NeurIPS 2025 | 山大等提出VT-FSL:让LLM看图说话生成新样本,刷新10项SOTA
但这里有个痛点:模型补充的知识很可能是凭空“脑补”的,和实际给它的那几张图片对不上号,导致指导信息有噪声,效果自然大打折扣。这强制使得三种模态的表示在特征空间中高度对齐和一致,从而实现了全局和非线性的信息融合,远比简单的特征拼接或相加要鲁棒得多。让机器像人类一样,只看几张图片就能认识一个全新的事物,这是计算机视觉领域一个非常经典且富有挑战性的任务,我们称之为“小样本学习”(Few-Shot Lea
让机器像人类一样,只看几张图片就能认识一个全新的事物,这是计算机视觉领域一个非常经典且富有挑战性的任务,我们称之为“小样本学习”(Few-Shot Learning, FSL)。
过去的方法通常是想办法给模型补充一些额外的“知识”(语义信息),或者设计复杂的模块来融合这些知识。但这里有个痛点:模型补充的知识很可能是凭空“脑补”的,和实际给它的那几张图片对不上号,导致指导信息有噪声,效果自然大打折扣。
最近,一篇被 NeurIPS 2025 接收的论文 《VT-FSL: Bridging Vision and Text with LLMs for Few-Shot Learning》,为我们提供了一个非常优雅的解决方案。来自山东大学等机构的研究者们提出了一个名为 VT-FSL 的新框架,巧妙地利用大语言模型(LLM)来解决上述难题。
-
论文标题:VT-FSL: Bridging Vision and Text with LLMs for Few-Shot Learning
-
作者:Wenhao Li, Qiangchang Wang, Xianjing Meng, Zhibin Wu, Yilong Yin
-
机构:山东大学、深圳河套学院、山东财经大学
-
论文地址:https://arxiv.org/abs/2509.25033
-
代码仓库:https://github.com/peacelwh/VT-FSL
-
录用信息:NeurIPS 2025
VT-FSL的核心思想
VT-FSL的核心可以概括为两步:先让LLM“看图说话”生成精准的补充材料,再通过一种巧妙的几何方法将所有信息“三位一体”地对齐。

整个框架如上图所示,主要包含两大创新模块:
-
跨模态迭代提示(Cross-modal Iterative Prompting, CIP)
-
跨模态几何对齐(Cross-modal Geometric Alignment, CGA)
接下来,CV君带大家一步步拆解这两个模块的精妙之处。
第一步:让LLM“看图说话”,精准生成新样本
传统方法直接用类别名(比如“阿拉斯加雪橇犬”)去问LLM,得到的描述可能非常宽泛。而CIP的聪明之处在于,它不仅告诉LLM类别名称,还把那仅有的几张“小样本”图片一并“喂”给LLM看。

