面向边缘通用智能的多大语言模型系统:架构、信任与编排——论文阅读
本文探讨了边缘计算环境下实现通用智能的新范式——多大语言模型(Multi-LLM)系统。传统边缘AI依赖专用窄域模型,存在任务单一、泛化不足等局限。而大语言模型展现出类人智能的通用能力,但其边缘部署面临计算资源、能耗等挑战。研究提出通过多LLM协作架构,结合合作、竞争和集成三种机制,形成优势互补。数学建模显示,该系统能分解任务、优化响应质量,并通过博弈论框架减少偏见和幻觉。实验证明,Multi-L
面向边缘通用智能的多大语言模型系统:架构、信任与编排
Luo H, Liu Y, Zhang R, et al. Toward edge general intelligence with multiple-large language model (Multi-LLM): architecture, trust, and orchestration[J]. IEEE Transactions on Cognitive Communications and Networking, 2025.
引言:从边缘智能到通用智能的范式转变
边缘计算作为一种将计算资源推向网络边缘的分布式计算范式,通过在数据源附近进行处理,显著降低了计算数据交换相关的延迟和带宽使用。这种架构优势对于交通管理、应急响应和自主导航等时间敏感的智能应用而言至关重要。然而传统的边缘人工智能系统主要依赖于专门的窄域模型,每个模型都针对特定任务进行设计和优化,例如目标检测模型专注于识别图像中的物体,交通预测模型专门分析道路流量模式。
这些传统模型虽然在其目标问题上表现出色,但本质上缺乏处理现代城市和空中生态系统等日益复杂动态环境所需的灵活性和通用推理能力。它们的局限性体现在几个方面:首先是任务特异性,每个模型只能执行其训练时设定的特定任务,无法跨域迁移;其次是泛化能力不足,模型难以处理训练分布之外的情况;再次是缺乏推理能力,这些模型无法进行复杂的因果推理或多步骤决策。
与此形成鲜明对比的是,大语言模型展现出了令人瞩目的类人智能水平。这些基于Transformer架构的模型在理解、生成和推理自然语言及多模态数据方面表现出色。它们的通用智能特性源于在海量预训练数据上学习到的广泛知识表示,使其能够在无需针对性重新训练的情况下执行各种任务。这种能力对于需要多样性和适应性的边缘应用极具吸引力,从而催生了边缘通用智能的概念。
边缘通用智能是指让边缘节点(包括物联网设备、车辆、无人机和城市基础设施)获得增强的上下文感知能力、推理能力和多模态交互能力。这种演进使得更智能、更自主和更具适应性的服务能够直接在边缘提供,减少了对云连接的依赖并加速了决策过程。然而在边缘部署大语言模型引入了独特的挑战,包括有限的设备计算资源(边缘设备通常只有几GB的内存和有限的处理能力)、能量约束(许多边缘设备依赖电池供电)以及与云端交互的高通信开销。
为了缓解这些困难,研究者开发了一系列解决方案。模型压缩技术如剪枝、量化和知识蒸馏被采用来减少模型大小和推理复杂度。能量感知的推理、调度和动态模型调用策略被设计来合理分配任务并延长设备电池寿命。边缘本地推理增强和边缘云协同计算方法被提出来处理高通信开销。
然而即便如此,单个大语言模型在边缘应用中仍然暴露出关键局限。不同的大语言模型由于训练数据、语言或专业领域的差异,可以相互补充。对同一查询的响应往往因模型的不同训练语料库和模型偏差而存在差异。单个大语言模型在适应异构上下文时面临困难,例如专注于交通管理的大语言模型可能无法处理医疗查询。此外如果训练数据有限,单个大语言模型可能遭受知识过时或产生幻觉的问题。
多大语言模型系统被提出作为推动边缘通用智能前沿的方法。通过让多个大语言模型作为集合或网络协作,我们可以结合它们的优势并缓解个体弱点。例如Wang等人利用一个大语言模型池(包括GPT-3.5、GPT-4、LLaMA变体等)来共同生成全面的养老护理计划,在主题覆盖范围上优于任何单一模型。研究者还开始探索多大语言模型系统来模拟"群体智能",其中基于大语言模型的代理讨论或投票决定答案以提高可靠性。这也被视为多代理系统的先决基础。
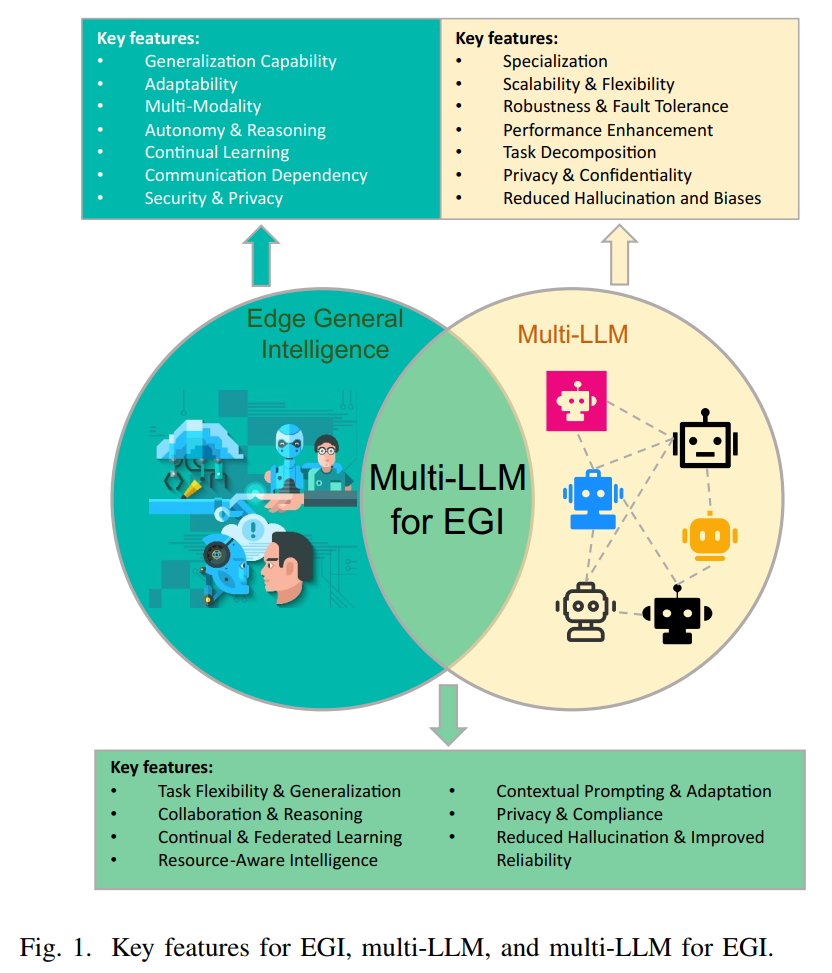
图1解读:论文第2页的图1清晰展示了边缘通用智能、多大语言模型以及面向边缘通用智能的多大语言模型三者的关键特征对比。图中采用三个相互交叠的圆形区域表示这三个概念及其关系。左侧的深蓝色圆圈代表边缘通用智能,列出了泛化能力、适应性、多模态处理、自主性与推理、持续学习、通信依赖性、安全与隐私等关键特征。右上方的黄色圆圈代表多大语言模型,强调了专业化、可扩展性与灵活性、鲁棒性与容错能力、性能增强、任务分解、隐私与保密性、减少幻觉和偏见等优势。底部的绿色交叠区域则代表面向边缘通用智能的多大语言模型系统,综合了任务灵活性与泛化、协作与推理、持续与联邦学习、资源感知智能、上下文提示与适应、隐私与合规、减少幻觉与提高可靠性等特性。这个三圆交叠的设计巧妙地展示了多大语言模型如何成为实现边缘通用智能的关键技术路径。
多大语言模型的理论基础与协作机制
多大语言模型系统的数学形式化
从数学角度来看,多大语言模型系统可以形式化为一个由NNN个大语言模型组成的集合M={M1,M2,…,MN}\mathcal{M} = \{M_1, M_2, \ldots, M_N\}M={M1,M2,…,MN}。每个模型MiM_iMi可以表示为一个条件概率分布:
Mi:X→P(Y)M_i: \mathcal{X} \rightarrow \mathcal{P}(\mathcal{Y})Mi:X→P(Y)
其中X\mathcal{X}X是输入空间(提示、上下文等),Y\mathcal{Y}Y是输出空间(生成的文本、决策等),P(Y)\mathcal{P}(\mathcal{Y})P(Y)是Y\mathcal{Y}Y上的概率分布。给定输入x∈Xx \in \mathcal{X}x∈X,模型MiM_iMi生成输出yiy_iyi的概率为:
P(yi∣x,Mi)=∏t=1TP(yi,t∣yi,<t,x,Mi)P(y_i | x, M_i) = \prod_{t=1}^{T} P(y_{i,t} | y_{i,<t}, x, M_i)P(yi∣x,Mi)=t=1∏TP(yi,t∣yi,<t,x,Mi)
其中yi,ty_{i,t}yi,t表示第ttt个生成的token,yi,<ty_{i,<t}yi,<t表示前t−1t-1t−1个token,TTT是序列长度。
在多大语言模型系统中,关键问题是如何聚合NNN个模型的输出来产生最终响应。这个聚合过程可以表示为一个函数A\mathcal{A}A:
y∗=A({(y1,s1),(y2,s2),…,(yN,sN)})y^* = \mathcal{A}(\{(y_1, s_1), (y_2, s_2), \ldots, (y_N, s_N)\})y∗=A({(y1,s1),(y2,s2),…,(yN,sN)})
其中yiy_iyi是第iii个模型的输出,sis_isi是对应的置信度分数或质量度量,y∗y^*y∗是最终输出。
三种核心协作范式的深度分析
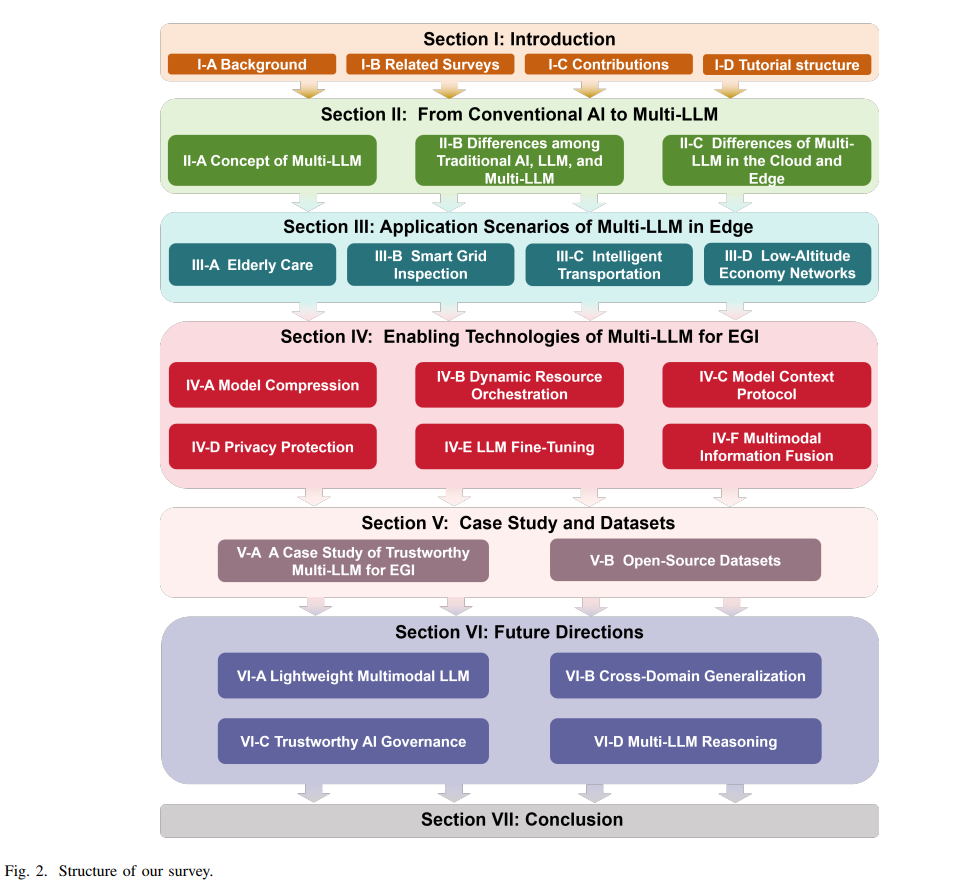
图2详细解读:论文第4页的图2是理解多大语言模型协作机制的关键。该图采用自上而下的层次结构,顶部是"从传统AI到多大语言模型"的总标题。第一层展示了"多大语言模型概念",通过三个并列的模块说明了协作方法:合并(Merge)、集成(Ensemble)和协作(Cooperate)。图的中间部分列出了传统AI、单一大语言模型和多大语言模型三种范式的差异。最底层详细阐述了多大语言模型的应用场景,包括养老护理、智能电网检查、智能交通和低空经济网络四个典型场景。整个图表通过颜色编码(蓝色表示概念层,绿色表示对比层,橙色表示应用层)清晰地展示了多大语言模型系统的理论框架和实践价值。
合作协同模式的数学建模
合作协同描述了多个大语言模型以一致目标协同工作的场景,通常通过任务分解或互补优势来增强整体性能。这种范式可以通过任务分解函数来建模:
T(x)={t1,t2,…,tK}\mathcal{T}(x) = \{t_1, t_2, \ldots, t_K\}T(x)={t1,t2,…,tK}
其中T\mathcal{T}T将输入任务xxx分解为KKK个子任务。每个子任务tkt_ktk被分配给最适合的模型MikM_{i_k}Mik:
ik=argmaxi∈{1,…,N}Score(Mi,tk)i_k = \arg\max_{i \in \{1,\ldots,N\}} \text{Score}(M_i, t_k)ik=argi∈{1,…,N}maxScore(Mi,tk)
其中Score(Mi,tk)\text{Score}(M_i, t_k)Score(Mi,tk)衡量模型MiM_iMi处理子任务tkt_ktk的适配度。最终输出通过组合各子任务的结果获得:
y∗=C({(t1,yi1),(t2,yi2),…,(tK,yiK)})y^* = \mathcal{C}(\{(t_1, y_{i_1}), (t_2, y_{i_2}), \ldots, (t_K, y_{i_K})\})y∗=C({(t1,yi1),(t2,yi2),…,(tK,yiK)})
其中C\mathcal{C}C是组合函数,负责整合各个子任务的输出。
Owens等人的研究实现了中心化和去中心化对话框架,使多个大语言模型能够通过通信来集体减少偏见并增强公平性。在他们的框架中,偏见检测可以建模为:
Bias(y)=EM∈M[d(y,yfair)]\text{Bias}(y) = \mathbb{E}_{M \in \mathcal{M}} [d(y, y_{\text{fair}})]Bias(y)=EM∈M[d(y,yfair)]
