译 | 使用大型语言模型(LLM)进行客户聚类:入门案例
客户聚类入门案例
文章出自:Mastering Customer Segmentation with LLMs
本篇技术亮点在于利用大语言模型(LLM)的文本嵌入能力,将复杂客户信息转化为高维向量,从而提升传统聚类算法(如Kmeans)的细分效果。它能捕获客户数据中更深层次的语义关联,使得生成的客户群体更具区分度和业务洞察力。
该方法适用于拥有丰富非结构化客户数据,且需要更精细化用户画像的商业场景。
例如,电商平台可根据用户评论、浏览历史等文本信息,结合购买数据,细分出对特定产品风格偏好、消费能力不同的客户群,进行精准营销;银行可分析客户的职业描述、交易习惯等,识别出潜在的高净值或风险客户,提供定制化服务。
文章目录
1 引言
客户细分项目可以通过多种方式进行。在本文中,我将向您介绍高级技术,不仅可以定义聚类,还可以分析结果。这篇帖子旨在帮助那些希望拥有多种工具来解决聚类问题并离高级数据科学家更近一步的数据科学家。
我们将在本文中看到什么?
让我们看看处理这类项目的 3 种方法:
- Kmeans
- K-Prototype
- LLM + Kmeans
作为小预览,我将展示不同模型创建的 2D 表示(PCA)的以下比较:
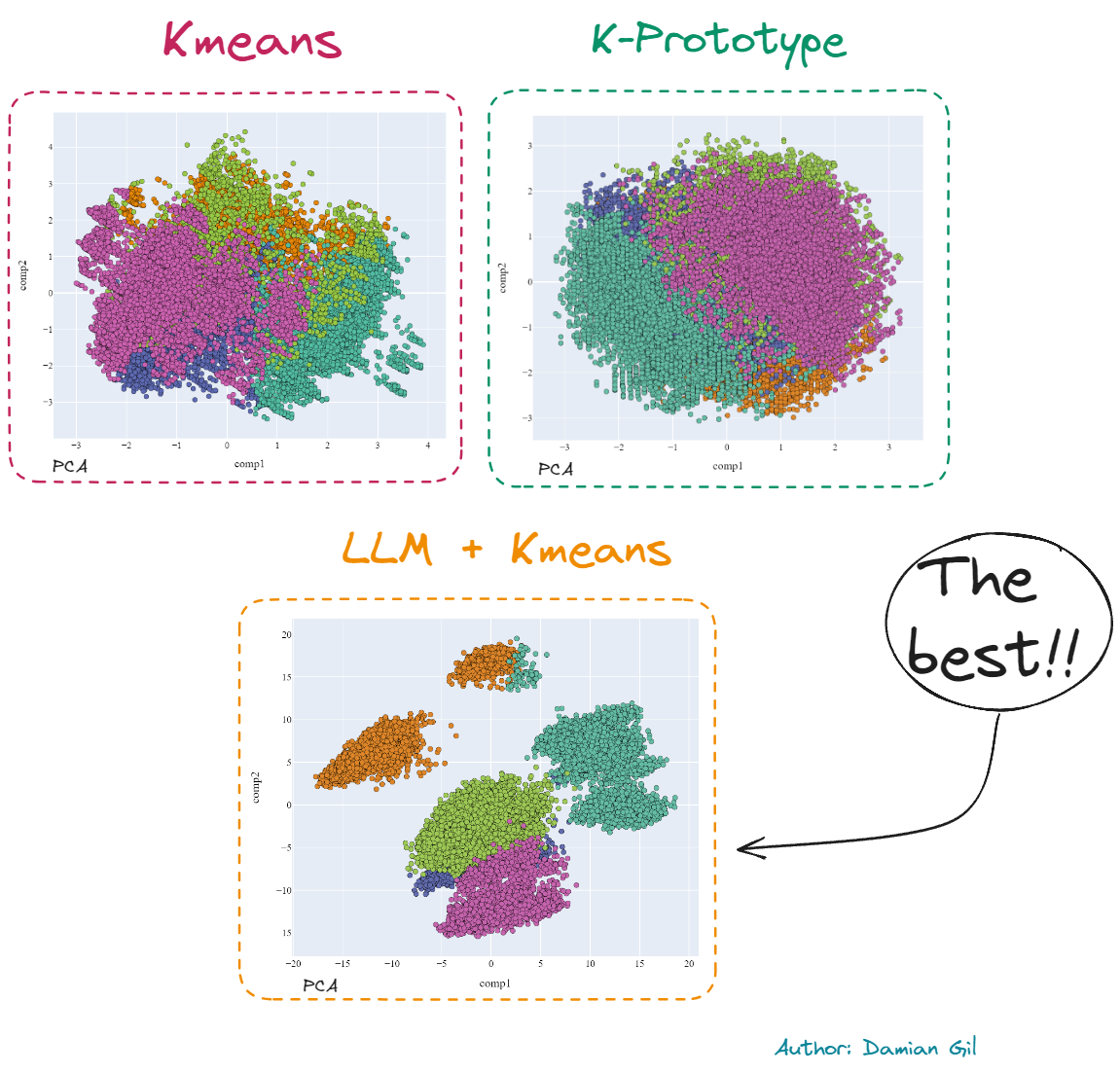
三种方法的图形比较(图片来源:作者)。
您还将学习降维技术,例如:
- PCA
- t-SNE
- MCA
部分结果如下:
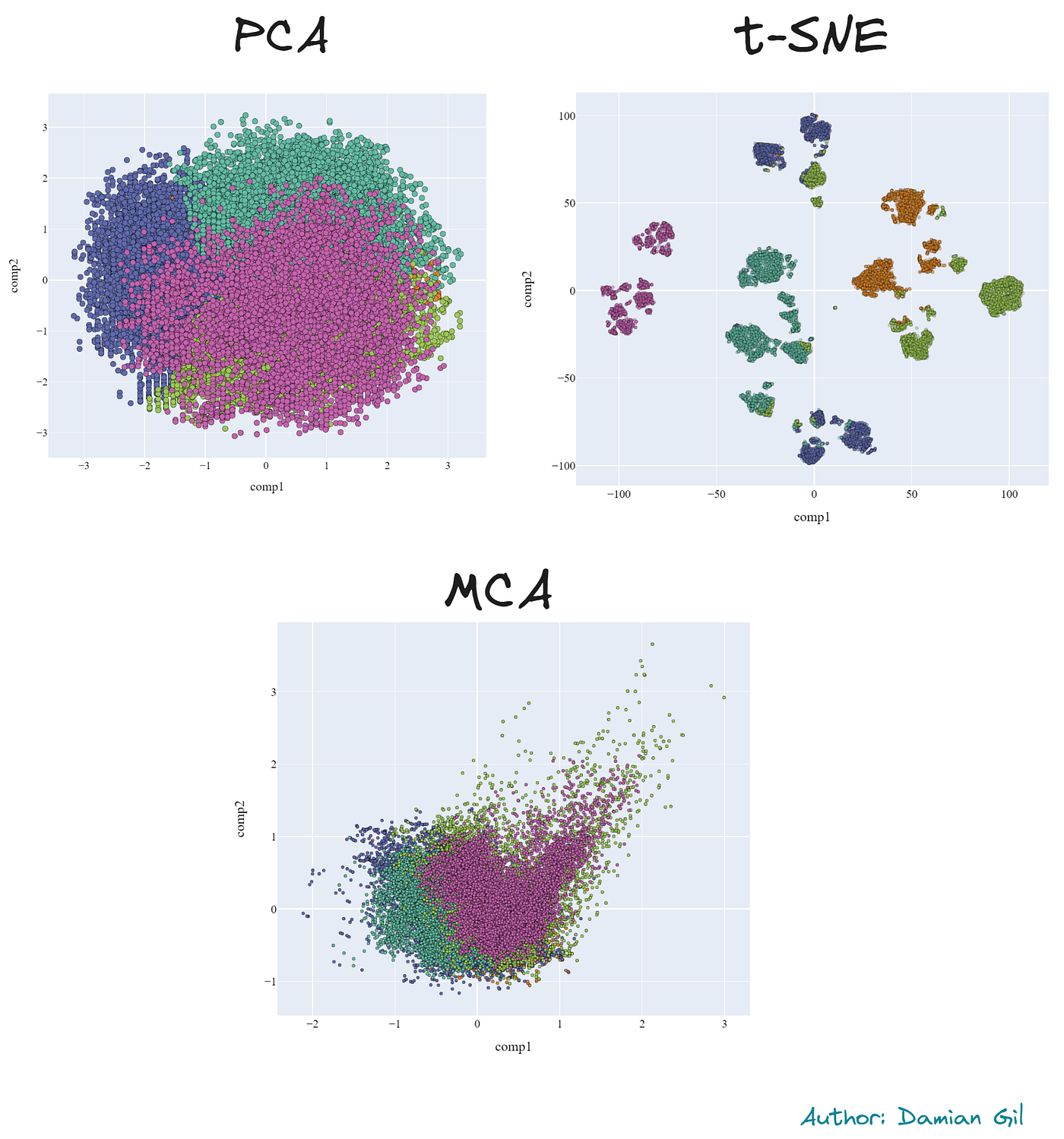
三种降维方法的图形比较(图片来源:作者)。
您可以在这里找到包含笔记本的项目。您也可以查看我的 GitHub:
一个非常重要的说明是,这不是一个端到端项目。这是因为我们跳过了这类项目中最重要的部分之一:探索性数据分析(EDA)阶段或变量选择。
2 数据
本项目使用的原始数据来自 Kaggle 的公开数据集:银行数据集 — 营销目标。此数据集中的每一行都包含有关公司客户的信息。有些字段是数值型的,有些是类别型的,我们将看到这扩展了解决问题的可能方法。
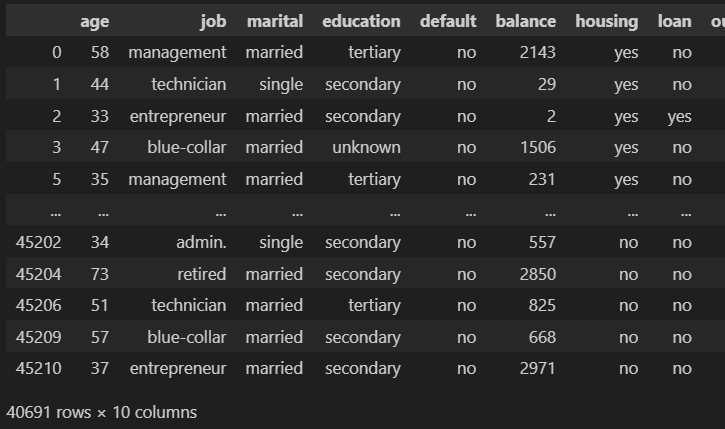
我们只保留前 8 列。我们的数据集看起来像这样:
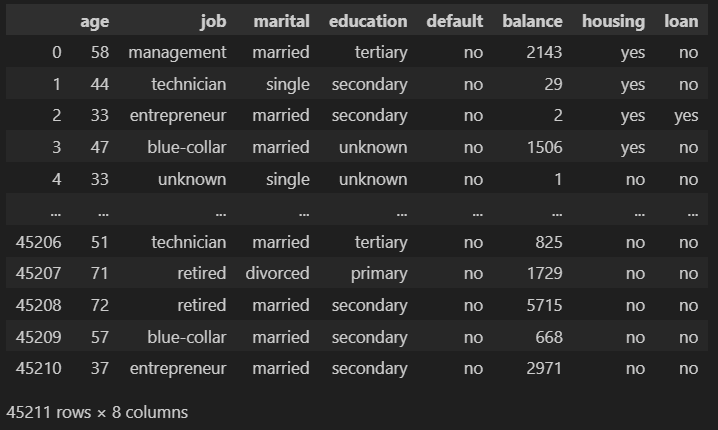
让我们简要描述一下我们数据集的列:
- age (数值型)
- job : 工作类型 (类别型: “admin.” ,”unknown”,”unemployed”, ”management”, ”housemaid”, ”entrepreneur”, ”student”, “blue-collar”, ”self-employed”, ”retired”, ”technician”, ”services”)
- marital : 婚姻状况 (类别型: “married”,”divorced”,”single”; 注意: “divorced” 表示离婚或丧偶)
- education (类别型: “unknown”,”secondary”,”primary”,”tertiary”)
- default: 是否有信用违约? (二元型: “yes”,”no”)
- balance: 年平均余额,单位欧元 (数值型)
- housing: 是否有住房贷款? (二元型: “yes”,”no”)
- loan: 是否有个人贷款? (二元型: “yes”,”no”)
对于该项目,我使用了 Kaggle 的训练数据集。在项目仓库中,您可以找到一个名为 “data” 的文件夹,其中存储了项目中使用的压缩数据集文件。此外,您还会在压缩文件内部找到两个 CSV 文件。一个是 Kaggle 提供的训练数据集 (train.csv),另一个是执行嵌入后生成的数据集 (embedding_train.csv),我们稍后将对此进行进一步解释。
为了进一步阐明项目结构,项目树如下所示:
clustering_llm
├─ data
│ ├─ data.rar
├─ img
├─ embedding.ipynb
├─ embedding_creation.py
├─ kmeans.ipynb
├─ kprototypes.ipynb
├─ README.md
└─ requirements.txt
3 方法 1: Kmeans
这是最常见的方法,也是您肯定会知道的方法。无论如何,我们都将对其进行研究,因为我将展示这些情况下的高级分析技术。您可以在名为 kmeans.ipynb 的 Jupyter 笔记本中找到完整的程序。
3.1 预处理
对变量进行预处理:
- 将类别变量转换为数值变量。
我们将对名义变量应用 OneHotEncoder,对序数特征(education)应用 OrdinalEncoder。 - 我们尝试确保数值变量具有高斯分布。为此,我们将应用 PowerTransformer。
让我们看看代码如何实现。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import plotly.express as px
import plotly.graph_objects as go
import seaborn as sns
import shap
from sklearn.cluster import KMeans
from sklearn.preprocessing import PowerTransformer, OrdinalEncoder
from sklearn.pipeline import Pipeline
from sklearn.manifold import TSNE
from sklearn.metrics import silhouette_score, silhouette_samples, accuracy_score, classification_report
from pyod.models.ecod import ECOD
from yellowbrick.cluster import KElbowVisualizer
import lightgbm as lgb
import prince
df = pd.read_csv("train.csv", sep = ";")
df = df.iloc[:, 0:8]
categorical_transformer_onehot = Pipeline(
steps=[
("encoder", OneHotEncoder(handle_unknown="ignore", drop="first", sparse=False))
])
categorical_transformer_ordinal = Pipeline(
steps=[
("encoder", OrdinalEncoder())
])
num = Pipeline(
steps=[
("encoder", PowerTransformer())
])
preprocessor = ColumnTransformer(transformers = [
('cat_onehot', categorical_transformer_onehot, ["default", "housing", "loan", "job", "marital"]),
('cat_ordinal', categorical_transformer_ordinal, ["education"]),
('num', num, ["age", "balance"])
])
pipeline = Pipeline(
steps=[("preprocessor", preprocessor)]
)
pipe_fit = pipeline.fit(df)
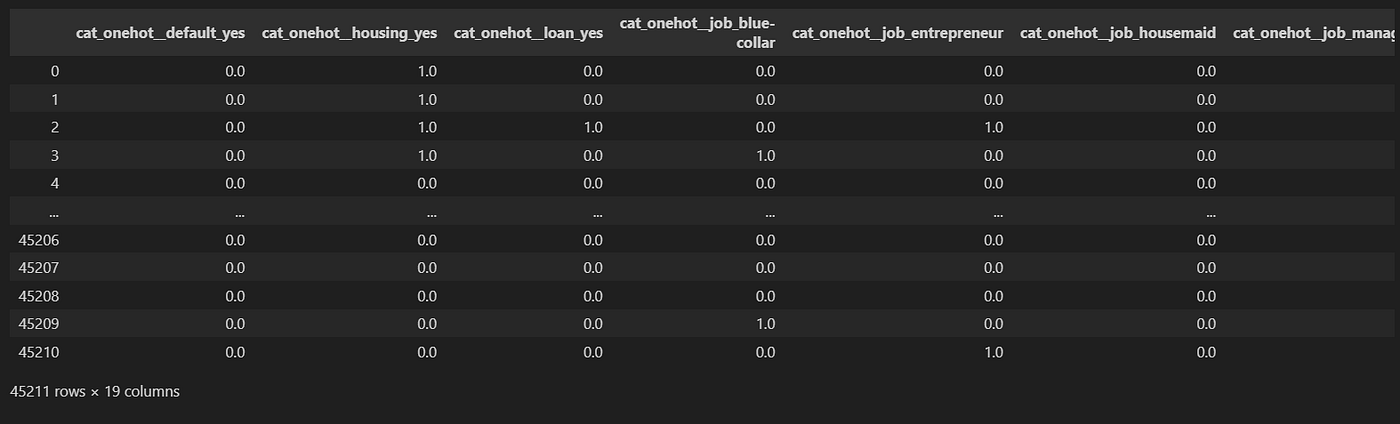
data = pd.DataFrame(pipe_fit.transform(df), columns = pipe_fit.get_feature_names_out().tolist())
print(data.columns.tolist())
输出:
['cat_onehot__default_yes',
'cat_onehot__housing_yes',
'cat_onehot__loan_yes',
'cat_onehot__job_blue-collar',
'cat_onehot__job_entrepreneur',
'cat_onehot__job_housemaid',
'cat_onehot__job_management',
'cat_onehot__job_retired',
'cat_onehot__job_self-employed',
'cat_onehot__job_services',
'cat_onehot__job_student',
'cat_onehot__job_technician',
'cat_onehot__job_unemployed',
'cat_onehot__job_unknown',
'cat_onehot__marital_married',
'cat_onehot__marital_single',
'cat_ordinal__education',
'num__age',
'num__balance']
3.2 异常值
Kmeans 对异常值非常敏感,因此我们的数据中异常值越少越好。我们可以应用使用 Z 分数选择异常值的典型方法,但在这篇文章中,我将向您展示一种更高级、更酷的方法。
那么,这种方法是什么呢?我们将使用 Python 异常值检测 (PyOD) 库。这个库专注于为不同情况检测异常值。更具体地说,我们将使用 ECOD 方法(“基于经验累积分布函数进行异常值检测”)。
该方法旨在获取数据的分布,从而了解概率密度较低的值(异常值)。如果您想了解更多,请查看 Github。
from pyod.models.ecod import ECOD
clf = ECOD()
clf.fit(data)
outliers = clf.predict(data)
data["outliers"] = outliers
data_no_outliers = data[data["outliers"] == 0]
data_no_outliers = data_no_outliers.drop(["outliers"], axis = 1)
data_with_outliers = data.copy()
data_with_outliers = data_with_outliers.drop(["outliers"], axis = 1)
print(data_no_outliers.shape)
print(data_with_outliers.shape)
输出:
(40690, 19)
(45211, 19)
3.3 建模
使用 Kmeans 算法的缺点之一是您必须选择要使用的聚类数量。在这种情况下,为了获取该数据,我们将使用 肘部法则。它包括计算聚类点与其质心之间的失真。目标很明确,即获得尽可能小的失真。在这种情况下,我们使用以下代码:
from yellowbrick.cluster import KElbowVisualizer
km = KMeans(init="k-means++", random_state=0, n_init="auto")
visualizer = KElbowVisualizer(km, k=(2,10))
visualizer.fit(data_no_outliers)
visualizer.show()
输出:
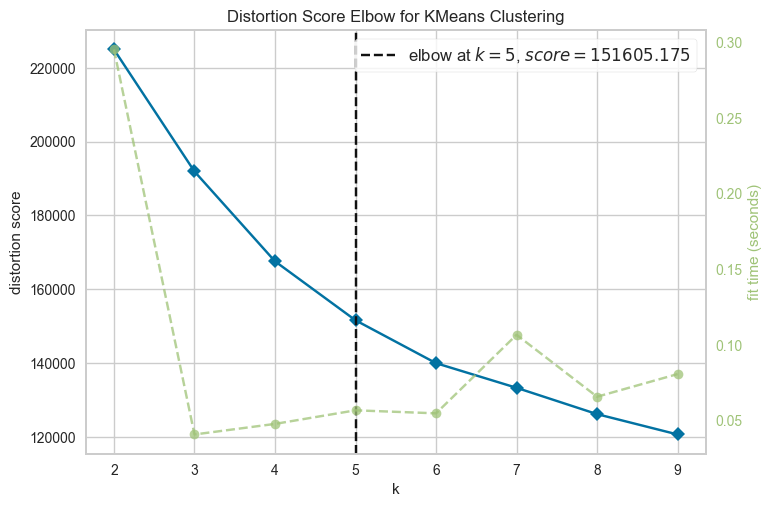
不同聚类数量的肘部得分(图片来源:作者)。
我们看到从 k=5 开始,失真没有发生剧烈变化。确实,理想情况是从 k=5 开始的行为几乎是平坦的。这种情况很少发生,可以应用其他方法来确定最优化聚类数量。为了确保,我们可以执行 轮廓(Silhoutte) 可视化。代码如下:
from sklearn.metrics import davies_bouldin_score, silhouette_score, silhouette_samples
import matplotlib.cm as cm
def make_Silhouette_plot(X, n_clusters):
plt.xlim([-0.1, 1])
plt.ylim([0, len(X) + (n_clusters + 1) * 10])
clusterer = KMeans(n_clusters=n_clusters, max_iter = 1000, n_init = 10, init = 'k-means++', random_state=10)
