ICCV 2025最佳学生论文 | 告别反演!FlowEdit开辟图像编辑新范式,用“多路径平均“实现SOTA级结构保持
准备素材:将需要编辑的图像上传至文件夹。配置编辑参数:创建edits.yaml文件,指定输入图像路径、源提示词、目标提示词及目标代码(用于描述源与目标的差异,将体现在输出文件名中),可参考示例文件格式。创建实验配置文件(如自定义),设置n_maxn_min等超参数,并指定edits.yaml的路径,具体参数含义可参考论文。执行编辑:运行命令python run_script.py --exp_ya
终于!ICCV 2025 大会已公布最佳论文与最佳学生论文(前者由卡内基梅隆大学团队摘得,后者归属以色列理工学院,均从11000多篇投稿中脱颖而出,最佳论文解读见公众号另一篇文章),本文聚焦最佳学生论文《 FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained Flow Models》。
其核心目标是让AI按“把猫变成狗”这类指令修改图片,同时最大程度保留原图结构与风格——这一任务颇具挑战:传统“先反演再编辑”方法如同将画作拆解为杂乱颜料点(噪声)后重绘,易出现画面失真或丢失原作精髓的问题。而该论文提出的 FlowEdit 跳过了“拆解”步骤,恰似高明画家直接在原画上修改,构建起从原始图像到目标图像的直接平滑路径,不仅编辑更稳定、对原图结构破坏更小,效果也达到了新的SOTA水平。
1. 【导读】

论文标题:FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained Flow Models
作者:Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, Tomer Michaeli
作者机构:以色列理工学院 (Technion – Israel Institute of Technology)
论文来源:ICCV 2025 Best Student Paper
论文链接:https://openaccess.thecvf.com/content/ICCV2025/papers/Kulikov_FlowEdit_Inversion-Free_Text-Based_Editing_Using_Pre-Trained_Flow_Models_ICCV_2025_paper.pdf
项目链接:项目主页:https://matankleiner.github.io/flowedit/;代码仓库:https://github.com/fallenshock/FlowEdit
2. 【论文速读】
针对现有基于预训练文本到图像(T2I)流模型的图像编辑常依赖反转操作、跨模型迁移性差等问题,该论文提出FlowEdit——一种无反转、无优化且模型无关的文本驱动图像编辑方法。该方法摒弃“反转-重采样”范式,直接构建源分布(对应源提示)与目标分布(对应目标提示)间的常微分方程(ODE) ,通过更短的传输路径降低运输成本,实现更优的结构保真度。在Stable Diffusion 3和FLUX模型上的实验表明,FlowEdit在复杂编辑任务中达成当前最优性能,既精准契合文本提示,又能有效保留原图结构特征。

3.【从“反转困局”到“直接映射”:FlowEdit的研究缘起与领域探索】
3.1 研究背景
- 现有文本到图像(T2I)流/扩散模型编辑依赖“图像-噪声反转”,效果有限且需额外干预,跨模型迁移性差。
- 即便无反转误差,“反转-编辑”仍易丢失源图结构;注入内部特征虽提升保真度,却限制对新模型的适配。