其中d(⋅,⋅)d(\cdot, \cdot)d(⋅,⋅)是偏差度量,yfairy_{\text{fair}}yfair是理想的无偏响应。系统通过最小化这个偏差来优化输出。
竞争对抗模式的博弈论视角
竞争对抗模式引入了模型之间的竞争或对抗动态。这可以用博弈论框架来描述。考虑一个NNN人非合作博弈,其中每个模型MiM_iMi的策略空间是其可能的输出Yi\mathcal{Y}_iYi,效用函数ui(y1,…,yN)u_i(y_1, \ldots, y_N)ui(y1,…,yN)衡量给定所有模型输出时模型iii的收益。
在对抗性辩论框架中,模型可以视为不同答案的"倡导者"或辩论者,他们迭代地批评彼此的推理。这个过程可以建模为一个多轮博弈,第rrr轮的状态为:
s(r)=(y1(r),y2(r),…,yN(r),c1(r),c2(r),…,cN(r))s^{(r)} = (y_1^{(r)}, y_2^{(r)}, \ldots, y_N^{(r)}, c_1^{(r)}, c_2^{(r)}, \ldots, c_N^{(r)})s(r)=(y1(r),y2(r),…,yN(r),c1(r),c2(r),…,cN(r))
其中yi(r)y_i^{(r)}yi(r)是模型iii在第rrr轮的输出,ci(r)c_i^{(r)}ci(r)是其置信度。更新规则为:
yi(r+1)=Mi(x,{yj(r),cj(r)}j≠i)y_i^{(r+1)} = M_i(x, \{y_j^{(r)}, c_j^{(r)}\}_{j \neq i})yi(r+1)=Mi(x,{yj(r),cj(r)}j=i)
即每个模型根据其他模型的当前输出和置信度来更新自己的响应。这个迭代过程持续直到达到纳什均衡或满足某个停止条件。
Feng等人利用这种方法,使多个大语言模型能够对抗性地批评不确定响应,缓解幻觉并提高答案保真度。他们的置信度估计可以表示为:
ci=σ(1N−1∑j≠iAgreement(yi,yj))c_i = \sigma\left(\frac{1}{N-1}\sum_{j \neq i} \text{Agreement}(y_i, y_j)\right)ci=σ N−11j=i∑Agreement(yi,yj)
其中σ\sigmaσ是sigmoid函数,Agreement(⋅,⋅)\text{Agreement}(\cdot, \cdot)Agreement(⋅,⋅)衡量两个输出之间的一致性。
集成整合模式的统计学原理
集成方法是一种经典的机器学习技术,已被改编应用于大语言模型。多个模型并行运行于同一任务,各自独立生成答案,然后通过预定义的聚合机制合成这些结果。目标是利用每个模型的个体优势并抵消它们的独立错误,从而提高整体准确性或可靠性。
最简单的集成策略是投票。对于分类任务,最终预测通过多数投票获得:
y∗=argmaxy∈Y∑i=1N1[yi=y]y^* = \arg\max_{y \in \mathcal{Y}} \sum_{i=1}^{N} \mathbb{1}[y_i = y]y∗=argy∈Ymaxi=1∑N1[yi=y]
其中1[⋅]\mathbb{1}[\cdot]1[⋅]是指示函数。对于生成任务,可以使用加权投票,其中每个模型的贡献由其置信度或历史性能加权:
y∗=argmaxy∈Y∑i=1Nwi⋅1[yi=y]y^* = \arg\max_{y \in \mathcal{Y}} \sum_{i=1}^{N} w_i \cdot \mathbb{1}[y_i = y]y∗=argy∈Ymaxi=1∑Nwi⋅1[yi=y]
其中wiw_iwi是模型MiM_iMi的权重,满足∑i=1Nwi=1\sum_{i=1}^{N} w_i = 1∑i=1Nwi=1且wi≥0w_i \geq 0wi≥0。
更复杂的集成方法涉及概率平均。如果每个模型输出概率分布Pi(y∣x)P_i(y|x)Pi(y∣x),集成分布可以计算为:
Pens(y∣x)=∑i=1NwiPi(y∣x)P_{\text{ens}}(y|x) = \sum_{i=1}^{N} w_i P_i(y|x)Pens(y∣x)=i=1∑NwiPi(y∣x)
或者使用几何平均:
Pens(y∣x)∝∏i=1NPi(y∣x)wiP_{\text{ens}}(y|x) \propto \prod_{i=1}^{N} P_i(y|x)^{w_i}Pens(y∣x)∝i=1∏NPi(y∣x)wi
Luo等人设计的加权拜占庭容错共识是一个更高级的集成例子。在这个框架中,权重wiw_iwi不仅基于模型的性能,还基于其可信度:
wi=α⋅qi+β⋅tiw_i = \alpha \cdot q_i + \beta \cdot t_iwi=α⋅qi+β⋅ti
其中qiq_iqi是模型iii的质量分数,tit_iti是其信任值,α+β=1\alpha + \beta = 1α+β=1是平衡参数。这个设计显著增强了高生成能力和高可信度大语言模型的投票权,同时削弱了恶意大语言模型的影响。
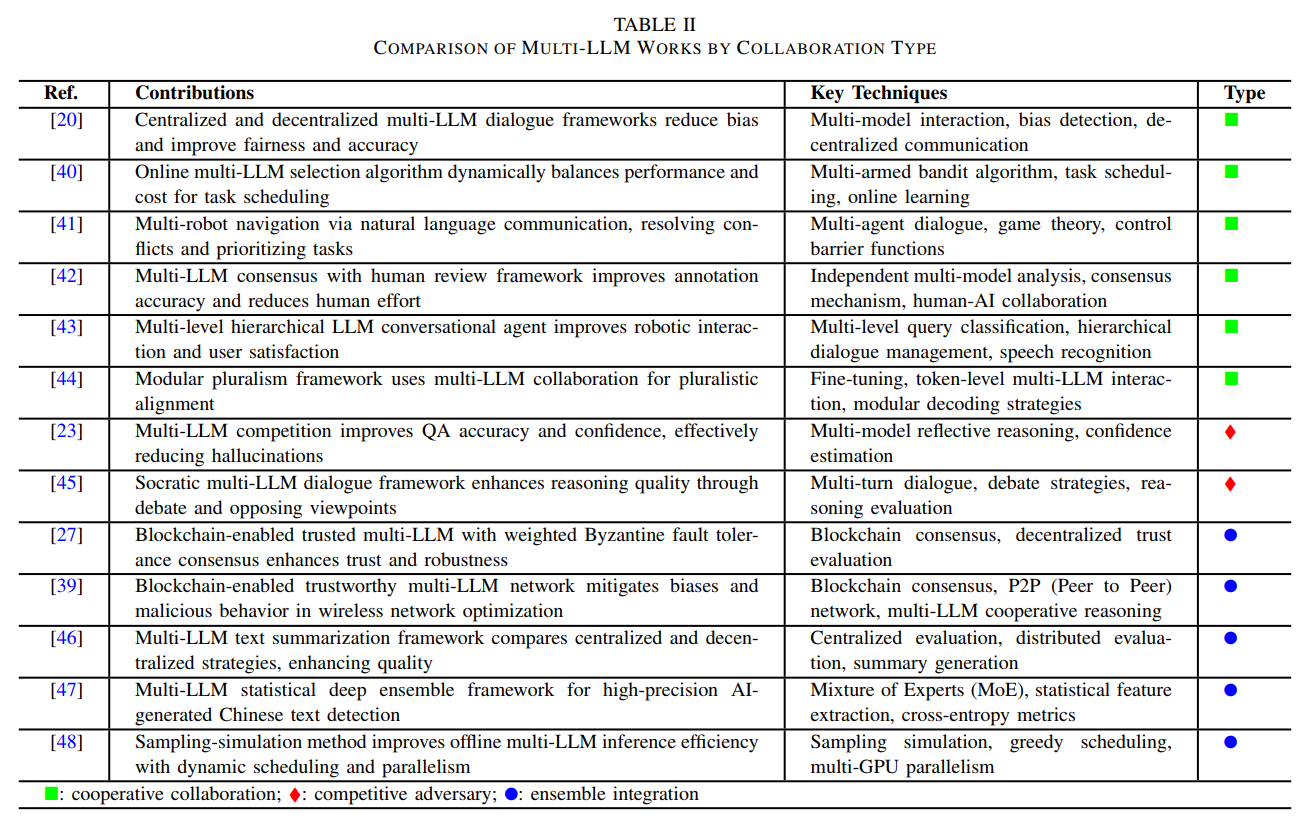
表II详细解读:论文第5页的表II提供了按协作类型对多大语言模型工作进行比较的全面概览。该表采用三列结构:参考文献、贡献和关键技术。表中用三种符号标记协作类型:■表示合作协同,♦表示竞争对抗,●表示集成整合。例如Owens等人的工作使用多模型交互和偏见检测实现了中心化和去中心化的多大语言模型对话框架以减少偏见;Dai等人开发的在线多大语言模型选择算法采用多臂赌博机算法动态平衡性能和成本;Feng等人的多大语言模型竞争通过多模型反思推理和置信度估计改善问答准确性并有效减少幻觉。这个表格清晰地展示了不同协作模式在实际系统中的实现方式和技术特点。
从传统AI到多大语言模型的演进分析
传统AI模型的局限性剖析
传统AI模型包括经典机器学习算法和紧凑型神经网络,为特定任务量身定制。每个模型在明确定义的数据集上训练以执行特定功能,如目标检测、异常检测或信号分类。常见设计包括决策树、支持向量机以及轻量级卷积神经网络或浅层多层感知器。这些模型被选择是因为它们能在资源有限的设备上高效运行。
从数学角度看,传统AI模型可以表示为从输入空间到输出空间的映射f:X→Yf: \mathcal{X} \rightarrow \mathcal{Y}f:X→Y。对于监督学习任务,模型通过最小化经验风险来训练:
f^=argminf∈F1n∑i=1nL(f(xi),yi)+λR(f)\hat{f} = \arg\min_{f \in \mathcal{F}} \frac{1}{n}\sum_{i=1}^{n} L(f(x_i), y_i) + \lambda R(f)f^=argf∈Fminn1i=1∑nL(f(xi),yi)+λR(f)
其中{(xi,yi)}i=1n\{(x_i, y_i)\}_{i=1}^{n}{(xi,yi)}i=1n是训练数据,LLL是损失函数,R(f)R(f)R(f)是正则化项,λ\lambdaλ是正则化参数,F\mathcal{F}F是假设空间。
这种设计理念的核心是保持模型狭窄和针对目标任务优化,使用手工特征或专门的网络架构来最大化目标域内的准确性。然而这些模型的推理和泛化能力是有限的。它们无法推断超出训练分布的情况,也没有能力处理超出狭窄授权范围的任务。这可以用泛化边界来量化。根据统计学习理论,模型的泛化误差可以用Vapnik-Chervonenkis维度dVCd_{VC}dVC来界定:
P(∣Errortrain−Errortrue∣>ϵ)≤2⋅2dVC⋅e−nϵ28P(|\text{Error}_{\text{train}} - \text{Error}_{\text{true}}| > \epsilon) \leq 2 \cdot 2^{d_{VC}} \cdot e^{-\frac{n\epsilon^2}{8}}P(∣Errortrain−Errortrue∣>ϵ)≤2⋅2dVC⋅e−8nϵ2
对于固定的dVCd_{VC}dVC(即固定容量的模型),只有当测试分布与训练分布相似时,这个界才有意义。
单一大语言模型的突破与挑战
单一大语言模型代表了向通用智能的重大飞跃。这些基于Transformer架构的模型具有深层自注意力机制和超大参数量(通常从几十亿到数千亿参数),在海量文本或多模态语料库上进行预训练。
Transformer的核心是自注意力机制,对于输入序列X=[x1,x2,…,xL]\mathbf{X} = [x_1, x_2, \ldots, x_L]X=[x1,x2,…,xL],自注意力计算为:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k}}\right)\mathbf{V}Attention(Q,K,V)=softmax(dkQKT)V
其中Q=XWQ\mathbf{Q} = \mathbf{X}\mathbf{W}_QQ=XWQ,K=XWK\mathbf{K} = \mathbf{X}\mathbf{W}_KK=XWK,V=XWV\mathbf{V} = \mathbf{X}\mathbf{W}_VV=XWV分别是查询、键和值矩阵,WQ,WK,WV\mathbf{W}_Q, \mathbf{W}_K, \mathbf{W}_VWQ,WK,WV是可学习的权重矩阵,dkd_kdk是键向量的维度。
