小米秋招算法二面:GSPO和GRPO的区别?
一个长度为 500 的序列,其未经归一化的 importance ratio 几乎必然会比一个长度为 50 的序列的 ratio 数量级不同,这意味着,长序列和短序列的 importance ratio 根本不具有可比性。大家熟知的是 GRPO 结果监督中对奖励的硬估计(数学题对就是 1,错就是 0),但 GRPO 保持了对过程监督的兼容,逐 token 的奖励并没有被抛弃,毕竟在当时过程监督就是
是时候准备面试和实习了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。

从本质上来说,GSPO 是对结果奖励的精神的一种发扬光大——the unit of optimazation objective should match the unit of reward,一个全局奖励优化一个 sequence。
它太符合直觉,以至于让人不免疑惑起 GRPO 当时为什么会采用 token 级别的 ratio 进行优化?
当我们回顾 GRPO 诞生的 DeepSeekMath 一文,会发现其中带有非常浓重的过程监督的色彩,这非常具有迷惑性——DeepSeek 用了一个脱胎于过程监督的算法来进行结果监督,并取得了瞩目的效果。
Group Sequence Policy Optimization(GSPO,组序列策略优化)由千问团队提出, 应用于 Qwen3 系列模型,其核心思想返璞归真:奖励既然是给整个序列的,那么优化也应该在序列的层面上进行。
论文:Group Sequence Policy Optimization[HuggingFace]
https://huggingface.co/papers/2507.18071
01
Motivation
GSPO 的思想来源于强化学习实践中的观察,常见的强化学习过程可以用下面的伪代码概括:
for prompts in dataloader:
# Stage 1: response生成
batch = actor.generate_sequences(prompts)
# Stage 2: 训练数据准备
batch = critic.compute_values(batch)
batch = reference.compute_log_prob(batch)
batch = reward.compute_reward(batch)
batch = compute_advantages(batch)
# Stage 3: actor和critic训练
critic_metrics = critic.update_critic(batch)
actor_metrics = actor.update_actor(batch)
第一阶段:响应生成(Response Generation) 在这个阶段,当前的策略模型(actor)接收输入提示词(prompts),并生成相应的文本序列。
这些生成的序列将作为后续训练的基础数据,代表了模型在当前策略下的行为表现。
第二阶段:训练数据准备(Training Data Preparation) 这是强化学习的核心数据处理阶段。
包含四个关键步骤:
-
价值估计:critic 模型对生成的序列计算状态价值函数,预测每个状态的期望回报
-
参考概率计算:reference 模型(通常是原始的预训练模型)计算生成序列的对数概率,用于后续的 KL 散度约束,防止策略偏离过远
-
奖励计算:reward 模型根据预设的奖励函数对生成的序列进行评分,这通常反映了人类偏好或任务目标
-
优势函数计算:基于奖励和价值估计计算优势函数(advantages),用于指导策略梯度的更新方向
第三阶段:模型参数更新(Model Parameter Update) 利用准备好的训练数据。
分别更新两个核心组件:
-
Critic 更新:使用时序差分(TD)误差或其他价值函数学习方法优化 critic 网络,提高价值估计的准确性
-
Actor 更新:基于策略梯度方法(如 PPO)更新 actor 网络参数,利用优势函数引导策略朝着更高奖励的方向优化
为了提升采样效率,各个强化学习框架中通用的做法是将一个巨大 batch size 的 rollout 数据(第一阶段一次性完成大量推理)拆分成很多 mini-batch 来进行梯度更新。
由于梯度更新发生了多次,这个过程不可避免地形成了 off-policy learning(离线学习)——Response 来自旧的策略模型 θ_old 而非当前最新的模型 θ。

强化学习流程
为了弥补分布变化带来的差异,从 PPO 开始在损失函数中都使用了重要性采样(importance sampling)。
通过对真实分布(behavior distribution)π_beh 中的样本重新分配权重来估计函数 f 在目标分布 π_tar 下的期望(李宏毅老师的 off-policy 一节视频中有对下式的详细讲解):


