安装es、kibana、logstash
本文介绍了ELK(Elasticsearch、Logstash、Kibana)的安装与配置过程。首先提供各组件下载地址,指导用户创建专用目录并解压安装包。重点说明Elasticsearch的配置修改,包括外网访问、端口设置、内存优化以及安全认证等,强调需为非root用户运行。接着介绍Kibana的配置方法,包括关联Elasticsearch、设置中文界面等。最后以MySQL同步为例展示Logsta
·
下载 elk
下载地址
elasticsearch地址: https://www.elastic.co/cn/downloads/elasticsearch
kibana地址: https://www.elastic.co/cn/downloads/kibana
logstash地址: https://www.elastic.co/cn/downloads/logstash
解压elk
创建es全家桶文件夹
cd /usr/local
mkdir elk
cd elk
将下载文件放入elk中,也可以通过wget+下载地址直接下载
tar -zxvf logstash-9.1.2-linux-x86_64.tar.gz
tar -zxvf kibana-9.1.2-linux-x86_64.tar.gz
tar -zxvf elasticsearch-9.1.2-linux-x86_64.tar.gz
修改配置文件
elasticsearch
vim -v elasticsearch-9.1.2/config/elasticsearch.yml
# 修改外网可访问、端口号、集群节点、添加密码验证、日志数据存储位置等
# ~如图
# 关闭自动学习功能,或者更新下载插件
#elasticsearch.yml插入
xpack.ml.enabled: false
#或下载插件
yum install -y glibc libstdc++ libatomic
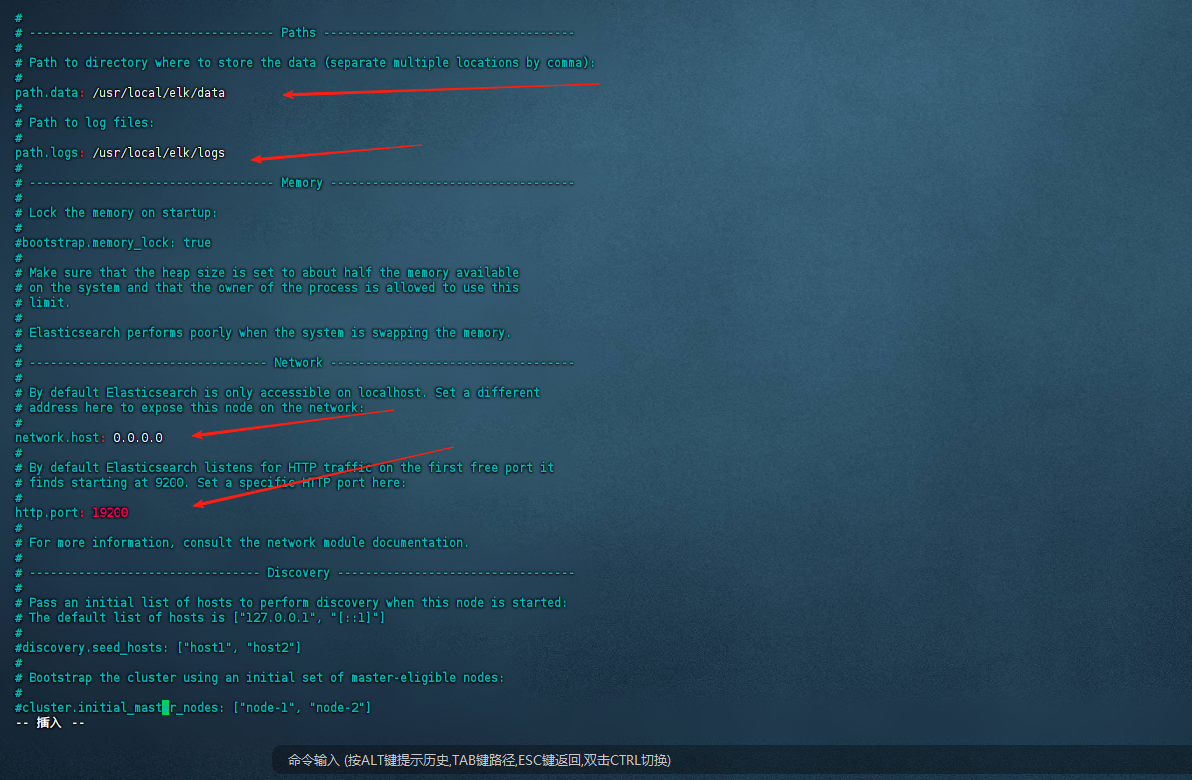
