Qwen-3模型特点图文详解
在实际测试中,Qwen-3能够理解用户提出的编程需求,提供语法正确、逻辑清晰的代码片段,甚至包括注释和优化建议。值得注意的是,即便参数规模远小于闭源的GPT-4(推测OpenAI-o1为GPT-4的一个公开指标版本),Qwen-3依然展现出媲美甚至超越的实力。,根据官方报告,Qwen-3各尺寸模型相对于Qwen-2.5呈现出“小模型赶超大模型”的趋势:如 Qwen-3-1.7B≈Qwen-2.5-
#Qwen3 #AI #大模型 #AIAgent

Qwen-3模型正式发布,阿里巴巴创新性地引入了混合推理模式与混合专家架构。图中Qwen吉祥物形象代表了Qwen-3模型家族。
昨天深夜,阿里巴巴正式发布并开源了全新的通义千问 Qwen-3 系列模型,引发了业界的广泛关注。作为通义千问家族的第三代大模型,Qwen-3一经问世便在开源模型中登顶,其性能被报道全面超越此前领先的开源模型 DeepSeek-R1 和 OpenAI 的 o1 模型。更令人瞩目的是,Qwen-3采用了创新的混合专家(MoE)架构,总参数规模达 2350 亿,但每次推理仅需激活约 220 亿参数,成本仅为同级别模型的三分之一。与此同时,Qwen-3还能灵活切换“快思考”与“慢思考”模式,对简单问题秒级响应,对复杂任务逐步深度推理。下面,我们就从架构创新、性能指标、模型对比、应用优势和开源情况等方面,对Qwen-3模型进行详细图文解析。
架构创新:混合专家与双模式推理
Mixture-of-Experts (混合专家) 架构: Qwen-3的架构最大亮点是在大型语言模型中引入了混合专家(MoE)技术。传统Transformer的每一层前馈网络通常都是稠密激活,而在Qwen-3中,一部分前馈层被替换为MoE稀疏层。MoE层由多个“专家”子模型组成,通过门控路由网络为每个输入选择少数几个专家激活,从而达到“用更少的计算,获得更大的模型容量”。例如,旗舰版 Qwen-3-235B-A22B 模型虽然总参数2350亿,但每条输入仅需激活约220亿参数参与计算,相当于用稠密模型10%的计算量就实现了同等性能。这种设计显著提升了计算效率,使得Qwen-3成为国内首个“混合推理”大模型,可以在降低算力消耗的同时保持甚至超越以往模型的效果。此外,Qwen-3通过分层稀疏调度和动态专家激活等机制优化了MoE训练的稳定性,确保模型在推理时专家负载均衡,不会因为某些专家过度忙碌而影响性能。
“快思考”与“慢思考”模式: 为了兼顾简单问答的响应速度和复杂推理的深入思考,Qwen-3开创性地支持两种推理模式。在“思考模式”下,模型会先生成一系列隐藏的推理步骤,逐步演绎出答案,适合数学、逻辑等需要缜密思考的问题;而在“非思考模式”下,模型直接给出简洁答复,更加高效快捷,适合日常对话和简单问答。这两种模式可以无缝切换,用户甚至可以通过参数设置来开启或关闭模型的“思考”过程。这种双模架构让Qwen-3既能“深思熟虑”,又能“快速反应”,极大提升了模型在不同场景下的适应能力。例如,对于复杂的数学题,启用思考模式后模型可以多阶段推理,得到更高的准确率;而对于简单提问,则无需冗长推理,立即给出答案,从而节省计算资源。
