深入刨析向量数据库:基本原理与流程实现
然而,AI 的搜索是基于概率驱动,在AI的应用场景里是基于对搜索词的语义揣测,进行相似度匹配,如:找内容“相似”的文本或图像。这时向量搜索大显身手:它根据向量之间的距离(如:欧氏距离、余弦相似度)来查找距离最近的向量,从而找到语义相近的项。制,向量数据库能够在一毫秒到几毫秒的时间内,从千万甚至亿级规模的数据中检索出相似项,这正是ANN索引的强大所在。通过优化磁盘I/O的访问模式,DiskANN能在
向量数据库(Vector Database)是一种专门用于存储、索引和查询高维向量数据的数据库系统,其核心设计目标是对向量数据实现高效的相似性搜索(Similarity Search)而非精确匹配。与传统关系型数据库相比,它在数据类型、存储方式和应用场景上存在根本性差异。
1,什么是向量?
向量(Vector)在数学和计算机科学中是一个兼具大小和方向的多维数值对象,而在人工智能领域,它成为表示现实世界复杂特征的“数学指纹”。
数学描述:向量是 n 维空间中的点坐标,表示为有序数组 [v₁, v₂, ..., vₙ],例如三维向量 [0.2, -1.7, 0.5]。它的几何意义:可类比为从原点指向该点的箭头,长度(模)体现整体强度,方向表达特征趋势。
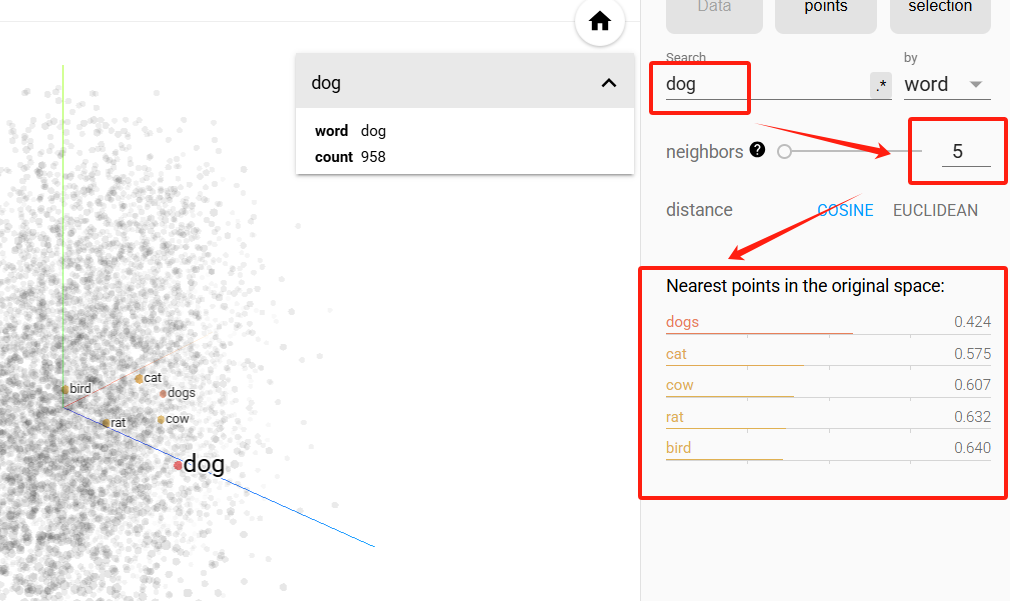
下面是谷歌开源的向量(Embedding)可视化工具,把词条或图片等数据文件,通过不同的降维技术(如PCA、t-SNE等)将高维数据投影到二维或三维空间中,进行直观地展示。这是我加载的词向量模型,每个蓝点是一个英文单词的向量点。
Embedding Projector地址:https://projector.tensorflow.org/
2,什么是向量搜索?
