微软开源实时 TTS 模型:VibeVoice-Realtime-0.5B
微软开源轻量级TTS模型VibeVoice-Realtime-0.5B,实现低延迟、长时稳定、多角色音色适配,适用于智能语音交互与企业级应用。
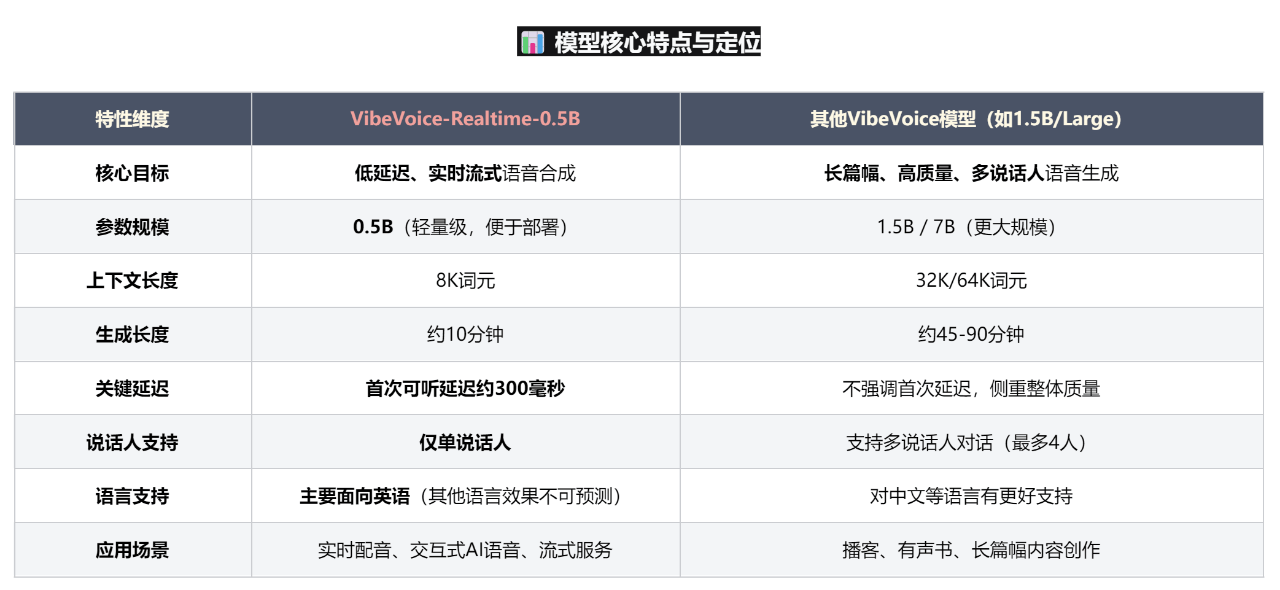
近日,微软开源了 VibeVoice-Realtime-0.5B 轻量级实时文本转语音(TTS)模型,以 0.5B 参数的紧凑设计实现了“低延迟、长时稳定、多角色音色适配”三大核心优势,为智能语音交互场景提供了高效能解决方案。该模型凭借高保真音质与低资源消耗特性,精准契合企业级语音合成需求,在零售、内容生产、客户服务及数字媒体等领域展现显著价值。
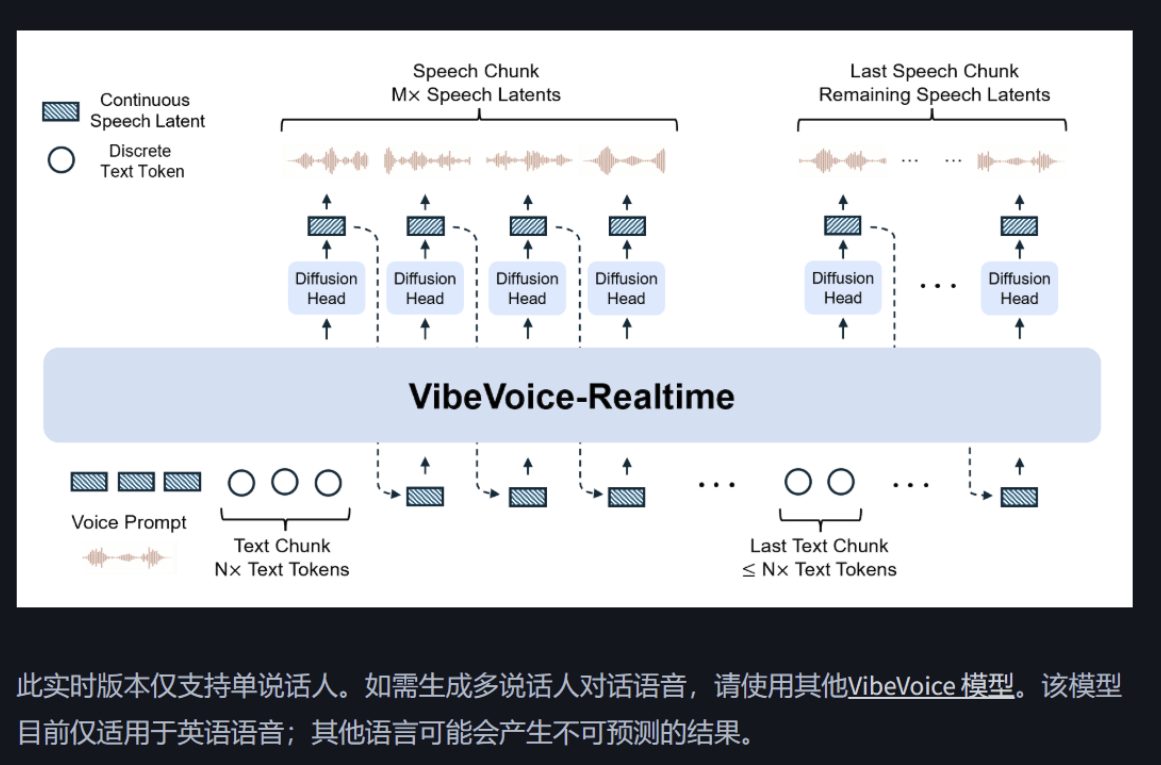
【模型核心参数与性能】
模型采用 0.5B 超轻量化参数架构,支持 24kHz 采样率的高保真音频输出,专注英文语音合成。其创新压缩架构通过 σ-VAE 技术实现音频数据 3200 倍高效压缩,在保证音质还原度的同时大幅降低传输带宽与存储成本。
【四大核心技术突破】
- 实时交互低延迟:生成延迟显著低于同类模型,适配智能助手、直播配音等实时场景,实现“即输即出”的流畅对话体验,避免传统 TTS 因延迟导致的语义割裂问题。
- 长音频稳定性:单次可连续生成 10 分钟音频,全程保持音色一致性、语速平稳性及节奏自然度,彻底解决传统模型长文本合成中音色漂移、节奏紊乱的痛点。
- 多角色音色模拟:支持单人合成中嵌入自然对话细节,如呼吸停顿、语调起伏等,实现“咨询专员”“售后顾问”等多身份音色自动切换,增强对话真实感与场景适配度。