多头注意力机制通过并行运行hhh个注意力头来捕获不同的表示子空间:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO\text{MultiHead}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)\mathbf{W}_OMultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中headi=Attention(QWiQ,KWiK,VWiV)\text{head}_i = \text{Attention}(\mathbf{Q}\mathbf{W}_i^Q, \mathbf{K}\mathbf{W}_i^K, \mathbf{V}\mathbf{W}_i^V)headi=Attention(QWiQ,KWiK,VWiV)。
大语言模型通过在大规模语料库D\mathcal{D}D上最大化似然来预训练:
θ∗=argmaxθ∑x∈DlogPθ(x)=argmaxθ∑x∈D∑t=1∣x∣logPθ(xt∣x<t)\theta^* = \arg\max_{\theta} \sum_{x \in \mathcal{D}} \log P_{\theta}(x) = \arg\max_{\theta} \sum_{x \in \mathcal{D}} \sum_{t=1}^{|x|} \log P_{\theta}(x_t | x_{<t})θ∗=argθmaxx∈D∑logPθ(x)=argθmaxx∈D∑t=1∑∣x∣logPθ(xt∣x<t)
这种无监督或自监督学习使模型学习到语言和世界知识的广泛统计表示,其基本设计理念利用大规模的数据,赋予模型远超任何单一狭窄任务模型的处理能力。
单一大语言模型在边缘可以作为多功能AI代理,通过提示或少样本示例处理众多任务,而不需要针对任务的重新编程。它们展现出一定程度的通用推理能力,能够通过从训练知识中提取类比示例来解决从未明确训练过的问题。然而在边缘硬件上部署单一大语言模型具有挑战性,因为资源需求巨大。这些模型通常需要数十GB的内存和显著的计算能力,例如数百亿参数的模型需要专门的硬件加速器。
尽管单一大语言模型能力卓越,但在边缘计算中的使用暴露出关键局限。个体模型通常会产生幻觉,由于训练数据不完整或架构约束而生成有偏见或虚假的内容。这些问题不仅阻碍了在动态网络设置中的可靠性和适应性,还突出了单模型方法作为潜在瓶颈的问题。
多大语言模型系统的优势量化分析
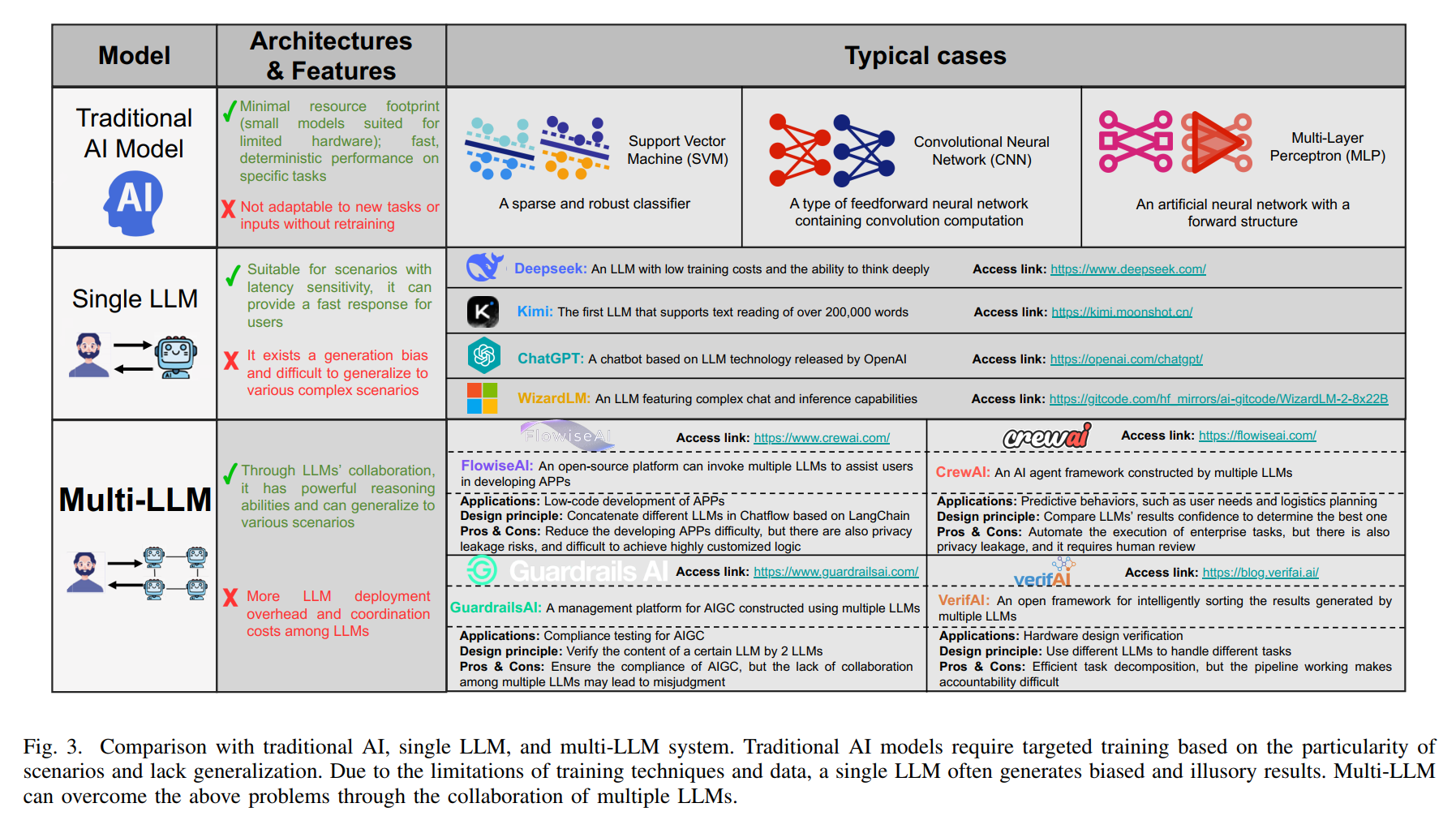
图3深度解读:论文第6-7页的图3通过详细的对比表格和示例案例,展示了传统AI、单一大语言模型和多大语言模型系统之间的本质差异。图的顶部展示了三个模型类别的架构与特征概览。左侧的传统AI模型部分列出了最小资源占用、快速确定性性能等优势,但也指出了无需重新训练就无法适应新任务的局限。中间的单一大语言模型部分强调了适用于延迟敏感场景和能够为用户提供快速响应的特点,同时指出存在生成偏见且难以泛化到各种复杂场景的问题。右侧的多大语言模型部分突出了通过大语言模型协作具有强大推理能力且能泛化到各种场景的优势,但也承认更多大语言模型部署开销和大语言模型之间协调成本的挑战。
图的中部展示了四个典型案例,每个都附有访问链接。Deepseek被描述为具有低训练成本和深度思考能力的大语言模型;Kimi是首个支持超过20万字文本阅读的大语言模型;ChatGPT是OpenAI发布的基于大语言模型技术的聊天机器人;WizardLM则具有复杂对话和推理能力。右侧的多大语言模型案例包括FlowiseAI(可调用多个大语言模型协助用户开发应用程序的开源平台)、GuardrailsAI(使用多个大语言模型构建的AIGC管理平台)、CrewAI(由多个大语言模型构建的AI代理框架)和VerifAI(用于智能排序多个大语言模型生成结果的开源框架)。
图的底部展示了三种传统AI算法的示意图:支持向量机(一种稀疏且鲁棒的分类器)、卷积神经网络(包含卷积计算的前馈神经网络类型)和多层感知器(具有前向结构的人工神经网络)。整个图表通过视觉化的方式清晰地传达了从专用狭窄模型到通用智能再到协作智能的演进路径。
多大语言模型系统的能力源于其成员模型的多样性和专业化。通过利用每个大语言模型的不同知识库和优势,这样的系统可以覆盖比任何单一模型更广泛的任务或更复杂的任务空间。这种优势可以从信息论的角度进行量化。考虑一个具有NNN个模型的系统,每个模型具有不同的知识分布Pi(y∣x)P_i(y|x)Pi(y∣x)。系统的总知识多样性可以用互信息来衡量:
D(M)=∑i=1NH(Y∣X,Mi)−H(Y∣X,M)\mathcal{D}(\mathcal{M}) = \sum_{i=1}^{N} H(Y|X, M_i) - H(Y|X, \mathcal{M})D(M)=i=1∑NH(Y∣X,Mi)−H(Y∣X,M)
其中H(Y∣X,Mi)H(Y|X, M_i)H(Y∣X,Mi)是给定模型MiM_iMi时YYY的条件熵,H(Y∣X,M)H(Y|X, \mathcal{M})H(Y∣X,M)是给定整个系统时的条件熵。这个度量捕获了系统相对于个体模型减少的不确定性。
在可扩展性和灵活性方面,与单一大语言模型相比,扩展通常意味着重新训练或微调整个模型,对于多大语言模型系统,可以在不重新训练整个系统的情况下添加或替换新模型,从而适应新任务。这可以建模为模块化函数近似。假设目标函数为f∗:X→Yf^*: \mathcal{X} \rightarrow \mathcal{Y}f∗:X→Y,多大语言模型系统可以表示为:
f^(⋅)=A({Mi(⋅)}i=1N)\hat{f}(\cdot) = \mathcal{A}(\{M_i(\cdot)\}_{i=1}^{N})f^(⋅)=A({Mi(⋅)}i=1N)
添加新模型MN+1M_{N+1}MN+1只需要学习适当的聚合权重,而不是重新训练所有模型。
在鲁棒性和容错能力方面,多大语言模型系统本质上引入了冗余和专业化。考虑每个模型的错误率ϵi\epsilon_iϵi,假设错误是独立的,通过多数投票,系统错误率为:
ϵsys=∑k>N/2(Nk)ϵk(1−ϵ)N−k\epsilon_{\text{sys}} = \sum_{k > N/2} \binom{N}{k} \epsilon^k (1-\epsilon)^{N-k}ϵsys=k>N/2∑(kN)ϵk(1−ϵ)N−k
其中ϵ=1N∑i=1Nϵi\epsilon = \frac{1}{N}\sum_{i=1}^{N} \epsilon_iϵ=N1∑i=1Nϵi是平均错误率。对于ϵ<0.5\epsilon < 0.5ϵ<0.5且NNN足够大,ϵsys≪ϵ\epsilon_{\text{sys}} \ll \epsilonϵsys≪ϵ,展示了集成的鲁棒性。
边缘与云端多大语言模型部署的差异化策略
多大语言模型系统的移动边缘部署与云端部署在多个关键维度上存在本质差异,这些差异不仅影响系统架构设计,还决定了性能优化的策略选择。
推理延迟的量化分析
推理延迟在边缘通常更低,因为数据在源附近处理,避免了到远程数据中心的长网络回程。总延迟可以分解为:
Latencytotal=Latencycompute+Latencynetwork\text{Latency}_{\text{total}} = \text{Latency}_{\text{compute}} + \text{Latency}_{\text{network}}Latencytotal=Latencycompute+Latencynetwork
对于边缘部署:
Latencyedge=Latencycomputelocal+LatencynetworkLAN\text{Latency}_{\text{edge}} = \text{Latency}_{\text{compute}}^{\text{local}} + \text{Latency}_{\text{network}}^{\text{LAN}}Latencyedge=Latencycomputelocal+LatencynetworkLAN
对于云端部署:
Latencycloud=Latencycomputecloud+2⋅LatencynetworkWAN\text{Latency}_{\text{cloud}} = \text{Latency}_{\text{compute}}^{\text{cloud}} + 2 \cdot \text{Latency}_{\text{network}}^{\text{WAN}}Latencycloud=Latencycomputecloud+2⋅LatencynetworkWAN
其中LatencynetworkWAN≫LatencynetworkLAN\text{Latency}_{\text{network}}^{\text{WAN}} \gg \text{Latency}_{\text{network}}^{\text{LAN}}LatencynetworkWAN≫LatencynetworkLAN,因为广域网延迟通常比局域网延迟高一到两个数量级。即使Latencycomputelocal>Latencycomputecloud\text{Latency}_{\text{compute}}^{\text{local}} > \text{Latency}_{\text{compute}}^{\text{cloud}}Latencycomputelocal>Latencycomputecloud(因为边缘设备计算能力较弱),网络延迟的差异通常主导总体延迟,使边缘部署在延迟敏感应用中更具优势。
资源约束的优化建模
资源约束在边缘环境中更为明显。边缘服务器具有有限的计算、内存和电力。例如一个70亿参数的LLaMA 2模型在全精度下需要约28GB内存(假设每个参数使用4字节的FP32表示):
