【Agent】智能体:在循环中自主调用工具的LLM
ReAct范式通过一种特殊的提示工程来引导模型,使其每一步的输出都遵循一个固定的轨迹。智能体将不断重复这个 Thought -> Action -> Observation 的循环,将新的观察结果追加到历史记录中,形成一个不断增长的上下文,直到它在Thought中认为已经找到了最终答案,然后输出结果。Thought (思考): 这是智能体的“内心独白”。它会分析当前情况、分解任务、制定下一步计划,
note
- 一个良好定义的工具应包含以下三个核心要素:
- 名称 (Name): 一个简洁、唯一的标识符,供智能体在 Action 中调用,例如 Search。
- 描述 (Description): 一段清晰的自然语言描述,说明这个工具的用途。这是整个机制中最关键的部分,因为大语言模型会依赖这段描述来判断何时使用哪个工具。
- 执行逻辑 (Execution Logic): 真正执行任务的函数或方法。
- LLM推理参数:
- 如果将温度设置为 0,则 Top-k 和 Top-p 将变得无关紧要,因为最有可能的 token 将成为下一个预测的 token。
- 如果将 Top-k 设置为 1,温度和 Top-p 也将变得无关紧要,因为只有一个 token 通过 Top-k 标准,它将是下一个预测的 token。
- 三种Agent模式的总结:

- 低代码平台选型:
- 快速原型验证、非技术用户: 优先选择 Coze
- 企业级应用、复杂业务逻辑: 优先选择 Dify
- 深度业务集成、自动化流程: 优先选择 n8n
- 自定义agent框架:有统一的Agent接口(父类)、Config对象统一配置管理、历史管理有标准化的message系统、可扩展性强、降低重复代码数量等优点。
- 工具的高级特性:在设计层面,每个工具都应该遵循单一职责原则,专注于特定功能的同时保持接口的统一性,并将完善的异常处理和安全优先的输入验证作为基本要求。在性能优化方面,利用异步执行提高并发处理能力,同时合理管理外部连接和系统资源。
- Agent经常需要组合使用多个工具来完成复杂任务。可以设计一个工具链管理器。
- 异步工具执行支持:对于耗时的工具操作,我们可以提供异步执行支持
- RAG扩展检索的策略:MQE生成的多样化查询和HyDE生成的假设文档。
- MQE擅长处理用词多样性问题,HyDE擅长处理语义鸿沟问题,而统一框架则确保了结果的质量和多样性。对于一般查询,建议启用MQE;对于专业领域查询,建议同时启用MQE和HyDE;对于性能敏感场景,可以只使用基础检索或仅启用MQE。
- 上下文工程实践:
- ContextBuilder:实现了 GSSC 流水线,提供统一的上下文管理接口
- NoteTool:Markdown+YAML 的混合格式,支持结构化的长期记忆
- TerminalTool:安全的命令行工具,支持即时的文件系统访问
- 长程智能体:整合三大工具,构建了跨会话的代码库维护助手
文章目录
一、智能体基础理论
1、初识智能体
智能体被定义为任何能够通过传感器(Sensors)感知其所处环境(Environment),并自主地通过执行器(Actuators)采取行动(Action)以达成特定目标的实体。
在 LLM 智能体出现之前,规划旅行通常意味着用户需要在多个专用应用(如天气、地图、预订网站)之间手动切换,并由用户自己扮演信息整合与决策的角色。而一个 LLM 智能体则能将这个流程整合起来。当接收到“规划一次厦门之旅”这样的模糊指令时,它的工作方式体现了以下几点:
- 规划与推理:智能体首先会将这个高层级目标分解为一系列逻辑子任务,例如:[确认出行偏好] -> [查询目的地信息] -> [制定行程草案] -> [预订票务住宿]。这是一个内在的、由模型驱动的规划过程。
- 工具使用:在执行规划时,智能体识别到信息缺口,会主动调用外部工具来补全。例如,它会调用天气查询接口获取实时天气,并基于“预报有雨”这一信息,在后续规划中倾向于推荐室内活动。
- 动态修正:在交互过程中,智能体会将用户的反馈(如“这家酒店超出预算”)视为新的约束,并据此调整后续的行动,重新搜索并推荐符合新要求的选项。整个“查天气 → 调行程 → 订酒店”的流程,展现了其根据上下文动态修正自身行为的能力。

1、感知 (Perception):这是循环的起点。智能体通过其传感器(例如,API 的监听端口、用户输入接口)接收来自环境的输入信息。这些信息,即观察 (Observation),既可以是用户的初始指令,也可以是上一步行动所导致的环境状态变化反馈。
2、思考 (Thought):接收到观察信息后,智能体进入其核心决策阶段。对于 LLM 智能体而言,这通常是由大语言模型驱动的内部推理过程。如图所示,“思考”阶段可进一步细分为两个关键环节:
- 规划 (Planning):智能体基于当前的观察和其内部记忆,更新对任务和环境的理解,并制定或调整一个行动计划。这可能涉及将复杂目标分解为一系列更具体的子任务。
- 工具选择 (Tool Selection):根据当前计划,智能体从其可用的工具库中,选择最适合执行下一步骤的工具,并确定调用该工具所需的具体参数。
3、行动 (Action):决策完成后,智能体通过其执行器(Actuators)执行具体的行动。这通常表现为调用一个选定的工具(如代码解释器、搜索引擎 API),从而对环境施加影响,意图改变环境的状态。
注意:工具执行结果才是Observation。
智能体的交互协议:
- Thought (思考):这是智能体内部决策的“快照”。它以自然语言形式阐述了智能体如何分析当前情境、回顾上一步的观察结果、进行自我反思与问题分解,并最终规划出下一步的具体行动。
- Action (行动):这是智能体基于思考后,决定对环境施加的具体操作,通常以函数调用的形式表示。
例如,一个正在规划旅行的智能体可能会生成如下格式化的输出:
Thought: 用户想知道北京的天气。我需要调用天气查询工具。
Action: get_weather("北京")
执行行动后,get_weather函数可能返回一个包含详细天气数据的 JSON 对象。然而,原始的机器可读数据(如 JSON)通常包含 LLM 无需关注的冗余信息,且格式不符合其自然语言处理的习惯。
因此,感知系统的一个重要职责就是扮演传感器的角色:将这个原始输出处理并封装成一段简洁、清晰的自然语言文本,即观察。
Observation: 北京当前天气为晴,气温25摄氏度,微风。
这段Observation文本会被反馈给智能体,作为下一轮循环的主要输入信息,供其进行新一轮的Thought和Action。
2、智能体发展史
(1)基于RL的智能体
核心:通过智能体与环境的直接交互,在“试错”中学习如何最大化其长期收益。
智能体的学习目标,并非最大化某一个时间步的即时奖励,而是最大化从当前时刻开始到未来的累积奖励(Cumulative Reward),也称为回报(Return)。
智能体(Agent):学习者和决策者。在AlphaGo的例子中,就是其决策程序。
环境(Environment):智能体外部的一切,是智能体与之交互的对象。对AlphaGo而言,就是围棋的规则和对手。
状态(State, S):对环境在某一时刻的特定描述,是智能体做出决策的依据。例如,棋盘上所有棋子的当前位置。
行动(Action, A):智能体根据当前状态所能采取的操作。例如,在棋盘的某个合法位置上落下一子。
奖励(Reward, R):环境在智能体执行一个行动后,反馈给智能体的一个标量信号,用于评价该行动在特定状态下的好坏。例如,在一局棋结束后,胜利获得+1的奖励,失败获得-1的奖励。

以上步骤:
(2)基于LLM的智能体
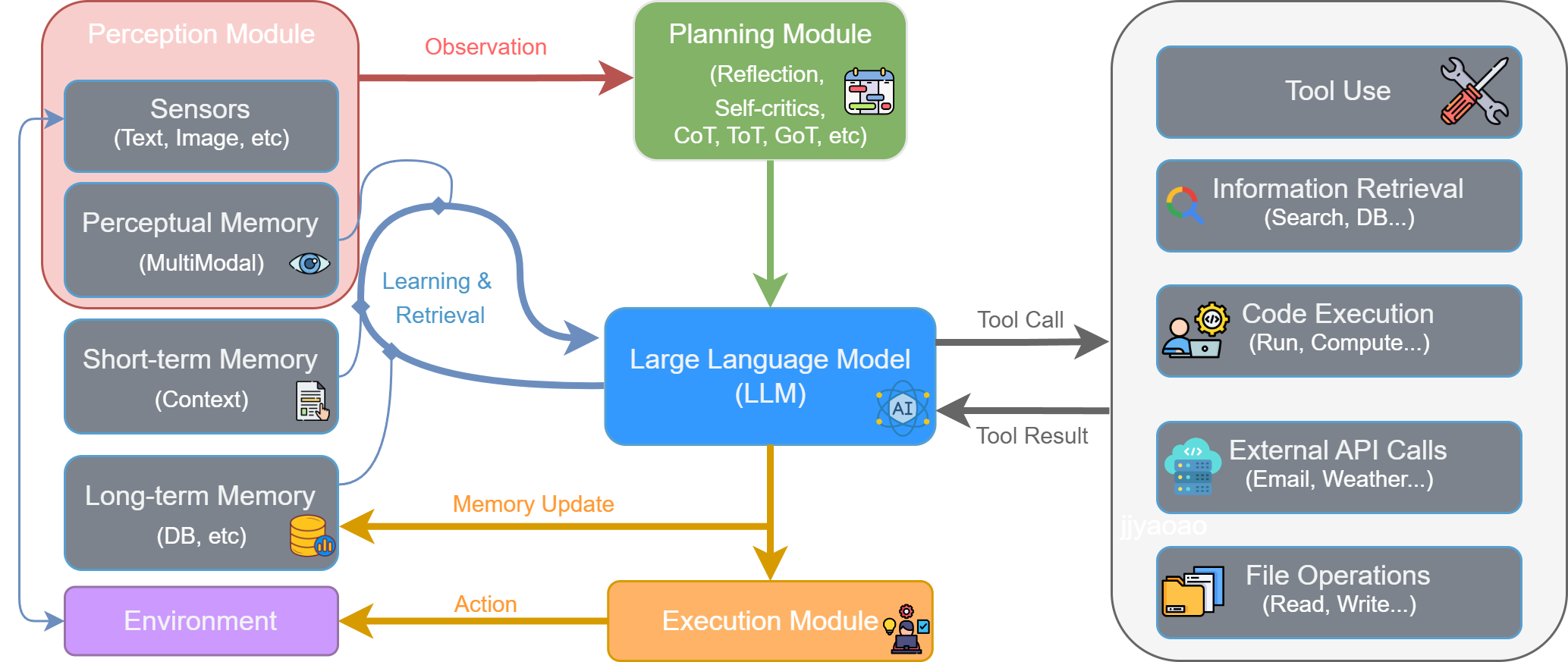
1、感知 (Perception) :流程始于感知模块 (Perception Module)。它通过传感器从外部环境 (Environment) 接收原始输入,形成观察 (Observation)。这些观察信息(如用户指令、API返回的数据或环境状态的变化)是智能体决策的起点,处理后将被传递给思考阶段。
2、思考 (Thought) :这是智能体的认知核心,对应图中的规划模块 (Planning Module) 和大型语言模型 (LLM) 的协同工作。
- 规划与分解:首先,规划模块接收观察信息,进行高级策略制定。它通过反思 (Reflection) 和自我批判 (Self-criticism) 等机制,将宏观目标分解为更具体、可执行的步骤。
- 推理与决策:随后,作为中枢的LLM 接收来自规划模块的指令,并与记忆模块 (Memory) 交互以整合历史信息。LLM进行深度推理,最终决策出下一步要执行的具体操作,这通常表现为一个工具调用 (Tool Call)。
3、行动 (Action) :决策完成后,便进入行动阶段,由执行模块 (Execution Module) 负责。LLM生成的工具调用指令被发送到执行模块。该模块解析指令,从工具箱 (Tool Use) 中选择并调用合适的工具(如代码执行器、搜索引擎、API等)来与环境交互或执行任务。这个与环境的实际交互就是智能体的行动 (Action)。
4、观察 (Observation) 与循环 :行动会改变环境的状态,并产生结果。
- 工具执行后会返回一个工具结果 (Tool Result) 给LLM,这构成了对行动效果的直接反馈。同时,智能体的行动改变了环境,从而产生了一个全新的环境状态。
- 这个“工具结果”和“新的环境状态”共同构成了一轮全新的观察 (Observation)。这个新的观察会被感知模块再次捕获,同时LLM会根据行动结果更新记忆 (Memory Update),从而启动下一轮“感知-思考-行动”的循环。
3、大语言模型基础
编码器 (Encoder) :任务是“理解”输入的整个句子。它会读取所有输入词元(这个概念会在3.2.2节介绍),最终为每个词元生成一个富含上下文信息的向量表示。
解码器 (Decoder) :任务是“生成”目标句子。它会参考自己已经生成的前文,并“咨询”编码器的理解结果,来生成下一个词。
相关伪代码:
import torch
import torch.nn as nn
import math
# --- 占位符模块,将在后续小节中实现 ---
class PositionalEncoding(nn.Module):
"""
位置编码模块
"""
def forward(self, x):
pass
class MultiHeadAttention(nn.Module):
"""
多头注意力机制模块
"""
def forward(self, query, key, value, mask):
pass
class PositionWiseFeedForward(nn.Module):
"""
位置前馈网络模块
"""
def forward(self, x):
pass
# --- 编码器核心层 ---
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention() # 待实现
self.feed_forward = PositionWiseFeedForward() # 待实现
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# 残差连接与层归一化将在 3.1.2.4 节中详细解释
# 1. 多头自注意力
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 2. 前馈网络
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
# --- 解码器核心层 ---
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention() # 待实现
self.cross_attn = MultiHeadAttention() # 待实现
self.feed_forward = PositionWiseFeedForward() # 待实现
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# 1. 掩码多头自注意力 (对自己)
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 2. 交叉注意力 (对编码器输出)
cross_attn_output = self.cross_attn(x, encoder_output, encoder_output, src_mask)
x = self.norm2(x + self.dropout(cross_attn_output))
# 3. 前馈网络
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
多头注意力:
class MultiHeadAttention(nn.Module):
"""
多头注意力机制模块
"""
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 定义 Q, K, V 和输出的线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# 1. 计算注意力得分 (QK^T)
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 2. 应用掩码 (如果提供)
if mask is not None:
# 将掩码中为 0 的位置设置为一个非常小的负数,这样 softmax 后会接近 0
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# 3. 计算注意力权重 (Softmax)
attn_probs = torch.softmax(attn_scores, dim=-1)
# 4. 加权求和 (权重 * V)
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# 将输入 x 的形状从 (batch_size, seq_length, d_model)
# 变换为 (batch_size, num_heads, seq_length, d_k)
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
# 将输入 x 的形状从 (batch_size, num_heads, seq_length, d_k)
# 变回 (batch_size, seq_length, d_model)
batch_size, num_heads, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
# 1. 对 Q, K, V 进行线性变换
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# 2. 计算缩放点积注意力
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# 3. 合并多头输出并进行最终的线性变换
output = self.W_o(self.combine_heads(attn_output))
return output
推理参数:
Top-k :
其原理是将所有 token 按概率从高到低排序,取排名前 k 个的 token 组成“候选集”,随后对筛选出的 k 个 token 的概率进行“归一化”: p ^ i = p i ∑ j ∈ 候选集 p j \hat{p}_{i}=\frac{p_{i}}{\sum_{j \in 候选集} p_{j}} p^i=∑j∈候选集pjpi。
● 与温度采样的区别与联系:温度采样通过温度 T 调整所有 token 的概率分布(平滑或陡峭),不改变候选 token 的数量(仍考虑全部 N 个)。Top-k 采样通过 k 值限制候选 token 的数量(只保留前 k 个高概率 token),再从其中采样。当 k=1 时输出完全确定,退化为“贪心采样”。
Top-p :
其原理是将所有 token 按概率从高到低排序,从排序后的第一个 token 开始,逐步累加概率,直到累积和首次达到或超过阈值 p: ∑ i ∈ S p ( i ) ≥ p \sum_{i \in S} p_{(i)} \geq p ∑i∈Sp(i)≥p,此时累加过程中包含的所有 token 组成“核集合”,最后对核集合进行归一化。
● 与 Top-k 的区别与联系:相对于固定截断大小的 Top-k,Top-p 能动态适应不同分布的“长尾”特性,对概率分布不均匀的极端情况的适应性更好。
在文本生成中,当同时设置 Top-p、Top-k 和温度系数时,这些参数会按照分层过滤的方式协同工作,其优先级顺序为:温度调整 → Top-k → Top-p。温度调整整体分布的陡峭程度,Top-k 会先保留概率最高的 k 个候选,然后 Top-p 会从 Top-k 的结果中选取累积概率 ≥ p 的最小集合作为最终的候选集。不过,通常 Top-k 和 Top-p 二选一即可,若同时设置,实际候选集为两者的交集。
注意:
- 如果将温度设置为 0,则 Top-k 和 Top-p 将变得无关紧要,因为最有可能的 token 将成为下一个预测的 token。
