COBRA详解
稀疏ID可以唯一表示item,有很好的区分性,但丧失了对item的细粒度信息刻画。纯文本可以准确可以item属性,但构造成prompt太长,套入到LLM中会导致资源消耗过大。那么如何结合两者的优点呢?COBRA首先根据codebook生成item的稀疏ID,该ID可以理解为item的大类别。既不过于精细,像unique id,又不过于宽泛。然后将ID序列输入到Transformer Decoder
这是一篇生成式推荐用于召回场景的工作,其建模范式仍旧是输入端根据用户行为序列构造prompt,输出端预测next item。该工作巧妙地将稀疏ID与稠密向量表征级联融合起来,达到了SOTA水平。
传统方法对比
| 方案类型 | 核心技术 | 局限性 |
|---|---|---|
| 纯文本+LLM | 直接使用广告文本特征 | 输入过长,资源消耗大 |
| 短语表征 | 关键词压缩表达 | 信息丢失严重 |
| 稠密表征+对比学习 | 端到端向量编码 | 建模复杂度高,缺少兴趣探索 |
| 稀疏ID生成 | RQ-VAE量化技术 | 信息损失导致细粒度捕捉弱 |
COBRA介绍
稀疏ID可以唯一表示item,有很好的区分性,但丧失了对item的细粒度信息刻画。纯文本可以准确可以item属性,但构造成prompt太长,套入到LLM中会导致资源消耗过大。那么如何结合两者的优点呢?
COBRA首先根据codebook生成item的稀疏ID,该ID可以理解为item的大类别。既不过于精细,像unique id,又不过于宽泛。然后将ID序列输入到Transformer Decoder中预测稠密向量。
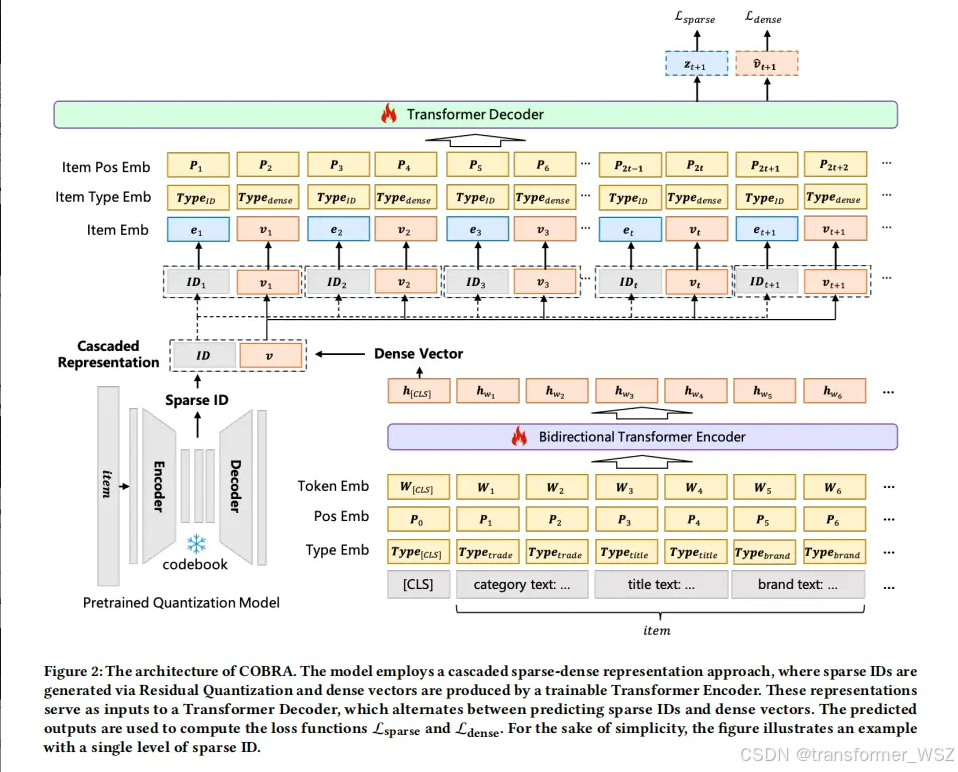
离线训练
两个预测任务的损失函数如下:
L sparse = − ∑ t = 1 T − 1 log ( exp ( z t + 1 I D t + 1 ) ∑ j = 1 C exp ( z t + 1 j ) ) L dense = − ∑ t = 1 T − 1 log exp ( cos ( v ^ t + 1 ⋅ v t + 1 ) ) ∑ item j ∈ Batch exp ( cos ( v ^ t + 1 , v item j ) ) \mathcal{L}_{\text {sparse }}=-\sum_{t=1}^{T-1} \log \left(\frac{\exp \left(z_{t+1}^{I D_{t+1}}\right)}{\sum_{j=1}^C \exp \left(z_{t+1}^j\right)}\right) \\ \left.\left.\mathcal{L}_{\text {dense }}=-\sum_{t=1}^{T-1} \log \frac{\exp \left(\cos \left(\hat{\mathbf{v}}_{t+1} \cdot \mathbf{v}_{t+1}\right)\right)}{\sum_{\text {item }_j \in \text { Batch }} \exp \left(\operatorname { c o s } \left(\hat{\mathbf{v}}_{t+1}, \mathbf{v}_{\text {item }}^j\right.\right.} \mathbf{}\right)\right) Lsparse =−t=1∑T−1log
∑j=1Cexp(zt+1j)exp(zt+1IDt+1)
Ldense =−t=1∑T−1log∑item j∈ Batch exp(cos(v^t+1,vitem jexp(cos(v^t+1⋅vt+1))
ID预测就是经典的多分类任务,dense vector就是经典的对比学习任务。
在线推理
-
稀疏ID生成:decoder根据beam search生成top M M M个ID,每个ID有其得分

