VLA 论文精读(二十七)RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete
这篇论文是北大和北京智源研究院(不是上海智元机器人)共同发表的一篇具身大脑的 VLA 论文。智源研究院作为国内在 VLA 领域中科研实力强劲的一个机构,其发表的论文还是相当有技术水平和思想的,值得阅读。
这篇论文是北大和北京智源研究院(不是上海智元机器人)共同发表的一篇具身大脑的 VLA 论文。智源研究院作为国内在 VLA 领域中科研实力强劲的一个机构,其发表的论文还是相当有技术水平和思想的,值得阅读。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLA 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete
- 原文链接: https://arxiv.org/abs/2502.21257
- 发表时间:2025年03月25日
- 发表平台:arxiv
- 预印版本号:[v2] Tue, 25 Mar 2025 05:46:03 UTC (35,951 KB)
- 作者团队:Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, Xinda Xue, Qinghang Su, Huaihai Lyu, Xiaolong Zheng, Jiaming Liu, Zhongyuan Wang, Shanghang Zhang
- 院校机构:
- Peking University;
- Beijing Academy of Artificial Intelligence;
- Institute of Automation, Chinese Academy of Sciences;
- Institute of Information Engineering, Chinese Academy of Sciences;
- The University of Hong Kong;
- University of Chinese Academy of Sciences
- 项目链接: https://superrobobrain.github.io/
- GitHub仓库: https://github.com/FlagOpen/RoboBrain2.0
Abstract
多模态大型语言模型 (Multimodal Large Language ModelsM, LLM) 的最新进展已在各种多模态情境中展现出卓越的能力。然而在机器人场景中的应用,尤其是在长周期操控任务中,却暴露出显著的局限性。这些局限性源于当前的 MLLM 缺乏三项必不可少的机器人大脑能力:规划能力 Planning Capability,即将复杂的操控指令分解为可管理的子任务;可供性感知 Affordance Perception,即识别和解读交互对象可供性的能力;以及轨迹预测 Trajectory Prediction,即预测成功执行所需的完整操控轨迹的能力。为了增强机器人大脑的核心能力,使其从抽象到具体,作者引入了 ShareRobot 一个高质量的异构数据集,标注了任务规划、对象可供性、末端执行器轨迹等多维信息。ShareRobot 的多样性和准确性已由三位人工标注员手动检查。基于此数据集作者开发了 RoboBrain,一个多模态学习模型 (MLLM) 的模型,融合了机器人数据和通用多模态数据,采用多阶段训练策略,并结合长视频和高分辨率图像来提升其机器人操控能力。大量实验表明,RoboBrain 在各种机器人任务中均达到了最佳性能,彰显了其提升机器人大脑能力的潜力,项目网站:RoboBrain。
