【实战】使用 Unsloth 高效微调 Qwen2.5-7B 全流程指南
【实战】使用 Unsloth 高效微调 Qwen2.5-7B 全流程指南
在大模型(LLM)微调领域,显存焦虑和训练速度一直是两大痛点。如果你手头只有一张 Colab 免费送的 Tesla T4 (16GB) 或者家用的 RTX 30/40 系显卡,想微调像 Qwen2.5-7B 这样优秀的模型,通常会非常吃力。
今天我们要介绍的神器是 Unsloth。它通过重写 PyTorch 的底层计算内核,实现了:
- 🚀 训练速度提升 2-5 倍
- 📉 显存占用减少 70% (甚至更少)
- ✨ 精度无损
本文将手把手带你跑通 Qwen2.5-7B 的 LoRA 微调流程,从环境配置到导出 GGUF 模型,一气呵成。
🛠️ 微调流程概览
在开始代码之前,我们先通过一张图来理解整个微调流水线:
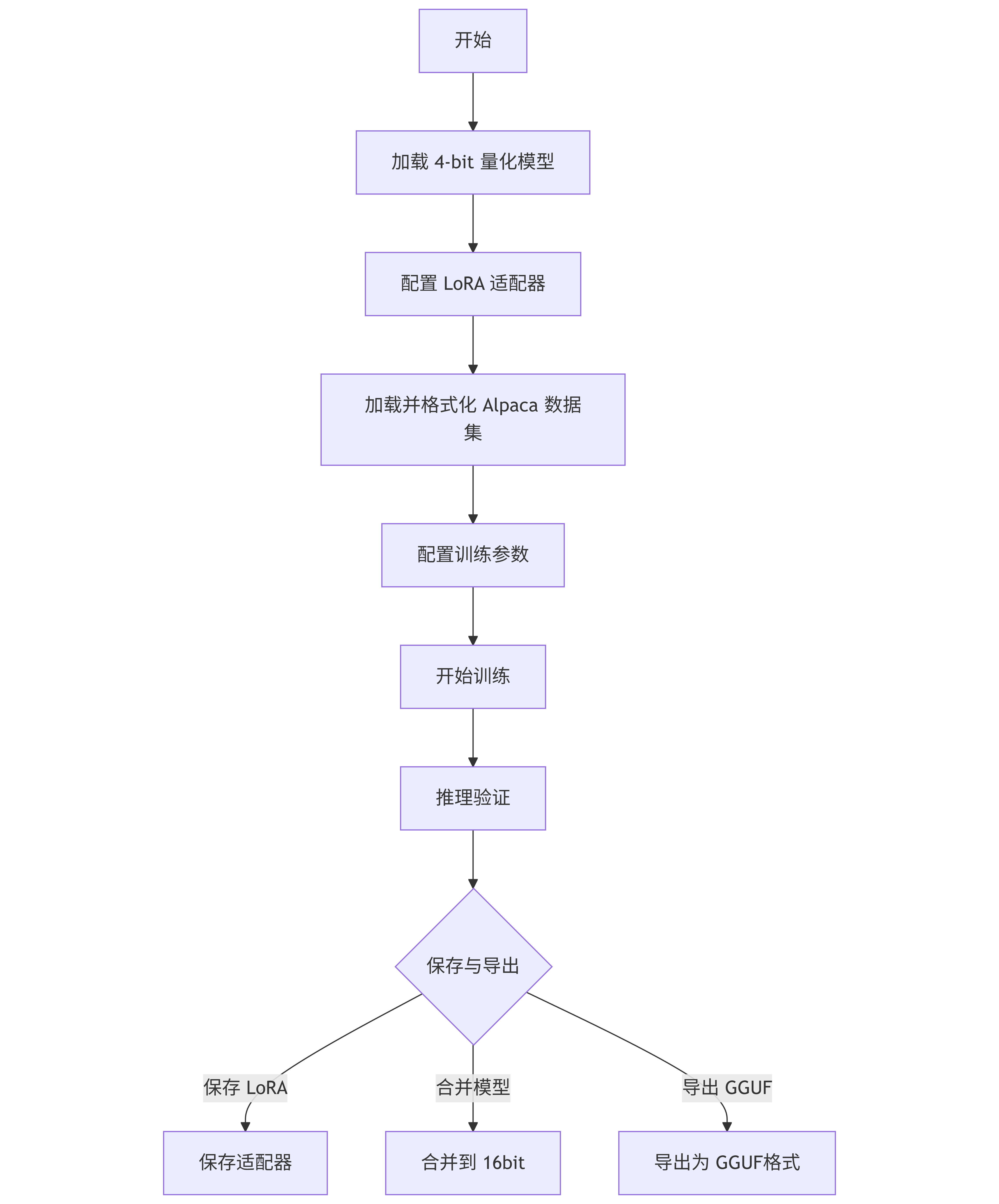
1. 环境设置与模型加载
首先,我们需要加载预训练模型。为了在有限的显存下运行,我们使用 load_in_4bit=True。Unsloth 对 Llama、Mistral、Qwen 等架构做了深度优化。
注意:如果你使用的是 Ampere 架构显卡(RTX 3090, A100 等),建议使用
bfloat16以获得更好的数值稳定性;如果是 Tesla T4,则使用float16。
from unsloth import FastLanguageModel
import torch
# --- 核心配置 ---
max_seq_length = 2048 # 支持自动 RoPE 缩放,长文本可设为 4096
dtype = None # None = 自动检测显卡支持的数据类型
load_in_4bit = True # 节省 4 倍显存的关键
# --- 加载模型 ---
model, tokenizer = FastLanguageModel.from_pretrained(
# 可以直接填 "unsloth/Qwen2.5-7B-Instruct" 自动下载
# 这里演示加载本地路径的情况
model_name = "/root/autodl-tmp/models/Qwen/Qwen2___5-7B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
2. 配置 LoRA (Low-Rank Adaptation)
LoRA 让我们不需要更新模型的全部参数,只训练极小一部分“适配器”。
Unsloth 的优势在于它默认支持所有线性层(q, k, v, o, gate, up, down),这比只微调 q, v 效果要好得多。同时,它特有的 use_gradient_checkpointing="unsloth" 技术能进一步通过计算换显存,非常适合长上下文训练。
model = FastLanguageModel.get_peft_model(
model,
r = 16, # LoRA 秩。建议 8, 16, 32。越大越聪明,但参数越多。
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16,
lora_dropout = 0, # 设为 0 以优化速度
bias = "none", # 设为 none 以优化速度
# [关键] Unsloth 特有的梯度检查点优化,节省 30% 显存
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
3. 数据集准备 (Alpaca 格式)
我们使用经典的 Alpaca 指令微调格式。一定要注意处理 EOS Token(结束符),否则模型在推理时会停不下来,一直胡言乱语。
from datasets import load_dataset
# 定义 Prompt 模板
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # 必须添加 EOS!
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# 填充模板并加上 EOS
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
# 加载数据集(可以是 HuggingFace ID 或本地路径)
dataset = load_dataset("/root/autodl-tmp/datasets/yahma/alpaca-cleaned", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
