12 项技术让 RAG 不再困难 → RAG 流水线达到 99% 的准确率
文章的技术亮点在于介绍了12种提升RAG准确率的方法,如PageIndex和多向量检索,这些方法使得系统在复杂查询中表现更佳。适用场景包括需要处理复杂、多源信息的应用,如金融分析和法律咨询。
本篇文章RAG is Hard Until I Know these 12 Techniques → RAG Pipeline to 99% Accuracy适合想深入了解检索增强生成(RAG)系统的读者。文章的技术亮点在于介绍了12种提升RAG准确率的方法,如PageIndex和多向量检索,这些方法使得系统在复杂查询中表现更佳。适用场景包括需要处理复杂、多源信息的应用,如金融分析和法律咨询。
我曾以为魔法只存在于 LLM 中——我错了。
当我第一次开始构建**检索增强生成(RAG)**系统时,我坚信成功的关键仅仅是使用更大、更强大的 LLM。我以为一个更好的模型会解决我所有的问题。我错了。
经过数月的构建和迭代,我意识到 RAG 的真正魔力不在于模型本身。它在于如何智能地检索、排序和推理信息的艺术。

RAG 不再困难,直到我掌握了这些技术 → RAG 流水线达到 99% 的准确率
如今,我能够将我的 RAG 系统扩展到 98% 的准确率——这个水平我曾认为是不可能达到的。不同之处不在于模型;而在于我在此过程中学到的具体技术。我很高兴能分享那些彻底改变了我的一切方法。
- 个人见解: 为什么早期的 RAG 实现对我来说失败了。
- 启示: 真正的突破来自于智能地检索、排序和推理。
- 承诺: 最终,读者将理解那些将我的 RAG 流水线准确率提高到 99% 的确切技术。

记住艾德·史塔克(Eddard Stark)所说的话。
1. 为什么基础 RAG 会失败?
“大多数 RAG 系统在开始之前就已经崩溃了。”
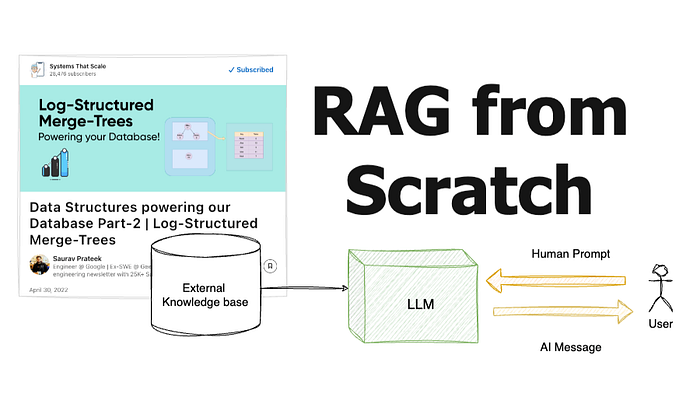
当我第一次开始构建 RAG 应用程序时,我遵循了大家都在谈论的经典流程:分块文档 → 嵌入它们 → 存储在向量数据库中 → 检索 top-k 相似分块。理论上,这听起来很可靠——但在实际使用中,这种方法往往会失败。
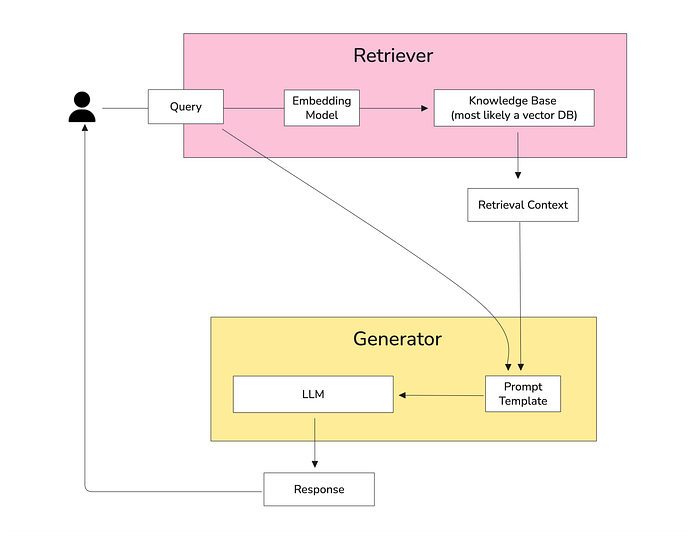
基础 RAG 架构
原因如下:
- 复杂查询需要多块推理: 当答案需要结合多个分块的信息时,简单的相似性搜索会遇到困难。
- 上下文跨越多个部分: 传统的分块破坏了文档的自然流程,导致模型丢失重要上下文。
