怎么计算 LoRA 微调所需的显存(VRAM)?
怎么计算 LoRA 微调所需的显存(VRAM)?
计算 LoRA 微调所需的显存(VRAM),可以拆解为四个主要部分:基础模型权重 + LoRA 参数与优化器状态 + 激活值(Activations) + 缓冲区/碎片(Overhead)。
以 7B(70 亿参数)模型为例,以下是详细的计算方法和估算:
1. 核心公式
总显存≈基础模型权重+LoRA参数及优化器+激活值+固定开销 \text{总显存} \approx \text{基础模型权重} + \text{LoRA参数及优化器} + \text{激活值} + \text{固定开销} 总显存≈基础模型权重+LoRA参数及优化器+激活值+固定开销
2. 具体计算步骤(以 7B 模型为例)
A. 基础模型权重 (Base Model Weights)
这是显存占用的“底座”,取决于你加载模型的精度。
- FP16 / BF16 (半精度): 每参数 2 Bytes。
- 7×109×2 Bytes≈14 GB7 \times 10^9 \times 2 \text{ Bytes} \approx \mathbf{14 \text{ GB}}7×109×2 Bytes≈14 GB
- INT8 (8-bit 量化): 每参数 1 Byte。
- 7×109×1 Byte≈7 GB7 \times 10^9 \times 1 \text{ Byte} \approx \mathbf{7 \text{ GB}}7×109×1 Byte≈7 GB
- INT4 (QLoRA, 4-bit 量化): 每参数 0.5 Byte (+少量反量化开销)。
- 7×109×0.5 Bytes+overhead≈4∼4.5 GB7 \times 10^9 \times 0.5 \text{ Bytes} + \text{overhead} \approx \mathbf{4 \sim 4.5 \text{ GB}}7×109×0.5 Bytes+overhead≈4∼4.5 GB
结论 A:如果是 QLoRA(INT4),底座只需要约 4.5GB;如果是标准 LoRA(FP16),底座需要 14GB。
B. LoRA 参数与优化器 (LoRA Params & Optimizer)
LoRA 只训练极少量的参数(通常是原模型的 0.1% ~ 1%)。
假设 LoRA 的 Rank r=64r=64r=64,可训练参数大约在 20M ~ 100M 之间(取决于针对多少个模块)。
- LoRA 权重: 极小,通常 < 200 MB。
- 优化器状态 (AdamW): AdamW 需要保存一阶和二阶动量,每参数需要 8 Bytes(FP32)。
- 即使是 1 亿参数:108×8 Bytes≈800 MB10^8 \times 8 \text{ Bytes} \approx 800 \text{ MB}108×8 Bytes≈800 MB。
结论 B:LoRA 部分的显存占用非常小,通常预留 0.5 GB ~ 1 GB 绰绰有余。
C. 激活值 (Activations) —— 最大的变量
这是显存爆炸的主要原因,取决于 Batch Size (批次大小) 和 Sequence Length (序列长度)。
- 不开启梯度检查点 (No Gradient Checkpointing): 显存占用巨大,因为要保存每一层的中间结果用于反向传播。
- 开启梯度检查点 (Gradient Checkpointing): 强烈推荐。用计算换显存,虽然慢 20-30%,但能极大降低激活值显存(通常降低 3-4 倍)。
估算(7B 模型,开启梯度检查点):
- Seq Len = 512, Batch Size = 1: 约 0.5 GB
