从零开始掌握RAG检索增强生成:构建企业级知识问答系统
RAG技术通过结合LLM、向量数据库、Embedding和Rerank模型,构建文档入库(离线处理)和问答分析(在线处理)两阶段架构。它解决了LLM的知识时效性、幻觉问题和上下文窗口限制,提高回答准确性和可靠性,降低成本。尽管面临系统复杂性和中间环节依赖等挑战,但在企业知识管理、智能客服、专业研究等需要准确性、时效性、隐私和可追溯性的场景中具有广泛应用价值。
RAG技术通过结合LLM、向量数据库、Embedding和Rerank模型,构建文档入库(离线处理)和问答分析(在线处理)两阶段架构。它解决了LLM的知识时效性、幻觉问题和上下文窗口限制,提高回答准确性和可靠性,降低成本。尽管面临系统复杂性和中间环节依赖等挑战,但在企业知识管理、智能客服、专业研究等需要准确性、时效性、隐私和可追溯性的场景中具有广泛应用价值。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
今天我来分享一下RAG——Retrieval-Augmented Generation(检索增强生成)相关的知识。
RAG除了要使用LLM,还需要使用向量数据库,还要用Embedding模型将文档转换为向量,用Rerank模型对检索到的文档进行排序。
整体架构流程图
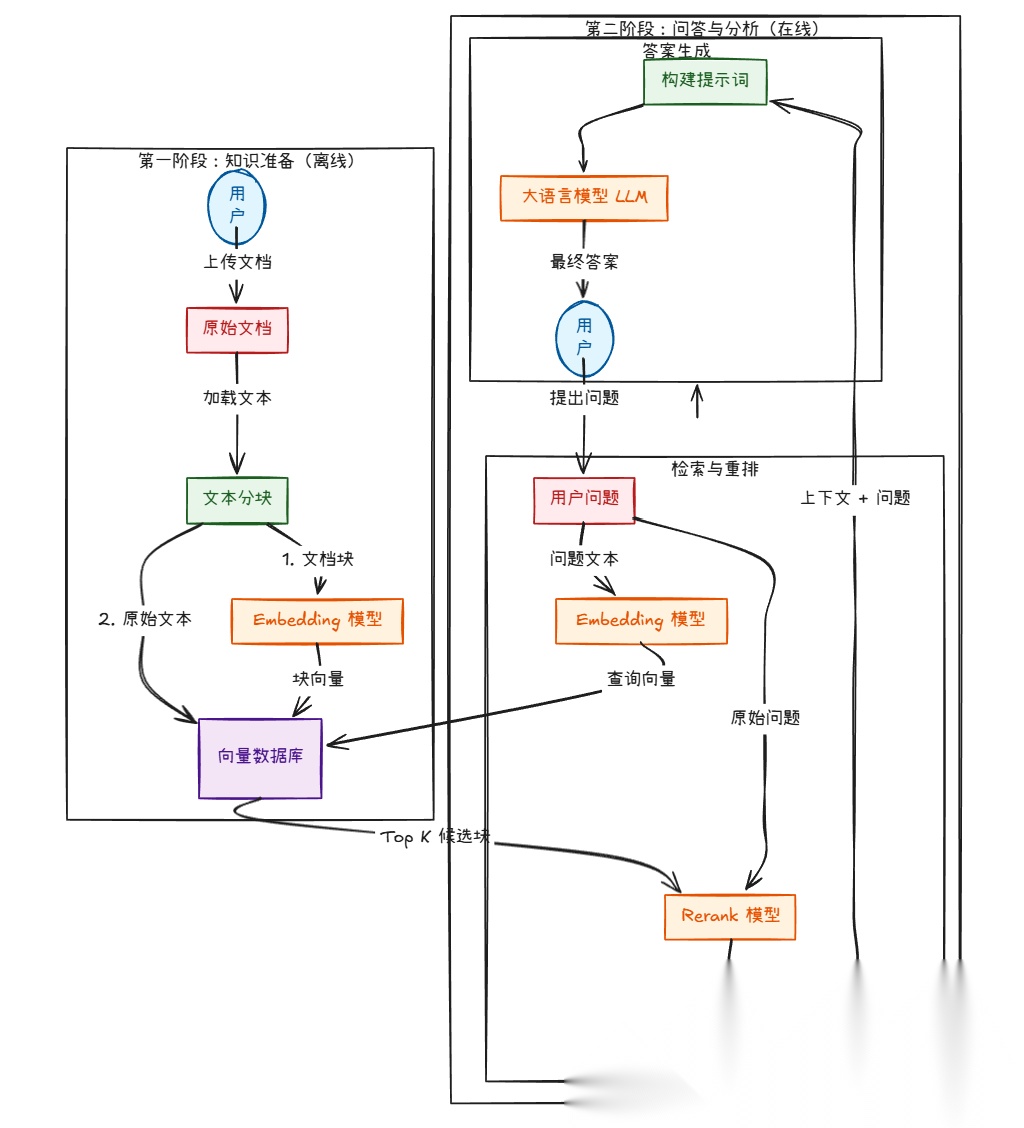
第一阶段:文档入库(离线处理)
1.文档上传与解析:用户上传PDF、Word、TXT等格式的文档。系统首先需要解析这些文件,提取出纯文本内容。
2.文档分块:一篇长文档(如几十页的PDF)不能直接处理。系统会将其切分成多个有意义的、大小适中的文本块。分块策略非常关键,可以是按段落、按固定长度、或按语义结构等。
3.向量化:使用 Embedding模型 将每个文本块转换成一个高维向量(一长串数字)。这个向量是文本块在数学空间中的“语义坐标”,意思相近的文本块,其向量在空间中的距离也相近。
4.存入向量数据库:将这些向量以及它们对应的原始文本块,一同存储到 向量数据库 中。至此,文档的知识就被“编码”并索引好了,等待被查询。
第二阶段:问答分析(在线处理)
1.用户提问:用户输入一个问题,例如“这份报告中,第三季度的营收增长点是什么?”
