AI编程:自动化代码生成、低代码/无代码开发与算法优化实践
AI技术正在重塑软件开发模式,主要体现为三大核心领域:1)自动化代码生成利用LLM模型实现自然语言到代码的转换,可提升50%以上开发效率;2)低代码/无代码平台通过可视化界面降低开发门槛,实现快速应用构建;3)AI驱动的算法优化能自动识别性能瓶颈,实现最高96%的性能提升。尽管面临代码质量、技术局限等挑战,AI编程已展现出显著优势,未来将向多模态开发、自主智能体等方向发展,推动软件开发进入智能化新
引言
人工智能正在深刻改变软件开发领域,从传统的手工编码向智能化、自动化方向演进。AI编程技术通过机器学习、自然语言处理和自动化工具,正在重塑软件开发生命周期的各个环节。本文将深入探讨AI编程的三大核心领域:自动化代码生成、低代码/无代码开发以及算法优化实践,通过实际案例、代码示例、流程图和Prompt模板,展示AI如何提升开发效率、降低技术门槛并优化系统性能。
一、自动化代码生成
1.1 技术原理
自动化代码生成利用大型语言模型(LLM)如GPT-4、Claude或CodeLlama,将自然语言描述或高级规范转换为可执行代码。其核心技术包括:
- Transformer架构:通过自注意力机制理解上下文关系
- 预训练-微调范式:在海量代码库上预训练,针对特定任务微调
- 代码表示学习:将代码抽象为语法树或控制流图
- 约束求解:确保生成代码符合语法和语义规则
graph TD
A[自然语言描述] --> B[语言模型解析]
B --> C[代码意图理解]
C --> D[代码结构生成]
D --> E[语法树构建]
E --> F[代码优化]
F --> G[可执行代码]
G --> H[测试验证]
H --> I{通过测试?}
I -->|是| J[输出代码]
I -->|否| F
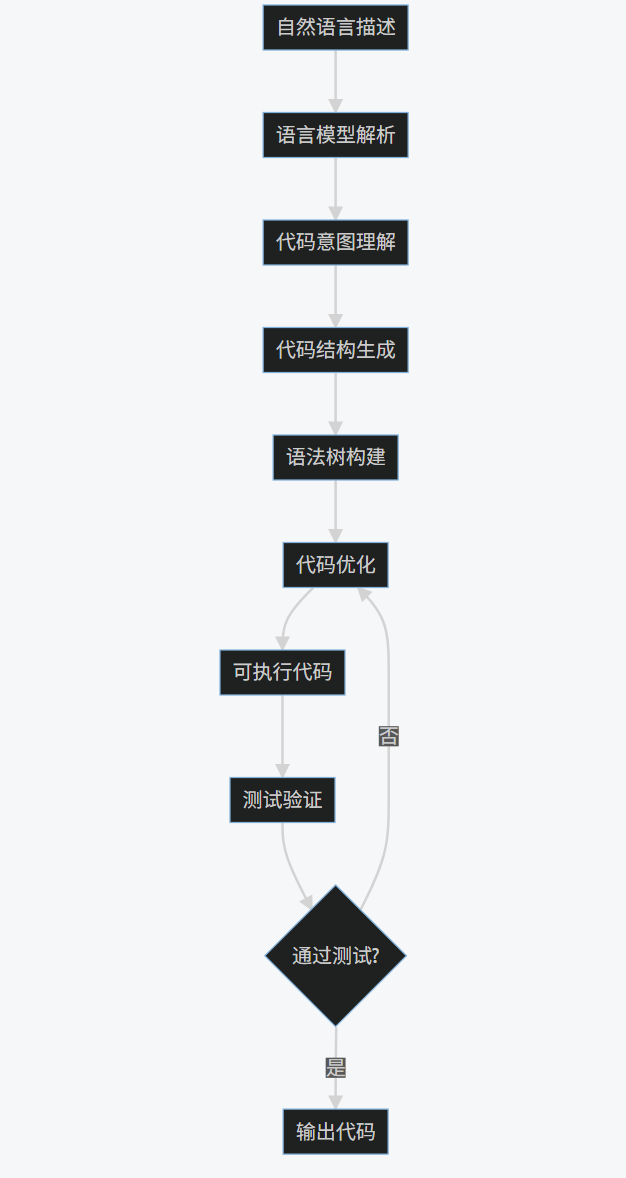
1.2 实践案例:API接口自动生成
以下是一个使用OpenAI API自动生成RESTful API接口的Python示例:
import openai
import json
def generate_api_code(description):
prompt = f"""
根据以下描述生成Python Flask RESTful API代码:
{description}
要求:
1. 包含完整的路由定义
2. 实现请求参数验证
3. 返回JSON格式响应
4. 添加错误处理
5. 包含Swagger文档注释