1. Introduction
多模态大型语言模型 (MLLM) 的最新进展显著推动了通用人工智能 (AGI) 的发展。通过利用来自互联网的海量多模态数据集并运用自监督学习技术,MLLM 在视觉感知和理解人类语言指令方面展现出卓越的能力,在视觉问答(visual question answering)、图像字幕生成(image captioning)、情感分析(sentiment analysis)等任务中表现出色。尽管 MLLM 取得了显著进展,但其在机器人领域的应用探索仍处于早期阶段,这凸显了其作为未来研究和创新的关键领域。
最近的研究探讨了 MLLM 在机器人技术中的应用,重点关注 规划和子目标分解(planning and subgoal decomposition)、动作排序(action sequencing)、重新规划和反馈(replanning and feedback)。然而在机器人场景中的有效性,尤其是在长视域操作任务(long-horizon manipulation tasks)中暴露出明显的局限性。这些局限性源于当前MLLM缺乏三项关键的机器人能力:规划、可供性感知、轨迹预测,如 Fig.1 所示。假设一个机械臂负责拿起茶壶并将水倒入杯中。MLLM 应该能够将此任务分解为多个子任务,例如 “approach the teapot and lift it”、“move the teapot until the spout is positioned over the cup”、“tilt the teapot to pour”。对于每个子任务,例如 “approach and grasp the teapot”,MLLM 必须利用可供性感知来准确识别茶壶的可抓取区域;轨迹预测对于确定从起点到茶壶可抓取部分的完整路径至关重要。现有 MLLM 面临的这一挑战主要源于缺乏专为机器人操作任务设计的大规模、细粒度数据集。

为了赋能 RoboBrain 从抽象指令理解到具体动作表达的核心能力,作者首先引入了 ShareRobot 数据集,一个专为机器人操作任务设计的大规模细粒度数据集。具体来说,作者标注了任务规划、物体可供性、末端执行器轨迹等多维信息。在 ShareRobot 的基础上,基于LLaVA 架构开发了RoboBrain,这是一个MLLM模型,旨在增强机器人在复杂任务中的感知和规划能力。在 RoboBrain 的训练过程中,精心设计了机器人数据与通用多模态数据的比例,实施了多阶段训练策略,并融合了长视频和高分辨率图像。这种方法赋予了 RoboBrain 强大的机器人场景视觉信息感知能力,支持历史帧记忆和高清图像输入,从而进一步提升了机器人操作规划的能力。大量实验结果表明,RoboBrain 在多个机器人基准测试中的表现均优于现有模型,包括 RoboVQA 和 OpenEQA 达到了 SOTA 水平。在轨迹和可供性预测准确率方面也表现出了竞争力。这些发现验证了所提出的数据集和框架在增强机器人大脑能力方面的有效性。总而言之,本文的主要贡献如下:
- 提出了 RoboBrain,一个专为机器人操作而设计的统一多模态大型语言模型,它通过将抽象指令转化为具体动作,从而更高效地执行任务;
- 精心设计了机器人数据与通用多模态数据的比例,实施了多阶段训练策略,并结合了长视频和高分辨率图像。这种方法为RoboBrain提供了历史帧记忆和高分辨率图像输入,从而进一步提升了其在机器人操作规划方面的能力;
- 引入了 ShareRobot,一个高质量的异构数据集,它标记了多维信息,包括任务规划、物体可供性和末端执行器轨迹,从而有效地增强了各种机器人功能;
- 全面的实验结果表明,RoboBrain 在各种机器人基准测试中均达到了最佳性能,凸显了其在机器人技术领域的实际应用潜力;
2. Related Work
MLLM for Robotic Manipulation Planning
现有研究大多利用多模态学习模型 (MLLM),主要侧重于理解自然语言和视觉观察任务,较少关注将高级任务指令分解为可操作步骤。PaLM E 通过将现实世界的观察结果映射到语言嵌入空间来生成多模态输入;RT-H 和 RoboMamba 则通过额外的策略头生成推理结果以及机器人动作。然而,虽然这些模型能够生成规划文本和动作,但它们仍然缺乏执行复杂原子任务的足够机制,这凸显了 增强可供性感知和轨迹预测的需求。
Datasets for Manipulation Planning
早期的操作数据集主要由带注释的图像和视频组成,重点介绍了基本的手部与物体的交互,包括抓取和推动。机器人操作领域的最新进展强调多模态和跨实体数据集,以增强泛化能力。诸如 RH20T、BridgeDataV2 和 DROID 等数据集增强了场景多样性,拓宽了操作场景的范围。此外,RT-X 将来自 22 个实体的 60 个数据集的数据汇编到 Open X-Embodiment (OXE) 存储库中。本研究 从 OXE 中提取高质量数据,将高级描述分解为低级规划指令,并将其改编为问答格式以增强模型训练。
3. ShareRobot Dataset
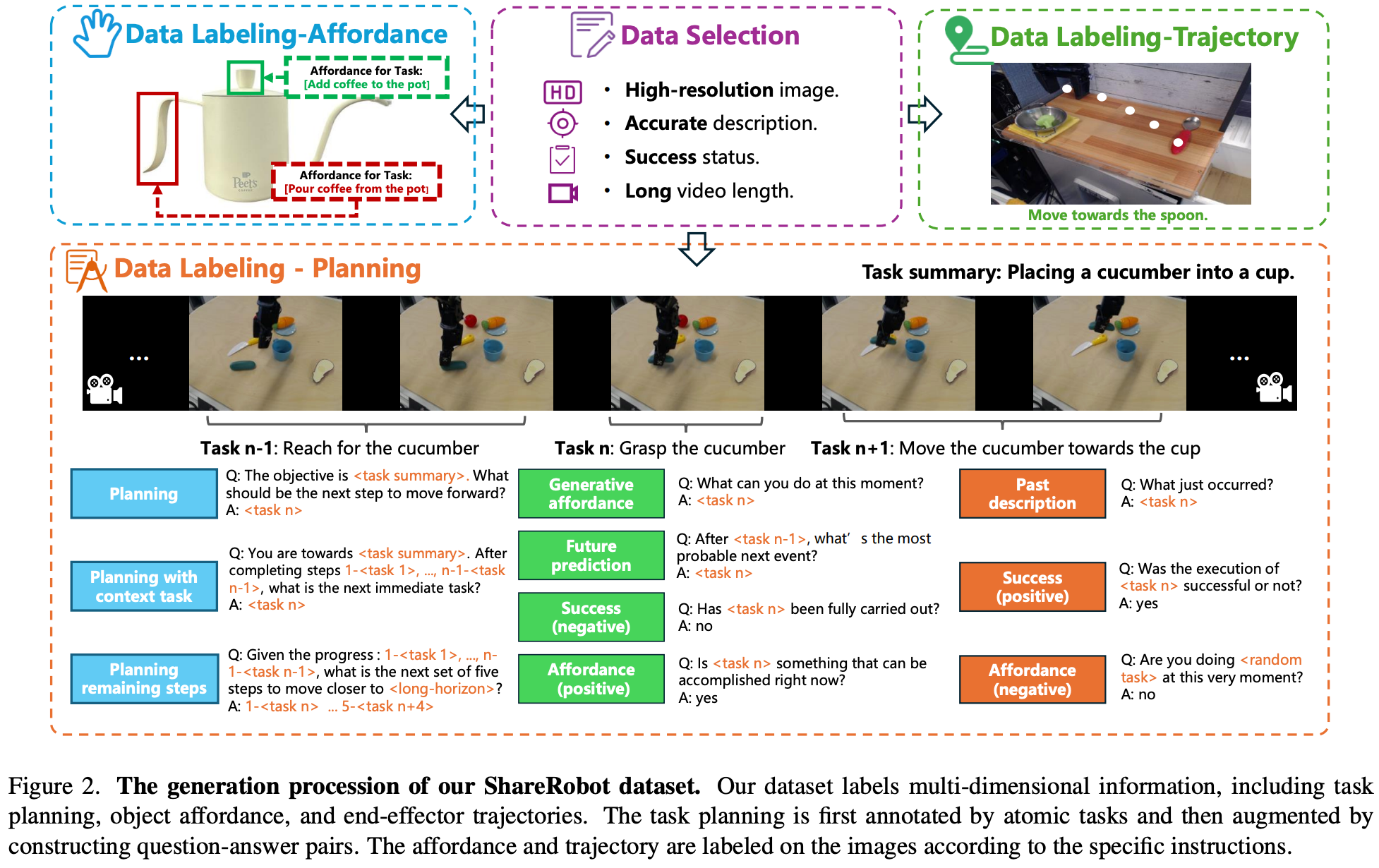
为了增强 RoboBrain 的规划、舞蹈感知和轨迹预测能力,作者开发了一个名为 ShareRobot 的数据集,一个专为机器人操控任务设计的大规模、细粒度数据集。数据集的生成流程如 Fig.2 所示。
3.1. Overview
ShareRobot 是一个全面的数据集,通过将抽象概念转化为具体操作,从而提高任务执行效率。ShareRobot 数据集的主要特点包括:
- Fine-grained:与提供广义高级任务描述的 Open X-Embodiment 数据集不同,ShareRobot 中的每个数据点都包含与各个帧相关的详细低级规划指令。这种特异性提高了模型在正确时刻执行任务的准确性;
- Multi-dimensional:为了增强 RoboBrain 的能力,使其从抽象到具体,我们标记了任务规划、物体可供性和末端执行器轨迹,从而提高任务处理的灵活性和精确度;
- High quality:制定了严格的标准,用于从 Open-X-Embodiment 数据集中筛选数据,重点关注高分辨率、精准描述、成功执行任务、可见的可供性和清晰的运动轨迹。基于这些标准验证了 51,403 个实例,以确保高质量,为 Robo Brain 的核心功能奠定基础;