作为一个开发者,大家都在用传统的关系型数据库(如:Mysql、Oracle等),关系型数据库存储的是结构化数据,可通过主键或索引字段实现精确匹配查询。然而,AI 的搜索是基于概率驱动,在AI的应用场景里是基于对搜索词的语义揣测,进行相似度匹配,如:找内容“相似”的文本或图像。这时向量搜索大显身手:它根据向量之间的距离(如:欧氏距离、余弦相似度)来查找距离最近的向量,从而找到语义相近的项。这使得我们能够实现,如:相近语义的文字检索、以图搜图、个性化推荐等功能,而这些是传统数据库难以实现的。
例如:我搜索dog,就能根据dog关键词的向量,找到语义相近的所有词,并根据相似度高低进行排序展示。注意:这个相似度距离是可设置的。
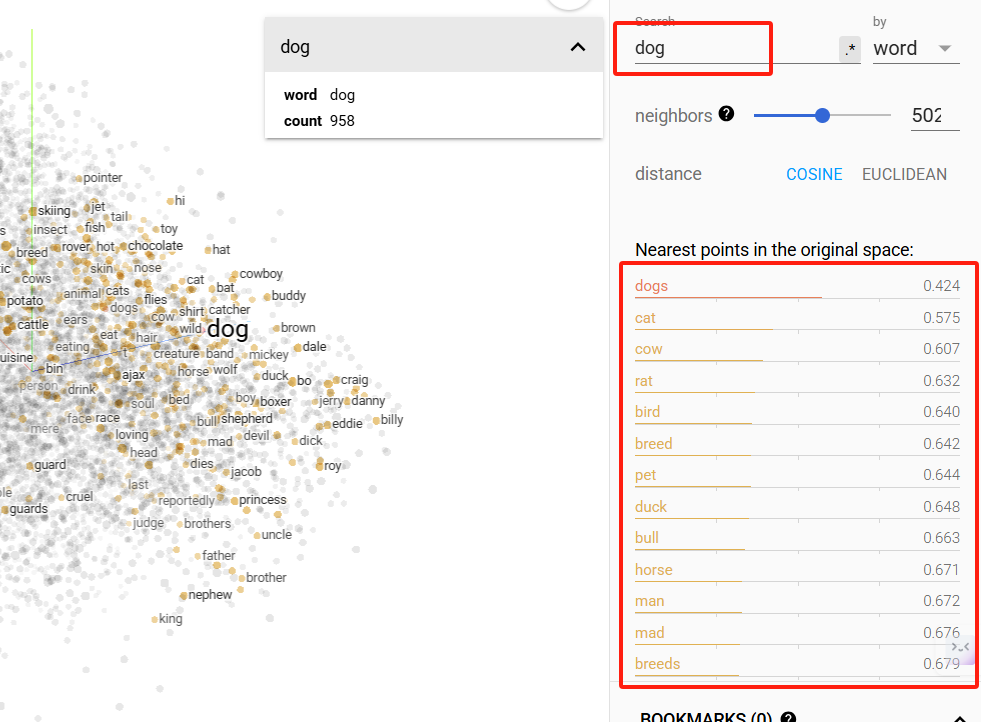
相似度设置为5时,搜索结果如下。在实际应用中,此值不能过低,一般建议在500左右。
3,向量数据的抽象展示
向量是通过大模型获取,如通过深度学习模型提取特征:
text_vector = model.encode("金毛犬") # 输出512维数组 [0.21, -0.33, ..., 0.78]image_vector = model.encode(狗狗图片) # 输出1024维数组模型核心能力是把语义/视觉特征解构为高维向量(如“金毛犬”可能激活[动物, 犬科, 温顺]等维度)。
|
数据类型 |
原始形态 |
向量化表示(示例) |
|---|---|---|
|
文本 |
“帮我推荐跑鞋” |
[0.71, -0.02, 0.49, ...] (512维) |
|
图像 |
狗狗照片.jpg |
[0.33, 0.89, -0.17, ...] (1024维) |
|
用户行为 |
点击序列{商品A,B} |
[0.92, 0.11, -0.43, ...] (256维) |
4,与传统数据库的主要差异
传统数据库主要处理结构化数据,AI 应用场景中需要基于搜索词语义进行相似度匹配查询。
|
维度 |
向量数据库 |
传统关系型数据库 |
|---|---|---|
|
数据类型 |
非结构化数据的高维向量表示 |
结构化数据(行/列) |
|
查询方式 |
相似性搜索(语义/特征匹配) |
精确匹配(SQL条件查询) |
|
典型操作 |
cosine_similarity(vec1, vec2) |
SELECT * WHERE id=100 |
|
适用场景 |
推荐系统、图像检索、语义搜索 |
传统的业务数据存储、用户管理等 |
这里讲完了向量和向量数据库的基本概念,我们已经知道向量数据库能够高效实现相似度搜索,其核心在于底层的算法和数据结构来应对高维向量的存储和检索挑战。那我们再说说向量的距离计算、相似度搜索机制,及向量压缩和存储优化技术。
5,向量的距离度量
向量距离的计算方法根据应用场景和需求不同而有所区分,核心是通过数学公式衡量多维空间中向量的相似性或差异性。
1)欧氏距离(L2)
欧氏距离是衡量两个向量之间“距离”的常用方法。它是在欧几里得空间中,两个点之间的最短直线距离。距离越小表示越相似。对于 n 维向量 a 和 b,欧氏距离计算公式如下:
d(a, b) = sqrt((a1-b1)^2 + (a2-b2)^2 + ... + (an-bn)^2)2)余弦相似度(Cosine)