cluster_labels = clusterer.fit_predict(X)
silhouette_avg = silhouette_score(X, cluster_labels)
print(
"For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg,
)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_clusters)
plt.fill_betweenx(
np.arange(y_lower, y_upper),
0,
ith_cluster_silhouette_values,
facecolor=color,
edgecolor=color,
alpha=0.7,
)
plt.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
plt.title(f"The Silhouette Plot for n_cluster = {n_clusters}", fontsize=26)
plt.xlabel("The silhouette coefficient values", fontsize=24)
plt.ylabel("Cluster label", fontsize=24)
plt.axvline(x=silhouette_avg, color="red", linestyle="--")
plt.yticks([])
plt.xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
range_n_clusters = list(range(2,10))
for n_clusters in range_n_clusters:
print(f"N cluster: {n_clusters}")
make_Silhouette_plot(data_no_outliers, n_clusters)
plt.savefig('Silhouette_plot_{}.png'.format(n_clusters))
plt.close()
输出:
N cluster: 2
For n_clusters = 2 The average silhouette_score is : 0.18111287366156115
N cluster: 3
For n_clusters = 3 The average silhouette_score is : 0.16787543108034586
N cluster: 4
For n_clusters = 4 The average silhouette_score is : 0.1583411958880734
N cluster: 5
For n_clusters = 5 The average silhouette_score is : 0.1672987260052535
N cluster: 6
For n_clusters = 6 The average silhouette_score is : 0.15485098506258177
N cluster: 7
For n_clusters = 7 The average silhouette_score is : 0.1495307642182009
N cluster: 8
For n_clusters = 8 The average silhouette_score is : 0.15098396457075294
N cluster: 9
For n_clusters = 9 The average silhouette_score is : 0.14842917303536465
可以看出,最高的轮廓得分是在 n_cluster=9 时获得的,但如果与其它得分相比,得分的变化也相当小。目前,之前的结果没有提供太多信息。另一方面,之前的代码创建了轮廓可视化,这为我们提供了更多信息:
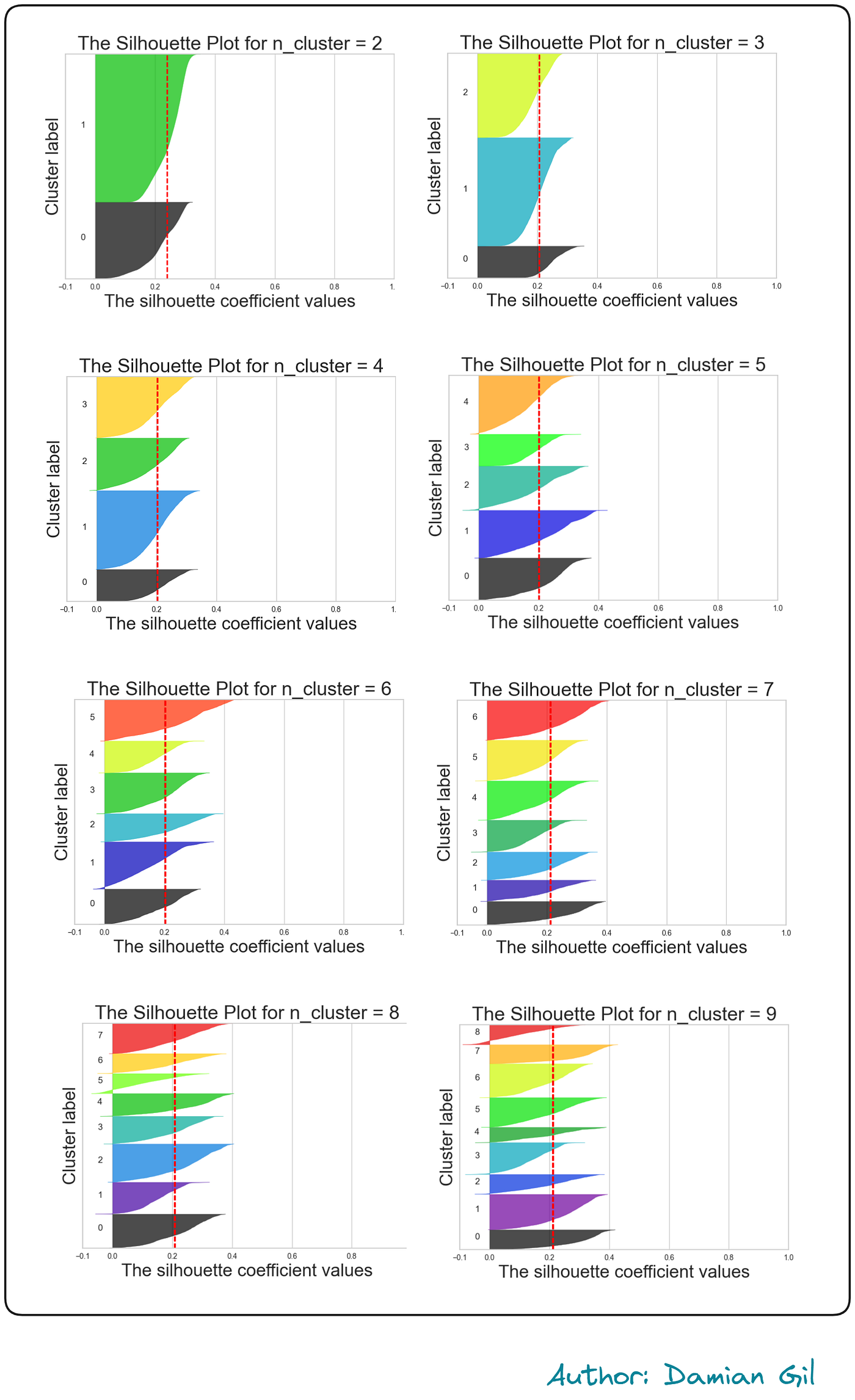
不同聚类数量的轮廓方法图形表示(图片来源:作者)。
由于理解这些表示并不是本文的目标,我将得出结论,似乎没有一个非常明确的决定哪个数字是最好的。在查看了之前的表示后,我们可以选择 K=5 或 K=6。这是因为对于不同的聚类,它们的轮廓得分都高于平均值,并且聚类大小没有不平衡。此外,在某些情况下,营销部门可能对拥有最少数量的聚类/客户类型感兴趣(这可能或可能不是这种情况)。
最后,我们可以创建 K=5 的 Kmeans 模型。
km = KMeans(n_clusters=5,
init='k-means++',
n_init=10,
max_iter=100,
random_state=42)
clusters_predict = km.fit_predict(data_no_outliers)
输出:
clusters_predict -> array([4, 2, 0, ..., 3, 4, 3])
np.unique(clusters_predict) -> array([0, 1, 2, 3, 4])
3.4 评估
Kmeans 模型的评估方式比其他模型更开放。我们可以使用:
- 指标
- 可视化
- 解释(对公司来说非常重要)。
关于模型评估指标,我们可以使用以下代码:
from sklearn.metrics import silhouette_score
from sklearn.metrics import calinski_harabasz_score
from sklearn.metrics import davies_bouldin_score
"""
Davies Bouldin 指数定义为每个聚类与其最相似聚类的平均相似度度量,
其中相似度是聚类内距离与聚类间距离之比。
DB 指数的最小值为 0,而较小的值(接近 0)表示更好的模型,
可以生成更好的聚类。
"""
print(f"Davies bouldin score: {davies_bouldin_score(data_no_outliers,clusters_predict)}")
"""
Calinski Harabaz 指数 -> 方差比准则。
Calinski Harabaz 指数定义为聚类间离散度之和与聚类内离散度之和的比率。
指数越高,聚类越可分离。
"""
print(f"Calinski Score: {calinski_harabasz_score(data_no_outliers,clusters_predict)}")
"""
轮廓得分是用于计算聚类算法拟合优度的指标,
但也可以用作确定最佳 k 值的方法(详情见此)。
其值范围从 -1 到 1。
值为 0 表示聚类重叠,并且数据或 k 值不正确。
1 是理想值,表示聚类非常密集且分离良好。
"""
print(f"Silhouette Score: {silhouette_score(data_no_outliers,clusters_predict)}")
输出:
Davies bouldin score: 1.676769775662788
Calinski Score: 6914.705500337112
Silhouette Score: 0.16729335453305272
如所示,我们的模型表现并非特别好。戴维斯得分告诉我们聚类之间的距离相当小。
这可能由多种因素造成,但请记住,模型的能量是数据;如果数据没有足够的预测能力,您就不能期望获得出色的结果。
对于可视化,我们可以使用降维方法,即 PCA。为此,我们将使用 Prince 库,该库专注于探索性分析和降维。如果您愿意,可以使用 Sklearn 的 PCA,它们是相同的。
首先,我们将计算 3D 中的主成分,然后进行表示。这是前述步骤执行的两个函数:
import prince
import plotly.express as px
def get_pca_2d(df, predict):
pca_2d_object = prince.PCA(
n_components=2,
n_iter=3,
rescale_with_mean=True,
rescale_with_std=True,
copy=True,
check_input=True,
engine='sklearn',
random_state=42
)
pca_2d_object.fit(df)
df_pca_2d = pca_2d_object.transform(df)
df_pca_2d.columns = ["comp1", "comp2"]
df_pca_2d["cluster"] = predict
return pca_2d_object, df_pca_2d
def get_pca_3d(df, predict):
pca_3d_object = prince.PCA(
n_components=3,
n_iter=3,
rescale_with_mean=True,
rescale_with_std=True,
copy=True,
check_input=True,
engine='sklearn',
random_state=42
)
pca_3d_object.fit(df)
df_pca_3d = pca_3d_object.transform(df)
df_pca_3d.columns = ["comp1", "comp2", "comp3"]
df_pca_3d["cluster"] = predict
return pca_3d_object, df_pca_3d
def plot_pca_3d(df, title = "PCA Space", opacity=0.8, width_line = 0.1):
df = df.astype({"cluster": "object"})
df = df.sort_values("cluster")
fig = px.scatter_3d(
df,
x='comp1',
y='comp2',
z='comp3',
color='cluster',
template="plotly",
color_discrete_sequence=px.colors.qualitative.Vivid,
title=title).update_traces(
marker={
"size": 4,
"opacity": opacity,
"line": {
"width": width_line,
"color": "black",
}
}
).update_layout(
width = 800,
height = 800,
autosize = True,
showlegend = True,
legend=dict(title_font_family="Times New Roman",
font=dict(size= 20)),
scene = dict(xaxis=dict(title = 'comp1', titlefont_color = 'black'),
yaxis=dict(title = 'comp2', titlefont_color = 'black'),
zaxis=dict(title = 'comp3', titlefont_color = 'black')),
font = dict(family = "Gilroy", color = 'black', size = 15))
fig.show()
不用太担心这些函数,按如下方式使用它们:
pca_3d_object, df_pca_3d = get_pca_3d(data_no_outliers, clusters_predict)
plot_pca_3d(df_pca_3d, title = "PCA Space", opacity=1, width_line = 0.1)
print("The variability is :", pca_3d_object.eigenvalues_summary)
输出:
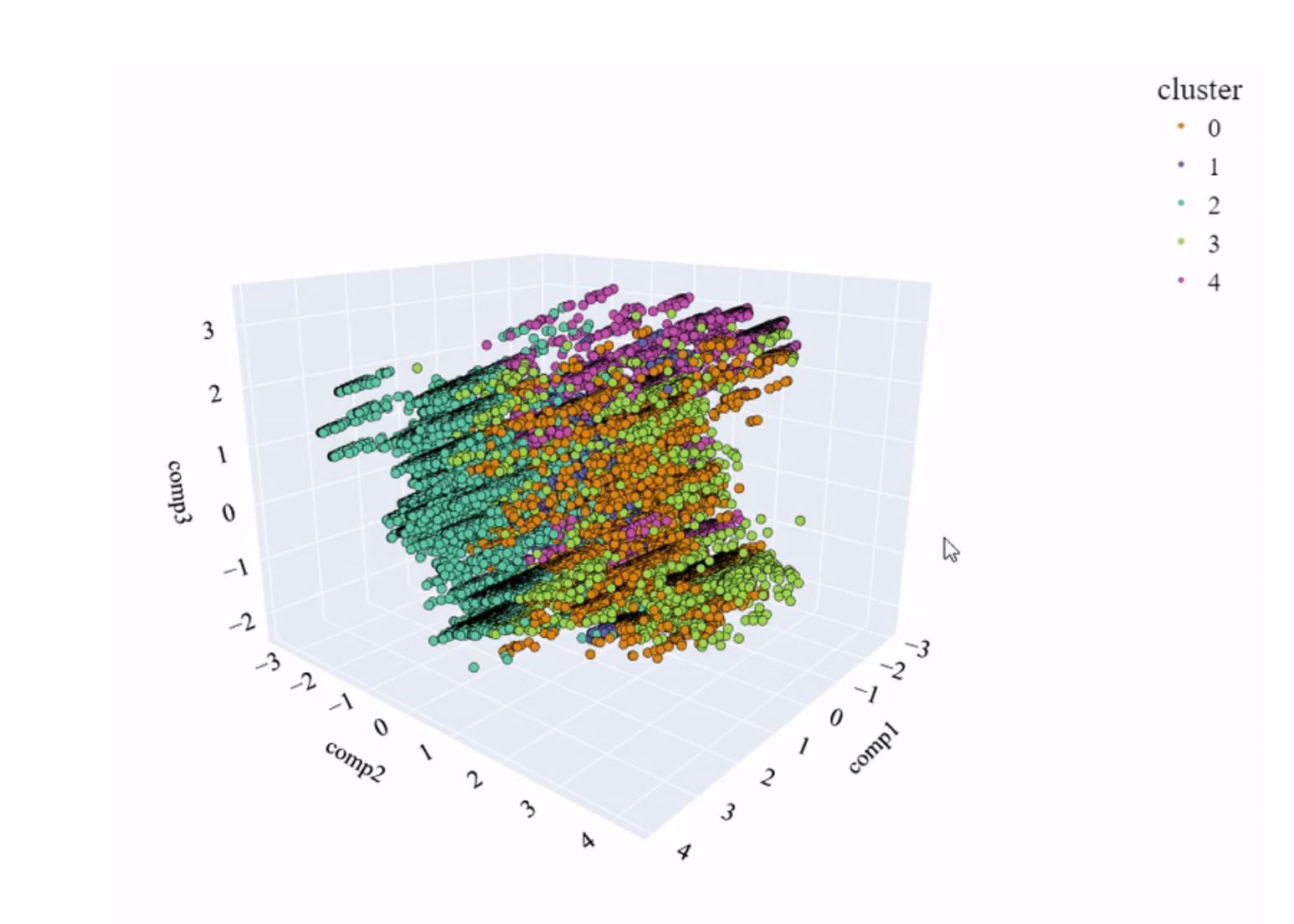
PCA 空间和模型创建的聚类。
可以看出,聚类之间几乎没有分离,也没有明确的划分。这与指标提供的信息一致。
有一点需要记住,但很少有人会注意到,那就是 PCA 和特征向量的变异性。
可以说,每个字段都包含一定量的信息,并且这增加了其信息量。如果 3 个主要成分的累积和达到约 80% 的变异性,我们可以说这是可以接受的,在表示中获得良好的结果。如果值较低,我们必须对可视化持保留态度,因为我们缺少其他特征向量中包含的大量信息。
下一个问题显而易见:执行的 PCA 的变异性是多少?
