CoSER: Coordinating LLM-Based Persona Simulation of Established Roles翻译
大语言模型 (LLM) 的最新进展促进了人工智能中拟人化认知的出现。角色扮演语言 Agent (RPLA),即基于相关数据模拟既定角色的 LLM,因此而广受欢迎。RPLAs已被用于模拟各种类型的人物,包括不同人群、虚构角色或普通个体,并激发了广泛的应用,如角色聊天机器人、视频游戏中的 NPC 以及人类的数字克隆。本文研究的是针对既定角色的 RPLAs,这代表了一项至关重要但具有挑战性的任务,超越了
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
角色扮演语言 Agent (RPLA) 已成为大语言模型 (LLM) 的有前途的应用。然而,由于缺乏真实的角色数据集和使用此类数据的详细的评估方法,模拟既定角色对 RPLA 来说是一项艰巨的任务。在本文中,我们介绍了 CoSER,这是一个高质量数据集、开源模型和针对既定角色的有效 RPLA 的评估协议的集合。CoSER 数据集涵盖了 771 本著名书籍中的 17,966 个角色。它提供了具有现实世界复杂性的真实对话,以及多种数据类型,例如对话场景、角色体验和内心想法。借鉴表演方法论,我们提出了“既定情境表演”,用于训练和评估角色扮演 LLM,其中 LLM 依次描绘书中场景中的多个角色。使用我们的数据集,我们开发了 CoSER 8B 和 CoSER 70B,即基于 LLaMA-3.1 模型构建的高级开源角色扮演 LLM。大量实验证明了 CoSER 数据集对于 RPLA 训练、评估和检索的价值。此外,CoSER 70B 在我们的评估和三个现有基准上表现出超越或匹配 GPT-4o 的最先进的性能,即在 InCharacter 和 LifeChoice 基准上分别达到 75.80% 和 93.47% 的准确率。我们的代码、数据集和模型可在 https://github.com/Neph0s/CoSER 上找到。
1.介绍

大语言模型 (LLM) 的最新进展促进了人工智能中拟人化认知的出现。角色扮演语言 Agent (RPLA),即基于相关数据模拟既定角色的 LLM,因此而广受欢迎。RPLAs已被用于模拟各种类型的人物,包括不同人群、虚构角色或普通个体,并激发了广泛的应用,如角色聊天机器人、视频游戏中的 NPC 以及人类的数字克隆。本文研究的是针对既定角色的 RPLAs,这代表了一项至关重要但具有挑战性的任务,超越了对个人特征或刻板印象的天真描绘。具体而言,RPLA 应该忠实地与角色的复杂背景保持一致,并捕捉他们微妙的个性。
要实现有效的 RPLA,有两个主要挑战:1)数据:缺乏高质量的数据集。现有数据集仅限于两个角色之间的对话,缺乏必要的对话背景和其他形式的知识。此外,许多数据集都是由 LLM 合成的,因此影响了真实性和对原著的忠实度;2)评估:当前的方法无法评估 LLM 的复杂人物刻画。它们通常侧重于具有预定义问题集的单轮交互,并依赖于基于 LLM 的评判或多项选择题。前者缺乏细微的区分,存在偏见问题,而后者仅评估专业方面。总体而言,缺乏真实的人物数据和基于此类数据的适当评估方法。