通过计算两个向量的夹角余弦值来评估他们的相似度。两个向量夹角的余弦值范围[-1,1],数值越大表示越相似。给定两个属性向量,A和B,其余弦相似性θ由点积和向量长度给出,如下所示:
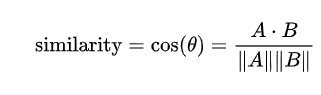
3)点积相似度(Inner Product)
点积相似度也被称为内积相似度,反映两个向量在同一方向上的投影大小。常用于评估向量与某些潜在特征的匹配程度。在推荐场景下,可能用最大内积来度量相似度。对于向量 a=[a1,a2,...,an]a=[a1,a2,...,an] 和 b=[b1,b2,...,bn]b=[b1,b2,...,bn],点积相似度公式为:
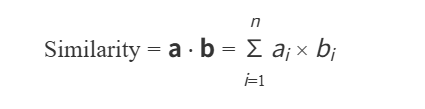
结果值越大,表示向量越相似。
那么,在实际应用中,如何选择度量方式呢?具体选择这取决于向量的含义和应用。例如,当向量各分量已经过归一化时,余弦相似度常用于表示文本或文档的语义相似;在需要匹配强度的场景,内积更合适一些。无论何种度量,向量数据库内部通常会支持多种度量供用户指定,如 L2、Cosine、IP 等,以适应不同的相似性定义。
6,常见的向量索引
向量索引是一种以向量作为键的索引机制。它是原始向量数据的浓缩形式,旨在提供高效且快速的搜索能力。与直接处理原始嵌入相比,向量索引的紧凑性显著降低了内存需求,并提升了数据可访问性。作为一种核心的数据结构,向量索引能够有效地管理高维向量数据,便于执行快速相似性搜索和最近邻查询。向量索引采用了算法来有序地组织高维向量,以便进行高效的搜索。这种排列并非随机,而是通过将相似的向量聚集在一起来实现的。这样,向量索引就能支持快速而精确的相似性搜索和模式识别,尤其适用于大型和复杂的数据集。
1)倒排索引(IVF,Inverted File)
倒排索引是一种常见的向量检索索引类型。它将文档中的每个词作为关键字,建立一个词汇表,记录出现该词的文档列表。当用户输入一个查询词时,系统可以快速找到包含该词的文档。检索时,先根据查询向量找到最近的几个簇中心,只在这些簇内搜索最近邻,而不必遍历全集。这类似于先粗略定位再精细查找,大大减少需要计算距离的向量数量。
2)基于图的检索(HNSW)
HNSW 是一种高效存取数据的复杂方法。其图形结构的灵感来自两种不同的技术: 概率跳表(skip list)和 NSW。它结合了两种传统结构的优点: 链表的快速插入能力和数组的快速检索特性。查找速度快且精度高,是目前主流向量数据库普遍支持的索引。它的一个关键优势是在保持高召回的同时性能非常好,不过它需要将图结构存于内存,对内存消耗相对较大。为了控制内存占用,可以结合PQ对向量进行压缩存储,或者调节每个节点邻居数M等参数。
3)乘积量化(PQ,Product Quantization)
它是一种向量压缩技术,将每个向量分成了若干子向量,这样每个原始向量可以用几个字节的码字表示,计算距离时通过查表快速得到近似距离。PQ大幅减少内存占用,同时保持较高的召回率,是提高查询性能和节省存储的常用技术。在实践中,PQ常与IVF结合形成IVF-PQ索引:先用IVF缩小搜索范围,再用PQ近似计算精细距离。通过将向量分段并用字节编码,大幅减少存储空间和计算量,适合超大规模数据。
4)磁盘索引(DiskANN)
