【n8n纯手打教程】零基础一键批量生成微信公众号/小红书爆款文章(Github,Huggingface)【二】
本文介绍了利用n8n平台实现微信公众号/小红书文章自动生成的全流程。首先通过LLM模型生成格式化内容,提取标题和正文;然后使用Unsplash等API获取配图;最后整合图文内容并转换为HTML格式。教程详细展示了代码节点的配置方法,包括内容提取、图片获取、数据合并等关键步骤,并提供了完整的工作流程图解。该方案可实现从内容生成到排版发布的一键自动化操作,适用于AI热点等类型文章的批量生产。
【n8n纯手打教程】零基础一键批量生成微信公众号/小红书爆款文章(Github,Huggingface)【一】
上一次,我们已经实现了将实时的信息传给llm,进行总结报告并输出
接下来将进行处理llm输出的内容并进行并配图
配图
为了配图我们需要进行提取主要内容和标题,我们这里是提取标题,利用上一步llm生成的格式化回复“标题”生图
首先创建一个code节点
// 这段代码将处理所有传入的item,而不仅仅是第一个
// 使用 .map() 遍历上游节点传来的每一个 n8n Item 对象
const processedItems = $input.all().map(item => {
// 从当前正在遍历的 item 中提取 .json 数据
const jsonData = item.json;
// 为当前这个 item 初始化默认值
let title = "AI 最新热点";
let articleMarkdown = "无法解析文章内容。";
// 检查当前 item 的数据结构是否符合预期
if (jsonData && jsonData.content && jsonData.content.parts && jsonData.content.parts.length > 0 && jsonData.content.parts[0].text) {
// 提取真正的文本内容
const fullText = jsonData.content.parts[0].text;
// 匹配标题
const titleMatch = fullText.match(/\[TITLE\](.*?)\[\/TITLE\]/);
title = titleMatch ? titleMatch[1].trim() : "AI 最新热点";