答案如下:

可以看出,前 3 个成分的变异性为 27.98%,不足以得出有根据的结论。
当我们应用 PCA 方法时,由于它是一个线性算法,它无法捕捉更复杂的关系。幸运的是,有一种称为 t-SNE 的方法,它能够捕捉**这些复杂的多元关系**。这可以帮助我们进行可视化,因为使用之前的方法我们没有取得很大的成功。
如果您在自己的电脑上尝试,请记住它的计算成本更高。因此,我对原始数据集进行了采样,但仍然花了大约 5 分钟才得到结果。代码如下:
from sklearn.manifold import TSNE
sampling_data = data_no_outliers.sample(frac=0.5, replace=True, random_state=1)
sampling_clusters = pd.DataFrame(clusters_predict).sample(frac=0.5, replace=True, random_state=1)[0].values
df_tsne_3d = TSNE(
n_components=3,
learning_rate=500,
init='random',
perplexity=200,
n_iter = 5000).fit_transform(sampling_data)
df_tsne_3d = pd.DataFrame(df_tsne_3d, columns=["comp1", "comp2",'comp3'])
df_tsne_3d["cluster"] = sampling_clusters
plot_pca_3d(df_tsne_3d, title = "PCA Space", opacity=1, width_line = 0.1)
结果,我得到了以下图像。它显示了聚类之间更清晰的分离,但不幸的是,我们仍然没有得到好的结果。
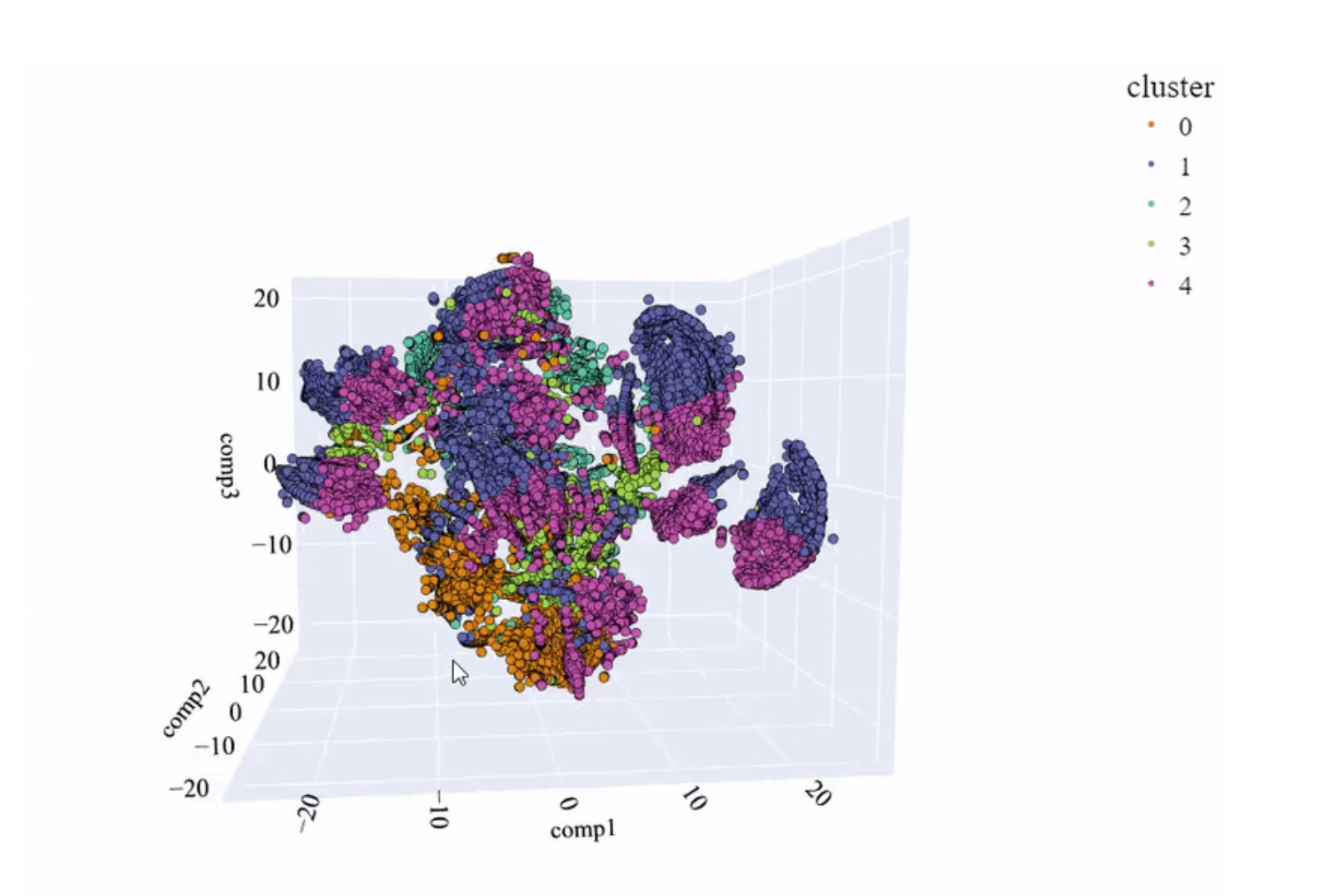
t-SNE 空间和模型创建的聚类(图片来源:作者)。
事实上,我们可以比较 PCA 和 t-SNE 在 2 维下进行的降维。使用第二种方法,改进是显而易见的。
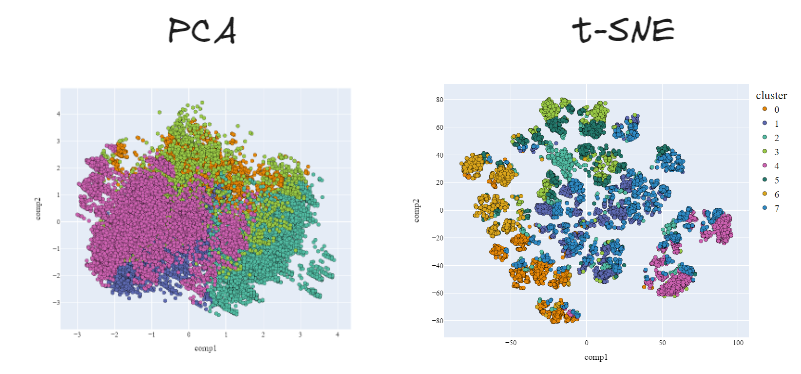
不同降维方法和模型定义的聚类的不同结果(图片来源:作者)。
最后,让我们稍微探讨一下模型的工作原理,哪些特征最重要,以及聚类的主要特征是什么。
为了查看每个变量的重要性,我们将使用在这种情况下典型的“技巧”。我们将创建一个分类模型,其中“X”是 Kmeans 模型的输入,“y”是 Kmeans 模型预测的聚类。
选择的模型是 LGBMClassifier。该模型功能强大,并且在处理类别和数值变量时表现良好。在训练好新模型后,使用 SHAP 库,我们可以获得每个特征在预测中的重要性。代码如下:
import lightgbm as lgb
import shap
clf_km = lgb.LGBMClassifier(colsample_by_tree=0.8)
clf_km.fit(X=data_no_outliers, y=clusters_predict)
explainer_km = shap.TreeExplainer(clf_km)
shap_values_km = explainer_km.shap_values(data_no_outliers)
shap.summary_plot(shap_values_km, data_no_outliers, plot_type="bar", plot_size=(15, 10))
输出:
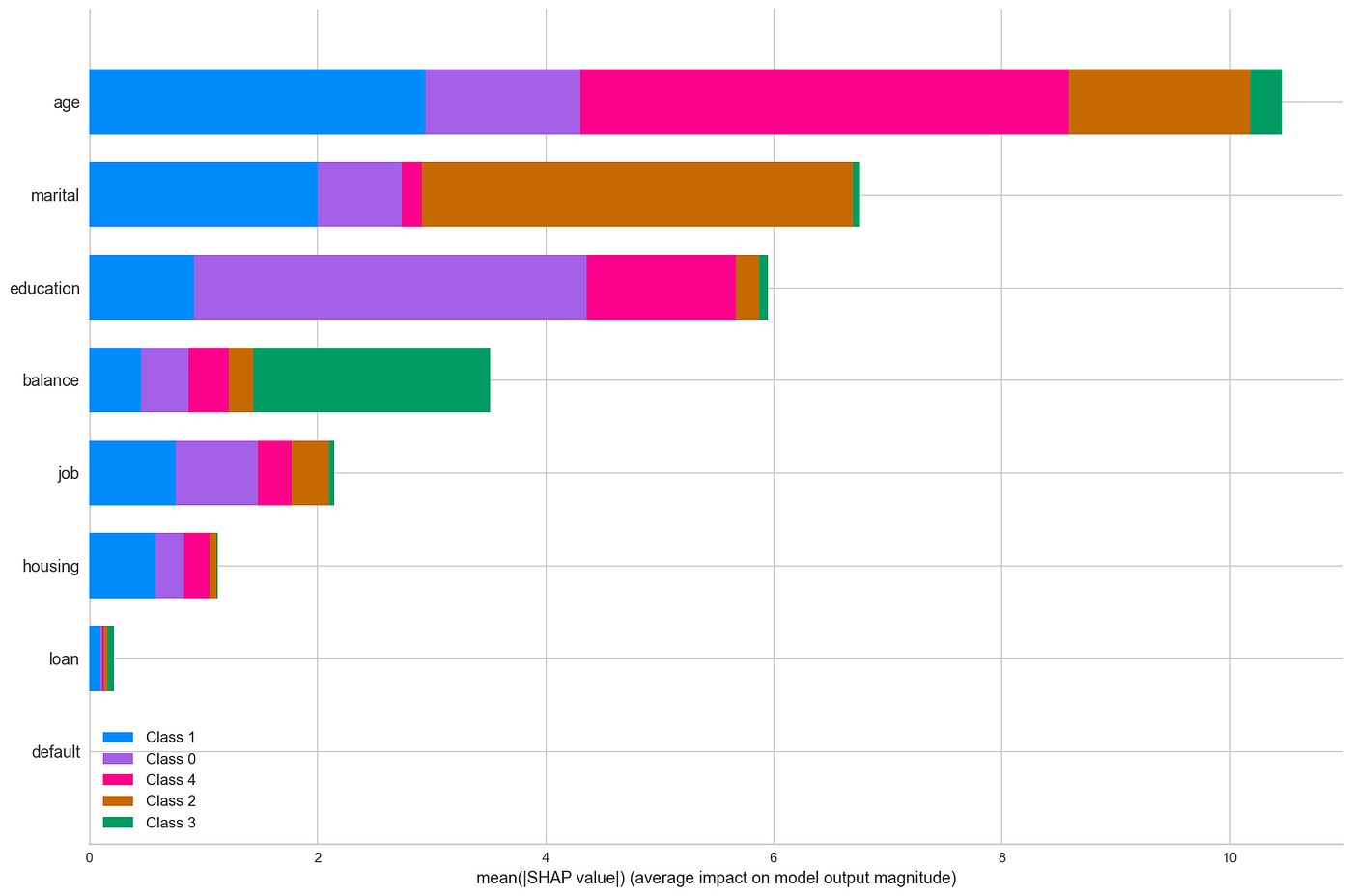
模型中变量的重要性(图片来源:作者)。
可以看出,特征 age 具有最大的预测能力。还可以看出,聚类 3(绿色)主要通过 balance 变量进行区分。
最后,我们必须分析聚类的特征。这项研究的这一部分对业务至关重要。为此,我们将获取数据集中每个特征的均值(对于数值变量)和最频繁值(类别变量),针对每个聚类:
df_no_outliers = df[df.outliers == 0]
df_no_outliers["cluster"] = clusters_predict
df_no_outliers.groupby('cluster').agg(
{
'job': lambda x: x.value_counts().index[0],
'marital': lambda x: x.value_counts().index[0],
'education': lambda x: x.value_counts().index[0],
'housing': lambda x: x.value_counts().index[0],
'loan': lambda x: x.value_counts().index[0],
'contact': lambda x: x.value_counts().index[0],
'age':'mean',
'balance': 'mean',
'default': lambda x: x.value_counts().index[0],
}
).reset_index()
输出:
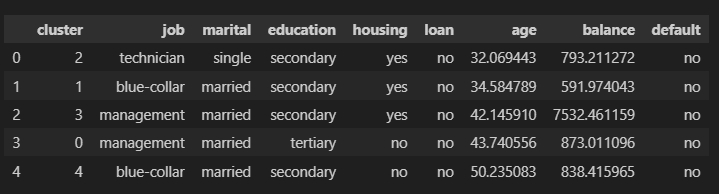
我们看到,job=blue-collar 的聚类在特征之间没有很大的差异,除了年龄特征。这是不理想的,因为很难区分每个聚类的客户。在 job=management 的情况下,我们获得了更好的区分。
经过不同方式的分析,它们都得出了相同的结论:“我们需要改进结果”。
4 方法 2: K-Prototype
如果我们回顾原始数据集,我们会发现它包含类别变量和数值变量。不幸的是,Skelearn 提供的 Kmeans 算法不接受类别变量,这迫使我们修改原始数据集并对其进行大幅度更改。
幸运的是,您已经阅读了我和我的帖子。最重要的是,感谢 ZHEXUE HUANG 和他的文章 Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values,有一个算法接受类别变量进行聚类。该算法称为 K-Prototype。提供它的库是 Prince。
.ipynb) 找到 Jupyter 笔记本。
4.1 预处理
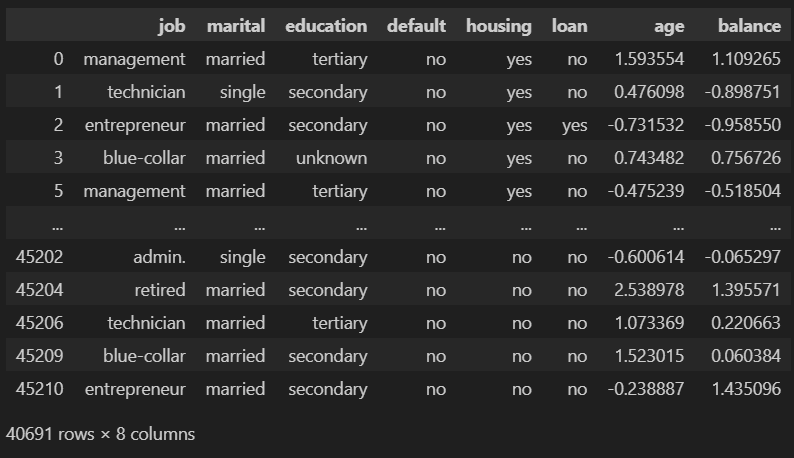
由于我们有数值变量,我们必须对它们进行某些修改。始终建议所有数值变量都处于相似的尺度,并且分布尽可能接近高斯分布。我们将用于创建模型的数据集是这样创建的:
pipe = Pipeline([('scaler', PowerTransformer())])
df_aux = pd.DataFrame(pipe.fit_transform(df_no_outliers[["age", "balance"]]), columns = ["age", "balance"])
df_no_outliers_norm = df_no_outliers.copy()