- 端到端高效架构:从文本输入到音频输出的全流程优化,确保在低算力设备上亦可高效运行,兼顾企业级部署的成本控制与性能需求。
【行业落地价值场景】
- 智能客服与热线服务:毫秒级响应配合多角色音色切换,使虚拟客服能够根据业务场景自动调整语调与节奏,提升用户信任度与咨询转化率,消除传统单一音色带来的机械感。
- 有声内容生产革新:在播客、有声书及企业培训音频制作中,单次 10 分钟连续生成能力可减少 80% 人工调校成本,确保长时音频的音色统一性与叙事连贯性。
- 数字人交互增强:为品牌虚拟代言人、企业数字员工赋予多角色对话能力,通过模拟真人呼吸、停顿等细节,使虚拟形象互动更贴近真实沟通,强化品牌亲和力与用户沉浸感。
- 直播与短视频配音:实时文本转语音功能可同步匹配直播脚本更新节奏,支持批量文本导入生成多段音频,满足电商直播实时口播、短视频矩阵日更配音等高频内容产出需求,显著降低对专业配音的周期与成本依赖。
VibeVoice-Realtime-0.5B 的开源为语音合成领域注入新动能,其轻量化设计与高价值能力组合,正推动企业级语音交互向更自然、更高效、更低成本的方向演进,成为数字化转型中不可或缺的语音技术基础设施。
领驭科技深耕AI领域的创新与实践落地,持续关注微软&OpenAI、GPT、DeepSeek等主流大语言模型(LLM)的前沿动态。我们聚焦技术迭代细节,拆解应用落地逻辑,从底层算法演进到产业级实践案例,全方位梳理大语言模型的发展脉络。期待与关注AI发展的伙伴交流探讨,欢迎持续关注。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)