一文搞懂大模型的预训练、微调和蒸馏
三者并非替代关系,而是互补 —— 预训练提供 “土壤”,微调播下 “种子”,蒸馏让 “果实” 可触及。理解它们的差异与协同,是掌握大模型技术的关键一步。
·
初学者常对大模型的预训练(Pre-training)、微调(Fine-tuning)和蒸馏(Distillation)感到困惑,三者虽均属模型训练,但目标、数据和实现方式差异显著。
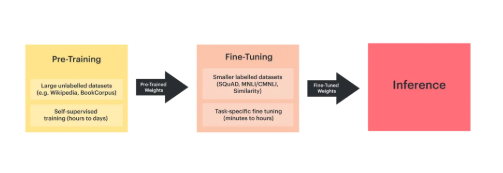
一、预训练(Pre-training):构建认知大厦的地基
核心定位:让模型成为 “知识百科全书”,掌握通用认知能力。
类比场景:相当于人类从小学到大学的基础教育阶段—— 学习语言、数学、科学等基础学科,不针对某一职业,但形成理解世界的底层逻辑。
技术特点:
- 目标:
- 挖掘数据中的通用规律(如语言语法、图像像素关联),让模型具备跨领域的基础理解能力。
- 例如:GPT-3 通过海量网文预训练,学会 “理解人类语言的逻辑”。
- 数据:
- 量大但粗糙:使用互联网公开的无标注 / 弱标注数据(如网页文本、公开图像库),数据规模通常以 TB 级计算。
- 特点:覆盖范围广,但质量参差不齐(含噪声数据)。
- 实现方式:
- 大规模无监督学习:通过自监督任务(如预测文本下一个词、图像掩码恢复)驱动模型学习。
- 暴力堆算力:依赖千亿级参数和超算集群训练,成本极高(如训练 GPT-4 消耗数千万美元算力)。
- 局限性:
- 缺乏专业技能:模型能 “理解” 但不会 “专精”(如能识别图像中的动物,但无法诊断医学影像)。
- 数据瓶颈:高质量公开数据接近耗尽,单纯扩大模型规模的效果边际递减。
二、微调(Fine-tuning):从通才到专才的蜕变
核心定位:让模型成为 “领域专家”,解决具体场景问题。
类比场景:大学毕业后的职业培训—— 如医生进入医院学习心内科专业知识,程序员学习特定领域代码规范。
技术特点:
- 目标:
- 将预训练的通用能力 “迁移” 到具体任务(如医疗诊断、法律文书生成),提升特定场景下的精度。
- 例如:用医疗文本微调 GPT-4,使其能生成符合规范的病历报告。
- 数据:
- 量小但精细:使用领域内的标注数据(如标注好的医疗影像、法律条文),数据规模通常为万级到百万级。
- 特点:专业性强,需符合行业标准(如医疗数据需遵循 HIPAA 隐私规范)。
- 实现方式:
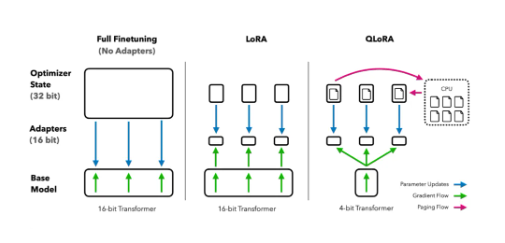
- 参数更新策略:
- 全量微调:更新模型所有参数(适合数据充足的场景,但计算成本高)。
- 轻量级微调:仅调整部分参数(如 Adapter、LoRA 技术),减少计算量(适合数据稀缺场景)。
- 监督学习主导:通过标注数据的输入 - 输出对(如 “症状描述→诊断结果”)训练模型。
- 参数更新策略:
- 应用价值:
- 打造垂直领域模型:如金融领域的智能客服、工业领域的故障预测模型。
- 成本平衡:无需重新训练大模型,只需在预训练基础上 “小修小补”。
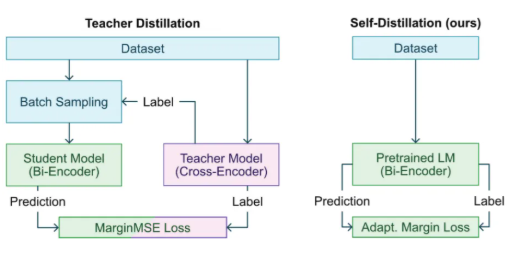
三、蒸馏(Knowledge Distillation):让知识 “轻装上阵”
核心定位:让大模型的知识 “平民化”,适配资源受限场景。
类比场景:资深专家将经验 “浓缩” 为手册 —— 新人无需从头摸索,通过学习手册快速掌握核心技能。
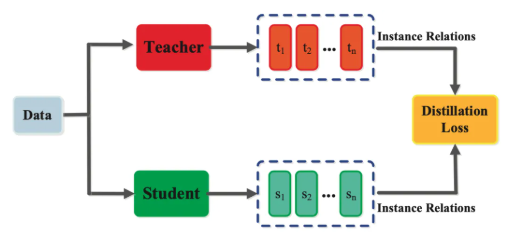
技术特点:
- 目标:
- 将大模型(教师模型)的 “隐性知识” 迁移到小模型(学生模型),实现模型轻量化。
- 例如:将 GPT-4 的推理逻辑压缩到一个参数仅 10 亿的模型,使其能在手机端运行。
- 数据:
- 教师模型的输出:非原始数据,而是教师模型对数据的 “理解”(如文本分类的概率分布、图像识别的中间特征)。
- 软标签价值:教师模型的 “模糊判断”(如 “该文本 70% 属于金融类、20% 属于科技类”)比硬标签(“金融类”)包含更多知识。
- 实现方式:
- 损失函数设计:同时优化学生模型对真实标签的预测(硬损失)和对教师输出的拟合(软损失)。
- 结构适配:学生模型可采用更简单的架构(如更小的 Transformer 层数),通过模仿教师模型的推理过程提升性能。
- 应用场景:
- 边缘设备部署:如智能音箱、自动驾驶车载系统(需低延迟、低功耗)。
- 隐私保护:在医疗等敏感领域,小模型可本地处理数据,避免上传大模型导致隐私泄露。
四、三者对比表:一图理清关键差异
| 维度 | 预训练 | 微调 | 蒸馏 |
|---|---|---|---|
| 核心目标 | 掌握通用认知能力 | 精通特定领域任务 | 压缩知识到轻量级模型 |
| 数据类型 | 海量无标注数据 | 领域标注数据 | 教师模型输出(软标签) |
| 模型规模 | 大(千亿级参数) | 与预训练模型相同 | 小(百万到亿级参数) |
| 典型场景 | 训练 GPT-4、LLaMA 等基础模型 | 医疗对话机器人、法律文书生成 | 手机端智能助手、车载 AI |
| 技术挑战 | 数据稀缺、算力成本高 | 领域数据获取难 | 知识迁移效率优化 |
五、总结:技术演进的 “分工协作”
- 预训练是 “基础设施”:为 AI 发展奠定通用能力基础,但面临数据和算力瓶颈。
- 微调是 “应用落地的桥梁”:让通用模型快速适配垂直场景,成为当前商业化的主流路径。
- 蒸馏是 “普惠工具”:让 AI 从 “云端” 走向 “终端”,解决实际部署中的资源限制问题。
三者并非替代关系,而是互补 —— 预训练提供 “土壤”,微调播下 “种子”,蒸馏让 “果实” 可触及。理解它们的差异与协同,是掌握大模型技术的关键一步。
扫码关注公众号“大模型星球”
关注并回复:977C
解锁更多大模型知识

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 32
32 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)