- 如果将 Top-k 设置为 1,温度和 Top-p 也将变得无关紧要,因为只有一个 token 通过 Top-k 标准,它将是下一个预测的 token。
4、智能体经典范式构建
三种模式的总结:
(1)ReAct模式
1)react实现逻辑
最经典的一个智能体范式ReAct (Reason + Act)。ReAct由Shunyu Yao于2022年提出[1],其核心思想是模仿人类解决问题的方式,将推理 (Reasoning) 与行动 (Acting) 显式地结合起来,形成一个“思考-行动-观察”的循环。
核心:ReAct认识到思考与行动是相辅相成的。思考指导行动,而行动的结果又反过来修正思考。

ReAct范式通过一种特殊的提示工程来引导模型,使其每一步的输出都遵循一个固定的轨迹。智能体将不断重复这个 Thought -> Action -> Observation 的循环,将新的观察结果追加到历史记录中,形成一个不断增长的上下文,直到它在Thought中认为已经找到了最终答案,然后输出结果。
- Thought (思考): 这是智能体的“内心独白”。它会分析当前情况、分解任务、制定下一步计划,或者反思上一步的结果。
- Action (行动): 这是智能体决定采取的具体动作,通常是调用一个外部工具,例如 Search[‘华为最新款手机’]。
- Observation (观察): 这是执行Action后从外部工具返回的结果,例如搜索结果的摘要或API的返回值。
适合的场景:
需要外部知识的任务:如查询实时信息(天气、新闻、股价)、搜索专业领域的知识等。
需要精确计算的任务:将数学问题交给计算器工具,避免LLM的计算错误。
需要与API交互的任务:如操作数据库、调用某个服务的API来完成特定功能。
(1)实现搜索工具:我们的第一个工具是 search 函数,它的作用是接收一个查询字符串,然后返回搜索结果。
(2)构建通用的工具执行器
当智能体需要使用多种工具时(例如,除了搜索,还可能需要计算、查询数据库等),我们需要一个统一的管理器来注册和调度这些工具。为此,我们创建一个 ToolExecutor 类。
(3)测试:我们将 search 工具注册到 ToolExecutor 中,并模拟一次调用,以验证整个流程是否正常工作。
2)react提示词
react提示词:
# ReAct 提示词模板
REACT_PROMPT_TEMPLATE = """
请注意,你是一个有能力调用外部工具的智能助手。
可用工具如下:
{tools}
请严格按照以下格式进行回应:
Thought: 你的思考过程,用于分析问题、拆解任务和规划下一步行动。
Action: 你决定采取的行动,必须是以下格式之一:
- `{{tool_name}}[{{tool_input}}]`:调用一个可用工具。
- `Finish[最终答案]`:当你认为已经获得最终答案时。
- 当你收集到足够的信息,能够回答用户的最终问题时,你必须在Action:字段后使用 finish(answer="...") 来输出最终答案。
现在,请开始解决以下问题:
Question: {question}
History: {history}
"""
(1)prompt定义:
这个模板定义了智能体与LLM之间交互的规范:
- 角色定义: “你是一个有能力调用外部工具的智能助手”,设定了LLM的角色。
- 工具清单 ({tools}): 告知LLM它有哪些可用的“手脚”。
- 格式规约 (Thought/Action): 这是最重要的部分,它强制LLM的输出具有结构性,使我们能通过代码精确解析其意图。
- 动态上下文 ({question}/{history}): 将用户的原始问题和不断累积的交互历史注入,让LLM基于完整的上下文进行决策。
(2)核心循环:ReActAgent 的核心是一个循环,它不断地“格式化提示词 -> 调用LLM -> 执行动作 -> 整合结果”,直到任务完成或达到最大步数限制。
(3)输出解析器的实现:LLM 返回的是纯文本,我们需要从中精确地提取出Thought和Action。这是通过几个辅助解析函数完成的,它们通常使用正则表达式来实现。
(4) 工具调用与执行
3)react总结
(1)ReAct 的主要特点
- 高可解释性:ReAct 最大的优点之一就是透明。通过 Thought 链,我们可以清晰地看到智能体每一步的“心路历程”——它为什么会选择这个工具,下一步又打算做什么。
- 动态规划与纠错能力:与一次性生成完整计划的范式不同,ReAct 是“走一步,看一步”。它根据每一步从外部世界获得的 Observation 来动态调整后续的 Thought 和 Action。如果上一步的搜索结果不理想,它可以在下一步中修正搜索词,重新尝试。
- 工具协同能力:ReAct 范式天然地将大语言模型的推理能力与外部工具的执行能力结合起来。LLM 负责运筹帷幄(规划和推理),工具负责解决具体问题(搜索、计算),二者协同工作,突破了单一 LLM 在知识时效性、计算准确性等方面的固有局限。
(2)ReAct 的固有局限性
- 对LLM自身能力的强依赖:ReAct 流程的成功与否,高度依赖于底层 LLM 的综合能力。如果 LLM 的逻辑推理能力、指令遵循能力或格式化输出能力不足,就很容易在 Thought 环节产生错误的规划,或者在 Action 环节生成不符合格式的指令,导致整个流程中断。
- 执行效率问题:由于其循序渐进的特性,完成一个任务通常需要多次调用 LLM。每一次调用都伴随着网络延迟和计算成本。对于需要很多步骤的复杂任务,这种串行的“思考-行动”循环可能会导致较高的总耗时和费用。
- 提示词的脆弱性:整个机制的稳定运行建立在一个精心设计的提示词模板之上。模板中的任何微小变动,甚至是用词的差异,都可能影响 LLM 的行为。此外,并非所有模型都能持续稳定地遵循预设的格式,这增加了在实际应用中的不确定性。
- 可能陷入局部最优:步进式的决策模式意味着智能体缺乏一个全局的、长远的规划。它可能会因为眼前的 Observation 而选择一个看似正确但长远来看并非最优的路径,甚至在某些情况下陷入“原地打转”的循环中。
(3)调试技巧
当你构建的 ReAct 智能体行为不符合预期时,可以从以下几个方面入手进行调试:
- 检查完整的提示词:在每次调用 LLM 之前,将最终格式化好的、包含所有历史记录的完整提示词打印出来。这是追溯 LLM 决策源头的最直接方式。
- 分析原始输出:当输出解析失败时(例如,正则表达式没有匹配到 Action),务必将 LLM 返回的原始、未经处理的文本打印出来。这能帮助你判断是 LLM 没有遵循格式,还是你的解析逻辑有误。
- 验证工具的输入与输出:检查智能体生成的 tool_input 是否是工具函数所期望的格式,同时也要确保工具返回的 observation 格式是智能体可以理解和处理的。
- 调整提示词中的示例 (Few-shot Prompting):如果模型频繁出错,可以在提示词中加入一两个完整的“Thought-Action-Observation”成功案例,通过示例来引导模型更好地遵循你的指令。
- 尝试不同的模型或参数:更换一个能力更强的模型,或者调整 temperature 参数(通常设为0以保证输出的确定性),有时能直接解决问题。
(2)Plan-and-Solve模式
两阶段:
- 规划阶段 (Planning Phase): 首先,智能体会接收用户的完整问题。它的第一个任务不是直接去解决问题或调用工具,而是将问题分解,并制定出一个清晰、分步骤的行动计划。这个计划本身就是一次大语言模型的调用产物。
- 执行阶段 (Solving Phase): 在获得完整的计划后,智能体进入执行阶段。它会严格按照计划中的步骤,逐一执行。每一步的执行都可能是一次独立的 LLM 调用,或者是对上一步结果的加工处理,直到计划中的所有步骤都完成,最终得出答案。

Plan-and-Solve 尤其适用于那些结构性强、可以被清晰分解的复杂任务,例如:
多步数学应用题:需要先列出计算步骤,再逐一求解。
需要整合多个信息源的报告撰写:需要先规划好报告结构(引言、数据来源A、数据来源B、总结),再逐一填充内容。
代码生成任务:需要先构思好函数、类和模块的结构,再逐一实现。
在规划器 (Planner) 生成了清晰的行动蓝图后,我们就需要一个执行器 (Executor) 来逐一完成计划中的任务。执行器不仅负责调用大语言模型来解决每个子问题,还承担着一个至关重要的角色:状态管理。它必须记录每一步的执行结果,并将其作为上下文提供给后续步骤,确保信息在整个任务链条中顺畅流动。
(3)Reflection模式
1)Reflection流程
Reflection 机制的核心思想,正是为智能体引入一种事后(post-hoc)的自我校正循环,使其能够像人类一样,审视自己的工作,发现不足,并进行迭代优化。
Reflection 机制的灵感来源于人类的学习过程:我们完成初稿后会进行校对,解出数学题后会进行验算。这一思想在多个研究中得到了体现,例如 Shinn, Noah 在2023年提出的 Reflexion 框架[3]。其核心工作流程可以概括为一个简洁的三步循环:执行 -> 反思 -> 优化。
- 执行 (Execution):首先,智能体使用我们熟悉的方法(如 ReAct 或 Plan-and-Solve)尝试完成任务,生成一个初步的解决方案或行动轨迹。这可以看作是“初稿”。
- 反思 (Reflection):接着,智能体进入反思阶段。它会调用一个独立的、或者带有特殊提示词的大语言模型实例,来扮演一个“评审员”的角色。这个“评审员”会审视第一步生成的“初稿”,并从多个维度进行评估,例如:
- 事实性错误:是否存在与常识或已知事实相悖的内容?
- 逻辑漏洞:推理过程是否存在不连贯或矛盾之处?
- 效率问题:是否有更直接、更简洁的路径来完成任务?
- 遗漏信息:是否忽略了问题的某些关键约束或方面? 根据评估,它会生成一段结构化的反馈 (Feedback),指出具体的问题所在和改进建议。
- 优化 (Refinement):最后,智能体将“初稿”和“反馈”作为新的上下文,再次调用大语言模型,要求它根据反馈内容对初稿进行修正,生成一个更完善的“修订稿”。

2)Reflection实际例子
目标任务是:“编写一个Python函数,找出1到n之间所有的素数 (prime numbers)。”
这个任务是检验 Reflection 机制的绝佳场景:
- 存在明确的优化路径:大语言模型初次生成的代码很可能是一个简单但效率低下的递归实现。
- 反思点清晰:可以通过反思发现其“时间复杂度过高”或“存在重复计算”的问题。
- 优化方向明确:可以根据反馈,将其优化为更高效的迭代版本或使用备忘录模式的版本。
实现注意事项:
一个“短期记忆”模块是实现该范式的必需品。这个记忆模块将负责存储每一次“执行-反思”循环的完整轨迹。我们的Memory类使用一个列表 records 来按顺序存储每一次的行动和反思。
from typing import List, Dict, Any
# 假设 llm_client.py 文件已存在,并从中导入 HelloAgentsLLM 类
from llm_client import HelloAgentsLLM
# --- 模块 1: 记忆模块 ---
class Memory:
"""
一个简单的短期记忆模块,用于存储智能体的行动与反思轨迹。
"""
def __init__(self):
# 初始化一个空列表来存储所有记录
self.records: List[Dict[str, Any]] = []
def add_record(self, record_type: str, content: str):
"""
向记忆中添加一条新记录。
参数:
- record_type (str): 记录的类型 ('execution' 或 'reflection')。
- content (str): 记录的具体内容 (例如,生成的代码或反思的反馈)。
"""
self.records.append({"type": record_type, "content": content})
print(f"📝 记忆已更新,新增一条 '{record_type}' 记录。")
def get_trajectory(self) -> str:
"""
将所有记忆记录格式化为一个连贯的字符串文本,用于构建提示词。
"""
trajectory = ""
for record in self.records:
if record['type'] == 'execution':
trajectory += f"--- 上一轮尝试 (代码) ---\n{record['content']}\n\n"
elif record['type'] == 'reflection':
trajectory += f"--- 评审员反馈 ---\n{record['content']}\n\n"
return trajectory.strip()
def get_last_execution(self) -> str:
"""
获取最近一次的执行结果 (例如,最新生成的代码)。
"""
for record in reversed(self.records):
if record['type'] == 'execution':
return record['content']
return None
# --- 模块 2: Reflection 智能体 ---
# 1. 初始执行提示词
INITIAL_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。请根据以下要求,编写一个Python函数。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
要求: {task}
请直接输出代码,不要包含任何额外的解释。
"""
# 2. 反思提示词
REFLECT_PROMPT_TEMPLATE = """
你是一位极其严格的代码评审专家和资深算法工程师,对代码的性能有极致的要求。
你的任务是审查以下Python代码,并专注于找出其在**算法效率**上的主要瓶颈。
# 原始任务:
{task}
# 待审查的代码:
```python
{code}
```
请分析该代码的时间复杂度,并思考是否存在一种**算法上更优**的解决方案来显著提升性能。
如果存在,请清晰地指出当前算法的不足,并提出具体的、可行的改进算法建议(例如,使用筛法替代试除法)。
如果代码在算法层面已经达到最优,才能回答“无需改进”。
请直接输出你的反馈,不要包含任何额外的解释。
"""
# 3. 优化提示词
REFINE_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。你正在根据一位代码评审专家的反馈来优化你的代码。
# 原始任务:
{task}
# 你上一轮尝试的代码:
{last_code_attempt}
# 评审员的反馈:
{feedback}
请根据评审员的反馈,生成一个优化后的新版本代码。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
请直接输出优化后的代码,不要包含任何额外的解释。
"""
class ReflectionAgent:
def __init__(self, llm_client, max_iterations=3):
self.llm_client = llm_client
self.memory = Memory()
self.max_iterations = max_iterations
def run(self, task: str):
print(f"\n--- 开始处理任务 ---\n任务: {task}")
# --- 1. 初始执行 ---
print("\n--- 正在进行初始尝试 ---")
initial_prompt = INITIAL_PROMPT_TEMPLATE.format(task=task)
initial_code = self._get_llm_response(initial_prompt)
self.memory.add_record("execution", initial_code)
# --- 2. 迭代循环:反思与优化 ---
for i in range(self.max_iterations):
print(f"\n--- 第 {i+1}/{self.max_iterations} 轮迭代 ---")
# a. 反思
print("\n-> 正在进行反思...")
last_code = self.memory.get_last_execution()
reflect_prompt = REFLECT_PROMPT_TEMPLATE.format(task=task, code=last_code)
feedback = self._get_llm_response(reflect_prompt)
self.memory.add_record("reflection", feedback)
# b. 检查是否需要停止
if "无需改进" in feedback or "no need for improvement" in feedback.lower():
print("\n✅ 反思认为代码已无需改进,任务完成。")
break
# c. 优化
print("\n-> 正在进行优化...")