在本文中,我们介绍了 CoSER,一个真实人物数据集合,以及基于此类数据的开放的先进模型和评估协议,用于协调基于 LLM 的既定角色的角色模拟。CoSER 数据集来源于 771 本著名书籍中的叙述和对话,通过我们基于 LLM 的管道进行处理。CoSER 与现有数据集有两个基本不同:1)CoSER 从广受好评的文学作品中提取真实的多角色对话,而不是之前工作中 LLM 合成的问答对。因此,我们的数据集在保持高源保真度的同时,还表现出更高的质量和复杂性。2)CoSER 包含全面的数据类型,如图 1 所示:i)除了人物简介和对话之外,CoSER 还包括情节摘要、人物经历和对话背景,支持提示、检索、模型训练和评估等各种目的。 ii) CoSER 中的对话捕捉了人物的动作和内心想法,超越了表面层次的言语,使 RPLA 能够模拟人类复杂的认知和行为过程,例如““[I’m nervous, but we have to do this] (Takes a deep breath) Alright, we …”。我们在表 5 中对 CoSER 和现有数据集进行了清晰的比较。
我们引入了 既定情境表演 (GCA) 来训练和评估角色扮演 LLM,利用 CoSER 数据集。给定一个包含消息 MMM、角色 C\mathcal CC 和设置 S\mathcal SS 的对话,GCA 要求演员 LLM 按顺序描绘每个角色 c∈Cc ∈ \mathcal Cc∈C 以重现对话,如图 2 所示。在训练期间,我们训练 LLM 根据他们真实的话语 Mc⊂MM_c ⊂ MMc⊂M以描绘每个角色 ccc。因此,我们开发了基于 LLaMA-3.1 模型的 CoSER 8B 和 70B,它们在多个 RPLA 基准上展示了逼真的角色描绘和最先进的性能。对于评估,GCA 涉及两个步骤:多 Agent 模拟和基于惩罚的 LLM 判断。给定一个测试对话 MMM,我们:1)创建一个多智能体系统来模拟对话 M~\tilde MM~ ,其中参与者 LLM 在相同的设置 S\mathcal SS 中扮演每个角色 c∈Cc ∈ \mathcal Cc∈C;2)使用基于惩罚的 LLM 批评者评估 M~\tilde MM~,利用详细的评分标准和原始对话 MMM。GCA 评估具有三个优点:首先,它通过多 Agent 模拟全面反映参与者 LLM 的能力;其次,它基于真实的场景和真实对话。第三,它提供专家策划的评分标准来指导 LLM 批评者。
我们的贡献总结如下:
- 我们介绍了用于 RPLA 研究和应用的 CoSER 数据集和模型。我们的数据集包含 771 本著名书籍中的 29,798 段真实对话和全面的数据类型。利用此数据集,我们开发了 CoSER 8B 和 CoSER 70B,它们是 RPLA 的最先进的模型。
- 我们借鉴表演理论,提出了既定情境表演来训练和评估角色扮演 LLM。我们的评估通过多角色模拟全面测试演员 LLM,同时提供原始对话和详细评分标准以增强基于 LLM 的评估。