# 修改内存大小,看自己的内存,不能超过当前运行内存剩余的一半,否则会报错
vim -v elasticsearch-9.1.2/config/jvm.options
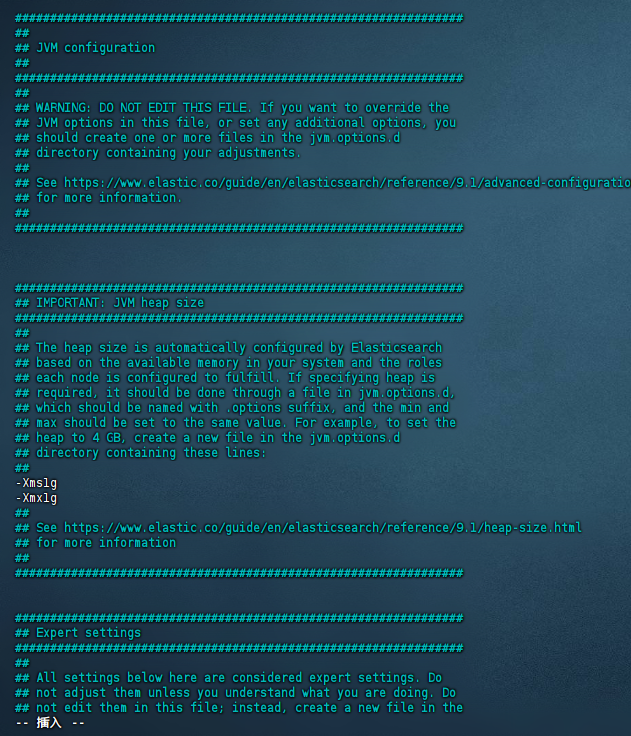
修改最小缓存
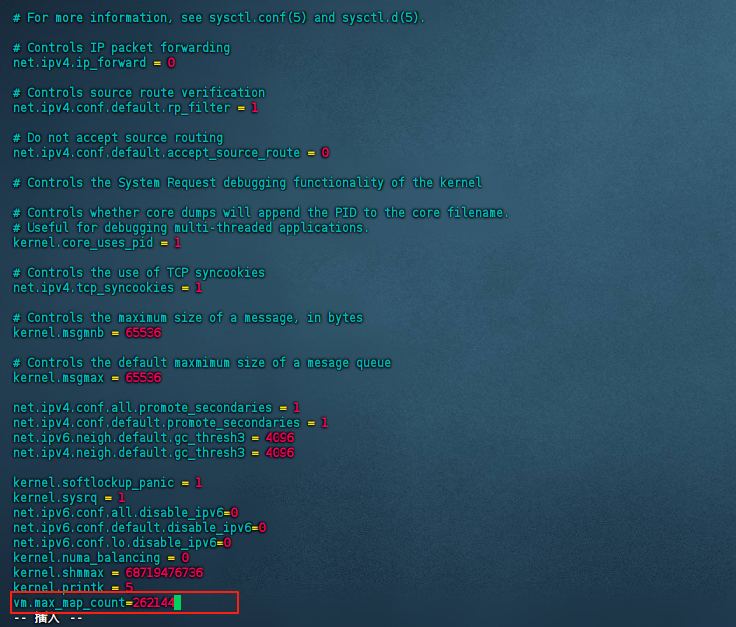
vim -v /etc/sysctl.conf
vm.max_map_count=262144
#生效配置
sudo sysctl -p
如果是root用户
# es不允许使用root启动
#添加新分组和指定用户,授权访问文件,通过指定用户访问
sudo groupadd elk
sudo useradd -g elk elasticsearch
sudo chown -R elasticsearch:elk /usr/local/elk
sudo -u elasticsearch elasticsearch-9.1.2/bin/elasticsearch
启动后
启动后在config中自动生成certs文件(里边为key文件)
并在elasticsearch.yml中自动插入验证配置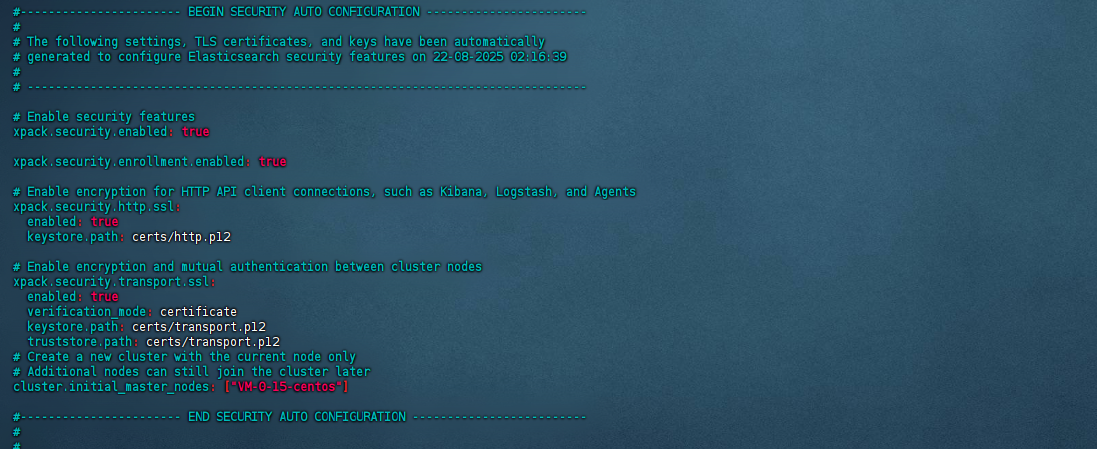
修改默认账户密码
可以使用自动生成和手动输入
# 生成随机密码
# elastic(超级管理员,默认用户名)
./elasticsearch-9.1.2/bin/elasticsearch-reset-password -u elastic -a
# 默认账号
# 手动设置默认账号的密码
./elasticsearch-9.1.2/bin/elasticsearch-reset-password -u kibana_system -i
# kibana_system(Kibana 连接 Elasticsearch 使用的用户)
# logstash_system(Logstash 连接 Elasticsearch 使用的用户)
# beats_system(Filebeat/Metricbeat 等连接 Elasticsearch 使用的用户)
# apm_system(APM Server 连接 Elasticsearch 使用的用户)
# remote_monitoring_user(用于监控的用户)

修改kibana.yml
