喜提CVPR顶会:域泛化研究为何如此受宠,这篇文章看完我学会了
和小图一起研究域泛化新突破
关注gongzhonghao【计算机sci论文精选】
域泛化旨在解决模型在数据分布偏移下的脆弱性——当训练域与测试域存在分布差异时,传统深度模型性能显著退化。这一挑战在医疗影像、自动驾驶等关键场景中尤为严峻:例如医疗肿瘤分割的误差可能因设备差异放大至生死攸关的0.5mm阈值,而自动驾驶系统在沙尘环境中的目标误报率激增37%。
今天小图为大家精选三篇域泛化方向的论文,快和小图一起研究CVPR域泛化新突破!
图灵学术论文辅导
标题:Leveraging Vision-Language Models for ImprovingDomain Generalization in Image Classification
方法:
文章首先分析了VLM中图像和文本嵌入的特性,发现文本嵌入对领域外泛化更为关键。基于此,提出VL2V-ADiP方法,分为三个阶段:对齐阶段,通过线性投影头将学生模型特征与VLM嵌入对齐;蒸馏阶段,利用VLM的图像和文本嵌入进一步优化学生模型特征;预测阶段,直接使用VLM文本嵌入作为分类器权重进行预测。
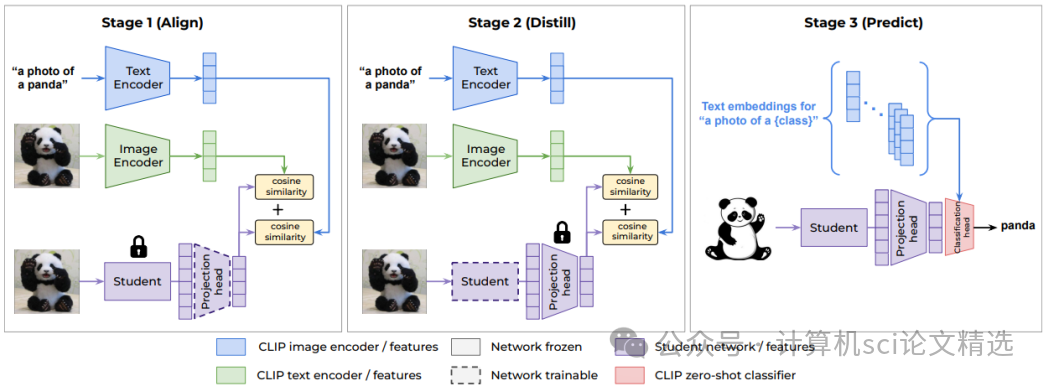
创新点:
-
首次提出将视觉和语言模态对齐后再进行知识蒸馏,有效结合了预训练学生模型的特征与VLM的图像编码器和文本嵌入,显著提升了学生模型的领域外泛化性能。
-
在黑盒设置下,创新性地通过输入输出访问来蒸馏VLM,不依赖于中间特征,拓展了知识蒸馏在多模态模型中的应用范围。