那么,GRPO 为什么要使用这种逐 token 的重要性采样呢?原因是,向来如此。
自 RLHF 被引入 LLM 的训练中以来,使用的 PPO 算法及其变体,都将 LLM 输出一个 token 视为一个 action。
自 PPO 开始,重要性采样在 token 级别进行都是把 token 当作 action 的结果。
甚至于奖励 Reward 和优势 Advantage 的计算都要服从 action 的频率,变成一个 token 一个奖励/优势(将 Reward model 所天然具有的结果奖励通过反向遍历序列计算GAE的方式变成每个 token 的 A_t )。
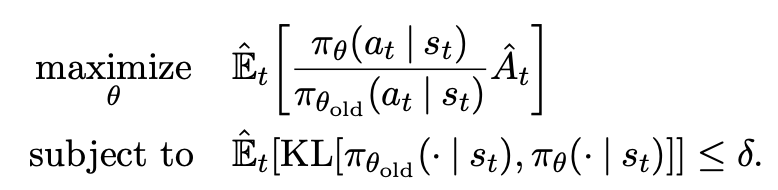
PPO 的优化目标
GRPO 的核心贡献是它取消了对 value model 的依赖,利用组内相对奖励计算优势。
它在结果监督的路径上迈进了一大步,以至于让人忽略了它本身是在一篇使用过程监督方法的论文中提出的:

DeepSeekMath 论文原文
大家熟知的是 GRPO 结果监督中对奖励的硬估计(数学题对就是 1,错就是 0),但 GRPO 保持了对过程监督的兼容,逐 token 的奖励并没有被抛弃,毕竟在当时过程监督就是大行其道。
到现在,结果监督已经被证明是简单且高效的, GSPO 才能反其道而行之——要用 action 去适配奖励,而不是用奖励去适配 action。
既然奖励是对于一个 sequence 产生的,那么 action 就应该被定义为一个 sequence,重要性采样也就要在 action/sequence 的维度进行。
02
算法细节
GSPO 与 GRPO 的差异仅仅是重要性采样的权重不同。
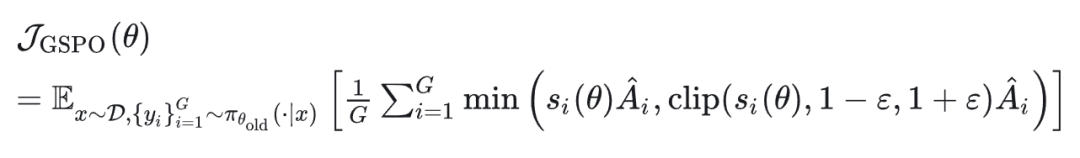
其中奖励沿用了 GRPO 中的基于组的优势估计:
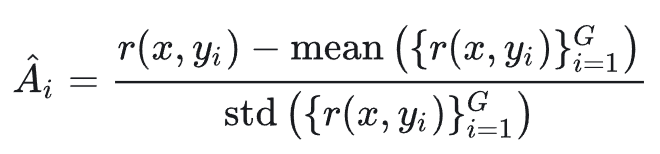
最重要的是重要性采样的比率 s_i(θ):
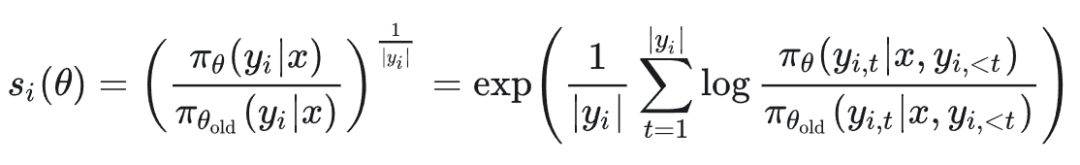
s_i(θ)使用长度归一化来减少方差并且控制数值范围不过高,我们来深入分析一下其背后的原因和合理性,主要可以归结为以下两点:
1. 解决序列似然的“累乘效应”,降低方差
在没有归一化的情况下,序列级别的重要性比例是:
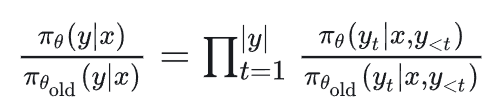
这是一个连乘积,这种“累乘效应”会带来两个严重问题,一是数值不稳定:数值会变得非常大或非常小,容易出现溢出问题。
二是方差极大:只要序列中有一个 token 的概率比 π_old 下的概率低很多,整个序列的 importance ratio 就会急剧下降。反之亦然。
这使得 importance ratio 对个别 token 的变化极其敏感,导致梯度估计的方差非常大,训练过程会剧烈波动,甚至崩溃。
GSPO 提出的归一化方法等价于对每个 token 的重要性比例 π_θ(yt|...)/π_old(yt|...) 取几何平均数。
取几何平均数(或者说,在对数域下取算术平均数)极大地平滑了这种累乘效应。
它将一个可能跨越多个数量级的、剧烈波动的乘积,转换为了一个在 1 附近波动的、更稳定的均值。这有效地降低了梯度估计的方差,是保证算法稳定训练的核心。
如论文 4.1 节所述:
Note that we adopt length normalization in si(θ) to reduce the variance and to control si(θ) within a unified numerical range. Otherwise, the likelihood changes of a few tokens can result in dramatic fluctuations of the sequence-level importance ratio…
2. 统一不同长度序列的比较基准
在强化学习训练中,模型生成的回复(response)长度 |y| 是可变的。一个回复可能只有 50 个 token,另一个可能有 500 个。
一个长度为 500 的序列,其未经归一化的 importance ratio 几乎必然会比一个长度为 50 的序列的 ratio 数量级不同,这意味着,长序列和短序列的 importance ratio 根本不具有可比性。
长度归一化通过 (·)^(1/|y|) 操作,无论序列长短,归一化后的 si(θ) 都被拉回到了一个相似的数值尺度上。
一个长度为 500 的序列,其归一化后的 ratio si(θ) 与一个长度为 50 的序列的 si(θ) 是可以直接比较的。这对于后续的裁剪(clipping)操作至关重要。
PPO 类的算法依赖于将 importance ratio 裁剪到一个 [1-ε, 1+ε] 的范围内,以防止策略更新过快。
有了归一化,所有序列的 si(θ) 都在一个可控的范围内,因此可以使用一个全局统一的裁剪范围 ε,这大大简化了算法设计和超参调整。
如论文 4.1 节所述:
…and the importance ratios of responses with different lengths will require varying clipping ranges.
梯度计算如下:
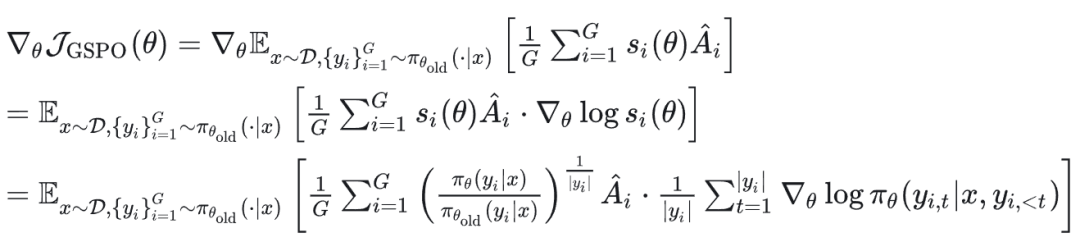
03
对比分析
将 GSPO 和 GRPO 总结对比如下图:

GSPO vs GRPO
另一个经常被拿来和这两种算法对比的是字节的 DAPO,之前读这篇论文的时候没写博客解读。
一是改动不大,二是觉得强化学习很多算法没法定量对比(与数据也有很大关系,有时候甚至觉得奖励方差大一点也没关系,只要均值较好就有效果)。
并不是说 DAPO 提出的方法不重要,clipping 对于低概率的 token 不友好,限制了模型的探索空间,这是非常重要的洞察。

GRPO vs DAPO vs GSPO
最近读了一篇定性分析强化学习的各种策略的论文,觉得很有收获值得一读,有意思的是这篇论文里把 GRPO 称为 sequence 级别的优化 。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)