vim -v kibana-9.1.2/config/kibana.yml
#修改如下
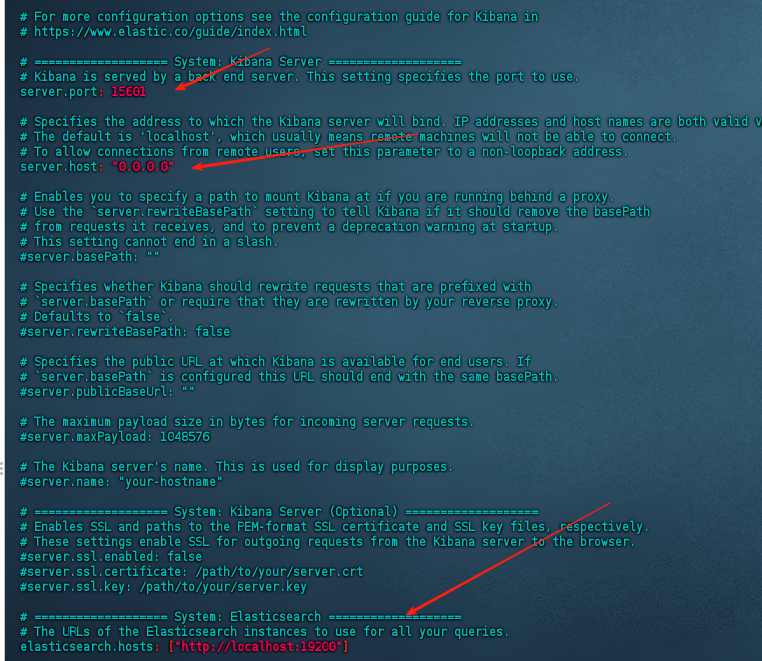
写入es账号密码
 kabana设置中文
kabana设置中文
在kibana.yml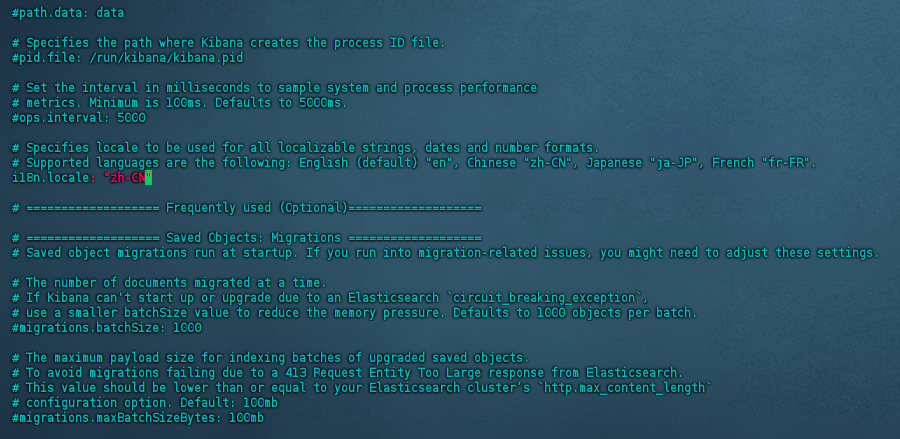
如果是root用户
# kibana同样不允许使用root启动
#添加新分组和指定用户,授权访问文件,通过指定用户访问
# sudo groupadd elk
# sudo useradd -g elk elasticsearch
# sudo chown -R elasticsearch:elk /usr/local/elk
sudo -u elasticsearch ./kibana-9.1.2/bin/kibana
修改logstash.yml (一个同步mysql的例子)
vim -v logstash-9.1.2/config/logstash.yml
#修改端口号范围、以及账号密码

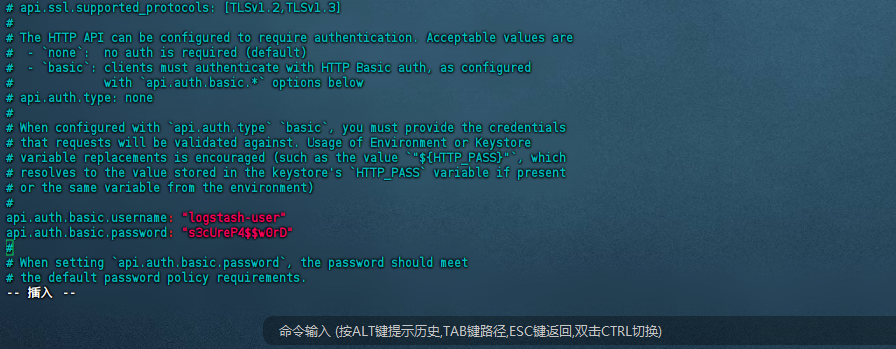 新建conf文件
新建conf文件
# 创建conf
touch logstash-9.1.2/config/logstash.conf
# 修改conf
vim -v logstash-9.1.2/config/logstash.conf
cd logstash-9.1.2
bin/logstash-plugin install logstash-integration-jdbc
分为三个模块,输入、过滤、输出
input {
file {
path => "/data/workspace/workspace/work-cloud/logs/project/test-server.log" # 日志文件路径
