Agentic AI: 搭建长时间记忆模块
Agentic AI: 搭建长时间记忆模块
本篇文章Agentic AI: Building Long-Term Memory探讨了为大型语言模型(LLM)构建长期记忆的挑战与解决方案。文章的技术亮点在于对短期和长期记忆的清晰区分,以及使用向量和知识图谱两种架构的比较,帮助读者理解如何有效管理信息。
如果您曾使用过LLM,您会知道它们是无状态的。如果您没有,可以把它们想象成没有短期记忆。
一个例子是电影《记忆碎片》,主角需要不断被提醒发生了什么,他用贴有事实的便签来拼凑出下一步应该做什么。
要与LLM对话,我们每次交互时都需要不断提醒它们对话内容。
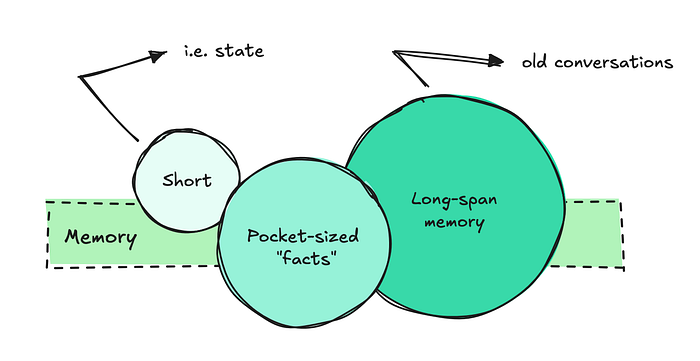
实现我们所说的“短期记忆”或状态很容易。我们只需获取一些之前的问答对,并将它们包含在每次调用中。
另一方面,长期记忆则完全是另一回事。
为了确保LLM能够提取正确的事实、理解之前的对话并关联信息,我们需要构建一些相当复杂的系统。
本文将探讨问题而非堆砌术语,探索构建高效系统所需的一切,回顾不同的架构选择,并审视可以帮助我们的开源和云提供商。
1 思考解决方案
让我们首先思考构建LLM记忆的过程,以及我们需要它具备哪些才能高效运行。
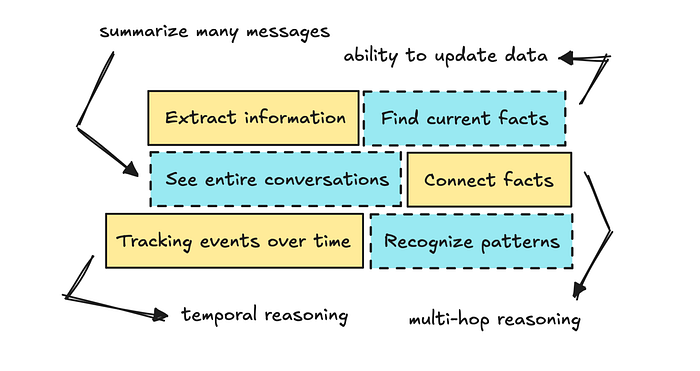
我们需要做的第一件事是让LLM能够提取旧消息,告诉我们说了什么。这样我们就可以问它:“你告诉我斯德哥尔摩那家餐厅叫什么名字?” 这将是基本信息提取。
如果您是LLM系统构建的完全新手,您的第一个想法可能是将整个对话直接放入上下文窗口,让LLM自行理解。
然而,这种策略使得LLM难以分辨哪些重要,哪些不重要,这可能导致它产生幻觉。一旦这些对话规模增长,您还必须限制它们的长度。
您的第二个想法可能是存储每条消息以及摘要,并使用语义搜索(即RAG中的检索)在查询到来时获取信息。
