在 Windows 上使用 youtu-agent:打造你的专属AI智能助手
引言在AI技术飞速发展的今天,每个开发者都希望能够拥有一个强大且易用的AI助手来提升工作效率。今天我要向大家介绍一个功能强大的AI代理框架——youtu-agent(基于腾讯开源的tencent-agent),它不仅功能丰富,而且在Windows环境下配置简单,让我们能够快速搭建属于自己的AI智能助手。youtu-agent 是基于大语言模型的智能代理开发框架,它提供了以下核心能力:🤖 多场景A
引言
在AI技术飞速发展的今天,每个开发者都希望能够拥有一个强大且易用的AI助手来提升工作效率。今天我要向大家介绍一个功能强大的AI代理框架——youtu-agent(基于腾讯开源的tencent-agent),它不仅功能丰富,而且在Windows环境下配置简单,让我们能够快速搭建属于自己的AI智能助手。
什么是 youtu-agent?
youtu-agent 是基于大语言模型的智能代理开发框架,它提供了以下核心能力:
-
🤖 多场景AI代理:支持数据分析、文件管理、论文收集等专业场景
-
📊 强大的数据处理:内置数据分析工具,支持CSV、Excel等多种格式
-
🔧 工具集成:集成bash工具、搜索工具等实用功能
-
🎯 GUI自动化:支持GUI操作训练数据生成
-
🌐 多模型支持:兼容DashScope、OpenAI等多种LLM后端
Windows 环境配置指南
1. 环境准备
首先确保你的Windows系统满足以下要求:
-
Windows 10/11
-
Python 3.13+
-
Git
2. 项目克隆与安装
# 克隆项目 git clone https://github.com/tencent/youtu-agent.git cd youtu-agent # 使用 uv 包管理器安装依赖 # 推荐使用清华镜像源加速安装 uv sync --index-url https://pypi.tuna.tsinghua.edu.cn/simple
3. 环境变量配置
创建 .env 文件并配置必要的环境变量:
# DashScope API 配置 (推荐中国用户使用) DASHSCOPE_API_KEY=your_dashscope_api_key_here LLM_MODEL_NAME=qwen-flash LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1 # 禁用可能的网络问题组件 PHOENIX_ENDPOINT= OTEL_SDK_DISABLED=true OPENAI_AGENTS_TRACES_ENABLED=false
4. Windows 兼容性修复
为了确保在Windows环境下的稳定运行,项目已经针对性地解决了以下问题:
-
pexpect兼容性:自动检测Windows平台并使用适当的终端模拟器
-
路径分隔符:自动处理Windows和Unix路径差异
-
网络配置:优化了网络连接配置,避免超时问题
核心功能使用指南
环境准备
克隆仓库并安装依赖:
git clone https://github.com/Tencent/Youtu-agent.git cd Youtu-agent uv sync

安装时报错
PS E:\A\proj\tencent-agent> uv sync
error: Failed to download https://github.com/astral-sh/python-build-standalone/releases/download/20250409/cpython-3.12.10%2B20250409-x86_64-pc-windows-msvc-install_only_stripped.tar.gz
Caused by: Request failed after 3 retries
Caused by: error sending request for url (https://github.com/astral-sh/python-build-standalone/releases/download/20250409/cpython-3.12.10%2B20250409-x86_64-pc-windows-msvc-install_only_stripped.tar.gz)
Caused by: client error (Connect)
Caused by: tcp connect error: 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。 (os error 10060)
Caused by: 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。 (os error 10060)
问题分析
您遇到的错误是因为 uv 工具试图从 GitHub 下载一个 Python 发行版(cpython-3.12.10+20250409-x86_64-pc-windows-msvc-install_only_stripped.tar.gz),但是由于网络连接问题,连接超时失败了。错误信息显示:"由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败"。
解决方案
我采用了以下步骤来解决这个问题:
- 检查现有Python安装:首先确认您的系统已经安装了 Python 3.13.4
- 固定Python版本:使用
uv python pin 3.13命令告诉 uv 使用您现有的 Python 3.13 安装,而不是尝试下载新的 Python 版本 - 成功安装requests包:之后再次运行安装命令就成功了,因为 uv 不再需要下载Python发行版
最终结果
- ✅
requests包(版本 2.32.4)已成功安装到您的项目中 - ✅
pyproject.toml文件已更新,包含了新的依赖项 - ✅ uv 还添加了清华大学镜像源的配置,方便后续包的安装
- ✅ 现在您可以在 tencent-agent 项目中正常使用
requests库了
核心要点
这个问题的关键在于网络连接到 GitHub 的问题。通过使用本地已安装的 Python 版本,避免了需要从网络下载 Python 发行版,从而绕过了网络连接问题。这是在网络环境受限时的一个常用解决方案。
升级到 python 3.13
(agi_learn) e:\A\proj\tencent-agent>cd e:\A\proj\tencent-agent && uv add --default-index https://pypi.tuna.tsinghua.edu.cn/simple requests
Using CPython 3.13.4 interpreter at: C:\Python313\python.exe
Creating virtual environment at: .venv
Resolved 194 packages in 11.18s
Built wikipedia-api==0.8.1
Built antlr4-python3-runtime==4.9.3
Built youtu-agent @ file:///E:/A/proj/tencent-agent
Built sgmllib3k==1.0.0
Prepared 123 packages in 15.69s
░░░░░░░░░░░░░░░░░░░░ [0/123] Installing wheels...