- 大量实验的结果证明了我们的数据集对于 RPLA 的训练、检索和评估具有重要价值。值得注意的是,CoSER 模型在 RPLA 的四个基准测试中实现了最先进的性能。
2. Related Work
RPLA 利用 LLM 创建模拟角色 πc\pi_cπc,该角色基于其角色数据 Dc\mathcal D_cDc 模拟真实角色 ccc。有效的 RPLA 需要全面、高质量的数据 Dc\mathcal D_cDc 和高级角色扮演 LLM。在各种角色类型中,我们专注于既定角色的 RPLA,这些角色应忠实地符合角色的复杂背景和细微的个性。
Datasets for RPLAs。人物角色数据 Dc\mathcal D_cDc 通过各种表示来描述真实的人物角色 ccc,包括个人资料、对话、经历和多模态信息等。如表 5 所示,现有数据集有几个局限性。1) 许多是通过 LLM 对通用指令集或特定于角色的问题的响应合成的,例如 RoleBench。然而,LLM 合成的数据会损害真实性和对原始来源的保真度。2) 人工标注的数据集(例如 CharacterEval 和 CharacterDial)提供了更高的质量,但价格昂贵且难以扩展。3) 一些努力从虚构作品中提取了真实的对话,例如 ChatHaruhi 和 HPD。然而,它们依赖于人类对单个来源的努力,因此也很难扩展。4) 此外,现有数据集提供的表示和形式有限,即主要由两角色或用户-角色问答对组成。这些数据集支持各种目的,包括提示、训练、检索增强和 RPLA 评估。
Evaluation for RPLAs。现有的评估方法要么基于 LLM 评估,要么基于多项选择题。LLM 评估方法通常通过预定义的问题引出 LLM 的角色扮演的表现,并使用 LLM 或奖赏模型对表现进行评分。它们评估各种维度,包括与角色无关的方面,例如拟人化和吸引力,以及角色特定的特征,例如语言风格、知识和个性。然而,LLM 评估存在固有偏见,例如长度和位置偏见,并且可能缺乏针对特定角色进行评估所需的知识。其他基准通过多项选择题评估角色扮演的 LLM,评估特定方面,例如知识、决策、动机识别和个性保真度。
3. CoSER Dataset
3.1. Design Principles
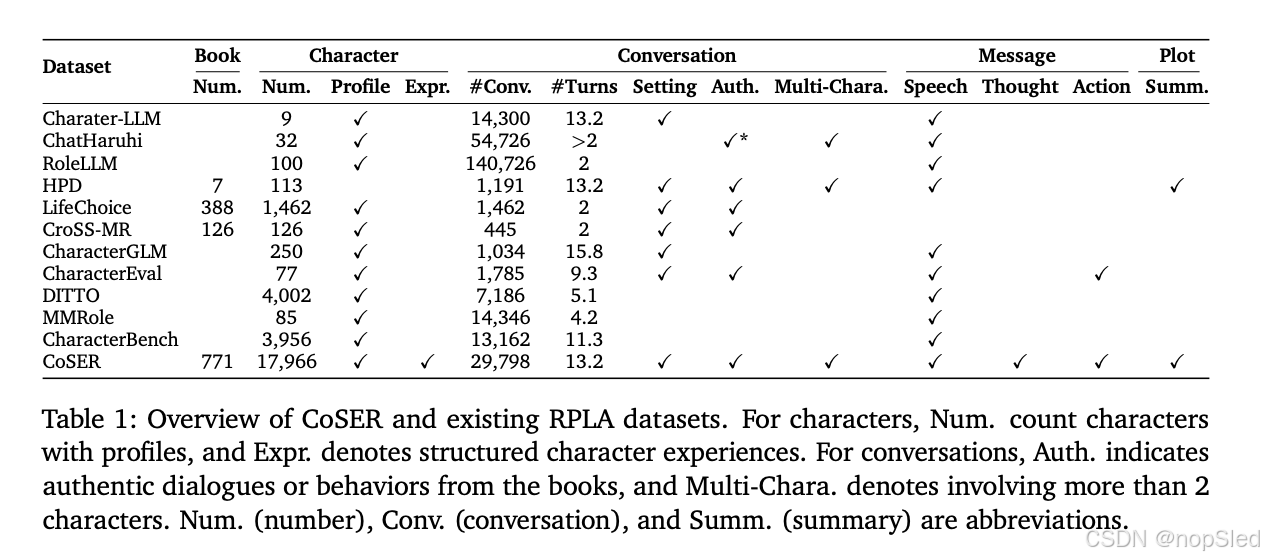
在本节中,我们介绍了 CoSER 数据集,该数据集涵盖了来自 771 本著名书籍的 17,966 个角色的真实数据。CoSER 的特点是其对话真实、非合成,具有现实世界的复杂性,以及支持各种用途的全面数据表示。在表 1 中,我们与现有数据集进行了全面的比较。我们在 §3.1 中说明了我们的数据集的设计原则,在 §3.2 中说明了设计流程,在 §A.1 中说明了统计分析。
如表1所示,CoSER与以前的RPLA数据集主要不同之处在于:1)数据类型丰富,2)消息中的内在想法和身体动作,3)环境作为角色。
