[论文阅读] 人工智能 + 软件工程(测试)| 让 LLM 单元测试生成告别 “幻觉” 与模糊,示例精炼有了新方案
CLAST 旨在解决基于上下文学习(ICL)的大语言模型(LLM)单元测试生成中示例语义模糊的问题。现有方法如 RAGGen、TELPA 依赖高质量示例,但实际示例常存在多场景混合、文本模糊等缺陷,而 UTgen 等精炼技术易因 LLM 幻觉降低测试有效性。CLAST 结合程序分析与 LLM,通过 “测试净化”(拆分复杂测试为单场景)和 “文本清晰度增强”(LLM 生成 + AST 匹配后处理)提
让 LLM 单元测试生成告别 “幻觉” 与模糊,示例精炼有了新方案
论文信息
- 论文原标题:Clarifying Semantics of In-Context Examples for Unit Test Generation
- 研究机构:§ollege of Intelligence and Computing, Tianjin University, Tianjin, China ;Huawei Cloud Computing Technologies Co., Ltd., Beijing, China
- 发表情况:accepted in the research track of ASE 2025
1. 一段话总结
现有基于上下文学习(ICL) 的大语言模型(LLM)单元测试生成技术(如RAGGen、TELPA)受限于示例的语义清晰度(逻辑复杂、文本模糊),而现有精炼技术(如UTgen)因依赖LLM易产生幻觉,导致测试有效性下降。为此,研究提出CLAST——一种结合程序分析与LLM的单元测试精炼技术,通过“测试净化”(拆分复杂测试为单场景)和“文本清晰度增强”(LLM生成注释/标识符+AST匹配后处理)提升示例质量;在7个项目(4个开源+3个工业项目) 评估中,CLAST完全保留原始测试有效性(UTgen平均降低编译成功率12.90%、通过率35.82%、行覆盖率4.65%、变异分数5.07%),超85.33%用户偏好其语义清晰度,且将RAGGen/TELPA生成测试的编译成功率、通过率、行覆盖率分别提升25.97%、28.22%、45.99%(对比UTgen)。
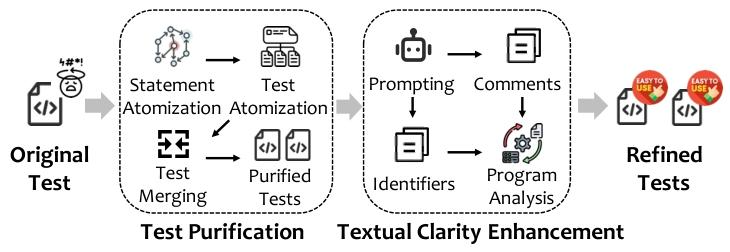
2. 思维导图

3. 详细总结
一、引言(INTRODUCTION)
- 研究背景
- 自动化单元测试是保障软件质量的关键,传统搜索式方法(如EvoSuite、Randoop)存在局限性,而LLM基于ICL技术(如RAGGen、TELPA)能生成更具上下文感知的测试,无需大规模微调。
- ICL的有效性高度依赖上下文示例的语义清晰度,其包含两维度:①逻辑清晰度(单一场景);②文本清晰度(标识符/注释准确)。
- 现有问题
- 开发者/工具生成的测试普遍存在语义模糊:混合多场景断言、标识符歧义(如
mColumn3)、注释缺失。 - 现有精炼技术UTgen仅依赖LLM,易产生幻觉(如引入不存在API
getColumnDimension),导致测试有效性下降(如RAGGen在Time项目行覆盖率从57.32%降至22.94%)。
- 开发者/工具生成的测试普遍存在语义模糊:混合多场景断言、标识符歧义(如
- 研究目标:提出CLAST,通过程序分析与LLM结合,提升测试示例语义清晰度的同时,完全保留原始测试有效性。
二、动机(MOTIVATION)
以getColumnMatrix方法的原始测试为例,暴露核心痛点:
- 原始测试缺陷:混合“有效索引3”和“无效索引5”两个场景,标识符
mColumn3无明确含义,RAGGen用其作为示例时无覆盖率提升。 - UTgen的不足:
- 误解测试意图:将“特定索引”错误解读为“边界值”(如
matrix.getColumnDimension()-1)。 - 引入无效代码:调用不存在的
getColumnDimensionAPI,导致RAGGen覆盖率从72%降至60%。
- 误解测试意图:将“特定索引”错误解读为“边界值”(如
- 核心启示:需拆分多场景测试,并通过程序分析避免LLM幻觉,这是CLAST设计的核心依据。
三、核心方法(METHODOLOGY)
CLAST分为“测试净化”和“文本清晰度增强”两大模块,流程如下图(论文Fig.1):
3.1 测试净化:拆分复杂测试,提升逻辑清晰度
| 步骤 | 核心操作 | 目标 |
|---|---|---|
| 语句原子化 | 拆分复合语句(如int a,b;→int a; int b;),控制结构(if/for)视为整体 |
避免后续切片导致语法错误 |
| 测试原子化 | 1. 将多断言测试拆分为单断言测试;2. 构建变量依赖图,反向切片移除与断言无关的语句 | 每个测试聚焦单一场景 |
| 测试合并 | 合并前缀相同的单断言测试(如相同初始化步骤) | 减少冗余,保留场景完整性 |
术语定义:原子化语句S_a=(T, V_r, V_w, C),其中T为语句类型,V_r为读变量集,V_w为写变量集,C为控制结构标记。
3.2 文本清晰度增强:优化注释与标识符,避免LLM幻觉
- LLM提示生成:
- 采用one-shot ICL,提供高质量示例(注释按“Arrange-Act-Assert”模式,标识符贴合语义)。
- 示例:注释“// Act: Retrieve the column matrix at index 3”,标识符
matrixUnderTest替代m。
- 程序分析后处理(核心创新):
- 注释匹配:解析LLM生成代码的AST,提取注释;通过
similarity = type_match × CodeBLEU(阈值0.7)匹配原始代码语句,避免注释错位。 - 标识符替换:提取LLM生成的标识符映射,AST反向遍历替换(避免位置偏移错误),若存在重复则重新提示LLM。
- 注释匹配:解析LLM生成代码的AST,提取注释;通过
四、实验设计(EVALUATION DESIGN)
4.1 研究问题(RQ)
| RQ | 研究内容 |
|---|---|
| RQ1 | CLAST在精炼测试时,是否保留有效性并提升语义清晰度? |
| RQ2 | CLAST精炼的示例,能否提升ICL-based测试生成的效果? |
| RQ3 | CLAST的“测试净化”和“后处理”组件,分别有何贡献? |
4.2 实验对象
- 数据集:7个Java项目(4开源+3工业),详情如下:
类型 项目名称 特点 开源(Defects4J) Chart、Time、Lang、Math 广泛用于测试生成研究,JUnit框架 工业 PATool(程序分析工具)、Microservice(微服务)、DAService(数据分析) Java 17,无公开数据,防数据泄露 - 目标方法:
- RAGGen:用开发者编写的测试为示例;
- TELPA:用EvoSuite生成的测试为反例;
- LLM:CodeLlama-7b(CL-7B)、deepseekcoder-6.7b(DS-7B)。
- 基线:
- Base:无上下文示例;
- Origin:原始测试示例;
- UTgen:现有精炼技术示例。
4.3 评估指标
| 维度 | 指标 | 定义 |
|---|---|---|
| 测试有效性 | CSR(编译成功率) | 成功编译的测试占比 |
| PR(通过率) | 编译成功且执行通过的测试占比 | |
| Cov(行覆盖率) | 测试覆盖的代码行数占比 | |
| MS(变异分数) | 测试检测出的人工注入缺陷(变异体)占比 | |
| 语义清晰度 | 用户研究 | 15名参与者(10工业+5学术,平均6.8年经验),对“简洁性、描述性、注释质量”排名 |
五、实验结果与分析
5.1 RQ1:CLAST的精炼效果(对比UTgen/Origin)
1. 有效性保留(论文Table I):CLAST完全保留原始测试有效性,UTgen显著下降:
| 技术 | 开发者测试 - 平均变化(∆) | 工具生成测试 - 平均变化(∆) | ||||||
|---|---|---|---|---|---|---|---|---|
| CSR | PR | Cov | MS | CSR | PR | Cov | MS | |
| UTgen | -10.07% | -32.30% | -3.76% | -3.29% | -15.73% | -39.33% | -5.53% | -6.84% |
| CLAST | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
2. 语义清晰度(论文Fig.2):超85.33%用户偏好CLAST:
- 简洁性:90.00%参与者将CLAST列为第一;
- 描述性:85.33%参与者列为第一;
- 注释质量:90.67%参与者列为第一。
5.2 RQ2:CLAST对ICL测试生成的提升(论文Table II)
对比Base(无示例)、Origin(原始示例)、UTgen(精炼示例),CLAST效果最优:
- 核心提升(对比UTgen):
- 平均提升生成测试的CSR 25.97%、PR 28.22%、Cov 45.99%。
- 典型案例:
- RAGGen+CL-7B在Time项目:行覆盖率从UTgen的22.94%提升至63.41%;
- TELPA+DS-7B在Lang项目:通过率从UTgen的58.96%提升至79.10%。
- Origin的局限:虽比Base提升(如RAGGen+CL-7B覆盖率+29.03%),但因语义模糊,提升有限(如Math项目仅从49.41%→51.88%)。
5.3 RQ3:消融实验(组件贡献)(论文Table III、IV)
| 变体 | 核心缺失 | 有效性变化(平均) | 语义清晰度变化 |
|---|---|---|---|
| w/o purify(无净化) | 不拆分多场景测试 | 无下降(保留后处理) | 简洁性第一占比从90%→55% |
| w/o post(无后处理) | 不做AST匹配/CodeBLEU筛选 | CSR-12.46%、PR-13.65% | 无显著下降,但引入幻觉 |
| w/o both(两者都无) | 无净化+无后处理 | CSR-23.10%、PR-25.38% | 清晰度垫底 |