Memorymodel=Nparams×Bytesper_param=7×109×4=28 GB\text{Memory}_{\text{model}} = N_{\text{params}} \times \text{Bytes}_{\text{per\_param}} = 7 \times 10^9 \times 4 = 28 \text{ GB}Memorymodel=Nparams×Bytesper_param=7×109×4=28 GB
这超过了大多数边缘设备的容量。通过量化到INT8(每参数1字节),内存需求可以降低到:
Memoryquantized=7×109×1=7 GB\text{Memory}_{\text{quantized}} = 7 \times 10^9 \times 1 = 7 \text{ GB}Memoryquantized=7×109×1=7 GB
这仍然很大,但对于某些边缘服务器来说是可行的。
资源分配可以表述为一个优化问题。给定NNN个模型和DDD个设备,目标是最小化延迟同时满足资源约束:
minXmaxi=1DLatencyi(X)\min_{\mathbf{X}} \max_{i=1}^{D} \text{Latency}_i(\mathbf{X})Xmini=1maxDLatencyi(X)
受约束于:
∑j=1Nxij⋅Memoryj≤Capacityimem,∀i\sum_{j=1}^{N} x_{ij} \cdot \text{Memory}_j \leq \text{Capacity}_i^{\text{mem}}, \quad \forall ij=1∑Nxij⋅Memoryj≤Capacityimem,∀i
∑j=1Nxij⋅Computej≤Capacityicomp,∀i\sum_{j=1}^{N} x_{ij} \cdot \text{Compute}_j \leq \text{Capacity}_i^{\text{comp}}, \quad \forall ij=1∑Nxij⋅Computej≤Capacityicomp,∀i
∑i=1Dxij=1,∀j\sum_{i=1}^{D} x_{ij} = 1, \quad \forall ji=1∑Dxij=1,∀j
xij∈{0,1},∀i,jx_{ij} \in \{0, 1\}, \quad \forall i, jxij∈{0,1},∀i,j
其中xijx_{ij}xij是二进制变量,指示模型jjj是否部署在设备iii上,Memoryj\text{Memory}_jMemoryj和Computej\text{Compute}_jComputej分别是模型jjj的内存和计算需求,Capacityimem\text{Capacity}_i^{\text{mem}}Capacityimem和Capacityicomp\text{Capacity}_i^{\text{comp}}Capacityicomp是设备iii的容量。
系统架构的拓扑设计
系统架构在边缘场景中往往是分布式的。模型推理可能在多个边缘节点之间拆分,或者在设备和边缘服务器之间协作执行。这可以用图论来建模。考虑一个网络图G=(V,E)\mathcal{G} = (\mathcal{V}, \mathcal{E})G=(V,E),其中V\mathcal{V}V是节点集(设备和服务器),E\mathcal{E}E是边集(通信链接)。每条边(i,j)∈E(i, j) \in \mathcal{E}(i,j)∈E具有带宽bijb_{ij}bij和延迟lijl_{ij}lij。
模型分区可以表示为将模型层{L1,L2,…,LK}\{L_1, L_2, \ldots, L_K\}{L1,L2,…,LK}映射到节点π:{1,…,K}→V\pi: \{1, \ldots, K\} \rightarrow \mathcal{V}π:{1,…,K}→V。通信成本为:
Costcomm(π)=∑k=1K−11[π(k)≠π(k+1)]⋅(∣Ak∣bπ(k),π(k+1)+lπ(k),π(k+1))\text{Cost}_{\text{comm}}(\pi) = \sum_{k=1}^{K-1} \mathbb{1}[\pi(k) \neq \pi(k+1)] \cdot \left(\frac{|A_k|}{b_{\pi(k), \pi(k+1)}} + l_{\pi(k), \pi(k+1)}\right)Costcomm(π)=k=1∑K−11[π(k)=π(k+1)]⋅(bπ(k),π(k+1)∣Ak∣+lπ(k),π(k+1))
其中∣Ak∣|A_k|∣Ak∣是层kkk和k+1k+1k+1之间传输的激活数据大小,1[⋅]\mathbb{1}[\cdot]1[⋅]是指示函数。
云端架构通常是中心化的,所有计算在一个位置进行,可以简化为:
Costcloud=Latencycompute(all layers)\text{Cost}_{\text{cloud}} = \text{Latency}_{\text{compute}}(\text{all layers})Costcloud=Latencycompute(all layers)
这些架构差异导致了不同的优化策略和性能特征。
支撑多大语言模型边缘部署的关键技术
模型压缩的理论与实践
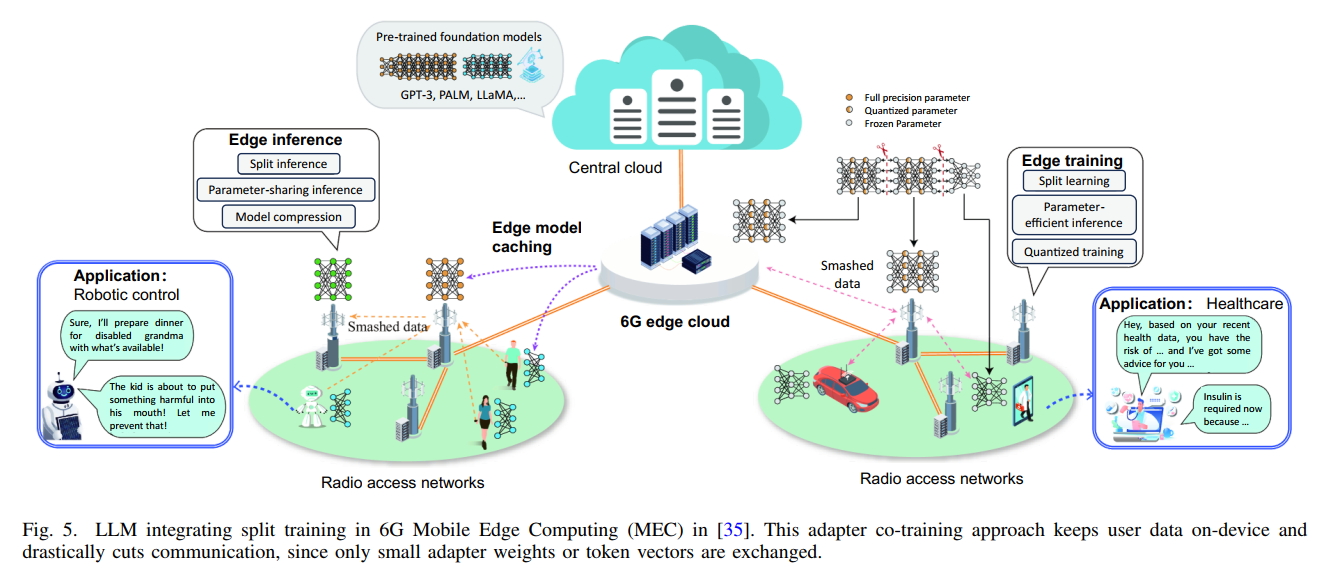
图5架构解读:论文第11页的图5展示了大语言模型在6G移动边缘计算中集成分裂训练的完整框架。图的上方显示了预训练的基础模型(GPT-3、PALM、LLaMA等)存储在中央云中。图的中心部分是6G边缘云,连接着多个无线接入网络。左侧展示了边缘推理的三种方式:分裂推理、参数共享推理和模型压缩。右侧展示了边缘训练的三种方式:分裂学习、参数高效推理和量化训练。图中使用不同颜色的圆圈表示全精度参数(实心)、量化参数(斜纹)和冻结参数(空心)。底部展示了两个具体应用:左边是机器人控制应用(为残疾奶奶准备晚餐的场景),右边是医疗保健应用(基于健康数据提供建议和胰岛素管理的场景)。整个图表清晰地展示了适配器协同训练方法如何保持用户数据在设备上,同时大幅削减通信,因为只交换小型适配器权重或令牌向量。
模型压缩旨在减少大语言模型的内存占用和计算复杂度,同时保持性能。主要技术包括知识蒸馏、量化、剪枝和低秩分解。
知识蒸馏的数学框架
知识蒸馏通过训练一个小型学生模型MSM_SMS来模仿大型教师模型MTM_TMT的行为。给定输入xxx,教师模型产生softmax输出:
pT=softmax(zT/τ)=exp(zT/τ)∑jexp(zT,j/τ)\mathbf{p}_T = \text{softmax}(\mathbf{z}_T / \tau) = \frac{\exp(\mathbf{z}_T / \tau)}{\sum_j \exp(z_{T,j} / \tau)}pT=softmax(zT/τ)=∑jexp(zT,j/τ)exp(zT/τ)
其中zT\mathbf{z}_TzT是教师的logits,τ\tauτ是温度参数。学生模型类似地产生pS\mathbf{p}_SpS。
蒸馏损失结合了与真实标签的交叉熵和与教师软标签的Kullback-Leibler散度:
Ldistill=(1−α)LCE(y,pS)+ατ2KL(pT∥pS)\mathcal{L}_{\text{distill}} = (1-\alpha) \mathcal{L}_{\text{CE}}(y, \mathbf{p}_S) + \alpha \tau^2 \text{KL}(\mathbf{p}_T \| \mathbf{p}_S)Ldistill=(1−α)LCE(y,pS)+ατ2KL(pT∥pS)
其中α\alphaα是平衡参数,τ2\tau^2τ2是温度缩放因子。KL散度定义为:
KL(pT∥pS)=∑jpT,jlogpT,jpS,j\text{KL}(\mathbf{p}_T \| \mathbf{p}_S) = \sum_j p_{T,j} \log \frac{p_{T,j}}{p_{S,j}}KL(pT∥pS)=j∑pT,jlogpS,jpT,j
DistilBERT通过这种方法将BERT的参数量减少40%,同时保留97%的性能。TinyBERT更进一步,采用多阶段蒸馏,不仅匹配输出分布,还匹配中间层的注意力矩阵和隐藏状态:
Lhidden=1L∑l=1L∥HS(l)Wl−HT(l)∥F2\mathcal{L}_{\text{hidden}} = \frac{1}{L} \sum_{l=1}^{L} \|\mathbf{H}_S^{(l)} \mathbf{W}_l - \mathbf{H}_T^{(l)}\|_F^2Lhidden=L1l=1∑L∥HS(l)Wl−HT(l)∥F2
Lattn=1L∑l=1L∥AS(l)−AT(l)∥F2\mathcal{L}_{\text{attn}} = \frac{1}{L} \sum_{l=1}^{L} \|\mathbf{A}_S^{(l)} - \mathbf{A}_T^{(l)}\|_F^2Lattn=L1l=1∑L∥AS(l)−AT(l)∥F2
其中H(l)\mathbf{H}^{(l)}H(l)和A(l)\mathbf{A}^{(l)}A(l)分别是第lll层的隐藏状态和注意力矩阵,Wl\mathbf{W}_lWl是对齐矩阵,∥⋅∥F\|\cdot\|_F∥⋅∥F是Frobenius范数。
量化技术的精度分析
