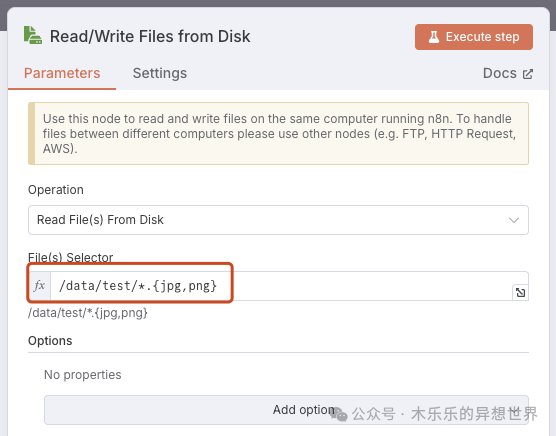
批量读取指定文件夹内图片,兼容 jpg 和 png 格式
实现方法:在 n8n 的Read/Write Files from Disk节点中,使用 /data/test/*.{jpg,png} 作为文件选择器,轻松实现对 jpg 和 png 两种主流图片格式的批量读取。优势:
- 支持多格式扩展,后续如需支持 gif、bmp,只需在花括号内添加即可。
- 适合大规模数据集的灵活处理
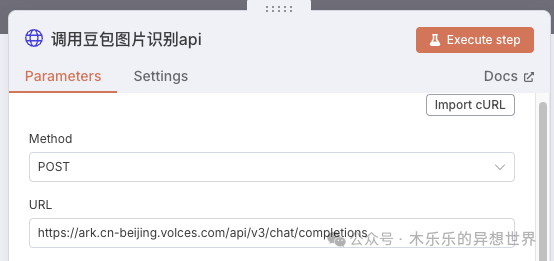
在 n8n 平台内调用国内大模型
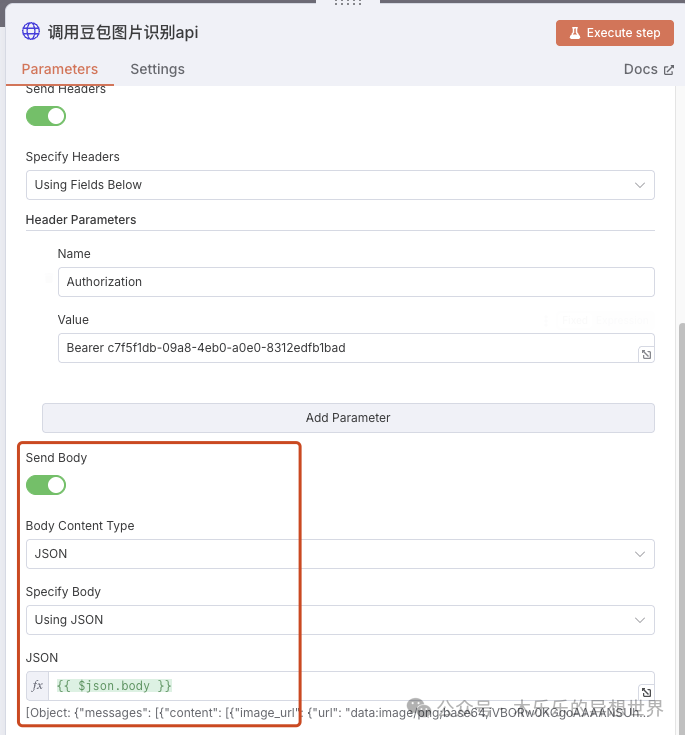
n8n平台唯一的缺陷大概就是对国内大模型的生态支持不足了吧。为了解决这个痛点,我们可以通过 n8n 的 HTTP Request 节点,配置 API 地址、Header(如 Authorization),即可无缝对接豆包等国内主流大模型。优势:
- 无需写代码,拖拽配置即可完成对接。
- 支持自定义 header,兼容各种 API 鉴权方式。
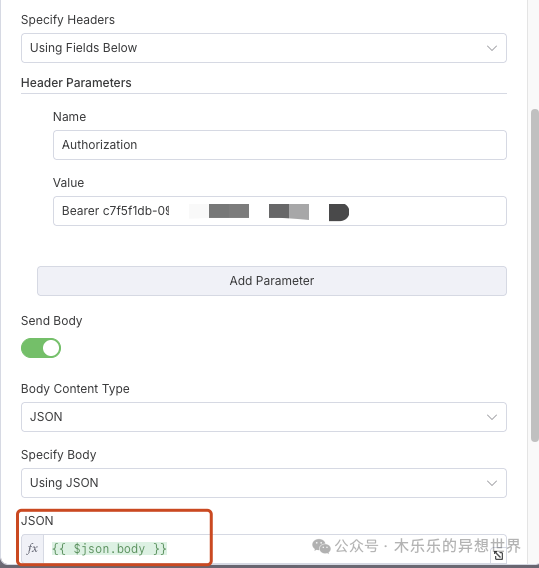
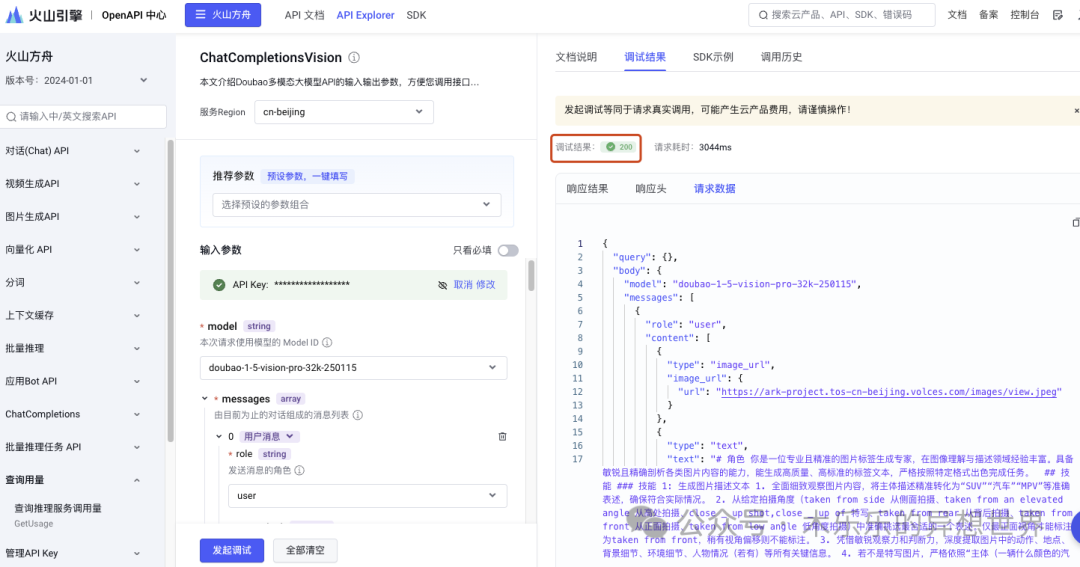
建议在 n8n 配置 http 请求之前,在火山引擎的 api 调试界面先确认配置参数。调通后再到 n8n 配置 http 请求。
本地图片转 base64,适配大模型 API
当前的图像识别模型,图像入参的方法有两种,一个是存储在云端的 url 地址,比如字节的示例:https://ark-project.tos-cn-beijing.volces.com/images/view.jpeg