-
稠密向量生成:根据每个稀疏ID继续生成dense vector,然后检索出同一个ID下的跟vector相似的top N N N个候选item

-
最终召回候选集生成:为了兼顾多样性(即不同ID)以及准确性(即同一ID下的候选item),联合打分取top K K K个item召回

在离线实验结果
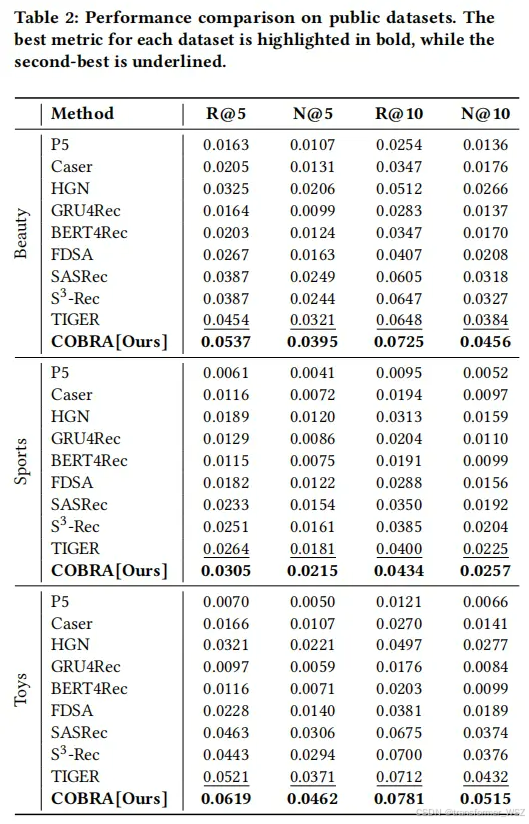
在公共数据集上,离线指标提升很明显。在A/B实验上,转化率和收入也在咔咔涨,就不细说了。
参考

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0


 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)