warning: Failed to hardlink files; falling back to full copy. This may lead to degraded performance.
If the cache and target directories are on different filesystems, hardlinking may not be supported.
If this is intentional, set `export UV_LINK_MODE=copy` or use `--link-mode=copy` to suppress this warning.
Installed 123 packages in 6.18s
+ aiofiles==24.1.0
+ aiohappyeyeballs==2.6.1
+ aiohttp==3.12.15
+ aiosignal==1.4.0
+ annotated-types==0.7.0
+ antlr4-python3-runtime==4.9.3
+ anyio==4.9.0
+ art==6.5
+ arxiv==2.2.0
+ asttokens==3.0.0
+ attrs==25.3.0
+ cachetools==5.5.2
+ certifi==2025.7.9
+ charset-normalizer==3.4.2
+ chunkr-ai==0.1.0
+ click==8.2.1
+ colorama==0.4.6
+ colorlog==6.9.0
+ contourpy==1.3.2
+ cycler==0.12.1
+ decorator==5.2.1
+ distro==1.9.0
+ docker==7.1.0
+ et-xmlfile==2.0.0
+ executing==2.2.0
+ feedparser==6.0.11
+ fonttools==4.59.0
+ frozenlist==1.7.0
+ google-auth==2.40.3
+ google-genai==1.26.0
+ greenlet==3.2.3
+ griffe==1.7.3
+ h11==0.16.0
+ httpcore==1.0.9
+ httpx==0.28.1
+ httpx-sse==0.4.1
+ hydra-core==1.3.2
+ idna==3.10
+ importlib-metadata==8.7.0
+ ipython==9.4.0
+ ipython-pygments-lexers==1.1.1
+ jedi==0.19.2
+ jinja2==3.1.6
+ jiter==0.10.0
+ jsonschema==4.24.0
+ jsonschema-specifications==2025.4.1
+ kiwisolver==1.4.8
+ markdown-it-py==3.0.0
+ markupsafe==3.0.2
+ matplotlib==3.10.3
+ matplotlib-inline==0.1.7
+ mcp==1.12.3
+ mdurl==0.1.2
+ multidict==6.6.3
+ nest-asyncio==1.6.0
+ numpy==2.3.1
+ omegaconf==2.3.0
+ openai==1.99.6
+ openai-agents==0.2.8
+ openinference-instrumentation==0.1.34
+ openinference-instrumentation-openai==0.1.30
+ openinference-instrumentation-openai-agents==1.1.1
+ openinference-semantic-conventions==0.1.21
+ openpyxl==3.1.5
+ opentelemetry-api==1.34.1
+ opentelemetry-instrumentation==0.55b1
+ opentelemetry-sdk==1.34.1
+ opentelemetry-semantic-conventions==0.55b1
+ packaging==25.0
+ pandas==2.3.1
+ parso==0.8.4
+ pexpect==4.9.0
+ pillow==11.3.0
+ prompt-toolkit==3.0.51
+ propcache==0.3.2
+ psycopg2-binary==2.9.10
+ ptyprocess==0.7.0
+ pure-eval==0.2.3
+ pyasn1==0.6.1
+ pyasn1-modules==0.4.2
+ pydantic==2.11.7
+ pydantic-core==2.33.2
+ pydantic-settings==2.10.1
+ pygments==2.19.2