- 需突破“反转依赖”,设计无优化、模型无关的方法,直接建立源-目标分布映射,兼顾文本契合度与结构保留。
3.2 相关工作
- 优化类方法:通过优化图像贴合提示,资源消耗大,流模型相关方法较少。
- 无优化类方法:
- 主流路径:以“反转”为核心,改进精度仍难解决结构丢失,且受限于特定模型(如扩散模型)。
- 流模型专属:少数相关工作仍依赖反转或特征注入,存在迁移性、保真度不足等问题。
- 本研究突破:FlowEdit无需反转与优化,不干预模型内部,通过直接ODE路径实现编辑,提升适配性与保真度。
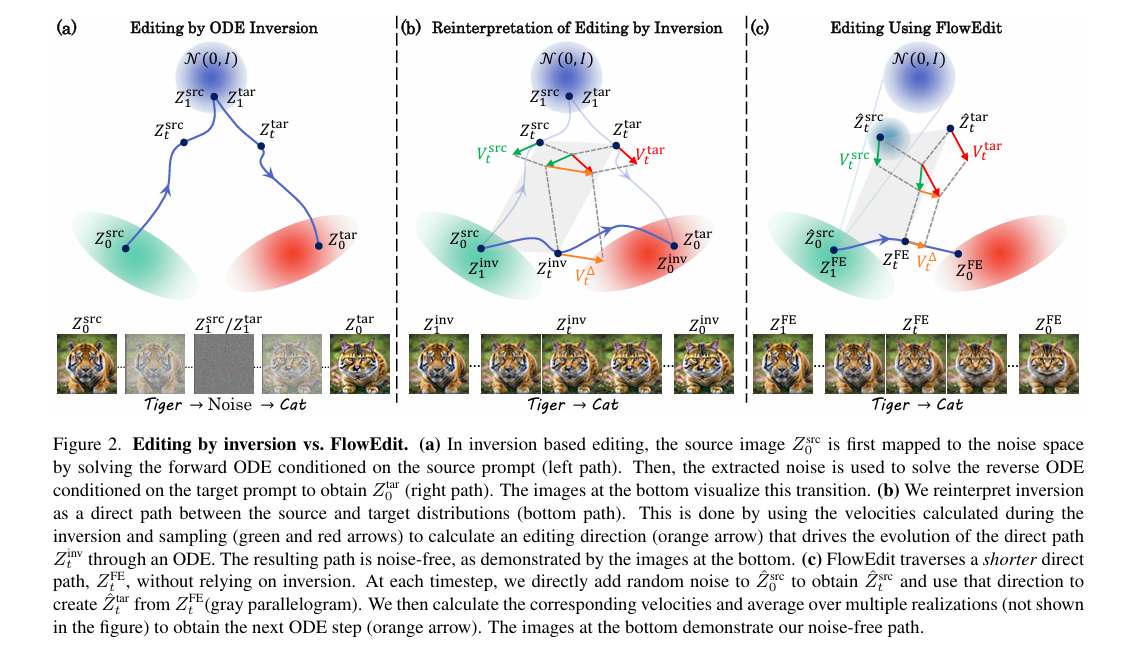
4.【跳出反转怪圈:FlowEdit的直接映射方法论】
4.1 基础理论铺垫(Preliminaries)
4.1.1 整流流模型(Rectified Flow models)
- 核心目标:构建两个随机向量分布 X 0 X_0 X0与 X 1 X_1 X1间的传输路径,通过时间 t ∈ [ 0 , 1 ] t \in [0,1] t∈[0,1]上的常微分方程(ODE)定义: d Z t = V ( Z t , t ) d t dZ_t = V(Z_t, t)dt dZt=V(Zt,t)dt,其中 V V V是时间依赖的速度场(由神经网络参数化)。
- 采样逻辑:通常设 X 1 ∼ N ( 0 , I ) X_1 \sim N(0,I) X1∼N(0,I)(标准高斯分布),从 t = 1 t=1 t=1的高斯样本出发,反向求解ODE得到 t = 0 t=0 t=0时 X 0 X_0 X0的样本。
- 关键特性:整流流的时间 t t t边缘分布对应 X 0 X_0 X0与 X 1 X_1 X1的线性插值,采样路径更平直,需更少离散化步骤即可求解ODE。
- 文本条件适配:文本到图像流模型的速度场扩展为 V ( X t , t , C ) V(X_t, t, C) V(Xt,t,C), C C C为文本提示,模型训练于文本-图像对 ( C , X 0 ) (C, X_0) (C,X0),支持从条件分布 X 0 ∣ C X_0 | C X0∣C采样。
4.1.2 基于ODE反转的图像编辑
- 核心流程:给定源图像 X s r c X^{src} Xsrc、源提示 c s r c c_{src} csrc和目标提示 c t a r c_{tar} ctar,定义文本条件速度场 V s r c ( X t , t ) = V ( X t , t , c s r c ) V^{src}(X_t, t) = V(X_t, t, c_{src}) Vsrc(Xt,t)=V(Xt,t,csrc)、 V t a r ( X t , t ) = V ( X t , t , c t a r ) V^{tar}(X_t, t) = V(X_t, t, c_{tar}) Vtar(Xt,t)=V(Xt,t,ctar)。
- 反转步骤:从 t = 0 t=0 t=0的 Z 0 s r c = X s r c Z_0^{src}=X^{src} Z0src=Xsrc出发,求解正向ODE d Z t s r c = V s r c ( Z t s r c , t ) d t dZ_t^{src}=V^{src}(Z_t^{src}, t)dt dZtsrc=Vsrc(Ztsrc,t)dt,得到 t = 1 t=1 t=1时的噪声图 Z 1 s r c Z_1^{src} Z1src。
- 重采样步骤:以 Z 1 t a r = Z 1 s r c Z_1^{tar}=Z_1^{src} Z1tar=Z1src为起点,反向求解 V t a r V^{tar} Vtar对应的ODE,得到 t = 0 t=0 t=0时的编辑后图像 Z 0 t a r Z_0^{tar} Z0tar。