量化将模型权重和激活从浮点表示转换为低精度整数表示。给定一个浮点权重矩阵W∈Rm×n\mathbf{W} \in \mathbb{R}^{m \times n}W∈Rm×n,量化函数为:
Wq=round(W−zs)\mathbf{W}_q = \text{round}\left(\frac{\mathbf{W} - z}{s}\right)Wq=round(sW−z)
其中sss是缩放因子,zzz是零点,round是舍入函数。逆量化为:
W^=s⋅Wq+z\hat{\mathbf{W}} = s \cdot \mathbf{W}_q + zW^=s⋅Wq+z
对于对称量化(z=0z = 0z=0),缩放因子计算为:
s=max(∣W∣)2b−1−1s = \frac{\max(|\mathbf{W}|)}{2^{b-1} - 1}s=2b−1−1max(∣W∣)
其中bbb是量化位数。从FP32(32位)到INT8(8位)量化可以将内存占用减少到原来的1/41/41/4,同时将计算速度提高222到444倍。
量化引入的误差可以分析为:
E[(Wij−W^ij)2]=s212\mathbb{E}[(W_{ij} - \hat{W}_{ij})^2] = \frac{s^2}{12}E[(Wij−W^ij)2]=12s2
这是均匀量化噪声的方差。对于bbb位量化:
s≈2max(∣Wij∣)2bs \approx \frac{2 \max(|W_{ij}|)}{2^b}s≈2b2max(∣Wij∣)
因此均方误差随着位数增加指数衰减:
MSE≈max(∣Wij∣)23⋅4b\text{MSE} \approx \frac{\max(|W_{ij}|)^2}{3 \cdot 4^b}MSE≈3⋅4bmax(∣Wij∣)2
剪枝策略的优化理论
剪枝通过移除不重要的权重或神经元来减少模型大小。重要性可以用多种标准衡量。基于幅度的剪枝使用绝对值:
I(wij)=∣wij∣\mathcal{I}(w_{ij}) = |w_{ij}|I(wij)=∣wij∣
权重wijw_{ij}wij如果I(wij)<τ\mathcal{I}(w_{ij}) < \tauI(wij)<τ则被剪枝,其中τ\tauτ是阈值。
更复杂的方法使用二阶信息。给定损失函数L\mathcal{L}L,移除权重wijw_{ij}wij导致的损失变化的泰勒展开为:
ΔL≈∂L∂wijΔwij+12∂2L∂wij2(Δwij)2\Delta \mathcal{L} \approx \frac{\partial \mathcal{L}}{\partial w_{ij}} \Delta w_{ij} + \frac{1}{2} \frac{\partial^2 \mathcal{L}}{\partial w_{ij}^2} (\Delta w_{ij})^2ΔL≈∂wij∂LΔwij+21∂wij2∂2L(Δwij)2
对于剪枝,Δwij=−wij\Delta w_{ij} = -w_{ij}Δwij=−wij,所以:
ΔL≈−∂L∂wijwij+12Hiiwij2\Delta \mathcal{L} \approx -\frac{\partial \mathcal{L}}{\partial w_{ij}} w_{ij} + \frac{1}{2} H_{ii} w_{ij}^2ΔL≈−∂wij∂Lwij+21Hiiwij2
其中Hii=∂2L∂wij2H_{ii} = \frac{\partial^2 \mathcal{L}}{\partial w_{ij}^2}Hii=∂wij2∂2L是Hessian矩阵的对角元素。权重的显著性得分为:
I(wij)=∣∂L∂wijwij∣+12Hiiwij2\mathcal{I}(w_{ij}) = \left|\frac{\partial \mathcal{L}}{\partial w_{ij}} w_{ij}\right| + \frac{1}{2} H_{ii} w_{ij}^2I(wij)= ∂wij∂Lwij +21Hiiwij2
结构化剪枝移除整个神经元或通道。对于神经元jjj,其重要性可以定义为:
I(j)=∑i∣wij∣\mathcal{I}(j) = \sum_i |w_{ij}|I(j)=i∑∣wij∣
或使用激活统计:
I(j)=Ex∼D[∣hj(x)∣]\mathcal{I}(j) = \mathbb{E}_{x \sim \mathcal{D}}[|h_j(x)|]I(j)=Ex∼D[∣hj(x)∣]
其中hj(x)h_j(x)hj(x)是神经元jjj对输入xxx的激活。
低秩分解的矩阵理论
低秩分解将大型权重矩阵分解为较小矩阵的乘积。给定权重矩阵W∈Rm×n\mathbf{W} \in \mathbb{R}^{m \times n}W∈Rm×n(假设m,n≫rm, n \gg rm,n≫r),可以近似为:
W≈AB\mathbf{W} \approx \mathbf{A} \mathbf{B}W≈AB
其中A∈Rm×r\mathbf{A} \in \mathbb{R}^{m \times r}A∈Rm×r和B∈Rr×n\mathbf{B} \in \mathbb{R}^{r \times n}B∈Rr×n,r≪min(m,n)r \ll \min(m, n)r≪min(m,n)是秩。
参数数量从mnmnmn减少到(m+n)r(m + n)r(m+n)r。压缩比为:
Compression ratio=mn(m+n)r\text{Compression ratio} = \frac{mn}{(m + n)r}Compression ratio=(m+n)rmn
对于m=n=1024m = n = 1024m=n=1024和r=64r = 64r=64:
Compression ratio=10242(1024+1024)×64≈8\text{Compression ratio} = \frac{1024^2}{(1024 + 1024) \times 64} \approx 8Compression ratio=(1024+1024)×6410242≈8
最优分解可以通过奇异值分解(SVD)获得:
W=UΣVT\mathbf{W} = \mathbf{U} \mathbf{\Sigma} \mathbf{V}^TW=UΣVT
保留前rrr个最大奇异值:
Wr=U:,1:rΣ1:r,1:rV:,1:rT\mathbf{W}_r = \mathbf{U}_{:,1:r} \mathbf{\Sigma}_{1:r,1:r} \mathbf{V}_{:,1:r}^TWr=U:,1:rΣ1:r,1:rV:,1:rT
Frobenius范数误差为:
∥W−Wr∥F=∑i=r+1min(m,n)σi2\|\mathbf{W} - \mathbf{W}_r\|_F = \sqrt{\sum_{i=r+1}^{\min(m,n)} \sigma_i^2}∥W−Wr∥F=i=r+1∑min(m,n)σi2
其中σi\sigma_iσi是第iii个奇异值。
ALBERT使用因式分解嵌入,将嵌入矩阵E∈RV×H\mathbf{E} \in \mathbb{R}^{V \times H}E∈RV×H(VVV是词汇量,HHH是隐藏维度)分解为:
E=E1E2\mathbf{E} = \mathbf{E}_1 \mathbf{E}_2E=E1E2
其中E1∈RV×E\mathbf{E}_1 \in \mathbb{R}^{V \times E}E1∈RV×E和E2∈RE×H\mathbf{E}_2 \in \mathbb{R}^{E \times H}E2∈RE×H,E≪HE \ll HE≪H。参数从V×HV \times HV×H减少到V×E+E×HV \times E + E \times HV×E+E×H。
动态资源编排的优化算法
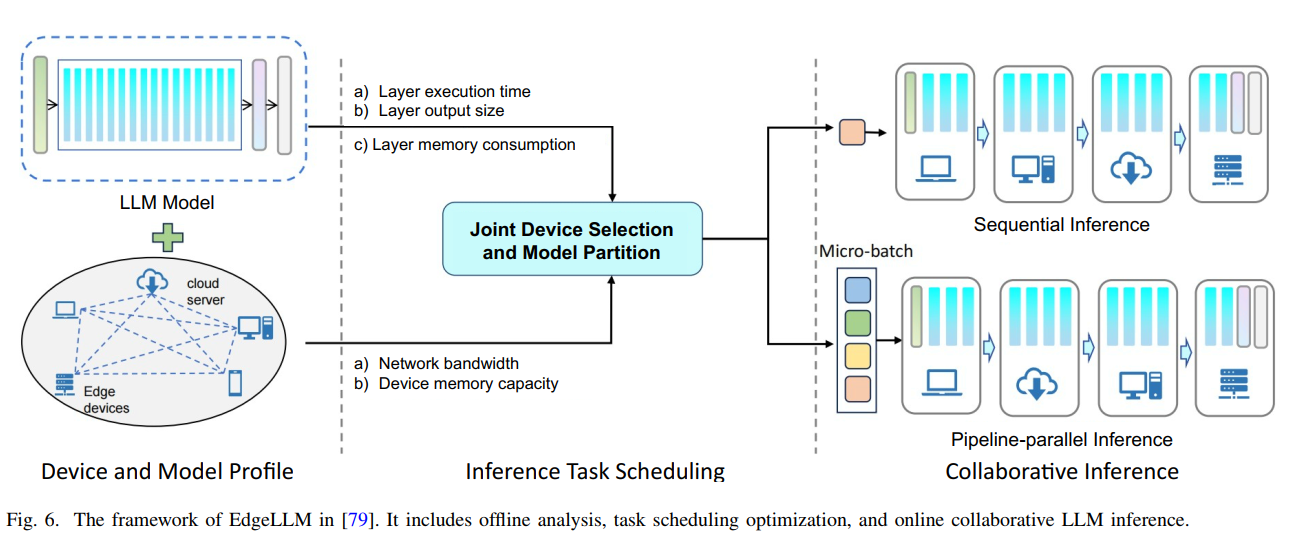
图6系统架构解读:论文第12页的图6详细展示了EdgeShard框架的完整工作流程。图分为三个主要部分:左侧是"设备和模型配置"阶段,包括大语言模型模型的三个关键指标(层执行时间、层输出大小、层内存消耗)以及两个设备约束(网络带宽和设备内存容量);中间是"推理任务调度"阶段,展示了联合设备选择和模型分区的优化过程;右侧是"协作推理"阶段,展示了两种推理模式——顺序推理(按层依次处理)和流水线并行推理(多设备并行处理)。图中使用不同颜色的条形块表示大语言模型的不同层,箭头表示数据流动和处理顺序。图的底部显示了四个设备节点(笔记本电脑、台式机、云服务器和服务器集群),它们通过网络连接进行协作推理。这个框架通过动态规划算法来分配层到设备,以最小化延迟并最大化吞吐量。
动态资源编排旨在将计算任务和模型组件智能地分配到异构边缘设备上,以优化延迟、能耗和准确性的综合指标。
早期退出机制的决策理论
早期退出允许模型在中间层终止推理,如果当前预测的置信度足够高。对于LLL层模型,每层lll都有一个分类器flf_lfl和置信度估计器clc_lcl。
决策策略可以表述为阈值策略:
Exit at layer l if cl(fl(x))>τl\text{Exit at layer } l \text{ if } c_l(f_l(x)) > \tau_lExit at layer l if cl(fl(x))>τl
其中τl\tau_lτl是第lll层的置信度阈值。最优阈值可以通过优化延迟-准确性权衡来确定:
min{τl}l=1LEx∼D[Latency(x,{τl})]+λEx∼D[Error(x,{τl})]\min_{\{\tau_l\}_{l=1}^{L}} \mathbb{E}_{x \sim \mathcal{D}} [\text{Latency}(x, \{\tau_l\})] + \lambda \mathbb{E}_{x \sim \mathcal{D}} [\text{Error}(x, \{\tau_l\})]{τl}l=1LminEx∼D[Latency(x,{τl})]+λEx∼D[Error(x,{τl})]
其中λ\lambdaλ是权衡参数。
EdgeBERT使用基于熵的策略。预测熵定义为:
H(fl(x))=−∑k=1KpklogpkH(f_l(x)) = -\sum_{k=1}^{K} p_k \log p_kH(fl(x))=−k=1∑Kpklogpk
其中pkp_kpk是类别kkk的预测概率。低熵表示高置信度,所以退出条件是:
H(fl(x))<τentropyH(f_l(x)) < \tau_{\text{entropy}}H(fl(x))<τentropy
期望延迟为:
E[Latency]=∑l=1LP(exit at l)⋅tl\mathbb{E}[\text{Latency}] = \sum_{l=1}^{L} P(\text{exit at } l) \cdot t_lE[Latency]=l=1∑LP(exit at l)⋅tl
其中tlt_ltl是计算到第lll层的累积时间。
级联推理的概率模型
级联推理使用一系列逐渐更强大的模型,从小型模型开始,仅在必要时升级到更大的模型。考虑一个级联{M1,M2,…,MK}\{M_1, M_2, \ldots, M_K\}{M1,M2,…,MK},其中MkM_kMk比Mk−1M_{k-1}Mk−1更强大但也更昂贵。
对于输入xxx,首先查询M1M_1M1。如果其预测置信度超过阈值τ1\tau_1τ1,则返回该预测;否则查询M2M_2M2,依此类推。形式上:
y^(x)={y1if c1(x)>τ1y2if c1(x)≤τ1 and c2(x)>τ2⋮yKotherwise\hat{y}(x) = \begin{cases} y_1 & \text{if } c_1(x) > \tau_1 \\ y_2 & \text{if } c_1(x) \leq \tau_1 \text{ and } c_2(x) > \tau_2 \\ \vdots \\ y_K & \text{otherwise} \end{cases}y^(x)=⎩ ⎨ ⎧y1y2⋮yKif c1(x)>τ1if c1(x)≤τ1 and c2(x)>τ2otherwise
成本可以表示为:
Cost(x)=∑k=1K1[query Mk]⋅Costk\text{Cost}(x) = \sum_{k=1}^{K} \mathbb{1}[\text{query } M_k] \cdot \text{Cost}_kCost(x)=k=1∑K1[query Mk]⋅Costk
其中1[query Mk]\mathbb{1}[\text{query } M_k]1[query Mk]指示是否查询模型kkk。
Agreement-Based Cascading(ABC)使用集成一致性作为退出标准。在级别kkk,使用NkN_kNk个模型的集成。如果至少mmm个模型同意一个答案,则退出:
Exit at level k if maxy∑i=1Nk1[yi=y]≥m\text{Exit at level } k \text{ if } \max_y \sum_{i=1}^{N_k} \mathbb{1}[y_i = y] \geq mExit at level k if ymaxi=1∑Nk1[yi=y]≥m
这确保了集成共识,从而提高了可靠性。
模型分区的动态规划算法
模型分区将大语言模型的层分布到多个设备上。给定模型的LLL层和DDD个设备,目标是找到最优分区来最小化端到端延迟。
设π:{1,…,L}→{1,…,D}\pi: \{1, \ldots, L\} \rightarrow \{1, \ldots, D\}π:{1,…,L}→{1,…,D}是分区函数,π(l)=d\pi(l) = dπ(l)=d表示层lll部署在设备ddd上。总延迟包括计算延迟和通信延迟:
Latency(π)=∑l=1Ltlcomp(π(l))+∑l=1L−11[π(l)≠π(l+1)]⋅tlcomm(π(l),π(l+1))\text{Latency}(\pi) = \sum_{l=1}^{L} t_l^{\text{comp}}(\pi(l)) + \sum_{l=1}^{L-1} \mathbb{1}[\pi(l) \neq \pi(l+1)] \cdot t_l^{\text{comm}}(\pi(l), \pi(l+1))Latency(π)=l=1∑Ltlcomp(π(l))+l=1∑L−11[π(l)=π(l+1)]⋅tlcomm(π(l),π(l+1))
其中tlcomp(d)t_l^{\text{comp}}(d)tlcomp(d)是在设备ddd上计算层lll的时间,tlcomm(d,d′)t_l^{\text{comm}}(d, d')tlcomm(d,d′)是从设备ddd到d′d'd′传输层lll输出的时间。
这可以用动态规划求解。定义子问题DP[l][d]\text{DP}[l][d]DP[l][d]为将前lll层部署使得层lll在设备ddd上的最小延迟:
DP[l][d]=mind′∈{1,…,D}[DP[l−1][d′]+tlcomp(d)+1[d′≠d]⋅tl−1comm(d′,d)]\text{DP}[l][d] = \min_{d' \in \{1, \ldots, D\}} \left[\text{DP}[l-1][d'] + t_l^{\text{comp}}(d) + \mathbb{1}[d' \neq d] \cdot t_{l-1}^{\text{comm}}(d', d)\right]DP[l][d]=d′∈{1,…,D}min[DP[l−1][d′]+tlcomp(d)+1[d′=d]⋅tl−1comm(d′,d)]
边界条件为DP[1][d]=t1comp(d)\text{DP}[1][d] = t_1^{\text{comp}}(d)DP[1][d]=t1comp(d)。最优解为:
mind∈{1,…,D}DP[L][d]\min_{d \in \{1, \ldots, D\}} \text{DP}[L][d]d∈{1,…,D}minDP[L][d]
时间复杂度为O(L⋅D2)O(L \cdot D^2)O(L⋅D2),对于合理的LLL和DDD值是可行的。
EdgeShard扩展了这个基本算法,加入了内存约束和并行执行。它制定了一个联合设备选择和模型分区问题:
minπ,Xmaxd=1DLatencyd(π,X)\min_{\pi, \mathbf{X}} \max_{d=1}^{D} \text{Latency}_d(\pi, \mathbf{X})π,Xmind=1maxDLatencyd(π,X)
受约束于:
∑l:π(l)=dMemoryl≤Capacityd,∀d\sum_{l: \pi(l) = d} \text{Memory}_l \leq \text{Capacity}_d, \quad \forall dl:π(l)=d∑Memoryl≤Capacityd,∀d
∑d=1Dxld=1,∀l\sum_{d=1}^{D} x_{ld} = 1, \quad \forall ld=1∑Dxld=1,∀l
xld∈{0,1},∀l,dx_{ld} \in \{0, 1\}, \quad \forall l, dxld∈{0,1},∀l,d
其中X=[xld]\mathbf{X} = [x_{ld}]X=[xld]是分配矩阵。
多智能体调度的强化学习方法
MASITO框架使用多智能体深度强化学习来调度推理任务并在时间和能量约束下进行卸载。每个边缘服务器iii运行一个代理,其状态空间Si\mathcal{S}_iSi包括本地任务队列、资源利用率和邻居状态。动作空间Ai\mathcal{A}_iAi包括本地执行、卸载到邻居或卸载到云。
多智能体马尔可夫决策过程(MMDP)可以表示为元组⟨N,{Si},{Ai},R,P⟩\langle \mathcal{N}, \{\mathcal{S}_i\}, \{\mathcal{A}_i\}, \mathcal{R}, P \rangle⟨N,{Si},{Ai},R,P⟩,其中N={1,…,N}\mathcal{N} = \{1, \ldots, N\}N={1,…,N}是代理集,R:S×A→R\mathcal{R}: \mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R}R:S×A→R是联合奖励函数,P:S×A×S→[0,1]P: \mathcal{S} \times \mathcal{A} \times \mathcal{S} \rightarrow [0, 1]P:S×A×S→[0,1]是转移概率。
联合策略π={π1,…,πN}\pi = \{\pi_1, \ldots, \pi_N\}π={π1,…,πN},其中πi:Si→P(Ai)\pi_i: \mathcal{S}_i \rightarrow \mathcal{P}(\mathcal{A}_i)πi:Si→P(Ai)。目标是最大化累积折扣奖励:
J(π)=Eπ[∑t=0∞γtrt]J(\pi) = \mathbb{E}_{\pi} \left[\sum_{t=0}^{\infty} \gamma^t r_t\right]J(π)=Eπ[t=0∑∞γtrt]
其中γ∈(0,1)\gamma \in (0, 1)γ∈(0,1)是折扣因子。
