从 ROS1的 Bag 文件中提取源数据(centos系统conda环境,不依赖ROS环境)
ROS Bag 文件数据提取指南摘要 本文介绍无需完整ROS环境即可从.bag文件中提取图像和点云数据的方法: 环境配置 仅需安装rosbags、opencv-python和numpy三个Python包 文件分析 提供Python脚本查看bag文件内容,包括话题类型、消息数量和时长 图像提取 分析图像数据格式 批量提取RGB图像并保存为PNG格式 自动创建输出目录并处理异常 点云提取 保存原始点云
·
从 ROS Bag 文件中提取源数据指南
📋 概述
本文档介绍如何从 ROS .bag 文件中提取图像和点云等源数据,无需安装完整的 ROS 环境。
🛠️ 环境准备
1. 安装必要的 Python 包
pip install rosbags opencv-python numpy
2. 验证安装
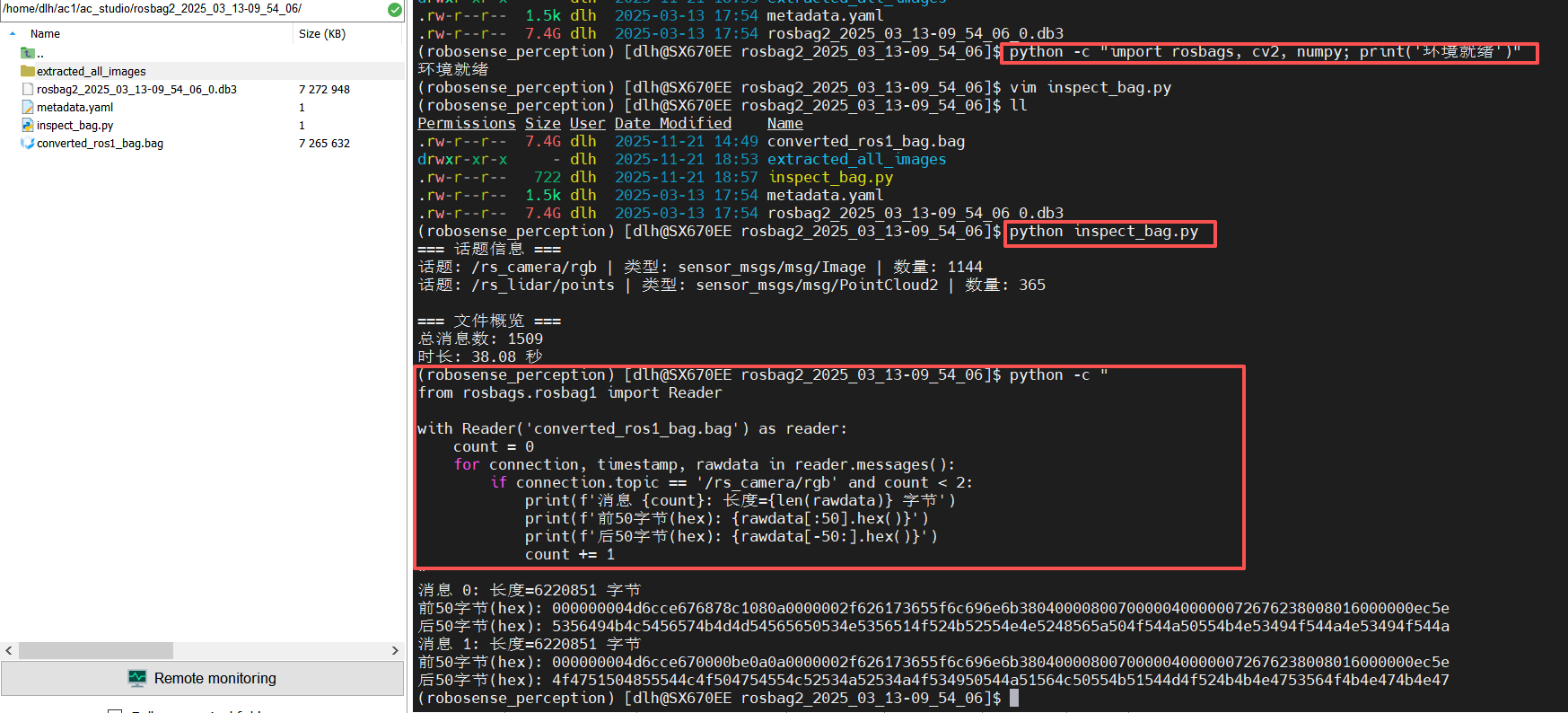
python -c "import rosbags, cv2, numpy; print('环境就绪')"
🔍 分析 Bag 文件内容
查看文件信息
# inspect_bag.py
from rosbags.rosbag1 import Reader as Reader1
from rosbags.rosbag2 import Reader as Reader2
import os
file_path = "converted_ros1_bag.bag" # 你的 bag 文件路径
if file_path.endswith('.bag'):
Reader = Reader1
else:
Reader = Reader2
with Reader(file_path) as reader:
print("=== 话题信息 ===")
for connection in reader.connections:
print(f"话题: {connection.topic} | 类型: {connection.msgtype} | 数量: {connection.msgcount}")
print("\n=== 文件概览 ===")
total_msg_count = sum(conn.msgcount for conn in reader.connections)
print(f"总消息数: {total_msg_count}")
duration_ns = reader.duration
print(f"时长: {duration_ns / 1e9:.2f} 秒")
运行命令:
python inspect_bag.py
📸 提取图像数据
分析图像数据格式
python -c "
from rosbags.rosbag1 import Reader
with Reader('converted_ros1_bag.bag') as reader:
count = 0
for connection, timestamp, rawdata in reader.messages():
if connection.topic == '/rs_camera/rgb' and count < 2:
print(f'消息 {count}: 长度={len(rawdata)} 字节')
print(f'前50字节(hex): {rawdata[:50].hex()}')
print(f'后50字节(hex): {rawdata[-50:].hex()}')
count += 1
"
提取所有图像
# extract_images.py
from rosbags.rosbag1 import Reader
import cv2
import numpy as np
import os
def extract_all_images():
os.makedirs('extracted_images', exist_ok=True)
count = 0
with Reader('converted_ros1_bag.bag') as reader:
for connection, timestamp, rawdata in reader.messages():
if connection.topic == '/rs_camera/rgb':
