大模型高效微调:LoRA及其变种全解析
LoRA是一种高效的大模型微调方法,通过低秩分解在原始模型旁增加可学习矩阵,显著降低显存需求并保持与全参数微调相近的效果。文章详细介绍了LoRA原理及其多种变种,如QLoRA(4bit加载)、LoRA+(不同学习率)、AdaLoRA(动态调整秩)、DoRA(分解大小和方向)等。这些方法在保持模型性能的同时,进一步优化了训练效率和资源消耗,成为大模型参数高效微调(PEFT)的重要研究方向,在工程界得
LoRA是一种高效的大模型微调方法,通过低秩分解在原始模型旁增加可学习矩阵,显著降低显存需求并保持与全参数微调相近的效果。文章详细介绍了LoRA原理及其多种变种,如QLoRA(4bit加载)、LoRA+(不同学习率)、AdaLoRA(动态调整秩)、DoRA(分解大小和方向)等。这些方法在保持模型性能的同时,进一步优化了训练效率和资源消耗,成为大模型参数高效微调(PEFT)的重要研究方向,在工程界得到广泛应用。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
原文:https://zhuanlan.zhihu.com/p/818782004
- 前言
=====
随着LLM的发展和应用,在LLM的预训练模型基础上做微调,使其适用于自己的业务场景的研究越来越多。与全参数SFT相比LoRA是在冻结LLM本身参数的基础上,在旁路增加两个可学习的矩阵,用于训练和学习,最后推理是LLM输出和可学习的矩阵的输出相加,得到最终的输出。它与全参数微调方法区别是:
资源上的差异:
- • 全参数微调:需要加载和更新全部LLM参数,需要更高的显存(需要的显存一般是单一参数的4倍),数据量上也需要更多的微调数据;
- • LoRA:只需要加载LLM参数,训练两个可学习的低秩矩阵,显存和数据量要求较低,训练速度也更快;
效果上差异:
- • 全参数微调:存在灾难性遗忘的风险,理论效果上限更高;
- • LoRA:和全参数微调效果差距不大,稳定性和扩展性更好;
- LoRA原理
=========
