大模型落地:从微调到企业级解决方案的完整实践指南
本文系统讲解大语言模型(LLMs)在企业落地的技术路径,涵盖四大核心模块:1)模型微调(LoRA/QLoRA方法),通过领域数据适配提升垂直场景表现;2)提示词工程(CRISPE框架),优化API调用效果;3)多模态应用(Qwen-VL等模型),实现图文/视频理解;4)企业级解决方案,包括统一API网关、模型路由、缓存机制等架构设计。文章提供代码示例、流程图和架构图,并分享智能客服系统落地案例,实
随着大语言模型(Large Language Models, LLMs)技术的迅猛发展,越来越多的企业希望将大模型能力融入自身业务流程中。然而,从“可用”到“好用”再到“可靠、可维护、可扩展”,中间存在巨大的工程鸿沟。本文将系统性地讲解大模型在实际场景中的落地路径,涵盖 大模型微调(Fine-tuning)、提示词工程(Prompt Engineering)、多模态应用(Multimodal Applications) 以及 企业级解决方案(Enterprise Solutions) 四大核心模块,并辅以代码示例、Mermaid流程图、Prompt模板和架构图,帮助开发者与架构师构建高可用的大模型应用。
一、大模型微调(Fine-tuning)
1.1 为什么需要微调?
虽然通用大模型(如 Llama 3、Qwen、GPT-4)具备强大的泛化能力,但在特定领域(如医疗、金融、法律)或特定任务(如工单分类、合同解析)上表现往往不够精准。微调通过在特定数据集上继续训练模型,使其适应垂直场景,提升准确率、降低幻觉风险。
1.2 微调方法概览
| 方法 | 描述 | 适用场景 |
|---|---|---|
| 全参数微调(Full Fine-tuning) | 更新所有模型参数 | 数据充足、算力充足 |
| LoRA(Low-Rank Adaptation) | 仅训练低秩矩阵,冻结主干 | 资源受限、快速迭代 |
| QLoRA | LoRA + 量化(4-bit) | 极低显存需求(<10GB) |
| P-Tuning / Prompt Tuning | 学习可学习的 prompt embedding | 少样本、轻量级适配 |
推荐实践:对于大多数企业场景,LoRA 是性价比最高的选择。
1.3 使用 Hugging Face + PEFT 进行 LoRA 微调(代码示例)
python
编辑
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from peft import LoraConfig, get_peft_model, TaskType
from datasets import load_dataset
from trl import SFTTrainer
# 加载基础模型(以 Qwen-1.8B 为例)
model_name = "Qwen/Qwen1.5-1.8B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