-
提出了自蒸馏方法VL2V-SD,能够将VLM文本编码器的泛化能力迁移到其图像编码器,为领域泛化提供了新的视角和有效途径。
论文链接:
https://arxiv.org/pdf/2310.08255
图灵学术论文辅导
标题:PracticalDG: Perturbation Distillation on Vision-Language Models for HybridDomain Generalization
方法:
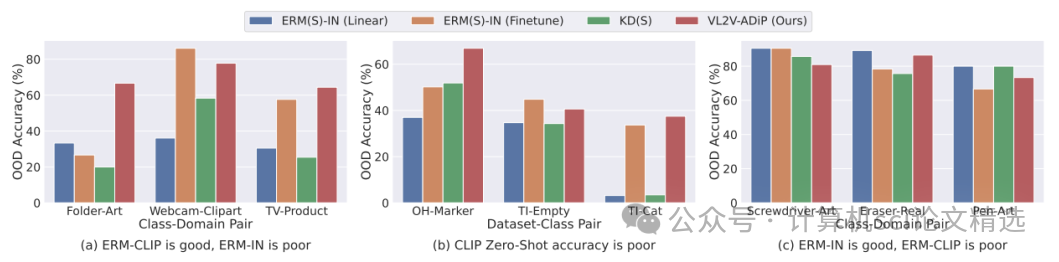
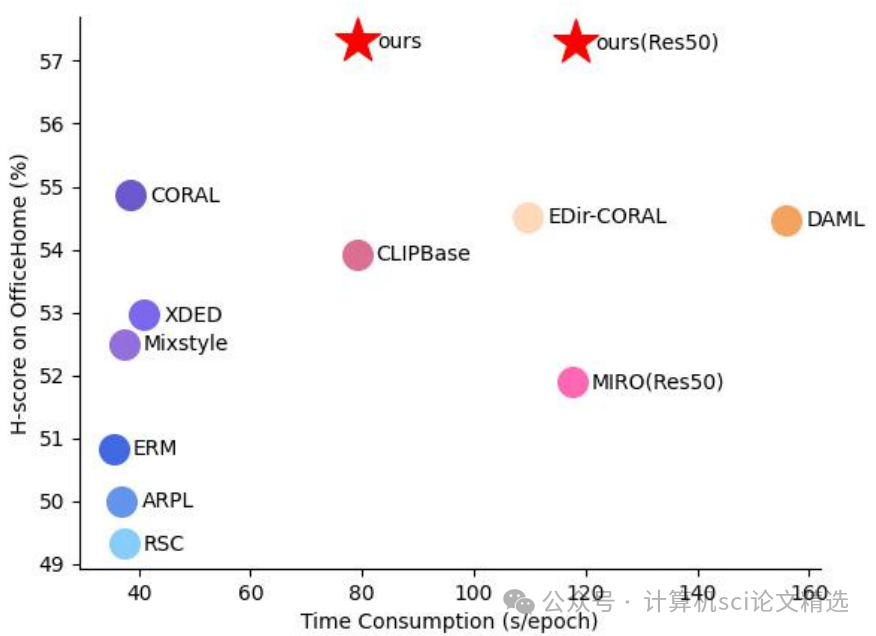
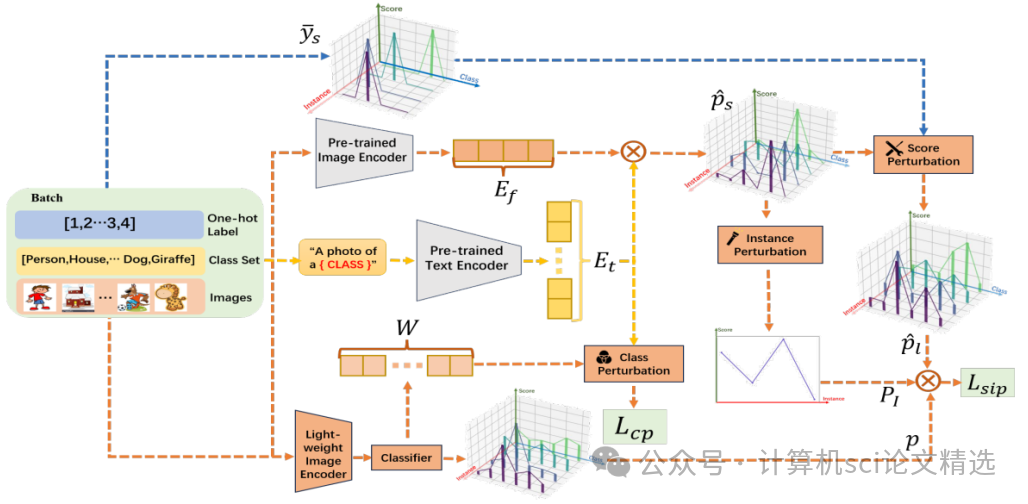
文章首先介绍了OSDG和CLIP模型的背景知识,然后详细描述了SCI-PD方法。该方法包括Score Perturbation, SP、Instance Perturbation, IP和Class Perturbation, CP三个部分。分数扰动通过将准确的GT标签信息融入CLIP的相似度分数中,平衡了语义信息和GT标签的噪声;实例扰动通过挖掘实例底层语义,利用权重分布来增强模型对不同实例的语义理解;类别扰动则将预训练文本嵌入的语义信息融入分类器的类别权重中,以增强模型的零样本学习能力。
创新点:
-
提出了一种新的混合领域泛化(HDG)任务,其源域的标签集不相同且多样化,同时提出了一个新的评估指标H2-CV,以全面评估模型的鲁棒性。