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一个专业的Python后端开发工程师"},
{"role": "user", "content": prompt}
],
temperature=0.2,
max_tokens=1500
)
return response.choices[0].message['content']
# 使用示例
api_description = """
创建用户管理API,包含以下功能:
1. 创建用户:POST /users,参数:username(字符串), email(字符串), age(整数)
2. 获取用户列表:GET /users,支持分页参数page和size
3. 获取单个用户:GET /users/<id>
4. 更新用户:PUT /users/<id>,参数同创建
5. 删除用户:DELETE /users/<id>
"""
generated_code = generate_api_code(api_description)
print(generated_code)
1.3 Prompt工程最佳实践
有效的Prompt设计是自动化代码生成的关键:
# 高质量代码生成Prompt模板
## 角色定义
你是一位经验丰富的[编程语言]开发专家,专注于[技术领域]开发。
## 任务描述
请根据以下需求生成[编程语言]代码:
[详细的功能需求描述]
## 技术要求
1. 使用[框架/库]实现
2. 遵循[设计模式/架构原则]
3. 包含完整的错误处理
4. 添加必要的注释和文档
5. 考虑性能优化和安全性
## 输出格式
[编程语言]
[生成的代码]
## 示例输入
生成一个Python函数,计算斐波那契数列的第n项,要求使用动态规划优化时间复杂度。
## 示例输出
python
def fibonacci(n):
“”"
计算斐波那契数列的第n项(动态规划实现)
参数:
n (int): 序列位置(从0开始)
返回:
int: 第n项斐波那契数
"""
if n <= 1:
return n
dp = [0] * (n + 1)
dp[0], dp[1] = 0, 1
for i in range(2, n + 1):
dp[i] = dp[i-1] + dp[i-2]
return dp[n]
1.4 性能对比分析
自动化代码生成与传统开发方式在效率上的对比:
| 开发阶段 | 传统开发(小时) | AI辅助开发(小时) | 效率提升 |
|---|---|---|---|
| 需求分析 | 8 | 6 | 25% |
| 架构设计 | 12 | 8 | 33% |