另一种是 base64 数据格式。后者一般用于处理个人电脑或者服务器环境内的图像格式转换。
wpm需要处理的图片都是在服务器本地,利用 n8n 的“Extract from File”节点将图片转为 base64,再在 Code 节点中拼接成 data:image/<格式>;base64, 的标准格式,确保 API 能正确识别图片内容。
- 全自动转换,避免手动处理的繁琐和出错。
- 兼容所有主流图片格式,适配性强。
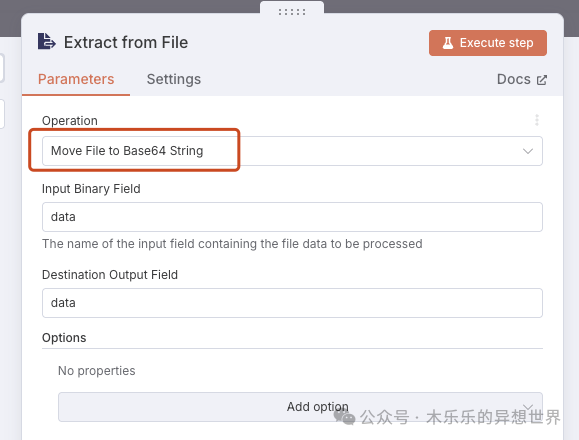
Extract from File节点配置
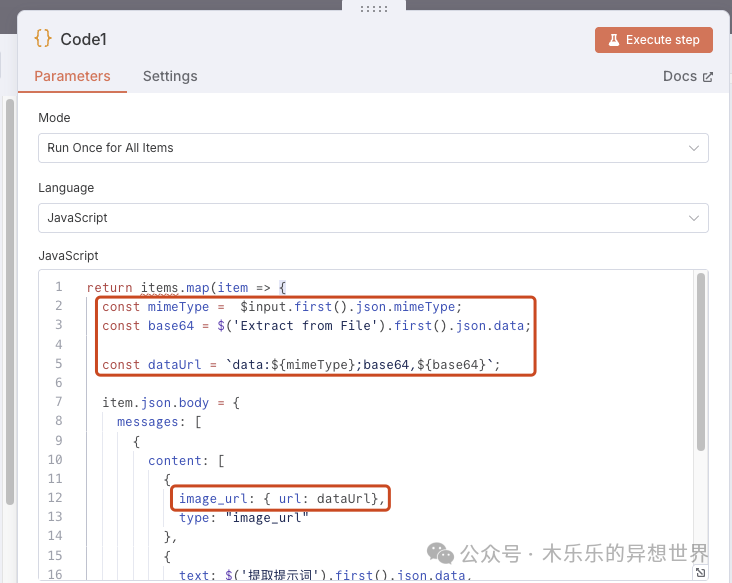
Code 转换节点配置
复杂 JSON 拼接报错用 code 节点解决
这个绝对是处理起来最烦躁的地方。
在 n8n 的 Code 节点中,手动组装复杂的 JSON 请求体经常会有 JSON 格式错误的报错。为了避免 HTTP Request 节点表达式插值带来的类型和格式问题。我们可以使用 n8n 自带的 Code 转换节点。
- 灵活应对各种嵌套结构的 API 请求。
- 保证请求体格式100%符合大模型 API 要求,避免报错。
return items.map(item => {
const mimeType = $input.first().json.mimeType;
const base64 = $('Extract from File').first().json.data;
const dataUrl = `data:${mimeType};base64,${base64}`;
item.json.body = {
messages: [