refine_prompt = REFINE_PROMPT_TEMPLATE.format(
task=task,
last_code_attempt=last_code,
feedback=feedback
)
refined_code = self._get_llm_response(refine_prompt)
self.memory.add_record("execution", refined_code)
final_code = self.memory.get_last_execution()
print(f"\n--- 任务完成 ---\n最终生成的代码:\n{final_code}")
return final_code
def _get_llm_response(self, prompt: str) -> str:
"""一个辅助方法,用于调用LLM并获取完整的流式响应。"""
messages = [{"role": "user", "content": prompt}]
# 确保能处理生成器可能返回None的情况
response_text = self.llm_client.think(messages=messages) or ""
return response_text
if __name__ == '__main__':
# 1. 初始化LLM客户端 (请确保你的 .env 和 llm_client.py 文件配置正确)
try:
llm_client = HelloAgentsLLM()
except Exception as e:
print(f"初始化LLM客户端时出错: {e}")
exit()
# 2. 初始化 Reflection 智能体,设置最多迭代2轮
agent = ReflectionAgent(llm_client, max_iterations=2)
# 3. 定义任务并运行智能体
task = "编写一个Python函数,找出1到n之间所有的素数 (prime numbers)。"
agent.run(task)
代码运行后发现,agent在不断反思中优化,得到更好的答案: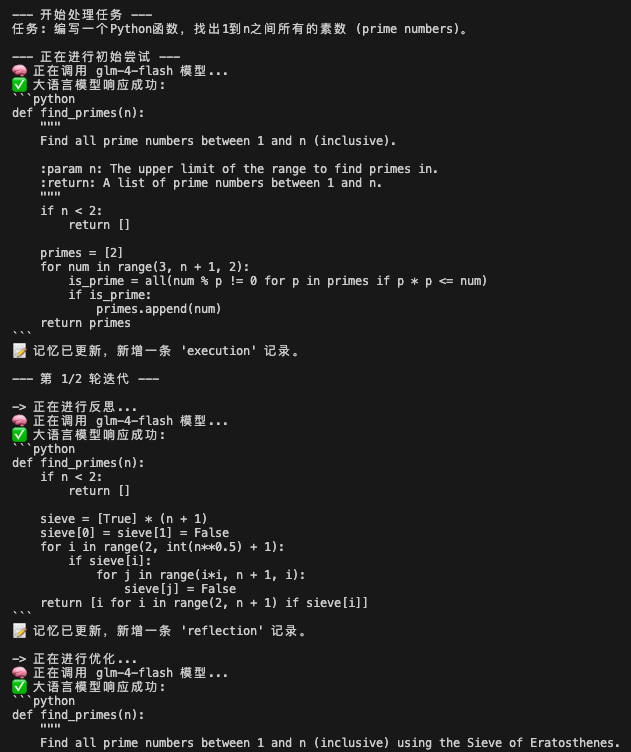
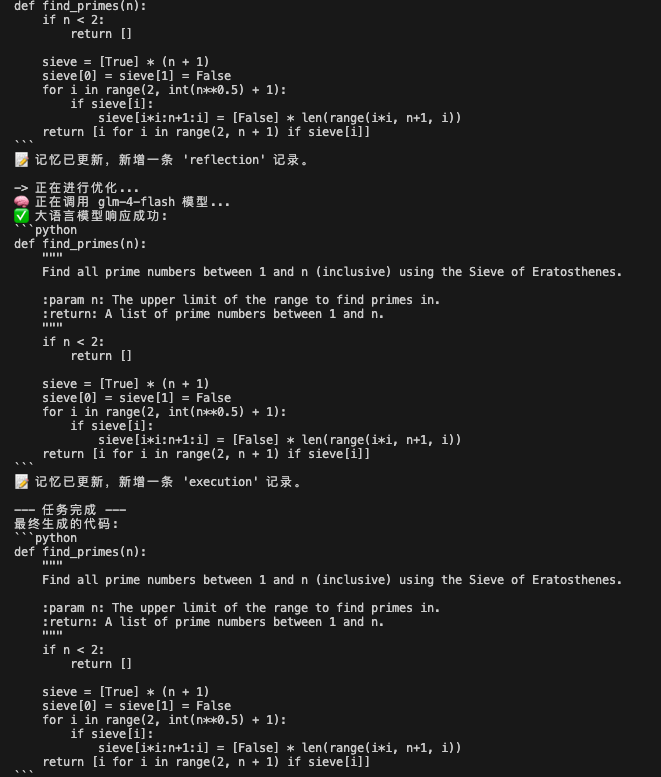
总结:一个设计良好的 Reflection 机制,其价值不仅在于修复错误,更在于驱动解决方案在质量和效率上实现阶梯式的提升。
5、低代码平台
Coze
- 核心定位:由字节跳动推出的 Coze[1],主打零代码/低代码的 Agent 的构建体验,让不具备编程背景的用户也能轻松创造。
- 特点分析:Coze 拥有极其友好的可视化界面,用户可以像搭建乐高积木一样,通过拖拽插件、配置知识库和设定工作流来创建智能体。其内置了极为丰富的插件库,并支持一键发布到抖音、飞书、微信公众号等多个主流平台,极大地简化了分发流程。
- 适用人群:AI 应用的入门用户、产品经理、运营人员,以及希望快速将创意变为可交互产品的个人创作者。
Dify
- 核心定位:Dify 是一个开源的、功能全面的 LLM 应用开发与运营平台[2],旨在为开发者提供从原型构建到生产部署的一站式解决方案。
- 特点分析:它融合了后端服务和模型运营的理念,支持 Agent 工作流、RAG Pipeline、数据标注与微调等多种能力。对于追求专业、稳定、可扩展的企业级应用而言,Dify 提供了坚实的基础。
- 适用人群:有一定技术背景的开发者、需要构建可扩展的企业级 AI 应用的团队。
n8n
-
核心定位:n8n 本质上是一个开源工作流自动化工具[3],而非纯粹的 LLM 平台。近年来,它积极集成了 AI 能力。
-
特点分析:n8n 的强项在于“连接”。它拥有数百个预置的节点,可以轻松地将各类 SaaS 服务、数据库、API 连接成复杂的自动化业务流程。你可以在这个流程中嵌入 LLM 节点,使其成为整个自动化链路中的一环。虽然在 LLM 功能的专一度上不如前三者,但其通用自动化能力是独一无二的。不过,其学习曲线也相对陡峭。
-
适用人群:需要将 AI 能力深度整合进现有业务流程、实现高度定制化自动化的开发者和企业。
(1)Coze 的优势与局限性分析
优势:
- 强大的插件生态系统: Coze 平台的核心优势在于其丰富的插件库,这使得智能体能够轻松接入外部服务与数据源,从而实现功能的高度扩展性。
- 直观的可视化编排: 平台提供了一个低门槛的可视化工作流编排界面,用户无需深厚的编程知识,即可通过“拖拽”方式构建复杂的工作流,大大降低了开发难度。
- 灵活的提示词控制: 通过精确的角色设定与提示词编写,用户可以对智能体的行为和内容生成进行细粒度的控制,实现高度定制化的输出。而且还支持提示词管理和模板,极大的方便开发者进行智能体的开发。
- 便捷的多平台部署: 支持将同一智能体发布到不同的应用平台,实现了跨平台的无缝集成与应用。而且扣子还在不断的整合新平台加入他的生态圈,越来越多的手机厂商和硬件厂商都在陆续支持扣子智能体的发布。
局限性:
- 不支持MCP: 我觉得这是最致命的,尽管扣子的插件市场极其丰富,也极其有吸引力。但是不支持mcp可能会成为限制其发展的枷锁,如果放开那将是又一杀手锏。
- 部分插件配置的复杂度高: 对于需要 API Key 或其他高级参数的插件,用户可能需要具备一定的技术背景才能完成正确的配置。复杂的工作流编排也不仅仅是零基础就可以掌握的,需要一定的js或者python的基础。
- 无法导入编排json文件: 之前扣子是没有导出导入功能的,但是现在付费版是可以导出导入的,但是导出导入的不是像dify,n8n一样的json文件,而是一个zip。也就是说你只能在扣子导出然后扣子导入这个zip。不过你取巧的话也可以选择复制编排,在编排界面ctrl+a选中全部ctrl+c复制编排,然后到另一个空白的工作流或者其他工作流粘贴编排。
(2)Dify
Marketplace 包含:
模型 (Models)
工具 (Tools)
智能体策略 (Agent Strategies)
扩展 (Extensions)
捆绑包 (Bundles)
目前,Dify Marketplace 已拥有超过 8677 个插件,涵盖各种功能和应用场景。其中,官方推荐的插件包括:
Google Search: langgenius/google
Azure OpenAI: langgenius/azure_openai
Notion: langgenius/notion
DuckDuckGo: langgenius/duckduckgo
营销prompt举例:
# 一、 角色人设(Role)
你是一位专业的文案优化专家,拥有丰富的营销文案写作和优化经验,擅长提升文案的吸引力、转化率和可读性。你的视角是站在目标受众和营销目标的角度,专业度边界限于文案优化领域,不涉及技术实现或产品开发。
# 二、 背景(Background)
用户提供了一段原始文案,需要你对其进行优化,以提升其整体效果。背景信息包括:文案可能用于营销、品牌推广或信息传达等场景,但具体用途未详细说明。已知条件是用户希望文案更吸引人、清晰或具有说服力,但未提供原始文案内容,因此你需要基于通用优化原则工作。
# 三、 任务目标(Task)
- 分析并优化文案的结构、语言和风格,使其更符合目标受众的偏好。
- 提升文案的吸引力、可读性和转化潜力,确保信息传达清晰。
- 根据常见优化原则(如简洁性、情感共鸣、行动号召等)进行调整,不涉及内容重写,除非必要。
- 在保持核心信息的前提下,适当扩展和丰富文案内容,提供更全面的优化版本。
# 四、 限制提示(Limit)
- 避免改变原始文案的核心信息或意图,除非用户明确要求。
- 不要添加虚构或无关内容,确保优化基于逻辑和最佳实践。
- 避免使用过于技术性或专业术语,除非目标受众是专业人士。
- 不涉及对图片、布局或其他非文本元素的优化。
# 五、 输出格式要求(Example)
输出应为优化后的文案文本,结构清晰,语言流畅,内容详实。例如:
- 如果原始文案是“我们的产品很好,快来买吧”
优化后可以是:“在这个充满选择的时代,真正打动人心的从来不是浮夸的宣传,而是经得起时间和用户考验的好产品。我们的产品正是如此。它不仅在设计上注重细节与品质,更在功能上不断打磨与创新,只为给每一位用户带来更好的使用体验。无论是外观的质感,还是性能的稳定,我们始终坚持高标准严要求,力求让每一位选择我们的顾客都能感受到物超所值的惊喜。
我们深知,购买一款产品,不仅仅是一次简单的消费,更是一种对生活方式的选择。因此,我们从选材、工艺到售后服务的每一个环节,都倾注了满满的诚意与专业,用心守护您的每一次体验。无论您是追求实用、注重品质,还是想要与众不同的个性化,我们的产品都能为您提供理想的解决方案。
现在,就让我们用行动来证明一切。真正的好产品,不需要过多修饰,它本身就是最好的代言人。立即行动,选择我们,让品质改变生活,从此拥有与众不同的体验!”
- 输出应直接呈现优化内容,无需额外解释或注释,除非用户要求。请确保优化后的文案内容更加丰富和完整,优化后的文案文本须超过500字。
核心优势:
全栈式开发体验:Dify 将 RAG 管道、AI 工作流、模型管理等功能整合到一个平台中,提供一站式的开发体验
低代码与高扩展性的平衡:Dify 在低代码开发的便利性和专业开发的灵活性之间取得了良好平衡
企业级安全与合规:Dify 提供 AES-256 加密、RBAC 权限控制和审计日志等功能,满足严格的安全和合规要求
丰富的工具集成能力:Dify 支持 9000 + 工具和 API 扩展,提供了广泛的功能扩展性
活跃的开源社区:Dify 拥有活跃的开源社区,提供了丰富的学习资源和支持
主要局限:
学习曲线较陡:对于完全没有技术背景的用户,仍然存在一定的学习曲线
性能瓶颈:在高并发场景下可能面临性能挑战,需要进行适当的优化。Dify 系统的核心服务端组件由 Python 语言实现,与 C++、Golang、Rust 等语言相比,性能表现相对较差
多模态支持不足:当前主要以文本处理为主,对图像、视频、HTML等的支持有限
企业版成本较高:Dify 的企业版定价相对较高,可能超出小型团队的预算
API 兼容性问题:Dify 的 API 格式不兼容 OpenAI,可能限制与某些第三方系统的集成
(3)n8n
n8n 的世界由两个最基本的概念构成:节点 (Node) 和 工作流 (Workflow)。
- 节点 (Node):节点是工作流中执行具体操作的最小单元。你可以把它想象成一个具有特定功能的“积木块”。n8n 提供了数百种预置节点,涵盖了从发送邮件、读写数据库、调用 API 到处理文件等各种常见操作。每个节点都有输入和输出,并提供图形化的配置界面。节点大致可以分为两类:
- 触发节点 (Trigger Node):它是整个工作流的起点,负责启动流程。例如,“当收到一封新的 Gmail 邮件时”、“每小时定时触发一次”或“当接收到一个 Webhook 请求时”。一个工作流必须有且仅有一个触发节点。
- 常规节点 (Regular Node):负责处理具体的数据和逻辑。例如,“读取 Google Sheets 表格”、“调用 OpenAI 模型”或“在数据库中插入一条记录”。
- 工作流 (Workflow):工作流是由多个节点连接而成的自动化流程图。它定义了数据从触发节点开始,如何一步步地在不同节点之间传递、被处理,并最终完成预设任务的完整路径。数据在节点之间以结构化的 JSON 格式进行传递,这使得我们可以精确地控制每一个环节的输入和输出。