device_map="auto",
torch_dtype="auto"
)
# 配置 LoRA
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 输出可训练参数量(通常 <1%)
# 准备数据集(假设为 JSONL 格式)
dataset = load_dataset("json", data_files="data/train.jsonl")["train"]
# 定义格式化函数
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"### 指令:\n{example['instruction'][i]}\n\n### 输入:\n{example['input'][i]}\n\n### 回答:\n{example['output'][i]}"
output_texts.append(text)
return output_texts
# 训练配置
training_args = TrainingArguments(
output_dir="./qwen-lora-finetuned",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=10,
save_strategy="epoch",
fp16=True,
)
# 使用 SFTTrainer(Supervised Fine-Tuning)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset,
formatting_func=formatting_prompts_func,
max_seq_length=512,
)
trainer.train()
trainer.save_model("./final_model")1.4 微调流程图(Mermaid)
flowchart TD
A[收集领域数据] --> B[数据清洗与标注]
B --> C{数据量是否充足?}
C -- 是 --> D[全参数微调]
C -- 否 --> E[LoRA/QLoRA 微调]
D --> F[模型评估: BLEU, ROUGE, Accuracy]
E --> F
F --> G{指标达标?}
G -- 否 --> H[调整超参/增加数据]
G -- 是 --> I[模型部署]
H --> C
I --> J[上线监控与反馈闭环]
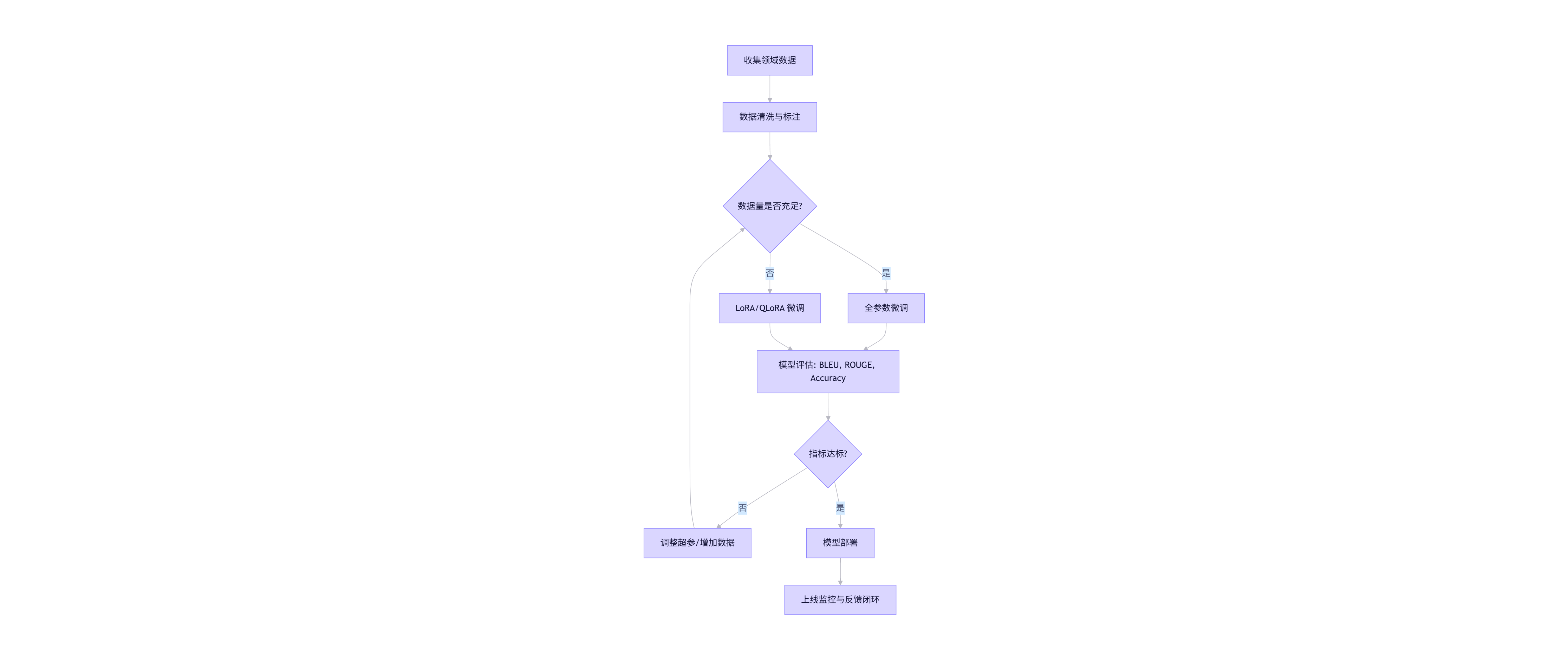
关键点:微调不是一次性工程,需建立 数据-训练-评估-反馈 的闭环机制。
二、提示词工程(Prompt Engineering)
2.1 提示词工程的核心价值
当无法进行微调(如使用闭源 API:GPT-4、Claude)时,高质量 Prompt 成为控制模型输出的关键手段。优秀的 Prompt 可显著提升任务准确率、减少 token 消耗、增强可控性。