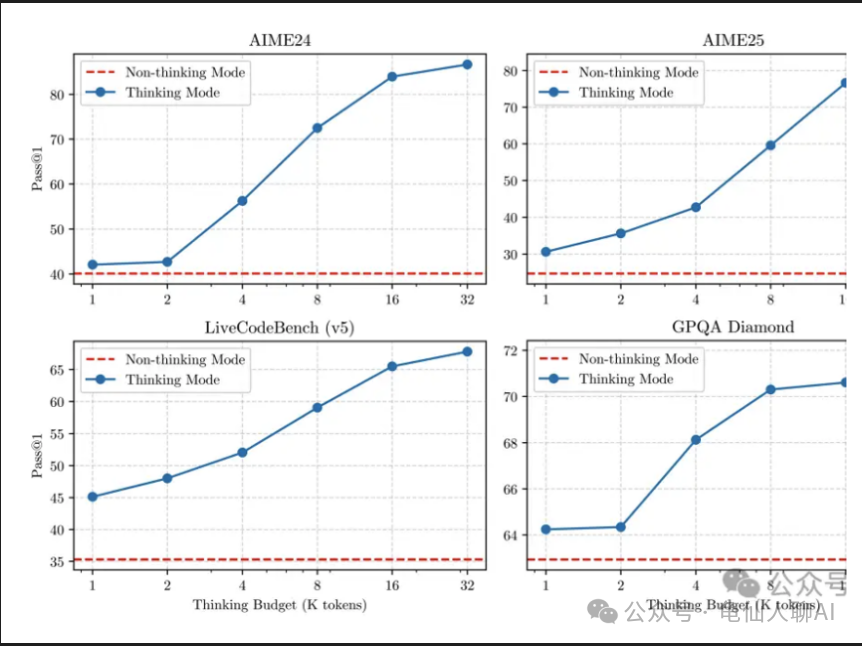
Qwen-3模型在多种任务中支持“思考(深度推理)”和“非思考(直接回答)”两种模式。上图比较了在不同“思考预算”(链式推理步骤长度)下,模型在AIME竞赛题、编程题(LiveCodeBench)和问答任务(GPQA)上的表现。蓝线为开启思考模式时准确率随预算提升的变化,红线为始终关闭思考时的水平线。可以看到,随着思考步骤增多,模型在复杂任务上的成绩显著提升,而非思考模式下性能几乎不变。这一结果直观展示了“慢思考”模式对复杂问题解答的价值。
基础结构改进:
Qwen-3在底层架构上也借鉴和改进了最新的Transformer技术。例如,引入RoPE位置编码的动态伸缩配置,支持最长 128K 长的上下文窗口,比前代模型的上下文长度大幅提升,能够处理超长文本输入。官方披露Qwen-3的预训练分三阶段完成:首先在4K长度下用 30 万亿 tokens 构建基础语言能力,然后增加专业知识(STEM、代码等)数据再训练 5 万亿 tokens,最后扩展上下文至32K长度以习得长文本处理。在模型结构细节上,Qwen-3对多头注意力机制和前馈层进行了优化,定制了支持RoPE和稀疏MoE的注意力层,并支持包括Yarn、LLaMA3等在内的多种RoPE变体配置。这一系列架构创新与优化,使得Qwen-3即使在较小参数规模下也具备惊人的能力——据官方报告,稠密版的Qwen-3-4B模型性能已可媲美Qwen-2.5的72B大模型。可以说,Qwen-3通过架构上的基础设计革新与混合专家策略,在提升模型智力的同时,实现了计算效率和灵活性的飞跃。
强劲性能:权威基准全面领跑
评估一个大模型的强弱,离不开在各项权威基准测试上的表现。Qwen-3在发布时公布了其在多项指标上的优异成绩,包括学术问答、数学推理、代码生成、常识判断等方面均全面领跑同类开源模型。尤其引人关注的是,在 MMLU(多学科知识问答)、GSM8K(数学字题)、HumanEval(代码生成评测)等基准上,Qwen-3的顶级型号接近甚至超越了以前只有超大模型才能达到的水平。
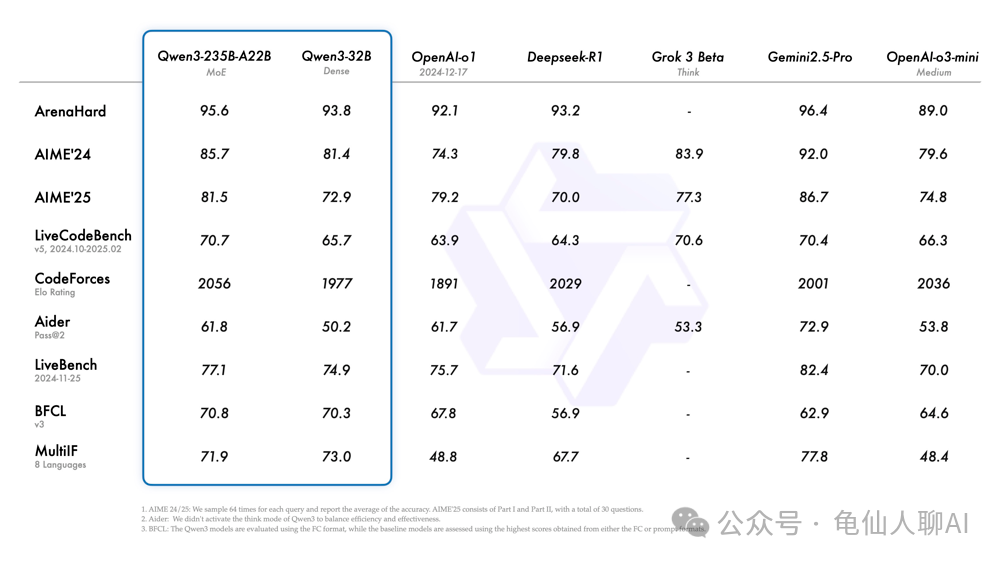
Qwen-3-235B-A22B(MoE版)模型在多个基准任务上的成绩对比【28†】。表中列出了Arena综合知识问答、AIME竞赛题(2024和2025)、编程题(LiveCodeBench)、算法竞赛(CodeForces Elo)、代码AI助手评测(Aider Pass@2)、综合性能测试(LiveBench)、智能体工具使用评测(BFCL)以及多语言常识测试(MultiLingualInference)等任务。可以看出,Qwen-3的旗舰版在几乎所有任务上都取得了领先成绩。例如,在综合知识测评Arena中,Qwen-3取得95.6的高分,超越OpenAI-o1的92.1和DeepSeek-R1的93.2。在数学与逻辑挑战AIME和编程挑战LiveCodeBench上,Qwen-3同样大幅领先同行模型。值得注意的是,即便参数规模远小于闭源的GPT-4(推测OpenAI-o1为GPT-4的一个公开指标版本),Qwen-3依然展现出媲美甚至超越的实力。