df_no_outliers_norm = df_no_outliers_norm.drop(["age", "balance"], axis = 1)
df_no_outliers_norm["age"] = df_aux["age"].values
df_no_outliers_norm["balance"] = df_aux["balance"].values
df_no_outliers_norm
4.2 异常值
由于我提出的异常值检测方法(ECOD)只接受数值变量,因此必须执行与 Kmeans 方法相同的转换。我们应用异常值检测模型,该模型将告诉我们哪些行需要删除,最终得到我们将用作 K-Prototype 模型输入的数据集:
4.3 建模
我们创建模型,为此我们首先需要获取最佳 k 值。为此,我们使用肘部法则和以下代码片段:
from kmodes.kprototypes import KPrototypes
from plotnine import *
import plotnine
cost = []
range_ = range(2, 15)
for cluster in range_:
kprototype = KPrototypes(n_jobs = -1, n_clusters = cluster, init = 'Huang', random_state = 0)
kprototype.fit_predict(df_no_outliers, categorical = categorical_columns_index)
cost.append(kprototype.cost_)
print('Cluster initiation: {}'.format(cluster))
df_cost = pd.DataFrame({'Cluster':range_, 'Cost':cost})
plotnine.options.figure_size = (8, 4.8)
(
ggplot(data = df_cost)+
geom_line(aes(x = 'Cluster',
y = 'Cost'))+
geom_point(aes(x = 'Cluster',
y = 'Cost'))+
geom_label(aes(x = 'Cluster',
y = 'Cost',
label = 'Cluster'),
size = 10,
nudge_y = 1000) +
labs(title = 'Optimal number of cluster with Elbow Method')+
xlab('Number of Clusters k')+
ylab('Cost')+
theme_minimal()
)
输出:
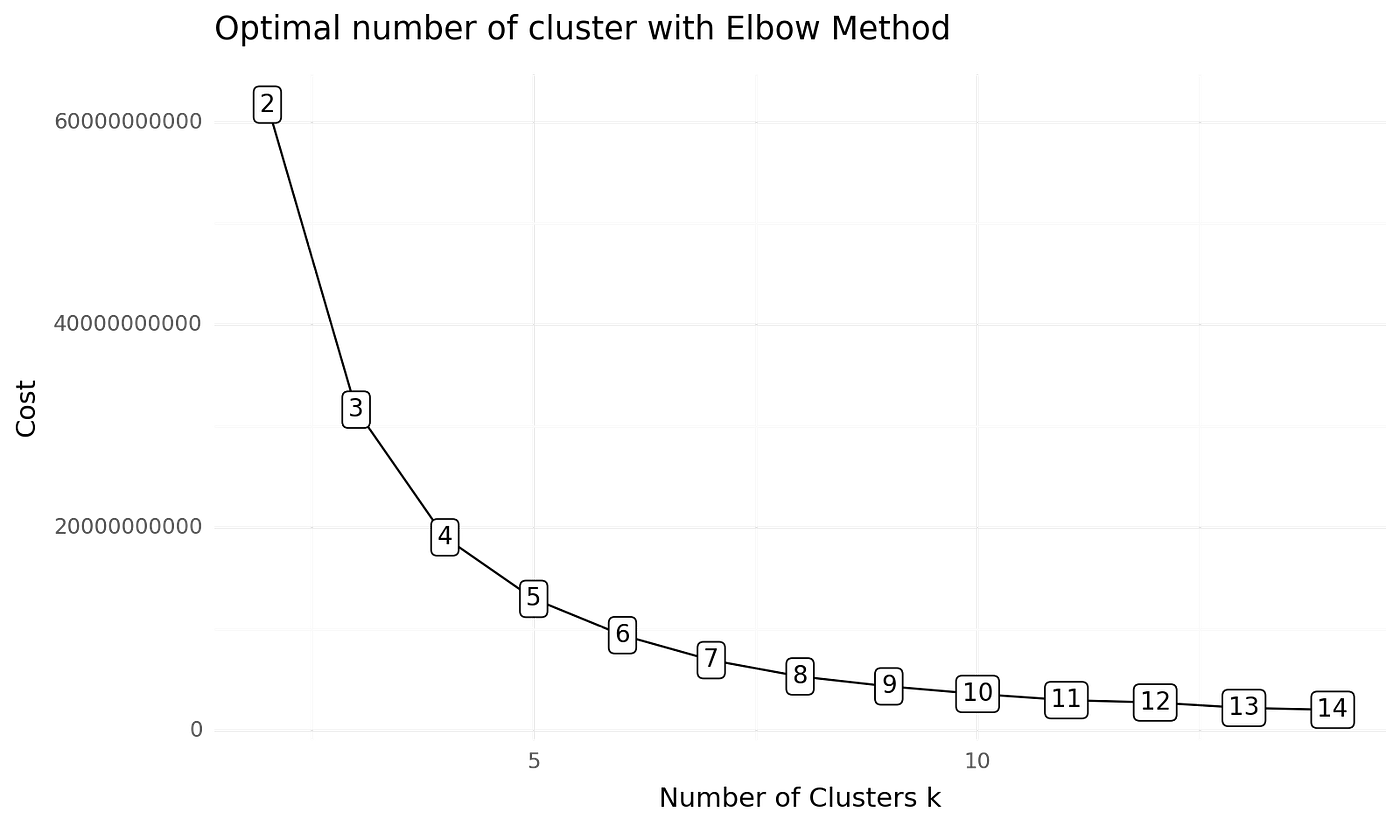
不同聚类数量的肘部得分(图片来源:作者)。
我们可以看到最好的选择是 K=5。
请注意,由于此算法比通常使用的算法花费的时间更长。对于上图,需要 86 分钟,这一点需要牢记。

好了,我们现在已经清楚了聚类的数量,我们只需要创建模型:
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
categorical_columns = df_no_outliers_norm.select_dtypes(exclude=numerics).columns
print(categorical_columns)
categorical_columns_index = [df_no_outliers_norm.columns.get_loc(col) for col in categorical_columns]
cluster_num = 5
kprototype = KPrototypes(n_jobs = -1, n_clusters = cluster_num, init = 'Huang', random_state = 0)
kprototype.fit(df_no_outliers_norm, categorical = categorical_columns_index)
clusters = kprototype.predict(df_no_outliers , categorical = categorical_columns_index)
输出:
clusters -> array([3, 1, 1, ..., 1, 1, 2], dtype=uint16)
我们已经有了模型及其预测,我们只需要对其进行评估。
4.4 评估
正如我们之前所见,我们可以应用多种可视化来直观地了解模型的优劣。不幸的是,PCA 方法和 t-SNE 不支持类别变量。但别担心,因为 Prince 库包含 MCA (多重对应分析) 方法,它确实接受混合数据集。事实上,我鼓励您访问此库的 Github,它包含多种适用于不同情况的超有用方法,请看下图:
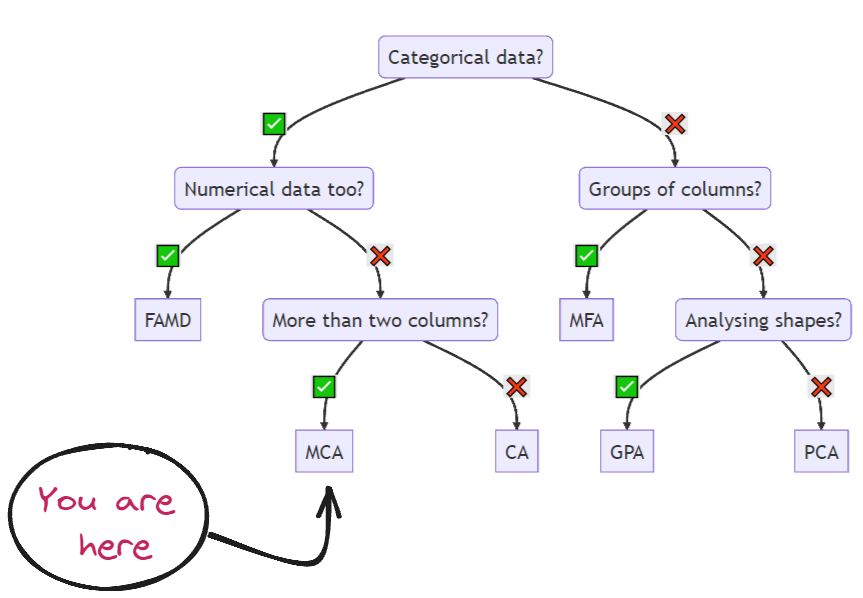
不同类型案例的降维方法(图片来源:作者和 Prince 文档)。
好的,计划是应用 MCA 来降维并进行图形表示。为此,我们使用以下代码:
from prince import MCA
def get_MCA_3d(df, predict):
mca = MCA(n_components =3, n_iter = 100, random_state = 101)
mca_3d_df = mca.fit_transform(df)
mca_3d_df.columns = ["comp1", "comp2", "comp3"]
mca_3d_df["cluster"] = predict
return mca, mca_3d_df
def get_MCA_2d(df, predict):
mca = MCA(n_components =2, n_iter = 100, random_state = 101)
mca_2d_df = mca.fit_transform(df)
mca_2d_df.columns = ["comp1", "comp2"]
mca_2d_df["cluster"] = predict
return mca, mca_2d_df
"-------------------------------------------------------------------"
mca_3d, mca_3d_df = get_MCA_3d(df_no_outliers_norm, clusters)
请记住,如果您想 100% 遵循每个步骤,可以查看 Jupyter 笔记本。
名为 mca_3d_df 的数据集包含以下信息:
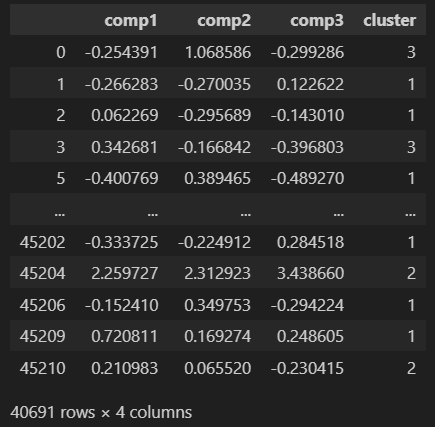
让我们使用 MCA 方法提供的降维结果进行绘图:
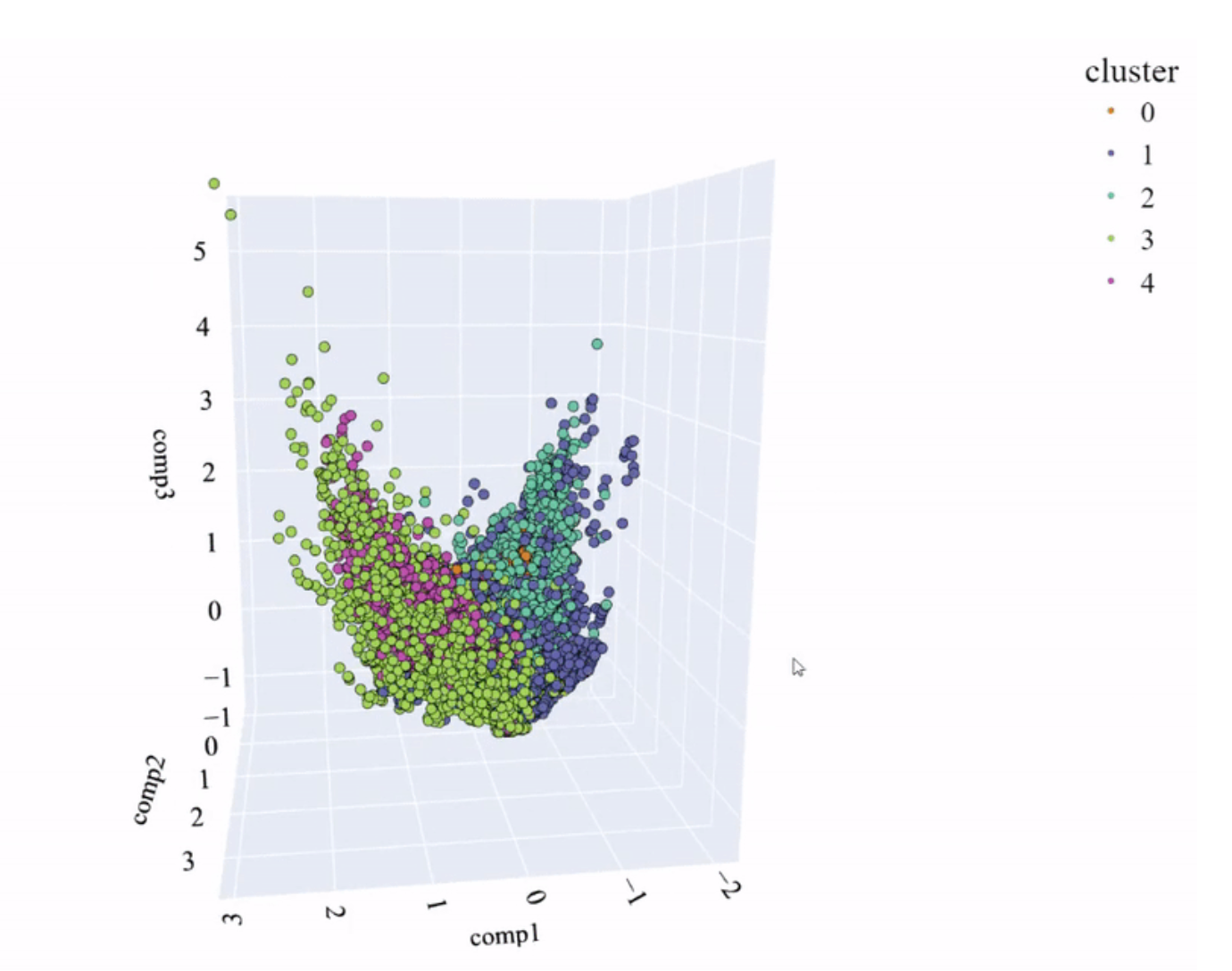
MCA 空间和模型创建的聚类(图片来源:作者)
哇,看起来不太好……聚类之间无法很好地区分。那么我们可以说这个模型不够好,对吗?