2.2 Prompt 设计原则(CRISPE 框架)
- Capacity and Role(角色设定)
- Result(期望输出)
- Input Data(输入信息)
- Steps(执行步骤)
- Persona(语气风格)
- Example(示例)
2.3 Prompt 示例模板
场景:客服工单分类
text
编辑
你是一名专业的客服系统AI助手,请根据用户描述将工单分类为以下类别之一:
- 支付问题
- 账户安全
- 功能咨询
- 投诉建议
- 其他
请严格按照以下格式输出:
{"category": "类别名称"}
用户描述:
"{user_input}"场景:合同条款提取(Few-shot)
text
编辑
请从以下合同文本中提取“违约金比例”和“争议解决地”。若未提及,请返回 null。
示例1:
合同文本:“如一方违约,应支付合同总额10%的违约金。争议提交至上海市仲裁委员会。”
输出:{"违约金比例": "10%", "争议解决地": "上海市"}
示例2:
合同文本:“本协议自签署日起生效,有效期三年。”
输出:{"违约金比例": null, "争议解决地": null}
现在请处理以下文本:
"{contract_text}"2.4 动态 Prompt 生成(代码示例)
python
编辑
def build_prompt(task, user_input, examples=None):
base_prompt = {
"ticket_classification": """
你是一名客服AI,请将以下用户问题分类:
类别:支付问题 / 账户安全 / 功能咨询 / 投诉建议 / 其他
输出格式:{"category": "..."}
用户问题:{}
""".strip(),
"contract_extraction": """
请从合同中提取“违约金比例”和“争议解决地”。
示例:
合同:“违约金为5%。” → {"违约金比例": "5%", "争议解决地": null}
合同:“争议由北京法院管辖。” → {"违约金比例": null, "争议解决地": "北京"}
当前合同:{}
""".strip()
}
return base_prompt[task].format(user_input)2.5 Prompt 优化流程(Mermaid)
flowchart LR
A[定义任务目标] --> B[设计初始Prompt]
B --> C[小批量测试]
C --> D{效果达标?}
D -- 否 --> E[添加示例/约束/角色]
E --> C
D -- 是 --> F[集成到系统]
F --> G[线上A/B测试]
G --> H[持续迭代]
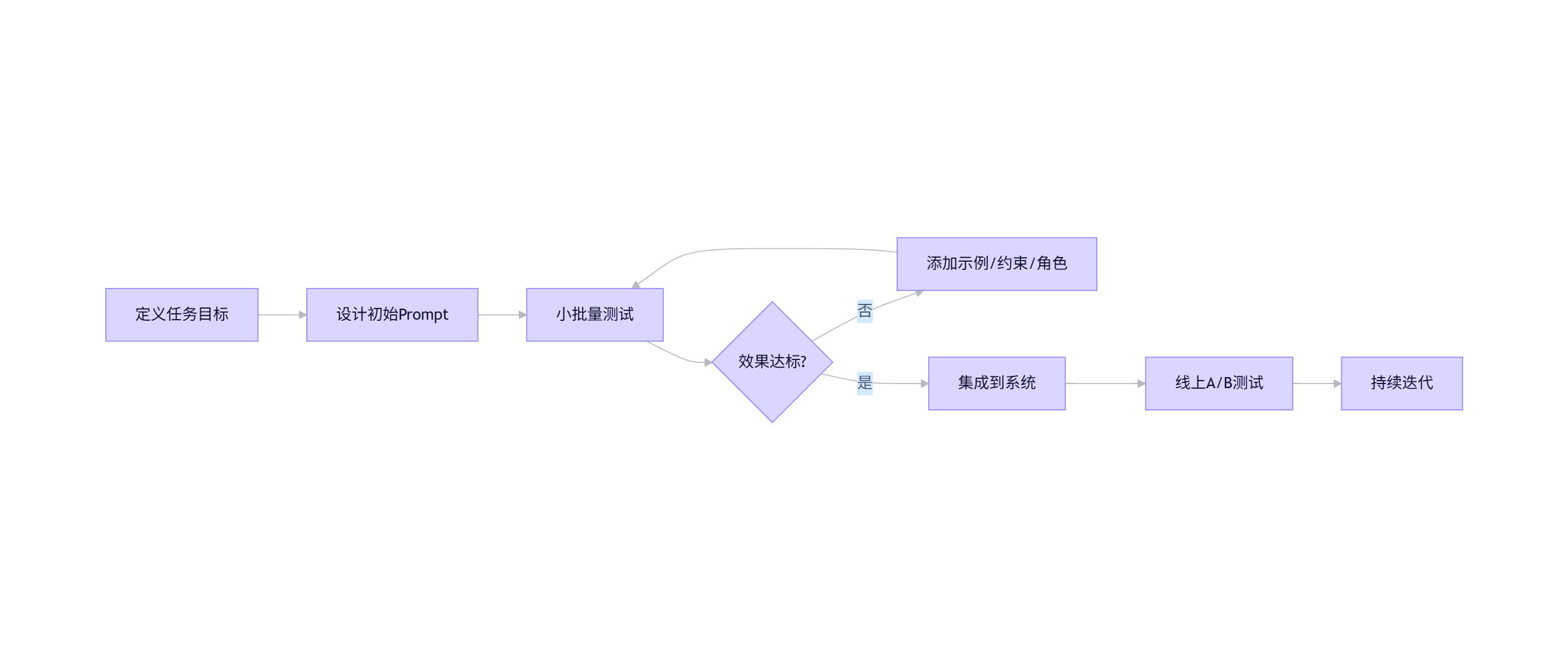
提示:使用 LangChain 或 LlamaIndex 可自动化管理复杂 Prompt 工作流。
三、多模态应用(Multimodal Applications)
3.1 什么是多模态大模型?