LoRA低秩适应微调,该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
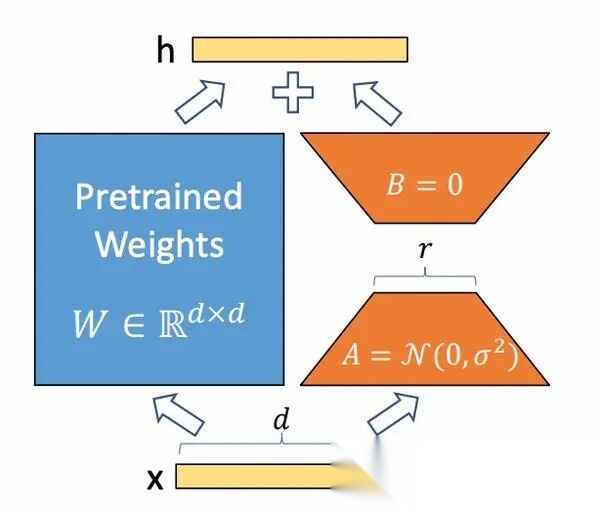
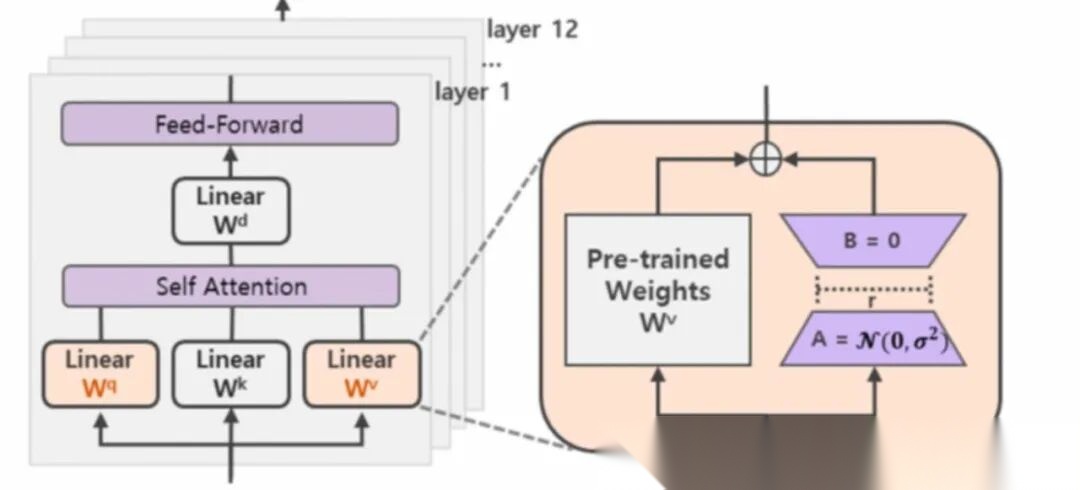
它的做法是:
1.在原始的Pretrain_LLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,合并作为输出,即在原始参数 、、 上增加AB矩阵(同一层QKV的AB矩阵参数共享,不同层不共享);
2.第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为(),从而来模拟所谓的本征秩(intrinsic rank)。
3.用随机高斯分布初始化,用 0 矩阵初始化,保证训练的开始此旁路矩阵依然是 0 矩阵;
- • 1.不将AB同时初始化为0,是为了保证训练可以顺利参数更新;
- • 2.不将AB同时高斯初始化,是为了让模型一开始AB矩阵不起作用,防止一开始 引入噪声;
- • 3.B高斯分布初始化,A用0初始化可以吗?目前看可以,如果不对请指正;
4.输出结果是两者相加:
- LoRA的变种
==========
QLoRA
与LoRA相比:LLM模型采用4bit加载,进一步降低训练需要显存。
QLoRA是进一步降低了微调需要的显存,QLoRA是将模型本身用4bit加载,训练时把数值反量化到bf16后进行训练,利用LoRA可以锁定原模型参数不参与训练,只训练少量LoRA参数的特性使得训练所需的显存大大减少。
LoRA+
与LoRA相比:AB矩阵采用不同的学习率;AB矩阵应用到全部参数矩阵。
LoRA+通过为矩阵A和B引入不同的学习率,更有效的训练LoRA适配器。LoRA在训练神经网络时,学习率是应用于所有权重矩阵(包括embeded和normalization层)。而LoRA+的作者可以证明,只有单一的学习率是次优的。将矩阵B的学习率设置为远高于矩阵A的学习率,可以使得训练更加高效。