通过一个包含“策略、感知、提炼、结论”四个阶段的结构化推理过程,CIP引导LLM生成 根植于视觉证据的、非常精确的类别描述。这个描述不会天马行空,而是紧密围绕着给定的样本图像。如下图所示,生成的描述非常具体详细。
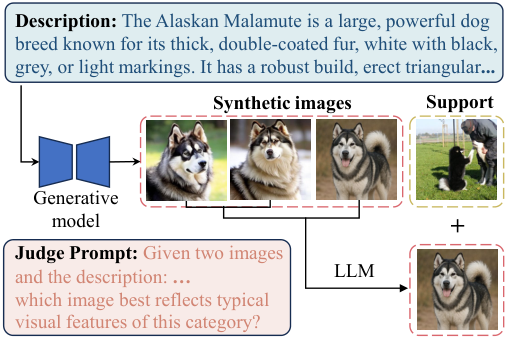
有了这样高质量的文本描述,能做什么呢?
-
生成文本提示:它本身就是对类别的高层语义补充。
-
生成视觉提示:更绝的是,研究者们利用这个描述,通过一个文本到图像的生成模型(如Stable Diffusion),零样本合成了更多 语义一致的新图像!
这样一来,原来只有几张样本的窘境被彻底打破了。凭空获得了高质量的文本知识和多样化的视觉样本,极大地丰富了对新类别的表示。
第二步:“三位一体”的几何对齐
现在我们手头有了三种信息:原始的 支持样本(Support)、LLM生成的 文本描述(Textual)、以及合成的 新图像(Synthetic)。如何将它们高效地融合起来呢?
这里就轮到第二个神器——跨模态几何对齐(CGA) 登场了。
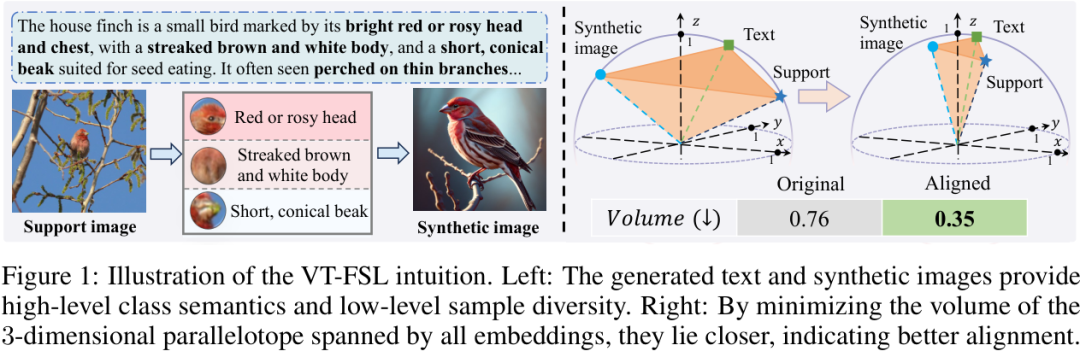
CGA的思路非常新颖。它将这三种信息的特征向量看作是三维空间中的三个点,这三个点可以构成一个平行六面体。CGA的目标,就是通过优化来 最小化这个平行六面体的体积。
从几何上直观理解,体积最小,就意味着这三个点在空间中被“挤”得更近,趋向于共线甚至共点。这强制使得三种模态的表示在特征空间中高度对齐和一致,从而实现了全局和非线性的信息融合,远比简单的特征拼接或相加要鲁棒得多。
刷新10项SOTA,效果斐然
理论上听起来很完美,那实际效果如何呢?VT-FSL在 10个不同的小样本学习基准 上都取得了新的SOTA(State-of-the-Art)成绩,涵盖了标准、跨域、细粒度等多种复杂场景。
以最经典的miniImageNet和tieredImageNet数据集为例,VT-FSL在1-shot和5-shot设置下均显著超越了以往的所有方法。

在细粒度分类任务上,VT-FSL同样表现出色,展现了其强大的特征分辨能力。
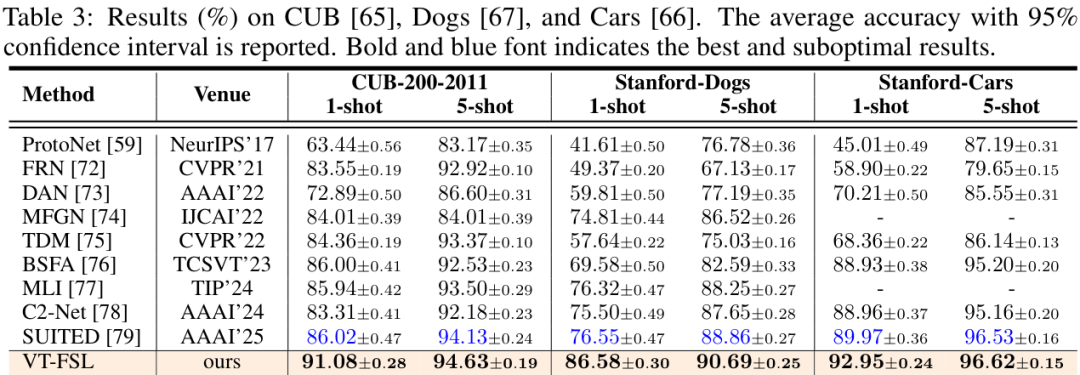
这些实打实的数据,充分证明了VT-FSL框架的有效性和泛化能力。
总而言之,VT-FSL通过“看图说话生成新样本”和“几何对齐融合特征”这两招,优雅地解决了小样本学习中的核心痛点。它不仅为我们展示了LLM在视觉任务中的巨大潜力,也为多模态学习领域提供了新的思路。作者已经开源了代码,CV君强烈推荐感兴趣的同学去深入研究一番。
你觉得这种利用LLM生成和对齐多模态特征的思路,还能用在哪些地方?欢迎在评论区聊聊!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)