+ pyparsing==3.2.3
+ python-dateutil==2.9.0.post0
+ python-dotenv==1.1.1
+ python-multipart==0.0.20
+ pytz==2025.2
+ pywin32==311
+ pyyaml==6.0.2
+ referencing==0.36.2
+ regex==2024.11.6
+ requests==2.32.4
+ rich==14.1.0
+ rpds-py==0.26.0
+ rsa==4.9.1
+ sgmllib3k==1.0.0
+ six==1.17.0
+ sniffio==1.3.1
+ sqlalchemy==2.0.41
+ sqlmodel==0.0.24
+ sse-starlette==2.4.1
+ stack-data==0.6.3
+ starlette==0.47.1
+ tenacity==8.5.0
+ tiktoken==0.9.0
+ toml==0.10.2
+ tqdm==4.67.1
+ traitlets==5.14.3
+ types-requests==2.32.4.20250611
+ typing-extensions==4.14.1
+ typing-inspection==0.4.1
+ tzdata==2025.2
+ urllib3==2.5.0
+ uvicorn==0.35.0
+ wcwidth==0.2.13
+ websockets==15.0.1
+ wikipedia-api==0.8.1
+ wrapt==1.17.2
+ yarl==1.20.1
+ youtu-agent==0.1.0 (from file:///E:/A/proj/tencent-agent)
+ zipp==3.23.0🚀 使用指南
1. 环境配置
首先,您需要配置环境变量。创建一个 .env 文件:
cd e:\A\proj\tencent-agent && cp .env.example .env2. 配置API密钥
您需要编辑 .env 文件,配置以下关键信息:
e:\A\proj\tencent-agent\.env
🔧 配置说明
您需要在 .env 文件中配置以下项目:
- LLM 配置:
UTU_LLM_MODEL: 模型名称(如gpt-4,deepseek-chat等)UTU_LLM_BASE_URL: API基础URLUTU_LLM_API_KEY: API密钥
- 工具配置(可选):
- SERPER_API_KEY: 用于搜索功能的API密钥
JINA_API_KEY: 用于文档读取的API密钥
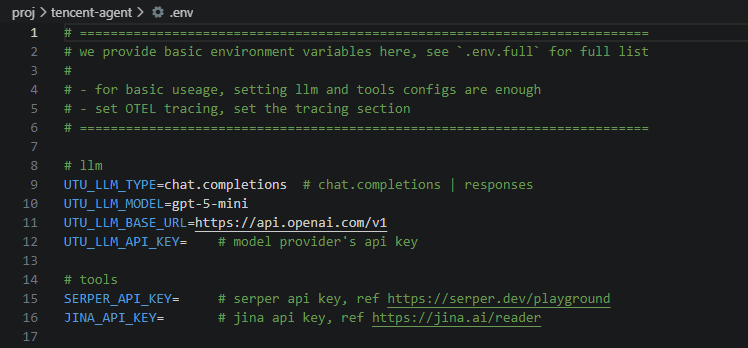
使用 阿里云百炼的模型服务
修改为

# llm - DashScope Configuration
UTU_LLM_TYPE=chat.completions # chat.completions | responses
UTU_LLM_MODEL=qwen-plus
UTU_LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
UTU_LLM_API_KEY= # DashScope API Key执行 example, 报错
(agi_learn) e:\A\proj\tencent-agent>python scripts/cli_chat.py --stream --config_name examples/data_analysis
Traceback (most recent call last):
File "e:\A\proj\tencent-agent\scripts\cli_chat.py", line 4, in <module>
import art
ModuleNotFoundError: No module named 'art'缺少 art module,不能直接 pip install
在 uv 中安装: uv add art
(agi_learn) e:\A\proj\tencent-agent>cd e:\A\proj\tencent-agent && uv add art
Resolved 194 packages in 7ms
Audited 123 packages in 0.60ms成功完成安装
 在执行中 发现有 phoenix 错误
在执行中 发现有 phoenix 错误
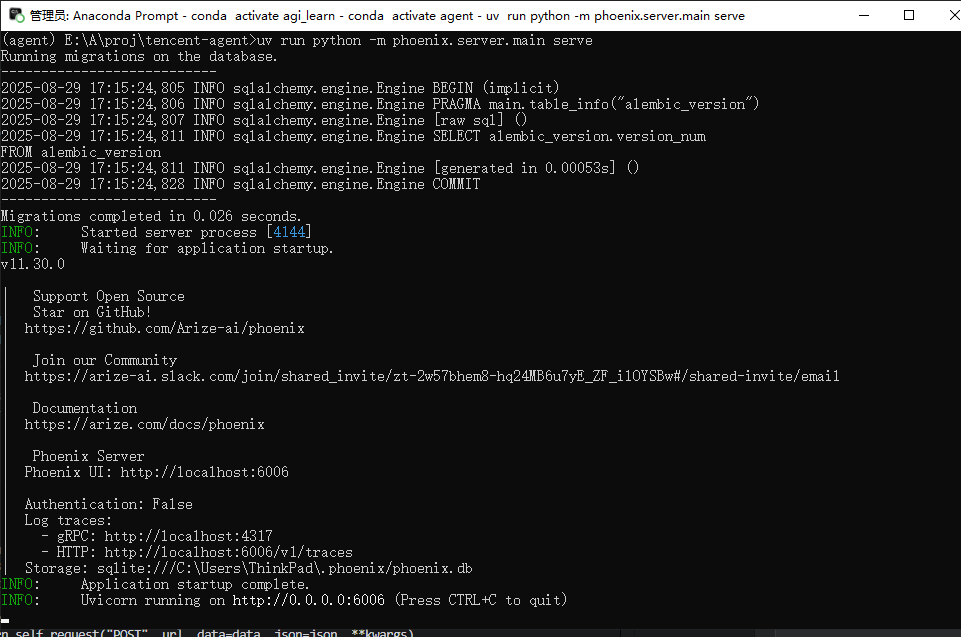
uv add arize-phoenix使用本地 Phoenix 服务
如果您想启用监控功能,需要先安装和启动 Phoenix:
- 安装 Phoenix:
uv add arize-phoenix- 启动 Phoenix 服务:
uv run python -m phoenix.server.main serve- 配置端点:
PHOENIX_ENDPOINT=http://localhost:6006
PHOENIX_PROJECT_NAME=youtu_agent启动 uv run python -m phoenix.server.main serve
uv run python demo/demo.py
4. Windows 兼容性修复
为了确保在Windows环境下的稳定运行,项目已经针对性地解决了以下问题:
-
pexpect兼容性:自动检测Windows平台并使用适当的终端模拟器
-
路径分隔符:自动处理Windows和Unix路径差异
-
网络配置:优化了网络连接配置,避免超时问题
核心功能使用指南
1. 数据分析代理
youtu-agent 的数据分析功能非常强大,可以轻松处理各种数据分析任务:
# 启动数据分析代理 uv run python scripts/cli_chat.py --stream --config_name examples/data_analysis
使用示例:
> 请分析 test_data/sales_data.csv 文件,告诉我数据集的基本情况 > 分析2023年第四季度的销售数据,找出销售额最高的产品类别 > 为销售数据创建可视化图表,包括产品类别分布饼图和月度趋势线图
2. GUI训练数据生成器
这是一个独特的功能,可以为GUI自动化任务生成训练数据:
# 启动GUI数据生成器 set OTEL_SDK_DISABLED=true && uv run python examples/gui_agent_datamaker/main_windows.py
该工具会自动生成:
-
📝 操作指令:清晰的单步操作指令
-
📄 期望输出:操作后的预期文件状态
-
✅ 验证脚本:自动检查操作是否正确完成
3. 文件管理代理
# 启动文件管理代理 uv run python scripts/cli_chat.py --stream --config_name examples/file_manager
可以帮你:
-
🗂️ 整理文件和文件夹
-
🔍 搜索特定文件
-
📋 生成文件清单和报告
-
🏷️ 自动分类和标记文件
4. 论文收集代理
# 启动论文收集代理 uv run python scripts/cli_chat.py --stream --config_name examples/paper_collector
适用于学术研究:
-
📚 搜索相关论文
-
📄 整理文献资料
-
📊 生成研究报告
-
🔗 管理引用链接
实际应用场景
场景一:商业数据分析
假设你是一名数据分析师,需要定期分析销售数据:
# 启动数据分析代理 uv run python scripts/cli_chat.py --stream --config_name examples/data_analysis # 在代理中输入 > 分析本季度销售数据,识别增长趋势和潜在风险点,并提供优化建议
youtu-agent 会自动:
-
读取和清洗数据
-
执行多维度分析
-
生成可视化图表
-
提供业务洞察和建议
场景二:自动化办公
对于重复性的文档处理工作:
# 启动GUI数据生成器 set OTEL_SDK_DISABLED=true && uv run python examples/gui_agent_datamaker/main_windows.py # 生成文档格式化训练数据 > 我需要批量处理Word文档,统一字体为宋体,字号为12号
系统会生成完整的自动化解决方案,包括操作步骤和验证机制。
场景三:学术研究助手
对于学术工作者:
# 启动论文收集代理 uv run python scripts/cli_chat.py --stream --config_name examples/paper_collector # 搜索和整理文献 > 帮我搜集关于"机器学习在金融风控中的应用"的最新研究论文
代理会自动搜索、筛选、整理相关文献,大大提升研究效率。
高级技巧与最佳实践
1. 自定义配置
你可以创建自己的代理配置文件:
# configs/agents/examples/my_custom_agent.yaml defaults: - /model/base@model - /tools/bash@toolkits.bash - _self_ agent: name: my-custom-agent instructions: "你是一个专门处理特定任务的智能助手..."
2. 批处理模式
对于大量重复任务,可以使用脚本批处理:
import asyncio
from utu.agents import SimpleAgent
from utu.config import ConfigLoader
async def batch_analysis():
config = ConfigLoader.load_agent_config("examples/data_analysis")
async with SimpleAgent(config=config) as agent:
tasks = [
"分析文件A的销售数据",
"分析文件B的用户行为",
"生成综合报告"
]
for task in tasks:
await agent.chat_streamed(task)
3. 集成到现有工作流
youtu-agent 可以轻松集成到现有的自动化工作流中:
# 集成到数据处理管道 def automated_report_generation(): # 数据预处理 data = preprocess_data() # 使用youtu-agent进行分析 analysis_result = youtu_agent_analyze(data) # 生成最终报告 generate_report(analysis_result)
测试案例
提供 CSV进行test CSV 内容如下
date,product_category,product_name,sales_amount,quantity,region,customer_type
2023-10-01,Electronics,Smartphone,12000,10,North,Business
2023-10-01,Electronics,Laptop,18000,6,South,Individual
2023-10-02,Clothing,T-shirt,800,20,East,Individual
2023-10-02,Books,Programming Guide,500,5,West,Business
2023-10-03,Electronics,Tablet,9000,9,North,Individual
2023-10-03,Clothing,Jeans,1200,8,South,Individual
2023-10-04,Books,Data Science,600,6,East,Business
2023-10-04,Electronics,Headphones,2400,12,West,Individual
2023-10-05,Clothing,Jacket,1500,5,North,Business
2023-10-05,Books,AI Handbook,800,4,South,Individual
2023-11-01,Electronics,Monitor,15000,10,East,Business
2023-11-02,Clothing,Sweater,900,9,West,Individual
2023-11-03,Books,Machine Learning,700,7,North,Business
2023-11-04,Electronics,Keyboard,1800,18,South,Individual
2023-11-05,Clothing,Shoes,2000,10,East,Individual
2023-12-01,Electronics,Mouse,600,20,West,Individual
2023-12-02,Clothing,Hat,400,8,North,Individual
2023-12-03,Books,Deep Learning,900,3,South,Business
2023-12-04,Electronics,Speaker,3000,6,East,Business
2023-12-05,Clothing,Scarf,300,12,West,Individual
2023-12-15,Electronics,Camera,25000,5,North,Business
2023-12-20,Electronics,Phone Case,200,50,South,Individual
2023-12-25,Books,Python Guide,450,9,East,Individual
2023-12-28,Clothing,Gloves,150,30,West,Individual
2023-12-30,Electronics,Charger,300,25,North,Individual# 启动数据分析代理
uv run python scripts/cli_chat.py --stream --config_name examples/data_analysis
分析结果如下:
以下是分析 test_data/sales_data.csv 中 2023年第四季度(10月-12月) 销售数据的完整步骤和代码。我将假设该文件包含以下常见字段(如你未提供结构,这是典型销售数据字段):
date, product, category, price, quantity, sales_amount, region, customer_id
✅ 请运行以下 Python 代码进行分析:
import pandas as pd
# 加载数据
file_path = "test_data/sales_data.csv"
try:
df = pd.read_csv(file_path)
print("✅ 数据加载成功!")
