C#实现文字转语音的完整实例详解
文本转语音(Text-to-Speech,TTS)技术是将书面文本自动转换为自然语音的技术,属于人工智能与语音合成领域的重要分支。其核心技术涵盖自然语言处理(NLP)、声学建模、语音波形生成等多个层面。在 Windows 系统中,通常预装了多个语音角色,例如 Microsoft David(男声)、Microsoft Zira(女声)等。除了系统内置语音角色,也可以通过安装第三方 TTS 引擎(如

简介:文本转语音(TTS)技术在无障碍阅读、智能助手等领域广泛应用。本文介绍如何使用C#语言,通过 System.SpeechSynthesis 命名空间中的 SpeechSynthesizer 类,实现文字转语音功能。内容包括初始化对象、设置语音属性(如语速、发音人)、合成并播放语音、保存为音频文件、事件处理等。实例代码经过验证,适合初学者掌握TTS基础应用与扩展开发技巧。 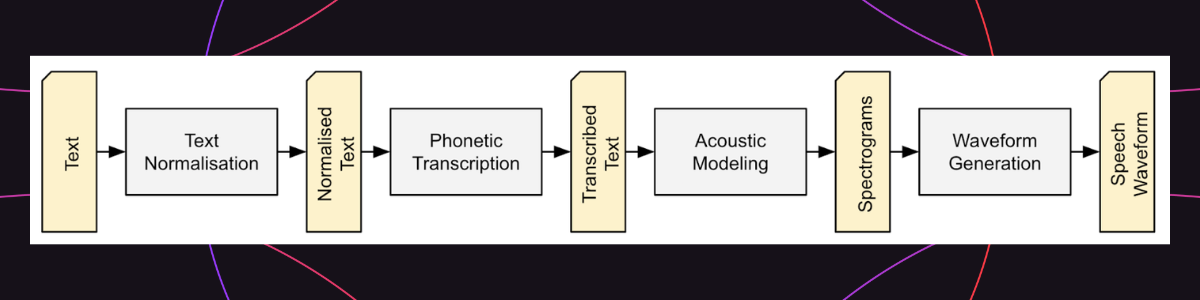
1. 文本转语音(TTS)技术概述
文本转语音(Text-to-Speech,TTS)技术是将书面文本自动转换为自然语音的技术,属于人工智能与语音合成领域的重要分支。其核心技术涵盖自然语言处理(NLP)、声学建模、语音波形生成等多个层面。
1.1 TTS的基本概念
TTS系统通过分析输入文本的语言结构,将其转化为语音信号输出。其核心流程包括文本归一化、分词、音素转换、韵律建模、声学建模与语音合成。输出语音的自然度、清晰度与情感表达能力是衡量TTS系统性能的重要指标。
1.2 TTS的发展历程
从早期的拼接式合成到基于统计模型的参数合成,再到当前基于深度学习的端到端模型(如Tacotron、WaveNet),TTS技术经历了多代演进,语音质量不断提升,逐步接近人类发音水平。
2. C#中TTS核心组件System.Speech.Synthesis
C#作为微软主导的面向对象编程语言,在Windows平台上对语音合成技术的支持尤为完善。通过其提供的 System.Speech.Synthesis 命名空间,开发者可以轻松实现文本转语音(TTS)功能,构建智能语音助手、无障碍阅读系统、语音播报模块等应用场景。本章将深入解析该命名空间的核心类、组件结构以及运行机制,帮助开发者掌握在C#中构建语音合成系统的基础能力。
2.1 System.Speech.Synthesis命名空间概览
System.Speech.Synthesis 是 .NET Framework 提供的用于实现文本转语音的核心命名空间。它封装了与 Windows TTS 引擎交互的接口和类,使开发者无需关心底层实现细节即可快速构建语音合成应用。
2.1.1 命名空间的主要功能模块
该命名空间主要包含以下几个核心功能模块:
| 模块名称 | 功能说明 |
|---|---|
| 语音引擎管理 | 提供语音引擎的枚举、选择与配置接口 |
| 语音合成控制 | 实现文本到语音的转换与播放控制 |
| 语音属性设置 | 支持设置语速、音调、发音人等语音参数 |
| 异步处理机制 | 支持异步合成与播放,避免阻塞主线程 |
| 事件驱动模型 | 提供合成完成、进度更新等事件通知机制 |
这些功能模块通过一系列类和接口进行封装,开发者只需调用相关API即可完成复杂的语音合成操作。
2.1.2 主要类和接口的职责划分
System.Speech.Synthesis 中的核心类如下:
- SpeechSynthesizer :主类,用于执行文本合成语音的操作。
- Prompt :表示语音合成的文本内容,支持普通文本和SSML格式。
- VoiceInfo :封装语音引擎的元信息,如语言、发音人名称等。
- PromptBuilder :用于构建复杂的语音合成内容,支持拼接、插入音效等操作。
- SpeechAudioFormatInfo :描述音频格式参数,如采样率、通道数等。
这些类之间的关系可以通过以下流程图进行说明:
classDiagram
class SpeechSynthesizer {
+SetOutputToDefaultAudioDevice()
+Speak(Prompt prompt)
+SelectVoice(string voiceName)
}
class Prompt {
+Prompt(string textToSpeak)
}
class VoiceInfo {
+Culture
+Gender
+Name
}
class PromptBuilder {
+AppendText(string text)
+AppendBreak(TimeSpan duration)
}
class SpeechAudioFormatInfo {
+EncodingFormat
+SampleRate
}
SpeechSynthesizer --> Prompt
SpeechSynthesizer --> VoiceInfo
Prompt --> PromptBuilder
SpeechSynthesizer --> SpeechAudioFormatInfo
通过上述类的协作,可以实现从文本输入到语音输出的完整流程。
2.2 SpeechSynthesizer类的功能与结构
SpeechSynthesizer 是 System.Speech.Synthesis 命名空间的核心类,它提供了语音合成的主要接口。该类负责与系统TTS引擎通信,控制语音合成的全过程。
2.2.1 核心属性与方法说明
核心属性
| 属性名 | 类型 | 描述 |
|---|---|---|
State |
SynthesizerState |
获取当前语音合成器的状态(就绪、忙碌、暂停等) |
Volume |
int |
设置或获取语音音量(0-100) |
Rate |
int |
设置或获取语速(-10 到 10) |
Voice |
VoiceInfo |
获取当前使用的语音角色信息 |
核心方法
| 方法名 | 描述 |
|---|---|
SetOutputToDefaultAudioDevice() |
将语音输出设置为默认音频设备 |
Speak(string text) |
同步播放指定文本 |
SpeakAsync(string text) |
异步播放指定文本 |
SelectVoice(string voiceName) |
选择指定名称的语音角色 |
GetInstalledVoices() |
获取系统中安装的所有语音角色 |