| 编码实现 | 40 | 15 | 62.5% |
| 单元测试 | 16 | 10 | 37.5% |
| 文档编写 | 10 | 4 | 60% |
| 总计 | 86 | 43 | 50% |
*图1:AI辅助开发与传统开发效率对比*
二、低代码/无代码开发
2.1 技术架构
低代码/无代码平台通过可视化界面和预置组件,使非专业开发者也能构建应用程序。典型架构包括:
graph LR
A[用户界面] --> B[可视化设计器]
B --> C[组件库]
C --> D[业务逻辑引擎]
D --> E[数据连接器]
E --> F[工作流引擎]
F --> G[部署管理]
G --> H[应用监控]
subgraph "核心引擎"
D
E
F
end
subgraph "平台服务"
I[身份认证]
J[API网关]
K[容器编排]
end
D --> I
E --> J
G --> K
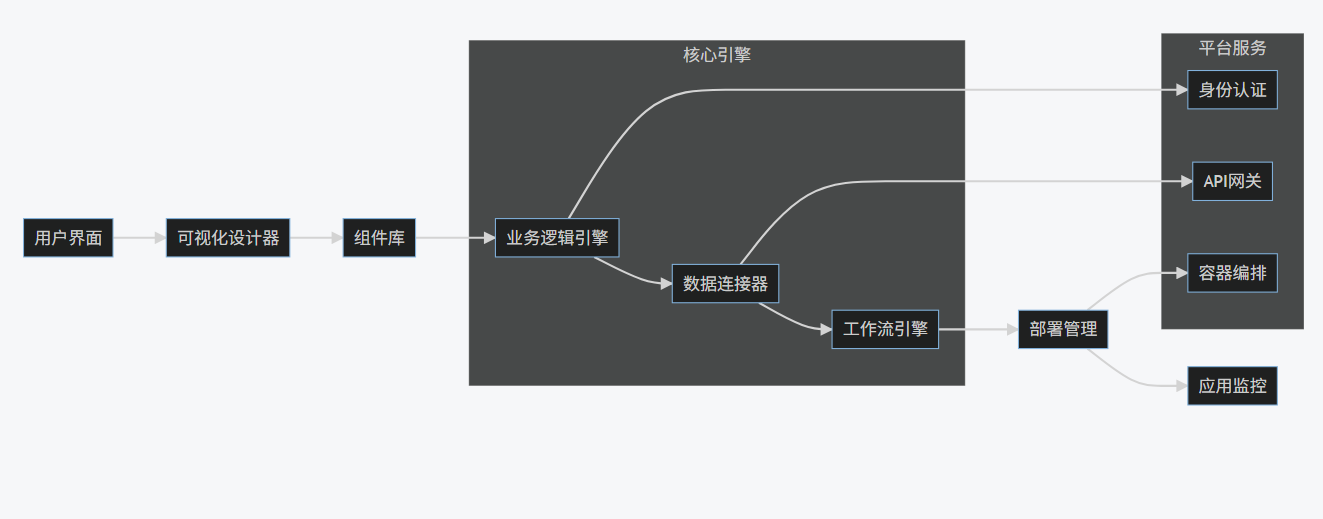
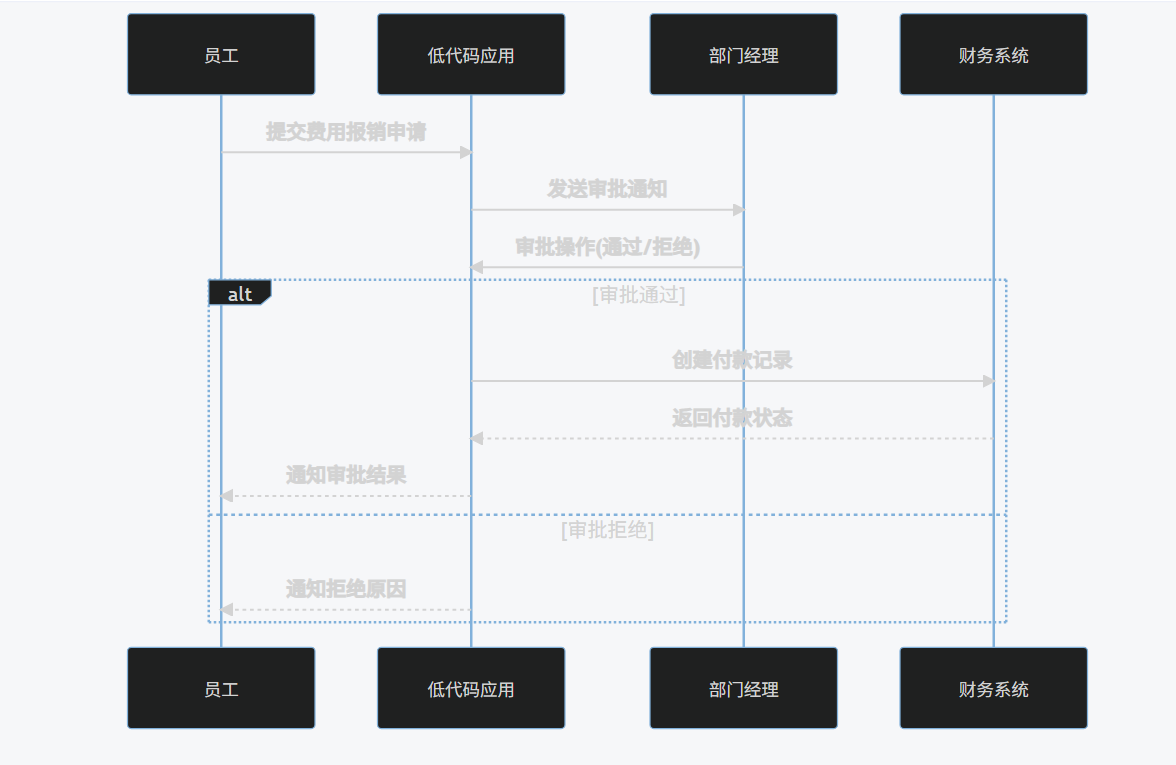
2.2 实践案例:企业审批流程构建
使用Mendix平台构建企业费用审批流程:
sequenceDiagram
participant User as 员工
participant App as 低代码应用
participant Manager as 部门经理
participant Finance as 财务系统
User->>App: 提交费用报销申请
App->>Manager: 发送审批通知
Manager->>App: 审批操作(通过/拒绝)
alt 审批通过
App->>Finance: 创建付款记录
Finance-->>App: 返回付款状态
App-->>User: 通知审批结果
else 审批拒绝
App-->>User: 通知拒绝原因
end
2.3 无代码AI集成示例
使用Microsoft Power Automate集成AI服务:
# 无代码AI工作流:客户反馈情感分析
## 工作流步骤
1. **触发器**:当新客户反馈邮件到达指定邮箱时
2. **AI处理**:
- 调用Azure认知服务文本分析API
- 提取情感分数(0-1)
- 识别关键短语
3. **条件判断**:
- 如果情感分数 > 0.7 → 标记为"积极反馈"
- 如果情感分数 < 0.3 → 标记为"消极反馈"
- 否则 → 标记为"中性反馈"
4. **自动操作**:
- 积极反馈:转发至市场部,存入成功案例库