DiskANN是微软研究提出的在磁盘上的ANN算法,它只将轻量级的索引结构放在内存,将大量原始向量和索引的其余部分存储在磁盘。通过优化磁盘I/O的访问模式,DiskANN能在一台64G内存的设备上处理十亿规模及以上的向量数据,并在保持95%以上召回率,同时将查询延迟控制在毫秒级。也就是来说,磁盘索引(DiskANN)让超大规模向量搜索成为可能,在牺牲一些查询响应的一致性的情况下,极大降低了内存需求,被认为是目前最有效的磁盘型向量索引之一。
7,ANN--近似最近邻机制
近似最近邻搜索(Approximate Nearest Neighbor Search, ANN)是一种通过牺牲部分精度来换取更高检索效率的算法,主要用于海量高维数据的快速相似性查找。
传统最近邻搜索(NNS)需遍历所有数据,时间复杂度O(n),而ANN通过空间划分、量化或图结构将复杂度降至O(log n)或更低,召回率通常控制在70%~99%。例:HNSW算法在十亿级数据中实现毫秒级响应,召回率>95%。但实践中可以达到接近100%的召回率。向量数据库在执行查询时,会依据用户设定的查找参数(如HNSW的ef、IVF的nprobe等)来平衡速度和精度。召回率(Recall)是衡量ANN搜索结果与真实最近邻重合程度的指标,用户可以通过调整参数在召回率和查询延迟之间做权衡。
在查询过程中,执行步骤如下:
1)预处理:将用户输入的查询词经过大模型编码成向量。
2)粗筛阶段:利用向量索引结构快速缩小候选集。如:HNSW图搜索锁定到一个小区域,IVF会先选出若干最近的聚类中心。从而大量降低了需精细比较的向量数量。
3)精筛阶段:对锁定的候选集,进行精确距离计算或更精细的比较,得到最后的Top K最近邻结果。有一些系统在这一步,可能会使用原始未压缩的向量重新计算一次距离(re-ranking),以提高结果精度。
4)附加处理:有时候还会对结果进行附加处理,如:指定的过滤条件、对距离进行归一化或转换为相似度分值等。如果用户请求了元数据字段,也会在这一步把对应的元数据取出附加到结果上。
通过近似最近邻检索(ANN)机制,向量数据库能够在一毫秒到几毫秒的时间内,从千万甚至亿级规模的数据中检索出相似项,这正是ANN索引的强大所在。当然,对不同规模和维度的数据,索引效果会有所差异,没有单一算法在所有情况下都是最优。因此实际应用中经常需要根据数据特点试验调整索引类型和参数,以达到理想的性能。
8,向量压缩和存储优化
向量相似性搜索需要大量的内存资源来实现高效搜索,特别是在处理密集的向量数据集时。而压缩的主要作用是压缩高维向量来优化内存存储。高维向量的数据量往往很庞大,一个100万条、512维的单精度浮点向量集合就需要近2GB内存。通过压缩与存储优化,实现 “用20%资源承载100%业务” 的效能革命,驱动AI落地的普适化与商业化。
为降低存储成本、提高查询效率,向量数据库在存储层面也采用了多种优化手段:
1)量化压缩
可通过乘积量化(PQ)、标量量化(SQ)、二值量化(BQ)量化技术,将向量进行压缩,达到减小计算和存储的开销。乘积量化(PQ)将高维向量分段压缩(如128D→8×16D),存储空间减少75%+。标量量化(SQ)可将32位浮点转8位整数,存储降至1/4。二值量化(BQ),存储减少32倍,端侧延迟<5ms,仅保留符号信息,精度损失较大。
|
技术 |
原理 |
存储缩减 |
精度损失 |
|---|---|---|---|
|
PQ |