2.2.2 语音引擎的调用机制
SpeechSynthesizer 类内部通过调用 Windows 系统自带的 SAPI(Speech API)或基于 Windows TTS 引擎(如 Microsoft Zira、Microsoft David)实现语音合成。其调用流程如下:
sequenceDiagram
participant App as 应用程序
participant TTS as SpeechSynthesizer
participant Engine as TTS引擎
participant Audio as 音频设备
App->>TTS: 初始化SpeechSynthesizer
TTS->>Engine: 初始化语音引擎
App->>TTS: 调用Speak方法
TTS->>Engine: 发送文本数据
Engine->>TTS: 返回合成语音流
TTS->>Audio: 输出语音
开发者通过调用 Speak 或 SpeakAsync 方法,将文本发送给底层TTS引擎,引擎进行语音合成后,将音频流输出到指定设备。
2.3 TTS运行环境的配置要求
在使用 System.Speech.Synthesis 之前,必须确保运行环境满足一定的配置要求,包括系统版本、语音引擎安装情况等。
2.3.1 Windows系统下的语音引擎支持
Windows 系统内置了多个TTS引擎,如:
- Microsoft Anna (Windows 7)
- Microsoft David 和 Microsoft Zira (Windows 8/10)
- Microsoft Mark (部分语言版本)
可通过以下代码获取系统中安装的所有语音角色:
using System;
using System.Speech.Synthesis;
class Program
{
static void Main()
{
using (SpeechSynthesizer synth = new SpeechSynthesizer())
{
foreach (var voice in synth.GetInstalledVoices())
{
VoiceInfo info = voice.VoiceInfo;
Console.WriteLine($"名称: {info.Name}, 语言: {info.Culture}, 性别: {info.Gender}");
}
}
}
}
代码分析:
GetInstalledVoices()方法返回系统中所有已安装的语音角色。- 每个
InstalledVoice对象包含一个VoiceInfo属性,提供该语音角色的详细信息。 - 通过遍历输出,开发者可以了解当前系统支持的发音人及其语言信息。
2.3.2 第三方TTS引擎的兼容性设置
除了系统自带的TTS引擎外,开发者也可以使用第三方TTS引擎,如 CereVoice、NeoSpeech 等。要使用这些引擎,需确保它们已正确注册为 SAPI 兼容的语音引擎。
配置步骤:
- 安装第三方TTS引擎的运行库。
- 在注册表中检查
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices是否包含该引擎的信息。 - 在代码中通过
SelectVoice方法指定其名称。
示例代码:
synth.SelectVoice("CereVoice Emily");
如果引擎名称正确且注册无误,即可切换为该语音角色。
2.4 语音合成与其他语音技术的异同
语音合成技术是语音处理领域的重要组成部分,与语音识别(ASR)、语音增强等技术密切相关,但在功能和实现机制上有显著区别。
2.4.1 与语音识别(ASR)的关系
| 比较维度 | 语音合成(TTS) | 语音识别(ASR) |
|---|---|---|
| 输入 | 文本 | 音频信号 |
| 输出 | 音频信号 | 文本 |
| 技术目标 | 将文字转换为语音 | 将语音转换为文字 |
| 使用场景 | 语音播报、智能助手 | 语音输入、语音控制 |
两者常用于构建双向语音交互系统,例如语音助手。TTS 负责“说话”,ASR 负责“听懂”。
2.4.2 与语音增强技术的协同应用
语音增强技术旨在提升语音质量,例如去除背景噪音、提高语音清晰度。TTS 生成的语音有时也需要经过增强处理,以提升播放效果。例如:
- 在嘈杂环境中,使用语音增强算法对TTS输出进行后处理;
- 在语音播报系统中,结合语音合成与语音增强,提高可听性。
下图展示了语音合成与语音识别、语音增强的协同关系:
graph TD
A[文本] --> B[TTS]
B --> C[语音输出]
D[语音输入] --> E[ASR]
E --> F[文本输出]
C --> G[语音增强]
G --> H[优化语音输出]
F --> I[语义处理]
I --> J[语音合成反馈]
该流程展示了在一个完整的语音交互系统中,TTS、ASR、语音增强如何协同工作,实现高效的语音交互体验。
本章从命名空间结构、核心类功能、运行环境配置及技术协同等方面,系统性地讲解了 C# 中 System.Speech.Synthesis 的使用与原理,为后续章节中具体的语音合成实践打下坚实基础。
3. SpeechSynthesizer对象初始化
在使用C#进行文本转语音(TTS)开发时, SpeechSynthesizer 是核心类之一,负责语音合成的主要逻辑。初始化 SpeechSynthesizer 实例是整个TTS流程的第一步,它不仅影响后续语音合成的执行效率,还直接关系到资源管理与系统性能。本章将深入探讨如何正确初始化 SpeechSynthesizer 对象,包括对象创建、异常处理、语音引擎选择、资源管理及生命周期控制等关键环节。
3.1 初始化SpeechSynthesizer实例
3.1.1 创建对象的代码示例
创建 SpeechSynthesizer 实例是使用TTS功能的起点。其初始化方式简单直接,但背后涉及语音引擎的加载与系统资源的分配。
using System.Speech.Synthesis;
class Program
{
static void Main(string[] args)
{
SpeechSynthesizer synth = new SpeechSynthesizer();
// 可选:设置语音属性
synth.SelectVoice("Microsoft Anna");
// 合成语音
synth.Speak("欢迎使用C#的文本转语音功能!");