- 需要澄清的模糊问题: 模糊或多部分的查询通常会检索到不相关的分块,让 LLM 难以猜测。
- 多源信息合成: 当答案需要连接不同文档或来源的事实时,基本的向量搜索无法有效处理关系。
真实案例: DoorDash、LinkedIn 和 Amazon 等公司已经意识到这些局限性,并远远超越了简单的向量相似性。他们实施了先进的检索策略,能够适应查询复杂性、文档结构和多源推理,从而使他们的 RAG 系统能够达到生产规模的性能。
这就是为什么理解超越基本检索的技术对于构建高准确率的 RAG 应用程序至关重要。
2. 高性能 RAG 的核心技术
“模型不是魔法——这些技术才是。”
当我第一次构建 RAG 系统时,我以为更大的 LLM 会解决所有问题。我错了。真正的区别来自于你如何检索、排序和组织你的知识。
让我们深入探讨那些将我的 RAG 流水线在 FinanceBench 上提升到 99% 准确率的技术。
高性能 RAG
2.1 PageIndex:类人文档导航
PageIndex 不再将文档视为孤立的分块,而是构建文档的分层树——就像人类快速浏览报告一样。
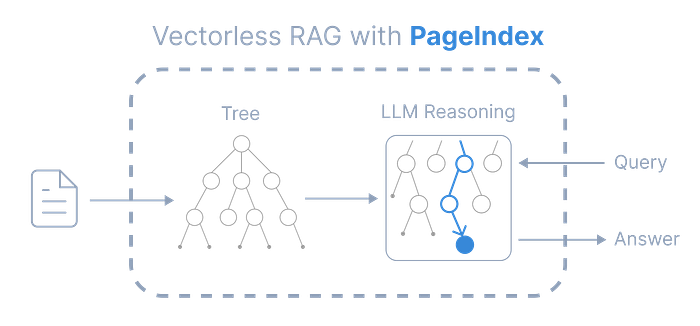
PageIndex,来源:https://github.com/VectifyAI/PageIndex
为什么它有效:
- LLM 可以对片段进行推理,而不是扫描不相关的分块。
- 没有人工分块 → 保留自然结构。
- 透明: 你可以追踪在推理过程中使用了哪些节点。
为什么要使用它?
它解决了**“分块”的根本问题。它不再检索不连贯的文本片段,而是允许 LLM 像人类一样导航和推理整个文档及其结构。这消除了幻觉,并通过提供完整的上下文将复杂数据集的准确性提高了 40% 以上**。
缺点:
- 高复杂性: 构建和维护分层树复杂且资源密集。
- 计算成本: 对树进行推理可能比简单的向量搜索慢。
事实: 在 FinanceBench 上,向量 RAG 的准确率约为 50%,而 PageIndex 达到了 98.7%。
from langchain.indexes import PageIndex
from langchain.llms import OpenAI
document_tree = PageIndex.from_documents(documents)
llm = OpenAI(temperature=0)
query = "What was the company's net profit trend in Q2?"