start_position => "beginning" # 从文件开头开始读取(可选:改为 "end" 仅读取新日志)
sincedb_path => "NUL" # 防止记录读取位置(Windows下可用 "NUL")
# 如果是在Linux/Mac,使用:sincedb_path => "/dev/"
# 如果是在Windows,使用:sincedb_path => "NUL"
}
}
filter {
# 使用 grok 解析日志格式
grok {
match => {
"message" => [
# 匹配时间、日志级别、线程、类名、SQL 或其他信息
"%{TIMESTAMP_ISO8601:timestamp} \| %{DATA:log_level} %{NUMBER:pid} \| %{GREEDYDATA:thread_info} \| %{DATA:class_name} \| %{GREEDYDATA:log_content}"
]
}
# 如果 grok 解析失败,标记为 _grokparsefailure
tag_on_failure => ["_grokparsefailure"]
}
# 提取 SQL 语句(如果日志内容包含 SQL)
if [log_content] =~ /Preparing: (.+)$/ or [log_content] =~ /==> Parameters: (.+)$/ {
grok {
match => {
"log_content" => [
"Preparing: %{GREEDYDATA:sql_statement}", # 提取 "Preparing: SELECT ..."
"==> Parameters: %{GREEDYDATA:sql_parameters}" # 提取参数(可选)
]
}
}
}
# 提取错误信息(如果日志级别是 ERROR 或包含异常堆栈)
if [log_level] == "ERROR" or [log_content] =~ /Exception|Error/ {
grok {