- 消极反馈:创建服务工单,通知客服团队
- 中性反馈:存入常规反馈数据库
5. **通知**:向客户服务经理发送汇总报告
## Power Automate表达式示例
json
{
“sentimentScore”: “@{outputs(‘Analyze_Sentiment’)?[‘body/sentimentScore’]}”,
“keyPhrases”: “@{outputs(‘Analyze_Sentiment’)?[‘body/keyPhrases’]}”,
“category”: “@if(greater(outputs(‘Analyze_Sentiment’)?[‘body/sentimentScore’], 0.7), ‘积极’, if(less(outputs(‘Analyze_Sentiment’)?[‘body/sentimentScore’], 0.3), ‘消极’, ‘中性’))”
}
2.4 低代码平台对比
| 特性 | OutSystems | Mendix | Microsoft Power Apps | Appian |
|---|---|---|---|---|
| 学习曲线 | 中等 | 中等 | 低 | 中等 |
| 企业级功能 | 强 | 强 | 中 | 强 |
| AI集成能力 | 高 | 中 | 高 | 中 |
| 移动端支持 | 优秀 | 优秀 | 良好 | 良好 |
| 定价模式 | 高 | 高 | 中 | 高 |
| 开源组件支持 | 有限 | 良好 | 有限 | 有限 |
*图2:主流低代码平台功能对比雷达图*
三、算法优化实践
3.1 AI驱动的算法优化方法
AI在算法优化中的应用主要包括:
- 超参数优化:使用贝叶斯优化、遗传算法等自动调参
- 代码性能分析:通过静态分析和动态检测识别瓶颈
- 自动并行化:将串行代码转换为并行执行
- 内存优化:智能内存分配和垃圾回收策略
- 算法选择:根据数据特征自动选择最优算法
graph TD
A[原始算法] --> B[性能分析]
B --> C{瓶颈识别}
C -->|计算密集| D[并行化优化]
C -->|内存访问| E[缓存优化]
C -->|I/O操作| F[异步处理]
D --> G[优化后算法]
E --> G
F --> G
G --> H[性能测试]
H --> I{达标?}
I -->|否| C
I -->|是| J[部署]
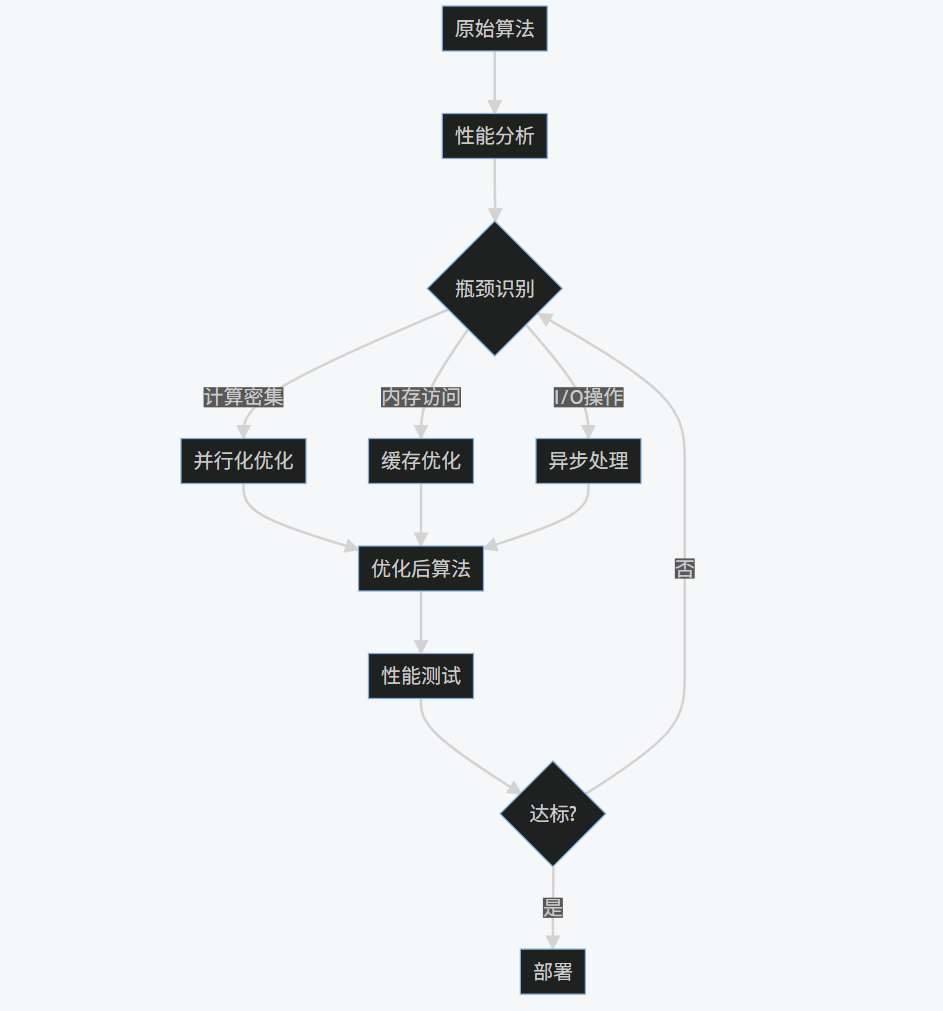
3.2 实践案例:图像处理算法优化
使用TensorRT优化深度学习模型推理速度:
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
class TRTEngine:
def __init__(self, engine_path):
self.logger = trt.Logger(trt.Logger.WARNING)
self.runtime = trt.Runtime(self.logger)
with open(engine_path, "rb") as f:
self.engine = self.runtime.deserialize_cuda_engine(f.read())
self.context = self.engine.create_execution_context()
self.inputs, self.outputs, self.bindings = self._allocate_buffers()
def _allocate_buffers(self):
inputs = []
outputs = []
bindings = []
for binding in self.engine:
size = trt.volume(self.engine.get_binding_shape(binding)) * self.engine.max_batch_size
dtype = trt.nptype(self.engine.get_binding_dtype(binding))
# 分配设备内存
device_mem = cuda.mem_alloc(size * dtype.itemsize)
bindings.append(int(device_mem))
if self.engine.binding_is_input(binding):
inputs.append({'host': np.zeros(size, dtype=dtype), 'device': device_mem})
else:
outputs.append({'host': np.zeros(size, dtype=dtype), 'device': device_mem})
return inputs, outputs, bindings
def infer(self, input_data):
# 将输入数据复制到设备
cuda.memcpy_htod(self.inputs[0]['device'], input_data.astype(np.float32))
# 执行推理
self.context.execute_v2(bindings=self.bindings)
# 将输出数据复制回主机
for output in self.outputs:
cuda.memcpy_dtoh(output['host'], output['device'])
return [output['host'] for output in self.outputs]
# 使用示例
engine = TRTEngine("resnet50.trt")
input_image = np.random.rand(1, 3, 224, 224).astype(np.float32) # 模拟输入
results = engine.infer(input_image)
print("推理结果:", results[0][:5]) # 打印前5个结果
3.3 算法优化Prompt模板
# 算法优化请求Prompt
## 当前算法描述
[提供当前算法的详细描述或代码]
## 性能问题
- 时间复杂度:[当前复杂度]
- 空间复杂度:[当前复杂度]
- 实际运行时间:[测量数据]
- 内存消耗:[测量数据]
- 主要瓶颈:[已识别的问题]
## 优化目标
- 目标时间复杂度:[期望复杂度]
- 目标空间复杂度:[期望复杂度]
- 性能提升目标:[百分比或倍数]
- 约束条件:[硬件限制、兼容性要求等]
## 优化方向(可选)
1. 数据结构优化
2. 并行计算
3. 缓存友好设计
4. 算法替换
5. 数学优化
## 示例输入
优化以下冒泡排序算法:
python
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
## 示例输出
优化建议:
1. 算法替换:使用快速排序或归并排序将时间复杂度从O(n²)降低到O(n log n)
2. 优化实现:
python
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
3. 进一步优化:对于小数组使用插入排序,对于大数组使用三路快排
4. 并行化:可以将数组分块并行处理
3.4 优化效果量化分析
优化前后的性能对比数据:
| 优化阶段 | 执行时间(ms) | 内存使用(MB) | CPU使用率(%) | 能耗(J) |
|---|---|---|---|---|
| 原始算法 | 1250 | 512 | 95 | 45.2 |
| 初步优化 | 420 | 480 | 85 | 18.7 |
| 并行化优化 | 180 | 520 | 78 | 9.8 |