t是放大因子,。
LoRA-FA
与LoRA相比:仅训练B矩阵。
LoRA-FA是LoRA与Frozen-A的缩写,在LoRA-FA中,矩阵A在初始化后被冻结,矩阵B是在用零初始化之后进行训练(就像在原始LoRA中一样)。这将参数数量减半,同时具有与普通LoRA相当的性能。
LoRA-drop
LoRA矩阵可以添加到神经网络的任何一层,LoRA-drop则引入了一种算法来决定哪些层由LoRA微调,哪些层不需要。
LoRA-drop步骤:
- • 1.对数据的一个子集进行采样,训练LoRA进行几次迭代;
- • 2.将每个LoRA适配器的重要性计算为BAx,其中A和B是LoRA矩阵,x是输入;
- • 3.如果这个输出很大,说明它会更剧烈地改变行为,如果它很小,这表明LoRA对冻结层的影响很小可以忽略;
- • 4.可以汇总重要性值,直到达到一个阈值(这是由一个超参数控制的),或者只取最重要的n个固定n的LoRA层;
- • 5.最后在整个数据集上进行完整的训练,其他层固定为一组共享参数,在训练期间不会再更改。
LoRA-drop算法允许只使用LoRA层的一个子集来训练模型。根据作者提出的证据表明,与训练所有的LoRA层相比,准确度只有微小的变化,但由于必须训练的参数数量较少,因此减少了计算时间。
AdaLoRA
在LoRA-drop中作者根据LoRA适配器的重要程度,选择部分不重要的LoRA不参与训练。而AdaLoRA作者则是根据重要程度,选择不同LoRA适配器调整秩的大小(原始LoRA所有层秩都一样)。另外AdaLoRA是根据LoRA矩阵的奇异值作为重要程度指标的。
AdaLoRA与相同秩的标准LoRA相比,两种方法总共有相同数量的参数,但这些参数的分布不同。在LoRA中,所有矩阵的秩都是相同的,而在AdaLoRA中,有的矩阵的秩高一些,有的矩阵的秩低一些,所以最终的参数总数是相同的。经过实验表明AdaLoRA比标准的LoRA方法产生更好的结果,这表明在模型的部分上有更好的可训练参数分布,这对给定的任务特别重要。
DoRA
通常认为LoRA等微调技术不如正常微调(Finetune)的原因是,LoRA被认为是对Finetune微调的一种低秩近似,通过增加Rank,LoRA可以达到类似Finetune的微调效果。但是作者发现LoRA的学习模式和FT很不一样,更偏向于强的正相关性,即方向和幅度呈很强的正相关,这可能对更精细的学习有害。
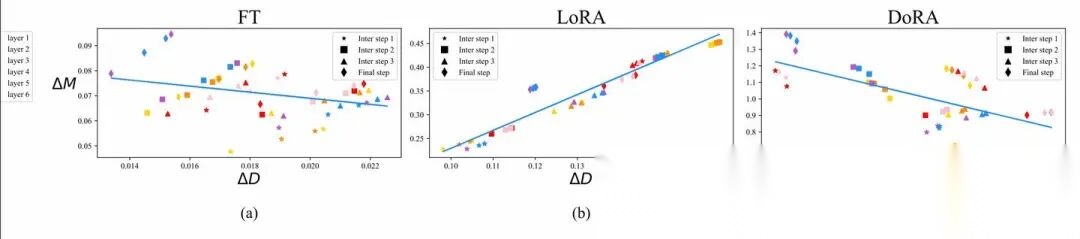
图中x轴是模型更新方向,y轴是幅度变化,图中的散点是每一层。可以看到FT的训练方式,更新的方向和幅度并没有太大关系(或者小的负相关),而LoRA存在较强的正相关性。
哪一种方向和幅度相关性更好?
这个不确定,但是LoRA的目的是利用较小参数达到和FT一致的效果,所以从相关性上应该LoRA的应该更像FT。所以作者将预训练参数矩阵进行分解,分解成包括大小(magnitude)和方向(directional)两个向量,只在方向上应用LoRA微调。
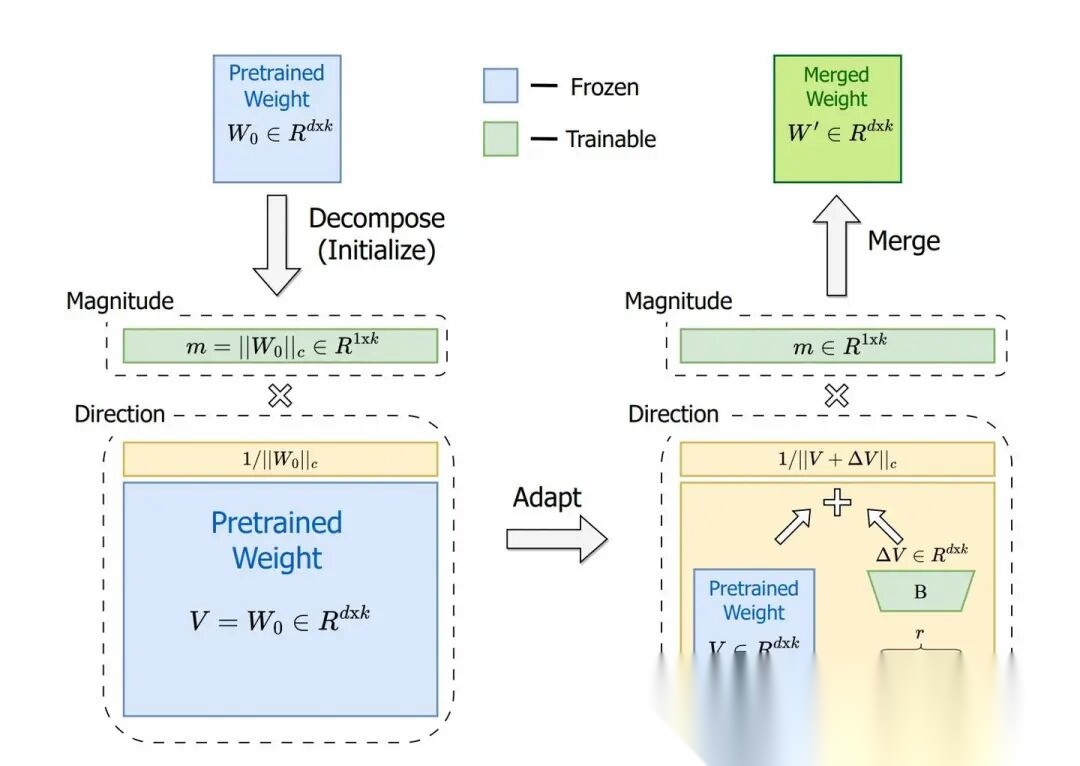
DoRA的作者通过将预训练矩阵W分解,得到大小为1 x d的大小向量m和方向矩阵V,从而独立训练大小和方向。然后方向矩阵V通过B* A增强(LoRA),然后m按原样训练。虽然LoRA倾向于同时改变幅度和方向(正如这两者之间高度正相关所表明的那样),DoRA可以更容易地将二者分开调整,或者用另一个的负变化来补偿一个的变化。所以可以DoRA的方向和大小之间的关系更像微调。代码如下