{
content: [
{
image_url: { url: dataUrl},
type: "image_url"
},
{
text: $('提取提示词').first().json.data,
type: "text"
}
],
role: "user"
}
],
model: "doubao-1-5-vision-pro-32k-250115"
};
return item;
});
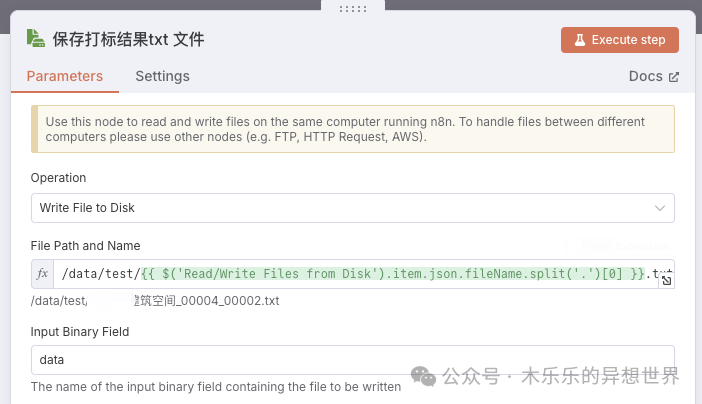
批量写出 txt 文件,文件名与图片前缀一致
图像标注训练集要求标签 txt 文件名和图像名称是需要一致的。这样在进行 Lora 模型训练的时候,训练器能够自动的把图像和标签做一一关联。
我们可以通过 n8n 的“保存打标结果txt 文件”节点,动态生成 txt 文件名,前缀与图片文件名一致,实现图片与标签一一对应。优势:
- 自动命名,避免人工对齐,提升数据集规范性。
- 方便后续模型训练和数据管理。
写在最后
这个自动工作作业中的图片和标签文件均在本地文件系统操作,数据不落地云端。保障了训练数据集的安全与本地化处理,特别适合对数据安全有要求的企业或科研场景。
n8n 的可视化界面让流程一目了然,便于团队成员理解、复用和二次开发,降低沟通和协作成本。
通过 n8n + 国内大模型 API 的组合,我们实现了车型 LORA 训练数据的全自动打标流水线。整个流程无需写后端代码,极大提升了数据准备效率和准确性。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 32
32 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)