4.2 对反转编辑的重新解读
- 本质重构:反转编辑可视为源与目标分布间的间接路径(需经高斯噪声分布),但可等价转化为直接路径 Z t i n v Z_t^{inv} Ztinv,满足 Z 1 i n v = Z 0 s r c Z_1^{inv}=Z_0^{src} Z1inv=Z0src( t = 1 t=1 t=1时为源图像)、 Z 0 i n v = Z 0 t a r Z_0^{inv}=Z_0^{tar} Z0inv=Z0tar( t = 0 t=0 t=0时为编辑后图像)。
- 直接ODE推导:对等价关系微分并代入反转编辑的ODE,得到直接路径的ODE: d Z t i n v = V t Δ ( Z t s r c , Z t t a r ) d t dZ_t^{inv} = V_t^{\Delta}(Z_t^{src}, Z_t^{tar})dt dZtinv=VtΔ(Ztsrc,Zttar)dt,其中 V t Δ ( Z t s r c , Z t t a r ) = V t a r ( Z t t a r , t ) − V s r c ( Z t s r c , t ) V_t^{\Delta}(Z_t^{src}, Z_t^{tar})=V^{tar}(Z_t^{tar}, t)-V^{src}(Z_t^{src}, t) VtΔ(Ztsrc,Zttar)=Vtar(Zttar,t)−Vsrc(Ztsrc,t)。
- 路径特性:该直接路径上的图像无噪声,且遵循“粗到细”的进化逻辑—— t t t接近1时修改粗结构, t t t减小后逐步优化细纹理。
4.3 FlowEdit核心方法设计
4.3.1 核心思想
摒弃反转依赖,通过多个随机配对的速度场平均,构建源与目标分布间更短的直接路径,降低传输成本,提升结构保真度。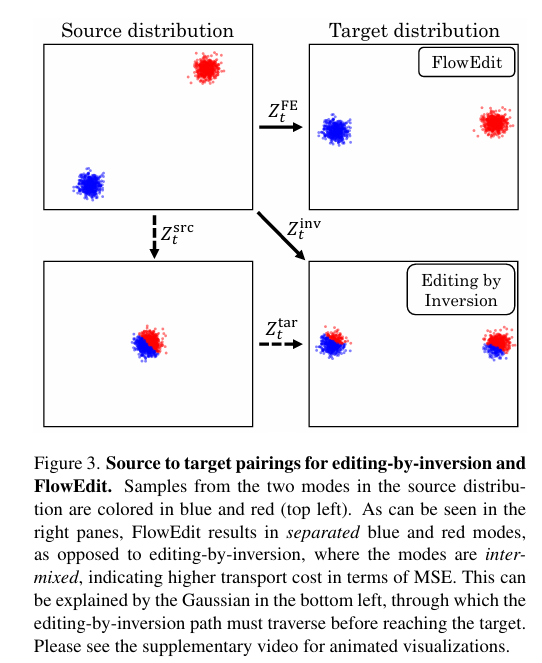
4.3.2 关键公式与流程
- 核心ODE: d Z t F E = E [ V t Δ ( Z ^ t s r c , Z t F E + Z ^ t s r c − Z 0 s r c ) ∣ Z 0 s r c ] d t dZ_t^{FE} = \mathbb{E}[V_t^{\Delta}(\hat{Z}_t^{src}, Z_t^{FE}+\hat{Z}_t^{src}-Z_0^{src}) | Z_0^{src}]dt dZtFE=E[VtΔ(Z^tsrc,ZtFE+Z^tsrc−Z0src)∣Z0src]dt,其中 Z ^ t s r c = ( 1 − t ) Z 0 s r c + t N t \hat{Z}_t^{src}=(1-t)Z_0^{src}+tN_t Z^tsrc=(1−t)Z0src+tNt, N t ∼ N ( 0 , 1 ) N_t \sim N(0,1) Nt∼N(0,1)且与 Z 0 s r c Z_0^{src} Z0src独立。
- 边界条件: Z 1 F E = Z 0 s r c Z_1^{FE}=Z_0^{src} Z1FE=Z0src( t = 1 t=1 t=1时初始化为源图像),求解ODE至 t = 0 t=0 t=0得到编辑后图像 Z 0 F E Z_0^{FE} Z0FE。
- 速度场计算:
- 对每个 N t N_t Nt采样,得到 Z ^ t s r c \hat{Z}_t^{src} Z^tsrc和 Z ^ t t a r = Z t F E + Z ^ t s r c − Z 0 s r c \hat{Z}_t^{tar}=Z_t^{FE}+\hat{Z}_t^{src}-Z_0^{src} Z^ttar=ZtFE+Z^tsrc−Z0src。