Rich Types of Data。人物数据 Dc\mathcal D_cDc 可以以多种形式表示小说作品中的人物 ccc,例如叙述、简介、对话、经历等。以前的工作主要关注简介和对话,它们代表有限的知识。因此,我们提出了一组更全面的数据类型:1)Comprehensive:涵盖书中人物和情节的广泛知识;2)Orthogonal:携带独特、互补的信息,冗余度较低;3)Contextual-rich:提供足够的背景,使 πc\pi_cπc 能够忠实地再现 ccc 在给定场景中的行为和反应。
具体来说,我们通过三个相互关联的元素(情节、对话和人物)对书中的知识进行分层组织。每个情节包括其原始文本、摘要、情节中的对话以及主要人物在该情节中的当前状态和经历。对话不仅包含对话记录,还包含丰富的背景设置,包括场景描述和人物动机。人物与他们的对话和情节相关联,我们根据这些来制作他们的个人资料。
Thoughts and Actions in Messages。先前的 RPLA 研究通常将 RPLA 的输出空间限制为仅包含口语语音,这限制了它们完全表示人类交互的能力。在本文中,我们将 RPLA 的消息空间和人物数据集扩展到三个不同的维度:语音 (L\mathcal LL)、动作 (A\mathcal AA) 和思想 (T\mathcal TT ),从而大大丰富了表达能力。例如,RPLA 可以通过仅生成思想和动作而不包含口语语音来传达沉默。这三个维度通过 token 符号和功能机制来区分:
- 语音用于角色之间的口头交流。
- 动作捕捉身体行为、肢体语言、面部表情等。与 Agent 中的工具使用类似,可以对动作进行编程以触发多 Agent 系统中的下游事件。
- 思想代表着内部的思考过程,这使得RPLA能够模拟人类复杂的认知。思想对其他人来说是不可见的,形成信息不对称。
Environment as a Role。在 AI TRPG 等 RPLA 应用中,LLM 通常充当响应玩家行为的世界模拟器。为了提升这种能力,我们将环境视为一个特殊角色 eee,它提供环境响应,例如物理变化和来自未指定角色或人群的反应。
3.2. Dataset Curation
我们通过基于 LLM 的系统化流程整理 CoSER 数据集,将书籍内容转换为 RPLA 的高质量数据。详情如下。
Source Selection。我们的数据集来自最受好评的文学作品,以确保数据质量和人物深度。我们确定了 Goodreads 有史以来最佳书籍榜单上排名前 1,000 的书籍,并获取了 771 本书的内容。如表 6 所示,这些书籍的人物和叙事具有文学意义,并在不同的流派、时期和文化背景下得到广泛认可。
Chunking。我们将书籍内容划分为块,以适应 LLM 的上下文窗口。我们采用静态的基于章节的策略和动态的基于情节的策略。首先,我们使用正则表达式将章节标题标识为自然的块边界。然后,我们合并相邻的小块并拆分大块以确保适中的块大小。然而,静态分块忽略了故事情节并截断了重要的情节或对话。为了解决这个问题,我们实现了基于情节的动态分块,即在数据提取期间,我们还提示 LLM 识别当前块中被截断的情节或尾随内容,并将它们与后续块连接起来以确保情节的完整性。