我希望您会说类似这样的话:
“嘿,达米安,别这么快!你有没有看过 MCA 提供的 3 个成分的变异性?”
确实,我们必须看看前 3 个成分的变异性是否足以得出结论。MCA 方法可以非常简单地获取这些值:
mca_3d.eigenvalues_summary
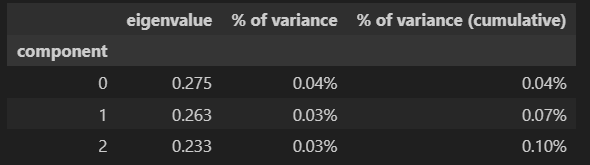
啊哈,这里有些有趣的东西。由于我们的数据,我们基本上得到了零变异性。
换句话说,我们无法从 MCA 提供的降维信息中,对我们的模型得出明确的结论。
通过展示这些结果,我试图举例说明真实数据项目中发生的情况。并非总能获得好的结果,但优秀的数据科学家知道如何识别原因。
我们还有最后一个选项可以直观地判断 K-Prototype 方法创建的模型是否合适。这个方法很简单:
- 将 PCA 应用于已进行预处理以将类别变量转换为数值变量的数据集。
- 获取 PCA 的成分。
- 使用 PCA 成分作为轴,并使用 K-Prototype 模型预测的点颜色进行表示。
请注意,PCA 提供的成分将与方法 1:Kmeans 相同,因为它们是相同的数据框。
让我们看看我们得到了什么……
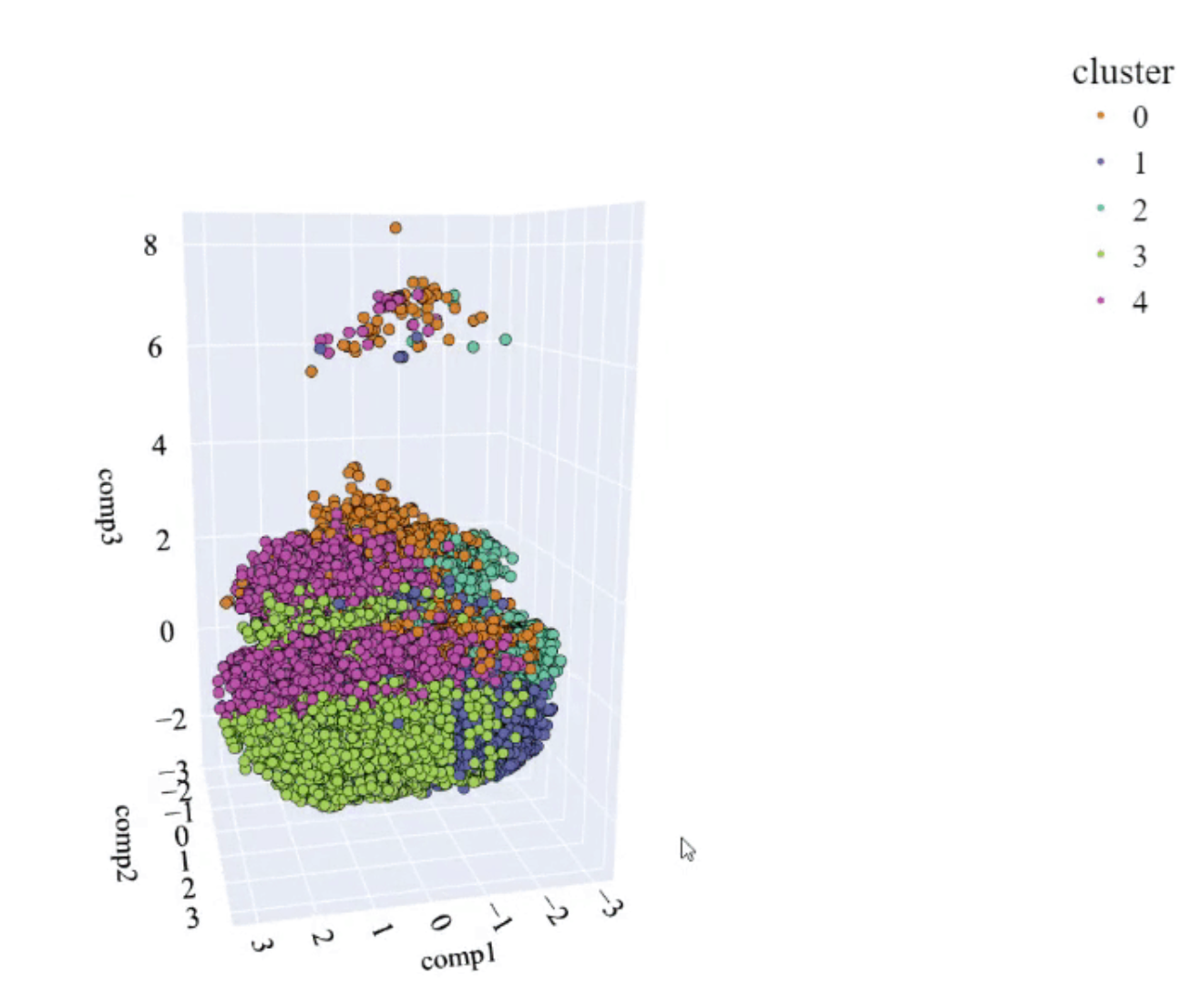
PCA 空间和模型创建的聚类(图片来源:作者)。
看起来还不错,事实上,它与 Kmeans 中获得的结果有某种相似之处。
最后,我们获得了聚类的平均值和每个变量的重要性:
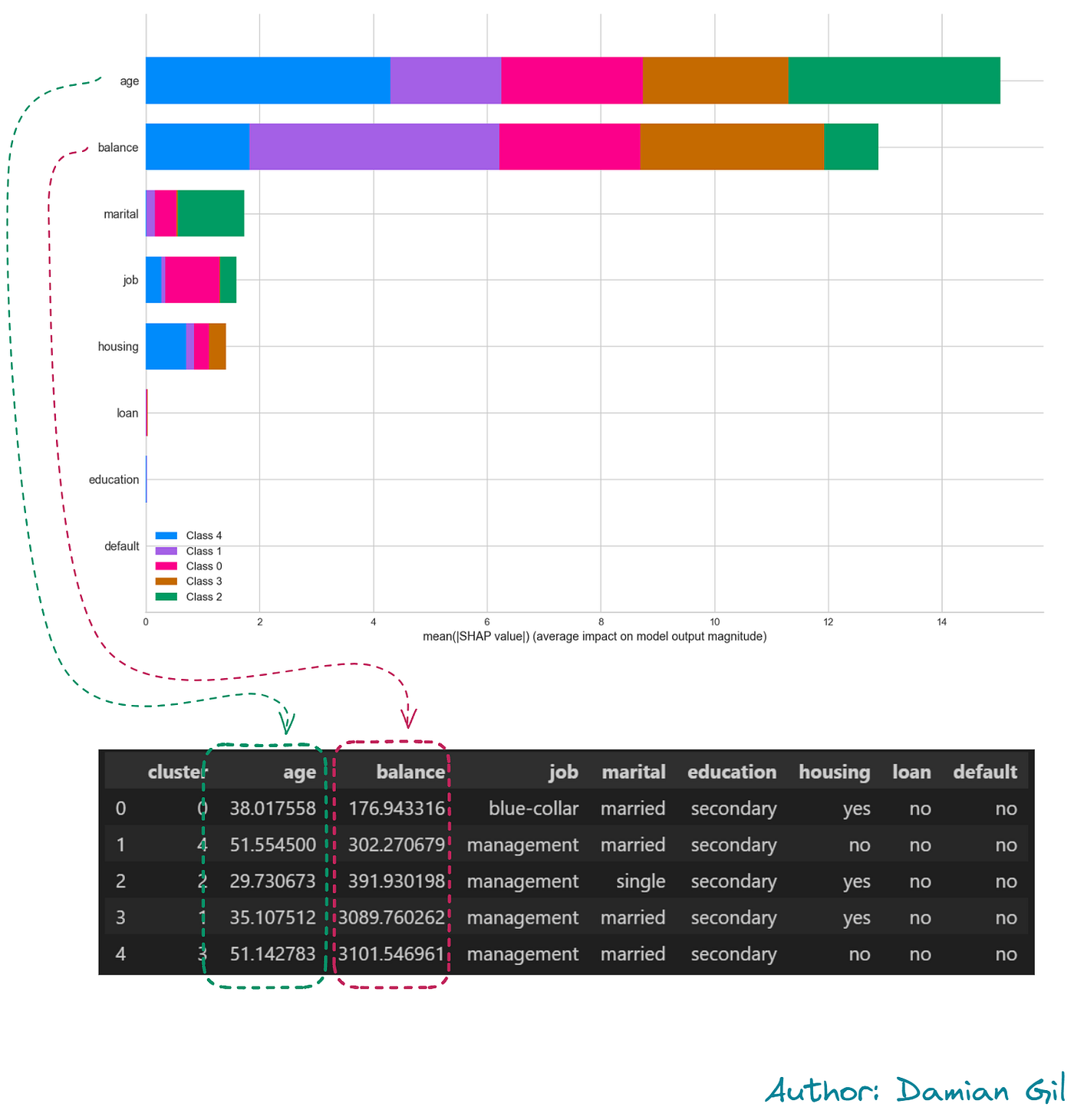
模型中变量的重要性。表格表示每个聚类中最频繁的值(图片来源:作者)。
权重最大的变量是数值变量,明显可以看出这两个特征的限制几乎足以区分每个聚类。
简而言之,可以说获得了与 Kmeans 类似的结果。
5 方法 3: LLM + Kmeans
这种组合可能非常强大,并能改善所获得的结果。我们直奔主题!