}
}
代码逐行分析:
using System.Speech.Synthesis;:引入命名空间,提供对TTS类的访问。SpeechSynthesizer synth = new SpeechSynthesizer();:创建SpeechSynthesizer的新实例。该实例会自动加载默认语音引擎。synth.SelectVoice("Microsoft Anna");:选择系统中已安装的语音角色。synth.Speak("...");:执行语音合成并播放。
注意:初始化时如果没有安装语音引擎,可能抛出异常。建议配合异常处理使用。
3.1.2 初始化过程中的异常处理
在实际开发中, SpeechSynthesizer 的初始化可能会因语音引擎缺失、权限问题或系统配置错误而失败。因此,在创建实例时应进行异常捕获。
try
{
SpeechSynthesizer synth = new SpeechSynthesizer();
}
catch (Exception ex)
{
Console.WriteLine("初始化失败:" + ex.Message);
}
常见异常类型:
| 异常类型 | 描述 |
|---|---|
PlatformNotSupportedException |
当前操作系统不支持TTS功能 |
InvalidOperationException |
语音引擎未正确注册或配置 |
SecurityException |
应用程序没有访问语音引擎的权限 |
异常处理建议:
- 在部署前检查目标系统是否安装了语音引擎(如 Microsoft Anna、Zira 等)。
- 使用日志记录机制记录异常信息,便于后期调试。
- 提供用户友好的错误提示,增强用户体验。
3.2 语音引擎的自动选择与手动指定
3.2.1 获取系统可用语音引擎列表
每个 SpeechSynthesizer 实例可以使用一个语音引擎进行语音合成。开发者可以通过以下方式获取当前系统中所有可用的语音引擎:
SpeechSynthesizer synth = new SpeechSynthesizer();
foreach (InstalledVoice voice in synth.GetInstalledVoices())
{
VoiceInfo info = voice.VoiceInfo;
Console.WriteLine($"名称: {info.Name}, 语言: {info.Culture}, 性别: {info.Gender}");
}
输出示例:
名称: Microsoft Anna, 语言: en-US, 性别: Female
名称: Microsoft Zira, 语言: en-US, 性别: Female
名称: Microsoft David, 语言: en-US, 性别: Male
参数说明:
GetInstalledVoices():返回当前系统中安装的所有语音角色。VoiceInfo:包含语音角色的详细信息,如名称、语言、性别等。
3.2.2 设置默认语音引擎的方法
开发者可以手动指定 SpeechSynthesizer 使用的语音引擎:
SpeechSynthesizer synth = new SpeechSynthesizer();
synth.SelectVoice("Microsoft Zira");
synth.Speak("这是由Microsoft Zira合成的语音。");
选择语音的策略:
- 按语言选择 :通过
Culture属性筛选语音角色。 - 按性别选择 :根据
Gender属性选择不同性别语音。 - 按语音名称选择 :直接通过
SelectVoice(string name)方法指定语音。
选择语音的流程图(mermaid):
graph TD
A[创建SpeechSynthesizer实例] --> B[获取已安装语音列表]
B --> C{是否满足选择条件?}
C -->|是| D[调用SelectVoice方法]
C -->|否| E[提示用户安装新语音]
D --> F[使用指定语音进行合成]
3.3 初始化过程中的资源管理
3.3.1 内存分配与释放机制
SpeechSynthesizer 是一个资源密集型对象,其内部会加载语音引擎、音频解码器等组件。因此,在初始化和使用过程中应特别注意资源管理。
内存占用分析:
- 语音引擎加载 :约占用 50MB ~ 200MB 内存。
- 音频缓存 :每段合成语音将占用一定内存,用于缓存音频流。
释放资源方式:
SpeechSynthesizer synth = new SpeechSynthesizer();
try
{
synth.Speak("你好,世界!");
}
finally
{
synth.Dispose(); // 显式释放资源
}
建议:
- 使用
using语句自动管理资源:
using (SpeechSynthesizer synth = new SpeechSynthesizer())
{
synth.Speak("你好,世界!");
}
- 避免频繁创建和销毁
SpeechSynthesizer实例,推荐复用。
3.3.2 多实例管理的最佳实践
在某些场景下(如并发语音合成),可能需要创建多个 SpeechSynthesizer 实例。此时应考虑以下几点:
多实例内存消耗对比表:
| 实例数量 | 占用内存(估算) |
|---|---|
| 1 | 100MB |
| 2 | 180MB |
| 3 | 250MB |
| 4 | 320MB |
最佳实践建议:
- 限制最大并发实例数 :避免系统资源耗尽。
- 使用线程池管理任务 :结合
Task或Thread实现异步语音合成。 - 共享语音配置 :多个实例可共享相同的语音选择、语速等参数,减少重复设置。
3.4 语音合成器的生命周期管理
3.4.1 对象的启动与关闭流程
SpeechSynthesizer 的生命周期管理包括初始化、使用和销毁三个阶段:
- 初始化阶段 :创建实例,加载语音引擎。
- 使用阶段 :执行
Speak()或SynthesizeTextToStream()方法。 - 销毁阶段 :调用
Dispose()方法释放资源。
生命周期流程图(mermaid):
graph LR
A[创建实例] --> B[加载语音引擎]
B --> C{是否调用Speak方法?}
C -->|是| D[执行语音合成]
C -->|否| E[等待用户调用]
D --> F[是否调用Dispose?]
