RankCoT:提高RAG系统准确性的新手段——让大模型学会对召回文档排序
通过让大模型学会对召回文档排序,提高RAG系统的准确性
·
论文地址:https://arxiv.org/pdf/2502.17888
代码地址:https://github.com/NEUIR/RankCo
动机
- RAG系统缺陷
- 因噪声检索到不相关信息,进而误导
- 当前方案及缺陷
- 检索结果重排:独立模块,会保留噪声;需要经验性阈值
- 检索结果总结:独立模块,容易忽略与query相关性,导致误导(客观有用的知识,但与问题无关)、细节丢失
- CoT:通过更细致的思考试图让llm正确利用召回文档,本质上只是推理优化手段,依赖于llm本身能力
解决
- 提出rankCoT:
- 基于相关文档上下文,要求llm对每个文档生成CoT输出
- CoT结果集合中,包含真实答案的为正样本,否则为负样本
- 使用DPO算法训练llm,使其为正样本分配更搞生成概率。相当于学习排序(pointwise的排序任务)
- 反思再提炼
为了避免DOP训练过程拟合不必要的表述pattern,会基于原始CoT输出再生成一个CoT输出,消除固定模式、增加多样性
效果
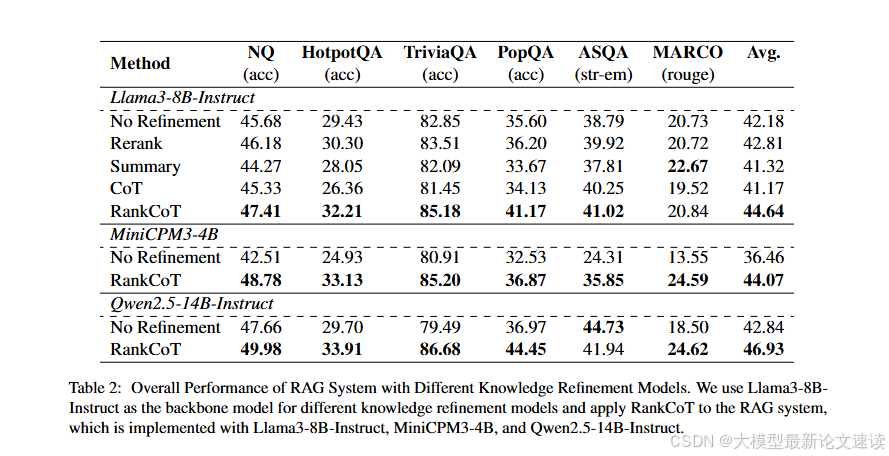
启发
- 开放式任务,使用RL调整llm已是基操,比SFT更安全有效?
- 基于llm输出再构造训练任务,并注意调整数据多样性、消除不必要的模式
- 多agent系统,可以考虑专门训练llm对其他agent/tools的协作能力,甚至将它们的功能吸收到llm中

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)