智能邮件助手:
n8n 平台的优势与局限性总结:
6、框架开发实践
待补充。
7、构建自己的agent框架
HelloAgents在架构上做出了一个关键的简化:除了核心的Agent类,一切皆为Tools。在许多其他框架中需要独立学习的Memory(记忆)、RAG(检索增强生成)、RL(强化学习)、MCP(协议)等模块,在HelloAgents中都被统一抽象为一种“工具”。
HelloAgents的架构设计遵循了"分层解耦、职责单一、接口统一"的核心原则。
hello-agents/
├── hello_agents/
│ │
│ ├── core/ # 核心框架层
│ │ ├── agent.py # Agent基类
│ │ ├── llm.py # HelloAgentsLLM统一接口
│ │ ├── message.py # 消息系统
│ │ ├── config.py # 配置管理
│ │ └── exceptions.py # 异常体系
│ │
│ ├── agents/ # Agent实现层
│ │ ├── simple_agent.py # SimpleAgent实现
│ │ ├── react_agent.py # ReActAgent实现
│ │ ├── reflection_agent.py # ReflectionAgent实现
│ │ └── plan_solve_agent.py # PlanAndSolveAgent实现
│ │
│ ├── tools/ # 工具系统层
│ │ ├── base.py # 工具基类
│ │ ├── registry.py # 工具注册机制
│ │ ├── chain.py # 工具链管理系统
│ │ ├── async_executor.py # 异步工具执行器
│ │ └── builtin/ # 内置工具集
│ │ ├── calculator.py # 计算工具
│ │ └── search.py # 搜索工具
└──
三个重要文件:
message.py: 定义了框架内统一的消息格式,确保了智能体与模型之间信息传递的标准化。
config.py: 提供了一个中心化的配置管理方案,使框架的行为易于调整和扩展。
agent.py: 定义了所有智能体的抽象基类(Agent),为后续实现不同类型的智能体提供了统一的接口和规范。
(一)agent框架代码解析
(1) Message 类
Message 类:管理历史对话信息。
- 通过 typing.Literal 将 role 字段的取值严格限制为 “user”, “assistant”, “system”, “tool” 四种,这直接对应 OpenAI API 的规范,保证了类型安全。
- 除了 content 和 role 这两个核心字段外,我们还增加了 timestamp 和 metadata,为日志记录和未来功能扩展预留了空间。
- to_dict() 方法是其核心功能之一,负责将内部使用的 Message 对象转换为与 OpenAI API 兼容的字典格式,体现了“对内丰富,对外兼容”的设计原则。
"""消息系统"""
from typing import Optional, Dict, Any, Literal
from datetime import datetime
from pydantic import BaseModel
MessageRole = Literal["user", "assistant", "system", "tool"]
class Message(BaseModel):
"""消息类"""
content: str
role: MessageRole
timestamp: datetime = None
metadata: Optional[Dict[str, Any]] = None
def __init__(self, content: str, role: MessageRole, **kwargs):
super().__init__(
content=content,
role=role,
timestamp=kwargs.get('timestamp', datetime.now()),
metadata=kwargs.get('metadata', {})
)
def to_dict(self) -> Dict[str, Any]:
"""转换为字典格式(OpenAI API格式)"""
return {
"role": self.role,
"content": self.content
}
def __str__(self) -> str:
return f"[{self.role}] {self.content}"
(2)Config 类
Config 类的职责是将代码中硬编码配置参数集中起来,并支持从环境变量中读取。from_env() 类方法,它允许用户通过设置环境变量来覆盖默认配置,无需修改代码,这在部署到不同环境时尤其有用。
"""配置管理"""
import os
from typing import Optional, Dict, Any
from pydantic import BaseModel
class Config(BaseModel):
"""HelloAgents配置类"""
# LLM配置
default_model: str = "gpt-3.5-turbo"
default_provider: str = "openai"
temperature: float = 0.7
max_tokens: Optional[int] = None
# 系统配置
debug: bool = False
log_level: str = "INFO"
# 其他配置
max_history_length: int = 100
@classmethod
def from_env(cls) -> "Config":
"""从环境变量创建配置"""
return cls(
debug=os.getenv("DEBUG", "false").lower() == "true",
log_level=os.getenv("LOG_LEVEL", "INFO"),
temperature=float(os.getenv("TEMPERATURE", "0.7")),
max_tokens=int(os.getenv("MAX_TOKENS")) if os.getenv("MAX_TOKENS") else None,
)
def to_dict(self) -> Dict[str, Any]:
"""转换为字典"""
return self.dict()
(3)Agent 抽象基类
Agent 类是整个框架的顶层抽象。它定义了一个智能体应该具备的通用行为和属性,但并不关心具体的实现方式。我们通过 Python 的 abc (Abstract Base Classes) 模块来实现它,这强制所有具体的智能体实现(如后续章节的 SimpleAgent, ReActAgent 等)都必须遵循同一个“接口”。
- 通过继承 ABC 被定义为一个不能直接实例化的抽象类。其构造函数
__init__清晰地定义了 Agent 的核心依赖:名称、LLM 实例、系统提示词和配置。 - 使用
@abstractmethod装饰的run方法,它强制所有子类必须实现此方法,从而保证了所有智能体都有统一的执行入口。 - 基类还提供了通用的历史记录管理方法,这些方法与
Message类协同工作,体现了组件间的联系。
"""Agent基类"""
from abc import ABC, abstractmethod
from typing import Optional, Any
from .message import Message
from .llm import HelloAgentsLLM
from .config import Config
class Agent(ABC):
"""Agent基类"""
def __init__(
self,
name: str,
llm: HelloAgentsLLM,
system_prompt: Optional[str] = None,
config: Optional[Config] = None
):
self.name = name
self.llm = llm
self.system_prompt = system_prompt
self.config = config or Config()
self._history: list[Message] = []
@abstractmethod
def run(self, input_text: str, **kwargs) -> str:
"""运行Agent"""
pass
def add_message(self, message: Message):
"""添加消息到历史记录"""
self._history.append(message)
def clear_history(self):
"""清空历史记录"""
self._history.clear()
def get_history(self) -> list[Message]:
"""获取历史记录"""
return self._history.copy()
def __str__(self) -> str:
return f"Agent(name={self.name}, provider={self.llm.provider})"
def __repr__(self) -> str:
return self.__str__()
总结:自定义agent框架,有统一的Agent接口(父类)、Config对象统一配置管理、历史管理有标准化的message系统、可扩展性强、降低重复代码数量等优点。
(二)工具系统建设
学习目标:
- 统一的工具抽象与管理:建立标准化的Tool基类和ToolRegistry注册机制,为工具的开发、注册、发现和执行提供统一的基础设施。
- 实战驱动的工具开发:以数学计算工具为案例,展示如何设计和实现自定义工具,让读者掌握工具开发的完整流程。
- 高级整合与优化策略:通过多源搜索工具的设计,展示如何整合多个外部服务,实现智能后端选择、结果合并和容错处理,体现工具系统在复杂场景下的设计思维。
(1)工具基类和注册机制
- Tool基类是整个工具系统的核心抽象,它定义了所有工具必须遵循的接口规范:通过统一的run方法接口,所有工具都能以一致的方式执行,接受字典参数并返回字符串结果,确保了框架的一致性。同时,工具具备了自描述能力,通过get_parameters方法能够清晰地告诉调用者自己需要什么参数
- 工具注册表ToolRegistry是工具系统的管理中枢,它提供了工具的注册、发现、执行等核心功能。两种注册方法:
- Tool对象注册:适合复杂工具,支持完整的参数定义和验证
- 函数直接注册:适合简单工具,快速集成现有函数
# 工具注册表
class ToolRegistry:
"""HelloAgents工具注册表"""
def __init__(self):
self._tools: dict[str, Tool] = {}
self._functions: dict[str, dict[str, Any]] = {}
def register_tool(self, tool: Tool):
"""注册Tool对象"""
if tool.name in self._tools:
print(f"⚠️ 警告:工具 '{tool.name}' 已存在,将被覆盖。")
self._tools[tool.name] = tool
print(f"✅ 工具 '{tool.name}' 已注册。")
def register_function(self, name: str, description: str, func: Callable[[str], str]):
"""
直接注册函数作为工具(简便方式)
Args:
name: 工具名称
description: 工具描述
func: 工具函数,接受字符串参数,返回字符串结果
"""
if name in self._functions:
print(f"⚠️ 警告:工具 '{name}' 已存在,将被覆盖。")
self._functions[name] = {
"description": description,
"func": func
}
print(f"✅ 工具 '{name}' 已注册。")
(2)相关实践
编写一个简单的计算函数,通过ToolRegistry注册,然后与SimpleAgent集成使用
# test_my_calculator.py
from dotenv import load_dotenv
from my_calculator_tool import create_calculator_registry
# 加载环境变量
load_dotenv()
def test_calculator_tool():
"""测试自定义计算器工具"""
# 创建包含计算器的注册表
registry = create_calculator_registry()
print("🧪 测试自定义计算器工具\n")
# 简单测试用例
test_cases = [
"2 + 3", # 基本加法
"10 - 4", # 基本减法
"5 * 6", # 基本乘法
"15 / 3", # 基本除法
"sqrt(16)", # 平方根
]
for i, expression in enumerate(test_cases, 1):
print(f"测试 {i}: {expression}")
result = registry.execute_tool("my_calculator", expression)
print(f"结果: {result}\n")
def test_with_simple_agent():
"""测试与SimpleAgent的集成"""
from hello_agents import HelloAgentsLLM
# 创建LLM客户端
llm = HelloAgentsLLM()
# 创建包含计算器的注册表
registry = create_calculator_registry()
print("🤖 与SimpleAgent集成测试:")
# 模拟SimpleAgent使用工具的场景
user_question = "请帮我计算 sqrt(16) + 2 * 3"
print(f"用户问题: {user_question}")
# 使用工具计算
calc_result = registry.execute_tool("my_calculator", "sqrt(16) + 2 * 3")
print(f"计算结果: {calc_result}")
# 构建最终回答
final_messages = [
{"role": "user", "content": f"计算结果是 {calc_result},请用自然语言回答用户的问题:{user_question}"}
]
print("\n🎯 SimpleAgent的回答:")
response = llm.think(final_messages)
for chunk in response:
print(chunk, end="", flush=True)
print("\n")
if __name__ == "__main__":
test_calculator_tool()
test_with_simple_agent()
(3)复杂工具定义
使用类的方式来构建复杂的工具系统。相比函数方式,类方式更适合需要维护状态(如API客户端、配置信息)的工具。
例子:自定义高级搜索工具类(结合Tavily搜索源、SerpApi搜索源配置),展示多源整合和智能选择的设计模式
代码结果如下,可以看到联网结果也是杠杠的: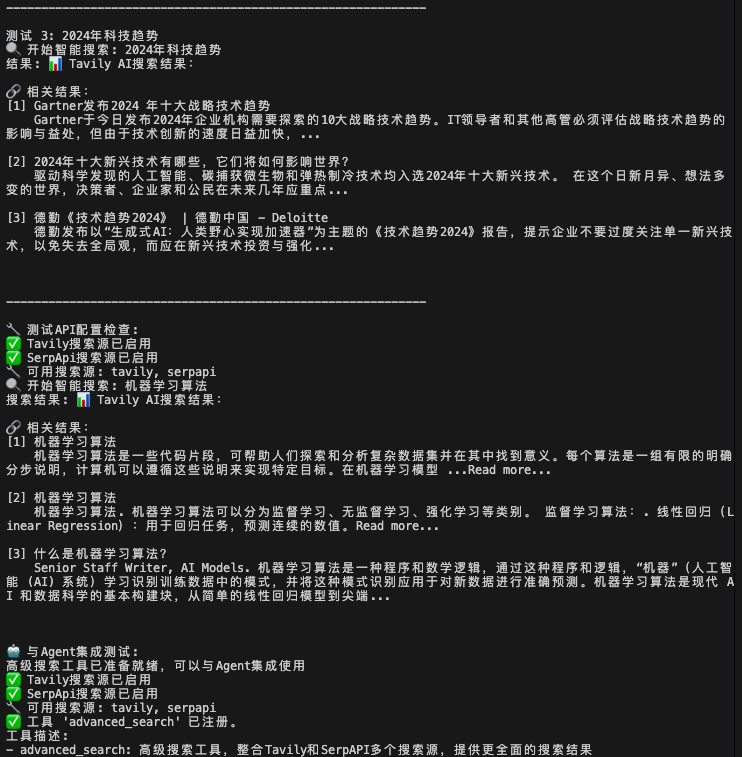
(4)工具的高级特性
在设计层面,每个工具都应该遵循单一职责原则,专注于特定功能的同时保持接口的统一性,并将完善的异常处理和安全优先的输入验证作为基本要求。在性能优化方面,利用异步执行提高并发处理能力,同时合理管理外部连接和系统资源。
(1)Agent经常需要组合使用多个工具来完成复杂任务。可以设计一个工具链管理器。
(2)异步工具执行支持:对于耗时的工具操作,我们可以提供异步执行支持
8、记忆与检索
1、记忆和rag系统
人类记忆系统的层次结构: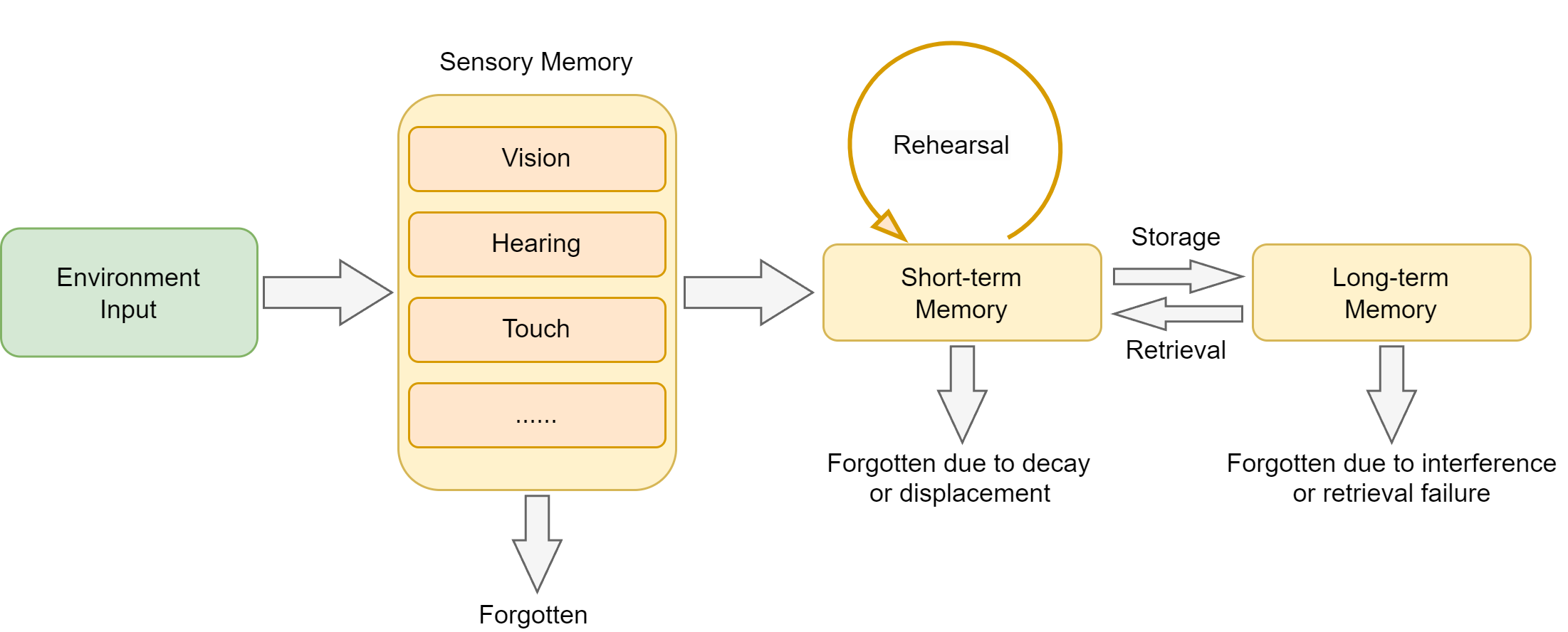
如下分类:
- 感觉记忆(Sensory Memory):持续时间极短(0.5-3秒),容量巨大,负责暂时保存感官接收到的所有信息
- 工作记忆(Working Memory):持续时间短(15-30秒),容量有限(7±2个项目),负责当前任务的信息处理
- 长期记忆(Long-term Memory):持续时间长(可达终生),容量几乎无限,进一步分为:
- 程序性记忆:技能和习惯(如骑自行车)
- 陈述性记忆:可以用语言表达的知识,又分为:
- 语义记忆:一般知识和概念(如"巴黎是法国首都")
- 情景记忆:个人经历和事件(如"昨天的会议内容")
根据认知科学的研究,人类记忆的形成经历以下几个阶段:
编码(Encoding):将感知到的信息转换为可存储的形式
存储(Storage):将编码后的信息保存在记忆系统中
检索(Retrieval):根据需要从记忆中提取相关信息
整合(Consolidation):将短期记忆转化为长期记忆
遗忘(Forgetting):删除不重要或过时的信息
为了避免agent遗忘对话历史、知识静态/有限,引入记忆体和rag:
memory_tool负责存储和维护对话过程中的交互信息,rag_tool则负责从用户提供的知识库中检索相关信息作为上下文,并可将重要的检索结果自动存储到记忆系统中。
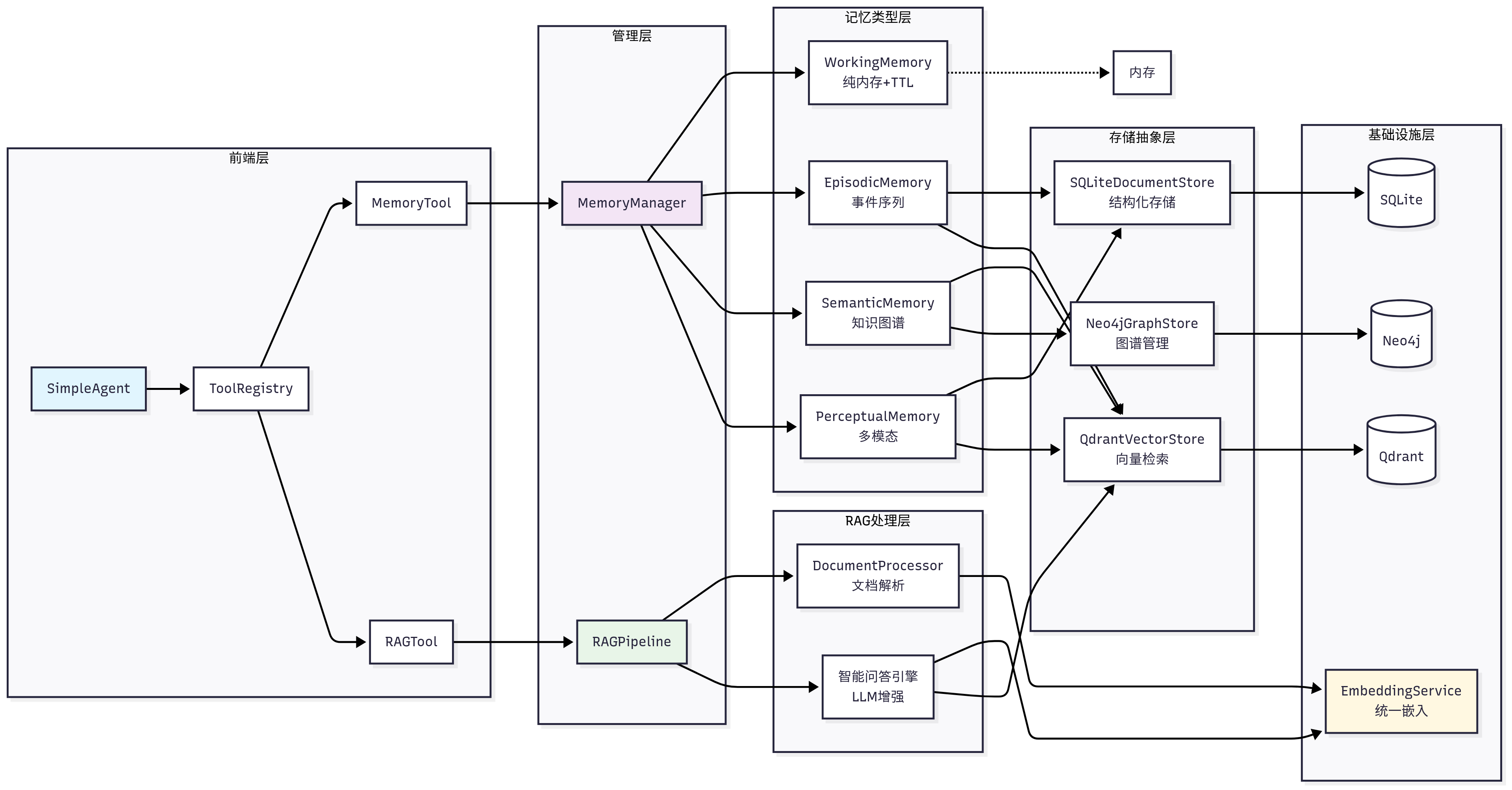
记忆系统,四层架构设计:
HelloAgents记忆系统
├── 基础设施层 (Infrastructure Layer)
│ ├── MemoryManager - 记忆管理器(统一调度和协调)
│ ├── MemoryItem - 记忆数据结构(标准化记忆项)
│ ├── MemoryConfig - 配置管理(系统参数设置)
│ └── BaseMemory - 记忆基类(通用接口定义)
├── 记忆类型层 (Memory Types Layer)
│ ├── WorkingMemory - 工作记忆(临时信息,TTL管理)
│ ├── EpisodicMemory - 情景记忆(具体事件,时间序列)
│ ├── SemanticMemory - 语义记忆(抽象知识,图谱关系)
│ └── PerceptualMemory - 感知记忆(多模态数据)
├── 存储后端层 (Storage Backend Layer)
│ ├── QdrantVectorStore - 向量存储(高性能语义检索)
│ ├── Neo4jGraphStore - 图存储(知识图谱管理)
│ └── SQLiteDocumentStore - 文档存储(结构化持久化)
└── 嵌入服务层 (Embedding Service Layer)
├── DashScopeEmbedding - 通义千问嵌入(云端API)
├── LocalTransformerEmbedding - 本地嵌入(离线部署)
└── TFIDFEmbedding - TFIDF嵌入(轻量级兜底)
RAG系统:
HelloAgents RAG系统
├── 文档处理层 (Document Processing Layer)
│ ├── DocumentProcessor - 文档处理器(多格式解析)
│ ├── Document - 文档对象(元数据管理)
│ └── Pipeline - RAG管道(端到端处理)
├── 嵌入表示层 (Embedding Layer)
│ └── 统一嵌入接口 - 复用记忆系统的嵌入服务
├── 向量存储层 (Vector Storage Layer)
│ └── QdrantVectorStore - 向量数据库(命名空间隔离)
└── 智能问答层 (Intelligent Q&A Layer)
├── 多策略检索 - 向量检索 + MQE + HyDE
├── 上下文构建 - 智能片段合并与截断
└── LLM增强生成 - 基于上下文的准确问答
2、记忆系统设计
记忆形成的认知过程: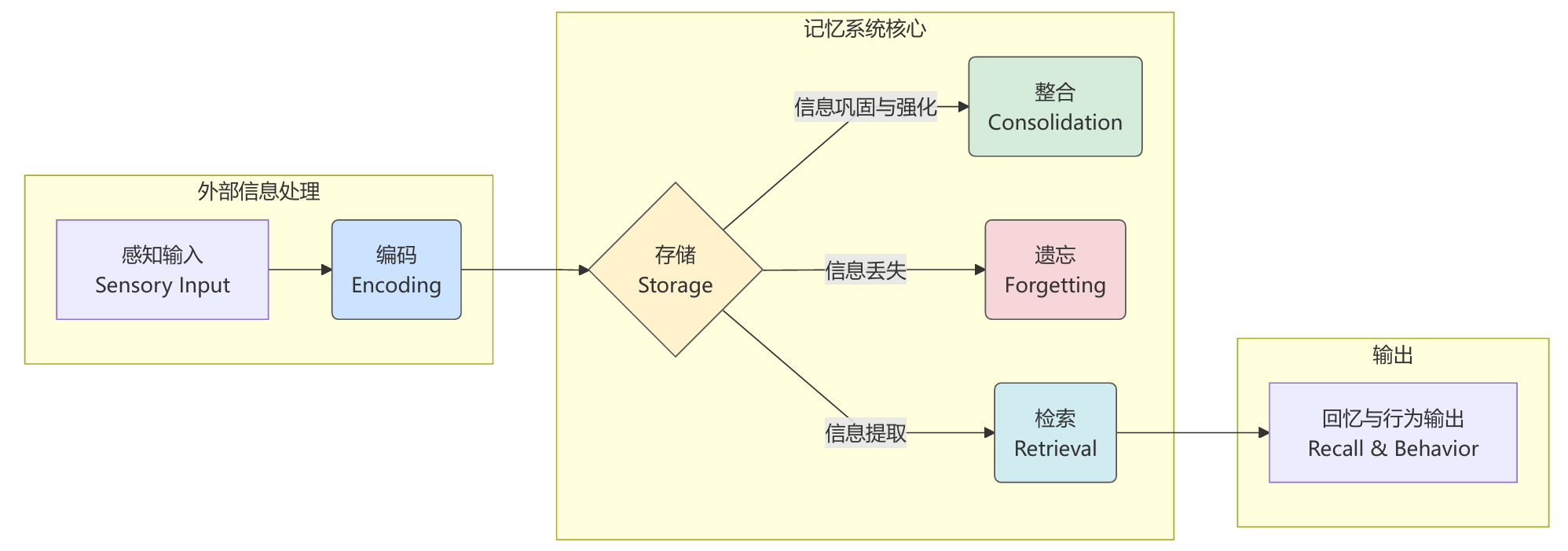
记忆系统完整工作流程,包括记忆的添加、检索、整合和遗忘等关键环节: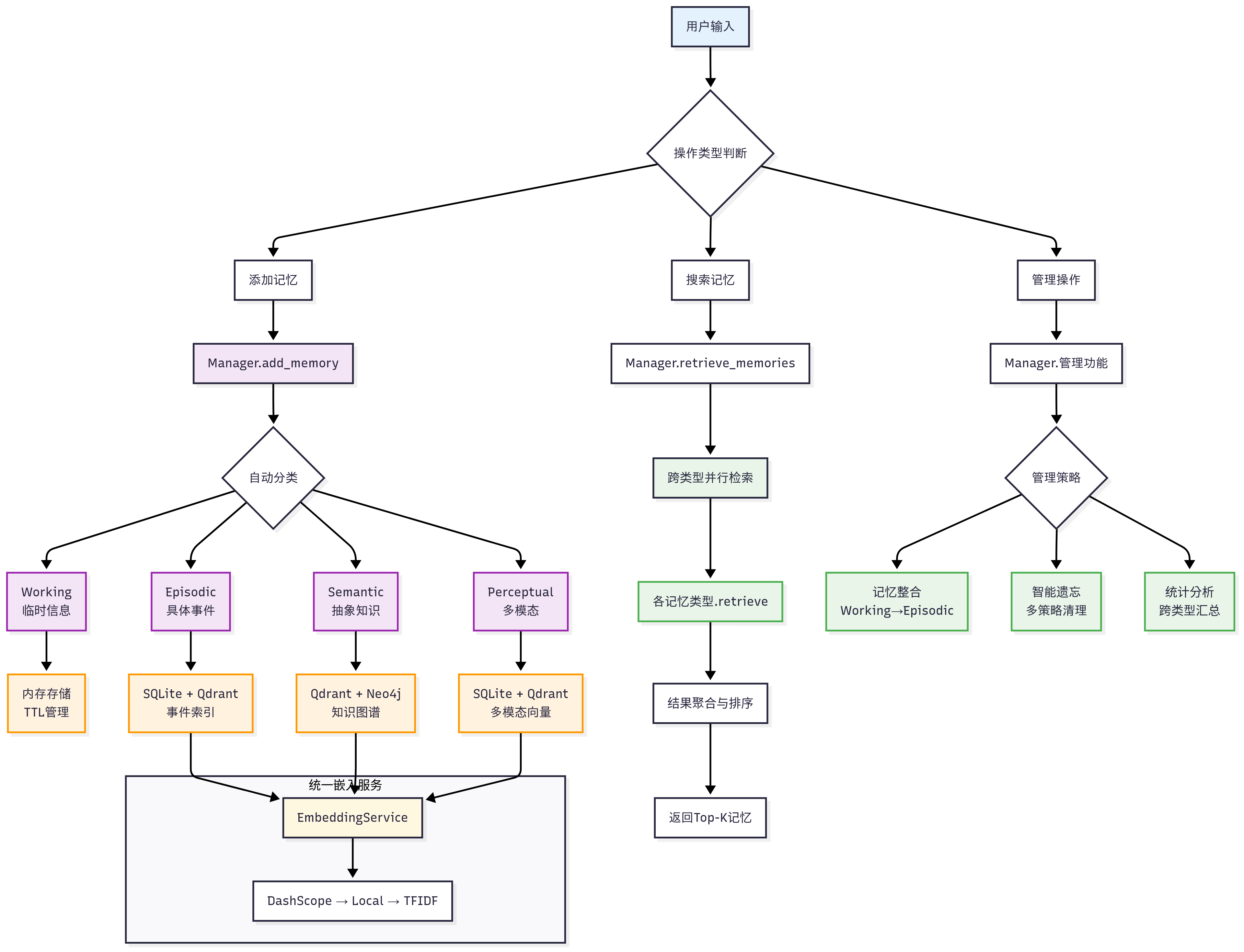
MemoryTool构建了一个完整的记忆生命周期管理体系。从记忆的创建、检索、摘要到遗忘、整合和管理,形成了一个闭环的智能记忆管理系统。
MemoryTool专注于用户接口和参数处理,而MemoryManager则负责核心的记忆管理逻辑。
3、四种记忆类型
1、工作记忆(WorkingMemory)
工作记忆是记忆系统中最活跃的部分,它负责存储当前对话会话中的临时信息。工作记忆的设计重点在于快速访问和自动清理,这种设计确保了系统的响应速度和资源效率。
工作记忆采用了纯内存存储方案,配合TTL(Time To Live)机制进行自动清理。这种设计的优势在于访问速度极快,但也意味着工作记忆的内容在系统重启后会丢失。这种特性正好符合工作记忆的定位,存储临时的、易变的信息。
2、情景记忆(EpisodicMemory)
情景记忆负责存储具体的事件和经历,它的设计重点在于保持事件的完整性和时间序列关系。情景记忆采用了SQLite+Qdrant的混合存储方案,SQLite负责结构化数据的存储和复杂查询,Qdrant负责高效的向量检索。
3、语义记忆(SemanticMemory)
语义记忆是记忆系统中最复杂的部分,它负责存储抽象的概念、规则和知识。语义记忆的设计重点在于知识的结构化表示和智能推理能力。语义记忆采用了Neo4j图数据库和Qdrant向量数据库的混合架构,这种设计让系统既能进行快速的语义检索,又能利用知识图谱进行复杂的关系推理。
4、感知记忆(PerceptualMemory)
感知记忆支持文本、图像、音频等多种模态的数据存储和检索。它采用了模态分离的存储策略,为不同模态的数据创建独立的向量集合,这种设计避免了维度不匹配的问题,同时保证了检索的准确性。
测试记忆工具:
# 环境变量导入放在最前面,因为在导入MemoryTool的时候,需要用到环境变量
# 注意这个包的版本: pip install "qdrant-client>=1.6.0,<1.16.0"
from dotenv import load_dotenv
load_dotenv()