match => {
"log_content" => [
"Exception: %{GREEDYDATA:exception_message}", # 提取异常信息
"Caused by: %{GREEDYDATA:cause_message}" # 提取原因(可选)
]
}
}
}
# 日期解析(将字符串时间转换为 Logstash 时间格式)
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp" # 覆盖默认的 @timestamp 字段
}
# 移除不需要的字段(可选)
mutate {
remove_field => ["message", "timestamp", "host", "path"] # 移除原始消息和其他冗余字段
}
}
output {
# 输出到 Elasticsearch
elasticsearch {
hosts => ["http://localhost:19200"] # Elasticsearch 地址
index => "scrm-server-logs-%{+YYYY.MM.dd}" # 索引名称(按天分割)
user => "logstash_system" # 如果启用了 Elasticsearch 安全认证
password => "pass" # 替换为实际密码
}
# 可选:输出到控制台(调试用)
stdout {
codec => rubydebug # 以结构化格式输出到控制台
}
}
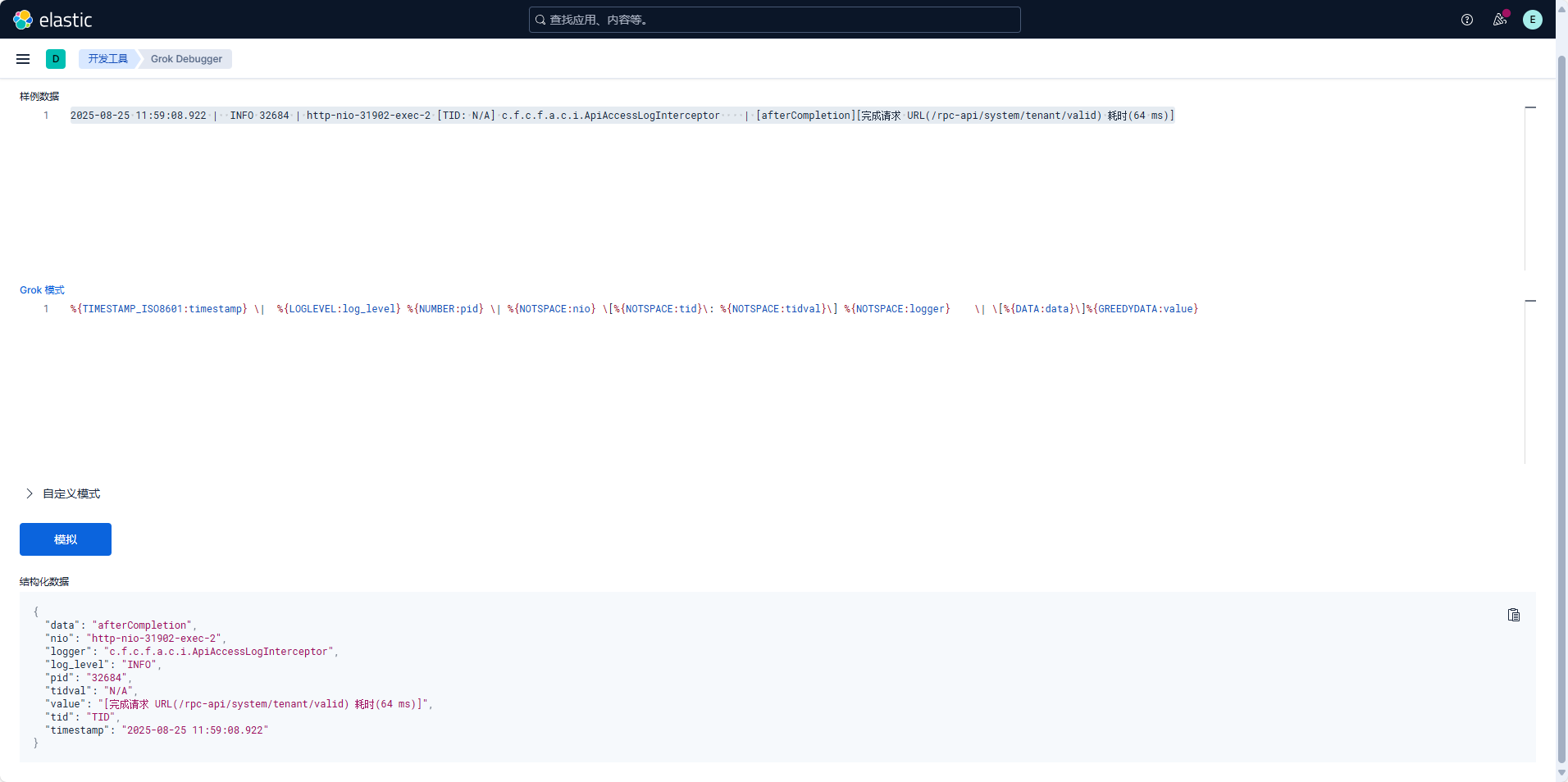
常用 Grok 关键词
| 关键词 | 注释 | 示例 |
|---|---|---|
| WORD | 非空格字符串 Hello、123 | |
| NOTSPACE | 非空格的连续字符 | GET /index.html |
| DATA | 任意数据(可能包含空格) | This is a test |
| GREEDYDATA | 贪婪匹配(尽可能多的字符) | *(直到行尾) |