4. 训练参数配置
这里使用 HuggingFace 的 SFTTrainer。对于显存较小的显卡,技巧是:调小 batch_size,调大 gradient_accumulation_steps。
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # 设为 True 可大幅加速训练,但需要数据处理配合
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4, # 等效 batch_size = 2 * 4 = 8
warmup_steps = 5,
max_steps = 60, # 演示用。实际训练建议设为一个 Epoch 或更多
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit", # 8-bit 优化器省显存
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
5. 训练与显存监控
一切就绪,开始训练。我们还可以顺便看看显存的使用情况。
# 记录初始显存
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"显卡: {gpu_stats.name}. 总显存: {max_memory} GB")
# --- 开始训练 ---
trainer_stats = trainer.train()
# 打印显存消耗统计
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
print(f"训练峰值显存: {used_memory} GB")
print(f"LoRA 额外消耗: {used_memory_for_lora} GB")
6. 推理验证
Unsloth 不仅训练快,推理也快。使用 FastLanguageModel.for_inference(model) 可以启用原生 2 倍速推理引擎。
FastLanguageModel.for_inference(model) # 开启推理加速
inputs = tokenizer(
[
alpaca_prompt.format(
"Continue the fibonnaci sequence.", # Instruction
"1, 1, 2, 3, 5, 8", # Input
"", # Output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
# 流式输出(打字机效果)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
7. 模型保存与 GGUF 导出 (Killer Feature)
这是 Unsloth 最强大的功能之一。你可以选择:
- 只保存 LoRA 权重:文件极小 (~100MB),便于分享。
- 合并并导出为 GGUF:直接用于 Ollama 或 Llama.cpp 本地部署。
# 1. 保存 LoRA 适配器
model.save_pretrained("lora_model")
tokenizer.save_pretrained("lora_model")
# 2. (可选) 导出为 GGUF 格式,直接用于 Ollama
# quantization_method 可选: "f16", "q4_k_m"(推荐), "q8_0"
if False:
model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
# model.push_to_hub_gguf("hf/model", tokenizer, quantization_method = "q4_k_m", token = "")
# 3. (可选) 合并为 16bit 模型用于 vLLM 部署
if False:
model.save_pretrained_merged("model", tokenizer, save_method = "merged_16bit")
总结
通过 Unsloth,我们成功在单卡显存受限的环境下,高效完成了 Qwen2.5-7B 的微调。它的核心优势在于:
- 4-bit 量化加载大大降低了门槛。
- Unsloth 优化内核让训练速度不再龟速。
- GGUF 一键导出打通了从训练到端侧部署的最后一公里。
现在,你已经拥有了一个专属的微调大模型,快去试试吧!