多模态模型(如 Qwen-VL、LLaVA、GPT-4V)能够同时理解 文本、图像、音频、视频 等多种模态信息,适用于更复杂的现实场景。
3.2 典型应用场景
| 场景 | 模型能力 | 示例 |
|---|---|---|
| 图文问答 | 图像理解 + 文本生成 | “这张发票的总金额是多少?” |
| 视频摘要 | 视频帧分析 + 时序建模 | 自动生成会议录像摘要 |
| 医疗影像报告 | CT/MRI 图像 + 医学术语生成 | “肺部CT显示磨玻璃影,建议随访” |
| 工业质检 | 缺陷图像识别 + 自然语言描述 | “产品表面有划痕,位置:右下角” |
3.3 使用 Qwen-VL 进行图文问答(代码)
python
编辑
from transformers import AutoProcessor, AutoModelForVision2Seq
import torch
from PIL import Image
# 加载 Qwen-VL 模型
model_id = "Qwen/Qwen-VL"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForVision2Seq.from_pretrained(
model_id,
trust_remote_code=True,
device_map="auto"
).eval()
# 输入图像与问题
image = Image.open("invoice.jpg")
query = "这张发票的总金额是多少?"
# 构造多模态输入
messages = [
{"role": "user", "content": f"<image>{query}"}
]
prompt = processor.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(prompt, images=[image], return_tensors="pt").to(model.device)
# 生成回答
with torch.no_grad():
output = model.generate(**inputs, max_new_tokens=100)
response = processor.decode(output[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(response) # 输出:¥1,280.003.4 多模态系统架构图
graph TD
A[用户上传图像/视频] --> B(多模态预处理)
B --> C{任务类型}
C -->|图文问答| D[Qwen-VL / LLaVA]
C -->|视频分析| E[Video-LLM + 帧采样]
C -->|语音+文本| F[Whisper + LLM]
D --> G[结构化输出]
E --> G
F --> G