| QUOTEDSTRING | 引号包裹的字符串 | “Hello World” |
| IP | IPv4 地址 | 192.168.1.1 |
| IPV6 | IPv6 地址 | 2001:0db8::1 |
| HOSTNAME | 主机名 | example.com |
| PORT | 端口号 | 8080 |
| TIMESTAMP_ISO8601 | ISO8601 时间格式 | 2023-10-10T13:55:36Z |
| HTTPDATE | HTTP 日期格式 | 10/Oct/2023:13:55:36 +0800 |
| DATE | 通用日期格式 | 10/Oct/2023 |
| METHOD | HTTP 方法 | GET、POST |
| URIPATH | URI 路径 | /index.html |
| URIQUERY | URI 查询参数 | ?id=123 |
| USERAGENT | User-Agent 字符串 | Mozilla/5.0 |
| NUMBER | 整数或浮点数 | 123、3.14 |
| INT | 整数 | 42 |
| BASE10NUM | 十进制数 | 12345 |
自定义模式
filter {
grok {
match => {
"message" => "%{CUSTOM_PATTERN:field_name}"
}
patterns_dir => ["/usr/local/elk/custom_patterns"] # 可选:自定义模式文件路径
}
}
同步mysql
# 安装jdbc插件
https://downloads.mysql.com/archives/c-j/
tar -zxvf mysql-connector-java-8.0.20.tar.gz
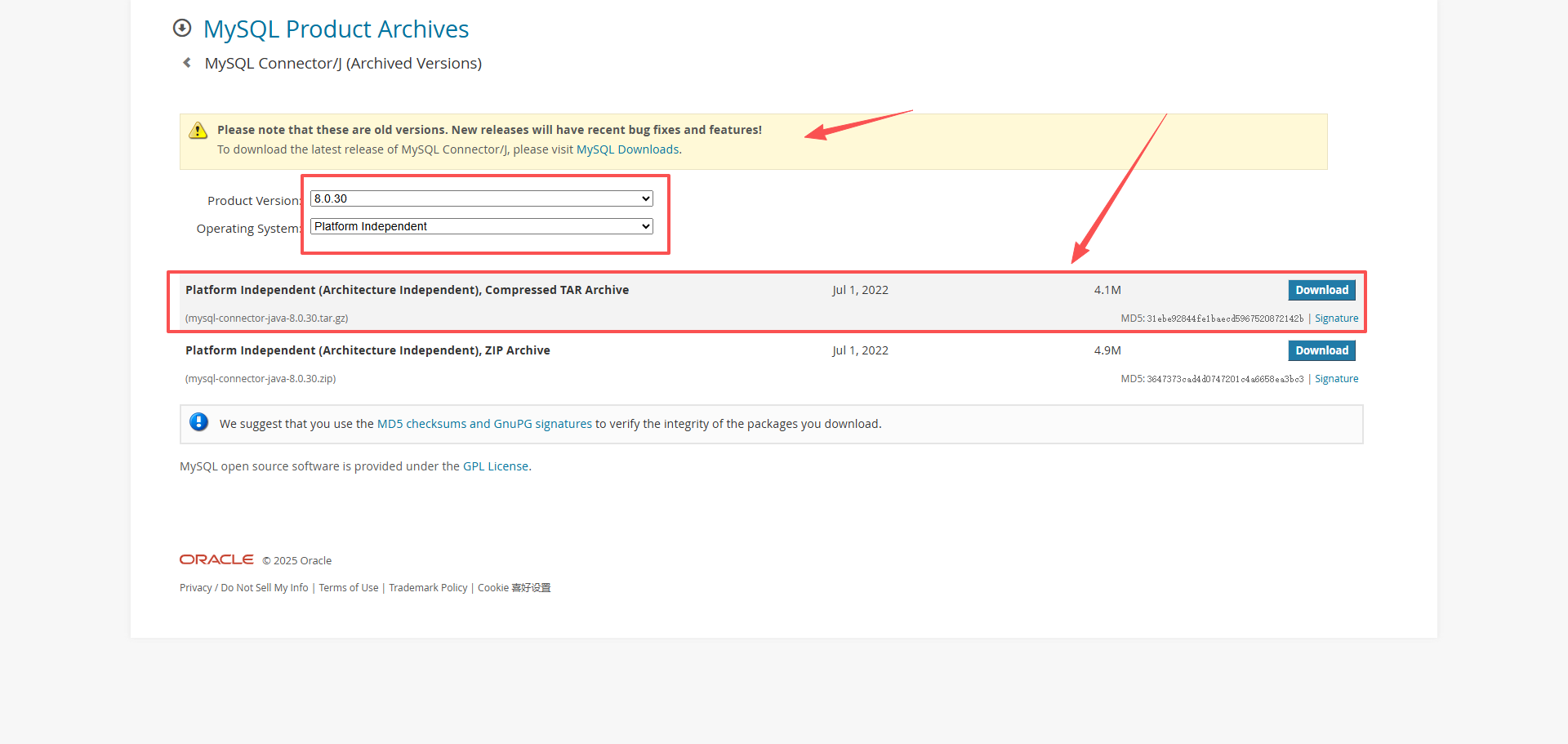
如果是root用户
# kibana同样不允许使用root启动
#添加新分组和指定用户,授权访问文件,通过指定用户访问