response = document_tree.query(query, llm=llm)
print(response)
2.2 多向量检索
不再为每个分块生成一个嵌入,而是生成表示不同方面的多个嵌入:摘要、关键词、潜在问题和全文。
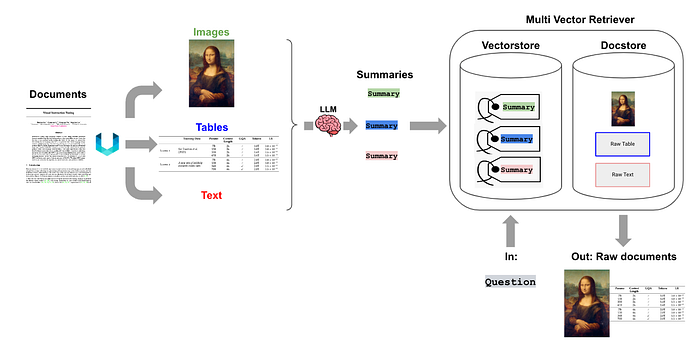
多向量检索,来源:https://blog.langchain.com/semi-structured-multi-modal-rag/
为什么它有效:
- 一个嵌入无法捕捉所有相关性角度。
- 多个嵌入允许以不同方式将内容与查询匹配。
为什么要使用它?
它克服了单一向量嵌入的**“单一视角”局限性**。通过捕捉文档的多个方面(例如,摘要、关键词、问题),它大大提高了成功和相关检索的机会,特别是对于复杂或多方面的查询。
缺点:
- 存储开销: 为每个分块存储多个嵌入会显著增加存储需求。
- 索引复杂性: 索引过程更复杂且耗时。
from langchain.vectorstores import FAISS
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = [
model.encode(chunk.text),
model.encode(chunk.summary),
model.encode(chunk.keywords)
]
faiss_index = FAISS.from_embeddings(embeddings)
2.3 元数据增强:上下文
元数据通过额外上下文丰富每个分块:来源、作者、创建日期、质量分数、相关实体。
优点:
- 提高检索精度。
- 帮助模型优先考虑可信来源。
为什么要使用它?
它添加了向量搜索本身无法捕捉的关键上下文。通过包含来源、日期和作者等信息,它有助于 LLM 做出更明智、更可信的决策,从而产生更高质量的答案和更好的引用召回率。
缺点:
- 人工工作: 手动添加元数据可能耗时且容易出错。
- 质量依赖: 检索的质量高度依赖于元数据的质量。
chunk = {
"text": "Company A reported a 10% increase in revenue.",
"source": "Quarterly Report 2025",
"author": "Finance Dept.",
"entities": ["Company A", "Revenue"],
"quality_score": 0.95
}
vectorstore.add_texts([chunk["text"]], metadatas=[chunk])
2.4 CAG(缓存增强生成)
CAG 通过将频繁访问的静态数据预加载到模型的键值缓存中,从而减少延迟。
- 适用于合规规则、产品手册或内部指南。
- 与 RAG 结合使用时:RAG 检索新信息,CAG 记住静态信息。
为什么要使用它?
它显著降低了频繁查询或静态信息的延迟和计算成本。通过将数据预加载到缓存中,它绕过了整个 RAG 流水线,为常见查询提供了即时、低成本的答案。
缺点:
- 可伸缩性限制: 缓存仅对高频、静态数据有效;对于动态或新信息则无用。
- 内存使用: 将数据预加载到 KV 缓存会消耗大量内存。
kv_cache = CAGCache()
kv_cache.preload(static_documents)
response = llm.generate(query, context=kv_cache)
事实: 使用 CAG 的公司报告称,高流量查询的响应时间加快了 50-70%。
2.5 上下文检索
该技术确保每个分块在嵌入之前都带有足够的上下文。受 Anthropic 研究的启发,它防止 LLM 误解孤立的分块。
def contextualize(chunk):
return f"In the 2022 finance report, {chunk['text']}"
embeddings = model.encode([contextualize(c) for c in chunks])
- 单独使用,检索准确率提高约 49%。
- 与重排序结合 → 高达 67% 的改进。
为什么要使用它?