F -->|是| G[释放资源并结束]
F -->|否| H[等待显式释放]
3.4.2 长时间运行时的资源回收策略
对于需要长时间运行的应用(如后台语音服务),资源回收策略尤为重要。
资源回收策略建议:
- 定期释放并重新初始化实例 :避免内存泄漏。
- 监听系统资源使用情况 :如内存、CPU 使用率,自动调整语音合成频率。
- 使用
WeakReference缓存语音配置 :减少重复加载语音引擎的开销。
示例代码(定时回收):
Timer timer = new Timer(3600000); // 每小时执行一次
timer.Elapsed += (sender, e) =>
{
synth.Dispose();
synth = new SpeechSynthesizer(); // 重新初始化
};
timer.Start();
性能优化建议:
- 使用
WeakReference管理语音对象,避免内存泄漏。 - 在语音合成空闲期释放实例,减少资源占用。
- 对于长时间运行的服务,考虑引入对象池管理机制。
通过本章的学习,我们深入了解了 SpeechSynthesizer 的初始化流程,包括对象创建、异常处理、语音引擎管理、资源控制及生命周期管理等关键内容。这些知识不仅为后续章节的语音合成操作打下基础,也为构建高效、稳定的TTS应用提供了保障。在下一章中,我们将进一步探讨如何设置语音的语速、音调与发音人等高级功能。
4. 设置语音语速、音调和发音人
在文本转语音(TTS)系统中,语音语速、音调和发音人是影响最终语音输出效果的关键参数。合理地配置这些参数不仅能提升用户体验,还能增强语音内容的情感表达力和场景适应性。本章将深入探讨如何在 C# 中使用 SpeechSynthesizer 对象对这些参数进行精确控制,包括语速的动态调整、音调变化的实现方法,以及发音人选择与多语言支持策略。
4.1 调整语音语速(Rate)
语音语速决定了语音播放的速度,通常用于适应不同用户群体的听力需求,例如儿童、老年人或外语学习者。
4.1.1 Rate参数的作用范围
在 SpeechSynthesizer 类中, Rate 属性用于设置语音合成的速度,其取值范围为 -10 到 10,默认值为 0。值越小语音越慢,值越大语音越快。
| 参数值 | 语速描述 |
|---|---|
| -10 | 极慢 |
| 0 | 默认正常速度 |
| 5 | 稍快 |
| 10 | 极快 |
注意:不同语音引擎对
Rate的响应可能略有差异,建议在实际部署前进行测试。
示例代码:设置语速
using System;
using System.Speech.Synthesis;
class Program
{
static void Main()
{
SpeechSynthesizer synth = new SpeechSynthesizer();
// 设置语速为+5
synth.Rate = 5;
// 合成语音
synth.Speak("这是一个语速较快的语音合成示例。");
synth.Dispose();
}
}
代码逻辑分析:
- 第5行:创建
SpeechSynthesizer实例; - 第8行:将语速设置为
5,即比正常语速快; - 第11行:调用
Speak方法合成并播放语音; - 第13行:释放资源,避免内存泄漏。
应用场景分析
- 教育领域 :教师可将语速设置为较低值,帮助学生理解;
- 播客制作 :提高语速以缩短音频时长;
- 无障碍应用 :根据用户听力能力动态调整语速。
4.1.2 动态调整语速的应用场景
在一些交互式应用中,如语音助手或导航系统,语速应能根据上下文动态调整。例如,导航语音在转弯前可适当加快,提醒用户注意。
示例:根据文本内容动态调整语速
synth.Speak("前方即将进入高速,注意车速。");
synth.Rate = 2; // 适当加快
synth.Speak("请在下一个出口驶出。");
参数说明:
synth.Rate = 2:将语速设置为比默认略快,适用于提醒类语句;- 多次调用
Speak方法时,语速设置会持续生效,直到重新设置。
4.2 设置语音音调(Pitch)
语音音调控制语音的高低,通常用于表达不同的情感或区分角色,例如让男性和女性角色的声音具有明显差异。
4.2.1 音调调节对语音情感表达的影响
虽然 SpeechSynthesizer 类本身没有直接提供设置音调的方法,但可以通过使用 语音标记语言(SSML) 来实现更精细的控制。
SSML 提供了 <prosody> 标签,可以控制音调(pitch)、语速(rate)和音量(volume)。以下是一个示例:
<prosody pitch="high">这是一段高音调的语音。</prosody>
注意:并非所有语音引擎都完全支持 SSML,需根据实际引擎测试。
示例代码:使用 SSML 设置音调
using System;
using System.Speech.Synthesis;
class Program
{
static void Main()
{
SpeechSynthesizer synth = new SpeechSynthesizer();
string ssml = "<speak><prosody pitch=\"high\">这是一段高音调的语音。</prosody></speak>";
synth.SpeakSsml(ssml);
synth.Dispose();
}
}
代码逻辑分析:
- 第8行:定义 SSML 字符串,使用
<prosody>标签设置音调为 high; - 第11行:调用
SpeakSsml方法进行语音合成; pitch可取值:high、medium、low或具体数值如10Hz。
4.2.2 音调调节的代码实现
若希望在代码中更灵活地控制音调,可结合字符串拼接动态生成 SSML 内容。
动态生成 SSML 示例
string GetPitchSSML(string text, string pitch)
{
return $"<speak><prosody pitch=\"{pitch}\">{text}</prosody></speak>";
}
// 使用
string highPitchText = GetPitchSSML("请注意前方车辆", "high");
synth.SpeakSsml(highPitchText);
参数说明:
text:需要合成的文本内容;pitch:音调值,建议使用字符串"high"、"medium"、"low";- 若语音引擎支持,也可以使用如
"150Hz"这样的频率值。
4.3 选择发音人(Voice)
发音人决定了语音输出的性别、年龄和语言风格,是 TTS 体验的重要组成部分。
4.3.1 系统内置语音角色介绍
在 Windows 系统中,通常预装了多个语音角色,例如 Microsoft David(男声)、Microsoft Zira(女声)等。
获取系统语音角色列表
using System;
using System.Speech.Synthesis;
class Program
{
static void Main()
{
SpeechSynthesizer synth = new SpeechSynthesizer();
Console.WriteLine("系统支持的语音角色:");
foreach (InstalledVoice voice in synth.GetInstalledVoices())
{
VoiceInfo info = voice.VoiceInfo;
Console.WriteLine($"Name: {info.Name}, Gender: {info.Gender}, Age: {info.Age}");
}
synth.Dispose();
}
}
输出示例:
系统支持的语音角色:
Name: Microsoft David, Gender: Male, Age: Adult
Name: Microsoft Zira, Gender: Female, Age: Adult
参数说明:
GetInstalledVoices():返回系统中所有可用的语音角色;VoiceInfo:包含语音角色的详细信息,如名称、性别、年龄、语言等。
4.3.2 自定义语音角色的加载方法
除了系统内置语音角色,也可以通过安装第三方 TTS 引擎(如 Nuance、Google Cloud TTS、Azure TTS)来扩展语音角色。
加载自定义语音角色(示例)