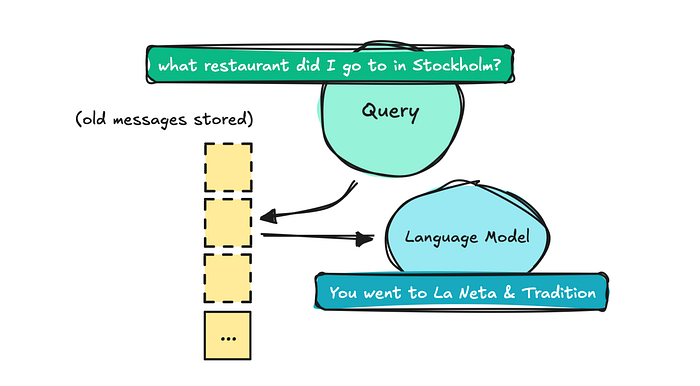
这类似于您构建标准朴素检索系统的方式。
问题在于,一旦它开始扩展(除了存储消息之外不进行任何操作),您将遇到内存膨胀、过时或相互矛盾的事实,以及不断增长且需要修剪的向量数据库。
您可能还需要了解事情发生的时间,以便您可以问:“你什么时候告诉我第一家餐厅的?” 这意味着您需要一定程度的时间推理。
这可能会促使您实现带有时间戳的更好元数据,以及可能是一个自编辑系统,用于更新和总结输入。
尽管更复杂,但自编辑系统可以在需要时更新事实并使其失效。
如果您继续深入思考这个问题,您可能还希望LLM能够关联不同的事实(执行多跳推理)并识别模式。
因此,您可以问它诸如“我今年参加了多少场音乐会?”或“根据这些信息,你认为我的音乐品味是什么?”之类的问题,这可能会引导您尝试知识图谱。
2 组织解决方案
这个问题变得如此之大,以至于人们开始更好地组织它。大多数团队似乎将长期记忆组织为两部分:袖珍事实和长期记忆的先前对话。
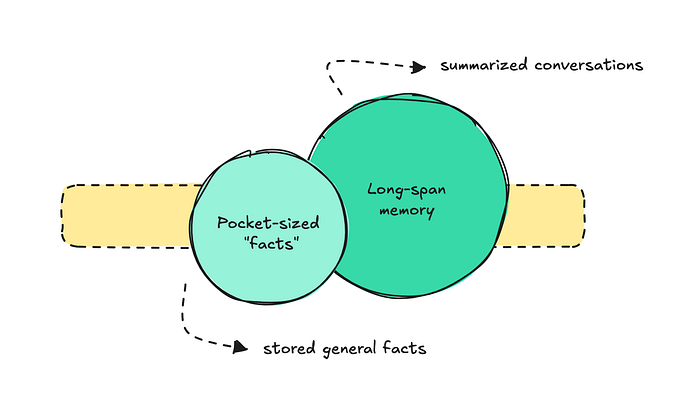
对于第一部分,即袖珍事实,我们可以以ChatGPT的记忆系统为例。
为了构建这种类型的记忆,它们可能使用分类器来决定一条消息是否包含应该存储的事实。
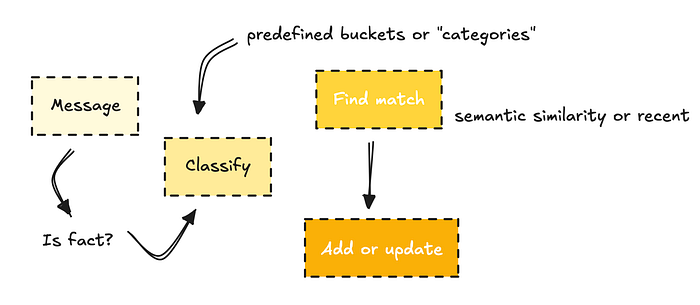
然后,它们将事实分类到预定义的桶中(例如个人资料、偏好或项目),如果与现有记忆相似则更新,如果不是则创建新记忆。
另一部分,长期记忆,意味着存储所有消息并总结整个对话,以便以后可以引用。这在ChatGPT中也存在,但就像袖珍记忆一样,您必须启用它。
在这里,如果您自行构建,您需要决定保留多少细节,同时要留意我们前面提到的内存膨胀和不断增长的数据库。
3 标准架构解决方案
如果我们看看其他人在做什么,这里有两种主要的架构选择:向量和知识图谱。
