大模型的常用加速推理方法
本文探讨了深度学习模型推理加速的多种技术策略。首先,并行化推理通过层间、层内和数据并行三种模式,将计算任务分配到多个处理单元,突破单线程性能瓶颈。其次,向量化推理利用SIMD指令集提高计算效率。循环分块通过优化缓存访问减少主存访问次数。算子融合将多个相邻算子合并,减少数据搬运和Kernel调用开销。量化推理通过降低数据精度减少内存占用和计算量。最后,文章强调多种加速方法的协同作用,如并行化与向量化
目录
1.并行化加速推理
并行化推理通过将计算任务拆解到多个处理单元(如 CPU 核心、GPU 线程、TPU 芯片等)同时执行,突破单线程处理的性能瓶颈。其核心思想是利用 "分而治之" 策略,将大模型的前向传播过程分解为层间并行、层内并行和数据并行三种主要模式:
1.1 层间并行
将神经网络的各层分配到不同计算设备,形成流水线作业。例如,第1层在设备A计算时,第2 层可在设备B预加载参数,实现层间计算重叠。设模型共L层,每层计算时间为tl,理想情况下流水线并行的总时间为:

1.2 层内并行
对单层内的矩阵运算进行拆分,如将矩阵乘法C=A×B(A∈Rm×k,B∈Rk×n)按行/列划分到多个线程。假设划分为P个线程,每个线程处理m/P×k和k×n的子矩阵,理论加速比可达P倍(忽略线程同步开销)。
1.3 数据并行
将输入数据批量(Batch)拆分到不同设备,各设备独立计算相同模型参数,最后聚合结果。设批量大小为N,拆分到D个设备,每个设备处理N/D样本,计算量从O(N⋅FLOPs)降至O((N/D)⋅FLOPs),理论加速比为D。
并行化的加速效果受阿姆达尔定律(Amdahl's Law)约束:
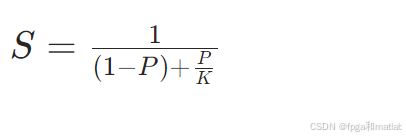
其中P为可并行化任务占比,K为并行处理单元数。例如,若模型90%的计算可并行(P=0.9),使用8块GPU(K=8),则理论加速比S≈5.71,而非理想的8倍。当批量大小过小时,通信开销可能抵消计算加速收益,因此存在最优批量阈值。
2.向量化推理
向量化利用CPU/GPU的SIMD指令集(如 x86 的 AVX、ARM 的 NEON、NVIDIA的CUDA SIMT),在单个时钟周期内对多个数据元素执行相同操作。例如,AVX-512指令可同时处理16个32位浮点数(FP32)或8个64位浮点数(FP64),使算术逻辑单元(ALU)的利用率从标量计算的20%-30%提升至80%以上。

其中load_vector为批量加载,×为向量乘法,reduce_vector为归约求和。假设n=64,AVX-512(w=16)仅需4次循环完成计算,较标量循环(64 次)减少94%的迭代次数。

3.循环分块
循环分块(Loop Tiling)通过将大循环拆解为小尺寸的子循环(块,Tile),使计算所需数据在缓存中停留更长时间,减少对主存的访问次数。其核心思想基于程序访问局部性原理:当处理一个数据块时,相邻数据大概率在缓存中(空间局部性),且近期访问的数据可能再次被访问(时间局部性)。

4.算子融合
算子融合(Operator Fusion)将神经网络中多个相邻算子合并为一个复合算子,避免中间结果写入显存/内存,减少计算设备(如GPU)的 Kernel 调用次数和数据搬运开销。例如,将 "卷积+批量归一化(BN)+ 激活函数(ReLU)" 融合为单个Kernel,省去两次数据读写(BN输出到 ReLU输入)。

设单个算子的计算时间为tc,Kernel调用时间为tk,数据搬运时间为tm。对于n个串行算子,原始总时间为:

5.量化推理
量化通过将模型参数和激活值从高精度浮点型(如 FP32)转换为低精度类型(如 INT8、FP16),减少内存占用和计算量。

6.方法协同与综合优化策略
实际应用中,多种加速方法需协同作用以实现最优性能:
并行化+向量化:在多GPU集群中,每个GPU利用SIMD指令加速层内计算,同时通过数据并行处理不同批量数据。
循环分块+算子融合:分块优化缓存访问,融合减少块间数据搬运,如将分块后的卷积与激活函数融合为单个 Kernel。
量化+并行化:低精度数据减少设备间通信量(如 INT8 梯度同步比 FP32 带宽需求降低 4 倍),提升数据并行效率。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 26
26 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)