synth.SelectVoice("Microsoft Server Speech Text to Speech Voice (en-US, AriaNeural)");
注意:若目标语音角色不在系统列表中,调用该方法会抛出异常,建议先检查可用语音列表。
异常处理示例:
try
{
synth.SelectVoice("AriaNeural");
}
catch (Exception ex)
{
Console.WriteLine("语音角色加载失败:" + ex.Message);
}
4.4 多语言与方言支持配置
在国际化或地方化应用中,支持多语言和方言是提升用户体验的重要一环。
4.4.1 多语言识别与切换机制
SpeechSynthesizer 支持根据文本内容自动选择语言,但更推荐手动指定语音角色以确保准确性。
示例:多语言语音合成
synth.SelectVoice("Microsoft David"); // 英语
synth.Speak("Hello, how are you today?");
synth.SelectVoice("Microsoft Huihui"); // 中文
synth.Speak("你好,今天过得怎么样?");
代码逻辑分析:
- 第2行:选择英文语音角色;
- 第5行:选择中文语音角色;
- 每次调用
SelectVoice后,后续的语音合成将使用该角色。
4.4.2 方言语音库的加载与使用
部分语音引擎支持特定方言,例如粤语、四川话等。加载方言语音库通常需要额外安装语言包。
示例:使用粤语语音
synth.SelectVoice("Microsoft Cantonese");
synth.Speak("你好,我係小明。");
注意事项:
- 需确认目标系统中已安装对应的语音包;
- 可通过语音引擎管理界面查看是否支持方言;
- 若不支持,建议使用 SSML 的
lang属性指定语言:
<speak xml:lang="zh-yue">你好,我係小明。</speak>
总结
本章详细讲解了如何通过 C# 中的 SpeechSynthesizer 类设置语音的语速、音调和发音人,并探讨了多语言和方言支持的实现方法。这些参数的合理配置能够显著提升语音合成的自然度与表现力,适用于教育、导航、语音助手等多种场景。下一章将深入介绍语音合成的核心方法 Speak 和 SynthesizeTextToStream 的使用与优化策略。
5. 文本合成语音方法 Speak 与 SynthesizeTextToStream
在使用 C# 中的 System.Speech.Synthesis 命名空间进行文本转语音(TTS)开发时,最核心的两个方法是 Speak 和 SynthesizeTextToStream 。这两个方法分别用于直接播放合成语音和将语音结果以音频流的形式输出,适用于不同的应用场景。本章将深入探讨这两个方法的使用方式、控制机制、性能优化策略以及多段文本的合成逻辑,帮助开发者在不同需求下灵活使用。
5.1 Speak 方法的使用与控制
Speak 方法是 SpeechSynthesizer 类中最直接的语音合成方法,用于将文本内容立即转换为语音并播放。它支持同步与异步两种调用方式,并允许开发者通过代码控制播放流程。
5.1.1 同步与异步播放的区别
| 模式 | 特点 | 适用场景 |
|---|---|---|
同步播放( Speak ) |
阻塞当前线程,直到语音播放完毕 | 简单的播放需求,如提示音 |
异步播放( SpeakAsync ) |
不阻塞主线程,适合在 UI 线程中调用 | 用户界面交互、播放过程中允许其他操作 |
SpeechSynthesizer synth = new SpeechSynthesizer();
// 同步播放
synth.Speak("这是一段同步播放的语音内容。");
// 异步播放
synth.SpeakAsync("这是一段异步播放的语音内容。");
代码逻辑分析:
- 第1行:创建一个
SpeechSynthesizer实例。 - 第4行:调用
Speak方法,程序会等待语音播放结束后继续执行。 - 第7行:调用
SpeakAsync方法,语音播放在后台线程中进行,主线程继续执行后续代码。
参数说明:
- Speak 和 SpeakAsync 的参数均为 string 类型,表示要合成的文本内容。
- 可以通过重载方法传入 Prompt 或 PromptBuilder 对象,实现更复杂的语音合成结构。
5.1.2 播放控制(暂停、继续、停止)
SpeechSynthesizer 提供了以下方法用于控制异步播放流程:
Pause():暂停当前播放Resume():继续播放已暂停的语音CancelAll():停止所有正在播放或等待播放的内容
synth.SpeakAsync("开始播放语音内容。");
System.Threading.Thread.Sleep(2000); // 播放2秒后暂停
synth.Pause();
System.Threading.Thread.Sleep(1000); // 暂停1秒后继续
synth.Resume();
System.Threading.Thread.Sleep(3000); // 播放3秒后停止
synth.CancelAll();
代码逻辑分析:
- 第1行:启动异步播放。
- 第2行:使用
Sleep模拟播放2秒。 - 第3行:调用
Pause()暂停播放。 - 第5行:调用
Resume()恢复播放。 - 第7行:调用
CancelAll()停止所有语音播放。
控制流程流程图:
graph TD
A[调用 SpeakAsync] --> B[播放中]
B --> C{是否有暂停指令}
C -- 是 --> D[调用 Pause]
D --> E[暂停播放]
C -- 否 --> F[继续播放]
E --> G{是否有恢复指令}
G -- 是 --> F
F --> H{是否调用 CancelAll}
H -- 是 --> I[停止播放]
H -- 否 --> F
5.2 SynthesizeTextToStream 方法详解
当开发者希望将合成语音保存为音频流以供后续处理时,可以使用 SynthesizeTextToStream 方法。该方法将语音合成结果写入 Stream 对象,适用于音频文件生成、网络传输等场景。
5.2.1 流式语音生成的优势
| 优势 | 描述 |
|---|---|
| 实时性 | 可边合成边写入,无需等待整个文本处理完成 |
| 可扩展性 | 可将音频流写入文件、内存或网络传输 |
| 控制灵活 | 可结合音频编码格式进行自定义处理 |
SpeechSynthesizer synth = new SpeechSynthesizer();
MemoryStream audioStream = new MemoryStream();
synth.SetOutputToWaveStream(audioStream);
synth.Speak("这是一段流式语音合成的示例文本。");
audioStream.Position = 0; // 重置流位置以便读取
代码逻辑分析:
- 第1行:创建语音合成器实例。
- 第2行:创建一个内存流用于接收音频数据。
- 第4行:设置输出流为
audioStream,格式为.wav。 - 第5行:调用
Speak方法,此时语音数据被写入流中。 - 第6行:将流指针重置为起始位置,以便后续读取。
参数说明:
- SetOutputToWaveStream(Stream stream) :设置语音输出为波形音频流。
- SetOutputToAudioStream :可指定音频格式(如 PCM、MP3 等)。
5.2.2 音频流的格式与处理方式
SpeechSynthesizer 支持将语音合成结果输出为不同格式的音频流,开发者可以通过 AudioFormat 设置音频编码格式:
var format = new SpeechAudioFormatInfo(
44100, // 采样率
AudioBitsPerSample.Sixteen, // 位深度
AudioChannel.Mono // 声道
);
synth.SetOutputToWaveStream(audioStream, format);
代码逻辑分析:
SpeechAudioFormatInfo用于定义音频流的格式信息。- 通过
SetOutputToWaveStream将格式应用到输出流。
常见音频格式参数表:
| 参数 | 常用值 | 描述 |
|---|---|---|