- 计算速度差 V t Δ = V t a r ( Z ^ t t a r , t ) − V s r c ( Z ^ t s r c , t ) V_t^{\Delta}=V^{tar}(\hat{Z}_t^{tar}, t)-V^{src}(\hat{Z}_t^{src}, t) VtΔ=Vtar(Z^ttar,t)−Vsrc(Z^tsrc,t),多次采样后取平均作为ODE更新方向。
4.3.3 实操优化
- 离散时间步:采用离散时间集 { t i } i = 0 T \{t_i\}_{i=0}^T {ti}i=0T驱动编辑, T T T为离散化步数。
- 期望近似:通过 n a v g n_{avg} navg次模型预测平均近似期望, n a v g = 1 n_{avg}=1 navg=1时仍能保证效果(利用时间步间自然平均)。
- 噪声独立性:设 N t N_t Nt的协方差满足 ∣ t − s ∣ > δ |t-s|>\delta ∣t−s∣>δ时 E [ N t N s ] = 0 \mathbb{E}[N_tN_s]=0 E[NtNs]=0( δ \delta δ为ODE离散步),确保噪声跨时间步独立。
- 编辑强度控制:定义 0 ≤ n m a x ≤ T 0 \leq n_{max} \leq T 0≤nmax≤T, Z t n m a x F E = X s r c Z_{t_{n_{max}}}^{FE}=X^{src} ZtnmaxFE=Xsrc, n m a x = T n_{max}=T nmax=T时编辑最强, n m a x < T n_{max}<T nmax<T时跳过前 ( T − n m a x ) (T-n_{max}) (T−nmax)步以减弱编辑强度。
4.3.4 简化算法流程
- 输入:源图像 X s r c X^{src} Xsrc、时间步 { t i } i = 0 T \{t_i\}_{i=0}^T {ti}i=0T、 n m a x n_{max} nmax(起始时间步)、 n a v g n_{avg} navg(采样平均次数)。
- 初始化: Z t n m a x F E = X s r c Z_{t_{n_{max}}}^{FE}=X^{src} ZtnmaxFE=Xsrc。
- 迭代更新:从 i = n m a x i=n_{max} i=nmax到 1 1 1,采样 N t ∼ N ( 0 , 1 ) N_t \sim N(0,1) Nt∼N(0,1),计算 Z ^ t i s r c \hat{Z}_{t_i}^{src} Z^tisrc、 Z ^ t i t a r \hat{Z}_{t_i}^{tar} Z^titar和 V t Δ V_t^{\Delta} VtΔ,平均 n a v g n_{avg} navg次后更新 Z t i − 1 F E = Z t i F E + ( t i − 1 − t i ) V t Δ Z_{t_{i-1}}^{FE}=Z_{t_i}^{FE}+(t_{i-1}-t_i)V_t^{\Delta} Zti−1FE=ZtiFE+(ti−1−ti)VtΔ。
- 输出: Z 0 F E Z_0^{FE} Z0FE(编辑后图像)。

点击阅读原文,获取更多论文相关咨询
5.【FlowEdit实战成绩单:从数据到落地的亮眼结果】
5.1 合成数据实验:低传输成本+强结构保留
- 实验:SD3生成1000张“猫”图,对比FlowEdit与精确反转法编辑为“狗”图的效果。