G --> H[业务系统集成]
H --> I[前端展示/数据库存储]
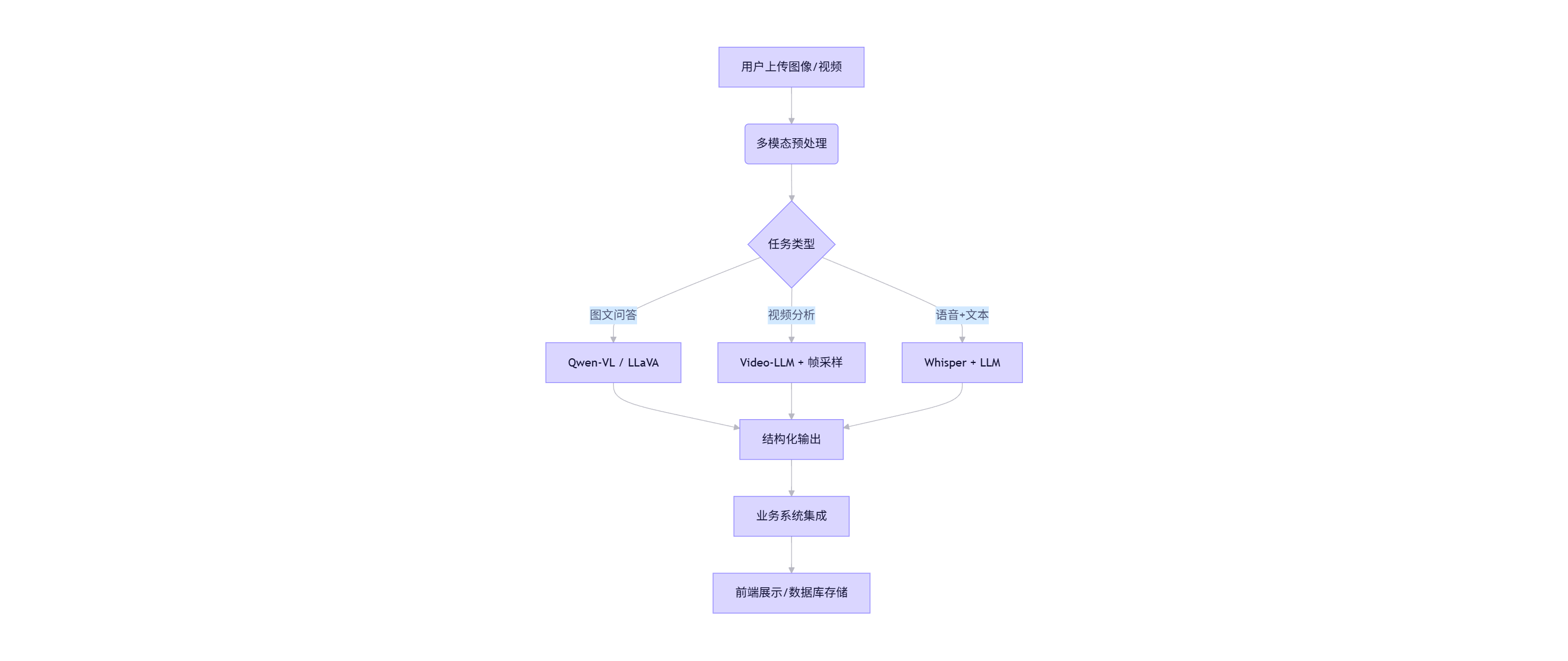
注意:多模态推理对 GPU 显存要求较高,建议使用 vLLM 或 TensorRT-LLM 进行加速。
四、企业级大模型解决方案
4.1 企业落地的核心挑战
| 挑战 | 解决方案 |
|---|---|
| 数据安全与隐私 | 私有化部署 + 数据脱敏 |
| 推理延迟高 | 模型量化 + 推理引擎优化 |
| 成本不可控 | Token 精简 + 缓存机制 |
| 缺乏可观测性 | 日志追踪 + LLM Ops 平台 |
| 多模型管理 | 统一 API 网关 + 模型路由 |
4.2 企业级架构设计(含图表)
整体架构图
flowchart TB
subgraph 用户端
U1[Web/App] --> U2[API Gateway]
end
subgraph 后端服务
U2 --> Auth[认证鉴权]
Auth --> Router[模型路由]
Router -->|简单任务| Cache[缓存层 Redis]
Router -->|复杂任务| Orchestrator[编排引擎]
end
subgraph 模型层
Orchestrator --> M1[微调后的 Qwen-7B]
Orchestrator --> M2[GPT-4 API]
Orchestrator --> M3[Qwen-VL 多模态]
Orchestrator --> M4[Embedding 模型]
end
subgraph 数据与运维
M1 & M2 & M3 --> Log[日志与监控 Prometheus/Grafana]
Log --> Alert[告警系统]
Feedback[用户反馈] --> Retrain[自动触发重训练]
end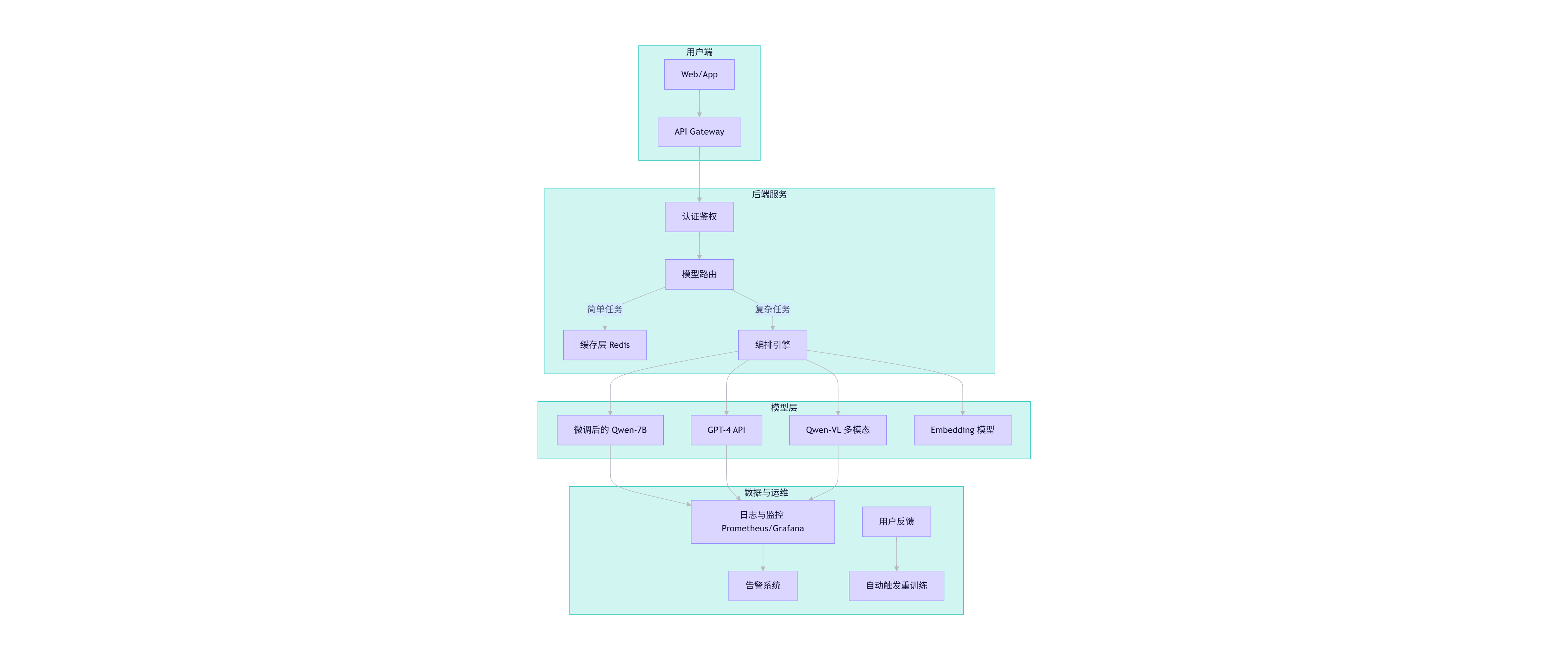
4.3 关键组件详解
1. 统一 API 网关
- 支持 OpenAI 兼容接口(
/v1/chat/completions) - 自动负载均衡、限流、熔断
2. 模型路由策略
python
编辑
def route_model(task_type, input_length, security_level):
if security_level == "high":
return "local_qwen_7b_lora" # 私有模型
elif task_type == "multimodal":
return "qwen_vl"
elif input_length < 100 and task_type == "simple_qa":
return "cache_or_gpt3.5"
else:
return "gpt4"3. 缓存机制(减少重复计算)
- 对高频 Prompt + Input 做 MD5 缓存
- TTL 设置为 24 小时