# sudo groupadd elk
# sudo useradd -g elk elasticsearch
# sudo chown -R elasticsearch:elk /usr/local/elk
sudo -u elasticsearch ./logstash-9.1.2/bin/logstash -f logstash-9.1.2/config/logstashMysql.conf
启动es和kibana脚本
#!/bin/bash
ELK_HOME="/usr/local/opt/elk"
ELK_USER="elasticsearch"
ES_PID_FILE="/usr/local/elk/elkpid/es.pid"
KIB_PID_FILE="/usr/local/elk/elkpid/kib.pid"
ES_LOG_FILE="/usr/local/elk/nohup/esstartup.log"
KIB_LOG_FILE="/usr/local/elk/nohup/kibstartup.log"
mkdir -p /usr/local/elk/elkpid
mkdir -p /usr/local/elk/nohup
# 停止 Elasticsearch
if [ -f "$ES_PID_FILE" ]; then
echo "[INFO] 正在停止 Elasticsearch..."
kill $(cat "$ES_PID_FILE")
rm -f "$ES_PID_FILE"
echo "[SUCCESS] Elasticsearch 已停止。"
else
echo "[WARNING] Elasticsearch PID文件不存在"
fi
# 启动 Elasticsearch
echo "[INFO] 正在启动 Elasticsearch..." | tee -a "$ES_LOG_FILE"
sudo -u $ELK_USER nohup "$ELK_HOME/elasticsearch-9.1.2/bin/elasticsearch" -d -p "$ES_PID_FILE" >> "$ES_LOG_FILE" 2>&1