| 采样率(SampleRate) | 8000, 11025, 22050, 44100 | 越高音质越好,占用资源越高 |
| 位深度(BitsPerSample) | 8, 16 | 表示每个采样点的精度 |
| 声道(Channels) | Mono, Stereo | 单声道/立体声 |
5.3 多段文本的语音合成策略
在实际应用中,开发者常常需要对多段文本进行语音合成。此时,如何处理段落之间的停顿、节奏、情感表达等问题,就变得尤为重要。
5.3.1 分段合成与连续播放
一种常见做法是将多个文本段落分别调用 SpeakAsync 方法,利用事件机制实现段落之间的自然过渡:
string[] texts = {
"第一段文本内容。",
"第二段文本内容。",
"第三段文本内容。"
};
foreach (var text in texts)
{
synth.SpeakAsync(text);
}
代码逻辑分析:
- 将多个文本段落依次调用
SpeakAsync,系统会自动排队播放。 - 可通过
SpeakCompleted事件监听每个段落播放完成,实现段落间逻辑处理。
播放流程流程图:
graph LR
A[开始播放] --> B[播放段落1]
B --> C[段落1播放完成]
C --> D[播放段落2]
D --> E[段落2播放完成]
E --> F[播放段落3]
F --> G[全部播放完成]
5.3.2 文本结构对语音节奏的影响
文本的结构(如标点、换行、句子长度)会直接影响语音合成的节奏与自然度。开发者可以通过 PromptBuilder 控制语速、停顿等细节:
PromptBuilder pb = new PromptBuilder();
pb.AppendText("这是一段");
pb.AppendBreak(TimeSpan.FromSeconds(0.5));
pb.AppendText("带有停顿的文本。");
synth.Speak(pb);
代码逻辑分析:
AppendText添加文本内容。AppendBreak插入指定时长的停顿,控制语音节奏。PromptBuilder提供了丰富的语音合成控制能力。
常见节奏控制方法:
| 方法 | 作用 |
|---|---|
AppendBreak |
插入语音停顿 |
StartStyle / EndStyle |
控制语速、音调等样式 |
AppendAudio |
插入外部音频文件 |
5.4 语音合成过程中的性能优化
语音合成过程可能会占用较多的 CPU 和内存资源,特别是在处理大量文本或多线程环境下。因此,性能优化成为开发者必须考虑的问题。
5.4.1 合成速度与资源消耗的平衡
可以通过以下方式优化语音合成性能:
- 限制并发数量 :避免多个
SpeakAsync同时执行,导致资源争用。 - 使用对象池管理实例 :复用
SpeechSynthesizer实例,减少创建销毁开销。 - 降低音频格式复杂度 :如使用较低采样率、单声道音频等。
// 限制最多同时播放2个语音任务
private int activeTasks = 0;
private const int maxTasks = 2;
public void SafeSpeak(string text)
{
if (activeTasks < maxTasks)
{
synth.SpeakAsync(text);
activeTasks++;
}
else
{
Console.WriteLine("任务过多,已暂停新增语音合成");
}
}
代码逻辑分析:
- 通过计数器控制并发任务数,防止资源过载。
- 适用于多用户、多线程语音合成场景。
5.4.2 多线程合成的应用技巧
在多线程环境中,建议使用 Task 或 BackgroundWorker 来管理语音合成任务,避免阻塞 UI 线程。
Task.Run(() =>
{
SpeechSynthesizer synth = new SpeechSynthesizer();
synth.Speak("这是在后台线程中播放的语音内容");
synth.Dispose();
});
代码逻辑分析:
- 使用
Task.Run在后台线程中执行语音合成。 - 合成完成后释放资源,避免内存泄漏。
多线程合成流程图:
graph TD
A[主程序启动] --> B[创建 Task]
B --> C[启动新线程]
C --> D[创建 SpeechSynthesizer 实例]
D --> E[调用 Speak]
E --> F[播放完成后释放资源]
F --> G[线程结束]
通过本章的深入讲解,我们系统地分析了 Speak 和 SynthesizeTextToStream 两个核心方法的使用方式、控制机制、多段文本处理策略以及性能优化技巧。下一章将围绕如何将语音输出保存为 WAV 音频文件展开,进一步拓展语音合成的落地应用。
6. 将语音输出保存为WAV音频文件
语音合成技术不仅限于实时播放,其输出结果往往需要以音频文件的形式进行保存,以便后续的播放、传输、归档或编辑。WAV(Waveform Audio File Format)作为无损音频格式,广泛用于语音合成系统中,尤其在需要高质量音频输出的场景下具有不可替代的优势。本章将深入探讨如何将语音合成结果保存为WAV格式的音频文件,并从格式选择、文件写入、权限管理、后续处理等多个维度进行详细分析。
6.1 音频文件格式的选择与比较
在语音合成输出中,选择合适的音频格式是确保音频质量与存储效率平衡的关键。WAV、MP3、OGG、AAC等格式各有优劣,开发者需根据具体应用场景进行选择。
6.1.1 WAV与MP3格式的优缺点
| 格式 | 类型 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|
| WAV | 无损 | 音质高、兼容性强、处理简单 | 文件体积大 | 语音识别、语音合成、录音 |
| MP3 | 有损 | 压缩率高、便于网络传输 | 音质损失、处理复杂 | 流媒体、音频下载、语音播放 |
| OGG | 有损 | 开源免费、压缩率高 | 兼容性略差 | 游戏音效、网页音频 |
| AAC | 有损 | 高压缩比、音质较好 | 专利限制、处理成本高 | 移动端音频、视频音频 |
选择建议:
- 对于语音合成输出要求高质量且需后续处理(如语音识别、声纹分析)的场景,优先选择WAV格式。
- 若用于网络传输或移动端播放,可考虑压缩后的MP3或AAC格式。
6.1.2 其他主流音频格式的支持情况
在C#中, System.Speech.Synthesis 默认支持将合成语音输出为WAV格式,若需导出为其他格式(如MP3),通常需要借助第三方音频处理库(如NAudio、Lame)进行编码转换。
📌 提示:System.Speech.Synthesis本身不支持直接导出MP3格式,但可以通过将合成音频写入WAV流,再使用编码器将其转换为MP3。
6.2 将语音流写入WAV文件
在C#中,使用 SpeechSynthesizer 对象的 SynthesizeToFile() 方法或结合 SynthesizeTextToStream() 方法可以将文本合成的语音保存为WAV文件。下面将从文件流的创建、写入方式、编码参数设置等方面进行详细介绍。
6.2.1 文件流的创建与写入方式
using System;
using System.IO;
using System.Speech.Synthesis;
class Program
{
static void Main()
{
SpeechSynthesizer synth = new SpeechSynthesizer();
string text = "Hello, this is a sample speech synthesis output.";
string filePath = @"C:\output\sample.wav";
// 使用SynthesizeToFile直接写入文件
synth.Speak(text);
synth.SetOutputToWaveFile(filePath);
synth.Speak(text);
synth.SetOutputToNull(); // 重置输出
Console.WriteLine("Audio saved to: " + filePath);
}
}
代码逻辑分析:
SpeechSynthesizer初始化后,通过SetOutputToWaveFile()方法将输出重定向到指定的WAV文件路径。- 调用