- 结论:测试净化负责提升语义清晰度,后处理负责避免LLM幻觉、保留有效性,两者缺一不可。
六、讨论(DISCUSSION)
- 用户反馈:90.67%参与者愿意将CLAST精炼的测试用于实际项目,33.3%参与者建议避免“过度文档化”(如冗余注释)。
- 效率优势:CLAST平均55.13秒/测试,UTgen需93.327秒(CLAST单轮LLM调用,UTgen迭代调用)。
- 泛化性验证:
- 集成到无ICL的HITS中:CLAST使行覆盖率从Origin的39.19%提升至41.90%(论文Table V);
- 大模型适配(DeepSeek-V3 610B):仍提升行覆盖率3.44%(论文Table VI);
- 跨语言潜力:替换AST工具(如tree-sitter支持JS/Python)、调整提示即可扩展。
七、结论与贡献
- 技术贡献:提出CLAST,结合程序分析与LLM,首次实现“语义清晰度提升+有效性完全保留”,公开复现包(https://github.com/chenyangyc/CLAST)。
- 方法贡献:从“上下文示例质量”视角优化ICL-based测试生成,为LLM代码生成的“数据质量优化”提供新思路。
- 实践贡献:多维度评估(7个项目、用户研究、消融实验)验证CLAST的实用价值,可用于测试生成、维护与调试。
4. 关键问题
问题1:CLAST相比UTgen,在解决“LLM-based单元测试生成依赖高质量示例”这一核心痛点上,有哪些不可替代的技术创新?
答案:核心创新体现在“双路径优化”,解决UTgen的固有缺陷:
- 逻辑清晰度优化(测试净化):UTgen未处理多场景混合问题,CLAST通过“语句原子化→测试原子化→测试合并”拆分复杂测试(如混合索引场景拆分为两个单场景),使LLM能准确理解测试意图,避免UTgen的“场景误解”(如将特定索引解读为边界值);
- 有效性保护(程序分析后处理):UTgen仅依赖LLM易产生幻觉,CLAST通过“AST节点匹配(type_match×CodeBLEU,阈值0.7)+标识符反向替换”筛选有效内容,确保精炼后测试无无效API(如UTgen的
getColumnDimension),完全保留原始测试的CSR、PR、Cov、MS(UTgen平均降CSR12.90%)。
问题2:实验中CLAST提升ICL-based单元测试生成效果的关键量化证据有哪些?这些证据能否支撑其在实际项目中的应用价值?
答案:1. 关键量化证据:
- 对比UTgen:在7个项目、2种ICL方法(RAGGen/TELPA)、2种LLM(CL-7B/DS-7B)中,CLAST使生成测试平均提升CSR 25.97%、PR 28.22%、Cov 45.99%,如RAGGen+CL-7B在Time项目Cov从22.94%→63.41%;
- 对比Origin:CLAST在RAGGen+DS-7B上平均提升Cov 21.27%,解决Origin因语义模糊导致的提升瓶颈(如Math项目仅从49.41%→51.88%);
- 泛化验证:集成到HITS(无ICL)后,Cov从39.19%→41.90%,适配大模型DeepSeek-V3 610B仍提升Cov 3.44%。
- 实际应用价值支撑:
- 有效性完全保留:避免测试失效导致的回归测试风险;
- 效率优势:55.13秒/测试(快于UTgen的93.327秒),支持并行执行;
- 用户认可:90.67%参与者愿用于实际项目,解决测试维护中的“理解成本”问题。
问题3:CLAST的“测试净化”和“程序分析后处理”组件分别如何影响其最终效果?若移除其中一个组件,会对测试精炼质量和ICL生成效果产生哪些具体影响?
答案:1. 组件作用机制:
- 测试净化:通过拆分多场景测试,降低LLM理解难度,核心影响“语义清晰度”——使LLM能生成更准确的注释/标识符(如将
m→matrixUnderTest); - 程序分析后处理:通过AST匹配和CodeBLEU筛选,过滤LLM生成的无效内容,核心影响“测试有效性”——避免幻觉导致的编译失败或功能错误。
- 移除组件的具体影响(基于消融实验):
- 移除“测试净化”(w/o purify):
- 语义清晰度下降:用户研究中“简洁性”第一占比从90%→55%;
- ICL生成效果:生成测试的Cov平均降低6.77%(LLM因场景混合无法学习有效模式);
- 移除“后处理”(w/o post):
- 测试有效性下降:CSR平均降低12.46%、PR降低13.65%(引入无效API如
getColumnDimension); - ICL生成效果:生成测试的CSR平均降低8.78%(示例失效导致LLM学习错误模式);
- 测试有效性下降:CSR平均降低12.46%、PR降低13.65%(引入无效API如
- 两者均移除(w/o both):效果最差,CSR降低23.10%,语义清晰度垫底,验证两组件的必要性。
- 移除“测试净化”(w/o purify):

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐

 12
12 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)