- Large scale:ShareRobot 拥有 1,027,990 个问答对,是用于任务规划、可供性感知和轨迹预测的最大开源数据集,能够更深入地理解从抽象到具体的复杂关系;
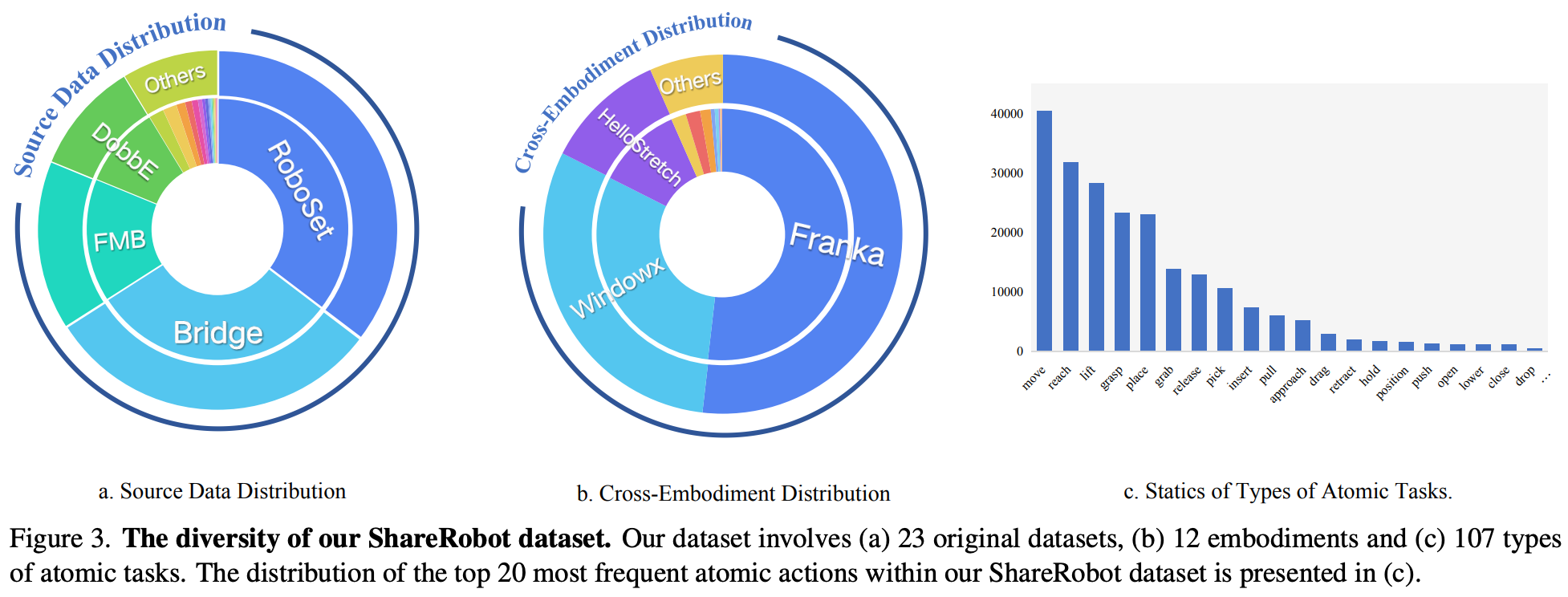
- Rich diversity:与 RoboVQA 数据集的有限场景相比,ShareRobot 具有 12 个实施例中的 102 个场景和 107 种原子任务,如
Fig.3所示。这种多样性使得 MLLM 能够从不同的现实世界环境中学习,从而增强其在复杂的多步骤规划中的鲁棒性; - Easy scalability:数据生成流程具有高可扩展性,能够随着新的机器人实例、任务类型和环境的发展而扩展。这种适应性确保 ShareRobot 数据集能够支持日益复杂的操作任务;
3.2. Data Selection
基于 Open X-embodiment 数据集,精心挑选了 51,403 个实例,主要关注图像质量、描述准确性和成功率。数据收集过程遵循以下原则:
- High-resolution image:剔除缺少图像或分辨率低的视频。分辨率低于 128 像素的视频都会被删除;
- Accurate description:没有描述或描述模糊的视频会被过滤掉,以免影响模型的规划能力;
- Success status:丢弃失败任务的视频,因为不成功的演示会阻碍模型的学习;
- Long video length:少于 30 帧的视频被排除在外,因为它们包含的原子任务有限;
- Object not covered:删除了目标物体或末端执行器被其他物体遮挡的视频,因为模型必须准确识别末端执行器的位置和物体的可供性;
- Clear Trajectories:排除了轨迹不清晰或不完整的演示,因为轨迹预测是 RoboBrain 的功能之一;
3.3. Data Labeling
Planning Labeling
从每个机器人操作演示中提取 30 帧,并利用 Gemini 将这些帧及其高级描述分解为低级规划指令;之后,三位注释员会审查并完善这些指令,以确保标注的准确性;随后,为 RoboVQA 中的 10 种问题类型分别设计了 5 个不同的模板。在数据生成过程中,随机选择每种问题类型的 2 个模板,为每个实例生成问答对。此过程将 51,403 个实例转换为 1,027,990 个问答对,注释员会监控数据生成过程以维护数据集的完整性。
Affordance Labeling
筛选了 6,522 张图像,并根据其高级描述,将每张图像的可供性区域标注为 { l ( x ) , l ( y ) , r ( x ) , r ( y ) } \{l^{(x)},l^{(y)},r^{(x)},r^{(y)}\} {l(x),l(y),r(x),r(y)},其中 { l ( x ) , l ( y ) } \{l^{(x)},l^{(y)}\} {l(x),l(y)} 是左上角的坐标、 { r ( x ) , r ( y ) } \{r^{(x)},r^{(y)}\} {r(x),r(y)} 是又下角的坐标。对每条指令进行严格的人工审核和改进,以确保其与相关的可供性区域精确对齐。