importoptimasfromutilsdataimportDataLoaderTensorDatasetimportimportnnasimportnnfunctionalasThisPyTorchLinearclassDoRALayerModule__init__4NoneNonesuper__init__ifNoneweightParameterFalseelseweightParameterTensorFalseifNonebiasParameterFalseelsebiasParameterTensorFalseMagnitudemParameterweightnorm20True1sqrttensorfloatlora_AParameterrandnlora_BParameterzerosforwardmatmullora_Alora_Bweightnorm20Truemreturnlinearbias
LongLoRA
LongLoRA 是港中文和 MIT 在 23 年发表的一篇 paper,主要是为了解决长上下文的注意力机制计算量很大的问题。
LLM支持长文本的方法,包括利用NTK等方式进行外推和内插(可参考:位置编码(下)[1],但为了让模型表现更好,一般还会进行微调。LongLoRA的要点:
- • 1.S2-attn注意力:这一点与LoRA无关,是为解决长序列注意力成二次方增加的问题,S2-attn在训练时不计算全局的注意力,而是将所有token分组,每个token只计算该组和相邻组的注意力,降低显存消耗,提升训练速度。(和longformer、Big Bird等处理长文本注意力方法没有太大区别,都是只算该token附近的注意力);
- • 2.LoRA训练(变种):在潜入层、归一化层也都加入了LoRA权重进行训练;
总结
LoRA系列大模型微调方法是大模型PEFT非常重要的一个研究方向,也是目前工程届应用最广法的微调方法之一,基于LoRA的改进的论文和方法还在不断更新。
引用链接
[1] 位置编码(下): https://zhuanlan.zhihu.com/p/720755157
如何学习AI大模型 ?
“最先掌握AI的人,将会晚掌握AI的人有竞争优势,晚掌握AI的人比完全不会AI的人竞争优势更大”。 在这个技术日新月异的时代,不会新技能或者说落后就要挨打。
老蓝我作为一名在一线互联网企业(保密不方便透露)工作十余年,指导过不少同行后辈。帮助很多人得到了学习和成长。
我是非常希望可以把知识和技术分享给大家,但苦于传播途径有限,很多互联网行业的朋友无法获得正确的籽料得到学习的提升,所以也是整理了一份AI大模型籽料包括:AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、落地项目实战等 免费分享出来。
- AI大模型学习路线图
- 100套AI大模型商业化落地方案
- 100集大模型视频教程
- 200本大模型PDF书籍
- LLM面试题合集
- AI产品经理资源合集

大模型学习路线
想要学习一门新技术,你最先应该开始看的就是学习路线图,而下方这张超详细的学习路线图,按照这个路线进行学习,学完成为一名大模型算法工程师,拿个20k、15薪那是轻轻松松!

视频教程
首先是建议零基础的小伙伴通过视频教程来学习,其中这里给大家分享一份与上面成长路线&学习计划相对应的视频教程。文末有整合包的领取方式

技术书籍籽料
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,这里也分享一份我学习期间整理的大模型入门书籍籽料。文末有整合包的领取方式

大模型实际应用报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。文末有整合包的领取方式

大模型落地应用案例PPT
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。文末有整合包的领取方式

大模型面试题&答案
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。文末有整合包的领取方式

领取方式
这份完整版的 AI大模型学习籽料我已经上传CSDN,需要的同学可以微⭐扫描下方CSDN官方认证二维码免费领取!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)