完整代码:
#!/usr/bin/env python
# coding: utf-8
# ==========================================
# 1. 环境设置与模型加载
# ==========================================
from unsloth import FastLanguageModel
import torch
# --- 配置参数 ---
# 设置最大序列长度。Unsloth 支持自动 RoPE 缩放,这里设为 2048。
# 如果数据很长,可以设置为 4096 或 8192(显存占用会增加)。
max_seq_length = 2048
# 数据类型设置:
# None = 自动检测。
# 如果是 Tesla T4 (Colab 免费卡) -> 使用 Float16
# 如果是 Ampere 架构 (RTX 3090, A100, H100) -> 使用 Bfloat16 (数值稳定性更好)
dtype = None
# 开启 4-bit 量化加载。这是 Unsloth 省显存的核心,比 16-bit 节省 4 倍显存。
load_in_4bit = True
# --- 加载模型 ---
model, tokenizer = FastLanguageModel.from_pretrained(
# 模型路径或 HuggingFace ID。
# 如果你在 Colab 或本地,可以直接用 "unsloth/Qwen2.5-7B-Instruct"
# 下面的路径是原作者特定环境的路径,使用时请根据实际情况修改
model_name="/root/autodl-tmp/models/Qwen/Qwen2___5-7B-Instruct",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
)
# ==========================================
# 2. 配置 LoRA (Low-Rank Adaptation)
# ==========================================
# LoRA 技术允许我们冻结模型主体,只训练一小部分新增的参数(适配器),从而大幅降低显存需求。
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA 的秩 (Rank)。值越大模型越“聪明”,但参数越多、训练越慢。常用值:8, 16, 32, 64。
# 指定要应用 LoRA 的模块。Unsloth 默认支持所有线性层,这样效果最好。
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha=16, # LoRA 的缩放因子。通常设置为 r 的 1 倍或 2 倍。
lora_dropout=0, # 为了优化速度,Unsloth 建议设为 0。
bias="none", # 为了优化速度,Unsloth 建议不训练 bias。
# *** 关键优化 ***
# 使用 Unsloth 特有的梯度检查点技术。
# 对于长上下文训练,这能减少约 30% 的显存占用,虽然会轻微降低训练速度。
use_gradient_checkpointing="unsloth",
random_state=3407, # 设置随机种子,保证结果可复现。
use_rslora=False, # 是否使用 Rank-Stabilized LoRA(一种变体),通常 False 即可。
loftq_config=None, # LoftQ 初始化配置,这里不使用。
)
# ==========================================
# 3. 数据准备与格式化
# ==========================================
# 定义 Alpaca 风格的提示词模板。
# 这种格式有助于指导模型区分指令(Instruction)、输入(Input)和回答(Response)。
alpaca_prompt = """Below is an instruction that describes a task,
paired with an input that provides further context.
Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
# 获取模型的结束符 (EOS)。
# 非常重要!如果不加 EOS,模型生成完答案后不会停止,而是会继续胡言乱语。
EOS_TOKEN = tokenizer.eos_token
# 数据格式化函数:将数据集中的列映射到 prompt 模板中
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# 填入模板,并强制在末尾加上 EOS 符
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return {"text": texts, } # 返回处理后的文本列表
# 加载数据集
from datasets import load_dataset
# 这里加载的是本地路径的数据集,如果没有,可以改成 HuggingFace 的数据集 ID,例如 "yahma/alpaca-cleaned"
dataset = load_dataset("/root/autodl-tmp/datasets/yahma/alpaca-cleaned", split="train")
# 批量应用格式化函数处理数据
dataset = dataset.map(formatting_prompts_func, batched=True, )
# ==========================================
# 4. 训练参数配置
# ==========================================
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
training_args = TrainingArguments(
# 显存优化的关键:
per_device_train_batch_size=2, # 每张卡单次处理的样本数。显存小就设小(如 1 或 2)。
gradient_accumulation_steps=4, # 梯度累积。这里 2 * 4 = 等效 batch_size 为 8。
warmup_steps=5, # 预热步数,刚开始学习率从 0 慢慢升上来,避免破坏权重。
max_steps=60, # 总训练步数。为了演示设为 60,实际训练通常需要更多(如几百上千步)。
learning_rate=2e-4, # 学习率。LoRA 微调通常用 2e-4 或 1e-4。
# 自动选择精度
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=1, # 每走一步打印一次日志
optim="adamw_8bit", # 使用 8-bit AdamW 优化器,比标准 AdamW 稍微省一点显存。
weight_decay=0.01, # 权重衰减,防止过拟合。
lr_scheduler_type="linear", # 学习率下降策略。
seed=3407,
output_dir="outputs", # 模型检查点保存目录。
report_to="none", # 不上传到 WandB 等平台,仅本地打印。
)
# SFT (Supervised Fine-Tuning) 训练器
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text", # 指定数据集中包含完整 prompt 的列名
max_seq_length=max_seq_length,
dataset_num_proc=2, # 数据处理进程数
# Packing (序列打包):将多个短样本拼成一个长样本训练。
# 设为 True 可以让训练速度提升约 5 倍!这里设为 False 可能是为了演示简单性。
packing=False,
args=training_args,
)
# ==========================================
# 5. 训练前内存检查 (可选)
# ==========================================
# 这段代码用于打印当前 GPU 显存的使用情况,方便查看基准线。
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
# ==========================================
# 6. 开始训练
# ==========================================
trainer_stats = trainer.train()
# ==========================================
# 7. 训练后内存统计 (可选)
# ==========================================
# 计算训练过程中额外消耗了多少显存,以及总耗时。
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory / max_memory * 100, 3)
lora_percentage = round(used_memory_for_lora / max_memory * 100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime'] / 60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
# ==========================================
# 8. 推理测试
# ==========================================
# 开启推理模式。Unsloth 会重写 PyTorch 的推理内核,使推理速度提升 2 倍。
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
alpaca_prompt.format(
"Continue the fibonnaci sequence.", # 指令
"1, 1, 2, 3, 5, 8", # 输入
"", # 输出留空,让模型生成
)
], return_tensors="pt").to("cuda")
# 生成文本
outputs = model.generate(**inputs, max_new_tokens=64, use_cache=True)
# 解码输出结果
tokenizer.batch_decode(outputs)
# --- 使用流式输出 (打字机效果) ---
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
# max_new_tokens 控制生成长度
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128)
# ==========================================
# 9. 模型保存
# ==========================================
# 注意:这里保存的只是 "Adapter" (LoRA 权重,约 100MB),不是完整的 7B 模型。
model.save_pretrained("lora_model")
tokenizer.save_pretrained("lora_model")
# ==========================================
# 10. 加载已保存的 LoRA 模型进行验证
# ==========================================
if True:
from unsloth import FastLanguageModel
# 重新加载基础模型 + LoRA 权重
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="lora_model", # 这里指向刚才保存的目录
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
)
FastLanguageModel.for_inference(model)
# 再次测试推理
inputs = tokenizer(
[
alpaca_prompt.format(
"What is a famous tall tower in Paris?",
"",
"",
)
], return_tensors="pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128)
# ==========================================
# 11. (高级功能) 合并模型与 GGUF 导出
# ==========================================
# 这里的代码块默认为 False,需要手动开启。
# --- 保存为合并后的模型 (Merged Model) ---
# 将 LoRA 权重直接合并进基础模型,方便在 vLLM 等其他推理框架中使用。
if False:
# 保存为 16-bit 精度 (Float16)
model.save_pretrained_merged("model", tokenizer, save_method="merged_16bit")
# 或者上传到 Hugging Face
model.push_to_hub_merged("hf/model", tokenizer, save_method="merged_16bit", token="")
# 保存为 4-bit 精度 (如果你想得到一个体积很小的模型文件)
model.save_pretrained_merged("model", tokenizer, save_method="merged_4bit")
# --- 导出为 GGUF 格式 (用于 Ollama / llama.cpp) ---
# 这是 Unsloth 的杀手级功能,可以直接将微调后的模型转为 GGUF。
if False:
# 转换为 q8_0 (8-bit 量化,速度快,精度高,体积较大)
model.save_pretrained_gguf("model", tokenizer)
# 转换为 f16 (全精度,体积最大)
model.save_pretrained_gguf("model", tokenizer, quantization_method="f16")
# 转换为 q4_k_m (4-bit 量化,推荐值,体积小,效果在 8B 模型上不错)
model.save_pretrained_gguf("model", tokenizer, quantization_method="q4_k_m")
# 推送到 Hugging Face
model.push_to_hub_gguf("hf/model", tokenizer, quantization_method="q4_k_m", token="")

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)