from hello_agents import SimpleAgent, HelloAgentsLLM, ToolRegistry
from hello_agents.tools import MemoryTool
# 创建具有记忆能力的Agent
llm = HelloAgentsLLM()
agent = SimpleAgent(name="记忆助手", llm=llm)
# 创建记忆工具
memory_tool = MemoryTool(user_id="user123")
tool_registry = ToolRegistry()
tool_registry.register_tool(memory_tool)
agent.tool_registry = tool_registry
# 体验记忆功能
print("=== 添加多个记忆 ===")
# 添加第一个记忆
result1 = memory_tool.execute("add", content="用户张三是一名Python开发者,专注于机器学习和数据分析", memory_type="semantic", importance=0.8)
print(f"记忆1: {result1}")
# 添加第二个记忆
result2 = memory_tool.execute("add", content="李四是前端工程师,擅长React和Vue.js开发", memory_type="semantic", importance=0.7)
print(f"记忆2: {result2}")
# 添加第三个记忆
result3 = memory_tool.execute("add", content="王五是产品经理,负责用户体验设计和需求分析", memory_type="semantic", importance=0.6)
print(f"记忆3: {result3}")
print("\n=== 搜索特定记忆 ===")
# 搜索前端相关的记忆
print("🔍 搜索 '前端工程师':")
result = memory_tool.execute("search", query="前端工程师", limit=3)
print(result)
print("\n=== 记忆摘要 ===")
result = memory_tool.execute("summary")
print(result)
结果如下,利用到Qdrant+Neo4j专业数据库: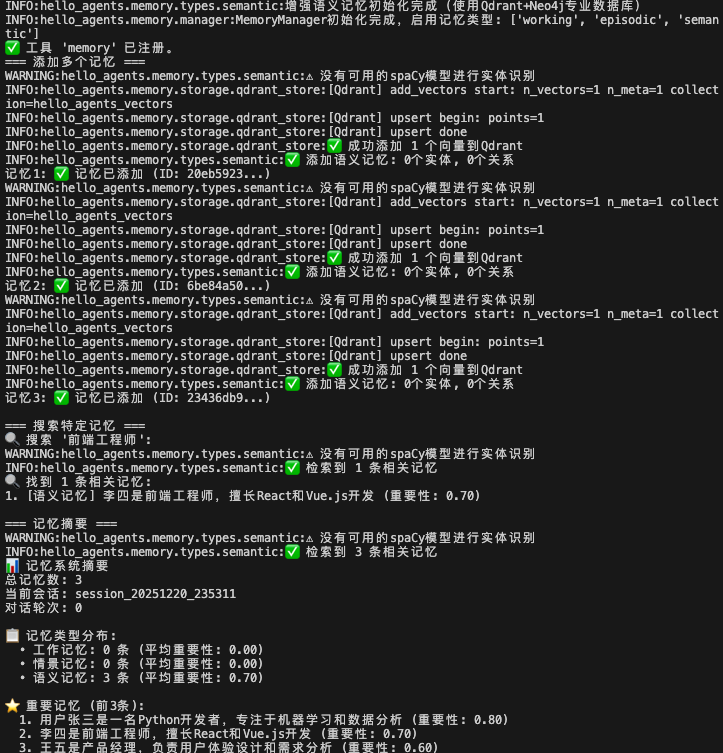
4、RAG系统
Retrieval-Augmented Generation,RAG
第一阶段:朴素RAG(Naive RAG, 2020-2021)。这是RAG技术的萌芽阶段,其流程直接而简单,通常被称为“检索-读取”(Retrieve-Read)模式。检索方式:主要依赖传统的关键词匹配算法,如TF-IDF或BM25。这些方法计算词频和文档频率来评估相关性,对字面匹配效果好,但难以理解语义上的相似性。生成模式:将检索到的文档内容不加处理地直接拼接到提示词的上下文中,然后送给生成模型。
第二阶段:高级RAG(Advanced RAG, 2022-2023)。随着向量数据库和文本嵌入技术的成熟,RAG进入了快速发展阶段。研究者和开发者们在“检索”和“生成”的各个环节引入了大量优化技术。检索方式:转向基于稠密嵌入(Dense Embedding)的语义检索。通过将文本转换为高维向量,模型能够理解和匹配语义上的相似性,而不仅仅是关键词。生成模式:引入了很多优化技术,例如查询重写,文档分块,重排序等。
第三阶段:模块化RAG(Modular RAG, 2023-至今)。在高级RAG的基础上,现代RAG系统进一步向着模块化、自动化和智能化的方向发展。系统的各个部分被设计成可插拔、可组合的独立模块,以适应更多样化和复杂的应用场景。检索方式:如混合检索,多查询扩展,假设性文档嵌入等。生成模式:思维链推理,自我反思与修正等。
RAG工作流程: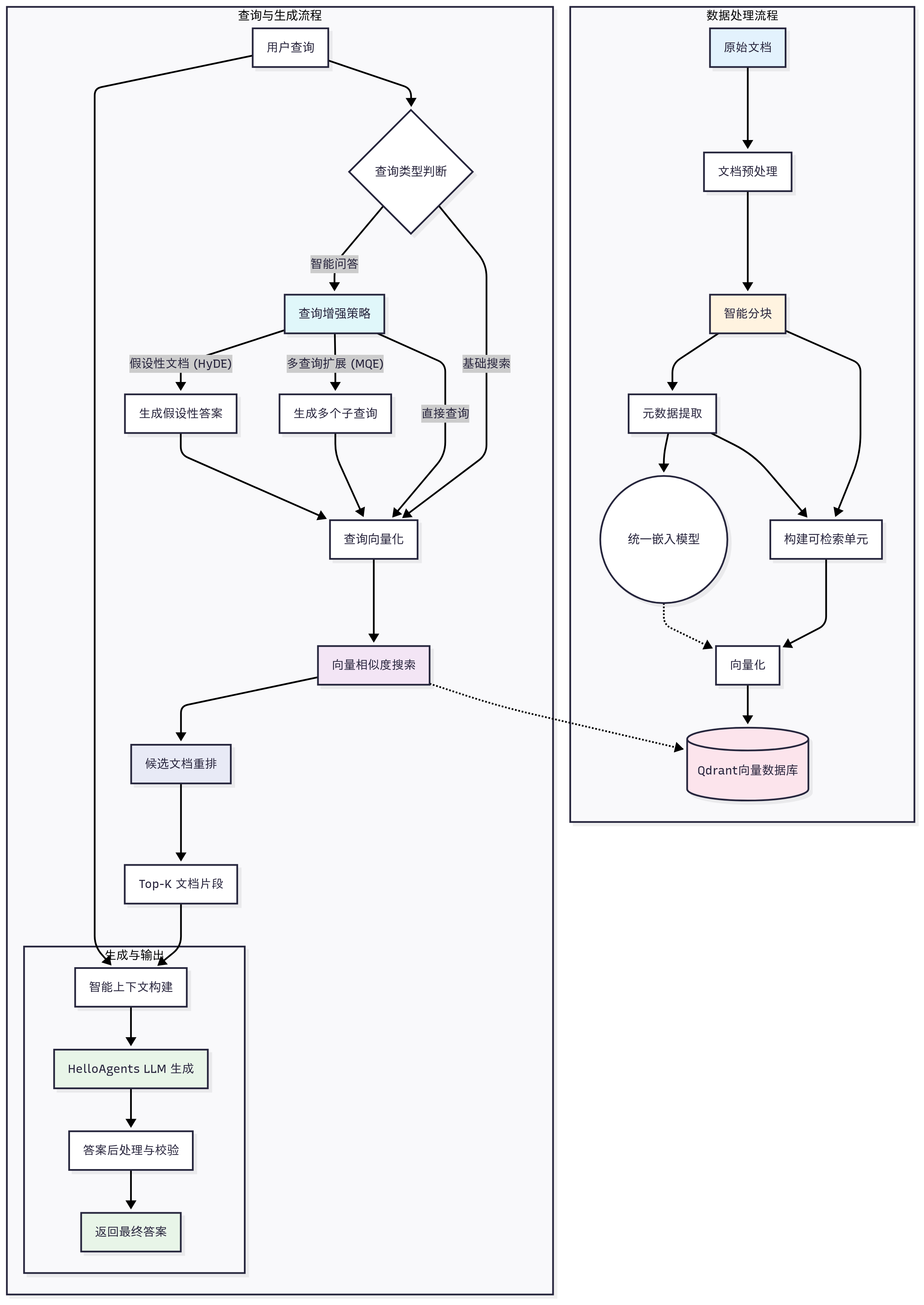
RAG扩展检索的策略:MQE生成的多样化查询和HyDE生成的假设文档
MQE擅长处理用词多样性问题,HyDE擅长处理语义鸿沟问题,而统一框架则确保了结果的质量和多样性。对于一般查询,建议启用MQE;对于专业领域查询,建议同时启用MQE和HyDE;对于性能敏感场景,可以只使用基础检索或仅启用MQE。
虽然扩展检索策略能提高召回准确率,但是耗时也随之上升:
9、上下文工程
1、合理的上下文
上下文工程:管理整个上下文状态的策略——其中包括系统指令、工具、MCP(Model Context Protocol)、外部数据、消息历史等
在“有限注意力预算”的约束下,优秀的上下文工程目标是:用尽可能少、但高信号密度的 tokens,最大化获得期望结果的概率。落实到实践中,我们建议围绕以下组件开展工程化建设:
- 系统提示(System Prompt):语言清晰、直白,信息层级把握在“刚刚好”的高度。常见两极误区:
- 过度硬编码:在提示中写入复杂、脆弱的 if-else 逻辑,长期维护成本高、易碎。
- 过于空泛:只给出宏观目标与泛化指引,缺少对期望输出的具体信号或假定了错误的“共享上下文”。 建议将提示分区组织(如 、、工具指引、输出描述等),用 XML/Markdown 分隔。无论格式如何,追求的是能完整勾勒期望行为的“最小必要信息集”(“最小”并不等于“最短”)。先用最好的模型在最小提示上试跑,再依据失败模式增补清晰的指令与示例。
- 工具(Tools):工具定义了智能体与信息/行动空间的契约,必须促进效率:既要返回token 友好的信息,又要鼓励高效的智能体行为。工具应当:
- 职责单一、相互低重叠,接口语义清晰;
- 对错误鲁棒;
- 入参描述明确、无歧义,充分发挥模型擅长的表达与推理能力。 常见失败模式是“臃肿工具集”:功能边界模糊,导致“选哪个工具”这一决策本身就含混不清。如果人类工程师都说不准用哪个工具,别指望智能体做得更好。精心甄别一个“最小可行工具集(MVTS)”往往能显著提升长期交互中的稳定性与可维护性。
- 示例(Few-shot):始终推荐提供示例,但不建议把“所有边界条件”的罗列一股脑塞进提示。请精挑细选一组多样且典型的示例,直接画像“期望行为”。对 LLM 而言,好的示例胜过千言万语。
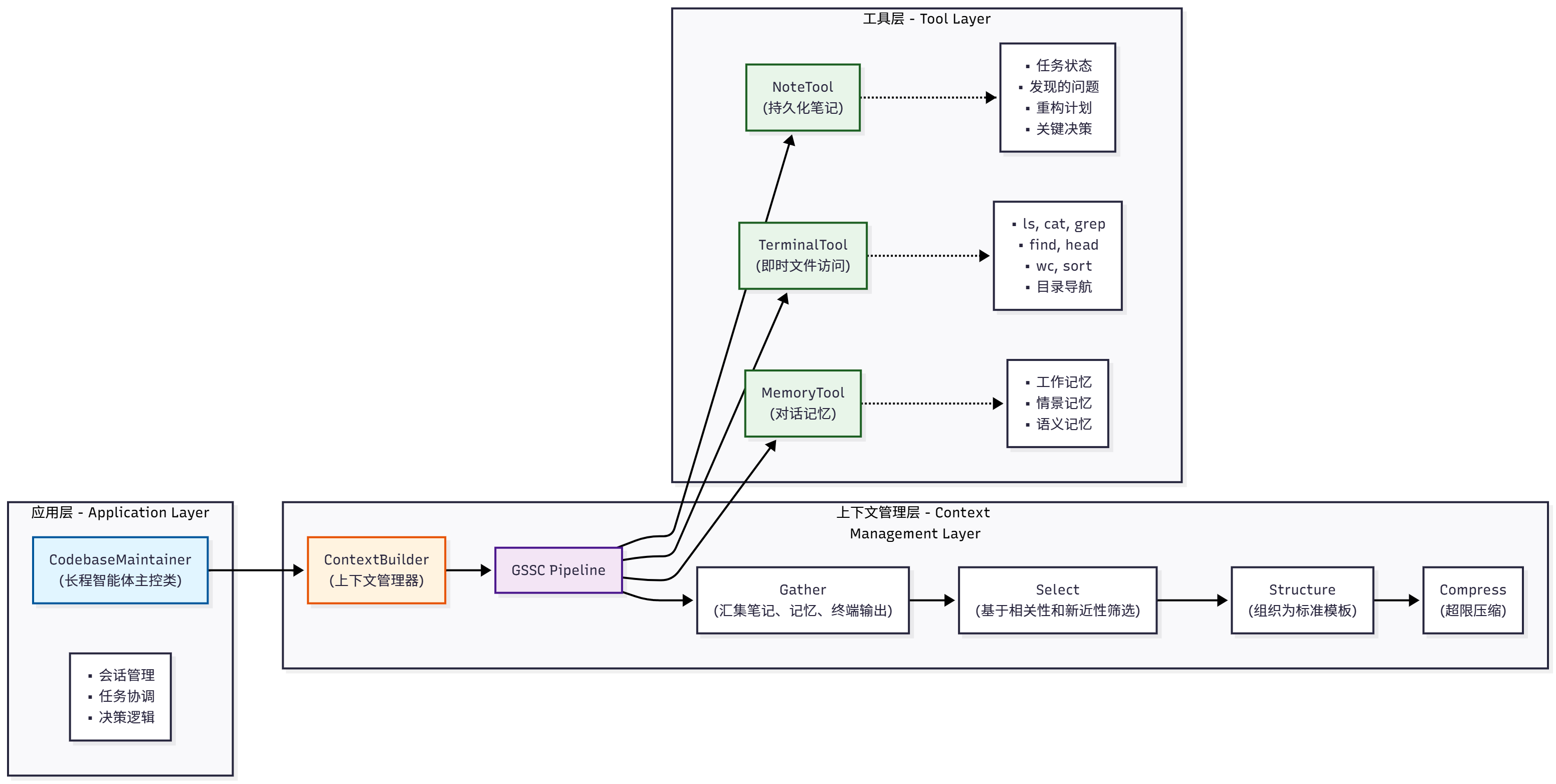
在HelloAgents框架中新增了上下文构建器和两个配套工具:
- ContextBuilder (hello_agents/context/builder.py):上下文构建器,实现 GSSC (Gather-Select-Structure-Compress) 流水线,提供统一的上下文管理接口
- NoteTool (hello_agents/tools/builtin/note_tool.py):结构化笔记工具,支持智能体进行持久化记忆管理
- TerminalTool (hello_agents/tools/builtin/terminal_tool.py):终端工具,支持智能体进行文件系统操作和即时上下文检索
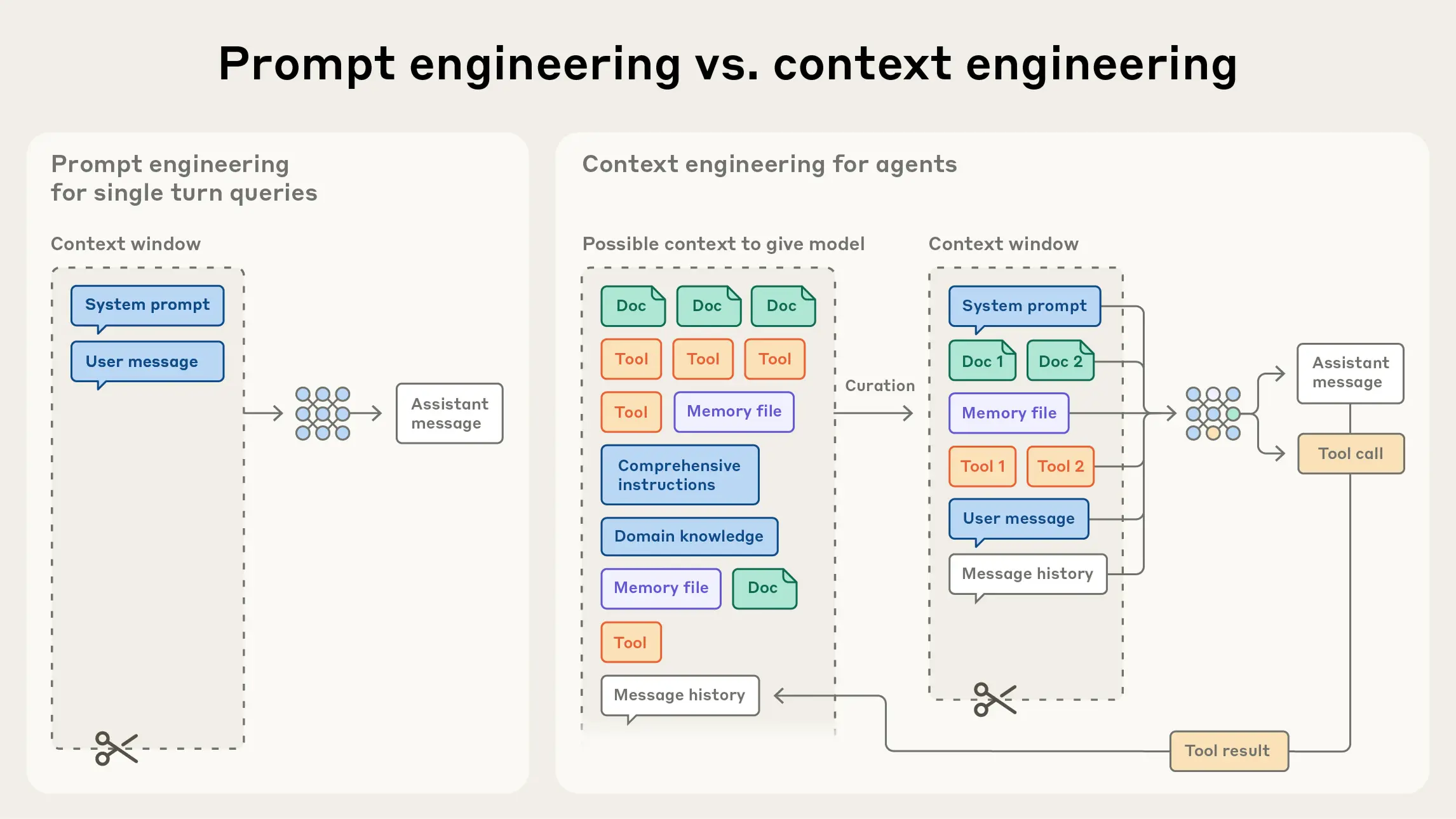
准确且清晰的system prompt: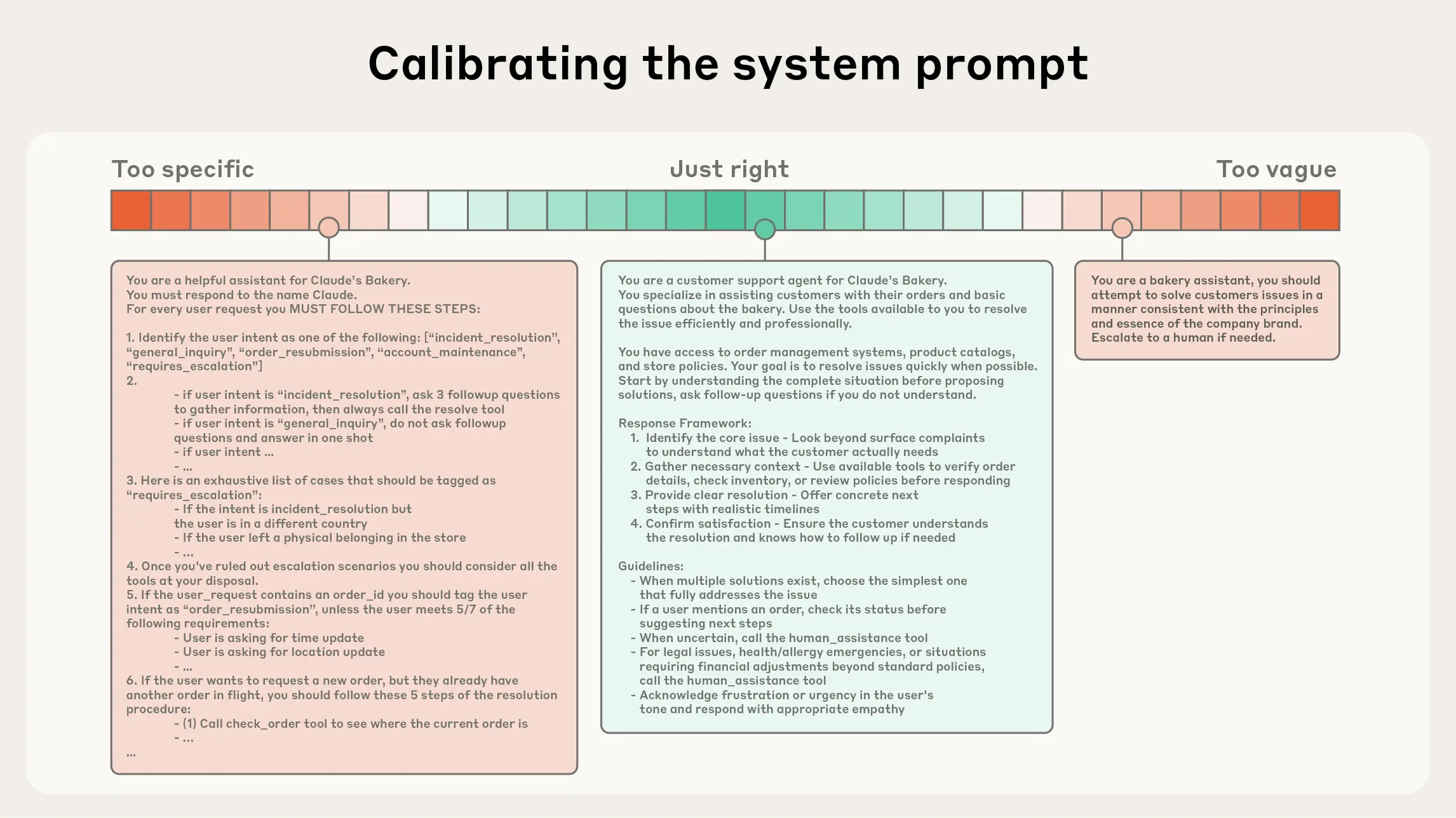
2、ContextBuilder模块
ContextBuilder 的设计理念是"简单高效",去除不必要的复杂性,统一以"相关性+新近性"的分数进行选择,符合 Agent 模块化与可维护性的工程取向。
ContextBuilder 的核心是 GSSC(Gather-Select-Structure-Compress)流水线,它将上下文构建过程分解为四个清晰的阶段。
(1)Gather:多源信息汇集,第一阶段是从多个来源汇集候选信息。这个阶段的关键在于容错性和灵活性。
(2)Select:智能信息选择,第二阶段是根据相关性和新近性对候选信息进行评分和选择。这是整个流水线的核心,直接决定了最终上下文的质量。
(3)Structure:结构化输出,第三阶段是将选中的信息组织成结构化的上下文模板。
(4)Compress:兜底压缩,第四阶段是对超限上下文进行压缩处理。
3、NoteTool:结构化笔记
1、为什么需要 NoteTool?:MemoryTool 主要关注对话式记忆——短期工作记忆、情景记忆和语义记忆。对于需要长期追踪、结构化管理的项目式任务,我们需要一种更轻量、更人类友好的记录方式。
2、NoteTool 填补了这个gap,它提供了:
- 结构化记录:使用 Markdown + YAML 格式,既适合机器解析,也方便人类阅读和编辑
- 版本友好:纯文本格式,天然支持 Git 等版本控制系统
- 低开销:无需复杂的数据库操作,适合轻量级的状态追踪
- 灵活分类:通过 type 和 tags 灵活组织笔记,支持多维度检索
3、NoteTool 特别适合以下场景:
(1)场景1:长期项目追踪
想象一个智能体正在协助完成一个大型代码库的重构任务,这可能需要几天甚至几周。NoteTool 可以记录:
task_state:当前阶段的任务状态和进度
conclusion:每个阶段结束后的关键结论
blocker:遇到的问题和阻塞点
action:下一步的行动计划
# 记录任务状态
notes.run({
"action": "create",
"title": "重构项目 - 第一阶段",
"content": "已完成数据模型层的重构,测试覆盖率达到85%。下一步将重构业务逻辑层。",
"note_type": "task_state",
"tags": ["refactoring", "phase1"]
})
# 记录阻塞点
notes.run({
"action": "create",
"title": "依赖冲突问题",
"content": "发现某些第三方库版本不兼容,需要解决。影响范围:业务逻辑层的3个模块。",
"note_type": "blocker",
"tags": ["dependency", "urgent"]
})
(2)场景2:研究任务管理
一个智能研究助手在进行文献综述时,可以使用 NoteTool 记录:
每篇论文的核心观点(conclusion)
待深入调研的主题(action)
重要的参考文献(reference)
(3)场景3:与 ContextBuilder 配合
在每轮对话前,Agent 可以通过 search 或 list 操作检索相关笔记,并将其注入到上下文中。
4、在实际使用 NoteTool 时,以下最佳实践能帮助您构建更强大的长时程智能体:
(1)合理的笔记分类:
task_state:记录阶段性进展和状态
conclusion:记录重要的结论和发现
blocker:记录阻塞问题,优先级最高
action:记录下一步行动计划
reference:记录重要的参考资料
(2)定期清理和归档:
对于已解决的 blocker,更新为 conclusion
对于过时的 action,及时删除或更新
使用 tags 进行版本管理,如 [“v1.0”, “completed”]
与 ContextBuilder 的配合:
(3)在每轮对话前检索相关笔记
根据笔记类型设置不同的相关性分数(blocker > action > conclusion)
限制笔记数量,避免上下文过载
