Unsloth:大模型微调的“超跑”——让训练速度提升2-5倍,显存暴降70%
Unsloth:大模型微调的“超跑”——让训练速度提升2-5倍,显存暴降70%
在开源大语言模型(LLM)爆发的今天,微调(Fine-tuning)已成为开发者定制专属模型的必经之路。然而,微调 Llama 3、Mistral 或 Gemma 等模型通常面临两大拦路虎:漫长的训练时间和巨大的显存开销。
今天为大家介绍一个在 AI 社区爆火的神器——Unsloth。它就像一只名为“不懒惰”的树懒,彻底改变了 LLM 的微调效率。
(图源:Unsloth GitHub 官方仓库)
🚀 什么是 Unsloth?
Unsloth 是一个开源的轻量级 LLM 训练/微调库。它的核心目标非常简单粗暴:在不损失任何精度的前提下,让模型训练速度更快,显存占用更低。
根据官方数据和社区实测,Unsloth 能带来惊人的性能提升:
- 训练速度:比使用 Hugging Face + Flash Attention 2 快 2 到 5 倍。
- 显存占用:最高可减少 70% 到 80% 的 VRAM 消耗。
- 精度无损:不同于某些近似加速方法,Unsloth 使用精确计算,准确率 0% 损失。
这意味着,以前需要昂贵 A100 显卡才能跑的任务,现在可能一张消费级的 RTX 3090 甚至免费的 Google Colab T4 就能搞定。
🛠️ Unsloth 的“黑科技”原理
Unsloth 之所以能实现如此巨大的性能飞跃,并非仅仅是工程上的修修补补,而是深入到底层数学和内核层面进行了重构:
-
手动推导的反向传播(Manual Autograd):
通常的深度学习框架(如 PyTorch)依赖自动微分引擎。Unsloth 团队手动推导了所有计算密集型阶段(如 MLP 和 Attention 模块)的微分数学公式,并重写了反向传播引擎,去除了大量冗余计算。 -
OpenAI Triton 内核重写:
他们使用 OpenAI 的 Triton 语言重写了 GPU 内核。这些定制内核极其高效,能够充分榨干 GPU 的算力,比通用的 CUDA 内核更快。 -
动态量化与内存管理:
Unsloth 极好地支持了 4-bit 和 16-bit 的 QLoRA/LoRA 微调,并在加载模型时就进行了极致的内存优化。
🌟 核心特性与支持模型
1. 广泛的模型支持
Unsloth 更新极快,几乎第一时间支持业界最热门的开源模型:
- Llama 系列:Llama 3.1 (8B, 70B, 405B), Llama 3, Llama 2
- Mistral 系列:Mistral v0.3, Mixtral 8x7B
- Google 系列:Gemma 2 (9B, 27B), Gemma
- 其他热门:Qwen 2.5, Phi-3, Yi, DeepSeek 等
2. 完美兼容 Hugging Face 生态
你不需要重新学习一套 API。Unsloth 与 Hugging Face 的 transformers、peft 和 trl 库无缝集成。你常用的 SFTTrainer 或 Trainer 代码几乎可以直接复用。
3. 便捷的模型导出
训练完成后,Unsloth 允许你通过一行代码将模型导出为多种格式,方便部署:
- GGUF:用于 llama.cpp、Ollama 等本地推理工具。
- Merged 16-bit / 4-bit:用于 vLLM 或直接推理。
- LoRA Adapters:仅保存微调后的权重。
⚡ 性能对比:Unsloth vs 标准库
下图展示了在单卡 NVIDIA Tesla T4(免费 Colab GPU)上的训练速度对比:
| 库 / 方法 | 训练时长 (越短越好) | 显存占用 (越低越好) |
|---|---|---|
| Hugging Face (标准) | 100% (基准) | 100% (基准) |
| Flash Attention 2 | ~70% | ~80% |
| Unsloth (普通) | ~50% (快2倍) | ~40% |
| Unsloth (Pro版) | ~5% - 30% (极速) | 极低 |
(注:Unsloth 开源版已足够强大,Pro 版提供多卡训练优化)
💻 快速上手指南
下面是一份基于 Unsloth 微调 Llama 3 的极简教程。
第一步:安装 Unsloth
根据你的 CUDA 版本(通常 Colab 是 12.1),运行以下命令:
# 安装 PyTorch 和 Unsloth
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps "xformers<0.0.27" "trl<0.9.0" peft accelerate bitsandbytes
(注意:本地安装请参考 GitHub 官方指南 以匹配你的 CUDA 版本)
第二步:加载模型 (4-bit 量化)
Unsloth 提供了一个 FastLanguageModel 类,极大简化了加载过程。
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # 支持自动 RoPE 缩放,可设为 4096, 8192 等
dtype = None # 自动检测 Float16/Bfloat16
load_in_4bit = True # 开启 4bit 量化以节省显存
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit", # 使用 Unsloth 预量化版本,下载更快
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
第三步:添加 LoRA 适配器
model = FastLanguageModel.get_peft_model(
model,
r = 16, # LoRA Rank
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16,
lora_dropout = 0, # Unsloth 建议设为 0 以加速
bias = "none", # Unsloth 建议设为 none 以加速
use_gradient_checkpointing = "unsloth", # 开启长上下文优化
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
第四步:开始训练
使用 Hugging Face 的 SFTTrainer 即可:
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset, # 你的数据集
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60, # 仅作演示
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
trainer.train()
第五步:推理与导出
训练完成后,你可以直接推理,或者导出为 GGUF 格式用于 Ollama:
# 导出为 GGUF (f16, q4_k_m, q8_0 等)
model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
🧐 总结
Unsloth 是目前单卡微调大语言模型的最佳选择之一。它通过极其硬核的底层优化,解决了显存焦虑和时间成本问题,让个人开发者和中小团队也能轻松玩转 Llama 3 级别的模型。
推荐使用场景:
- 在 Google Colab 或 Kaggle 免费 GPU 上微调模型。
- 本地显卡显存较小(如 8GB - 16GB)但想微调 8B/9B 模型。
- 需要快速迭代验证想法,不想等待数小时的训练。
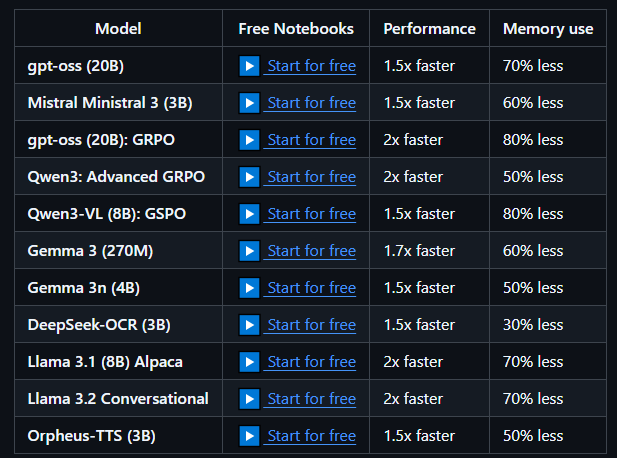
🔗 相关资源:
- GitHub 官网: https://github.com/unslothai/unsloth
- Hugging Face 模型库: https://huggingface.co/unsloth
- 免费 Colab 笔记本: 官网提供了大量现成的 Notebook 链接,一键运行即可。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)