它直接解决了由模糊或复杂查询引起的“检索失败”。通过添加简洁、模型生成的上下文,它引导搜索并确保在第一次尝试时检索到最相关的信息,从而提高效率和准确性。
缺点:
- 增加延迟: 在嵌入之前添加上下文的过程可能会引入少量延迟。
- 提示工程依赖: 有效性依赖于精心设计的提示以添加有用的上下文。
2.6 重排序 (Reranking)
“第一次检索还不够——你需要第二个意见。”
重排序添加了一个辅助模型来评估最初检索到的文档的相关性。这一步确保 LLM 只看到最符合上下文的分块,而不是盲目地信任向量相似性。
为什么要使用它?
它将检索结果的质量从“可能相关”提升到“高度相关”。简单的语义搜索通常会返回一堆相关文档,但重排序器会根据真实相关性对其进行排序,确保 LLM 只对最佳证据进行推理。
事实: 重排序可以将准确率比简单语义相似性提高多达 60%。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-MiniLM-L-6-v2")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ms-marco-MiniLM-L-6-v2")
def rerank(query, candidates):
inputs = tokenizer([query]*len(candidates), candidates, return_tensors='pt', padding=True)
scores = model(**inputs).logits.squeeze().detach().numpy()
ranked = [c for _, c in sorted(zip(scores, candidates), reverse=True)]
return ranked
top_candidates = rerank("Net profit trend Q2 2025", retrieved_docs)
缺点:
- 增加延迟: 运行第二个模型进行重排序会增加计算时间和检索过程的延迟。
- 成本: 使用更复杂的模型进行重排序会增加成本。
2.7 混合 RAG
“一种方法还不够——结合优势。”
混合 RAG 将基于向量的语义搜索与图遍历相结合,以处理:
- 语义相似性(向量搜索)。
- 实体关系和依赖性(图)。
为什么它很重要: 适用于多跳推理,其中答案需要连接文档中的事实。
为什么要使用它?
它结合了两种不同检索方法的优势。向量搜索擅长查找语义相似的信息,而图遍历非常适合多跳推理和连接实体。这使得系统能够有效地处理简单和复杂、相互关联的数据查询。
vector_candidates = vectorstore.similarity_search(query)
graph_candidates = knowledge_graph.query_related_entities(query)
hybrid_candidates = rerank(query, vector_candidates + graph_candidates)
缺点:
- 集成复杂性: 将向量搜索与图遍历系统结合在技术上具有挑战性,难以构建和维护。
- 高开销: 需要管理两种不同的搜索方法,增加了基础设施和维护成本。
2.8 自我推理
“让你的 LLM 成为一个积极的质量检查员。”
LLM 不再盲目信任检索到的分块,而是分多个阶段评估自己的输入:
- RAP(相关性感知过程): 评估检索质量。
- EAP(证据感知过程): 选择带有理由的关键句子。
- TAP(轨迹分析过程): 将推理路径综合为最终答案。
为什么要使用它?
它将 RAG 系统从一个被动检索器转变为一个主动、智能的代理。通过让 LLM 自己评估检索到的分块,它能够纠正自己的错误,完善搜索,并显著减少幻觉并提高引用准确性。
事实: 自我推理的准确率达到 83.9%,而标准 RAG 为 72.1%,并提高了引用召回率。
缺点:
- 执行缓慢: 多阶段推理过程计算成本高且缓慢。
- LLM 可靠性: 性能高度依赖于 LLM 的推理能力,而这并非总是可靠的。
for chunk in retrieved_chunks:
relevance_score = llm.evaluate_relevance(chunk, query)
if relevance_score > 0.7:
evidence_chunks.append(chunk)
answer = llm.synthesize_answer(evidence_chunks)
2.9 迭代 / 自适应 RAG
“并非所有查询都相同——区别对待。”
自适应 RAG 根据复杂性路由查询:
- 简单事实查询 → 单步检索。
- 复杂分析查询 → 多步迭代检索。
为什么要使用它?