从官方数据来看,Qwen-3-235B 在MMLU五选一问答测评中达到了约 87.8 分的成绩,在数学问题GSM8K上更是取得了 94.4 的高准确率,在代码生成HumanEval/MBPP评测中也超过 80 分,全面刷新了开源模型的纪录。相比之下,上一代 Qwen-2.5-72B 稠密模型在MMLU上的成绩约为86分,GSM8K约91.5分,Qwen-3显然实现了稳步的性能提升。即使是Qwen-3的小模型,也都有不俗表现:例如 Qwen-3-4B 已经可达到 Qwen-2.5 的72B模型在指令调优后的水平。这种“小模型,大能力”的现象凸显了架构和训练上的改进效果,让开发者以更低算力成本享受到更强的模型性能。
另外,Qwen-3还在中文基准C-Eval、高难度推理Benchmark、常识推断等评测中取得领先,表明它不仅在英文任务上表现优异,在中文等多语言任务上同样具备优势。这与其预训练时大幅扩充了语料规模、多语种覆盖广泛密切相关——Qwen-3预训练语料总计达 36 万亿 token,涵盖了 119 种语言和方言。因此,无论是中文、英文,还是其他小语种,Qwen-3都展现出强大的理解与生成能力,对于全球开发者来说都是一大利好。
对比分析:Qwen-3 vs Qwen-2 vs 主流大模型
作为新一代模型,Qwen-3与前代的Qwen-2.5,以及业界其他主流开源模型(如Meta的LLaMA 3系列、OpenAI GPT-4等)相比有哪些不同和提升呢?让我们从模型规模、架构特性和实际表现几个方面来对比分析。
与Qwen-2.5的比较: 首先在架构上,Qwen-2.5主要采用稠密Transformer架构(部分版本有MoE拓展),上下文长度一般为2048或8192;而Qwen-3全面引入了MoE稀疏专家和混合推理模式,大幅增加了上下文长度(最高128K),在结构上更加灵活智能。其次在训练数据上,Qwen-3使用了约36万亿token的语料,接近Qwen-2.5的一倍,并特别加强了代码、数学、逻辑推理等领域的数据合成。这样的数据提升使得Qwen-3在专业任务上的底蕴更足。性能方面,根据官方报告,Qwen-3各尺寸模型相对于Qwen-2.5呈现出“小模型赶超大模型”的趋势:如 Qwen-3-1.7B≈Qwen-2.5-3B,Qwen-3-8B≈Qwen-2.5-14B,Qwen-3-32B≈Qwen-2.5-72B。甚至 Qwen-3-4B 就已匹敌 Qwen-2.5-72B-Instruct 的表现。这意味着通过架构和训练优化,Qwen-3显著提升了模型效率,用更小的参数实现了更强的效果。最后在功能特性上,Qwen-3新增的双模式推理、MCP工具协议支持(详见下文)等,也都是Qwen-2.5所不具备的改进。