2.问题向量化:使用与入库时完全相同的Embedding模型,将用户的问题也转换成一个向量。
3.初步检索:系统拿着问题向量,去 向量数据库 中进行相似度搜索,快速找出与问题语义最相似的 Top K 个(比如 Top 20)文本块向量。这一步追求的是“快”和“广”,确保不漏掉潜在相关信息。
4.精排重排:初步检索的结果可能包含一些只是“沾点边”但并不精确的文本块。这时,Rerank模型 登场。它会接收“用户问题”和“初步检索到的Top K个文本块”,然后对这K个文本块进行更精细的相关性打分和排序,筛选出最相关的 Top N 个(比如 Top 3-5)。这一步追求的是“准”。
5.构建提示词:将用户的问题和经过Rerank筛选出的最相关的N个文本块,组合成一个精心设计的提示词。这个Prompt通常会告诉LLM:“你是一个助手,请根据以下参考资料回答用户的问题。参考资料:[…文本块1…] […文本块2…]。用户问题:[…用户问题…]。请基于资料进行回答。”
6.LLM生成答案:将构建好的Prompt发送给 LLM (大语言模型)。LLM会阅读这些参考资料,理解问题,并最终生成一个流畅、准确、有依据的答案。
7.返回结果:将LLM生成的答案(有时还会附上答案的来源文本块)返回给用户。
为什么要采用这种架构?有什么好处?
这种RAG架构并非凭空设计,它主要是为了解决单纯使用LLM的几个核心痛点。
1. 克服LLM的固有缺陷
- • 知识时效性问题:LLM的知识截止于其训练数据的时间点。对于训练数据之后的新信息、公司内部的私有文档、用户刚刚上传的文件,LLM一无所知。RAG通过检索最新的、私有的文档,让LLM能够访问并利用这些“外部知识”,实现了知识的动态更新。
- • 幻觉问题:LLM有时会“一本正经地胡说八道”,编造不存在的事实。RAG强制LLM基于提供的、可验证的文本片段来回答问题,极大地降低了幻觉的风险。答案变得“有据可查”。
- • 上下文窗口限制:即使是目前最先进的LLM,其能处理的文本长度(上下文窗口)也是有限的。你无法把一本几百页的书直接塞给LLM。RAG通过检索,只把最相关的几段话交给LLM,完美绕过了这个限制。
2. 提升回答的准确性和可靠性
- • 语义理解,而非关键词匹配:传统的关键词搜索无法理解同义词、近义词。例如,用户问“公司的利润情况”,而文档里写的是“盈利能力”。Embedding模型能理解“利润”和“盈利”在语义上是相近的,从而能正确检索到相关信息。
- • 答案可追溯、可验证:因为答案是基于检索到的特定文本块生成的,系统可以轻松地将答案的来源展示给用户。这在金融、法律、医疗等严肃场景中至关重要,能建立用户信任。
- • 处理复杂问题:对于需要综合文档多个部分信息才能回答的复杂问题,RAG可以检索到所有相关的片段,然后由LLM进行综合、推理和总结,这是传统搜索无法做到的。
3. 提高效率与降低成本
- • 降低API调用成本:LLM的API调用费用通常与输入和输出的Token数量成正比。如果每次都把整个大文档作为上下文发给LLM,成本会非常高昂。RAG只发送一小段精选的上下文,成本大大降低。
- • 提升响应速度:处理更短的上下文,LLM的推理速度会更快。虽然RAG增加了检索和重排的步骤,但相比于发送超长上下文给LLM,整体延迟通常更低,用户体验更好。
有什么坏处和挑战?