它创建了一个更高效、响应更快的系统。它不再采用一刀切的方法,而是将检索策略与查询的复杂性相匹配,为简单问题节省时间和资源,同时确保复杂问题的彻底性。
缺点:
- 路由复杂性: 根据复杂性路由查询的逻辑难以实现和微调。
- 开发时间增加: 构建具有不同检索路径的系统会增加大量的开发和测试工作。
优点: 优化准确性和成本,将计算集中在需要的地方。
complexity = query_classifier.predict(query)
if complexity == "simple":
answer = simple_retrieve(query)
else:
answer = iterative_retrieve(query)
2.10 图 RAG
“将文档转化为知识网络。”
图 RAG 从文档中构建知识图谱,连接实体、概念和事实:
- 支持多跳推理。
- 减少幻觉。
- 示例集成:MongoDB + LangChain
为什么要使用它?
它为多跳推理和知识密集型任务提供了强大的解决方案。通过创建结构化的知识图谱,它允许 LLM 遵循实体之间的关系,从而为复杂、相互关联的查询提供高度准确且无幻觉的答案。
缺点:
- 图构建开销: 从非结构化文本创建和维护知识图谱是一项复杂且耗时的任务。
- 可伸缩性问题: 将图和图遍历扩展到大量文档可能具有挑战性。
from langchain.graphs import KnowledgeGraph
kg = KnowledgeGraph()
kg.add_entities_from_documents(documents)
kg.add_edges_from_relationships(relationships)
related_entities = kg.query_entities("Company A", depth=2)
2.11 查询重写
“不要让你的系统猜测——先澄清意图。”
- 将模糊或结构不良的查询转换为可检索的格式。
- 将复杂问题分解为子查询。
- 添加领域特定上下文以提高精度。
为什么要使用它?
它通过使系统对模糊或表述不佳的问题更具鲁棒性,直接改善了用户体验。通过自动澄清或分解查询,它确保即使用户的初始提示不完美,搜索也能成功。
缺点:
- 潜在错误: LLM 的重写过程可能会误解用户的意图,导致不正确的结果。
- 增加延迟: 在搜索之前重写查询会增加额外的步骤和延迟。
def rewrite_query(raw_query):
return f"In the 2025 finance report, {raw_query}"
clean_query = rewrite_query("Net profit Q2")
2.12 BM25 集成
“将语义智能与精确匹配相结合。”
BM25 集成将语义向量搜索与基于关键词的排序融合:
- 并行运行两种搜索。
- 使用加权评分合并结果。
- 应用重排序以选择最相关的候选。
为什么要使用它?
它为语义搜索添加了关键的词汇精度层。通过包含关键词匹配,它确保系统能够找到纯语义搜索可能遗漏的精确术语、名称或代码,从而创建更全面、更准确的结果。
缺点:
- 参数调优: 权衡向量和关键词搜索结果需要仔细和复杂的调优。
- 有限的语义理解: 单独的 BM25 缺乏语义理解,如果平衡不当,可能会影响整体结果的质量。
from rank_bm25 import BM25Okapi
bm25 = BM25Okapi([doc.split() for doc in docs])
bm25_scores = bm25.get_scores(query.split())
final_scores = 0.6 * vector_scores + 0.4 * bm25_scores
ranked_docs = [doc for _, doc in sorted(zip(final_scores, docs), reverse=True)]
这些高级技术构成了高准确率、生产级 RAG 系统的骨干。当我系统地应用它们时,我的流水线从基本的约 50-60% 准确率提升到 FinanceBench 上的 99%,具有更快、更像人类的检索和最小的幻觉。
3. 实施策略:分阶段
“没有系统的计划,技术就毫无用处。”
我们讨论的所有 RAG 技术都很强大——但如果没有结构化的实施策略,即使是最好的方法也无法提供一致的结果。以下是我成功应用并适用于大多数 RAG 系统的分阶段方法:
3.1 阶段 1:基础
目标: 为你的检索系统建立坚实的基础。
- 文档预处理: 清理、标准化和结构化你的文档(去除噪音、处理表格、如果需要进行 HTML 解析)。