// 移除标题标签,得到纯净的文章内容
articleMarkdown = fullText.replace(/\[TITLE\].*?\[\/TITLE\]\s*\n?/, '').trim();
}
// 对于每一个处理完的 item,我们返回一个新的对象。
// 这个对象必须符合n8n的Item格式,即把我们的结果包在 .json 属性里。
return {
json: {
title: title,
articleMarkdown: articleMarkdown
}
};
});
// 最后,返回这个包含了所有处理结果的新数组
return processedItems;
这样我们就得到了一个有title,articlemarkdown的json格式化输出
我们同样可以提取主要内容等,只需要在提示词中改变prompt即可
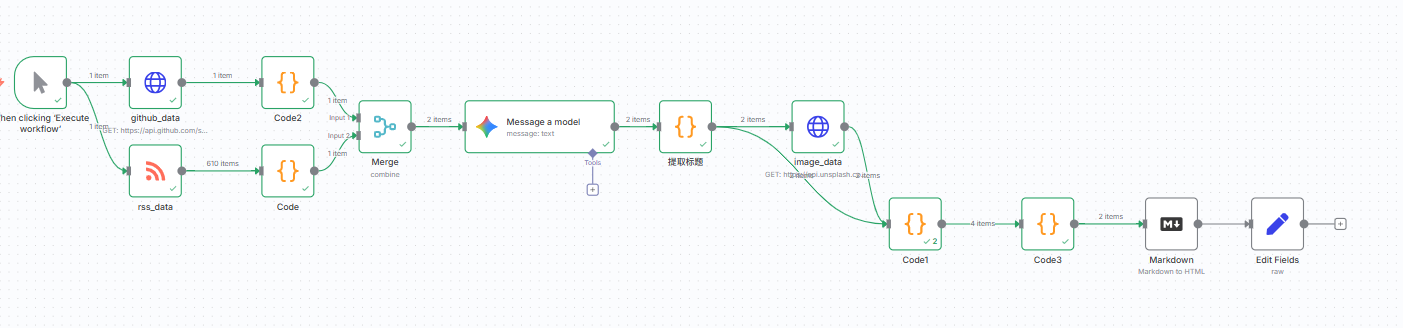
接下来,我们将提取到的标题,输出提取imagedata的请求当中
这里我们使用的是unsplash的这个读图网站,这里同样可以使用豆包等生图网站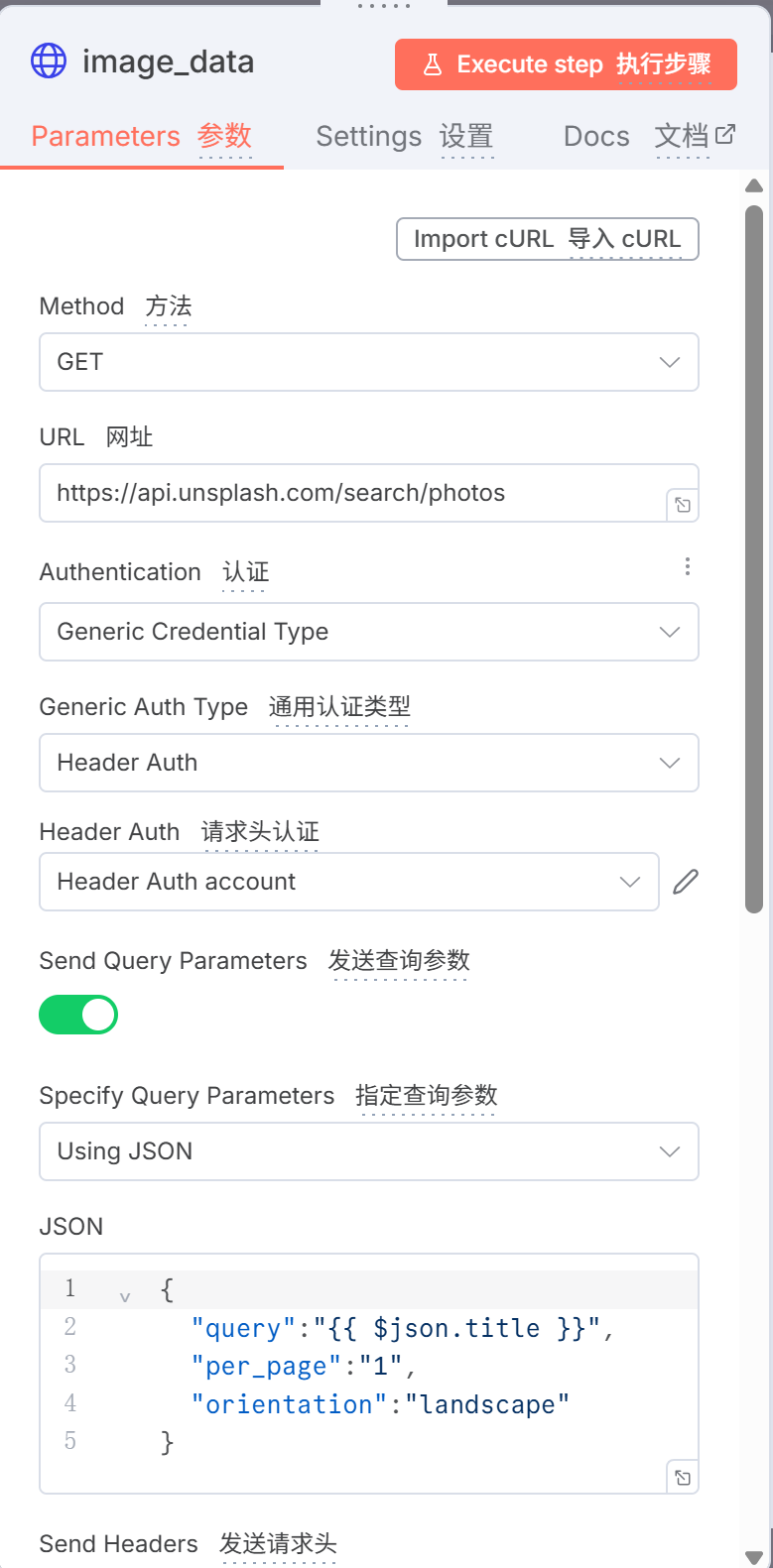
接下来进行流程的连图等操作
按照以下连图
整合
对于获取到的图片和整合的正文,我们将进行整合
创建code节点
// 这个简化版的代码,其唯一职责是:
// 将来自两个不同输入源的文章和图片数据,按顺序一一配对合并。
// 1. 从主输入获取所有文章数据项
// $input.all() 会获取连接到 Code 节点主输入(input 0)的所有数据项。
const articleItems = $input.all();
// 2. 从名为 'GetImages' 的节点获取所有图片数据项
// 这里的 'GetImages' 是你需要根据你的工作流设置的节点名称。
// 它代表了第二个输入源。
const imageItems = $('image_data').all();
// 3. 安全检查:确保文章和图片的数量能对上,防止工作流出错
if (imageItems.length !== articleItems.length) {
throw new Error(`数据不匹配!文章数量 (${articleItems.length}) 与图片数量 (${imageItems.length}) 不一致。`);