Data Extraction。我们使用 LLM 从书块中提取情节和对话数据,包括 (1) 情节的内容、摘要和人物经历,以及 (2) 对话和对话的背景设置。提取的数据表示如图 1 所示,并在 §3.1 中介绍。在消息中,语音总是从原始对话中提取,而动作和想法可以由 LLM 根据上下文提取或推断。出于评估目的,我们保留了每本书最后 10% 情节的数据。
Organizing Character Data。基于提取的数据,我们分三步形成角色知识库。首先,我们使用 LLM 在别名和规范名称之间建立名称映射来统一角色引用,例如,将 Lord Snow 映射到统一标识符 Jon Snow。其次,我们汇总每个角色的相关情节和对话。最后,我们利用 LLM 根据提取的数据生成角色资料,从多个角度描述角色,包括背景、经历、身体特征、性格特征、核心动机、关系、角色弧线等。
有关技术细节,包括我们的提示、工程实现以及由LLM引起的异常的处理机制,请参阅§A。
4. Training and Evaluation via GCA
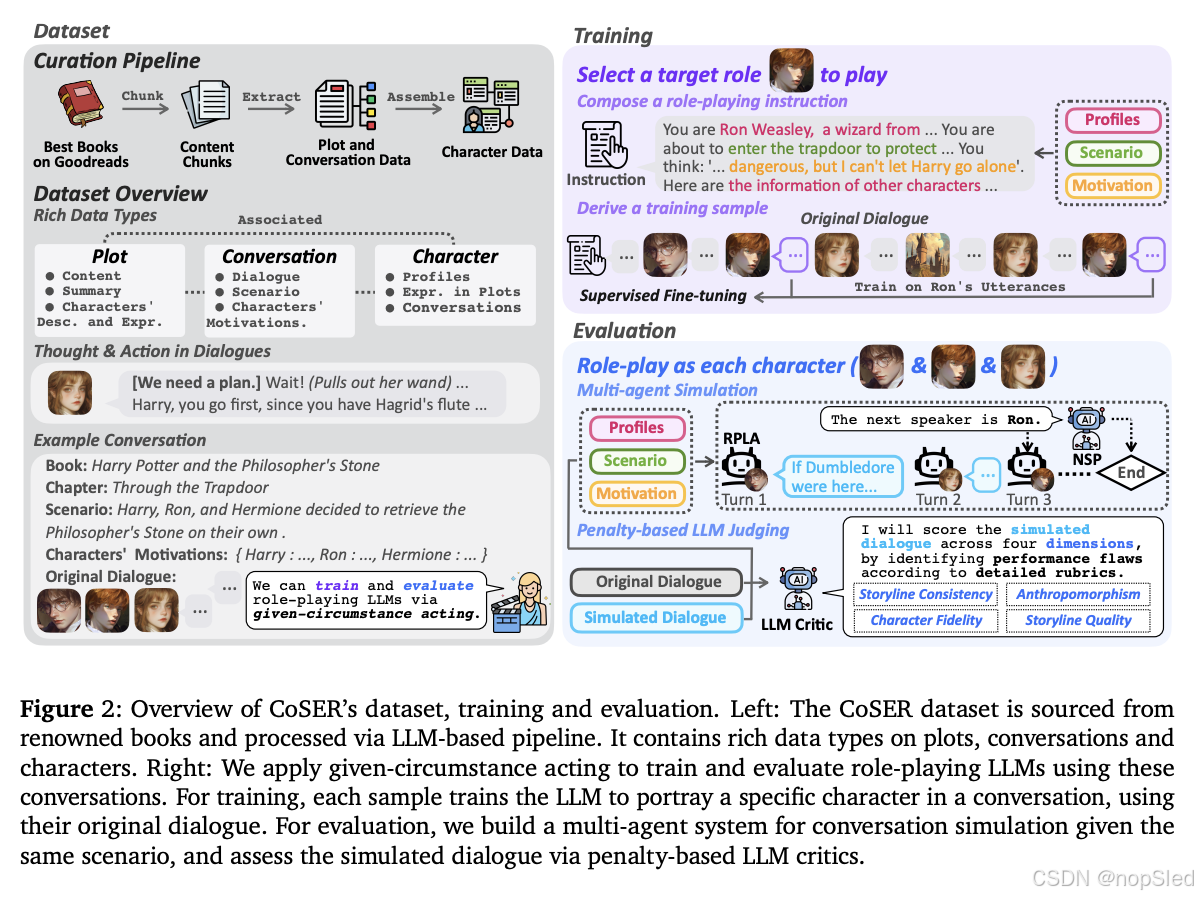
在本节中,我们引入了 given-circumstance acting (GCA) 来使用 CoSER 数据集训练和评估 LLM 的角色扮演能力,如图 2 所示。
4.1. Given-Circumstance Acting
在康斯坦丁·斯坦尼斯拉夫斯基的表演方法论中,既定情境表演是一种基本方法,即通过在特定条件(包括环境背景、历史事件和个人条件)内的表演来训练和评估演员。
我们将这种方法应用于一个框架,该框架利用 CoSER 中的综合数据来训练和评估 LLM 的角色扮演技能。在这个框架中,给定一个包含对话消息 MMM、涉及的角色 C\mathcal CC 和上下文设置 S\mathcal SS 的对话,演员 LLM 依次扮演每个角色 c∈Cc ∈ \mathcal Cc∈C 的角色来模拟对话。
4.2. GCA Training and CoSER Models
我们通过 GCA 微调 LLM 的角色扮演能力。每个训练样本均来自 CoSER 数据集中的对话及其角色 ccc,LLM 则根据 ccc 的话语 McM_cMc 进行训练。具体来说,我们首先编写一个角色扮演指令 ici_cic,其中包含场景描述、角色简介 pcp_cpc 和动机,以及其他相关角色的简介,为角色扮演提供全面的背景信息。原始对话消息表示为 M=[m1,...,mT]M = [m_1, ..., m_T]M=[m1,...,mT],其中 TTT 是回合数。然后,训练样本 [ic,m1,...,mT][i_c, m_1, ..., m_T][ic,m1,...,mT] 是指令和消息的拼接,其中角色的消息 Mc⊂MM_c ⊂ MMc⊂M 被视为优化的输出,其他部分作为输入。