我首先介绍了基于检索的方法。这通常是人们刚开始时会尝试的。检索使用向量存储(通常是稀疏搜索),这意味着它同时支持语义搜索和关键词搜索。
检索入门很简单:您嵌入文档并根据用户问题进行获取。
但正如我们前面所说,如果天真地这样做,意味着每个输入都是不可变的。这意味着即使事实发生变化,文本仍然会在那里。
这里可能出现的问题包括获取多个相互矛盾的事实,这会使代理感到困惑。最糟糕的是,相关事实可能被埋藏在检索到的文本堆中。
代理也不会知道某事何时被提及,或者它指的是过去还是未来。
正如我们之前讨论的,有办法解决这个问题。
您可以搜索旧记忆并更新它们,向元数据添加时间戳,并定期总结对话以帮助LLM理解获取细节的上下文。
但使用向量,您也面临着数据库不断增长的问题。最终,您需要修剪旧数据或压缩它,这可能会迫使您丢弃有用的细节。
如果我们看知识图谱(KGs),它们将信息表示为实体(节点)和它们之间的关系(边)的网络,而不是像向量那样表示为非结构化文本。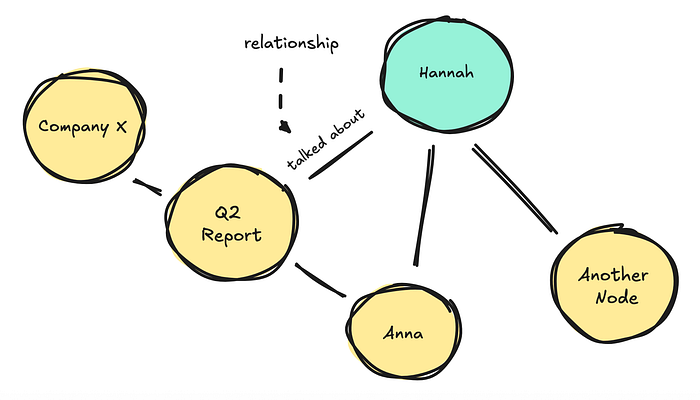
知识图谱不是覆盖数据,而是可以为旧事实分配一个 invalid_at 日期,这样您仍然可以追溯其历史。它们使用图遍历来获取信息,这让您可以跨多个跳点跟踪关系。
但正如我们提到的,我们可以通过获取旧事实并更新它们来使用向量做类似的事情。
但由于知识图谱可以在连接的节点之间跳转并以更结构化的方式保持事实更新,因此它们在多跳推理方面往往表现更好。
然而,知识图谱也有其自身的挑战。随着它们的增长,基础设施变得更加复杂,当系统需要深入查找正确信息时,您可能会开始注意到深度遍历期间的延迟更高。
维护它也可能相当昂贵。
尽管如此,总而言之,无论是基于向量还是基于知识图谱的解决方案,人们通常会更新记忆而不是仅仅添加新记忆,并增加设置特定桶的能力,就像我们在“袖珍”事实中看到的那样。
他们还经常使用LLM来总结和提取消息中的信息,然后再将其摄入。
如果我们回到最初的目标(同时拥有袖珍记忆和长期记忆),您可以混合使用RAG和KG方法来实现您想要的效果。