每个代理使用深度Q网络(DQN)来近似其Q函数Qi(si,ai;θi)Q_i(s_i, a_i; \theta_i)Qi(si,ai;θi),通过最小化时间差分误差来训练:
L(θi)=E[(ri+γmaxai′Qi(si′,ai′;θi−)−Qi(si,ai;θi))2]\mathcal{L}(\theta_i) = \mathbb{E}\left[\left(r_i + \gamma \max_{a_i'} Q_i(s_i', a_i'; \theta_i^-) - Q_i(s_i, a_i; \theta_i)\right)^2\right]L(θi)=E[(ri+γai′maxQi(si′,ai′;θi−)−Qi(si,ai;θi))2]
其中θi−\theta_i^-θi−是目标网络参数。
代理之间的协调通过消息传递实现。代理iii向其邻居jjj发送其当前负载和可用容量的信息:
mi→j(t)=(Loadi(t),Capacityi(t))m_{i \to j}(t) = (\text{Load}_i(t), \text{Capacity}_i(t))mi→j(t)=(Loadi(t),Capacityi(t))
代理iii使用收到的消息来更新其状态表示:
s~i(t)=[si(t),{mj→i(t)}j∈Ni]\tilde{s}_i(t) = [s_i(t), \{m_{j \to i}(t)\}_{j \in \mathcal{N}_i}]s~i(t)=[si(t),{mj→i(t)}j∈Ni]
其中Ni\mathcal{N}_iNi是代理iii的邻居集。
模型上下文协议的设计与优化
模型上下文协议定义了大语言模型之间以及大语言模型与外部系统之间如何交换上下文信息。高效的上下文管理对于减少内存占用和通信开销至关重要。
上下文压缩的信息论基础
上下文压缩旨在将长输入序列编码为紧凑表示,同时保留关键信息。In-Context Autoencoder(ICAE)训练一个轻量级自动编码器来总结输入。
给定输入序列x=[x1,…,xT]\mathbf{x} = [x_1, \ldots, x_T]x=[x1,…,xT],编码器EEE将其映射到K≪TK \ll TK≪T个记忆槽:
m=E(x)∈RK×d\mathbf{m} = E(\mathbf{x}) \in \mathbb{R}^{K \times d}m=E(x)∈RK×d
其中ddd是嵌入维度。解码器DDD从记忆槽重构输入:
x^=D(m)\hat{\mathbf{x}} = D(\mathbf{m})x^=D(m)
训练目标是最小化重构误差:
Lrecon=∥x−x^∥2\mathcal{L}_{\text{recon}} = \|\mathbf{x} - \hat{\mathbf{x}}\|^2Lrecon=∥x−x^∥2
加上保持大语言模型性能的任务损失:
Ltotal=Lrecon+λLtask(LLM(m),y)\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{recon}} + \lambda \mathcal{L}_{\text{task}}(\text{LLM}(\mathbf{m}), y)Ltotal=Lrecon+λLtask(LLM(m),y)
其中yyy是任务标签。
压缩率定义为:
ρ=K⋅dT⋅d=KT\rho = \frac{K \cdot d}{T \cdot d} = \frac{K}{T}ρ=T⋅dK⋅d=TK
对于K=T/4K = T/4K=T/4,ICAE实现了4×4\times4×压缩。
从信息论角度,压缩的目标是保留输入x\mathbf{x}x关于任务yyy的互信息。理想情况下:
I(m;y)≈I(x;y)I(\mathbf{m}; y) \approx I(\mathbf{x}; y)I(m;y)≈I(x;y)
同时最小化m\mathbf{m}m的熵H(m)H(\mathbf{m})H(m)以实现紧凑表示。这可以通过信息瓶颈原理来形式化:
maxmI(m;y)−βI(m;x)\max_{\mathbf{m}} I(\mathbf{m}; y) - \beta I(\mathbf{m}; \mathbf{x})mmaxI(m;y)−βI(m;x)
其中β\betaβ控制压缩和保留信息之间的权衡。
键值缓存管理的动态策略
Transformer模型在生成时维护键值(KV)缓存以避免重新计算过去的注意力。对于序列长度TTT和LLL层模型,KV缓存大小为:
SizeKV=2⋅L⋅T⋅d⋅b\text{Size}_{\text{KV}} = 2 \cdot L \cdot T \cdot d \cdot bSizeKV=2⋅L⋅T⋅d⋅b
其中ddd是隐藏维度,bbb是每个值的字节数。对于大TTT,这可能消耗大量内存。
EdgeInfinite引入了门控记忆机制来压缩旧的KV缓存。在时间步ttt,缓存分为三个部分:
- 注意力汇聚令牌(固定大小KsK_sKs):始终保留的初始令牌
- 滑动窗口(固定大小KwK_wKw):最近的KwK_wKw个令牌
- 压缩记忆(可变大小):较旧令牌的压缩表示
门控函数ggg决定哪些令牌压缩到记忆中:
gt=σ(Wght+bg)g_t = \sigma(\mathbf{W}_g \mathbf{h}_t + \mathbf{b}_g)gt=σ(Wght+bg)
其中ht\mathbf{h}_tht是时间步ttt的隐藏状态,σ\sigmaσ是sigmoid函数。
令牌ttt的键值对被添加到记忆中,权重为gtg_tgt:
Mkey=Mkey+gtkt,Mvalue=Mvalue+gtvt\mathbf{M}_{\text{key}} = \mathbf{M}_{\text{key}} + g_t \mathbf{k}_t, \quad \mathbf{M}_{\text{value}} = \mathbf{M}_{\text{value}} + g_t \mathbf{v}_tMkey=Mkey+gtkt,Mvalue=Mvalue+gtvt
注意力计算变为:
Attention(qt)=softmax(qt[Ks;Kw;Mkey]Td)[Vs;Vw;Mvalue]\text{Attention}(\mathbf{q}_t) = \text{softmax}\left(\frac{\mathbf{q}_t [\mathbf{K}_s; \mathbf{K}_w; \mathbf{M}_{\text{key}}]^T}{\sqrt{d}}\right) [\mathbf{V}_s; \mathbf{V}_w; \mathbf{M}_{\text{value}}]Attention(qt)=softmax(dqt[Ks;Kw;Mkey]T)[Vs;Vw;Mvalue]
其中[⋅;⋅][\cdot; \cdot][⋅;⋅]表示连接。
记忆大小为ddd(常数),而标准KV缓存大小与TTT线性增长,实现了无限上下文的恒定内存。
分布式推理的通信优化
在模型分布式推理(MDI-LLM)中,单个生成任务在设备之间拆分。模型的层在节点之间分区,通过流水线计算减少空闲时间。
考虑一个LLL层模型分布在DDD个设备上。设备ddd负责层Ld,startL_{d,\text{start}}Ld,start到Ld,endL_{d,\text{end}}Ld,end。对于批量大小BBB的输入,朴素的顺序执行总时间为:
Tseq=∑d=1Dtd⋅BT_{\text{seq}} = \sum_{d=1}^{D} t_d \cdot BTseq=d=1∑Dtd⋅B
其中tdt_dtd是设备ddd处理一个样本的时间。
流水线执行通过重叠计算来减少延迟。将批次分为MMM个微批次,每个大小B/MB/MB/M。设备ddd在微批次mmm上的计算与设备d+1d+1d+1在微批次m−1m-1m−1上的计算重叠。总时间为:
Tpipe=∑d=1Dtd⋅BM+(D−1)⋅maxdtd⋅BMT_{\text{pipe}} = \sum_{d=1}^{D} t_d \cdot \frac{B}{M} + (D-1) \cdot \max_d t_d \cdot \frac{B}{M}Tpipe=d=1∑Dtd⋅MB+(D−1)⋅dmaxtd⋅MB
=BM(∑d=1Dtd+(D−1)maxdtd)= \frac{B}{M} \left(\sum_{d=1}^{D} t_d + (D-1) \max_d t_d\right)=MB(d=1∑Dtd+(D−1)dmaxtd)
加速比为:
Speedup=TseqTpipe=∑d=1Dtd1M∑d=1Dtd+(1−1M)(D−1)maxdtd\text{Speedup} = \frac{T_{\text{seq}}}{T_{\text{pipe}}} = \frac{\sum_{d=1}^{D} t_d}{\frac{1}{M} \sum_{d=1}^{D} t_d + (1 - \frac{1}{M})(D-1) \max_d t_d}Speedup=TpipeTseq=M1∑d=1Dtd+(1−M1)(D−1)maxdtd∑d=1Dtd
对于大MMM和平衡的tdt_dtd(即td≈tˉt_d \approx \bar{t}td≈tˉ),这接近MMM。
通信优化可以通过张量并行来实现。对于矩阵乘法Y=XW\mathbf{Y} = \mathbf{X} \mathbf{W}Y=XW,将W\mathbf{W}W按列分区为[W1,…,WP][\mathbf{W}_1, \ldots, \mathbf{W}_P][W1,…,WP]:
Y=[XW1,…,XWP]\mathbf{Y} = [\mathbf{X} \mathbf{W}_1, \ldots, \mathbf{X} \mathbf{W}_P]Y=[XW1,…,XWP]
每个设备ppp计算Yp=XWp\mathbf{Y}_p = \mathbf{X} \mathbf{W}_pYp=XWp,然后连接结果。这将通信从传输整个Y\mathbf{Y}Y减少到只传输X\mathbf{X}X(广播)和同步连接,对于大矩阵显著降低了开销。
点对点协议的共识机制
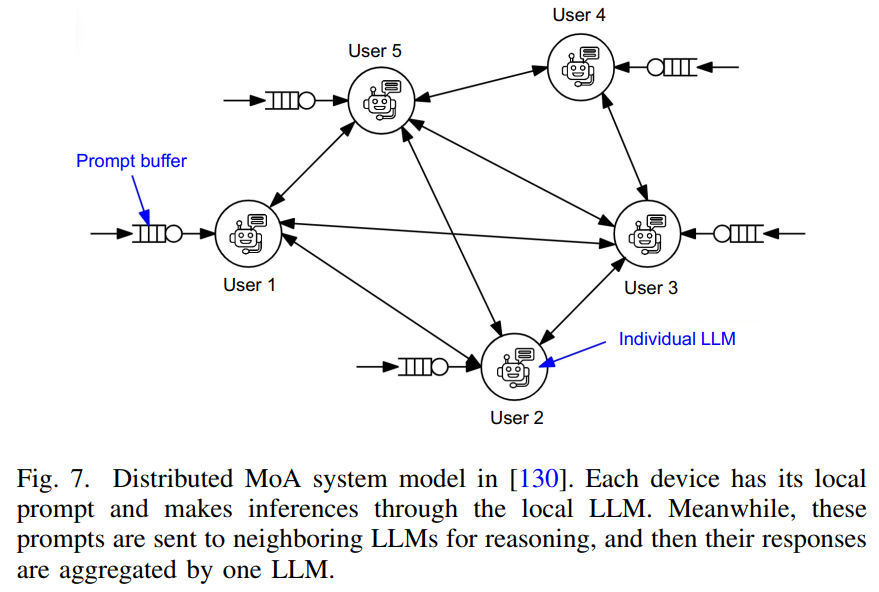
图7点对点网络解读:论文第13页的图7展示了分布式Mixture-of-Agents(MoA)系统模型的P2P网络结构。图的中心是一个提示缓冲区(Prompt buffer),周围分布着五个用户节点(User 1到User 5),每个用户节点都关联着一个单独的大语言模型(Individual LLM)。图中使用箭头表示信息流动:实线箭头表示用户向系统提交查询,虚线箭头表示大语言模型之间的通信和响应传递。每个设备都有其本地提示并通过本地大语言模型进行推理,同时这些提示被发送到相邻大语言模型进行推理,然后它们的响应被一个大语言模型聚合。这种去中心化的设计确保了即使在网络分区或节点故障的情况下,系统仍然可以继续运行,体现了多大语言模型系统的鲁棒性和容错能力。
在去中心化的多大语言模型系统中,点对点(P2P)协议允许模型直接通信而无需中央协调器。Mixture-of-Agents(MoA)系统就是一个例子。
每个设备iii运行大语言模型MiM_iMi并维护本地提示队列Qi\mathcal{Q}_iQi。当用户在设备iii生成查询qqq时:
- MiM_iMi生成初始响应ri(0)=Mi(q)r_i^{(0)} = M_i(q)ri(0)=Mi(q)
- 设备iii向其邻居Ni\mathcal{N}_iNi广播(q,ri(0))(q, r_i^{(0)})(q,ri(0))
- 每个邻居j∈Nij \in \mathcal{N}_ij∈Ni生成自己的响应rj(0)=Mj(q)r_j^{(0)} = M_j(q)rj(0)=Mj(q)并发送回设备iii
- 设备iii收集所有响应{rj(0)}j∈Ni∪{i}\{r_j^{(0)}\}_{j \in \mathcal{N}_i \cup \{i\}}{rj(0)}j∈Ni∪{i}
- 聚合器大语言模型MaggM_{\text{agg}}Magg(可能与MiM_iMi相同)综合这些响应:
r∗=Magg(q,{rj(0)}j∈Ni∪{i})r^* = M_{\text{agg}}(q, \{r_j^{(0)}\}_{j \in \mathcal{N}_i \cup \{i\}})r∗=Magg(q,{rj(0)}j∈Ni∪{i})
- 将r∗r^*r∗返回给用户
P2P网络的拓扑结构影响性能。对于一个具有NNN个节点的网络,如果每个节点有kkk个邻居(kkk-正则图),总通信成本为O(N⋅k)O(N \cdot k)O(N⋅k)。
共识协议确保网络就最终响应达成一致。一种简单的方法是投票。每个节点iii对接收到的响应进行评分:
si(r)=ScoreMi(q,r)s_i(r) = \text{Score}_{M_i}(q, r)si(r)=ScoreMi(q,r)
响应rrr的总分为:
S(r)=∑i=1Nsi(r)S(r) = \sum_{i=1}^{N} s_i(r)S(r)=i=1∑Nsi(r)
选择分数最高的响应:
r∗=argmaxrS(r)r^* = \arg\max_r S(r)r∗=argrmaxS(r)
更复杂的共识使用迭代细化。在第ttt轮:
- 每个节点iii提议响应ri(t)r_i^{(t)}ri(t)
- 节点交换提议并计算聚合rˉ(t)=1N∑i=1Nri(t)\bar{r}^{(t)} = \frac{1}{N} \sum_{i=1}^{N} r_i^{(t)}rˉ(t)=N1∑i=1Nri(t)(在嵌入空间中)
- 每个节点更新其提议:
ri(t+1)=(1−α)ri(t)+αrˉ(t)r_i^{(t+1)} = (1 - \alpha) r_i^{(t)} + \alpha \bar{r}^{(t)}ri(t+1)=(1−α)ri(t)+αrˉ(t)
- 重复直到收敛:maxi∥ri(t+1)−ri(t)∥<ϵ\max_i \|r_i^{(t+1)} - r_i^{(t)}\| < \epsilonmaxi∥ri(t+1)−ri(t)∥<ϵ
这类似于分布式平均共识算法,收敛到所有节点的平均提议。
拜占庭容错(BFT)协议处理恶意节点。对于NNN个节点,其中最多fff个是拜占庭(恶意的),需要N≥3f+1N \geq 3f + 1N≥3f+1来实现共识。实用拜占庭容错(PBFT)算法通过三阶段(预准备、准备、提交)确保一致性:
- 预准备:主节点广播提议rrr
- 准备:每个节点验证rrr并广播准备消息
- 提交:如果节点收到至少2f+12f + 12f+1个准备消息,它广播提交消息
- 执行:如果节点收到至少2f+12f + 12f+1个提交消息,它执行(接受)rrr
对于大语言模型响应,验证可以是检查响应质量或与节点自己的预测的一致性。
协作记忆的层次化管理
协作记忆框架为每个大语言模型提出了两层记忆架构。每个边缘设备上的模型实例维护:
- 私有记忆Mipriv\mathcal{M}_i^{\text{priv}}Mipriv:用户特定交互的本地存储
- 共享记忆Mshared\mathcal{M}^{\text{shared}}Mshared:可能使其他人受益的知识
当大语言模型MiM_iMi完成查询qqq并生成响应rrr时,它决定是否共享(q,r)(q, r)(q,r):
Share(q,r)={Trueif Utility(q,r)>τshareFalseotherwise\text{Share}(q, r) = \begin{cases} \text{True} & \text{if } \text{Utility}(q, r) > \tau_{\text{share}} \\ \text{False} & \text{otherwise} \end{cases}Share(q,r)={TrueFalseif Utility(q,r)>τshareotherwise
效用函数可以基于通用性:
Utility(q,r)=1∣Mshared∣∑(q′,r′)∈MsharedSimilarity(q,q′)\text{Utility}(q, r) = \frac{1}{|\mathcal{M}^{\text{shared}}|} \sum_{(q', r') \in \mathcal{M}^{\text{shared}}} \text{Similarity}(q, q')Utility(q,r)=∣Mshared∣1(q′,r′)∈Mshared∑Similarity(q,q′)
高效用表示查询qqq与现有共享记忆中的查询相似,因此可能对其他人有用。
当处理新查询qnewq_{\text{new}}qnew时,大语言模型首先从其私有记忆和共享记忆中检索相关示例:
Epriv=TopK(Mipriv,qnew,kpriv)\mathcal{E}_{\text{priv}} = \text{TopK}(\mathcal{M}_i^{\text{priv}}, q_{\text{new}}, k_{\text{priv}})Epriv=TopK(Mipriv,qnew,kpriv)
Eshared=TopK(Mshared,qnew,kshared)\mathcal{E}_{\text{shared}} = \text{TopK}(\mathcal{M}^{\text{shared}}, q_{\text{new}}, k_{\text{shared}})Eshared=TopK(Mshared,qnew,kshared)
其中TopK\text{TopK}TopK返回与qnewq_{\text{new}}qnew最相似的kkk个示例。然后将检索到的示例连接到提示中:
Prompt=[qnew,Epriv,Eshared]\text{Prompt} = [q_{\text{new}}, \mathcal{E}_{\text{priv}}, \mathcal{E}_{\text{shared}}]Prompt=[qnew,Epriv,Eshared]
rnew=Mi(Prompt)r_{\text{new}} = M_i(\text{Prompt})rnew=Mi(Prompt)
这使得大语言模型能够利用个人历史和集体知识。
在资源受限的边缘环境中,共享记忆有大小限制∣Mshared∣≤C|\mathcal{M}^{\text{shared}}| \leq C∣Mshared∣≤C。当达到容量时,必须驱逐旧条目。驱逐策略可以基于频率和新近度:
Score(q,r)=α⋅AccessCount(q,r)+β⋅1tcurrent−tadded(q,r)\text{Score}(q, r) = \alpha \cdot \text{AccessCount}(q, r) + \beta \cdot \frac{1}{t_{\text{current}} - t_{\text{added}}(q, r)}Score(q,r)=α⋅AccessCount(q,r)+β⋅tcurrent−tadded(q,r)1
其中α\alphaα和β\betaβ是权重。分数最低的条目被驱逐。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)