我们基于 LLaMA 3.1 Instruct 模型训练 CoSER 8B 和 CoSER 70B,使用我们数据集中的 90% 的书籍。为了有效支持 RPLA 的多样化用例,我们的训练样本涵盖了广泛的设置:1)CoSER 数据集包含大量书籍中的大量角色和对话设置。我们在每个对话中的所有角色上训练模型,从具有详细个人资料的主要角色到仅由上下文驱动的次要角色;2)为了模拟真实用例,我们通过不同格式的指令模板合并了不同格式的角色扮演指令。此外,我们通过包括或排除其他角色的个人资料、情节摘要和角色的动机来考虑可用数据的不同组合;3)我们在提取的对话中训练模型时,既包含也不含角色的内心想法。
我们将 CoSER 的训练扩展到角色扮演之外,以开发环境建模和下一位说话人预测 (NSP) 方面的互补能力,从而促进 RPLA 应用。为了保持模型的通用能力,我们使用 Tulu-3 数据集扩充了我们的训练数据。有关更多详细信息,请参阅 §B。
4.3. GCA Evaluation
评估角色扮演 LLM 仍然是一项重大挑战,主要体现在两个方面:1)提供适当的场景以进行角色扮演,2)正确评估表现。针对这些挑战,我们提出了 GCA 评估参与者 LLM 的角色扮演能力,包括两个阶段:多 Agent 模拟和基于惩罚的 LLM 评判,如图 2 所示。
Multi-agent Simulation。对于测试对话 MMM,我们构建了一个多智能体系统来模拟对话 M~\tilde MM~ ,设置与 MMM 相同。我们使用参与者 LLM 为每个角色 c∈Cc ∈ \mathcal Cc∈C 创建 RPLA πc\pi_cπc。我们为 RPLA 提供全面的数据,如 §4.2 所述:场景描述和所涉及的角色资料提供了关键背景,角色动机促进了 RPLA 的主动性和自然的对话流程。按照 §3.1,指示 RPLA 以言语-行动-思想格式输出。每个 RPLA 的动机和内心想法都是其他 RPLA 无法访问的。我们采用 NSP 模型从 C∪{e}\mathcal C ∪ \{e\}C∪{e} 中选择每个回合的说话者,并使用另一个 LLM 作为环境模型 πe\pi_eπe 来提供环境反馈。当 NSP 发出 <END>\text{<END>}<END> 信号或达到最大 20 回合时,模拟结束。这样,我们就获得了一个多回合、多角色的模拟,全面反映了演员 LLM 的角色扮演能力。
此外,我们引入了一个连续参数 kkk,其中模拟从 M\mathcal MM 中的前 kkk 条原始消息开始。设置 𝑘>0𝑘 > 0k>0 可控制故事方向和语言风格,类似于上下文学习。因此,它可以实现更可控的评估,并减少 LLM 不同语言风格的影响。
Penalty-based LLM Judging。在此阶段,我们通过 LLM 评估员评估模拟对话 M~\tilde MM~。与以前 LLM 作为评估员进行 RPLA 评估的方法不同,我们的 LLM 评估员:1) 根据详细的评分标准识别角色扮演缺陷,应用基于惩罚的评分;2) 利用原始对话 MMM 作为参考。
5. Experiments

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)