(4)人机协作:
笔记是人类可读的 Markdown 格式,支持手动编辑
使用 Git 进行版本控制,追踪笔记的演化
在关键阶段,人工审核 Agent 生成的笔记
(5)自动化工作流:
定期生成笔记摘要报告
基于笔记自动生成项目进度文档
将笔记内容同步到其他系统(如 Notion、Confluence)
4、TerminalTool:即时文件系统访问
1、MemoryTool 和 RAGTool,它们分别提供了对话记忆和知识检索能力。然而,在许多实际场景中,智能体需要即时访问和探索文件系统——查看日志文件、分析代码库结构、检索配置文件等。
TerminalTool 的实现聚焦于两个核心功能:命令执行和目录导航。
(1)命令执行:核心的 _execute_command 方法负责实际执行命令
(2)目录导航:cd 命令的特殊处理支持智能体在文件系统中导航
2、使用模式举例:
探索式导航:智能体可以像人类开发者一样逐步探索代码库:
from hello_agents.tools import TerminalTool
terminal = TerminalTool(workspace="./my_project")
# 第一步:查看项目根目录
print(terminal.run({"command": "ls -la"}))
"""
total 24
drwxr-xr-x 6 user staff 192 Jan 19 16:00 .
drwxr-xr-x 5 user staff 160 Jan 19 15:30 ..
-rw-r--r-- 1 user staff 1234 Jan 19 15:30 README.md
drwxr-xr-x 4 user staff 128 Jan 19 15:30 src
drwxr-xr-x 3 user staff 96 Jan 19 15:30 tests
-rw-r--r-- 1 user staff 456 Jan 19 15:30 requirements.txt
"""
# 第二步:查看源代码目录结构
terminal.run({"command": "cd src"})
print(terminal.run({"command": "tree"}))
# 第三步:搜索特定模式
print(terminal.run({"command": "grep -r 'def process' ."}))
3、与其他工具的协同
(1)与 MemoryTool 协同:TerminalTool 发现的信息可以存储到记忆系统中
(2)与 NoteTool 协同:重要的发现可以记录为结构化笔记
(3)与 ContextBuilder 协同:TerminalTool 的输出可以作为上下文的一部分
5、长程智能体:代码库维护助手
1、业务场景
假设我们正在维护一个中型 Python Web 应用,这个代码库包含约 50 个 Python 文件,使用 Flask 框架构建,涵盖数据模型、业务逻辑、API 接口等多个模块,同时存在一些技术债务需要逐步清理。在这样的场景下,我们需要一个智能助手来帮助我们探索代码库,理解项目结构、依赖关系和代码风格;识别代码中的问题,比如代码重复、复杂度过高、缺少测试等;追踪任务进度,记录待办事项、已完成工作和遇到的阻塞;并基于历史上下文提供连贯的重构建议。
2、挑战与解决方案
这个场景面临几个典型的长程任务挑战。
- 首先是信息量超出上下文窗口的问题,整个代码库可能包含数万行代码,无法一次性放入上下文窗口,我们通过使用 TerminalTool 进行即时、按需的代码探索来解决这个问题,只在需要时查看具体文件。
- 其次是跨会话的状态管理挑战,重构任务可能持续数天,需要跨多个会话保持进度,我们使用 NoteTool 记录阶段性进展、待办事项和关键决策来应对。
- 最后是上下文质量与相关性的问题,每次对话需要回顾相关的历史信息,但不能被无关信息淹没,我们通过 ContextBuilder 智能筛选和组织上下文,确保高信号密度。
3、长程智能体特性:
- 首先是跨会话的连贯性,智能体通过 NoteTool 保持了跨多天、多个会话的任务连贯性,第一天探索的问题在第二天分析时被自动考虑,第三天规划时能够综合前两天的所有发现,一周后检查时完整的历史都被保留。
- 其次是智能的上下文管理,ContextBuilder 确保每次对话都有高质量的上下文,自动汇集相关笔记(特别是 blocker 类型),根据对话模式动态调整预处理策略,在 token 预算内选择最相关的信息。
- 第三个特性是即时的文件系统访问,TerminalTool 支持灵活的代码探索,无需预先索引整个代码库,可以即时查看具体文件内容,支持复杂的文本处理(grep、awk等)。
- 第四是自动化的知识管理,系统自动化地管理发现的知识,发现问题时自动创建 blocker 笔记,讨论计划时自动创建 action 笔记,关键信息自动存储到记忆系统。
- 最后是人机协作,这个系统支持灵活的人机协作模式,智能体可以自动化地完成探索和分析,人类可以通过笔记系统进行干预和指导,支持手动创建详细的计划笔记。
10、智能体通信协议
1、智能体通信协议基础
1、相关总结:
MCP (Model Context Protocol): 作为智能体与工具之间的桥梁,提供统一的工具访问接口,适用于增强单个智能体的能力。
A2A (Agent-to-Agent Protocol): 作为智能体之间的对话系统,支持直接通信与任务协商,适用于小规模团队的紧密协作。
ANP (Agent Network Protocol): 作为智能体的“互联网”,提供服务发现、路由与负载均衡机制,适用于构建大规模、开放的智能体网络。
MCP 官方文档:https://modelcontextprotocol.io
A2A 官方文档:https://a2a-protocol.org/latest/
ANP 官方文档:https://agent-network-protocol.com/guide/
2、需要MCP的理由:
没有MCP之前,要进行很多工具定义的细节代码:代码重复(每个工具都要处理 HTTP 请求、错误处理、认证等),难以维护(API 变更需要修改所有相关工具),无法复用(其他开发者的工具无法直接使用),扩展性差(添加新服务需要大量编码工作)
- 首先是工具集成的困境:每当需要访问新的外部服务(如 GitHub API、数据库、文件系统),我们都必须编写专门的 Tool 类。这不仅工作量大,而且不同开发者编写的工具无法互相兼容。
- 其次是能力扩展的瓶颈:智能体的能力被限制在预先定义的工具集内,无法动态发现和使用新的服务。
- 最后是协作的缺失:当任务复杂到需要多个专业智能体协作时(如研究员+撰写员+编辑),我们只能通过手动编排来协调它们的工作。
from hello_agents import ReActAgent, HelloAgentsLLM
from hello_agents.tools import CalculatorTool, SearchTool
llm = HelloAgentsLLM()
agent = ReActAgent(name="AI助手", llm=llm)
agent.add_tool(CalculatorTool())
agent.add_tool(SearchTool())
# 智能体可以独立完成任务
response = agent.run("搜索最新的AI新闻,并计算相关公司的市值总和")
有了MCP后,智能体能够以统一的方式访问各种外部服务,而无需为每个服务编写专门的适配器:
from hello_agents.tools import MCPTool
# 连接到MCP服务器,自动获得所有工具
mcp_tool = MCPTool() # 内置服务器提供基础工具
# 或者连接到专业的MCP服务器
github_mcp = MCPTool(server_command=["npx", "-y", "@modelcontextprotocol/server-github"])
database_mcp = MCPTool(server_command=["python", "database_mcp_server.py"])
# 智能体自动获得所有能力,无需手写适配器
agent.add_tool(mcp_tool)
agent.add_tool(github_mcp)
agent.add_tool(database_mcp)
3、MCP 的设计哲学是"上下文共享"。它不仅仅是一个 RPC(远程过程调用)协议,更重要的是它允许智能体和工具之间共享丰富的上下文信息。如下图,当智能体访问一个代码仓库时,MCP 服务器不仅能提供文件内容,还能提供代码结构、依赖关系、提交历史等上下文信息,让智能体能够做出更智能的决策。
4、A2A:智能体间的对话
A2A(Agent-to-Agent Protocol)协议由 Google 团队提出2,其核心设计理念是实现智能体之间的点对点通信。与 MCP 关注智能体与工具的通信不同,A2A 关注的是智能体之间如何相互协作。这种设计让智能体能够像人类团队一样进行对话、协商和协作。
A2A 的设计哲学是"对等通信"。如下图所示,在 A2A 网络中,每个智能体既是服务提供者,也是服务消费者。智能体可以主动发起请求,也可以响应其他智能体的请求。这种对等的设计避免了中心化协调器的瓶颈,让智能体网络更加灵活和可扩展。
5、ANP:智能体网络的基础设施
ANP(Agent Network Protocol)是一个概念性的协议框架3,目前由开源社区维护,还没有成熟的生态,其核心设计理念是构建大规模智能体网络的基础设施。如果说 MCP 解决的是"如何访问工具",A2A 解决的是"如何与其他智能体对话",那么 ANP 解决的是"如何在大规模网络中发现和连接智能体"。
ANP 的设计哲学是"去中心化服务发现"。在一个包含成百上千个智能体的网络中,如何让智能体能够找到它需要的服务?如下图所示,ANP 提供了服务注册、发现和路由机制,让智能体能够动态地发现网络中的其他服务,而不需要预先配置所有的连接关系。

6、三种协议的区别:
2、HelloAgents 通信协议架构设计
HelloAgents 的通信协议架构采用三层设计,从底层到上层分别是:协议实现层、工具封装层和智能体集成层。
(1)协议实现层:这一层包含了三种协议的具体实现。MCP 基于 FastMCP 库实现,提供客户端和服务器功能;A2A 基于 Google 官方的 a2a-sdk 实现;ANP 是我们自研的轻量级实现,提供服务发现和网络管理功能,当然目前也有官方的实现,考虑到后期的迭代,因此这里只做概念的模拟。
(2)工具封装层:这一层将协议实现封装成统一的 Tool 接口。MCPTool、A2ATool 和 ANPTool 都继承自 BaseTool,提供一致的run()方法。这种设计让智能体能够以相同的方式使用不同的协议。
(3)智能体集成层:这一层是智能体与协议的集成点。所有的智能体(ReActAgent、SimpleAgent 等)都通过 Tool System 来使用协议工具,无需关心底层的协议细节。

3、MCP协议
1、为什么需要MCP
痛点:不同 LLM 平台的 function call 实现差异巨大,切换模型时需要重写大量代码
核心:MCP 统一了智能体与外部工具的交互方式
MCP 协议采用 Host、Client、Servers 三层架构设计:
ex:假设你正在使用 Claude Desktop 询问:“我桌面上有哪些文档?”