-
首次将VLM的知识蒸馏到轻量级视觉模型中,通过分数、类别和实例三个角度引入扰动(SCI-PD),有效提高了模型在OSDG任务上的性能。
-
通过实验验证了该方法在多个数据集上的有效性,尤其是在数据稀缺的情况下,展现出强大的鲁棒性。
论文链接:
https://arxiv.org/pdf/2404.09011
图灵学术论文辅导
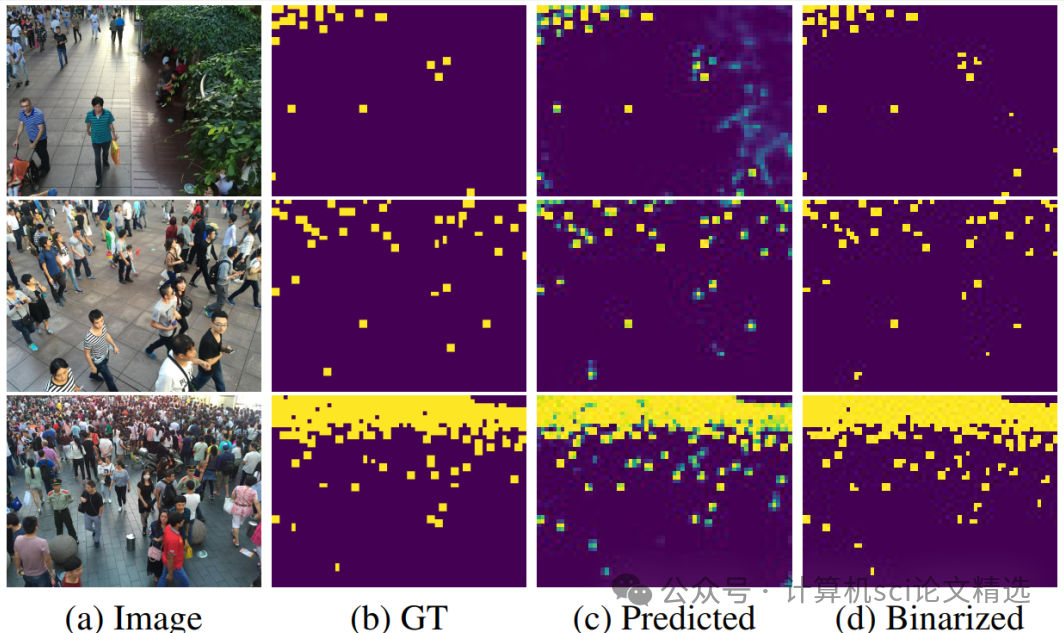
标题:Single Domain Generalization for Crowd Counting
方法:
文章通过将图像划分为网格,并采用块级分类作为辅助任务来减轻标签的模糊性。它利用注意力记忆库来存储多样化的密度值,并通过内容误差掩码和注意力一致性损失来重构领域不变特征。此外,MPCount还通过块级分类来过滤掉没有人类头部的区域,从而提高密度预测的准确性。

创新点:
-
提出了一种注意力记忆库,通过内容误差掩码和注意力一致性损失来重构领域不变特征,解决了密度回归问题。
-
引入了块级分类作为辅助任务,通过准确的块级二元标签来缓解像素级标签的模糊性,从而增强模型的鲁棒性。
-
在单领域泛化的背景下,首次提出了一种无需子域划分的SDG方法,即使在源域分布较窄的情况下也能有效工作。
论文链接:
https://arxiv.org/pdf/2403.09124
本文选自gongzhonghao【计算机sci论文精选】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)