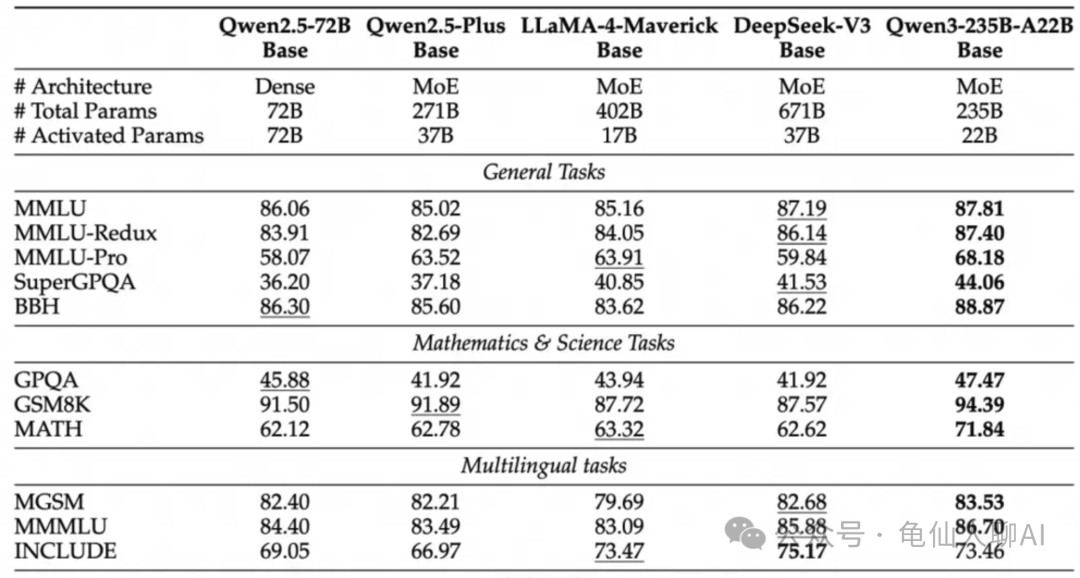
不同模型在各项基准测试上的表现对比。表格横轴列出了多个评测任务,包括综合知识(MMLU及衍生)、复杂问答(SuperGPQA)、大脑刁难(BBH),数学与代码(GSM8K, MATH, MBPP等),多语言推理(MGSM, MMLU等多语)以及代码理解/生成(EvalPlus, MultiPL-E等)。纵轴列出了模型,包括Qwen-2.5-72B(稠密)、Qwen-2.5-Plus(MoE 271B总参,37B激活)、LLaMA-4-Maverick(MoE 402B总参,17B激活)、DeepSeek-V3(MoE 671B总参,37B激活)以及Qwen-3-235B-A22B(MoE)。可以看到,Qwen-3(最右列)在多数任务上指标最高。例如在MMLU上达到87.81,略高于DeepSeek-V3的87.19和远高于LLaMA-4的85.16;在GSM8K数学题上,Qwen-3以94.39%准确率显著领先其他模型。一系列对比数据印证了Qwen-3在各领域的全面领先地位。
与LLaMA-3、GPT-4等的比较:
Qwen-3作为开源模型,与Meta的LLaMA-3系列和OpenAI的GPT-4也有不同定位。LLaMA-3家族(如LLaMA 3.1-70B、405B等)同样强调多语种和长上下文支持,但Qwen-3通过MoE在相似计算预算下提供了更大的参数容量,因此在数学推理、代码生成等方面更具优势。有报告指出,Qwen-3 72B模型在MMLU、GSM8K、HumanEval等标准上超越了LLaMA-3 70B模型。相比目前业界最强的GPT-4,Qwen-3作为开源模型在知识覆盖和推理能力上正不断逼近。虽然后者在某些复杂常识推理上仍有优势,但Qwen-3已经全面超过GPT-3.5水平,甚至在部分基准测试上达到或超越GPT-4早期版本的表现。值得一提的是,Qwen-3在多语言能力上支持接近120种语言,这一点甚至比GPT-4的已知公开能力范围更广,充分展现了阿里团队在大数据多语言训练上的雄厚实力。
应用场景中的优势与表现
除了论文中的数字和榜单排名,Qwen-3在实际应用中的综合表现也令人惊喜。借助其架构和性能优势,Qwen-3在问答对话、代码生成、复杂推理以及智能Agent等场景下展现出了强大的能力。
对话问答: 得益于超过20万亿token的通用语言预训练和后期的大规模指令微调,Qwen-3非常擅长于自然语言对话。它对人类指令有着卓越的遵循性和理解力,能够进行多轮上下文对话而保持逻辑连贯。在创意写作、角色扮演等开放式聊天场景中,Qwen-3表现出高度的语言创造力和仿真对话能力,回复既自然又引人入胜。这源于模型在人类偏好对齐上的优化——官方指出Qwen-3在人类偏好方面进行了强化学习调整,使其输出更加符合用户期望。无论是充当聊天助手、小故事撰写者,还是专业咨询问答,Qwen-3都能给予令人满意的回答。在中文场景下,Qwen-3凭借本土化的训练数据,能处理各种语言风格和词汇,对国内用户来说交流毫无障碍。