4 当前供应商解决方案(即插即用)
我将介绍几种不同的独立解决方案,它们可以帮助您设置记忆,并审视它们的工作方式、使用的架构以及其框架的成熟度。
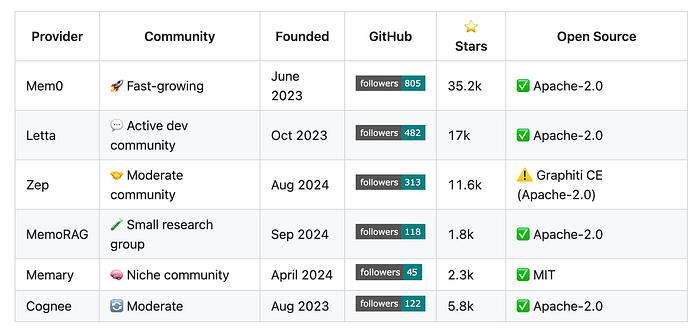
长期记忆提供商——我总是在这个仓库中收集资源
构建高级LLM应用程序仍然非常新颖,因此这些解决方案中的大多数都是在过去一两年内发布的。
当您刚开始时,查看这些框架是如何构建的,可以帮助您了解自己可能需要什么。
如前所述,它们中的大多数都属于知识图谱优先或向量优先类别。
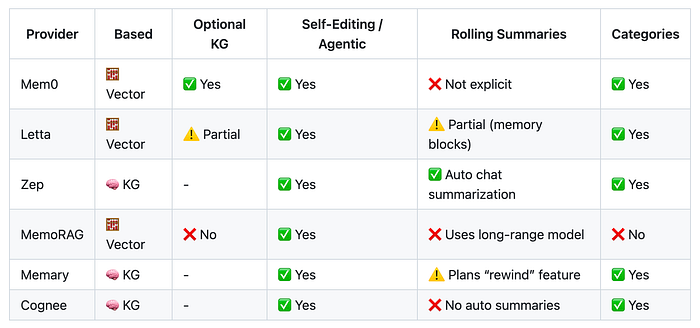
记忆提供商功能——我总是在这个仓库中收集资源
如果我们首先看Zep(或Graphiti),一个基于知识图谱的解决方案,它们使用LLM来提取、添加、使无效和更新节点(实体)和边(带时间戳的关系)。
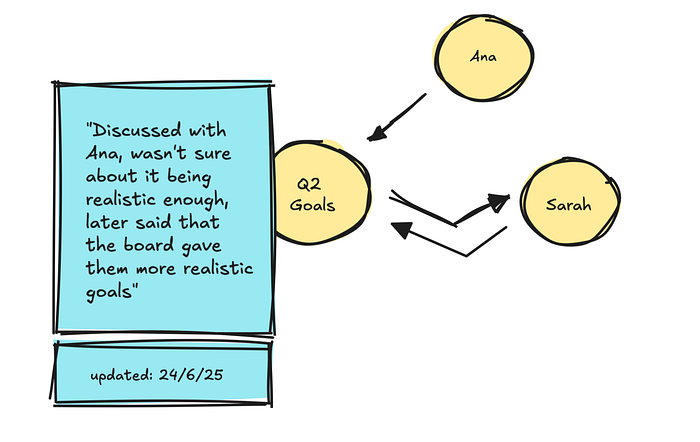
当您提出问题时,它会执行语义和关键词搜索以找到相关节点,然后遍历到连接的节点以获取相关事实。
如果新消息带有矛盾的事实,它会更新节点,同时保留旧事实。
这与Mem0不同,Mem0是一个基于向量的解决方案,它将提取的事实堆叠在一起,并使用自编辑系统来识别并完全覆盖无效事实。
Letta以类似的方式工作,但还包括额外的功能,如核心记忆,它存储对话摘要以及定义应填充内容的块(或类别)。
所有解决方案都能够设置类别,我们可以在其中定义系统需要捕获的内容。例如,如果您正在构建一个正念应用程序,一个类别可以是用户的“当前情绪”。这些与我们之前在ChatGPT系统中看到的基于口袋的桶相同。
我之前谈到的一点是,向量优先的方法在时间推理和多跳推理方面存在问题。
例如,如果我说我将在两个月后搬到柏林,但之前提到住在斯德哥尔摩和加利福尼亚,那么如果我几个月后问,系统会理解我现在住在柏林吗?