Trajectory Labeling
筛选了 6,870 张图像,并根据低级指令使用至少三个 { x , y } \{x,y\} {x,y} 坐标对每张图像的夹持器轨迹进行注释。对每条指令进行严格的人工审查和改进,以确保其与相关轨迹精确对齐。
3.4. Data Statistics
从 Open X 实例数据集中选择了 23 个原始数据集。源数据的分布如 Fig.3 所示。数据涉及 102 个不同的场景(例如卧室、实验室、厨房、办公室),涵盖 12 种不同的机器人本体。经统计,该数据集中有 132 种原子动作,词频较高的任务如Fig.3 (c)所示。最常见的 5 个原子任务是 “pick”、“move”、“reach”、“lift” 和 “place”,这些是实际机器人操作场景中常见的任务类型。这表明数据集分布合理。最终得到了 1,027,990 个用于规划的问答 (QA) 对。
- 规划 QA 对数据集:将 100 万个 QA 对拆分为训练集,将 2,050 个 QA 对拆分为测试集;
- 可供性数据集:将 6,000 张图片分成训练集,522 张图片分成测试集
- 轨迹数据集:将 6,000 张图片分成训练集,870 张图片分成测试集。
4. RoboBrain Model
本节将概述 RoboBrain,目标是使多模态大型语言模型 (MLLM) 能够理解抽象指令,并明确输出物体可供性区域和潜在的操作轨迹,从而实现从抽象到具体的过渡。采用多阶段训练策略:第一阶段 专注于通用的 OneVision (OV) 训练,以开发具有强大理解力和指令执行能力的基础 MLLM;第二阶段,即机器人训练阶段,旨在赋能 RoboBrain 的核心能力,从抽象到具体。
4.1. Model Architecture
RoboBrain 由三个模块组成:用于规划的基础模型、用于可供性感知的 A-LoRA 模型和用于轨迹预测的 T-LoRA 模型。在实际应用中,该模型首先生成详细的规划,然后将其拆分为子任务描述,以执行可供性感知和轨迹预测。RoboBrain 的流程如 Fig.4 所示。
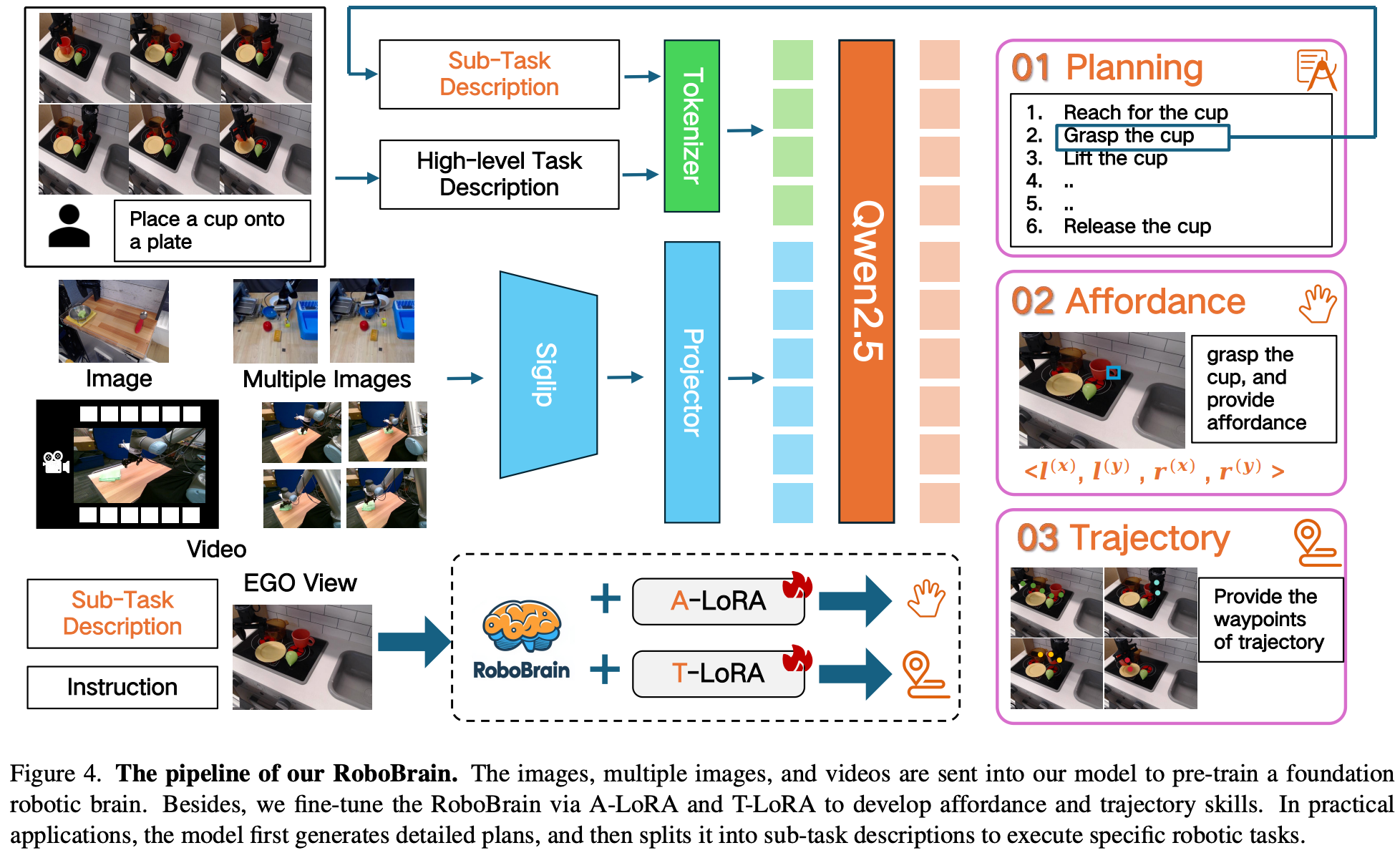
Foundational Model for Planning
利用 LLaVA 作为 RoboBrain 的基础模型,它包含三个主要模块:视觉编码器 Vision Encoder (ViT) g ( ⋅ ) g(\cdot) g(⋅)、映射器 Projectior h ( ⋅ ) h(\cdot) h(⋅) 、大型语言模型 (LLM) f ( ⋅ ) f(\cdot) f(⋅)。具体来说,采用了 SigLIP、一个 2-layer MPL 和 Qwen2.5-7B-Instruct。给定一个图像或视频 X v X_{v} Xv 作为视觉输入,ViT 将其编码为视觉特征 Z v = g ( X v ) Z_{v} = g(X_{v}) Zv=g(Xv),然后通过 projector 将这些特征映射到 LLM 的语义空间,从而生成一系列视觉 tokens H v = h ( Z v ) H_{v} = h(Z_{v}) Hv=h(Zv)。最后,LLM 生成一个基于人类语言指令 X t X_{t} Xt 和 H v H_{v} Hv,以自回归方式做出响应。