代码生成与推理: Qwen-3在编程任务上有突出的优势,这要归功于其在训练过程中融入了大量合成的代码语料和编程问答数据。在实际测试中,Qwen-3能够理解用户提出的编程需求,提供语法正确、逻辑清晰的代码片段,甚至包括注释和优化建议。例如,在LeetCode算法题或实际工程问题上,它常常可以生成正确的解法,展示出类似专业程序员的思路。在OpenAI的HumanEval基准(测试Python函数实现正确率)上,Qwen-3的得分已经达到80分以上,与GPT-4不相上下。这意味着开发者可以借助Qwen-3来辅助代码自动完成、单元测试生成等,提高开发效率。此外,Qwen-3强大的链式推理能力也让它在数学计算、多步逻辑推演方面有上佳的表现。对于复杂的数学推导题,Qwen-3借助“慢思考”模式能逐步给出推理过程,最终算出正确结果——这一点在教育辅导、学术研究等应用中非常有价值。
工具使用与Agent能力: 令业界兴奋的是,Qwen-3还是一个擅长调用外部工具的大模型。它原生支持了最近火热的MCP协议(Model Context Protocol,模型上下文协议),这是一种开放标准接口,方便LLM与外部数据源或服务连接。借助MCP和封装完善的Qwen-Agent框架,Qwen-3可以像一个智能体(Agent)那样,按照需求调用搜索引擎、数据库、计算器,甚至控制手机和电脑执行操作。在官方提供的Agent能力评测BFCL基准上,Qwen-3创造了 70.8 的高分,超过了Google Gemini2.5-Pro、OpenAI-o1等顶尖模型。这表明Qwen-3在自动化任务执行、工具协同方面达到了新的高度。设想一下,在一个智能助理应用中,Qwen-3既能回答你的问题,又能在需要时自主去互联网检索信息、调用日历查询安排,甚至远程操控智能家居设备——这些场景因为有了MCP支持变得更加轻松可行。随着这方面生态的成熟,Qwen-3有望成为各种AI应用爆发的赋能基石,为终端用户带来更加便捷强大的体验。
发布与开源:版本、授权与适配
模型家族与版本: 本次发布的 Qwen-3 系列包含了8款模型,其中 2 款是混合专家模型(MoE),6 款是稠密模型(Dense)。两款MoE模型分别是旗舰级的 Qwen3-235B-A22B(总参数2350亿,激活参数220亿,支持128K上下文)和轻量级的 Qwen3-30B-A3B(总参数300亿,激活参数30亿,128K上下文)。稠密模型则覆盖了从小到大的各种规模,包括 Qwen3-0.6B、1.7B、4B、8B、14B、32B,其中0.6B和1.7B模型上下文长为32K,其余8B及以上模型支持最长 128K 上下文。这样的产品线布局,使Qwen-3几乎覆盖了所有算力等级的需求:从移动端设备可以跑的几亿参数小模型,到需要多GPU集群支持的百亿/千亿参数大模型,一应俱全。