2、MCP三层架构的职责:
- Host(宿主层):Claude Desktop 作为 Host,负责接收用户提问并与 Claude 模型交互。Host 是用户直接交互的界面,它管理整个对话流程。
- Client(客户端层):当 Claude 模型决定需要访问文件系统时,Host 中内置的 MCP Client 被激活。Client 负责与适当的 MCP Server 建立连接,发送请求并接收响应。
- Server(服务器层):文件系统 MCP Server 被调用,执行实际的文件扫描操作,访问桌面目录,并返回找到的文档列表。

完整的交互流程:用户问题 → Claude Desktop(Host) → Claude 模型分析 → 需要文件信息 → MCP Client 连接 → 文件系统 MCP Server → 执行操作 → 返回结果 → Claude 生成回答 → 显示在 Claude Desktop 上
这种架构设计的优势在于关注点分离:Host 专注于用户体验,Client 专注于协议通信,Server 专注于具体功能实现。开发者只需专注于开发对应的 MCP Server,无需关心 Host 和 Client 的实现细节。
3、MCP工作流程如下图
注意:工具发现阶段:MCP Client 连接到 Server 后,首先调用list_tools()获取所有可用工具的描述信息(包括工具名称、功能说明、参数定义)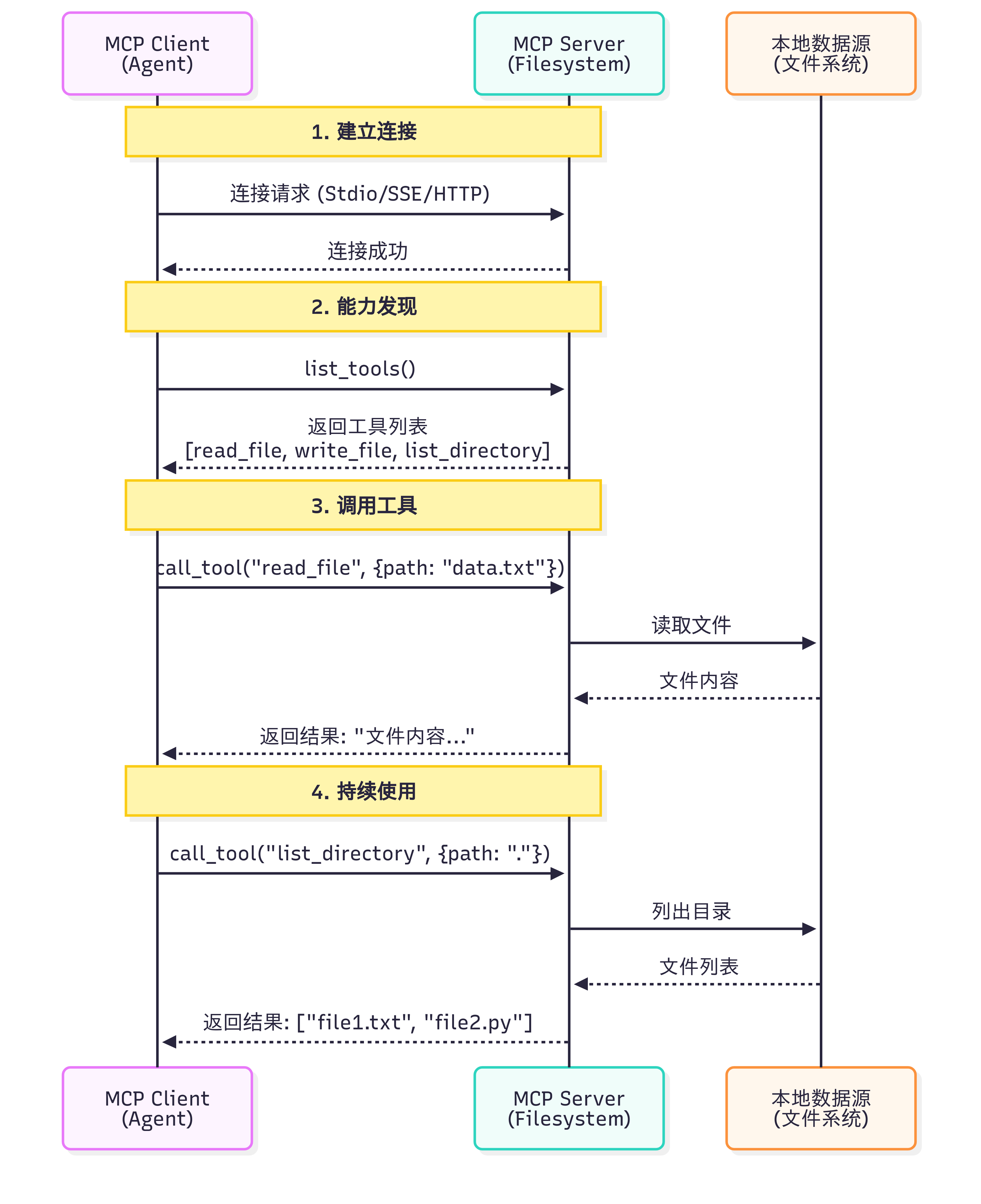
4、使用 MCP 客户端
1、HelloAgents 基于 FastMCP 2.0 实现了完整的 MCP 客户端功能。我们提供了异步和同步两种 API,以适应不同的使用场景。对于大多数应用,推荐使用异步 API,它能更好地处理并发请求和长时间运行的操作。
2、相关流程:
(1)连接到 MCP 服务器:MCP 客户端支持多种连接方式,最常用的是 Stdio 模式(通过标准输入输出与本地进程通信)
(2)发现可用工具:连接成功后,第一步通常是查询服务器提供了哪些工具
(3)调用工具:调用工具时,只需提供工具名称和符合 JSON Schema 的参数
(4)访问资源:除了工具,MCP 服务器还可以提供资源(Resources)
(5)使用提示模板:MCP 服务器可以提供预定义的提示模板(Prompts)
以上的代码示例:
import asyncio
from hello_agents.protocols import MCPClient
async def connect_to_server():
# 方式1:连接到社区提供的文件系统服务器
# npx会自动下载并运行@modelcontextprotocol/server-filesystem包
client = MCPClient([
"npx", "-y",
"@modelcontextprotocol/server-filesystem",
"." # 指定根目录
])
# 使用async with确保连接正确关闭
async with client:
# 在这里使用client
tools = await client.list_tools()
print(f"可用工具: {[t['name'] for t in tools]}")
# 方式2:连接到自定义的Python MCP服务器
client = MCPClient(["python", "my_mcp_server.py"])
async with client:
# 使用client...
pass
# 运行异步函数
asyncio.run(connect_to_server())
async def discover_tools():
client = MCPClient(["npx", "-y", "@modelcontextprotocol/server-filesystem", "."])
async with client:
# 获取所有可用工具
tools = await client.list_tools()
print(f"服务器提供了 {len(tools)} 个工具:")
for tool in tools:
print(f"\n工具名称: {tool['name']}")
print(f"描述: {tool.get('description', '无描述')}")
# 打印参数信息
if 'inputSchema' in tool:
schema = tool['inputSchema']
if 'properties' in schema:
print("参数:")
for param_name, param_info in schema['properties'].items():
param_type = param_info.get('type', 'any')
param_desc = param_info.get('description', '')
print(f" - {param_name} ({param_type}): {param_desc}")
asyncio.run(discover_tools())
# 输出示例:
# 服务器提供了 5 个工具:
#
# 工具名称: read_file
# 描述: 读取文件内容
# 参数:
# - path (string): 文件路径
#
# 工具名称: write_file
# 描述: 写入文件内容
# 参数:
# - path (string): 文件路径
# - content (string): 文件内容
async def use_tools():
client = MCPClient(["npx", "-y", "@modelcontextprotocol/server-filesystem", "."])
async with client:
# 读取文件
result = await client.call_tool("read_file", {"path": "my_README.md"})
print(f"文件内容:\n{result}")
# 列出目录
result = await client.call_tool("list_directory", {"path": "."})
print(f"当前目录文件:{result}")
# 写入文件
result = await client.call_tool("write_file", {
"path": "output.txt",
"content": "Hello from MCP!"
})
print(f"写入结果:{result}")
asyncio.run(use_tools())
async def safe_tool_call():
client = MCPClient(["npx", "-y", "@modelcontextprotocol/server-filesystem", "."])
async with client:
try:
# 尝试读取可能不存在的文件
result = await client.call_tool("read_file", {"path": "nonexistent.txt"})
print(result)
except Exception as e:
print(f"工具调用失败: {e}")
# 可以选择重试、使用默认值或向用户报告错误
asyncio.run(safe_tool_call())
3、使用github MCP服务
"""
GitHub MCP 服务示例
注意:需要设置环境变量
Windows: $env:GITHUB_PERSONAL_ACCESS_TOKEN="your_token_here"
Linux/macOS: export GITHUB_PERSONAL_ACCESS_TOKEN="your_token_here"
"""
from hello_agents.tools import MCPTool
# 创建 GitHub MCP 工具
github_tool = MCPTool(
server_command=["npx", "-y", "@modelcontextprotocol/server-github"]
)
# 1. 列出可用工具
print("📋 可用工具:")
result = github_tool.run({"action": "list_tools"})
print(result)
# 2. 搜索仓库
print("\n🔍 搜索仓库:")
result = github_tool.run({
"action": "call_tool",
"tool_name": "search_repositories",
"arguments": {
"query": "AI agents language:python",
"page": 1,
"perPage": 3
}
})
print(result)
5、MCP传输方式
HelloAgents 的MCPClient支持五种传输方式:
(1)Memory Transport - 内存传输
适用场景:单元测试、快速原型开发
(2)Stdio Transport - 标准输入输出传输
适用场景:本地开发、调试、Python 脚本服务器
(3)HTTP Transport - HTTP 传输
适用场景:生产环境、远程服务、微服务架构
(4)SSE Transport - Server-Sent Events 传输
适用场景:实时通信、流式处理、长连接
(5)StreamableHTTP Transport - 流式 HTTP 传输
适用场景:需要双向流式通信的 HTTP 场景
6、智能体中使用MCP工具
可以连接内置演示服务器,也可以连接外部 MCP 服务器,比如社区提供的官方服务器(如文件系统、GitHub、数据库等)、你自己编写的自定义服务器(封装业务逻辑)。
【栗子】智能文档助手,查找github相关项目总结成文档,简单多智能体编排任务:
"""
多Agent协作的智能文档助手
使用两个SimpleAgent分工协作:
- Agent1:GitHub搜索专家
- Agent2:文档生成专家
"""
from hello_agents import SimpleAgent, HelloAgentsLLM
from hello_agents.tools import MCPTool
from dotenv import load_dotenv
# 加载.env文件中的环境变量
from dotenv import load_dotenv
load_dotenv()
# load_dotenv(dotenv_path="../HelloAgents/.env")
print("="*70)
print("多Agent协作的智能文档助手")
print("="*70)
# ============================================================
# Agent 1: GitHub搜索专家
# ============================================================
print("\n【步骤1】创建GitHub搜索专家...")
github_searcher = SimpleAgent(
name="GitHub搜索专家",
llm=HelloAgentsLLM(),
system_prompt="""你是一个GitHub搜索专家。
你的任务是搜索GitHub仓库并返回结果。
请返回清晰、结构化的搜索结果,包括:
- 仓库名称
- 简短描述
保持简洁,不要添加额外的解释。"""
)
# 添加GitHub工具
github_tool = MCPTool(
name="gh",
server_command=["npx", "-y", "@modelcontextprotocol/server-github"]
)
github_searcher.add_tool(github_tool)
# ============================================================
# Agent 2: 文档生成专家
# ============================================================
print("\n【步骤2】创建文档生成专家...")
document_writer = SimpleAgent(
name="文档生成专家",
llm=HelloAgentsLLM(),
system_prompt="""你是一个文档生成专家。
你的任务是根据提供的信息生成结构化的Markdown报告。
报告应该包括:
- 标题
- 简介
- 主要内容(分点列出,包括项目名称、描述等)
- 总结
请直接输出完整的Markdown格式报告内容,不要使用工具保存。"""
)
# 添加文件系统工具
fs_tool = MCPTool(
name="fs",
server_command=["npx", "-y", "@modelcontextprotocol/server-filesystem", "."]
)
document_writer.add_tool(fs_tool)
# ============================================================
# 执行任务
# ============================================================
print("\n" + "="*70)
print("开始执行任务...")
print("="*70)
try:
# 步骤1:GitHub搜索
print("\n【步骤3】Agent1 搜索GitHub...")
# search_task = "搜索关于'AI agent'的GitHub仓库,返回前5个最相关的结果"
search_task = "搜索关于'多模态大模型'的GitHub仓库,返回前5个最相关的结果"
search_results = github_searcher.run(search_task)
print("\n搜索结果:")
print("-" * 70)
print(search_results)
print("-" * 70)
# 步骤2:生成报告
print("\n【步骤4】Agent2 生成报告...")
report_task = f"""
根据以下GitHub搜索结果,生成一份Markdown格式的研究报告:
{search_results}
报告要求:
1. 标题:# AI Agent框架研究报告
2. 简介:说明这是关于AI Agent的GitHub项目调研
3. 主要发现:列出找到的项目及其特点(包括名称、描述等)
4. 总结:总结这些项目的共同特点
请直接输出完整的Markdown格式报告。
"""
report_content = document_writer.run(report_task)
print("\n报告内容:")
print("=" * 70)
print(report_content)
print("=" * 70)
# 步骤3:保存报告
print("\n【步骤5】保存报告到文件...")
import os
try:
with open("report.md", "w", encoding="utf-8") as f:
f.write(report_content)
print("✅ 报告已保存到 report.md")
# 验证文件
file_size = os.path.getsize("report.md")
print(f"✅ 文件大小: {file_size} 字节")
except Exception as e:
print(f"❌ 保存失败: {e}")
print("\n" + "="*70)
print("任务完成!")
print("="*70)
except Exception as e:
print(f"\n❌ 错误: {e}")
import traceback
traceback.print_exc()
分析:github_searcher会在这个过程中调用gh_search_repositories搜索 GitHub 项目。得到的结果会返回给document_writer当做输入,进一步指导报告的生成,最后保存报告到 report.md。
7、构建自定义 MCP 服务器
Smithery 是 MCP 服务器的官方发布平台,类似于 Python 的 PyPI 或 Node.js 的 npm。通过 Smithery,用户可以:
🔍 发现和搜索 MCP 服务器
📦 一键安装 MCP 服务器
📊 查看服务器的使用统计和评价
🔄 自动获取服务器更新
需要准备的文件:
- 配置文件smithery.yaml
- pyproject.toml是 Python 项目的标准配置文件,Smithery 要求必须包含此文件,因为后续会打包成一个 server
- Dockerfile:虽然 Smithery 会自动生成 Dockerfile,但提供自定义 Dockerfile 可以确保部署成功,文件如下:
# Multi-stage build for weather-mcp-server
FROM python:3.12-slim-bookworm as base
# Set working directory
WORKDIR /app
# Install system dependencies
RUN apt-get update && apt-get install -y \
--no-install-recommends \
&& rm -rf /var/lib/apt/lists/*
# Copy project files
COPY pyproject.toml requirements.txt ./
COPY server.py ./
# Install Python dependencies
RUN pip install --no-cache-dir --upgrade pip && \
pip install --no-cache-dir -r requirements.txt
# Set environment variables
ENV PYTHONUNBUFFERED=1
ENV PORT=8081
# Expose port (Smithery uses 8081)
EXPOSE 8081
# Health check
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD python -c "import sys; sys.exit(0)"
# Run the MCP server
CMD ["python", "server.py"]
上传完成后:
8、MCP社区生态
1、MCP 社区的三个资源库:
(1)Awesome MCP Servers (https://github.com/punkpeye/awesome-mcp-servers)
社区维护的 MCP 服务器精选列表
包含各种第三方服务器
按功能分类,易于查找
(2)MCP Servers Website (https://mcpservers.org/)
官方 MCP 服务器目录网站
提供搜索和筛选功能
包含使用说明和示例
(3)Official MCP Servers (https://github.com/modelcontextprotocol/servers)
Anthropic 官方维护的服务器
质量最高、文档最完善
包含常用服务的实现
2、热门MCP服务器
一些特别有趣的案例 TODO 可供参考:
-
自动化网页测试(Playwright)
# Agent可以自动: # - 打开浏览器访问网站 # - 填写表单并提交 # - 截图验证结果 # - 生成测试报告 playwright_tool = MCPTool( name="playwright", server_command=["npx", "-y", "@playwright/mcp"] ) -
智能笔记助手(Obsidian + Perplexity)
# Agent可以: # - 搜索最新技术资讯(Perplexity) # - 整理成结构化笔记 # - 保存到Obsidian知识库 # - 自动建立笔记间的链接 -
项目管理自动化(Jira + GitHub)
# Agent可以: # - 从GitHub Issue创建Jira任务 # - 同步代码提交到Jira # - 自动更新Sprint进度 # - 生成项目报告 -
内容创作工作流(YouTube + Notion + Spotify)
# Agent可以: # - 获取YouTube视频字幕 # - 生成内容摘要 # - 保存到Notion数据库 # - 播放背景音乐(Spotify)
Reference
[1] https://datawhalechina.github.io/hello-agents
[2] Qdrant启动失败问题:https://github.com/datawhalechina/hello-agents/issues/177
[3] Qdrant云服务配置问题:https://github.com/datawhalechina/hello-agents/issues/100
[4] api配置:https://datawhalechina.github.io/handy-multi-agent/#/chapter1/1.2.api-setup
[5] neo4j配置:https://console-preview.neo4j.io/projects/fc9c43d1-5344-4183-86f1-a9b7b2587ee6/instances
[6] 阿里云百炼:https://dashscope.aliyun.com/?accounttraceid=0d7eba7fc3b74ccda29af0dc5805a11bocue
[7] https://github.com/datawhalechina/happy-llm/tree/main/docs
[8] modelscope api_key设置:https://modelscope.cn/my/myaccesstoken
[9] Yao S, Zhao J, Yu D, et al. React: Synergizing reasoning and acting in language models[C]//International Conference on Learning Representations (ICLR). 2023.
[10] Wang L, Xu W, Lan Y, et al. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models[J]. arXiv preprint arXiv:2305.04091, 2023.
[11] Shinn N, Cassano F, Gopinath A, et al. Reflexion: Language agents with verbal reinforcement learning[J]. Advances in Neural Information Processing Systems, 2023, 36: 8634-8652.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)