- 上下文分块: 避免任意分割;保留语义边界,使每个分块保留有意义的上下文。
构建良好的知识库 [VectorDB]
def preprocess_document(doc):
clean_text = clean_html(doc)
return split_into_semantic_chunks(clean_text)
chunks = [preprocess_document(d) for d in documents]
影响: 适当的基础通常能带来检索准确率最大的初始收益。
3.2 阶段 2:检索增强
目标: 提高模型所见文档的相关性。
- 重排序: 添加一个辅助模型以优先处理最符合上下文的分块。
- BM25 集成: 将语义向量搜索与精确关键词匹配相结合,以捕捉精确术语。
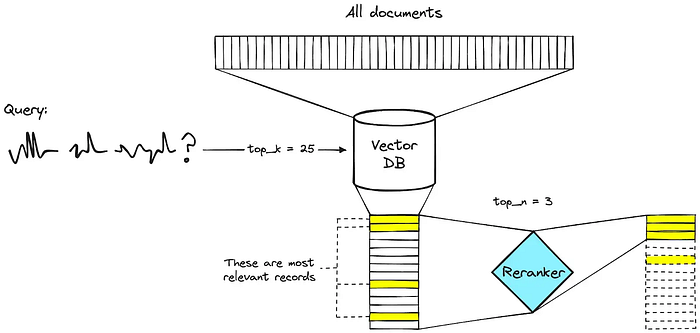
检索增强
示例:
final_scores = 0.6 * vector_scores + 0.4 * bm25_scores
ranked_docs = [doc for _, doc in sorted(zip(final_scores, docs), reverse=True)]
影响: 提高了检索精度,减少了进入 LLM 的不相关信息。
3.3 阶段 3:智能层
目标: 使你的系统具有查询感知和自适应能力。
- 查询重写: 在检索之前澄清用户意图,以减少歧义。
- 自适应路由 / 迭代 RAG: 根据复杂性路由查询;简单查询获得快速单步答案,复杂查询获得多步推理。
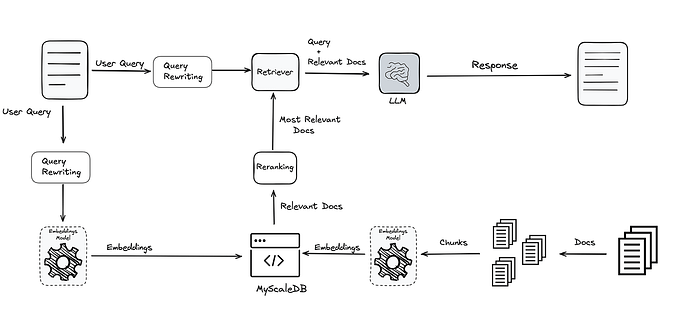
RAG 和基于 LLM 架构中的智能层
if query_classifier.predict(query) == "complex":
answer = iterative_retrieve(query)
else:
answer = simple_retrieve(query)
影响: 优化准确性和延迟,将资源集中在最需要的地方。
3.4 阶段 4:高级技术
目标: 有效处理复杂、多跳或关联数据。
- 图 RAG: 捕捉文档中实体和概念之间的关系。
- 自我推理: 让 LLM 评估分块相关性并综合推理路径。
- 多向量检索: 为不同方面(摘要、关键词、问题)使用每个分块的多个嵌入。
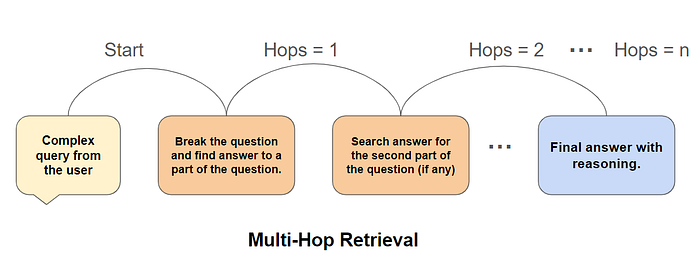
多跳和处理复杂查询
示例:
related_entities = knowledge_graph.query_entities("Company A", depth=2)
evidence_chunks = [c for c in retrieved_chunks if llm.evaluate_relevance(c, query) > 0.7]
answer = llm.synthesize_answer(evidence_chunks)
影响: 最大化生产级 RAG 系统的准确性、上下文感知度和可靠性。
实施 RAG 不仅仅是选择技术——它关乎战略性地分层。通过遵循这种分阶段计划,你可以确保每种技术都增强前一种技术的有效性,从而实现高准确率、可扩展的 RAG 流水线。
4. 衡量成功:正确的指标
“如果你无法衡量它,你就无法改进它。”
实施高性能 RAG 系统只是成功的一半。另一半是衡量它实际工作的效果。如果没有正确的指标,你将不知道哪些技术有帮助,哪些没有。
以下是评估 RAG 系统的关键指标:
4.1 忠实度
定义: 衡量模型响应与检索到的上下文的一致程度。
- 确保答案没有幻觉事实。
- 对于金融、医疗或法律等准确性不容妥协的领域至关重要。
概念示例:
f a i t h f u l n e s s _ s c o r e = l l m _ j u d g e . e v a l u a t e _ f a i t h f u l n e s s ( r e s p o n s e , r e t r i e v e d _ c h u n k s ) faithfulness\_score = llm\_judge.evaluate\_faithfulness(response, retrieved\_chunks) faithfulness_score=llm_judge.evaluate_faithfulness(response,retrieved_chunks)
4.2 答案相关性
定义: 响应是否真正回答了用户的查询?