- 结果:MSE(1376 vs 2239)、LPIPS(0.15 vs 0.25)更低,结构保留更优;FID(51.14 vs 55.88)、KID(0.017 vs 0.023)更低,贴合目标分布。

5.2 真实图像编辑:多场景适配+跨模型稳定
- 配置:70+张1024²真实图像、250+文本-图像对,在SD3(T=50、n_max=33)和FLUX(T=28、n_max=24)上测试,对比多款主流方法。
- 结果:精准完成局部编辑、多物体修改、风格转换,不引入无关元素;跨模型表现一致,背景细节保留优于竞品。

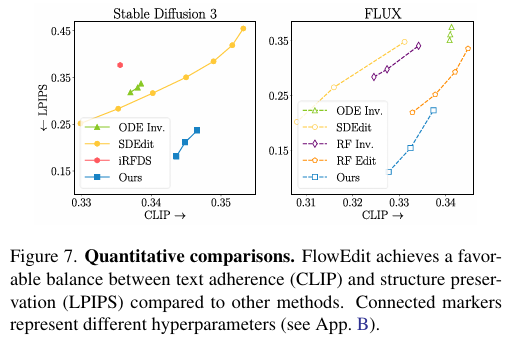
5.3 定量对比:最优文本-结构平衡
- 指标:LPIPS(结构保留)、CLIP(文本契合)。
- 结论:在SD3和FLUX上均实现双指标最佳平衡;n_avg=1时仍稳定,无需复杂调参即超越竞品。
5.4 功能拓展:支持风格编辑
- 实现:移除生成后期源图依赖,调整超参数允许适度结构偏差。
- 效果:完成“照片→动漫”“写实→Pixar风格”转换,兼顾风格一致性与主体轮廓保留。

6.【挣脱反转枷锁:图像编辑的直接映射新未来】
本文提出无反转、无优化且模型无关的文本驱动图像编辑方法FlowEdit,通过构建源与目标分布间的直接ODE路径,在SD3和FLUX模型上实现了更低的传输成本与更优的结构保留,在合成数据与真实图像编辑任务中均达成当前最优性能,还支持风格转换等拓展功能;未来可进一步优化对图像大范围、大幅度修改的适配能力,探索在视频编辑、3D内容修改等更广泛场景的应用潜力,持续推进文本驱动生成技术的实用性与灵活性。
7.【FlowEdit上手秘籍:三步玩转图像编辑】
7.1 环境搭建:备好“工具箱”
- 克隆代码仓库到本地。
- 安装依赖库:通过
pip install torch diffusers transformers accelerate sentencepiece protobuf命令安装基础依赖,若新版diffusers存在兼容问题,可尝试指定版本diffusers==0.30.1。 - 环境说明:已在CUDA 12.4和diffusers 0.30.0版本下测试通过。
7.2 快速体验:跑通示例
- 运行Stable Diffusion 3编辑:执行命令
python run_script.py --exp_yaml SD3_exp.yaml。 - 运行Flux编辑:执行命令
python run_script.py --exp_yaml FLUX_exp.yaml,即可体验预设示例的图像编辑效果。
7.3 自定义编辑:玩转专属内容
- 准备素材:将需要编辑的图像上传至
example_images文件夹。 - 配置编辑参数:
- 创建
edits.yaml文件,指定输入图像路径、源提示词、目标提示词及目标代码(用于描述源与目标的差异,将体现在输出文件名中),可参考示例文件格式。 - 创建实验配置文件(如自定义
my_exp.yaml),设置n_max、n_min等超参数,并指定edits.yaml的路径,具体参数含义可参考论文。
- 创建
- 执行编辑:运行命令
python run_script.py --exp_yaml <你的实验配置文件路径>,即可生成自定义编辑结果。
7.4 拓展玩法:更多模型支持
- ComfyUI实现:FLUX和HunyuanLoom模型的ComfyUI插件由logtd开发,可按需使用。
- 视频编辑:LTX-Video的ComfyUI实现可在其官方仓库中获取,支持视频编辑场景。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)