A-LoRA Module for Affordance Perception
在研究中,“affordance” 一词指的是人手与物体接触的区域。在交互过程中,人类会本能地与特定区域内的各种物体互动。这里使用边界框来表示可供性。形式上,考虑一个由多个物体及其可供性组成的图像 O i = { A i 0 , A i 1 , … , A i N } O_{i}=\{A^{0}_{i},A^{1}_{i},\dots,A^{N}_{i}\} Oi={Ai0,Ai1,…,AiN} 其中第 i i i 个对象拥有 N N N 个可供性。可供性在形式上被定义为 { l ( x ) , l ( y ) , r ( x ) , r ( y ) } \{l^{(x)},l^{(y)},r^{(x)},r^{(y)}\} {l(x),l(y),r(x),r(y)},其中 { l ( x ) , l ( y ) } \{l^{(x)},l^{(y)}\} {l(x),l(y)} 表示左上角的可供性、 { r ( x ) , r ( y ) } \{r^{(x)},r^{(y)}\} {r(x),r(y)} 表示右下角的可供性;
T-LoRA Module for Trajectory Prediction
在本研究中,“trajectory” 一词指的是中提出的二维视觉轨迹概念。将轨迹路点定义为一系列二维坐标,表示整个过程中末端执行器或手的运动。形式上,在时间步 t t t,轨迹路点可以表示为 P t : N = { ( x i , y i ) ∣ i = t , t + 1 , … , N } P_{t:N}=\{(x_{i},y_{i}) | i=t,t+1,\dots,N\} Pt:N={(xi,yi)∣i=t,t+1,…,N},其中 ( x i , y i ) (x_i, y_i) (xi,yi) 表示视觉轨迹中的第 i i i 个坐标, N N N 表示该场景中的总时间步数。
4.2. Training
Phase 1: General OV Training
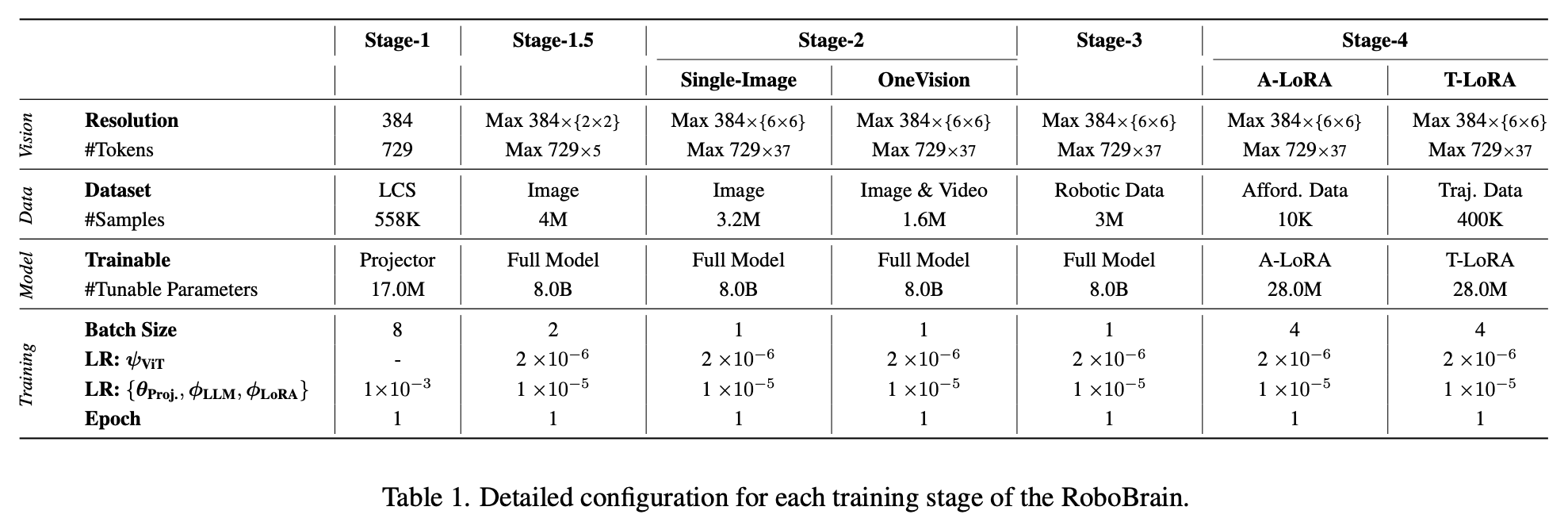
在第一阶段,利用 LLaVA OneVision 的最新训练数据和策略,构建一个具有通用多模态理解和视觉指令跟踪能力的基础模型。这为在第二阶段增强该模型的机器人操控规划能力奠定了基础。详细信息见 Table.1。
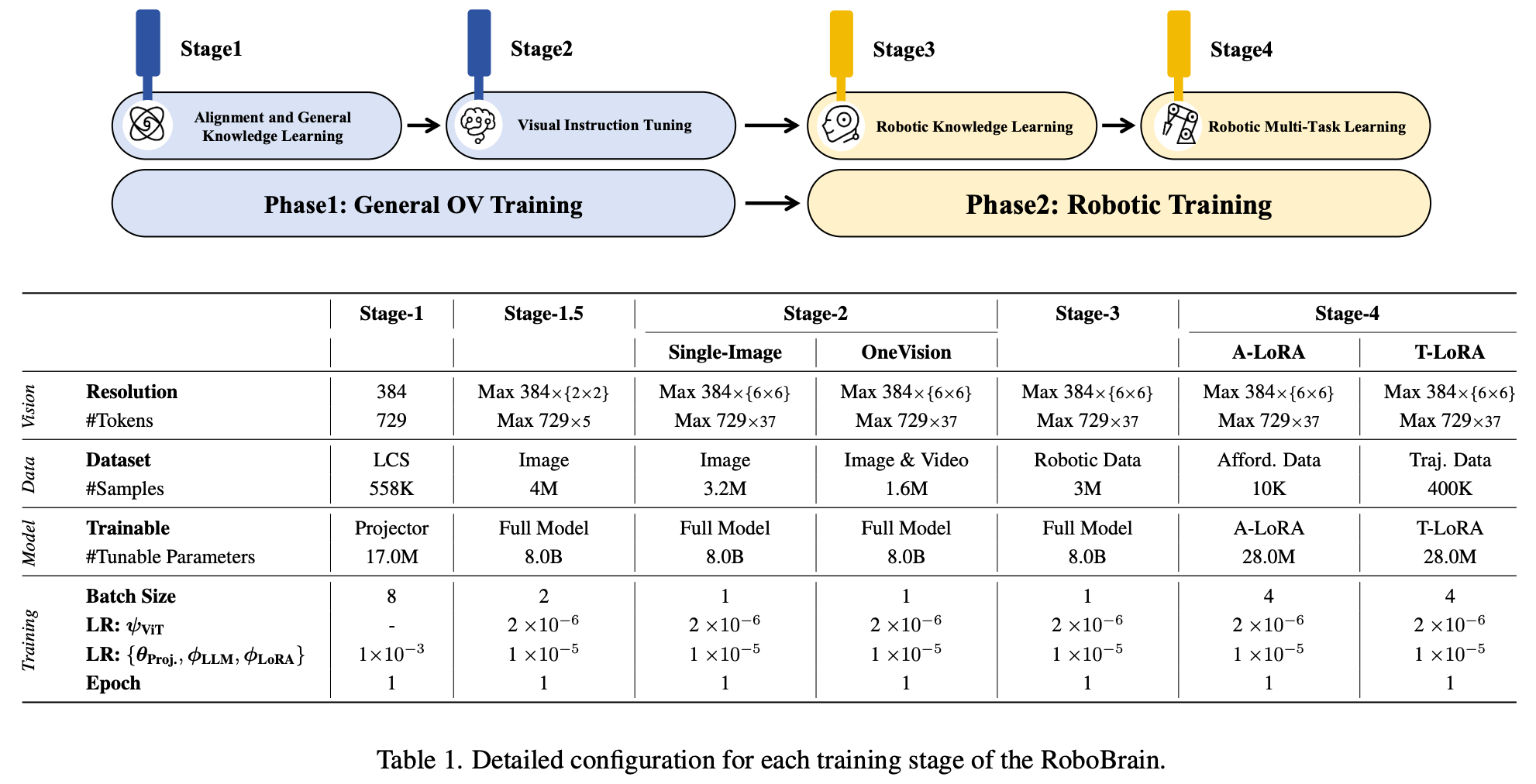
在 Stage 1 中,利用 LCS 558K 数据集中的图文数据训练 Projector,以便将视觉特征 Z v Z_v Zv 与 LLM 语义特征 H v H_v Hv 进行对齐;在 Stage 1.5 中,使用 4M 高质量图文数据训练整个模型,以增强模型的多模态常识理解能力;在 Stage 2 中,进一步使用来自 LLaVA OneVision-Data 的 3.2M 单图像数据和 1.6M 图像及视频数据训练整个模型,旨在增强 RoboBrain 的指令跟随能力,并提高对高分辨率图像和视频的理解。
Phase 2: Robotic Training