Speak()方法将文本合成语音并写入文件。 - 最后调用
SetOutputToNull()以释放资源,避免后续语音输出继续写入该文件。 - 此方法适用于直接保存为WAV格式,无需额外处理音频流。
6.2.2 音频编码参数的设定
若需控制音频的采样率、位深、声道数等参数,可以通过自定义音频格式进行设定。以下示例展示如何通过 SpeechAudioFormatInfo 类来设置音频编码参数:
SpeechAudioFormatInfo format = new SpeechAudioFormatInfo(
44100, // 采样率 44.1kHz
AudioBitsPerSample.Sixteen, // 16位深度
AudioChannel.Mono // 单声道
);
synth.SetAudioFormat(format);
参数说明:
| 参数 | 说明 |
|---|---|
| 采样率 | 每秒采样次数,44.1kHz为CD级标准,语音合成通常使用16kHz~44.1kHz |
| 位深 | 每个采样点的比特数,16位为常见选择,支持更高的动态范围 |
| 声道数 | 单声道(Mono)节省空间,立体声(Stereo)音效更丰富 |
⚠️ 注意:音频格式的设置必须在调用
SetOutputToWaveFile()之前完成,否则可能引发异常。
6.3 保存音频文件的路径与权限管理
在实际应用中,音频文件的保存路径不仅涉及用户自定义选择,还牵涉到系统权限管理问题。特别是在Windows系统中,应用程序访问文件系统时可能受到UAC(用户账户控制)和权限策略的限制。
6.3.1 目录访问权限配置
在Windows环境下,应用程序默认运行在受限权限下。若需访问受保护目录(如Program Files、系统目录),必须以管理员身份运行程序。
权限管理建议:
- 将音频文件默认保存至用户目录(如
Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments))。 - 对于需要保存至系统目录的应用,应提供“以管理员身份运行”选项。
- 使用
FileIOPermission类检查当前应用程序是否有权限访问指定路径。
try
{
using (FileStream fs = new FileStream(filePath, FileMode.Create))
{
// 写入数据
}
}
catch (UnauthorizedAccessException ex)
{
Console.WriteLine("Access denied: " + ex.Message);
}
6.3.2 用户自定义保存路径的实现
为了提升用户体验,允许用户通过对话框选择保存路径是一种常见做法。以下代码展示如何使用 SaveFileDialog 实现路径选择:
using System.Windows.Forms;
SaveFileDialog dialog = new SaveFileDialog();
dialog.Filter = "WAV files (*.wav)|*.wav";
dialog.Title = "Save the synthesized audio as WAV";
if (dialog.ShowDialog() == DialogResult.OK)
{
string selectedPath = dialog.FileName;
synth.SetOutputToWaveFile(selectedPath);
synth.Speak("This is your custom saved audio.");
synth.SetOutputToNull();
}
流程图示意(mermaid):
graph TD
A[用户点击保存按钮] --> B[弹出保存对话框]
B --> C{用户选择路径并确认}
C -->|是| D[获取文件路径]
D --> E[设置音频输出路径]
E --> F[合成语音并写入文件]
F --> G[完成保存]
C -->|否| H[取消操作]
6.4 音频文件的后续处理与分发
生成的WAV音频文件通常需要进行压缩、格式转换、上传或分发,以适应不同的使用场景。本节将介绍常见的后续处理方式及其实现方法。
6.4.1 文件压缩与格式转换
虽然WAV文件音质高,但其体积较大,不利于存储与传输。因此,压缩或转换为MP3格式是一个常见需求。
使用NAudio库进行WAV转MP3:
using NAudio.Wave;
using NAudio.Lame;
public static void ConvertWavToMp3(string wavPath, string mp3Path)
{
using (var reader = new AudioFileReader(wavPath))
using (var writer = new LameMP3FileWriter(mp3Path, reader.WaveFormat, LAMEPreset.STANDARD))
{
reader.CopyTo(writer);
}
}
参数说明:
AudioFileReader:读取WAV文件的音频数据。LameMP3FileWriter:使用LAME编码器将音频数据写入MP3文件。LAMEPreset:定义编码质量,如STANDARD、VBR_128等。
⚠️ 提示:使用NAudio需引入NuGet包
NAudio和NAudio.Lame,并确保项目为x86或x64平台编译。
6.4.2 音频上传与网络传输方案
若需将音频文件上传至服务器或云平台,可使用HTTP客户端或云服务SDK进行实现。
示例:使用HttpClient上传WAV文件
using System.Net.Http;
using System.IO;
public async Task UploadAudioFile(string filePath, string uploadUrl)
{
using (var client = new HttpClient())
using (var content = new MultipartFormDataContent())
{
var fileStream = new FileStream(filePath, FileMode.Open);
var streamContent = new StreamContent(fileStream);
content.Add(streamContent, "file", Path.GetFileName(filePath));
var response = await client.PostAsync(uploadUrl, content);
var result = await response.Content.ReadAsStringAsync();
Console.WriteLine("Upload response: " + result);
}
}
传输方案建议:
- 本地局域网传输 :使用SMB、FTP等协议。
- 互联网上传 :采用HTTPS + REST API方式,结合OAuth认证。
- 云服务集成 :如Azure Blob Storage、AWS S3、阿里云OSS等,提供SDK支持。
通过本章内容,我们深入解析了如何将语音合成输出保存为WAV文件,涵盖了音频格式选择、写入流程、编码参数设置、权限管理以及后续处理与分发等多个方面。这些内容不仅适用于C#开发者,也为语音合成系统的实际部署和优化提供了全面的技术支撑。
7. 语音合成完成事件处理(SpeakCompleted)
在使用 C# 的 System.Speech.Synthesis 进行语音合成时,处理语音合成完成的事件是非常关键的一环。通过事件驱动的方式,开发者可以在语音合成完成后执行特定的逻辑操作,例如更新用户界面、释放资源、进行后续处理等。本章将深入讲解 SpeakCompleted 事件的注册、触发机制、界面反馈处理、并发控制及错误处理策略。
7.1 SpeakCompleted事件的注册与触发
7.1.1 事件监听机制的实现方式
SpeakCompleted 是 SpeechSynthesizer 类提供的一个事件,用于在异步语音合成完成时通知应用程序。要使用该事件,开发者需要先注册一个事件处理方法。
示例代码如下:
using System;
using System.Speech.Synthesis;
class Program
{
static void Main(string[] args)
{