- 高检索准确率并不能保证 LLM 产生相关答案。
- 由自动化评估器和人工审阅者共同评估。
示例:
r e l e v a n c e _ s c o r e = l l m _ j u d g e . e v a l u a t e _ r e l e v a n c e ( r e s p o n s e , q u e r y ) relevance\_score = llm\_judge.evaluate\_relevance(response, query) relevance_score=llm_judge.evaluate_relevance(response,query)
4.3 上下文精度与召回率
上下文精度: 最相关的文档是否排在前面?
上下文召回率: 是否检索到所有相关文档?
- 精度确保 LLM 首先看到高质量的上下文。
- 召回率确保没有遗漏任何重要信息,特别是对于多跳或关联查询。
概念示例:
p r e c i s i o n = c o m p u t e _ p r e c i s i o n ( r e t r i e v e d _ d o c s , g r o u n d _ t r u t h _ d o c s ) precision = compute\_precision(retrieved\_docs, ground\_truth\_docs) precision=compute_precision(retrieved_docs,ground_truth_docs)
r e c a l l = c o m p u t e _ r e c a l l ( r e t r i e v e d _ d o c s , g r o u n d _ t r u t h _ d o c s ) recall = compute\_recall(retrieved\_docs, ground\_truth\_docs) recall=compute_recall(retrieved_docs,ground_truth_docs)
4.4 持续评估:LLM 作为评估者 + 人工验证
现代生产 RAG 系统通常使用 LLM 作为评估者框架来大规模自动评估指标:
- 评估者根据忠实度、相关性和格式合规性对输出进行评分。
- 人工审阅者验证样本,以确保与专家判断一致。
a l i g n m e n t _ r a t e = l l m _ j u d g e . c a l c u l a t e _ h u m a n _ a l i g n m e n t ( s a m p l e _ r e s p o n s e s , h u m a n _ l a b e l s ) alignment\_rate = llm\_judge.calculate\_human\_alignment(sample\_responses, human\_labels) alignment_rate=llm_judge.calculate_human_alignment(sample_responses,human_labels)
事实: LLM 评估者与人工审阅者85% 的时间保持一致,通常超过人工评分者之间的一致性(81%)。
系统地使用这些指标可确保你的 RAG 系统不仅仅是“工作”——它准确、可靠且持续改进。
5. 其他高级技术
“一旦你掌握了基础知识,这些高级技术将把你的 RAG 系统提升到一个新的水平。”
即使拥有坚实的基础和分阶段实施,高性能 RAG 系统仍受益于专门的优化和高级方法。以下是一些帮助我将准确性和可伸缩性推向生产级水平的技术:
5.1 嵌入模型优化
定义: 使用领域特定嵌入而非通用嵌入,以更好地捕捉数据中的细微差别。
- 通用嵌入通常会遗漏领域术语、缩写或结构化内容。
- 切换到在金融、医疗或法律数据上训练的嵌入可以显著提高检索准确率。
示例:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("bge-base-en-v1.5")
embeddings = model.encode(documents)
5.2 延迟分块
定义: 首先为整个文档生成嵌入,然后将其分块。
- 保留每个分块中的完整上下文。
- 对于传统分块会破坏上下文的长文档特别有用。
概念示例:
f u l l _ e m b e d d i n g = m o d e l . e n c o d e ( f u l l _ d o c u m e n t ) full\_embedding = model.encode(full\_document) full_embedding=model.encode(full_document)