开源协议与获取: 阿里巴巴将Qwen-3系列模型完全开源,并采用了宽松的 Apache 2.0 许可协议。这意味着个人开发者和企业都可以免费使用、修改、部署这些模型,包括商用用途,而无需担心版权或专利限制。模型权重现已上传至 Hugging Face、ModelScope 等平台,开发者可以很方便地下载预训练模型或指令微调后的权重。同时,GitHub 上也提供了相应的仓库(QwenLM/Qwen3),其中有详细的使用教程、示例代码和常见问题解答。用户可以通过Transformers库、ModelScope SDK等直接调用Qwen-3,并选择不同推理后端(如PyTorch原生、vLLM高效推理、FastChat等)进行部署。如果希望本地运行,小模型可以在笔记本电脑甚至手机上执行;而像235B这样的超大模型也能够在配备足够显存的服务器或云实例上运行。据测试,在苹果M2 Ultra芯片的电脑上,已经成功部署了Qwen3-235B MoE模型,生成速度可达 28 token/s——这证明了大型模型本地化的可能,也体现了Qwen-3高效架构带来的加速效果。
适配范围与生态: Qwen-3的发布为广大的AI应用场景提供了新选择。由于提供了从0.6B到235B的丰富模型规模,并且在语言、代码、多模态(未来扩展)等方面能力出色,Qwen-3可以被应用于聊天机器人、智能客服、内容创作、教育辅导、程序助手、数据分析等各类场景。比如,小参数的Qwen-3模型可部署在手机App中,实现离线的聊天问答或翻译功能;中等规模模型可作为私有部署的企业知识库问答引擎;超大模型则可以在云端提供高精度的AI服务。在与硬件平台的适配上,阿里云方面也提供了对自研昇腾AI芯片以及Hygon DCU的支持。社区开发者还将Qwen-3集成进了像Ollama、LMStudio、llama.cpp等本地LLM工具中,方便不同行业的人将其引入各自的项目。可以预见,随着Qwen-3的开源和推广,其生态将迅速繁荣,更多创新应用会基于这一强大的模型引擎诞生。
总结
Qwen-3的面世标志着国内大模型研发的又一座里程碑。通过架构上的大胆创新(混合专家稀疏激活、双模态推理等)和训练上的精益求精(海量高质量数据、多阶段优化),阿里巴巴成功打造出一个高性能、低成本、广适用的大语言模型。在诸多权威基准上,Qwen-3展现出领先优势,缩小了开源模型与封闭领先模型之间的差距。在实际应用中,它兼具快速响应与深度思考能力,能胜任从闲聊到推理、从创作到工具调用的各种任务。更重要的是,Qwen-3以完全开源的姿态开放给社区,这将大大加速AI技术的民主化进程。对于开发者而言,现在可以以前所未有的自由度使用这样强大的模型来构建产品和服务。展望未来,随着Qwen-3生态的完善和可能的持续迭代,我们有理由期待它在更多元的场景中大放异彩,引领新一轮的大模型应用创新热潮。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)