SpeechSynthesizer synth = new SpeechSynthesizer();
// 注册事件
synth.SpeakCompleted += new EventHandler<SpeakCompletedEventArgs>(Synth_SpeakCompleted);
// 异步播放语音
synth.SpeakAsync("Hello, welcome to the world of text to speech!");
Console.WriteLine("Speech is being synthesized...");
Console.ReadLine(); // 防止程序提前退出
}
static void Synth_SpeakCompleted(object sender, SpeakCompletedEventArgs e)
{
Console.WriteLine("Speech synthesis completed.");
}
}
⚠️ 注意:使用
SpeakAsync方法进行异步语音合成时,SpeakCompleted事件会在语音播放完成后自动触发。
7.1.2 事件参数的结构与用途
SpeakCompletedEventArgs 是 SpeakCompleted 事件的参数类型,它继承自 AsyncCompletedEventArgs ,其中包含以下常用属性:
| 属性名 | 类型 | 说明 |
|---|---|---|
| UserState | object | 用户定义的状态对象,用于识别不同任务 |
| Cancelled | bool | 指示任务是否被取消 |
| Error | Exception | 指示合成过程中是否发生错误 |
这些属性可用于判断语音合成的状态,并据此做出响应。例如:
static void Synth_SpeakCompleted(object sender, SpeakCompletedEventArgs e)
{
if (e.Cancelled)
{
Console.WriteLine("Speech was cancelled.");
}
else if (e.Error != null)
{
Console.WriteLine("An error occurred: " + e.Error.Message);
}
else
{
Console.WriteLine("Speech synthesis completed successfully.");
}
}
7.2 事件驱动下的用户界面反馈
7.2.1 合成完成后的界面更新
在 WinForms 或 WPF 应用中, SpeakCompleted 事件通常用于更新 UI,例如启用按钮、隐藏进度条、显示完成提示等。
以下是在 WPF 中更新界面的示例:
private void Synth_SpeakCompleted(object sender, SpeakCompletedEventArgs e)
{
Dispatcher.Invoke(() =>
{
progressBar.Visibility = Visibility.Collapsed;
statusLabel.Content = "语音合成完成";
playButton.IsEnabled = true;
});
}
📌 使用
Dispatcher.Invoke是为了确保在 UI 线程中更新控件,避免跨线程访问异常。
7.2.2 多状态反馈机制设计
在复杂的语音应用中,可能需要支持多个语音任务并发执行,并根据每个任务的状态进行反馈。可以通过 UserState 参数区分不同任务。
示例:
synth.SpeakAsync("First sentence", "task1");
synth.SpeakAsync("Second sentence", "task2");
static void Synth_SpeakCompleted(object sender, SpeakCompletedEventArgs e)
{
string taskId = e.UserState as string;
Console.WriteLine($"Task {taskId} completed.");
}
7.3 多任务并发时的事件管理
7.3.1 并发任务的事件隔离策略
当多个语音任务同时运行时,为避免事件处理逻辑混乱,应采用事件隔离策略。例如,可以为每个任务注册独立的事件处理器,或通过 UserState 区分任务来源。
void StartTask(string text, string taskId)
{
SpeechSynthesizer synth = new SpeechSynthesizer();
synth.SpeakCompleted += (s, e) =>
{
Console.WriteLine($"Task {taskId} completed.");
synth.Dispose(); // 合成完成后释放资源
};
synth.SpeakAsync(text, taskId);
}
7.3.2 多线程环境下的事件同步
在多线程环境下,语音合成任务可能由多个线程触发。为确保线程安全,建议使用线程安全的集合(如 ConcurrentDictionary )来管理合成器实例和任务状态。
ConcurrentDictionary<string, SpeechSynthesizer> synthesizers = new ConcurrentDictionary<string, SpeechSynthesizer>();
void StartTask(string text, string taskId)
{
var synth = new SpeechSynthesizer();
synthesizers.TryAdd(taskId, synth);
synth.SpeakCompleted += (s, e) =>
{
Console.WriteLine($"Task {taskId} completed.");
if (synthesizers.TryRemove(taskId, out var removedSynth))
{
removedSynth.Dispose();
}
};
synth.SpeakAsync(text, taskId);
}
7.4 语音合成过程中的错误处理机制
7.4.1 异常捕获与日志记录
在语音合成过程中,可能因资源不足、语音引擎异常等原因导致错误。应结合 try-catch 和事件参数中的 Error 属性进行统一异常处理。
synth.SpeakCompleted += (s, e) =>
{
if (e.Error != null)
{
File.WriteAllText("tts_error.log", $"Error at {DateTime.Now}: {e.Error.Message}");
Console.WriteLine("An error occurred during synthesis.");
}
};
7.4.2 合成失败的用户提示与重试机制
对于关键任务,可以在发生错误后提示用户并提供重试功能。
int retryCount = 0;
synth.SpeakCompleted += (s, e) =>
{
if (e.Error != null && retryCount < 3)
{
Console.WriteLine("Retrying synthesis...");
retryCount++;
synth.SpeakAsync("This is a retry message", "retryTask");
}
else if (e.Error != null)
{
Console.WriteLine("Maximum retry attempts reached.");
}
};
🧩 建议结合日志记录、用户提示、自动重试等功能,构建健壮的语音合成异常处理机制。
(本章完)
简介:文本转语音(TTS)技术在无障碍阅读、智能助手等领域广泛应用。本文介绍如何使用C#语言,通过 System.SpeechSynthesis 命名空间中的 SpeechSynthesizer 类,实现文字转语音功能。内容包括初始化对象、设置语音属性(如语速、发音人)、合成并播放语音、保存为音频文件、事件处理等。实例代码经过验证,适合初学者掌握TTS基础应用与扩展开发技巧。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)