在第二阶段,将在第一阶段开发的稳健多模态基础模型的基础上,构建一个更强大的机器人操作规划模型。目标是使 RoboBrain 能够理解复杂、抽象的指令,支持对历史帧信息和高分辨率图像的感知,并在预测潜在操作轨迹的同时输出物体可供性区域。这将有助于操作规划任务从抽象到具体的过渡。详细信息见 Table.1。
在 Stage 3 收集了 1.3M 的机器人数据,以提升模型的操控规划能力。具体而言,这些数据来源于 RoboVQA 800K、ScanView-318K(包括 MMScan-224K、3RScan-43K、ScanQA-25K、SQA3d 26K 以及本文介绍的 ShareRobot-200K 数据集的子集。这些数据集包含大量的场景扫描图像数据、长视频数据和高分辨率数据,以支持模型感知多样化环境的能力。此外,ShareRobot 数据集中细粒度、高质量的规划数据增强了 RoboBrain 的操控规划能力。为了缓解灾难性遗忘问题,从第一阶段选取了约 170 万个高质量的图文数据子集,与 Stage 3 收集的机器人数据混合进行训练,并相应地调整了整个模型。
在 Stage 4 利用来自 ShareRobot 数据集和其他开源资源的可供性和轨迹数据,增强了模型感知物体可供性和根据指令预测操作轨迹的能力。这是通过在训练过程中融入 LoRA 模块来实现的,以实现具体的操作能力。
5. Experiment
5.1. Implementation Details
在整个训练阶段采用了 Zero3 分布式训练策略,所有实验均在配备 8×A800 GPU 的服务器集群上进行。每个阶段的训练组件,包括图像分辨率设置、批量大小、训练周期和学习率,如 Table.1 所示。
5.2. Evaluation Metrics
Planning Task
作者选择了 RoboVQA 、OpenEQA 和 ShareRobot 的测试集作为机器人基准,进行多维度评估。对于 RoboVQA,采用 RoboMamba 中使用的 BLEU1 到 BLEU4 指标进行评估;对于 OpenEQA 和 ShareRobot,使用 GPT-4o 作为评估工具,根据模型预测与真实结果之间的一致性或相似性进行评分,并以此作为模型的最终性能得分。
Affordance Prediction
利用平均精度 (Average Precision, AP) 来评估模型的可供性性能。AP 指标总结了精确率-召回率曲线,该曲线绘制了不同阈值设置下精确率和召回率之间的关系。该指标通过多个并集 (IoU) 阈值进行计算,以获得更全面的评估。
Trajectory Prediction
评估真实轨迹与预测轨迹之间的相似性,两者均表示为二维航点序列,并遵循 Qwen2-VL 进行归一化,范围为 [0, 1000]。评估使用三个指标:Discrete Frechet Distance (DFD) 、Hausdorff Distance (HD) 、 Root Mean Square Error (RMSE)。DFD 捕捉整体形状和时间对齐;HD 识别最大偏差;RMSE 测量平均逐点误差。这些指标共同构成了对轨迹准确性和相似性的全面评估。
5.3. Evaluation on Robot Brain Task
Evaluation on Planning Task