LLM 无法直接理解书面文本,我们需要转换这类模型的输入。为此,需要进行句子嵌入。它包括将文本转换为数值向量。下图可以阐明这个概念:
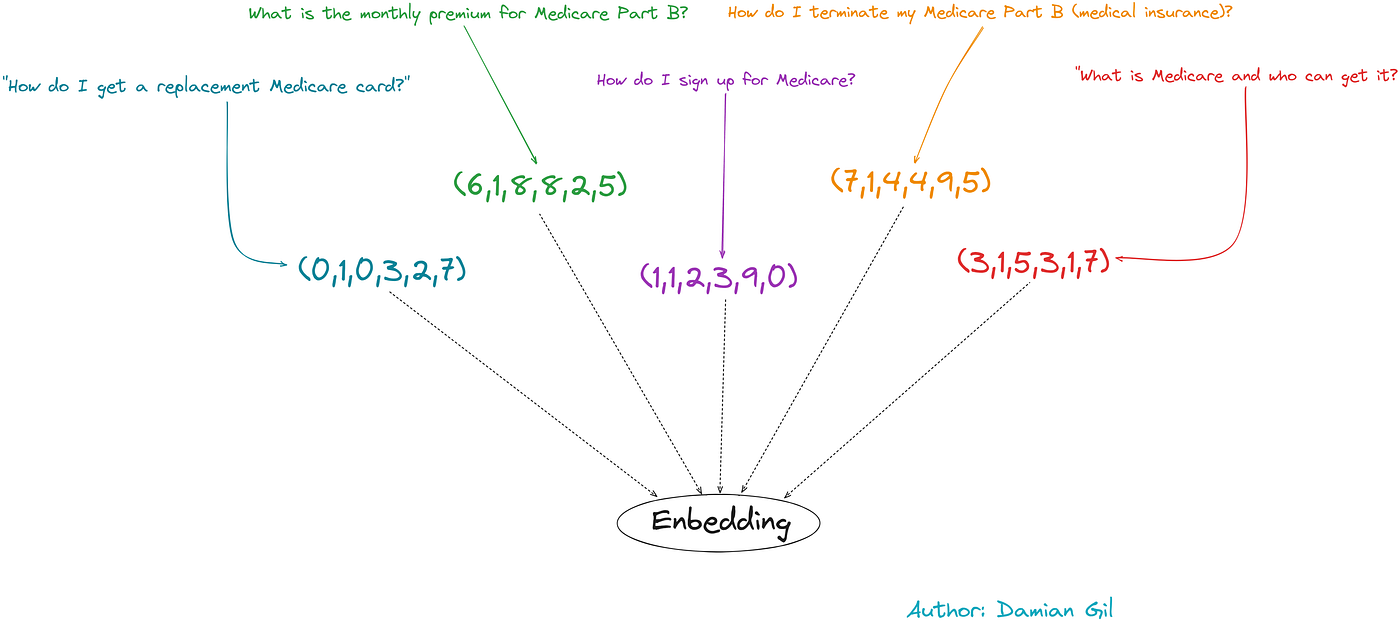
嵌入和相似性概念(图片来源:作者)。
这种编码是智能地进行的,也就是说,包含相似含义的短语将具有更相似的向量。请看下图:
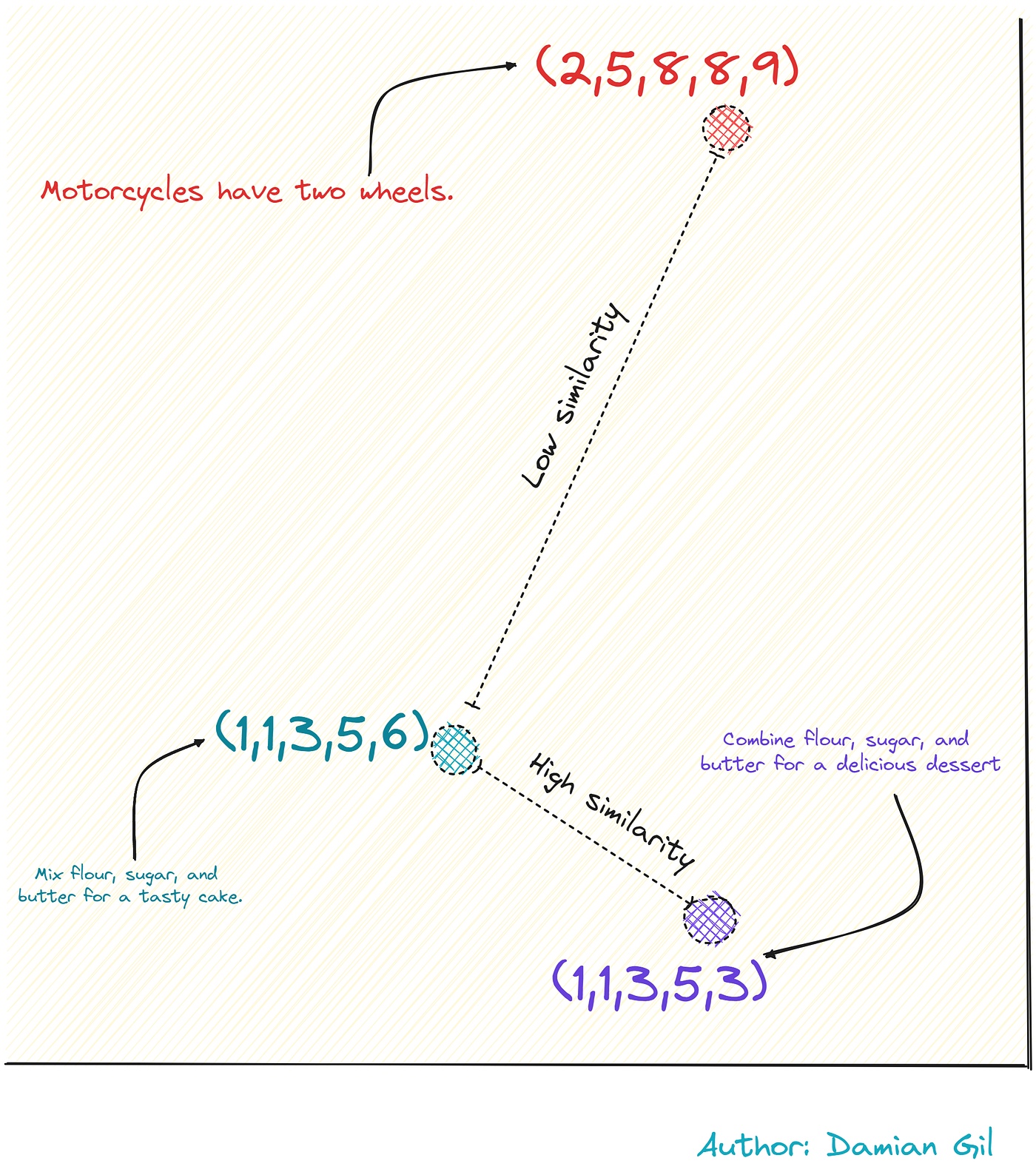
嵌入和相似性概念。
句子嵌入由所谓的转换器执行,这些转换器专门用于这种编码。通常,您可以选择这种编码生成的数值向量的大小。这里是关键点之一:
由于嵌入创建的向量维度很大,因此可以更精确地看到数据中的微小变化。
**因此,如果我们为富含信息的 Kmeans 模型提供输入,它将返回更好的预测。**这是我们追求的理念,其步骤如下:
- 通过句子嵌入转换我们的原始数据集
- 创建 Kmeans 模型
- 评估它
好的,第一步是通过句子嵌入对信息进行编码。目的是获取每个客户的信息并将其统一为包含其所有特征的文本。这部分需要大量的计算时间。这就是为什么我创建了一个脚本来完成这项工作,名为 embedding_creation.py。该脚本收集训练数据集中包含的值,并创建由嵌入提供的新数据集。这是脚本代码:
import pandas as pd
import numpy as np
from sentence_transformers import SentenceTransformer
df = pd.read_csv("data/train.csv", sep = ";")
def compile_text(x):
text = f"""Age: {x['age']},
housing load: {x['housing']},
Job: {x['job']},
Marital: {x['marital']},
Education: {x['education']},
Default: {x['default']},
Balance: {x['balance']},
Personal loan: {x['loan']},
contact: {x['contact']}
"""
return text
sentences = df.apply(lambda x: compile_text(x), axis=1).tolist()
model = SentenceTransformer(r"sentence-transformers/paraphrase-MiniLM-L6-v2")
output = model.encode(sentences=sentences,
show_progress_bar=True,
normalize_embeddings=True)
df_embedding = pd.DataFrame(output)
df_embedding
由于这一步非常重要,需要理解。我们逐点来看:
- 步骤 1:为每一行创建文本,其中包含完整的客户/行信息。我们还将其存储在 Python 列表中,以备后用。请看下图示例。
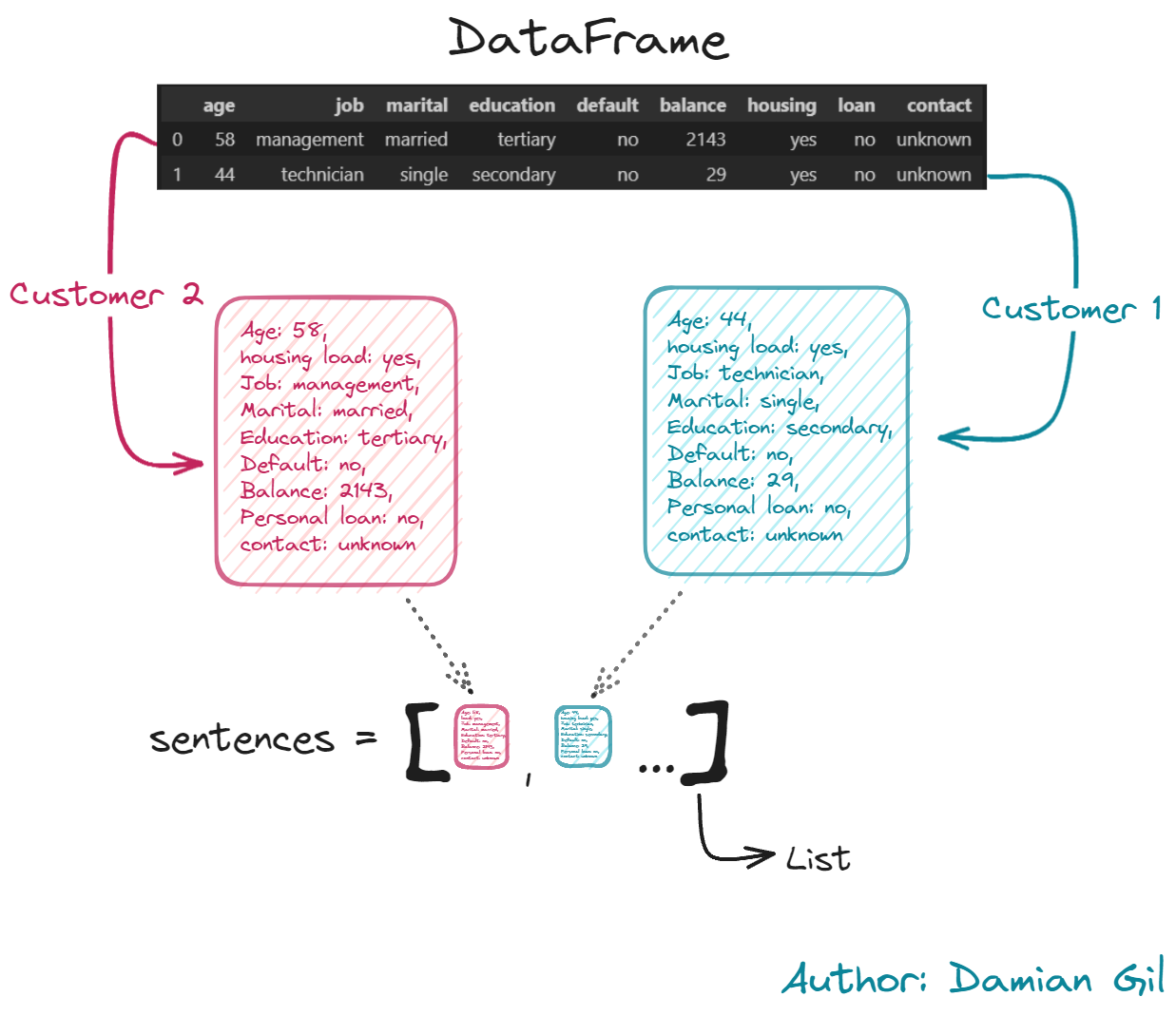
第一步的图形描述。
- 步骤 2:这是调用转换器的时候。为此,我们将使用存储在 HuggingFace 中的模型。该模型经过专门训练,可以在句子级别执行嵌入,与专注于标记和单词级别编码的 Bert 模型不同。要调用模型,您只需提供仓库地址,在本例中为 “sentence-transformers/paraphrase-MiniLM-L6-v2”。返回给我们的每个文本的数值向量将被归一化,因为 Kmeans 模型对输入的尺度敏感。创建的向量长度为 384。我们用它们创建一个具有相同列数的数据框。请看下图:
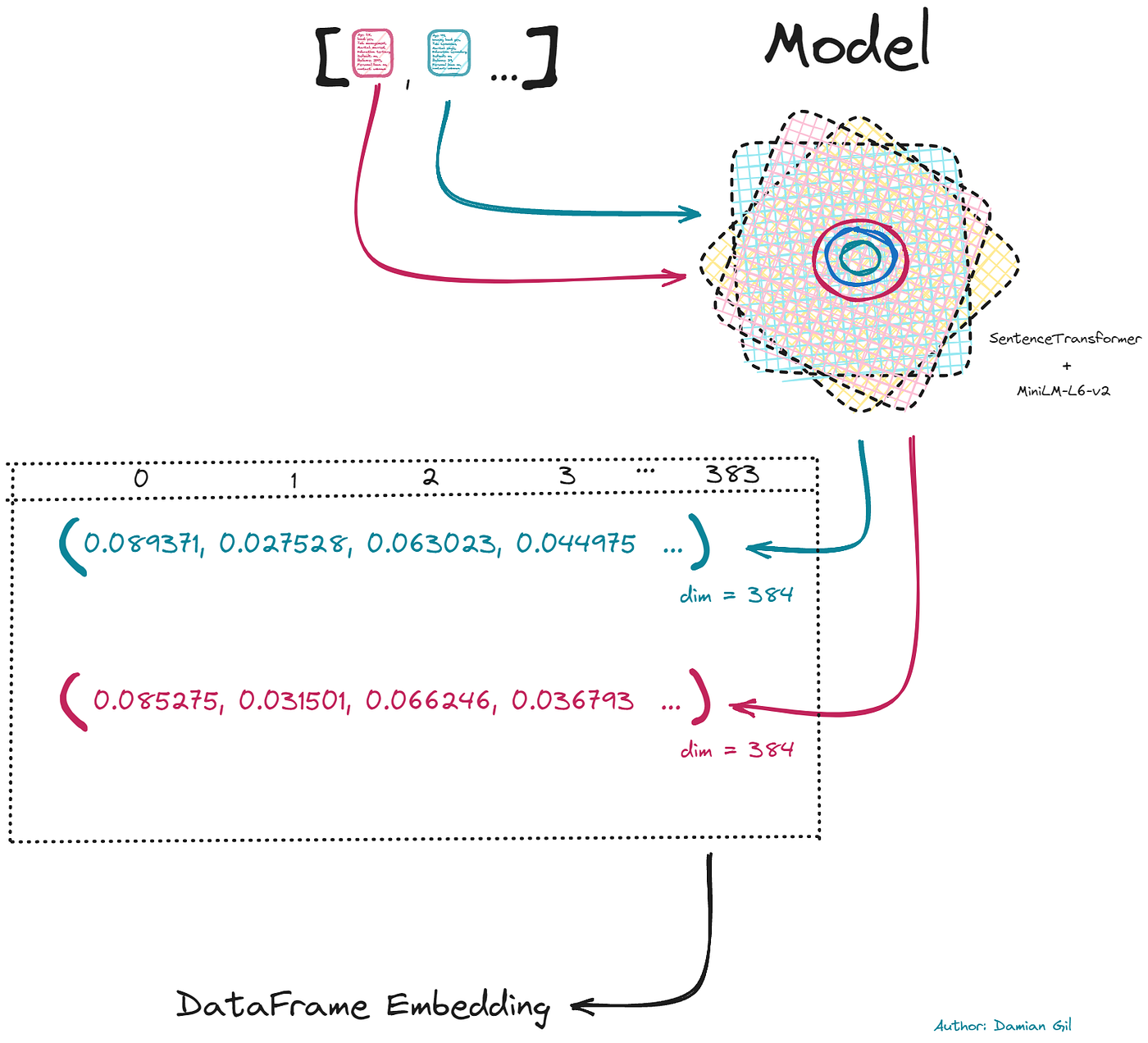
第二步的图形描述(图片来源:作者)。
最后,我们从嵌入中获取数据框,这将是我们 Kmeans 模型的输入。
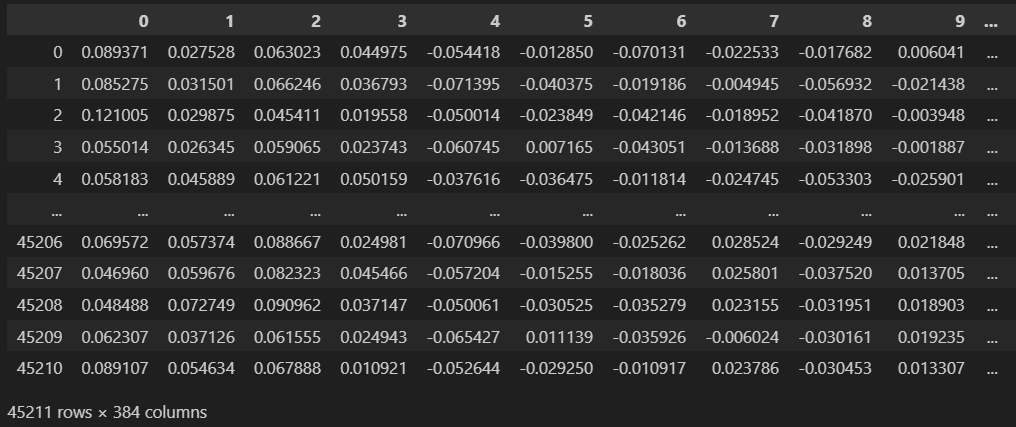
这一步是最有趣和最重要的步骤之一,因为我们为将要创建的 Kmeans 模型创建了输入。
创建和评估过程与上面所示的类似。为了不使帖子过长,仅显示每个点的结果。别担心,所有代码都包含在 名为 embedding 的 Jupyter 笔记本 中,因此您可以自行重现结果。
此外,应用句子嵌入后生成的数据集已保存为 csv 文件。此 csv 文件名为 embedding_train.csv。在 Jupyter 笔记本中,您将看到我们访问该数据集并基于它创建模型。
df = pd.read_csv("data/train.csv", sep = ";")
df = df.iloc[:, 0:8]
df_embedding = pd.read_csv("data/embedding_train.csv", sep = ",")
5.1 预处理
我们可以将嵌入视为预处理。
5.2 异常值
我们应用已介绍的检测异常值的方法 ECOD。我们创建一个不包含这些类型点的数据集。
df_embedding_no_out.shape -> (40690, 384)
df_embedding_with_out.shape -> (45211, 384)
5.3 建模
首先我们必须找出最佳聚类数量。为此,我们使用肘部法则。
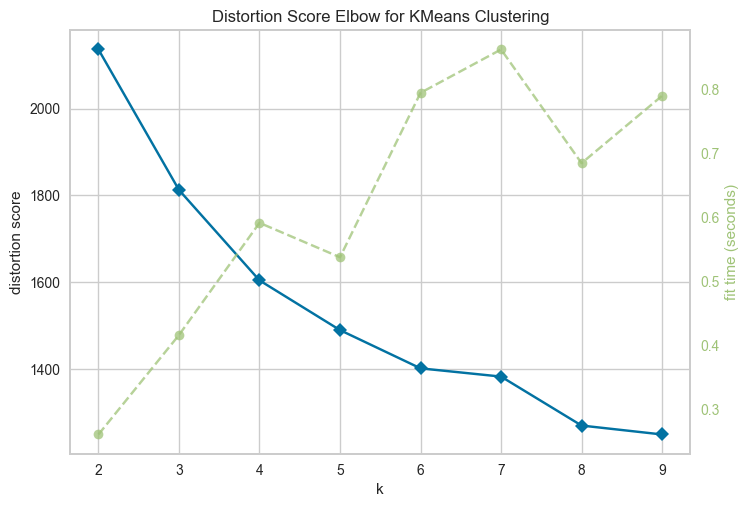
不同聚类数量的肘部得分(图片来源:作者)。
查看图表后,我们选择 k=5 作为我们的聚类数量。
n_clusters = 5
clusters = KMeans(n_clusters=n_clusters, init = "k-means++").fit(df_embedding_no_out)
print(clusters.inertia_)
clusters_predict = clusters.predict(df_embedding_no_out)
5.4 评估
接下来是创建我们的 Kmeans 模型,k=5。然后我们可以获得一些指标,例如:
Davies bouldin score: 1.8095386826791042
Calinski Score: 6419.447089002081
Silhouette Score: 0.20360442824114108
可以看出,这些值与之前获得的值非常相似。让我们研究使用 PCA 分析获得的可视化:
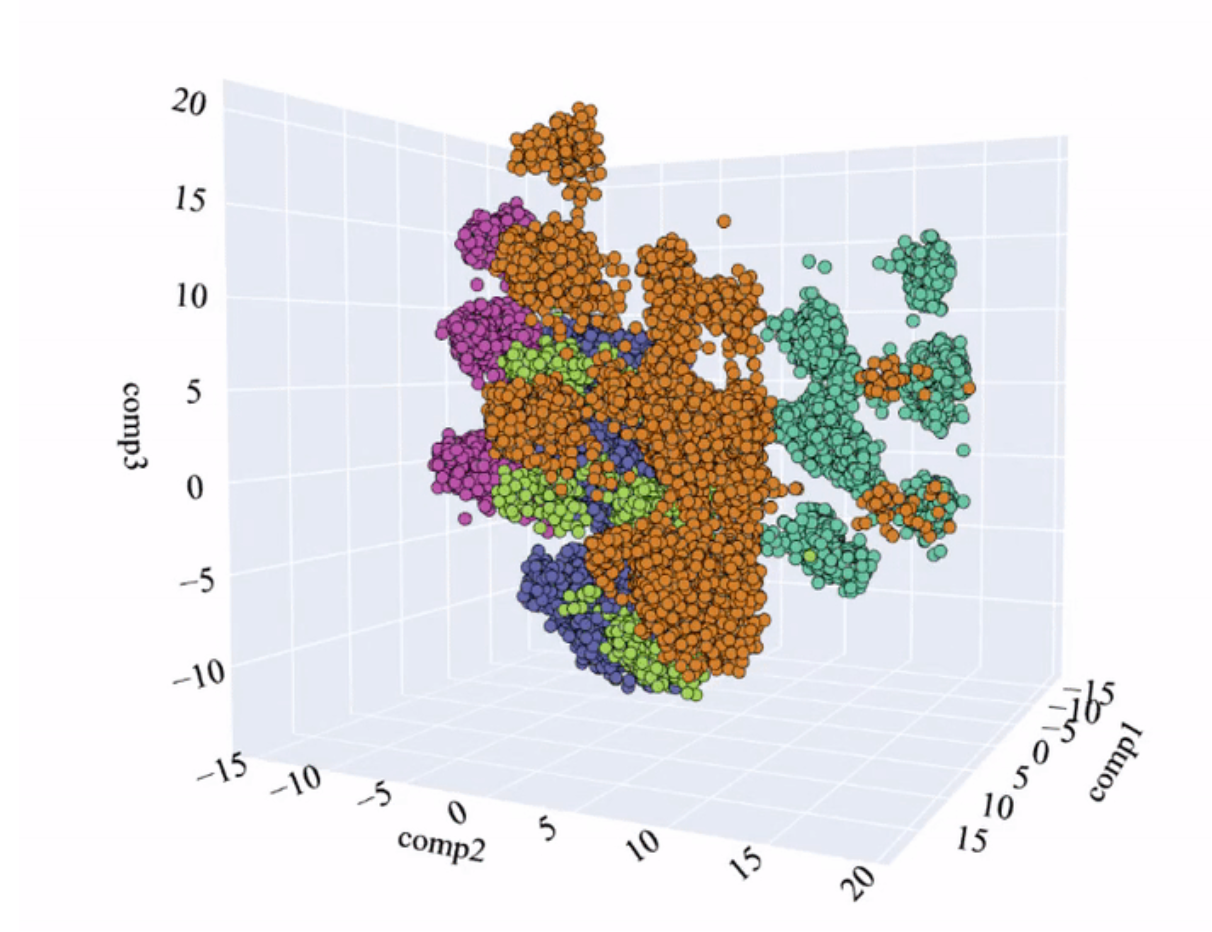
PCA 空间和模型创建的聚类(图片来源:作者)。
可以看出,聚类比传统方法更好地分化。这是个好消息。我们必须记住,考虑 PCA 分析前 3 个成分中包含的变异性很重要。根据经验,当它在 50% 左右(3D PCA)时,可以得出或多或少明确的结论。
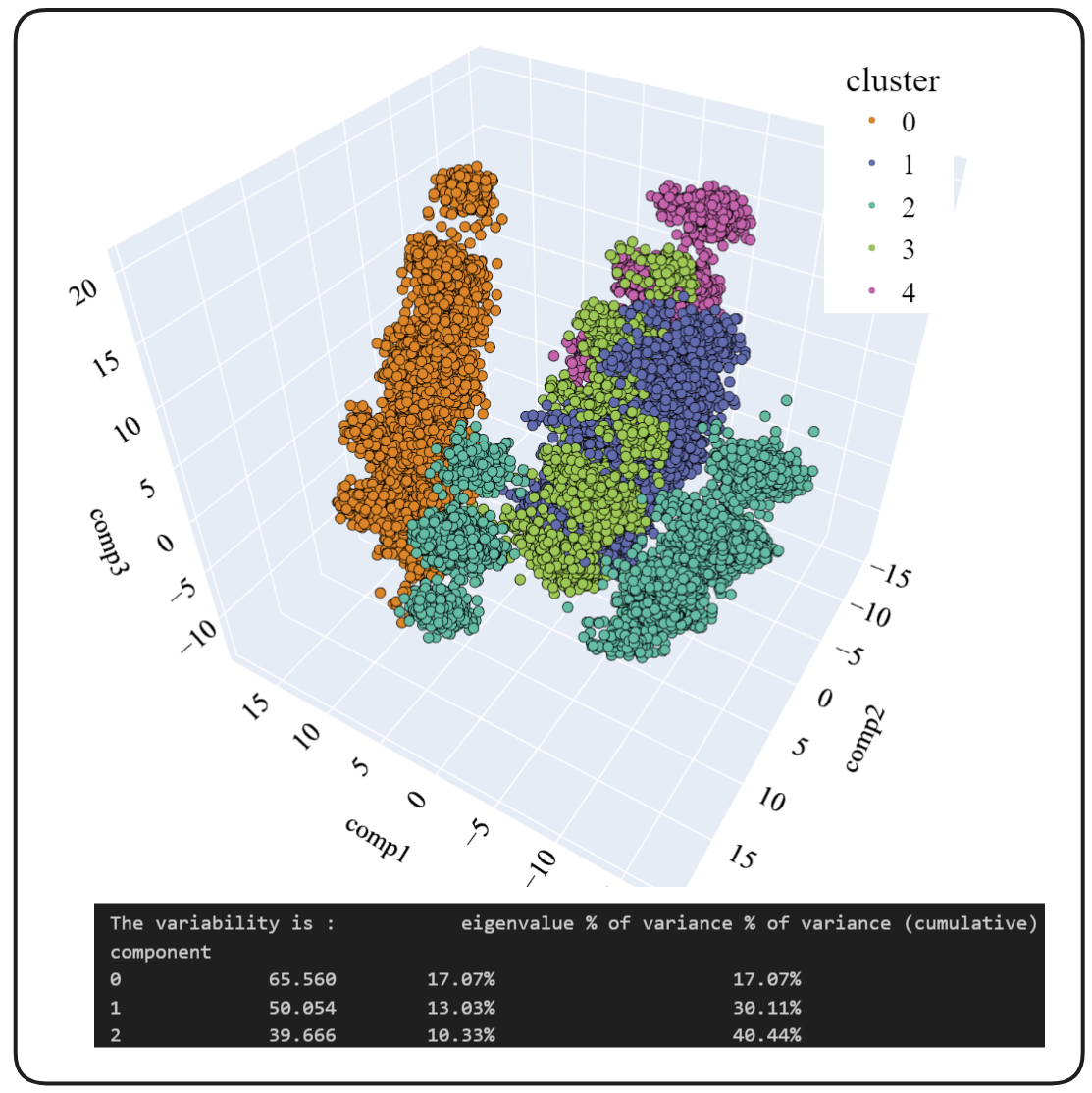
PCA 空间和模型创建的聚类。还显示了 PCA 前 3 个成分的变异性(图片来源:作者)。