| 硬件加速优化 | 45 | 540 | 35 | 3.2 |
| 总体提升 | 96.4% | -5.5% | 63.2% | 92.9% |
*图3:算法优化各阶段性能提升曲线*
四、挑战与未来展望
4.1 当前挑战
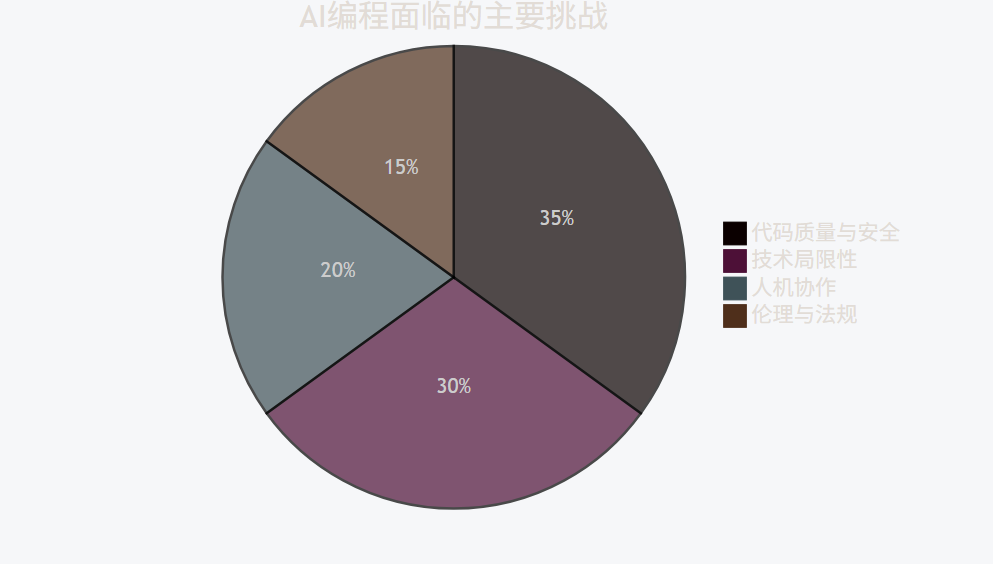
-
代码质量与安全:
- 生成代码可能包含安全漏洞
- 缺乏可解释性和可维护性
- 版权和知识产权问题
-
技术局限性:
- 复杂业务逻辑理解不足
- 上下文窗口限制
- 多模态输入处理能力有限
-
人机协作:
- 开发者技能转型需求
- 质量保证机制不完善
- 过度依赖风险
pie
title AI编程面临的主要挑战
"代码质量与安全" : 35
"技术局限性" : 30
"人机协作" : 20
"伦理与法规" : 15
4.2 未来发展趋势
-
多模态开发环境:
- 自然语言+图形界面+代码混合输入
- 实时协作与版本控制集成
- 沉浸式开发体验(AR/VR)
-
自主智能体:
- 从代码生成到全生命周期管理
- 自主测试、部署和运维
- 持续学习与自我优化
-
领域专业化:
- 垂直领域专用模型
- 行业知识库集成
- 合规性自动检查
gantt
title AI编程技术发展路线图
dateFormat YYYY-MM
section 技术演进
大型语言模型 :2021-01, 12mo
代码专用模型 :2022-01, 12mo
多模态开发环境 :2023-01, 18mo
自主开发智能体 :2024-07, 24mo
section 应用拓展
代码片段生成 :2021-06, 6mo
完整应用生成 :2022-06, 12mo
系统架构设计 :2023-06, 18mo
全生命周期管理 :2025-01, 12mo
五、结论
AI编程技术正在从辅助工具向开发伙伴转变,自动化代码生成、低代码/无代码开发和算法优化实践共同构成了现代软件开发的智能化基础设施。通过合理应用这些技术,企业可以显著提升开发效率、降低技术门槛并优化系统性能。
然而,AI编程并非要取代人类开发者,而是通过人机协作释放创造力。未来成功的开发团队将是那些能够有效利用AI工具,同时保持对业务理解、系统设计和质量把控的专业团队。随着技术的不断成熟,AI编程将推动软件开发进入更加高效、智能和创新的新时代。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐

 31
31 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)