作者选择了 6 个性能强大的 MLLM 作为比较基准,包括不同架构的开源和闭源模型,模型包括 GPT-4V、Claude3、LLaVA-1.5、LLaVA-OneVision-7b、Qwen2-VL-7b 和 RoboMamba。具体的实验结果如 Fig.5 所示。RoboBrain 在三个机器人基准测试中均优于所有基准模型。在 OpenEQA 和 ShareRobot 上,RoboBrain 的表现显著优于所有基准模型,这得益于其在理解机器人任务和感知长视频方面的强大能力。此外,在其他基准测试中也观察到了这种模式,Robo Brain 在 RoboVQA 上始终表现出色,其 BLEU-4 得分比排名第二的模型高出 18.75 分。这一结果凸显了其分解复杂长期任务规划的能力。

Evaluation on Affordance Prediction
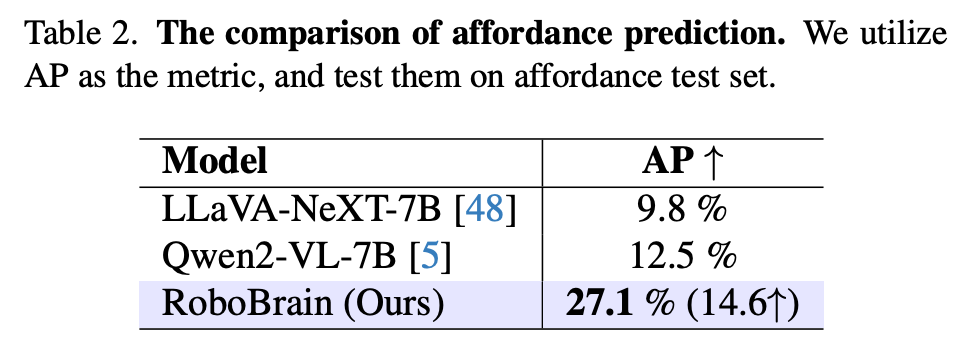
结果总结在 Table.2 中,比较了 Qwen2-VL-7B 和 LLaVA-NeXT-7B 模型。Qwen2-VL 具有卓越的视觉接地能力,而 LLaVA-NeXT 拥有高分辨率和强大的视觉感知能力。在 AGD20K 可供性测试集上对它们进行了测试。RoboBrain 显著优于其他模型,比 Qwen2-VL 高出 14.6 AP,比 LLaVA-NeXT 高出 17.3 AP。这验证了 RoboBrain 能够理解物体的物理属性并准确地提供可供性。
Evaluation on Trajectory Prediction
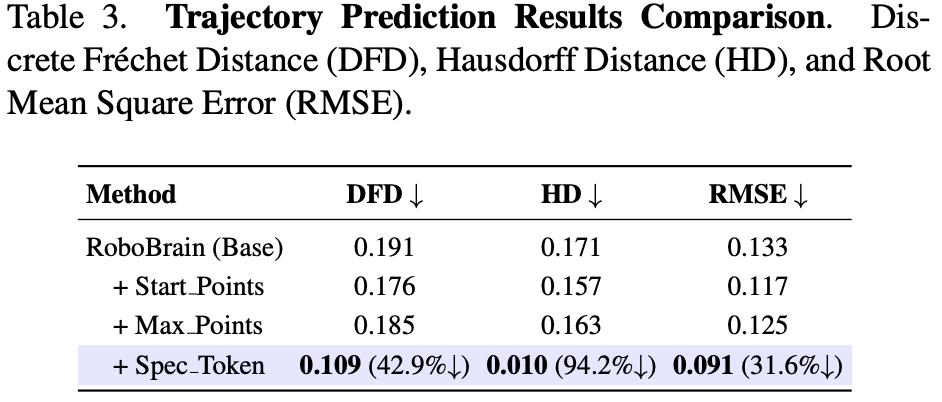
比较了模型的几个变体,结果如 Table.3 所示:
- Baseline:基于轨迹相关的 VQA 数据进行微调;
- Start Points:添加末端执行器的二维起始坐标;
- Max Points:通过均匀采样将航点数量限制为 10 个;
- ** Spec Token & End Points**:添加末端执行器位置和特殊标记,以强调航点和起始/目标点。
每个变体都建立在前一个变体的基础上,最终模型集成了所有组件。最有效的模型集成了所有设计选择。如 Table.3 最后一行所示,与基线相比,DFD、HD 和 RMSE 分别下降了 42.9%、94.2% 和 31.6%。作者发现添加起点可以校正生成的轨迹和末端执行器之间的平移偏移。
5.4. Visualization
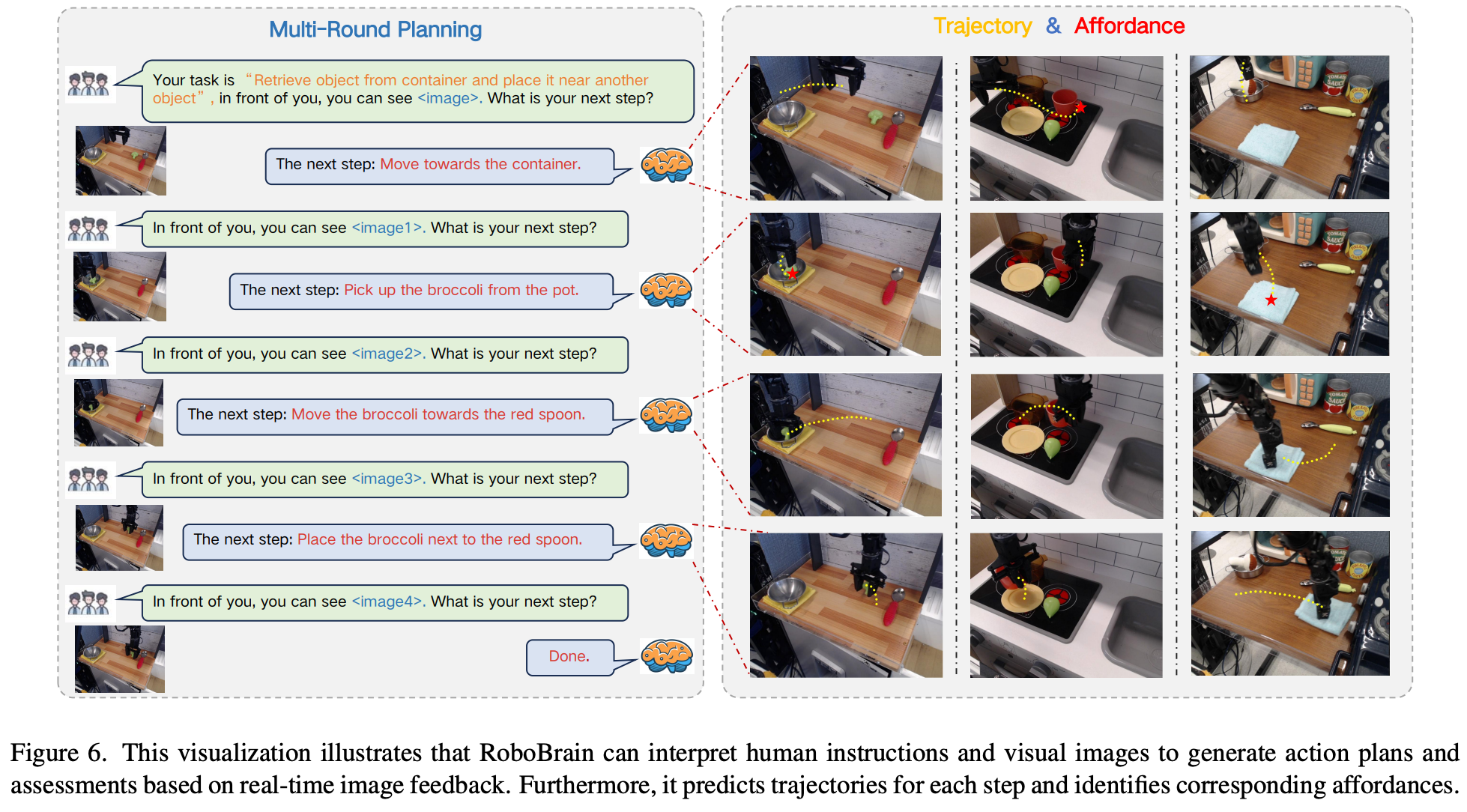
本节将在 Fig.6 中展示 RoboBrain 的视觉示例。RoboBrain 能够根据人类指令和视觉输入进行多轮交互,理解并规划未来步骤。它还能输出更具体的舞蹈和轨迹。
6. Conclusion
本文介绍了 ShareRobot,一个高质量的数据集,它标记了多维信息,包括任务规划、物体可供性和末端执行器轨迹;还介绍了 RoboBrain,一个 MLLM 的模型,它集成了机器人和通用多模态数据,采用多阶段训练策略,并利用长视频和高分辨率图像来增强机器人操控能力。大量实验表明,Robo Brain 在各种机器人任务中都达到了最佳性能,凸显了其显著提升机器人能力的潜力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐



 30
30 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)