我们看到,3 个成分的累积变异性为 40.44%,这是可以接受的,但并非理想。
我可以通过修改 3D 表示中点的透明度来直观地看到聚类的紧凑程度。这意味着当点在某个空间中聚集时,可以观察到一个黑点。为了理解我的意思,我展示了以下 GIF:
plot_pca_3d(df_pca_3d, title = "PCA Space", opacity=0.2, width_line = 0.1)
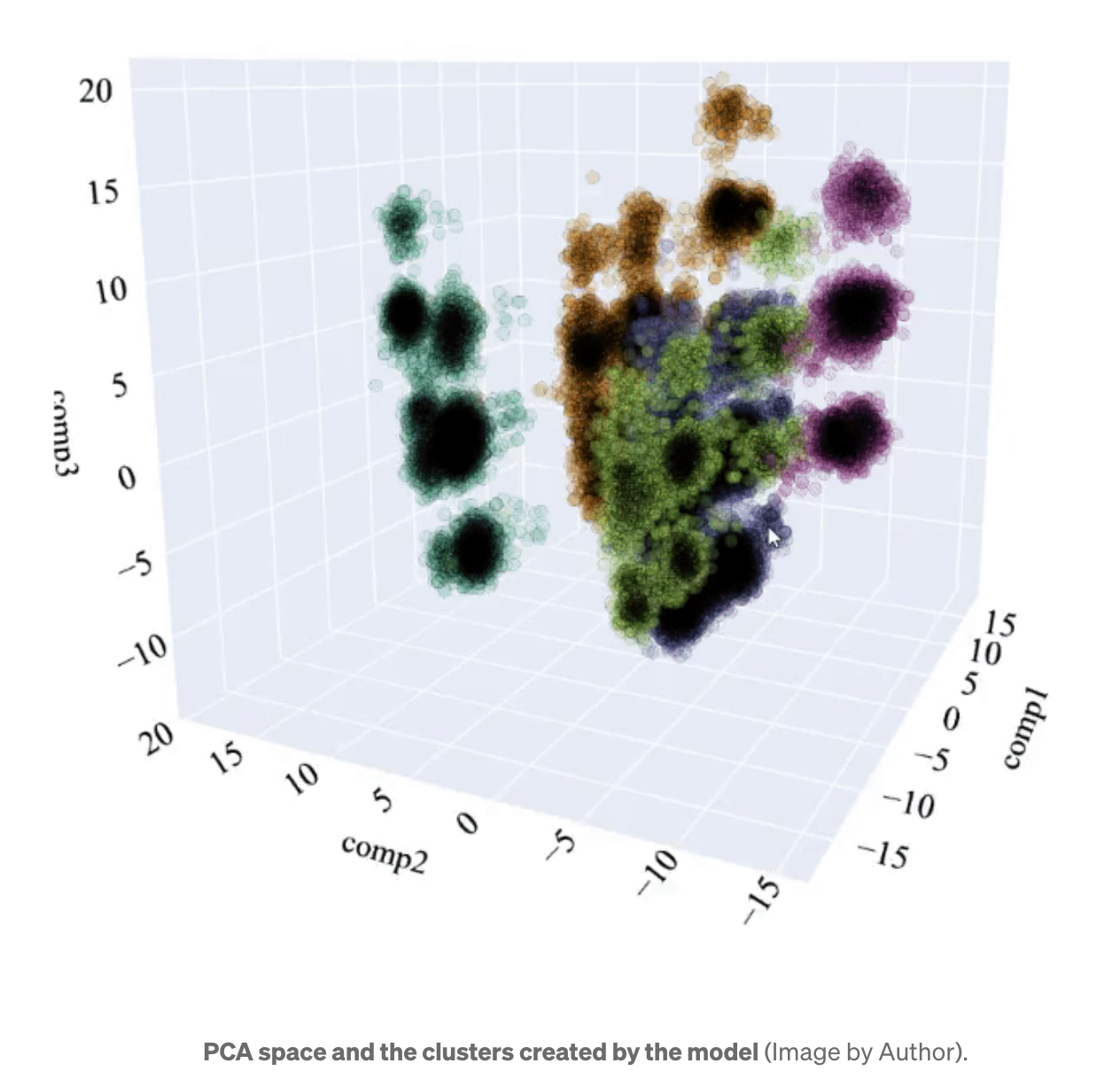
PCA 空间和模型创建的聚类(图片来源:作者)。
可以看出,空间中有几个点,同一聚类的点聚集在一起。这表明它们与其他点很好地分化,并且模型能够很好地识别它们。
即便如此,仍可以看出某些聚类无法很好地区分(例如:聚类 1 和 3)。因此,我们进行 t-SNE 分析,我们记得这是一种允许降维的方法,同时考虑了复杂的多元关系。
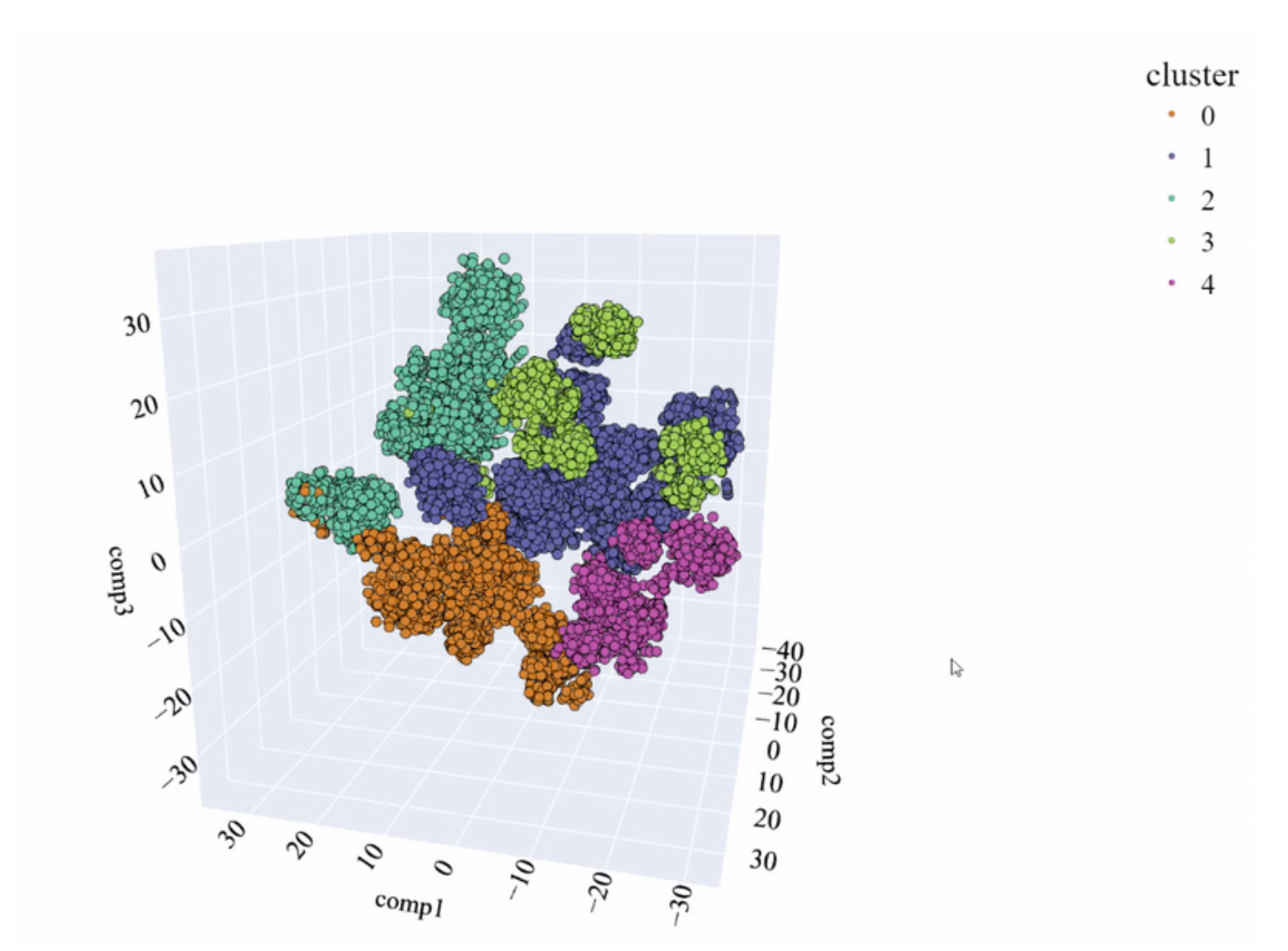
t-SNE 空间和模型创建的聚类(图片来源:作者)。
可以看到明显的改进。聚类之间没有重叠,并且点之间有明确的区分。使用第二种降维方法获得的改进是显著的。让我们看看 2D 比较:
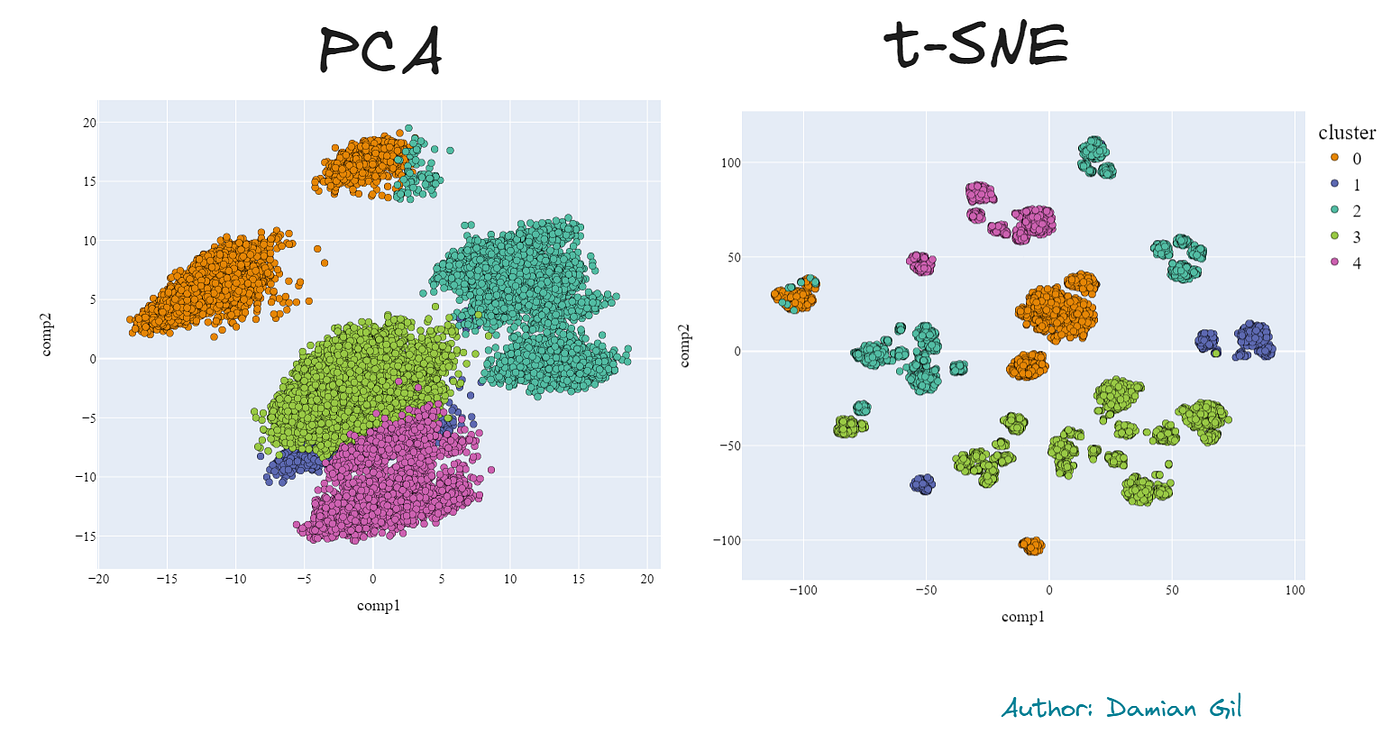
不同降维方法和模型定义的聚类的不同结果(图片来源:作者)。
再次可以看出,t-SNE 中的聚类比 PCA 更分离,区分度更好。此外,两种方法在质量上的差异小于使用传统 Kmeans 方法时的差异。
为了了解我们的 Kmeans 模型依赖于哪些变量,我们执行与之前相同的操作:我们创建一个_分类模型 (LGBMClassifier) 并分析特征的重要性。_
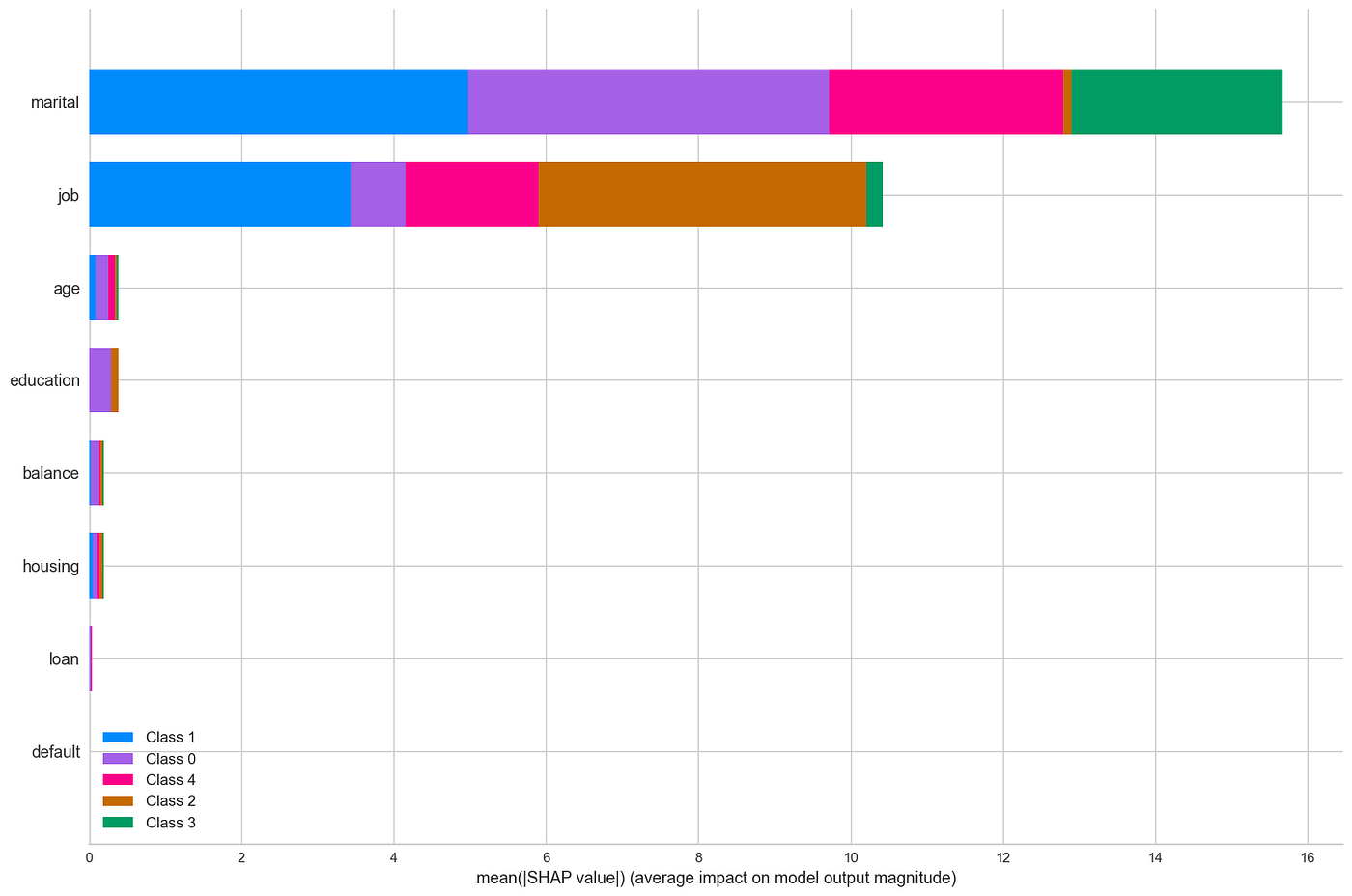
模型中变量的重要性(图片来源:作者)。
我们看到,这个模型主要基于“marital”和“job”变量。另一方面,我们看到有些变量没有提供太多信息。在实际案例中,应该创建一个没有这些信息量少变量的新模型。
Kmeans + 嵌入模型更优化,因为它需要更少的变量来提供良好的预测。好消息!
我们以最能揭示和最重要的部分结束。
经理和企业对 PCA、t-SNE 或嵌入不感兴趣。他们想要的是能够了解其客户的主要特征。
为此,我们创建了一个表格,其中包含每个聚类中可以找到的主要配置文件信息:
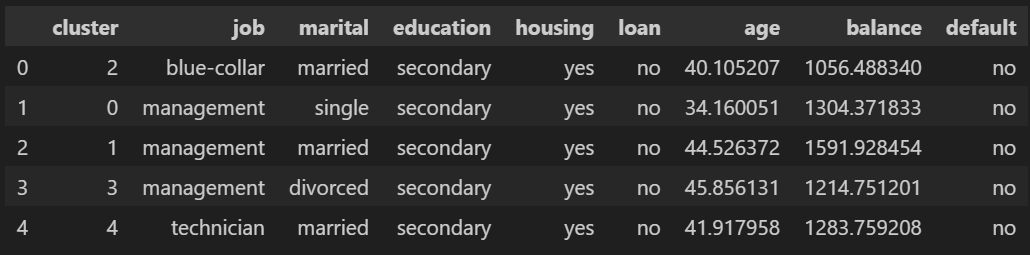
发生了一件非常奇怪的事情:最常见职位是“management”的聚类有 3 个。在这些聚类中,我们发现一种非常特殊的行为,即单身经理更年轻,已婚经理更年长,而离婚经理最年长。另一方面,余额表现不同,单身人士的平均余额高于离婚人士,已婚人士的平均余额更高。所说的内容可以总结在下图中:
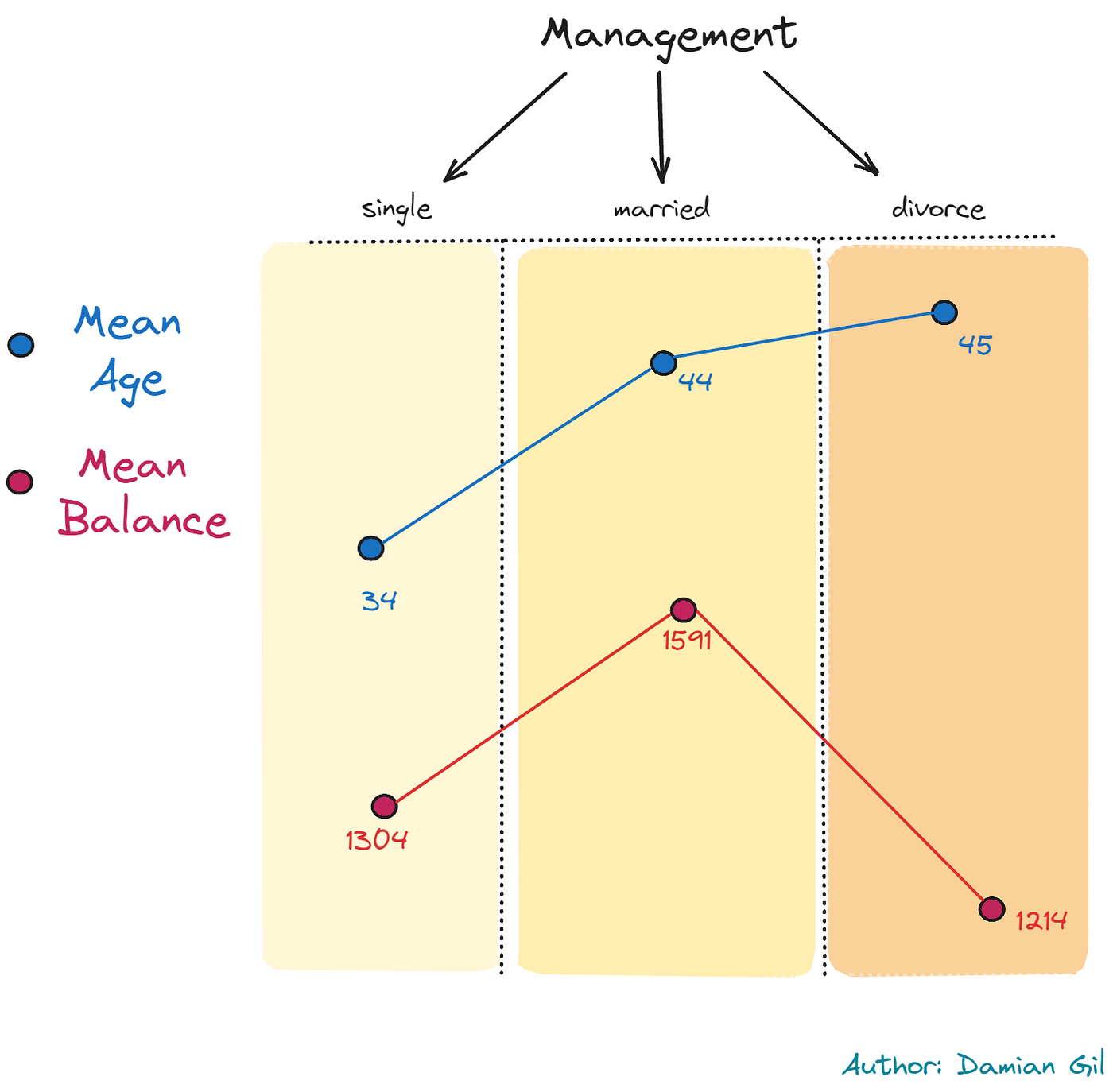
模型定义的客户画像(图片来源:作者)。
这一发现与现实和社会方面相符。它还揭示了非常具体的客户画像。这就是数据科学的魔力。
6 结论
结论很明确:
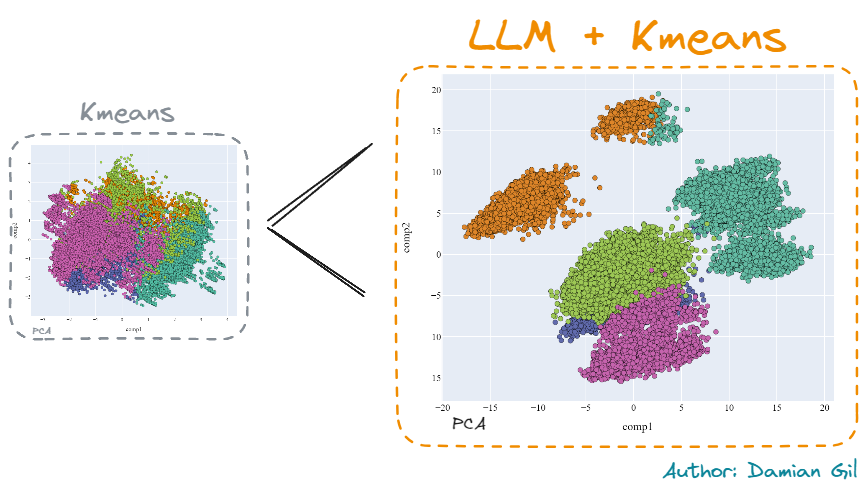
您必须拥有不同的工具,因为在实际项目中,并非所有策略都有效,并且您必须拥有增加价值的资源。可以清楚地看到,在 LLM 帮助下创建的模型脱颖而出。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)