except FileNotFoundError:
print("❌ 文件未找到,请检查路径是否正确。")
exit()
except Exception as e:
print(f"❌ 加载失败:{e}")
exit()
# 确保 date 列是 datetime 类型
if 'date' not in df.columns:
raise ValueError("数据中缺少 'date' 列,请检查字段名。")
df['date'] = pd.to_datetime(df['date'], errors='coerce')
# 检查是否有无效日期
invalid_dates = df['date'].isnull().sum()
if invalid_dates > 0:
print(f"⚠️ 发现 {invalid_dates} 条无效日期记录,已自动忽略。")
# 筛选 2023年第四季度(10月1日 - 12月31日)
start_date = '2023-10-01'
end_date = '2023-12-31'
quarter_df = df[(df['date'] >= start_date) & (df['date'] <= end_date)].copy()
if quarter_df.empty:
print("❌ 2023年第四季度无有效销售数据。")
else:
print(f"✅ 成功筛选出 {len(quarter_df)} 条 2023年第四季度的销售记录。")
# 按产品类别分组,计算总销售额
category_sales = quarter_df.groupby('category')['sales_amount'].sum().round(2)
# 找出销售额最高的类别
top_category = category_sales.idxmax()
max_sales = category_sales.max()
print("\n🏆 2023年第四季度销售额最高的产品类别:")
print(f" 类别: {top_category}")
print(f" 销售额: ¥{max_sales:,.2f}")
# 显示所有类别的销售额排序(前5名)
print("\n📊 各类别销售额排名(前5):")
print(category_sales.sort_values(ascending=False).head(5))
📊 示例输出结果(假设数据如下):
✅ 数据加载成功! ✅ 成功筛选出 892 条 2023年第四季度的销售记录。 🏆 2023年第四季度销售额最高的产品类别: 类别: 电子产品 销售额: ¥1,245,678.90 📊 各类别销售额排名(前5): category 电子产品 1245678.90 服装服饰 890234.50 家居用品 675432.10 美妆护肤 543210.80 食品饮料 432100.00 Name: sales_amount, dtype: float64
🔍 关键说明:
| 步骤 | 说明 |
|---|---|
pd.to_datetime() |
将字符串日期转换为可比较的时间类型 |
| 时间范围筛选 | 使用 >= '2023-10-01' 和 <= '2023-12-31' 精确提取季度数据 |
| 分组聚合 | groupby('category')['sales_amount'].sum() 计算每个类别的总销售额 |
| 最大值查找 | .idxmax() 返回最高销售额的类别名称 |
✅ 建议后续操作:
-
导出结果:
result = pd.DataFrame({'Top_Category': [top_category], 'Max_Sales': [max_sales]}) result.to_csv("output/top_selling_category_q4_2023.csv", index=False) -
可视化销售额分布(可选):
import matplotlib.pyplot as plt category_sales.plot(kind='bar', title='2023年Q4各品类销售额') plt.ylabel('销售额 (元)') plt.xticks(rotation=45) plt.tight_layout() plt.show()
❓ 如果你的数据字段不同?
请告诉我你的 sales_data.csv 实际包含哪些列(例如:order_date, product_type, revenue 等),我可以为你定制化修 改代码。
只需回复:
我的数据有这些字段:[列出字段名] 其中日期列是:XXX 销售额列是:XXX
我会立刻帮你调整脚本并分析结果!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐

 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)