c h u n k s _ e m b e d d i n g s = s p l i t _ e m b e d d i n g _ i n t o _ c h u n k s ( f u l l _ e m b e d d i n g , c h u n k _ s i z e = 512 ) chunks\_embeddings = split\_embedding\_into\_chunks(full\_embedding, chunk\_size=512) chunks_embeddings=split_embedding_into_chunks(full_embedding,chunk_size=512)
5.3 高级文档预处理
定义: 处理超出纯文本的复杂文档结构:
- HTML 感知解析: 保留标题、表格和层次结构。
- 表格感知处理: 准确提取结构化数据。
- 多模态内容: 处理带有嵌入文本的图像、图表或 PDF。
概念示例:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "html.parser")
text_chunks = [section.get_text() for section in soup.find_all("p")]
5.4 编码器中的融合 (FiD)
定义: 在生成之前并行处理问题-文档对,允许模型同时考虑多个来源。
- 改进复杂查询的多源推理。
- 在综合信息时优于顺序逐令牌生成。
概念示例:
r e s p o n s e s = f i d _ m o d e l . g e n e r a t e ( q u e r y , c o n t e x t _ d o c u m e n t s ) responses = fid\_model.generate(query, context\_documents) responses=fid_model.generate(query,context_documents)
$final_answer````markdown
f i n a l _ a n s w e r = c o m b i n e _ r e s p o n s e s ( r e s p o n s e s ) final\_answer = combine\_responses(responses) final_answer=combine_responses(responses)
5.5 RAG-Token 与 RAG-Sequence
定义: 在生成过程中集成检索内容的两种策略:
- RAG-Token: 为每个生成的令牌选择不同的文档 → 细粒度集成。
- RAG-Sequence: 为整个答案选择最佳的整体文档 → 更简单、更稳定的输出。
用例:
- RAG-Token → 非常适合具有高细节的多源合成。
- RAG-Sequence → 更适合简洁的单源答案。
概念示例:
a n s w e r = r a g _ s e q u e n c e _ m o d e l . g e n e r a t e ( q u e r y , r e t r i e v e d _ d o c u m e n t s ) answer = rag\_sequence\_model.generate(query, retrieved\_documents) answer=rag_sequence_model.generate(query,retrieved_documents)
a n s w e r = r a g _ t o k e n _ m o d e l . g e n e r a t e ( q u e r y , r e t r i e v e d _ d o c u m e n t s ) answer = rag\_token\_model.generate(query, retrieved\_documents) answer=rag_token_model.generate(query,retrieved_documents)
这些高级技术是可选的,但对于生产级 RAG 应用程序影响巨大,尤其是在处理长文档、复杂查询或领域特定数据集时。
6 结论 / 行动号召
“RAG 正在发展——你的系统也必须如此。”
大多数工程师一开始都认为 LLM 是魔法。但正如我们所看到的,真正的性能来自于你围绕它构建的检索和推理策略。准确性、可扩展性和可靠性并非来自更大的模型——它们来自更智能的系统。
如果你正在构建用于生产的 RAG,请记住:
- 准确性并非偶然 → 它关乎 PageIndex、重排序、元数据和自适应流水线。
- 速度不仅仅是硬件 → 它关乎 CAG、上下文检索和正确的数据缓存。
- 可靠性并非试错 → 它关乎衡量正确的指标并系统地应用高级技术。
不要依赖一次性的小技巧。采用系统化、分阶段的改进策略,将你的 RAG 应用程序从原型提升到生产就绪。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)