# 停止 Kibana
if [ -f "$KIB_PID_FILE" ]; then
echo "[INFO] 正在停止 Kibana..."
kill $(cat "$KIB_PID_FILE")
rm -f "$KIB_PID_FILE"
echo "[SUCCESS] Kibana 已停止。"
else
echo "[WARNING] Kibana PID 文件不存在"
fi
# 启动 Kibana
echo "[INFO] 正在启动 Kibana..." | tee -a "$KIB_LOG_FILE"
sudo -u $ELK_USER nohup "$ELK_HOME/kibana-9.1.2/bin/kibana" >> "$KIB_LOG_FILE" 2>&1 &
echo $! > "$KIB_PID_FILE"
sleep 20
if [ -f "$ES_PID_FILE" ] && ps -p $(cat "$ES_PID_FILE") > /dev/null; then
echo "[SUCCESS] elasticsearch 启动成功!PID: $(cat "$ES_PID_FILE")" | tee -a "$ES_LOG_FILE"
else
echo "[ERROR] elasticsearch 启动失败,请检查日志: $ES_LOG_FILE" | tee -a "$ES_LOG_FILE"
fi
if [ -f "$KIB_PID_FILE" ] && ps -p $(cat "$KIB_PID_FILE") > /dev/null; then
echo "[SUCCESS] Kibana 启动成功!PID: $(cat "$KIB_PID_FILE")" | tee -a "$KIB_LOG_FILE"
else
echo "[ERROR] Kibana 启动失败,请检查日志: $KIB_LOG_FILE" | tee -a "$KIB_LOG_FILE"
fi

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)