将高维向量切分为子段(如128维→8×16维),对每段独立量化生成码本,通过笛卡尔积组合还原近似向量 |
97%+ |
中等(召回率85%) |
|
SQ |
将32位浮点数(float32)线性映射为8位整数(uint8) |
75% |
低(召回率>95%) |
|
BQ |
将向量各维度符号转化为1/0(如[0.5, -0.3]→[1, 0]) |
96.875% |
高(召回率≈75%) |
典型地就是将成百上千维的向量压缩到几十或几百维,从而减少计算和存储开销。但量化降维通常要权衡信息损失,在很多任务上低维嵌入仍能保留主要的语义信息。
2)低精度混合存储
使用向量压缩技术,可采用 8 位或 16 位整数/浮点表示超过32位高维向量。例如,有的系统支持将向量压缩为 INT8,使得内存减少至少4倍,同时通过SIMD指令可并行算距离。通过可控精度损失换取存储与算力的指数级优化,已成为AI大规模落地的关键技术杠杆。
一般向量存储在内存空间,然而当数据规模达到一定量后,就会导致纯内存放不下,这是会考虑分层存储策略。一种方式是说的磁盘索引(DiskANN),把主要计算密集的结构留在内存,而将数据页置于磁盘并利用操作系统的预取机制。另一种是分批加载:在查询时根据需要动态加载部分向量到内存。一些向量数据库还支持分片(sharding)和副本,将数据拆分到多节点存储,每节点负责一部分数据并各自持有内存,这其实是在系统架构层面而非单机层面解决存储瓶颈。
通常压缩和存储是配套出现的,通过适当的压缩,用较小的代价存储巨量的向量,但压缩也会引入近似误差,所以,一般可结合近似最近邻搜索(ANN)方法一并考虑,确保在提高性能的同时维持可接受的检索精度。
9,常用的向量数据库
常用的向量数据库包括Chroma、Pinecone、VectorDB、Milvus、LanceDB和pgvector(PostgreSQL插件)等,它们在轻量级应用、实时搜索、多模态支持、大规模数据处理等不同场景下各有优势。
|
库 |
特性 |
优缺点 |
|---|---|---|
|
Chroma |
轻量级开源工具,适合小型项目或初学者。 适合场景:快速原型验证 |
无原生持久化存储,超10亿向量时性能下降40% |
|
LanceDB |
微秒级本地查询,无需独立服务部署,适配移动端。 适合场景:边缘设备部署 |
仅支持千万级数据,索引重建耗时长 |
|
Pinecone |
API调用成功率99.99%,内置RBAC权限与加密功能,适合实时推荐系统。 适合场景:实时推荐系统 |
百万token调用成本$0.13,长期使用费用较高 |
|
VectorDB |
无缝对接国产大模型(通义、文心),支持自动扩缩容与跨地域灾备。 适合场景:阿里系/国产模型 |
私有化部署功能受限,开源生态弱于Milvus。 |
|
Milvus |
有开源版和商业版,低延迟,适用于图像/视频检索场景。 适合场景:超大规模企业级 |
部署复杂,内存占用高(72B模型需3张A100显卡)。 |
|
pgvector |
支持ACID事务与SQL操作,开发门槛低,适合中小规模文本相似性匹配。 适合场景:PostgreSQL生态集成 |
10亿级数据导入超24小时,复杂过滤召回率下降25%。 |
往期文章:


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)