它能识别模式吗?使用知识图谱,信息已经结构化,使得LLM更容易使用所有可用的上下文。
使用向量,随着信息量的增长,噪音可能会变得太强,导致系统无法连接点。
对于Letta和Mem0,尽管总体上更成熟,但这两个问题仍然可能发生。
对于知识图谱,关注点在于它们扩展时的基础设施复杂性,以及它们如何管理不断增长的信息量。
尽管我没有彻底测试所有这些解决方案,并且仍然缺少一些部分(例如延迟数字),但我想提一下它们如何处理企业安全性,以防您希望在公司内部使用它们。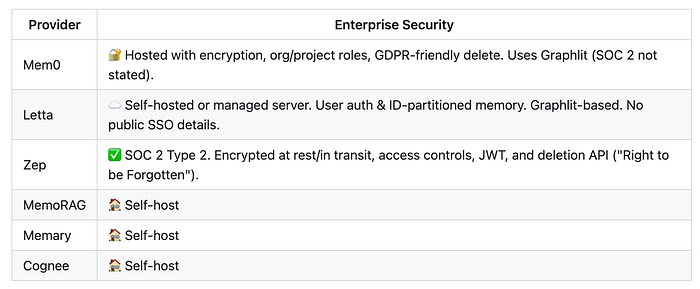
记忆云安全——我总是在这个仓库中收集资源
我发现唯一获得SOC 2 Type 2认证的云选项是Zep。然而,其中许多可以自托管,在这种情况下,安全性取决于您自己的基础设施。
这些解决方案仍然非常新。您最终可能会自己构建,但我建议您测试一下它们,看看它们如何处理边缘情况。
5 使用供应商的经济成本
能够为您的LLM应用程序添加功能固然很好,但您需要记住这也会增加成本。
我总是会包含一个关于实施某项技术的经济学部分,这次也不例外。这是我添加任何东西时首先检查的事情。我需要了解它将如何影响应用程序的单位经济效益。
大多数供应商解决方案都允许您免费开始。但一旦您超过几千条消息,成本就会迅速增加。
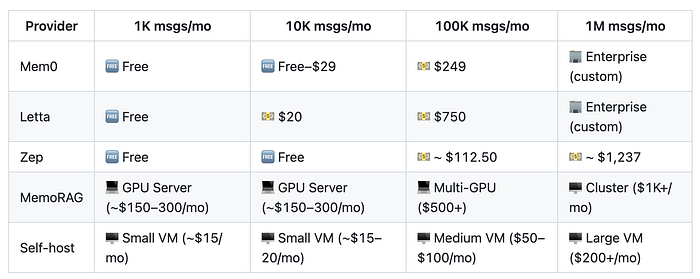
每条消息的“估计”记忆定价——我总是在这个
请记住,如果您的组织每天有几百个对话,当您通过这些云解决方案发送每条消息时,定价将开始累积。
从云解决方案开始可能是理想的选择,然后随着您的增长转向自托管。
您也可以尝试混合方法。
例如,实现您自己的分类器来决定哪些消息值得存储为事实以降低成本,同时将所有其他内容推送到您自己的向量存储中进行定期压缩和总结。
话虽如此,在上下文窗口中使用字节大小的事实应该胜过粘贴5000个令牌的历史块。预先向LLM提供相关事实也有助于减少幻觉,并通常降低LLM生成成本。
6 注意事项
重要的是要注意,即使有了记忆系统,您也不应该期望完美。这些系统有时仍然会产生幻觉或遗漏答案。
最好是预料到不完美,而不是追求100%的准确性,这样可以避免沮丧。
目前没有哪个系统能达到完美的准确性,至少目前还没有。研究表明幻觉是LLM固有的部分。即使添加记忆层也无法完全消除这个问题。
我希望这次练习能帮助您了解如何在LLM系统中实现记忆,如果您是新手的话。
仍然缺少一些部分,例如这些系统如何扩展、如何评估它们、安全性以及延迟在实际环境中的表现。
您需要自己测试这些。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)