- Seq Len = 2048, Batch Size = 1: 约 2 GB
- Seq Len = 4096, Batch Size = 1: 约 4 GB
结论 C:长文本训练会吃掉大量显存。
D. 缓冲区与碎片 (Overhead)
PyTorch 上下文、CUDA 核心库、以及显存碎片。
结论 D:通常预留 1 GB ~ 2 GB。
3. 7B 模型实战显存需求表
假设配置:Batch Size = 1 (配合梯度累积), 开启 Gradient Checkpointing。
| 训练模式 | 精度 | 序列长度 (Context) | 模型权重 | LoRA+优化器 | 激活值(估) | 缓冲区 | 总显存需求 (约) | 适用显卡示例 |
|---|---|---|---|---|---|---|---|---|
| QLoRA (推荐) | INT4 | 1024 | 4.5 GB | 0.5 GB | 1 GB | 1 GB | ~ 7 GB | RTX 3070/4060 (8G) |
| QLoRA | INT4 | 2048 | 4.5 GB | 0.5 GB | 2.5 GB | 1 GB | ~ 8.5 GB | RTX 3080 (10G/12G) |
| QLoRA | INT4 | 4096 | 4.5 GB | 0.5 GB | 5 GB | 1.5 GB | ~ 11.5 GB | RTX 3060/4070 (12G) |
| Standard LoRA | FP16 | 2048 | 14 GB | 0.5 GB | 2.5 GB | 1 GB | ~ 18 GB | RTX 3090/4090 (24G) |
| Standard LoRA | FP16 | 4096 | 14 GB | 0.5 GB | 5 GB | 1.5 GB | ~ 21 GB | RTX 3090/4090 (24G) |
4. 省显存技巧总结
如果你发现显存不够(OOM),请按以下顺序操作:
- 使用 QLoRA (4-bit):这是最立竿见影的,直接把 7B 的门槛从 24G 降到 8-12G。
- 开启 Gradient Checkpointing:在 HuggingFace TrainingArguments 中设置
gradient_checkpointing=True。这几乎是微调大模型的必选项。 - 降低 Per-Device Batch Size:设为 1,然后通过增加
gradient_accumulation_steps(梯度累积步数)来模拟大 Batch(例如 Batch=1, Accumulation=16 等于 Batch=16)。 - 降低序列长度 (Max Sequence Length):如果数据不需要 4k 长度,截断到 1024 或 512 能大幅省显存。
- 使用 Flash Attention 2:如果有 Ampere 架构(RTX 30系)或更新的显卡,安装并开启 Flash Attention 可以显著降低长序列的显存占用并加速训练。
- 分页优化器 (Paged AdamW):使用
bitsandbytes库中的paged_adamw_32bit,可以在显存不足时将优化器状态暂时转移到 CPU 内存中。
总结公式
对于 7B 模型 QLoRA 微调:
显存 ≈ 6GB + (序列长度 / 512) * 0.5GB
(这是一个粗略的经验法则,假设 Batch Size=1)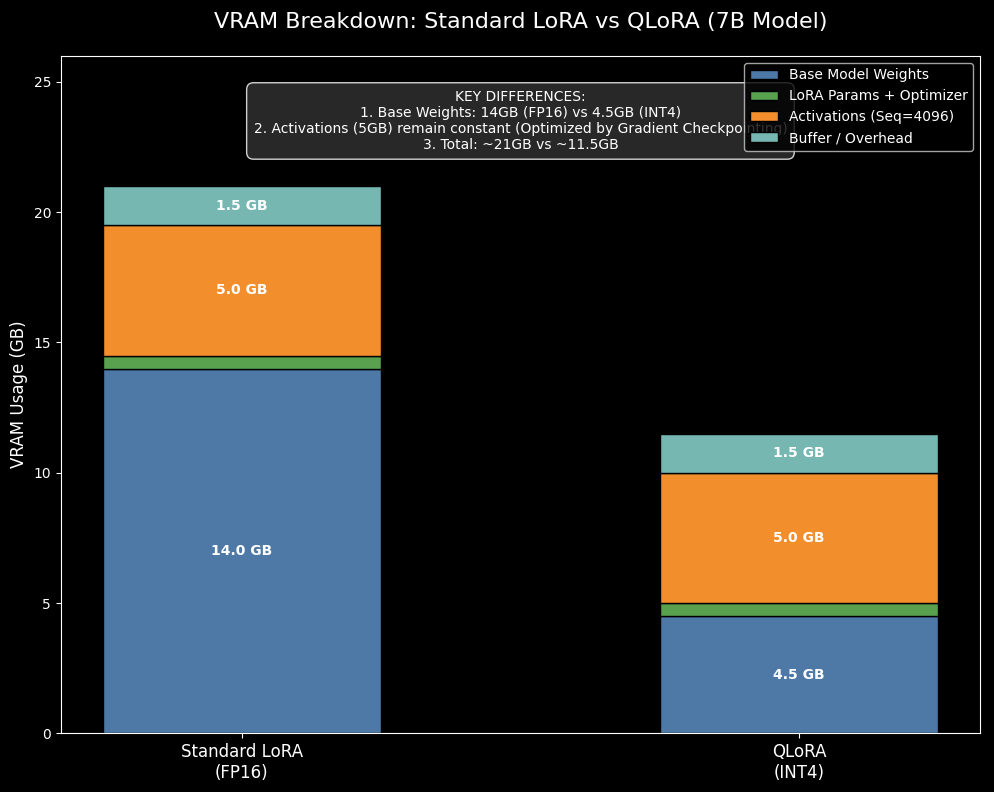

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)