4. LLM Ops 平台功能
- Prompt 版本管理
- A/B 测试(对比不同 Prompt 或模型)
- Token 消耗统计
- 幻觉检测(基于规则或小模型)
4.4 安全与合规
- 数据不出域:敏感数据在本地模型处理
- 输出过滤:使用正则或小模型过滤 PII(个人身份信息)
- 审计日志:记录所有输入输出,满足 GDPR/等保要求
五、综合案例:智能客服系统落地
5.1 需求背景
某电商平台需升级客服系统,支持:
- 自动回答常见问题
- 工单分类与摘要
- 发票图像识别
- 7×24 小时响应
5.2 技术方案
| 模块 | 技术选型 |
|---|---|
| 文本问答 | Qwen-7B + LoRA 微调(电商 FAQ 数据) |
| 工单分类 | Prompt Engineering + 规则后处理 |
| 发票识别 | Qwen-VL + OCR 后校验 |
| 部署方式 | Kubernetes + vLLM + Nginx |
5.3 性能指标(上线后)
| 指标 | 上线前 | 上线后 |
|---|---|---|
| 首响时间 | 120s | <3s |
| 人工转接率 | 65% | 28% |
| 满意度 | 3.8/5 | 4.5/5 |
| 月成本 | $15,000 | $6,200(节省 59%) |
六、未来趋势与建议
- Small Language Models (SLMs):7B 以下模型在边缘设备部署将成为主流。
- Agent 架构:大模型作为“大脑”,调用工具(搜索、数据库、API)完成复杂任务。
- RAG + 微调融合:结合外部知识库与领域微调,兼顾准确性与泛化性。
- 绿色 AI:通过蒸馏、剪枝、稀疏化降低碳足迹。
给企业的建议:
- 从小场景切入(如内部知识问答)
- 优先考虑开源模型(Qwen、Llama)以避免厂商锁定
- 建立 LLM 工程团队(含 MLOps、Prompt Engineer、安全专家)
附录:资源推荐
- 模型:Qwen 系列(通义千问)、Llama 3、Phi-3
- 框架:Hugging Face Transformers、LangChain、LlamaIndex、vLLM
- 工具:Weights & Biases(实验跟踪)、MLflow(模型管理)
- 书籍:《Generative AI with LangChain》、《Building LLM-Powered Applications》
结语:大模型落地不是“魔法”,而是系统工程。唯有将算法、工程、业务深度融合,才能释放其真正价值。本文提供的代码、流程图与架构设计,可作为企业构建大模型应用的起点。未来已来,唯快不破。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 133
133 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)