}
// 4. 使用 .map() 遍历所有文章,并与对应顺序的图片合并
const combinedItems = articleItems.map((articleItem, index) => {
// 从当前文章item中获取所需数据
const { title, articleMarkdown } = articleItem.json;
// 从对应顺序的图片item中获取数据
const imageData = imageItems[index].json;
let imageUrl = ''; // 设置一个默认的空图片链接
// 安全地从复杂的图片数据结构中提取出我们需要的URL
// 你的原始逻辑是正确的,这里保持不变。
if (imageData && imageData.results && imageData.results.length > 0 && imageData.results[0].urls && imageData.results[0].urls.regular) {
imageUrl = imageData.results[0].urls.regular;
} else {
// 添加一个警告,方便在 n8n 的执行日志中排查问题。
console.warn(`警告:文章 "${title}" (索引: ${index}) 未能找到对应的图片URL。`);
}
// 5. 返回一个符合 n8n 数据结构的新对象
// n8n 的 Code 节点期望返回一个对象数组,每个对象都有一个 `json` 属性。
return {
json: {
title: title,
articleMarkdown: articleMarkdown,
imageUrl: imageUrl
}
};
});
// 6. 将合并后的所有项目组成的数组作为最终输出
return combinedItems;
进行格式化返回之后,就是一个拥有标题,正文,图片的工作流程了
最后我们将正文提取,将markdown提取为html之后即可
搜索markdown组件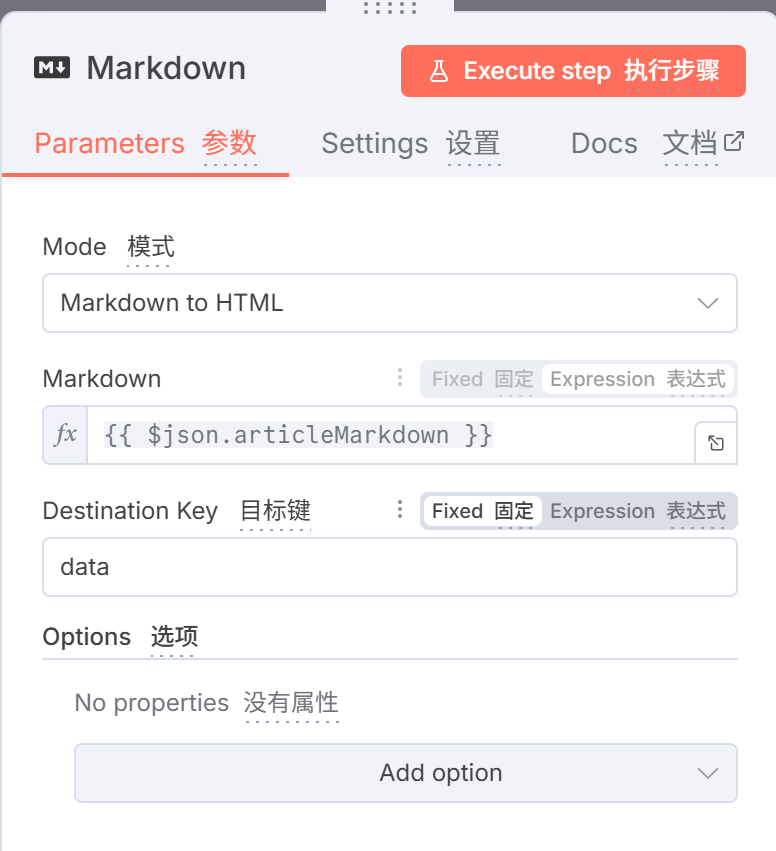
进行转义之后即可直接复制到微信公众粘贴

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)