没有完美的架构,RAG也不例外。它引入了新的复杂性和潜在问题。
1. 系统复杂性增加
组件多,维护难:需要管理、维护和更新四个不同的核心组件(Embedding模型、向量数据库、Rerank模型、LLM)。任何一个组件出问题,或者它们之间的版本不兼容,都可能导致整个系统失效。
技术栈要求高:需要掌握从文档解析、数据库管理到多种AI模型调用的综合技术,对开发团队的要求更高。
2. 效果高度依赖于“中间环节”
分块策略是“玄学”:如何切分文档对最终效果影响巨大。块太大,可能包含太多噪音,干扰LLM;块太小,可能丢失必要的上下文,导致LLM无法理解。目前没有万能的分块策略,需要根据文档类型不断调优。
检索质量是瓶颈:如果第一步的向量检索就没找到相关的文档块(“检索失败”),那么后续的Rerank和LLM再强大也无能为力,所谓“Garbage in, garbage out”。检索的质量直接决定了RAG系统的上限。
Rerank模型的额外开销:Rerank模型虽然能提升精度,但它本身也是一个需要调用的模型,会增加系统的延迟和成本。需要在精度和速度之间做权衡。
3. 新的潜在问题
“Lost in the Middle”问题:即使检索到了正确的上下文,LLM在处理时也可能倾向于关注开头和结尾的信息,而忽略中间的关键部分。
多文档矛盾问题:如果上传的多个文档对同一问题有矛盾的描述,RAG系统可能会把矛盾的片段都检索出来,导致LLM给出一个模棱两可或错误的答案。需要更复杂的策略来处理这种情况。
成本考量:虽然比发送超长上下文便宜,但你需要为Embedding、Rerank和LLM三个模型的API调用(或本地部署的硬件资源)分别付费,总成本仍然需要仔细评估。
一个生动的比喻
为了更好地理解,我们可以把整个系统比作一个 “超级智能图书馆的研究助理” :
- • 你的文档 = 图书馆里的藏书。
- • 文档分块 = 把每本书拆分成独立的章节或知识卡片。
- • Embedding模型 = 一位博览群书的图书管理员,他阅读每张知识卡片,然后给它贴上一个独特的、能概括其核心思想的“魔法标签”(向量)。
- • 向量数据库 = 一个神奇的卡片目录系统,只要你给它看一个“魔法标签”,它就能瞬间从数百万张卡片中找出标签最相似的那些。
- • 用户提问 = 你向研究助理提出一个研究课题。
- • 初步检索 = 助理拿着你的课题,去目录系统里快速找出所有可能相关的20张知识卡片。
- • Rerank模型 = 一位资深专家教授,他仔细审阅这20张卡片,帮你挑出其中最核心、最相关的3张。
- • LLM = 你这位聪明的学生,你仔细阅读教授挑出的3张卡片,然后结合自己的理解,写出一篇逻辑清晰、内容详实的研究报告(最终答案)。
总结
采用 LLM + 向量数据库 + Embedding + Rerank 的RAG架构,是为了构建一个既能理解语言(LLM),又能精准记忆和检索知识(向量数据库、Embedding、Rerank)的系统。
核心好处在于它扬长避短:利用LLM强大的推理和生成能力,同时通过外部检索弥补其在知识时效性、准确性和上下文长度上的短板,最终实现了一个更可靠、更准确、成本效益更高的文档分析解决方案。
主要坏处在于系统复杂度和对中间环节的强依赖。它的成功不再仅仅取决于LLM本身,而是取决于整个处理链路中每一个环节的精心设计和优化。对于追求高质量、高可靠性的企业级应用来说,这种复杂性是值得投入的,但对于简单的原型验证,可能会显得过于笨重。
虽然有不少缺点,但那些需要准确性、时效性、隐私和可追溯性的场景中却是刚需,如下:
| 场景类别 | 典型应用 | RAG的核心价值 |
|---|---|---|
| 企业知识管理 | HR政策、IT支持、内部问答 | 提升效率、降低沟通成本、保证信息一致 |
| 智能客服 | 产品FAQ、售后支持 | 降低人力成本、7x24服务、提升满意度 |
| 专业领域研究 | 法律、医疗、金融分析 | 高度准确、提供决策依据、降低风险 |
| 教育与培训 | 课程答疑、论文辅导 | 个性化学习、激发主动探索、解放教师 |
| 内容创作 | 营销文案、竞品分析 | 加速创作、品牌合规、数据驱动 |
| 个人信息管理 | 笔记搜索、邮件回顾 | 打造个人“第二大脑”,高效利用个人数据 |
核心原则:何时首选RAG?
当你遇到以下问题时,RAG就是最佳解决方案:
- • 答案需要基于特定文档:而不是LLM的通用知识。
- • 信息是动态变化的:比如每日更新的报告、新产品文档。
- • 数据是私密的或敏感的:如企业内部资料、个人健康记录。
- • 需要答案的来源和依据:必须能追溯到是哪个文件、哪句话说的。
RAG的应用边界几乎涵盖了所有需要与“特定文本集合”进行深度交互的场景。它就像一个万能的“即插即用”知识模块,可以为任何基于LLM的应用注入一个精准、可控、可更新的“灵魂”。
今天分享的内容就到这里,谢谢大家的关注和支持。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)