try:
# 根据分析得到的图像尺寸调整参数
# 示例:1920x1080 RGB 图像
width, height = 1920, 1080
expected_size = width * height * 3
# 提取图像数据(通常在消息末尾)
image_data = rawdata[-expected_size:]
img_array = np.frombuffer(image_data, dtype=np.uint8).reshape(height, width, 3)
# 保存为 PNG
cv2.imwrite(f'extracted_images/image_{count:06d}.png', img_array)
count += 1
if count % 100 == 0:
print(f'已提取 {count} 张图像')
except Exception as e:
print(f'处理图像 {count} 时出错: {e}')
continue
print(f'成功提取 {count} 张图像到 extracted_images/')
if __name__ == "__main__":
extract_all_images()
运行命令:
python extract_images.py
🌐 提取点云数据
提取点云数据
# extract_pointclouds.py
from rosbags.rosbag1 import Reader
import os
def extract_all_pointclouds():
os.makedirs('extracted_pointclouds', exist_ok=True)
count = 0
with Reader('converted_ros1_bag.bag') as reader:
for connection, timestamp, rawdata in reader.messages():
if connection.topic == '/rs_lidar/points':
try:
# 保存原始点云二进制数据
with open(f'extracted_pointclouds/pointcloud_{count:06d}.bin', 'wb') as f:
f.write(rawdata)
# 保存元数据信息
with open(f'extracted_pointclouds/pointcloud_{count:06d}_info.txt', 'w') as f:
f.write(f"时间戳: {timestamp}\n")
f.write(f"话题: {connection.topic}\n")
f.write(f"消息类型: {connection.msgtype}\n")
f.write(f"数据长度: {len(rawdata)} 字节\n")
count += 1
if count % 50 == 0:
print(f'已提取 {count} 帧点云')
except Exception as e:
print(f'处理点云 {count} 时出错: {e}')
continue
print(f'成功提取 {count} 帧点云数据到 extracted_pointclouds/')
if __name__ == "__main__":
extract_all_pointclouds()
运行命令:
python extract_pointclouds.py
🎯 一键提取脚本
批量提取所有数据
# extract_all.py
from rosbags.rosbag1 import Reader
import cv2
import numpy as np
import os
def extract_all_data():
# 创建输出目录
image_dir = 'extracted_data/images'
pcd_dir = 'extracted_data/pointclouds'
os.makedirs(image_dir, exist_ok=True)
os.makedirs(pcd_dir, exist_ok=True)
image_count = 0
pcd_count = 0
with Reader('converted_ros1_bag.bag') as reader:
print("开始提取所有传感器数据...")
for connection, timestamp, rawdata in reader.messages():
try:
if connection.topic == '/rs_camera/rgb':
# 提取图像
width, height = 1920, 1080
expected_size = width * height * 3
image_data = rawdata[-expected_size:]
img_array = np.frombuffer(image_data, dtype=np.uint8).reshape(height, width, 3)
cv2.imwrite(f'{image_dir}/image_{image_count:06d}.png', img_array)
image_count += 1
elif connection.topic == '/rs_lidar/points':
# 提取点云
with open(f'{pcd_dir}/pointcloud_{pcd_count:06d}.bin', 'wb') as f:
f.write(rawdata)
pcd_count += 1
# 进度显示
if (image_count + pcd_count) % 100 == 0:
print(f'处理进度: {image_count} 图像, {pcd_count} 点云')
except Exception as e:
continue
print(f"提取完成!")
print(f"- 图像: {image_count} 张 -> {image_dir}")
print(f"- 点云: {pcd_count} 帧 -> {pcd_dir}")
if __name__ == "__main__":
extract_all_data()
运行命令:
python extract_all.py
🔧 故障排除
常见问题及解决方案
-
编码错误
# 使用正确的 typestore from rosbags.typesys import get_typestore, Stores typestore = get_typestore(Stores.ROS1_NOETIC) -
图像尺寸不匹配
# 尝试常见图像尺寸 sizes_to_try = [ (480, 640), # 640x480 (720, 1280), # 1280x720 (1080, 1920), # 1920x1080 ] -
数据位置不确定
# 尝试不同的偏移量 for offset in [0, 100, 200, 500, 1000]: image_data = rawdata[offset:offset+expected_size]
📊 验证提取结果
# 检查提取的文件
ls -la extracted_images/ | head -5
ls -la extracted_pointclouds/ | head -5
# 统计文件数量
echo "图像数量: $(ls extracted_images/*.png 2>/dev/null | wc -l)"
echo "点云数量: $(ls extracted_pointclouds/*.bin 2>/dev/null | wc -l)"
# 检查文件完整性
file extracted_images/*.png 2>/dev/null | head -3
💡 使用技巧
- 增量提取: 如果数据量很大,可以分批提取
- 进度监控: 定期打印进度信息
- 错误处理: 使用 try-except 避免单个文件错误影响整体提取
- 元数据保存: 同时保存时间戳等元数据信息
📁 输出文件结构
extracted_data/
├── images/
│ ├── image_000000.png
│ ├── image_000001.png
│ └── ...
└── pointclouds/
├── pointcloud_000000.bin
├── pointcloud_000000_info.txt
└── ...

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)